Construction d'une recherche de produits en temps réel sur Databricks
par Jiayi Wu, Luke Lefebure et Adam Gurary
- Comment créer un système de recherche de produits en temps réel sur Databricks, couvrant l'ingestion, la récupération et le classement des composants nécessaires pour alimenter les expériences de recherche modernes.
- Une architecture de référence utilisant Databricks AI Search, Lakeflow et Lakebase pour traiter les données produit, récupérer les résultats pertinents et incorporer des signaux opérationnels en temps réel tels que les prix, l'inventaire et les préférences des utilisateurs.
- Bonnes pratiques et métriques pour exploiter la recherche à grande échelle, y compris l'évaluation de la qualité de la récupération, la surveillance de la latence et comment les agents et les applications peuvent s'appuyer sur les systèmes de recherche.
Imaginez que vous concevez un système de recherche pour une place de marché en ligne vendant des voitures. En quelques millisecondes, les utilisateurs s'attendent à des résultats qui correspondent à leur budget, à leurs préférences, qui sont disponibles près de chez eux et qui semblent pertinents.
C'est à quoi ressemble la recherche de produits web moderne. Ce n'est pas seulement un outil de recherche, mais un moteur de décision en temps réel qui doit récupérer, filtrer, classer et répondre presque instantanément — tout en équilibrant les métriques commerciales et techniques comme le revenu, le taux de clics, la latence et la pertinence.
Databricks fournit la plateforme de bout en bout pour construire ces systèmes — de l'ingestion de données évolutive (Lakeflow) à la récupération basée sur des vecteurs (AI Search) en passant par les données opérationnelles en temps réel (Lakebase) jusqu'aux expériences de recherche basées sur des agents (Agent Bricks). Ce blog explique comment ces éléments s'assemblent pour alimenter la recherche de produits en temps réel.
Composants pour la recherche de produits
La recherche de produits ne consiste pas simplement à répondre à une question ou à fournir des informations via un chatbot. C'est un processus de découverte et de décision — dynamique, personnalisé et profondément lié au revenu. Les acheteurs s'attendent à parcourir, comparer et explorer. L'objectif n'est pas de générer une seule réponse, mais de présenter un ensemble classé de choix qui semblent pertinents, fiables et dignes d'intérêt.
Un système de recherche de produits en temps réel comporte généralement 3 segments (Figure 1).
- L'ingestion prépare les données produit pour la recherche. Les titres, descriptions et attributs des produits sont traités, convertis en embeddings, enrichis de métadonnées et indexés pour une récupération rapide.
- La récupération trouve ce qui pourrait être pertinent en générant un ensemble de candidats à l'aide d'une recherche plein texte, sémantique ou hybride combinée à un filtrage structuré.
- Le raffinement détermine comment les résultats doivent être interprétés et ordonnés en appliquant la compréhension des requêtes, la logique de classement, la personnalisation et les règles métier.

{kind=link}
Derrière la barre de recherche
Aucune de ces expériences n'existe sans une infrastructure solide et des métriques significatives.
- L'infrastructure rend la vitesse et la pertinence possibles.
- Les métriques prouvent que votre système est réellement rapide et pertinent — pas seulement sur le papier.
La recherche de produits moderne exige les deux : la base d'ingénierie pour fournir des résultats, et la discipline des métriques pour valider continuellement que ces résultats sont suffisamment bons.
