Recherche 3x plus rapide : mise à l'échelle parallèle au moment du test avec Instructed-Retriever-1
Aujourd'hui, nous annonçons une mise à jour majeure qui rend Agent Bricks Knowledge Assistant à la fois plus rapide et plus performant. Le temps de génération des réponses a été divisé par 2, et le temps de recherche par plus de 3, ce qui ramène le Time To First Token (TTFT) à environ deux secondes.¹ Ainsi, les utilisateurs de Knowledge Assistant obtiendront des réponses nettement plus rapides pour tous leurs cas d'usage, sans aucune reconfiguration nécessaire ni compromis sur la qualité.
Ces gains sont rendus possibles par Instructed-Retriever-1, un modèle spécialisé dans la recherche d'informations conçu pour la mise à l'échelle parallèle au moment du test (parallel test-time scaling). Contrairement à la recherche agentique standard, où un agent travaille de manière séquentielle et analyse chaque résultat avant de décider de l'étape suivante, notre approche répartit ce travail en parallèle. Instructed-Retriever-1 est un modèle unique entraîné pour les deux étapes de la recherche : la génération de requêtes pour augmenter le rappel (recall) et le réordonnancement (reranking) pour augmenter la précision, exécutés en parallèle pour maintenir une faible latence. Dans cet article, nous décrivons comment cette approche permet d'obtenir des performances optimales au sens de Pareto, comment nous entraînons un modèle unique pour prendre en charge l'intégralité du pipeline de recherche, et comment nous validons les performances sur des charges de travail d'entreprise réalistes.
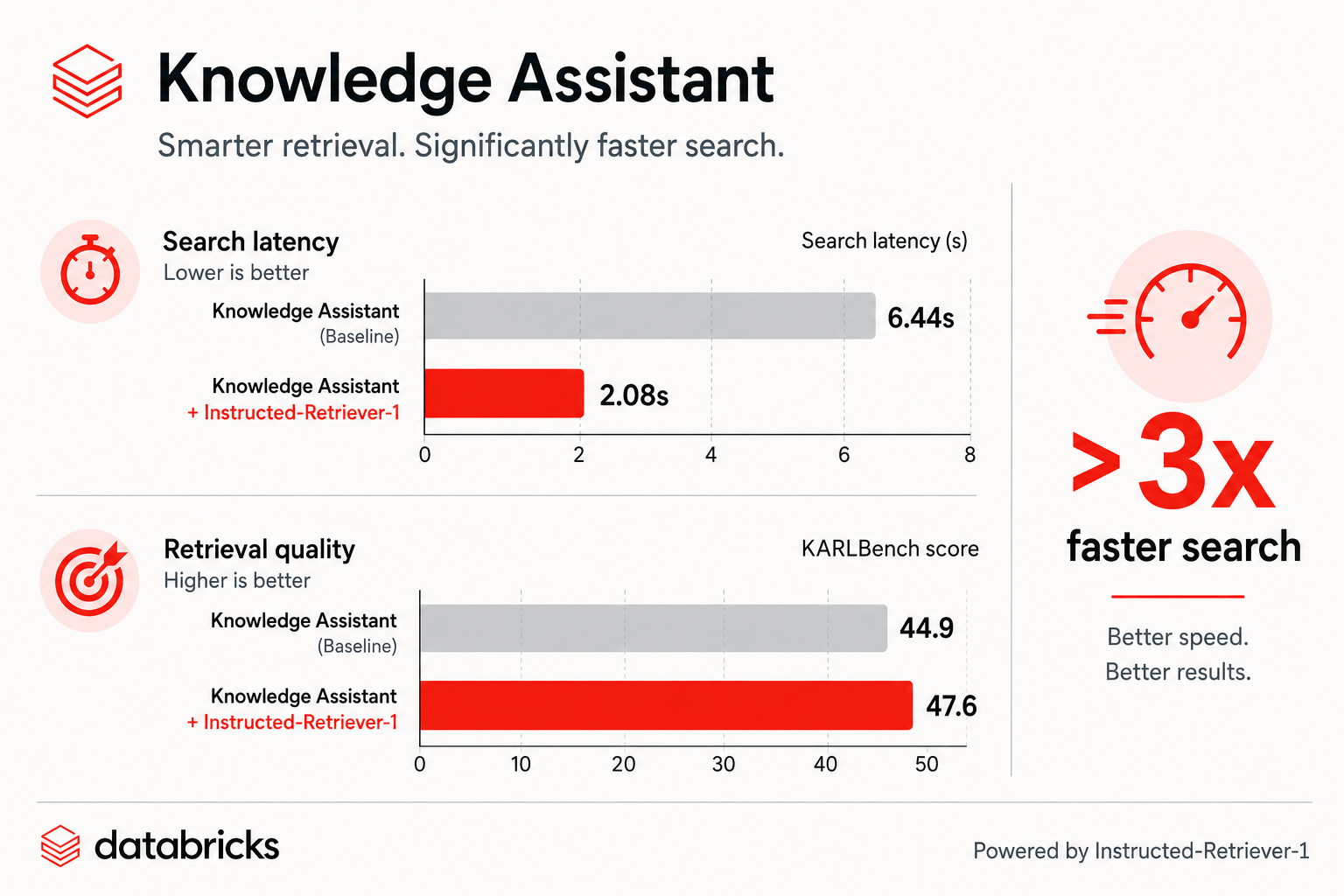
Figure : Sur KARLBench, Knowledge Assistant avec Instructed-Retriever-1 améliore à la fois la latence de recherche et la qualité de la recherche.
