Déployez des LLM privés à l'aide de Databricks Model Serving
par Ahmed Bilal, Ankit Mathur, Kasey Uhlenhuth et Joshua Hartman
Nous sommes ravis d'annoncer la préversion publique de la prise en charge de l'optimisation des GPU et des LLM pour Databricks Model Serving ! Avec ce lancement, vous pouvez déployer des modèles d'IA open source ou vos propres modèles personnalisés de tout type, y compris des LLM et des modèles Vision, sur la plateforme lakehouse. Databricks Model Serving optimise automatiquement votre modèle pour LLM Serving, offrant des performances de premier ordre sans aucune configuration.
Databricks Model Serving est le premier produit de service GPU sans serveur développé sur une plateforme unifiée de données et d'IA. Cela vous permet de créer et de déployer des applications GenAI, de l'ingestion des données et de l'affinement au déploiement et au monitoring des modèles, le tout sur une seule et même plateforme.
Développez des applications d'IA générative avec Databricks Model Serving
« Avec le service de modèles Databricks, nous intégrons l'IA générative à nos processus pour améliorer l'expérience client et accroître l'efficacité de nos opérations. Le service de modèles nous permet de déployer des LLM tout en conservant un contrôle total sur nos données et nos modèles. » —Ben Dias, Directeur Data Science et Analytique chez easyJet - En savoir plus
Hébergez des modèles d'IA en toute sécurité sans vous soucier de la gestion de l'infrastructure
Databricks Model Serving fournit une solution unique pour déployer n'importe quel modèle d'IA sans avoir besoin de comprendre une infrastructure complexe. Cela signifie que vous pouvez déployer n'importe quel modèle (langage naturel, vision, audio, tabulaire ou personnalisé), quelle que soit la manière dont il a été entraîné : qu'il ait été créé de zéro, qu'il provienne de l'open source ou qu'il ait été affiné avec des données propriétaires. log simplement votre modèle avec MLflow, et nous préparerons automatiquement un conteneur prêt pour la production avec des bibliothèques GPU comme CUDA et le déploierons sur des GPU serverless. Notre service entièrement managé se chargera de toutes les tâches complexes pour vous, éliminant ainsi le besoin de gérer les instances, de maintenir la compatibilité des versions et d'appliquer des correctifs. Le service montera automatiquement en charge les instances pour s'adapter aux variations du trafic, ce qui permettra de réduire les coûts d'infrastructure tout en optimisant les performances en matière de latence.