Présentation de l'architecture
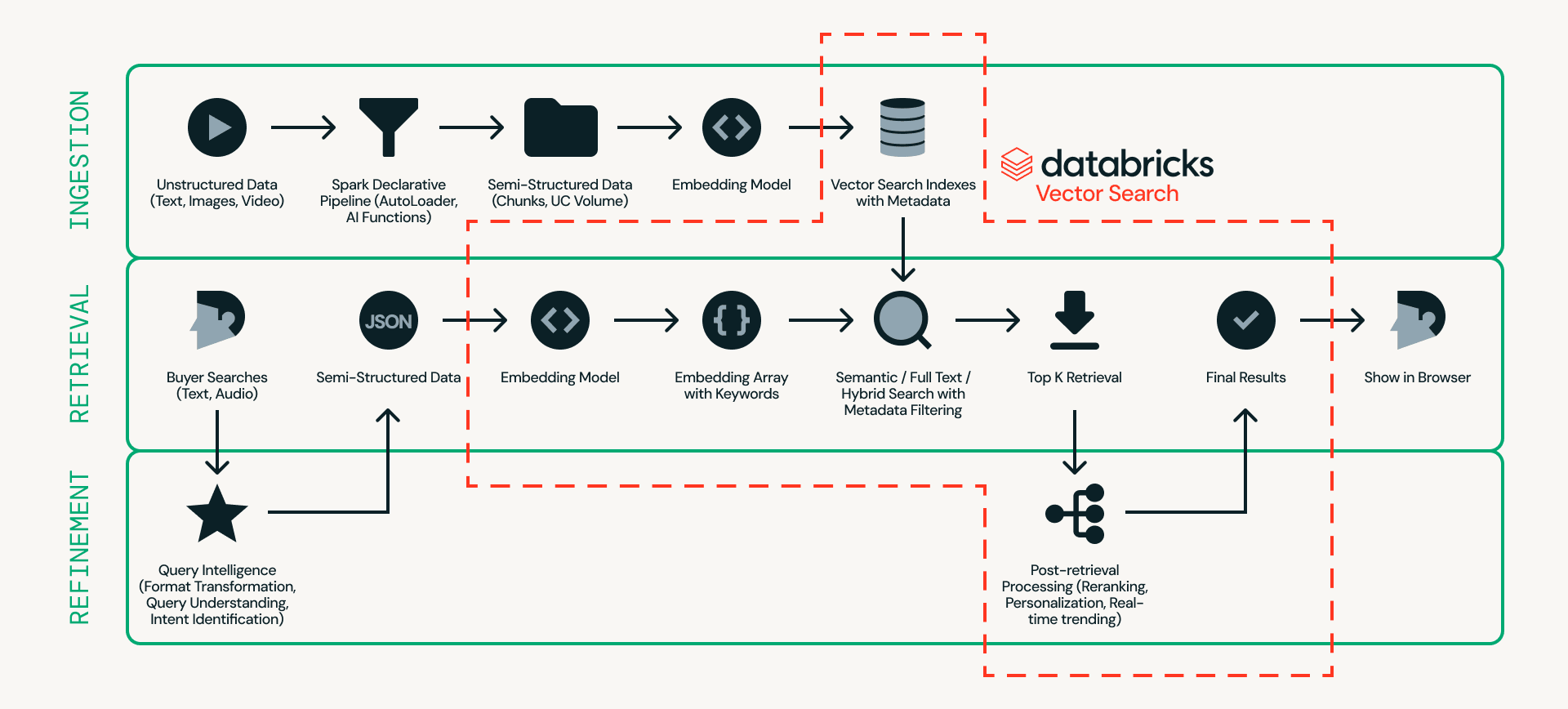
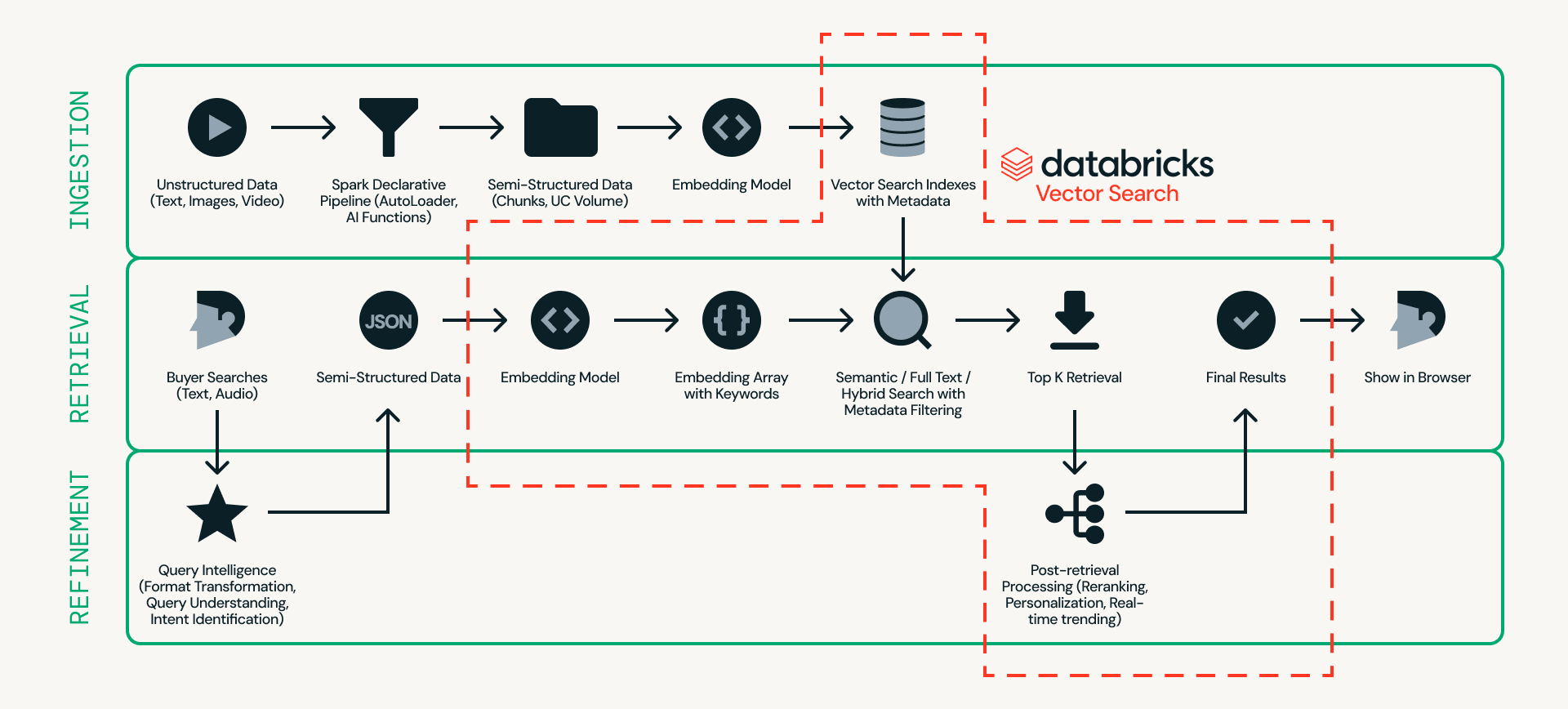
Tout d'abord, examinons l'architecture. La Figure 2 montre un exemple détaillé d'architecture de recherche de produits en temps réel.
{kind=link}
Au centre de cette conception se trouve Databricks AI Search, qui gère l'ingestion, la récupération et le raffinement sur une seule plateforme — éliminant le besoin de relier plusieurs systèmes externes.
- L'ingestion prépare les données produit afin qu'elles puissent être recherchées efficacement. Les sources non structurées telles que les listes de produits et les images sont traitées via des pipelines évolutifs utilisant Databricks Auto Loader, Lakeflow Spark Declarative Pipeline et AI Functions (par exemple, ai_parse_document). Les données peuvent ensuite être découpées et converties en embeddings avec des métadonnées (par exemple, modèle de voiture, couleur ou prix) dans Databricks AI Search.
- La récupération gère les requêtes en temps réel. L'entrée utilisateur est transformée en embeddings et en filtres structurés, et Databricks AI Search récupère les meilleurs candidats à l'aide de la recherche sémantique, de la recherche plein texte ou de la recherche hybride avec filtrage par métadonnées.
- Le raffinement améliore les candidats récupérés pour obtenir les résultats finaux. Bien que la récupération fournisse une base solide, cette couche affine les résultats en interprétant l'intention, en appliquant une logique de classement et en intégrant la personnalisation et les règles métier si nécessaire. Le contexte opérationnel en temps réel, tel que l'état de la session, l'inventaire, la tarification et les préférences de l'utilisateur, peut être servi via Lakebase, permettant des signaux de faible latence inférieurs à 10 ms d'influencer l'ordre final.
