coSTAR : Comment nous expédions rapidement des agents IA chez Databricks, sans rien casser
Comment nous sommes passés de révisions manuelles de deux semaines à des tests et raffinements automatisés en quelques heures
par Alkis Polyzotis
- Nous construisons et déployons des agents chez Databricks en utilisant une méthodologie complète et automatisée de test et de raffinement appelée coSTAR (coupled Scenario, Trace, Assess, Refine) que nous avons développée à l'aide de MLflow. La méthodologie est structurée autour d'une analogie avec le développement logiciel traditionnel, utilisant des LLM comme suite de tests et un assistant de codage pour affiner automatiquement l'implémentation de l'agent jusqu'à ce que les tests réussissent.
- Cette méthodologie a éliminé la boucle de développement antérieure, lente et manuelle, "exécuter, réviser, corriger, répéter", qui était sujette aux régressions et manquait de confiance. coSTAR a réduit le temps de vérification des modifications de deux semaines à quelques heures, permettant une vélocité de développement plus élevée.
- Les mêmes tests sont exécutés en production pour détecter les problèmes sur le trafic utilisateur réel, et dans le cadre de nos pipelines CI/CD, nous aidant à signaler les régressions causées par des modifications dans l'infrastructure dépendante.
Vous ne laisseriez jamais un assistant de codage refactoriser votre base de code sans une suite de tests. Sans tests, l'assistant navigue à l'aveugle. Il pourrait corriger une fonction et en casser silencieusement trois autres. Les tests sont ce qui boucle la boucle : exécutez-les, observez les échecs, corrigez le code, exécutez-les à nouveau. Pas de tests, pas de confiance.
Chez Databricks, nous développons et déployons continuellement des agents qui couvrent un large éventail de fonctionnalités, des nouvelles fonctionnalités de la plateforme Databricks (par exemple, les capacités d'ingénierie de données, d'analyse de traces et d'apprentissage automatique dans Genie Code), aux projets OSS (par exemple, l'assistant MLflow), aux flux de travail d'ingénierie internes (par exemple, le support sur appel ou les réviseurs de code automatisés). Ces agents peuvent effectuer des tâches de longue durée, générer des milliers de lignes de code et créer de nouveaux actifs de données et d'IA, entre autres. Bien que nous ayons eu quelques vérifications de base en place dès le début, nous manquions du type de suite de tests complète et automatisée qui nous permettrait d'itérer en toute confiance. Ce post décrit comment nous avons comblé cette lacune en utilisant MLflow, et la méthodologie coSTAR (coupled Scenario, Trace, Assess, Refine) que nous avons construite autour. coSTAR exécute deux boucles couplées : une qui aligne les juges sur le jugement humain expert afin qu'ils puissent être fiables, et une qui utilise ces juges fiables pour affiner automatiquement l'agent jusqu'à ce qu'il réussisse tous les scénarios de test.