« Le service de modèles Databricks décuple notre capacité à injecter de l'intelligence dans un large éventail de cas d'usage, depuis les applications de recherche sémantique jusqu'à la prédiction des tendances dans les médias. Parce que la plateforme masque et simplifie les opérations complexes de dimensionnement des serveurs CUDA et GPU, Databricks nous permet de nous concentrer sur notre véritable domaine d'expertise : étendre l'utilisation de l'IA à toutes les applications de Condé Nast sans nous préoccuper de l'infrastructure. »
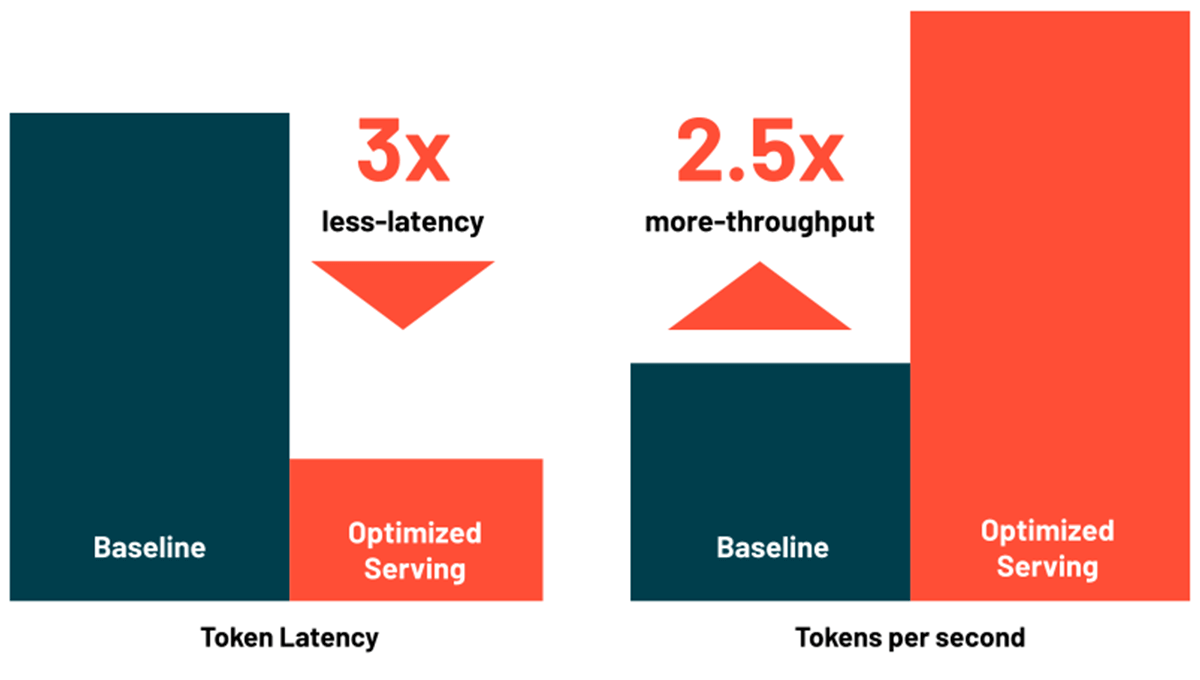
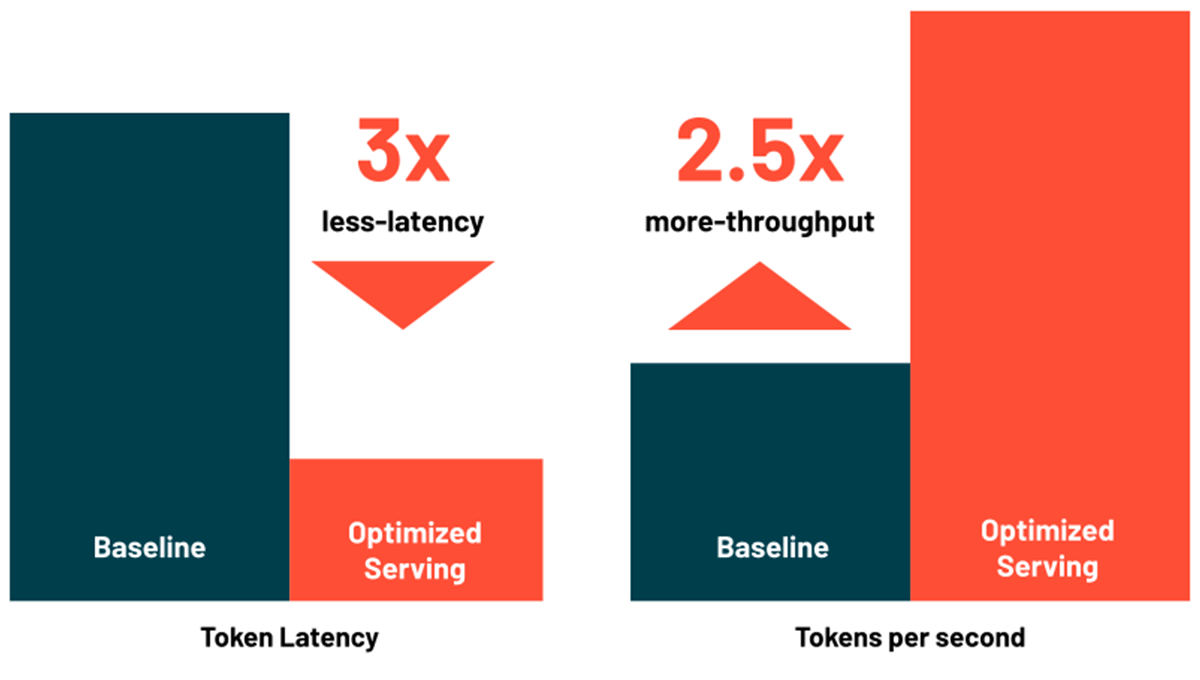
Réduisez la latence et les coûts grâce au service de LLM optimisé
Databricks Model Serving inclut désormais des optimisations pour servir efficacement les grands modèles linguistiques, réduisant la latence et les coûts jusqu'à 3 à 5 fois. Utiliser Optimized LLM Serving est incroyablement simple : il vous suffit de fournir le modèle avec ses poids OSS ou affinés, et nous nous occupons du reste pour garantir que le modèle est servi avec des performances optimisées. Cela vous permet de vous concentrer sur l'intégration de LLM dans votre application au lieu d'écrire des bibliothèques de bas niveau pour l'optimisation des modèles. Databricks Model Serving optimise automatiquement la classe de modèles MPT et Llama2, et la prise en charge d'autres modèles est à venir.
{kind=link}
Accélérez les déploiements grâce aux intégrations Lakehouse AI
Lors de la mise en production des LLM, il ne s'agit pas seulement de déployer des modèles. Vous devez également compléter le modèle à l'aide de techniques telles que la génération augmentée par récupération (RAG), l'affinement et efficace des paramètres (PEFT) ou l'affinement standard. De plus, vous devez évaluer la qualité du LLM et surveiller en continu les performances et la sécurité du modèle. Cela conduit souvent les équipes à consacrer un temps considérable à l'intégration d'outils hétérogènes, ce qui augmente la complexité opérationnelle et crée une surcharge de maintenance.
Databricks Model Serving est bâti sur une plateforme unifiée de données et d'IA qui vous permet de gérer l'intégralité du LLMOps, de l'ingestion des données et de l'affinement au déploiement et au monitoring, le tout sur une plateforme unique, créant une vue cohérente sur l'ensemble du cycle de vie de l'IA qui accélère le déploiement et minimise les erreurs. Model Serving s'intègre avec divers services LLM au sein du Lakehouse, notamment :
- Affinement: améliorez la précision et différenciez-vous en affinant les modèles de base avec vos données propriétaires directement sur Lakehouse.