Quelques directives pratiques lors de la construction de systèmes de recherche sur Databricks :
- Expérimentez facilement avec les modèles. Remplacez les modèles d'embedding avec un minimum de friction et tirez parti des capacités natives de reranking. Les futures mises à jour permettront le réglage fin en un clic des modèles de reranking directement dans la plateforme, simplifiant l'optimisation de la pertinence.
- Servez l'état de l'application à la vitesse de la recherche. Utilisez Lakebase pour stocker l'état de l'application en temps réel — contexte de session, inventaire, tarification, préférences utilisateur — avec une latence inférieure à 10 ms. La synchronisation CDC gérée de Lakebase vers Delta automatiquement, de sorte que les modèles de classement et les analyses reflètent toujours les données opérationnelles actuelles sans pipelines personnalisés.
- Testez la mise à l'échelle avant la production. Validez la latence et le débit dans des conditions de trafic réalistes, y compris les scénarios QPS élevés. Vous pouvez simuler des charges de travail de production dès aujourd'hui à l'aide du notebook de test de charge de recherche, avec une prise en charge native des tests de charge en un clic à venir dans une future version. Pour un trafic soutenu, tirez parti des endpoints QPS élevés pour gérer la concurrence à grande échelle, et surveillez les performances grâce à l'observabilité des endpoints pour suivre la latence, le débit et la santé du système.