1. Mise à l'échelle parallèle au moment du test pour la recherche
Nos recherches précédentes ont démontré que la qualité peut s'améliorer avec du calcul supplémentaire au moment du test (test-time compute). Cependant, la plupart des systèmes de recherche agentique actuels consacrent ce calcul à des opérations séquentielles, telles que les appels d'outils, les boucles de raisonnement-action et le raisonnement par chaîne de pensée. Ces méthodes améliorent certes la qualité de la recherche, mais au détriment d'une latence et de coûts nettement plus élevés. Pour l'entraînement d'Instructed-Retriever-1, nous empruntons une autre voie : plutôt que de mettre à l'échelle le calcul de manière séquentielle, nous le parallélisons lors de la phase de recherche initiale. En élargissant l'éventail des éléments de preuve récupérés et en sélectionnant d'emblée le contexte le plus pertinent, nous obtenons une recherche très efficace avec une latence nettement inférieure.
L'amélioration de la recherche initiale dépend fortement du framework d'entraînement (training harness). Notre framework fournit au modèle les instructions de l'utilisateur et le schéma précis de l'index de recherche sous-jacent, puis les propage à toutes les étapes ultérieures de génération de requêtes et de filtres, de réordonnancement et de génération de réponses. Nous avons décrit comment y parvenir dans notre précédent blog sur Instructed Retriever, et nous utilisons le même framework de recherche pour l'entraînement de notre modèle Instructed-Retriever-1. Cette approche est particulièrement importante pour les questions d'entreprise, qui impliquent souvent des contraintes spécifiques au domaine, telles que la période, l'organisation, le type de document ou le secteur de produits.
La génération parallèle de requêtes et de filtres améliore le rappel (recall) de l'ensemble de candidats en explorant simultanément plusieurs formulations et aspects d'une même demande. Cela permet au système d'effectuer des recherches plus larges tout en maintenant une faible latence. Une recherche plus large pose toutefois un défi d'agrégation. Différentes formulations peuvent renvoyer des fragments (chunks) redondants ou seulement partiellement pertinents. Pour sélectionner le contexte le plus utile à partir de l'ensemble de candidats fusionné, nous utilisons un réordonnanceur par groupe (groupwise reranker) multi-pivot. Les candidats sont classés dans des groupes parallèles, chacun étant ancré par un ou plusieurs fragments pivots, et les classements de groupe sont fusionnés dans un ordre final. Cela capture les principaux avantages de la comparaison des preuves en contexte tout en maintenant l'efficacité du réordonnancement.
Ensemble, ces étapes offrent deux leviers de mise à l'échelle au moment du test : l'augmentation du nombre de formulations de requêtes et de filtres améliore le rappel, tandis que l'augmentation du nombre de pivots améliore la précision. Comme ces deux étapes peuvent utiliser le parallélisme, le système peut allouer du calcul supplémentaire au moment du test pour obtenir un contexte de meilleure qualité tout en préservant une faible latence.