- Intégration de la recherche vectorielle: Intégrez et effectuez en toute transparence des recherches vectorielles pour les cas d'utilisation de la génération augmentée par récupération et de la recherche sémantique. Inscrivez-vous à la préversion ici.
- Gestion LLM intégrée: Intégration avec Databricks AI Gateway en tant que couche API centrale pour tous vos appels LLM.
- MLflow: Évaluez, comparez et gérez les LLM via le PromptLab de MLflow.
- Qualité et diagnostics: capturez automatiquement les requêtes et les réponses dans une table Delta pour surveiller et déboguer les modèles. Vous pouvez également combiner ces données avec vos étiquettes pour générer des datasets d'entraînement grâce à notre partenariat avec Labelbox.
- Gouvernance unifiée: gérez et gouvernez toutes les données et tous les actifs d'IA, y compris ceux consommés et produits par Model Serving, avec Unity Catalog.
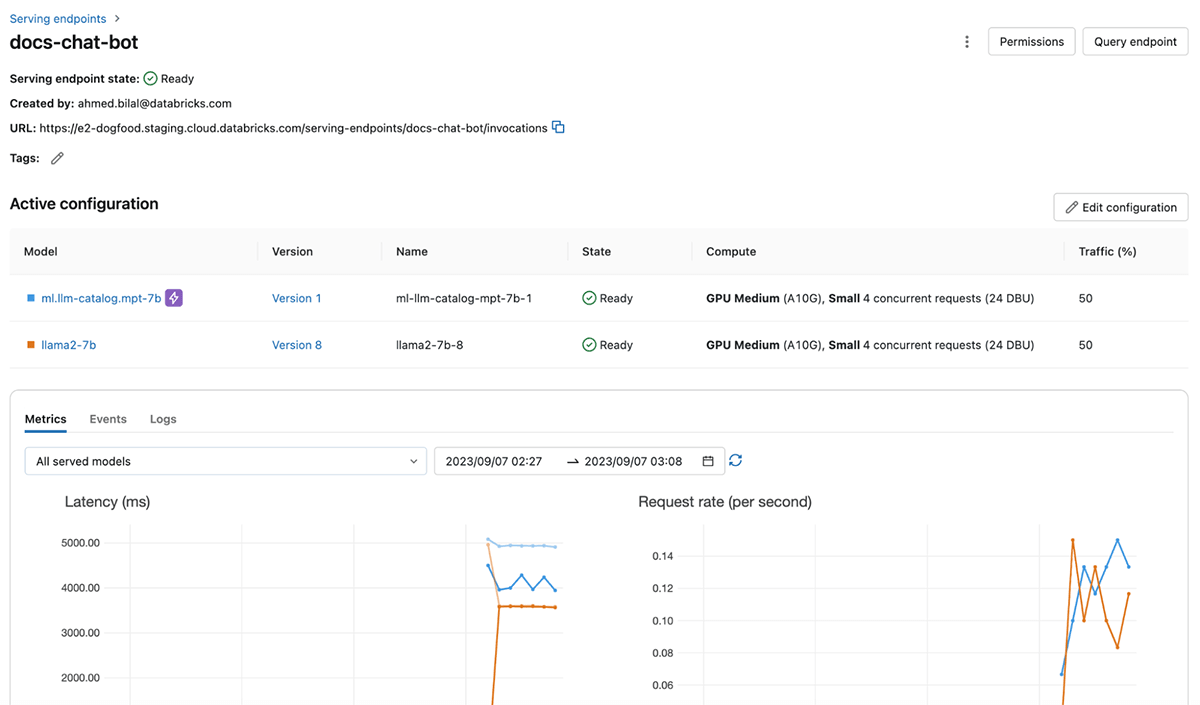
Garantir la fiabilité et la sécurité du service de LLM
Databricks Model Serving fournit des ressources de compute dédiées qui permettent l'inférence à grande échelle, avec un contrôle total sur les données, le modèle et la configuration du déploiement. En obtenant une capacité dédiée dans la région cloud de votre choix, vous bénéficiez d'une faible latence, de performances prévisibles et de garanties reposant sur un SLA. De plus, vos charges de travail de service sont protégées par plusieurs couches de sécurité, garantissant un environnement sécurisé et fiable même pour les tâches les plus sensibles. Nous avons mis en place plusieurs contrôles pour répondre aux besoins spécifiques en matière de conformité des Secteurs d'activité hautement réglementés. Pour plus de détails, veuillez consulter cette page ou contacter l'équipe de votre compte Databricks.
Prise en main du service GPU et LLM
- Essayez-le ! Déployez votre premier LLM sur Databricks Model Serving en consultant le tutoriel de démarrage (AWS | Azure).
- Explorez plus en détail la documentation de Databricks Model Serving.
- En savoir plus sur l'approche de Databricks en matière d'IA générative ici.
- Parcours d'apprentissage d'ingénieur en IA générative: suivez des cours à votre rythme, à la demande et avec instructeur sur l'IA générative
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.