- Construisez une recherche prête pour les agents dès le premier jour. Chaque index AI Search avec des embeddings gérés obtient automatiquement un serveur MCP géré. Utilisez-le pour une intégration d'agent sans configuration, le VectorSearchRetrieverTool pour un contrôle basé sur le code, ou pointez un Knowledge Assistant vers votre index pour des questions-réponses instantanées avec citations — alimenté par Instructed Retriever, qui offre une précision 70 % meilleure que les systèmes RAG standard.
Métriques importantes
Un système de recherche n'est pas réussi parce qu'il est élégant sur un diagramme. Il est réussi parce qu'il fournit des résultats rapides et pertinents qui génèrent des résultats commerciaux.
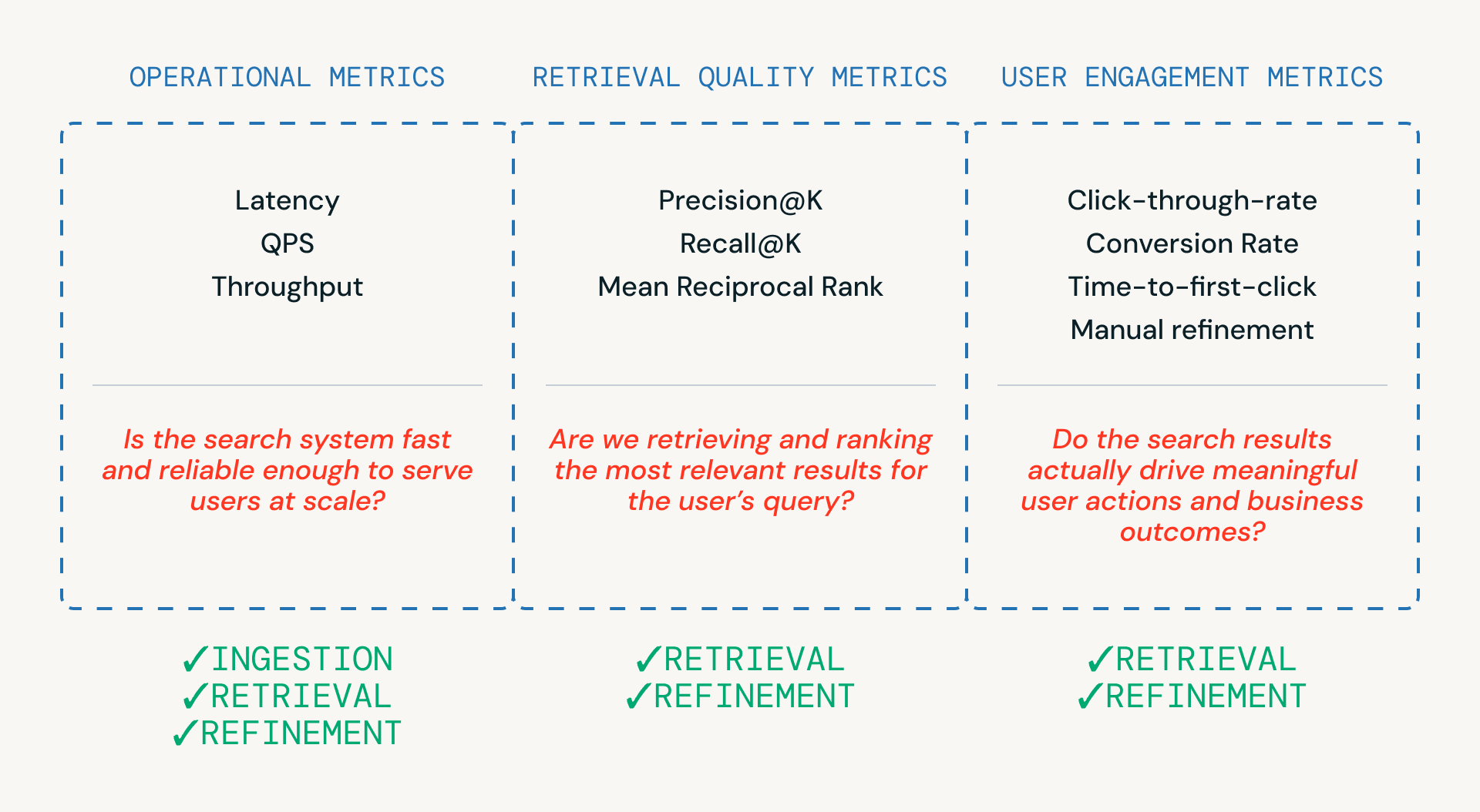
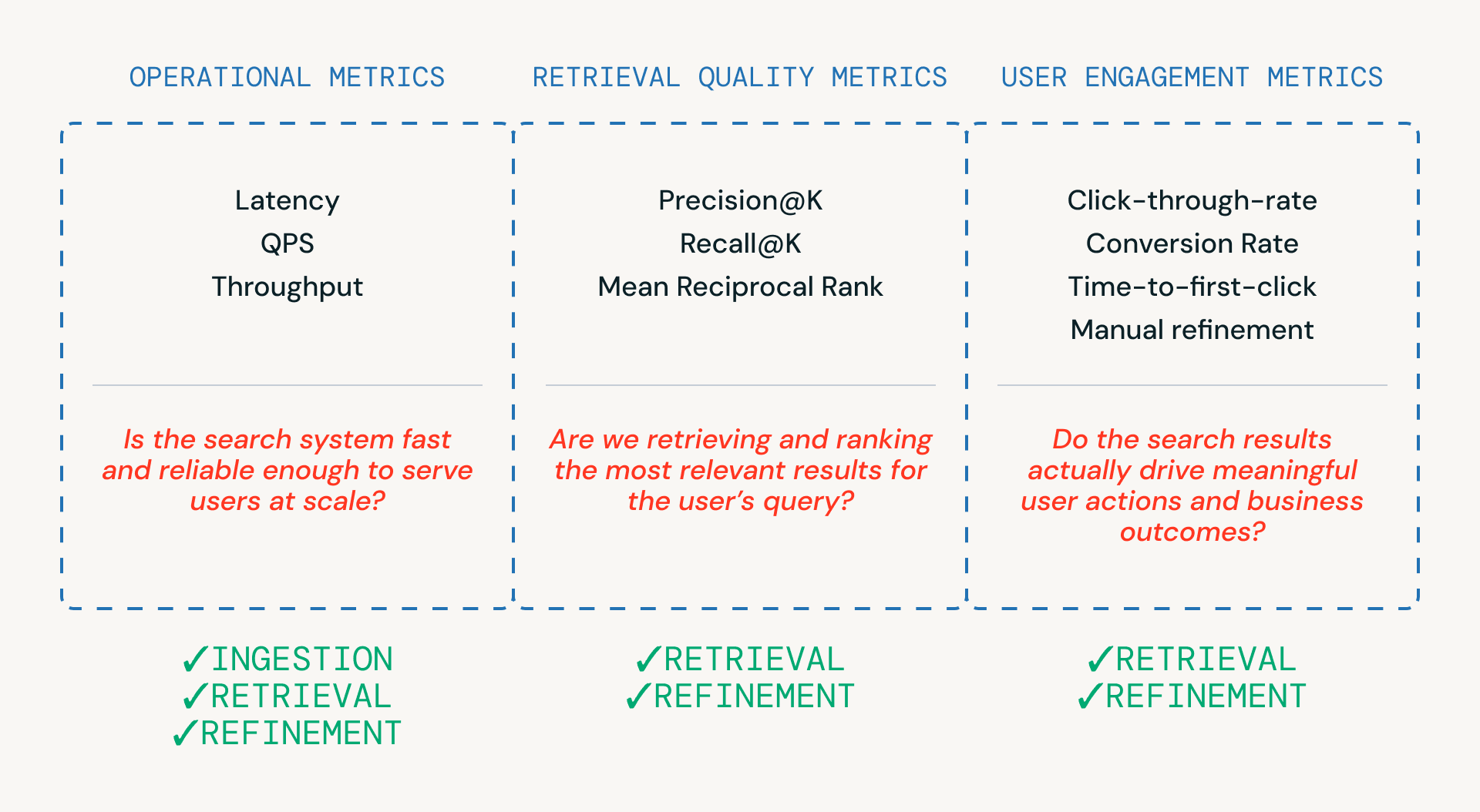
Comme le montre la Figure 3, trois catégories de métriques aident les équipes à évaluer un pipeline de recherche — chacune étant liée à une couche différente du système.
- Les métriques opérationnelles garantissent que le système est suffisamment rapide et fiable pour servir les utilisateurs à grande échelle. Elles sont essentielles à travers les étapes d'ingestion, de récupération et de raffinement.
- Les métriques de qualité de récupération mesurent si le système récupère et classe réellement des candidats pertinents, et sont étroitement liées aux étapes de récupération et de raffinement où le classement et le reranking se produisent.
- Les métriques d'engagement utilisateur capturent le comportement réel — que les utilisateurs cliquent, affinent ou finissent par convertir - fournissant des commentaires qui éclairent les améliorations de la récupération et des affinages au fil du temps.
{kind=link}
Quelques directives pratiques pour évaluer les systèmes de recherche sur Databricks :
- Équilibrez les métriques, n'en optimisez pas une seule. Des systèmes de recherche efficaces doivent équilibrer plusieurs métriques — vous ne gagnez rarement sur toutes les métriques à la fois. Par exemple, optimiser agressivement la précision peut augmenter la latence ou masquer des résultats pertinents, conduisant finalement à des acheteurs frustrés.
- Surveillez attentivement la latence en temps réel. Décomposez la latence par étapes du pipeline et suivez la latence des queues comme p95/p99 pour identifier rapidement les goulots d'étranglement. Des techniques telles que la mise en cache peuvent aider à respecter les SLA de latence stricts.
- Suivez les métriques systématiquement. Utilisez MLflow pour enregistrer et évaluer les métriques de récupération et d'engagement sur toutes les expériences. L'évaluation native de la qualité de récupération sera bientôt disponible pour Databricks AI Search, rendant cela encore plus facile.