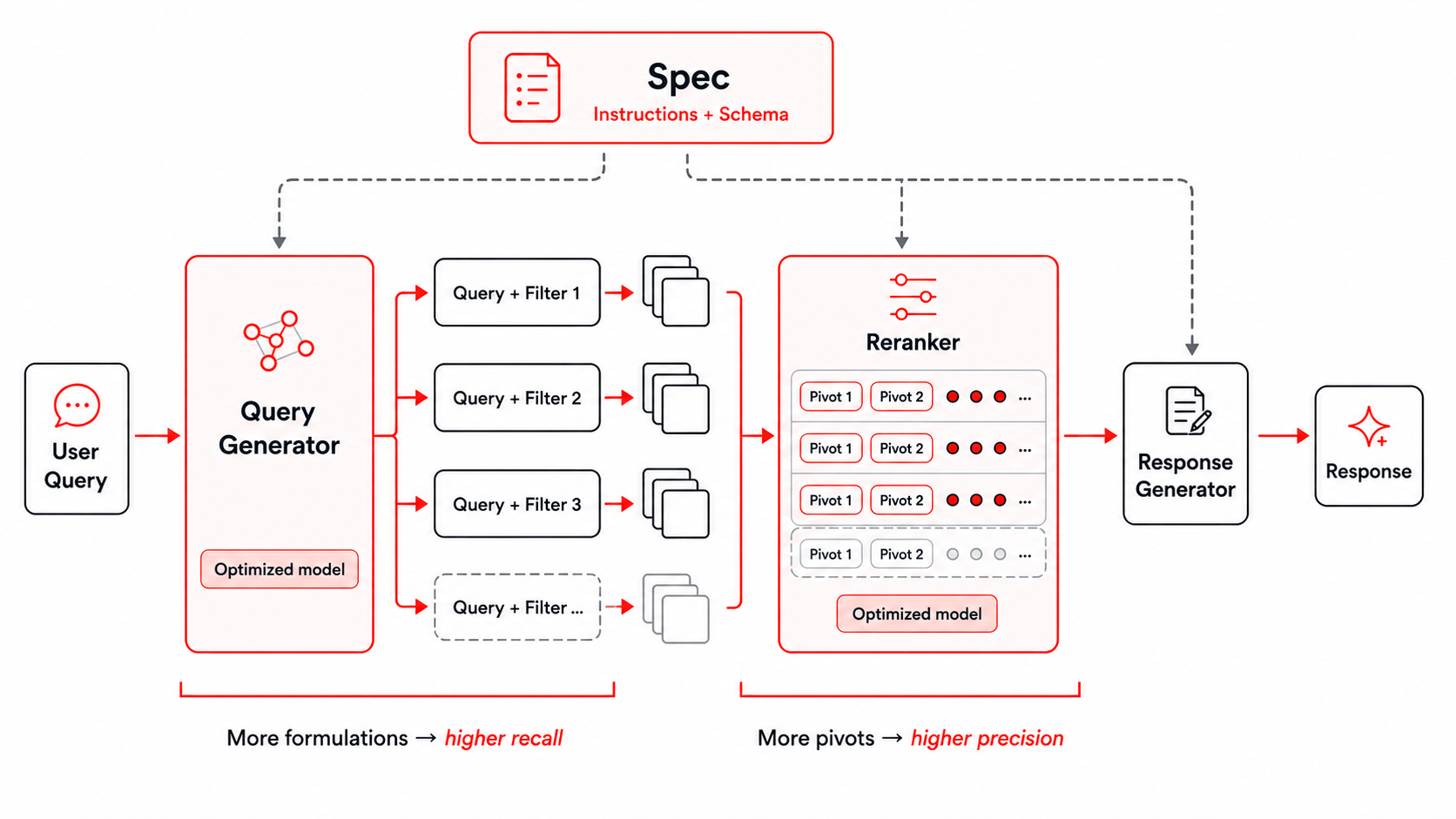
Figure : Le framework de recherche utilisé pour Instructed-Retriever-1.
2. Entraînement d'Instructed-Retriever-1
La mise à l'échelle parallèle au moment du test pour la recherche nécessite un modèle capable de faire deux choses bien : générer des recherches efficaces et évaluer les preuves récupérées. Nous avons entraîné Instructed-Retriever-1 en tant que modèle unique spécialisé dans la recherche d'informations, qui prend en charge la génération parallèle de requêtes et le réordonnancement. Le résultat est un modèle qui égale la qualité de recherche de Claude Sonnet 4.5 sur KARLBench tout en maintenant une faible latence.