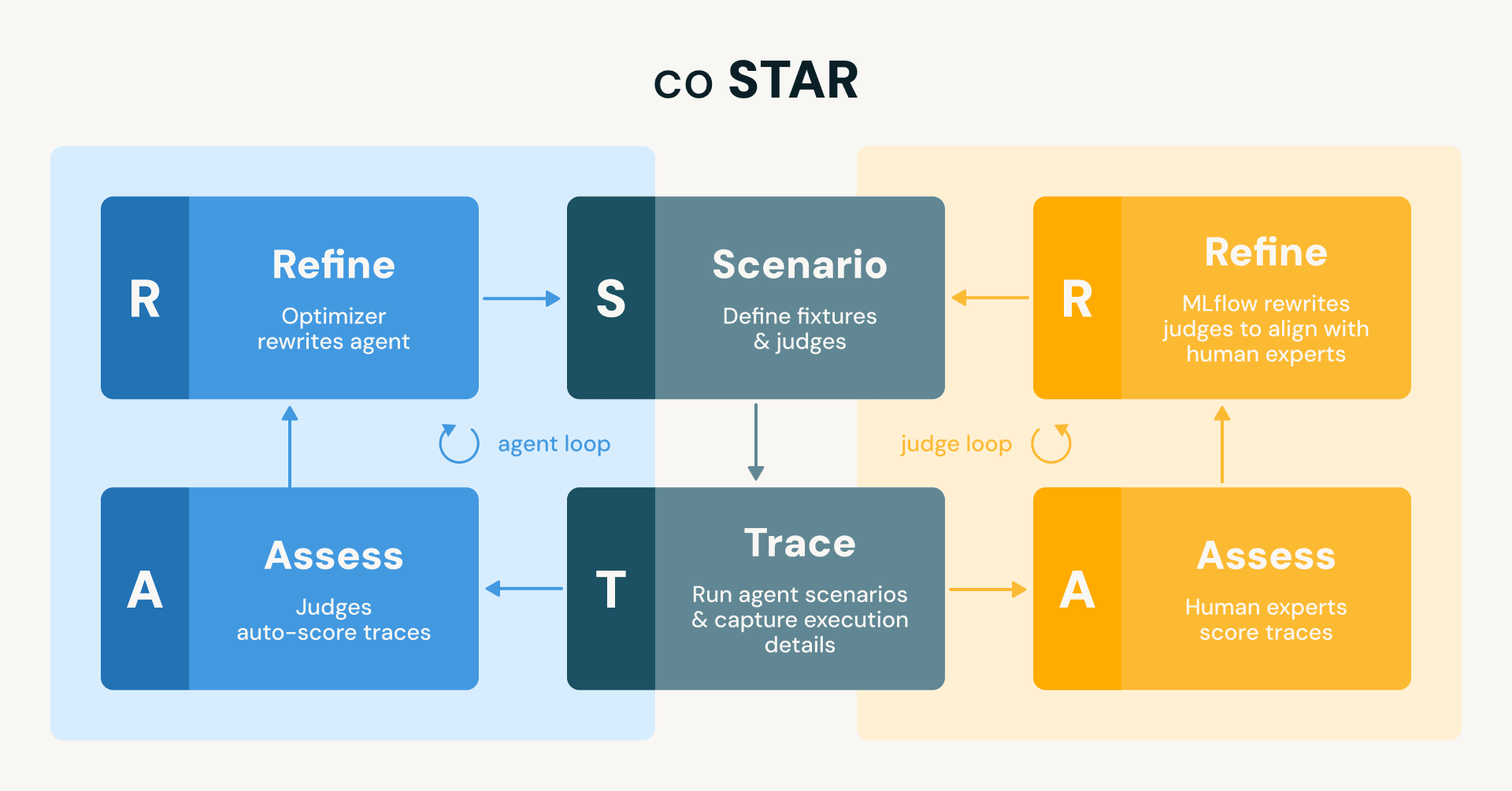
Figure : Le framework coSTAR exécute deux boucles STAR miroirs (Scenario → Trace → Assess → Refine). La boucle de l'agent (bleu) utilise des juges pour auto-évaluer les traces et affine l'agent pour l'aligner sur les juges. La boucle du juge (orange) utilise des experts humains pour évaluer les traces et affine les juges pour les aligner sur leurs évaluations. Les deux boucles partagent les mêmes scénarios et traces.
Le problème : Coder sans tests
Au début, notre boucle de développement ressemblait à ceci : exécuter l'agent, examiner manuellement sa sortie, repérer un défaut, demander à un assistant de codage de le corriger. Répéter.
Si cela vous rappelle l'écriture de code sans tests et le contrôle qualité manuel de chaque modification, c'est exactement ce que c'était. Et cela a échoué exactement comme vous pourriez le prédire. La réaction évidente est « alors écrivez des tests ». Mais les tests d'agents sont structurellement différents des tests d'une fonction déterministe, et plusieurs défis se cumulent à la fois :
- Non-déterminisme. La même implémentation, la même entrée, peut produire des sorties différentes lors d'exécutions différentes. Les tests doivent évaluer les propriétés de la sortie plutôt qu'affirmer des sorties exactes.
- Boucles de rétroaction lentes. Une seule exécution d'agent peut prendre des dizaines de minutes. Il n'y a pas d'itération comme le permet une suite de tests sub-seconde. Chaque cycle d'évaluation est coûteux.
- Erreurs en cascade. Une mauvaise décision à l'étape 3 provoque un échec à l'étape 7. Au moment où le symptôme apparaît, la cause racine est enfouie plusieurs étapes en arrière dans l'exécution de l'agent.
- Qualité subjective. Pour de nombreuses dimensions de test (ce code d'ingénierie de fonctionnalités est-il bon ? cette approche de nettoyage de données est-elle appropriée ?), il n'y a pas de vérité terrain. Le jugement de ces dimensions dépend de l'expertise du domaine.
Ces contraintes ont façonné chaque décision de conception qui suit. Elles sont aussi ce qui rend ce problème intéressant : nous ne construisons pas seulement un exécuteur de tests, nous construisons une méthodologie d'optimisation automatisée pour des processus stochastiques, de longue durée et multi-étapes où « correct » est une question de jugement.