Recherche en production à grande échelle — FOX Sports
FOX Sports a construit sa barre de recherche alimentée par l'IA sur Databricks AI Search, gérant des milliers de QPS avec une amélioration de 2x du taux de réussite des requêtes. Lancée pour le Super Bowl LIX, leur architecture démontre plusieurs modèles abordés dans ce blog :
- Ingestion en temps réel. Spark Structured Streaming ingère en continu du contenu dans les index Delta Sync au fur et à mesure de sa publication
- Récupération en deux phases. Correspondance exacte d'entités pour les joueurs et les équipes, plus recherche sémantique pondérée par le temps pour les articles et les vidéos, orchestrée par Databricks Model Serving
- Optimisation de la production. Une couche de mise en cache et une fonctionnalité de recherches tendances — générant plus de 25 % de toutes les requêtes de recherche — gèrent les pics de trafic élevés lors des événements en direct
De la recherche aux applications intelligentes
La recherche de produits n'existe pas isolément — c'est une couche dans une pile d'applications plus large. Voici comment le reste de la plateforme Databricks étend ce que vous pouvez construire sur AI Search.
Applications en temps réel avec Lakebase
Pour les applications de recherche destinées aux clients — marketplaces, catalogues de produits, plateformes médiatiques — l'index de recherche n'est qu'une partie de l'histoire. Les applications ont également besoin d'une base de données transactionnelle pour l'état opérationnel : niveaux de stock, prix, sessions utilisateur, préférences de personnalisation. Lakebase fournit cela sous la forme d'une base de données entièrement gérée, compatible PostgreSQL, nativement intégrée à la plateforme Databricks. La synchronisation bidirectionnelle gérée avec Delta Lake signifie que les modèles de classement s'entraînent sur les données opérationnelles les plus récentes, et les informations analytiques reviennent à la couche applicative — le tout gouverné par Unity Catalog.
Recherche basée sur des agents avec Agent Bricks
Databricks fournit automatiquement un serveur MCP géré pour chaque index AI Search, débloquant plusieurs modèles d'intégration :
- Assistant de connaissances. Un chatbot de questions-réponses sur vos documents. Pointez-le vers un index AI Search et obtenez une recherche de documents prête pour la production avec citations. Utilise Instructed Retriever sous le capot — 70 % de précision en plus que le RAG simple et 30 % de plus que le RAG agentique.
- Agents personnalisés. Utilisez le VectorSearchRetrieverTool ou MCP avec n'importe quel framework (OpenAI Agents SDK, LangGraph, LlamaIndex). Contrôle total sur les paramètres de récupération, les embeddings et les filtres. Déployez en tant qu'applications Databricks avec le traçage MLflow.
- Agent superviseur. Orchestrez plusieurs sous-agents : un Assistant de connaissances pour les Q&R de documents, un espace Genie pour les requêtes de données structurées et les fonctions UC pour la logique métier personnalisée — le tout coordonné par un seul superviseur.
Conclusion
Construire un système de recherche de produits moderne nécessite plus qu'un index de recherche. Cela nécessite une infrastructure conçue pour gérer l'échelle, les performances et l'observabilité du monde réel :
- Exécution à faible latence. La compréhension des requêtes, la récupération, le filtrage et le ré-classement doivent être effectués dans des budgets de latence stricts p95/p99.
- Capacité de récupération hybride. Combinez la similarité sémantique (embeddings) avec le filtrage structuré tel que le prix, la catégorie ou la disponibilité.
- Scalabilité sous charge. Maintenez un QPS et une concurrence élevés pendant les pics de trafic sans dégrader les performances.
- Observabilité. Maintenez une visibilité claire sur les décompositions de latence, les performances de classement et la santé globale du système.
- Prêt pour les agents par défaut. Chaque index AI Search est un outil MCP, immédiatement utilisable par l'Assistant de connaissances, les agents personnalisés et les Agents superviseurs.
- Support opérationnel complet. Lakebase fournit la base de données transactionnelle pour l'état des applications en temps réel, synchronisée avec Delta sans ETL.
Prêt à construire ? Suivez le guide de qualité de récupération pour évaluer et optimiser votre pipeline de recherche, voyez comment FOX Sports a construit une recherche alimentée par l'IA à grande échelle, et plongez dans la documentation AI Search pour commencer.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.