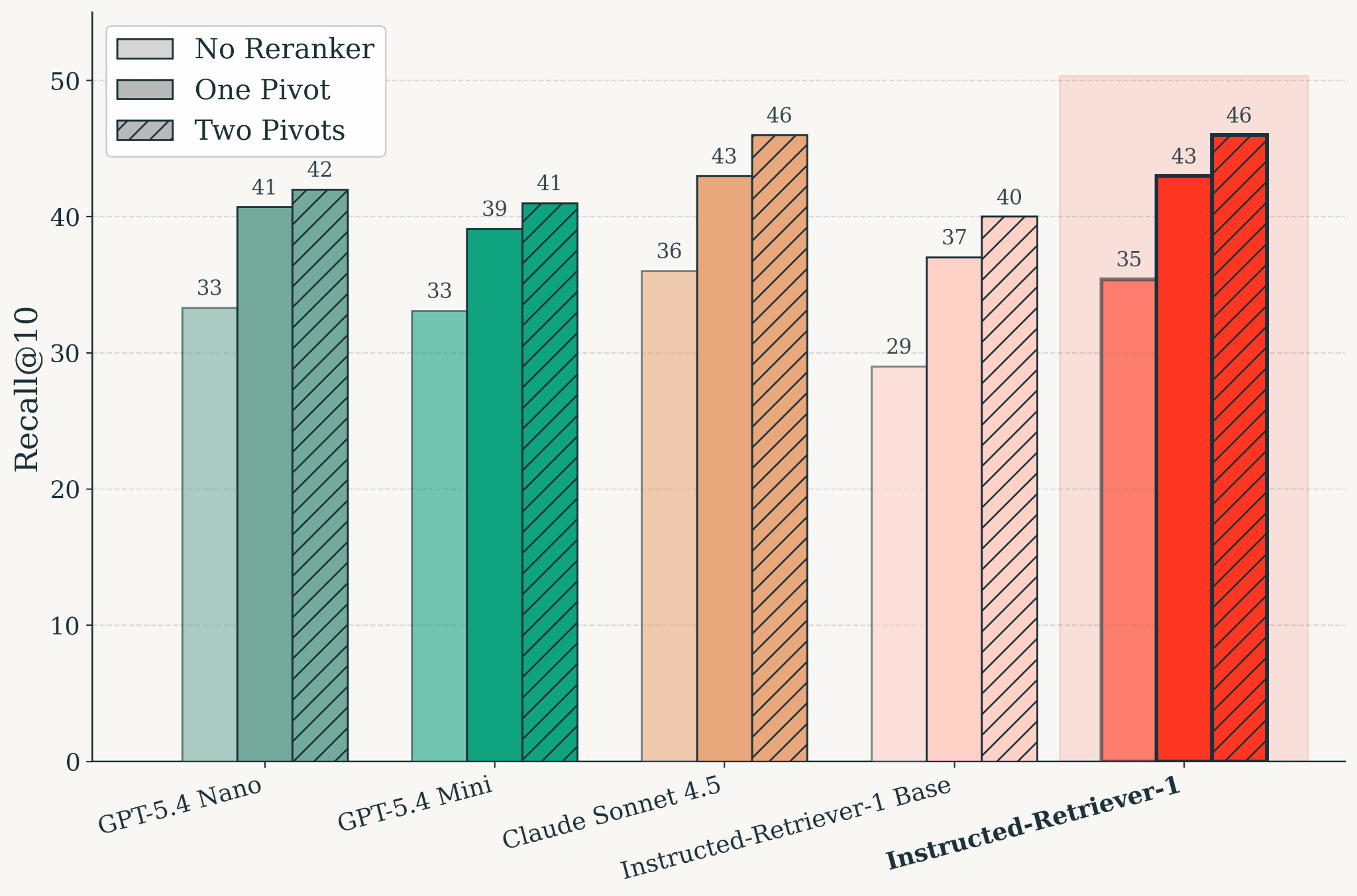
Figure : Qualité de la recherche sur KARLBench après entraînement, évaluée selon différentes configurations de réordonnancement. Instructed-Retriever-1 égale la qualité de recherche de Claude Sonnet 4.5. Quel que soit le modèle, le réordonnancement basé sur des pivots améliore le Recall@10 par rapport à l'absence de réordonnanceur, et l'utilisation de deux pivots améliore encore la qualité par rapport à un seul pivot.
Pour préparer les données pour l'entraînement, nous construisons des environnements de recherche synthétiques de type entreprise à partir d'un large corpus de pré-entraînement, indépendamment de notre benchmark d'évaluation. Nous les créons en utilisant l'approche de synthèse de données agentique décrite dans le rapport KARL. Les environnements qui en résultent reflètent les types de tâches que Knowledge Assistant doit gérer, notamment la recherche de faits, la synthèse, la recommandation, la résolution de problèmes et l'aide à la décision sur des corpus combinant des documents non structurés et des métadonnées structurées.
Le modèle est entraîné en deux étapes pour acquérir de multiples capacités de recherche. Le modèle obtenu prend en charge à la fois la génération de requêtes et de filtres, ainsi que des capacités de recherche de type vérification, rendant possibles les deux étapes qui rendent la mise à l'échelle parallèle au moment du test utile en pratique.
3. Validation d'Instructed-Retriever-1 en production
L'amélioration de la recherche n'a d'intérêt que si elle fonctionne sur des charges de travail réalistes et respecte les contraintes de latence en production. Nous évaluons Instructed-Retriever-1 sur un ensemble de données internes à grande échelle représentatif de l'utilisation de Knowledge Assistant, en mesurant si les deux mécanismes de mise à l'échelle présentés ci-dessus améliorent la qualité de la recherche : la génération parallèle de requêtes et de filtres pour le rappel, et le réordonnancement multi-pivot pour la précision.
Figure : Démonstration de Knowledge Assistant optimisé par Instructed-Retriever-1.
Qualité de la recherche sur des charges de travail réalistes
Notre ensemble de données d'évaluation est basé sur des charges de travail réelles de Knowledge Assistant, où les réponses utiles nécessitent souvent plusieurs éléments de preuve à l'appui plutôt qu'un seul document de référence (ground-truth). Nous évaluons la recherche en deux étapes. Tout d'abord, nous mesurons la latence et la qualité de la génération de requêtes sur l'ensemble des systèmes candidats. Pour la qualité, nous utilisons les scores d'évaluation d'un juge LLM (LLM-judge) pour la spécificité, la largeur et la pertinence. Ces métriques permettent de déterminer si les requêtes générées sont ciblées, couvrent les aspects importants de la demande et restent utiles pour répondre à la question.
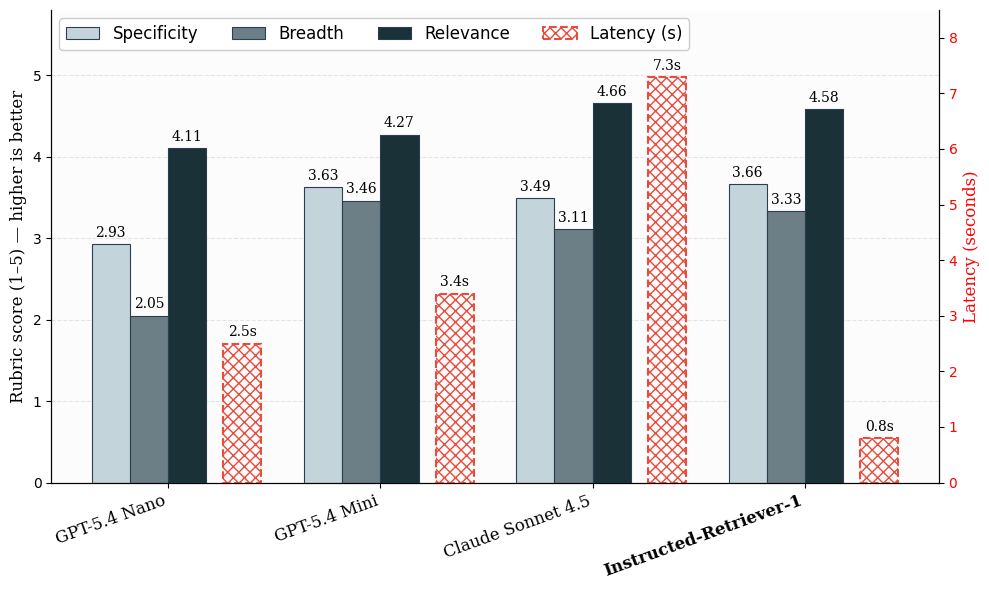
Figure : Qualité et latence de la génération de requêtes sur des exemples internes similaires à la production. Les scores moyens évaluent la qualité de la génération de requêtes selon la spécificité, la largeur et la pertinence sur une échelle de 1 à 5. La latence est calculée pour une étape de génération de requêtes.
Pour le réordonnancement, nous figeons l'ensemble des candidats récupérés et évaluons l'efficacité avec laquelle chaque réordonnanceur fait remonter les preuves les plus utiles. Pour obtenir des labels de pertinence denses, nous utilisons un LLM juge pour attribuer un score à chaque fragment sur une échelle de pertinence de type TREC de 0 à 3, puis nous calculons le nDCG@10 à partir des classements obtenus. Claude Sonnet 4.5 et Instructed-Retriever-1 obtiennent respectivement des scores de 80,1 et 81,0 pour le nDCG@10. Il s'agit de gains de +12,8 % et +14,1 % par rapport à une configuration sans réordonnancement, ce qui démontre l'efficacité de notre réordonnanceur par groupe multi-pivot.
Globalement, sur des charges de travail réalistes, Instructed-Retriever-1 affiche de solides performances sur l'ensemble des métriques d'évaluation de la génération de requêtes et reste compétitif par rapport à la référence la plus forte en matière de réordonnancement. Cela confirme l'intérêt d'utiliser un seul modèle spécialisé dans la recherche d'informations pour la génération de requêtes et la sélection de candidats.
Performances de service
La mise à l'échelle parallèle au moment de l'inférence n'est utile que si la puissance de calcul supplémentaire peut être fournie efficacement et s'adapte au nombre de recherches. À cette fin, Instructed-Retriever-1 utilise une architecture de type mélange d'experts (Mixture-of-Experts) et des optimisations de service, notamment la quantification FP8,2 le décodage spéculatif, ainsi qu'un ajustement supplémentaire de l'infrastructure pour l'ensemble du pipeline de recherche. Dans nos évaluations, le FP8 ne montre aucune dégradation de la qualité tout en améliorant la vitesse d'inférence et le débit par rapport au BF16.3 Le décodage spéculatif apporte une accélération supplémentaire de plus de 30 % pour le parcours combiné de génération de requêtes et de réordonnancement.
Conclusion
Cette mise à jour intègre la mise à l'échelle parallèle au moment de l'inférence (Parallel Test-Time Scaling) dans la pile de recherche en production. Le système effectue une recherche large grâce à la génération parallèle de requêtes et de filtres, puis réordonne précisément les résultats à l'aide d'une comparaison de preuves multi-pivots. Instructed-Retriever-1 alimente ces deux étapes avec un seul modèle spécialisé dans la recherche d'informations, entraîné pour la génération de recherche et le classement des preuves. Le résultat est un Knowledge Assistant à la fois plus performant et plus rapide : le temps de recherche est divisé par plus de 3, le temps de génération des réponses par 2, le TTFT est d'environ 2 s et la latence de bout en bout est systématiquement inférieure à 10 s sur notre configuration d'évaluation hors ligne.¹ Les premiers utilisateurs, comme l'Université de Baylor et d'autres, constatent déjà la différence.
« (La nouvelle expérience est) plus concise, avec un aspect plus réactif qui fait remonter les informations clés plus rapidement — une amélioration notable de l'UX pour nos cas d'usage. » —Kyle Van Pelt, directeur des processus et de la gouvernance, gestion des inscriptions à l'Université de Baylor.
Commencez dès aujourd'hui à en demander plus à votre Knowledge Assistant. Le déploiement d'Instructed-Retriever-1 a commencé pour tous les clients, aidant les équipes à récupérer un contexte de meilleure qualité avec moins d'attente ; vous pouvez poser plus de questions, découvrir plus de connaissances et passer plus rapidement de la question à la réponse. Essayez-le dès maintenant.
1 Estimations de latence mesurées en moyenne sur des évaluations hors ligne, avec une longueur moyenne d'environ 256 jetons (tokens) de sortie. La latence réelle peut varier en fonction de la structure des données dans les instances spécifiques du Knowledge Assistant et des requêtes.
2 Nous utilisons la bibliothèque ModelOpt de NVIDIA pour la quantification FP8.
3 Nous avons évalué les modèles BF16 et FP8 sur KARLBench sur 10 essais. Le FP8 n'a montré aucune dégradation statistiquement significative de la qualité par rapport au BF16 : la différence moyenne de score était de +0,33 point, avec une erreur type de 1,69 point et un intervalle de confiance à 95 % de [-2,99, 3,65].
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.