L'analogie qui guide notre approche
Si vous plissez les yeux, le développement d'agents correspond parfaitement à la boucle de développement que chaque ingénieur connaît déjà :
| Logiciel traditionnel | Développement d'agents |
|---|---|
| Code source | Implémentation de l'agent (y compris les invites, les choix de FM, les outils) |
| Suite de tests | Juges LLM |
| Fixtures de test (configuration, entrée, sortie attendue) | Définitions de scénarios (état initial, invite, attentes) |
| Exécuteur de tests / harnais | Le harnais de test exécute l'agent sous test, produit des traces |
| Correction des tests (les tests vérifient-ils la bonne chose ?) | Alignement des juges (le juge est-il d'accord avec les experts humains ?) |
| L'assistant de codage corrige le code jusqu'à ce que les tests réussissent | L'assistant de codage affine l'implémentation jusqu'à ce que les juges réussissent |
| La CI exécute tous les tests à chaque changement | La CI exécute les scénarios + les juges à chaque changement |
| Surveillance de la production | Les mêmes juges s'exécutent sur le trafic en direct |
Cette analogie n'est pas seulement illustrative. C'est l'architecture littérale de notre système, que nous appelons coSTAR : deux boucles couplées qui utilisent des définitions de Scénarios comme fixtures de test, la capture de Traces comme harnais de test, l'Assessment avec des juges comme suite de tests, et le Raffinage comme boucle rouge-vert. Passons en revue chaque élément.
S - Définitions de scénarios
Dans les tests traditionnels, une fixture de test configure les préconditions : créer une base de données, l'alimenter en données, configurer l'environnement. Notre équivalent est une définition de scénario : une description structurée de l'état initial, de l'invite de l'utilisateur et des résultats attendus.
Voici un scénario simplifié pour tester un agent Data Analyst sur un jeu de données désordonné :
Chaque scénario regroupe la configuration, l'entrée et les critères de succès en un seul endroit, tout comme une fixture de test. Nous maintenons une suite de ces scénarios pour différents agents, couvrant les cas courants, les cas limites et les échecs passés connus. La suite grandit au fil du temps à mesure que nous découvrons de nouveaux modes d'échec : chaque bug que nous trouvons en production devient un nouveau scénario, de la même manière que chaque bug de production devrait devenir un test de régression.
Pourquoi s'embêter avec cette structure ? Parce que les exécutions d'agents sont coûteuses. Un seul scénario prend des minutes à exécuter. Nous devons être délibérés sur ce que nous testons, et nous avons besoin que les définitions de scénarios soient portables : le même scénario peut être exécuté sur différentes implémentations d'agents ou différentes versions du même agent.
T - Capture de traces
Pour exécuter notre suite de tests, nous utilisons un harnais qui envoie l'invite de chaque scénario à l'agent sous test (AUT). Chaque exécution est capturée sous forme de trace MLflow : un journal structuré de chaque appel d'outil, de chaque sortie intermédiaire et de chaque artefact que l'agent produit. Pensez-y comme à un enregistreur de vol : il capture tout ce que l'agent a fait, dans l'ordre, afin que nous puissions inspecter n'importe quelle partie de l'exécution après coup.
Une décision architecturale clé : nous découplons l'exécution de l'évaluation. Le harnais de test produit des traces ; les juges (que nous présenterons ensuite) les évaluent. Ce sont des étapes distinctes. En persistant les traces, nous pouvons itérer sur les juges sans réexécuter les scénarios. Ajuster un seuil ? Réévaluer les traces enregistrées en quelques secondes. Ajouter un nouveau juge ? Exécutez-le sur toutes les traces que vous avez jamais collectées. Vous soupçonnez qu'un juge est erroné ? Comparez ses verdicts aux enregistrements et déboguez-le hors ligne. Une exécution coûteuse d'un agent produit des données qui sont réutilisées plusieurs fois, y compris comme candidats pour le Golden Set que nous utiliserons plus tard pour aligner les juges.
A - Évaluation avec des juges
Les juges opèrent sur les traces et raisonnent sur les *propriétés* de l'exécution : l'agent a-t-il produit du code valide ? La sortie a-t-elle atteint un seuil de qualité ? L'agent a-t-il suivi le bon processus ? Comme mentionné précédemment, cette évaluation est différente des tests unitaires traditionnels : la sortie de l'agent est non déterministe et riche, donc affirmer des sorties exactes est pratiquement inutile.
L'approche standard pour implémenter ces juges est « LLM-as-a-Judge » : alimenter la trace complète dans un modèle et demander un score et, surtout, une justification de ce score. Cependant, c'est comme écrire un test qui déverse tout l'état du programme dans une assertion. C'est coûteux, fragile et difficile à déboguer. Pour nos agents, une seule trace peut faire des milliers de lignes. La faire entrer dans la fenêtre de contexte d'un juge dégrade la qualité du jugement.
Au lieu de cela, nous utilisons les juges agentiques de MLflow : des juges qui sont eux-mêmes des agents, équipés d'outils pour explorer la trace de manière sélective. Tout comme un test bien écrit appelle une fonction spécifique et vérifie une valeur de retour spécifique, un juge agentique appelle un outil spécifique sur la trace et vérifie une propriété spécifique.
Voici quelques exemples de juges que nous avons utilisés pour nos agents :
Le juge d'invocation de compétences explore la trace et identifie si l'agent a invoqué des compétences ciblées par le scénario (sinon, le but de la compétence n'est pas clair pour l'AUT) :
Le juge des meilleures pratiques vérifie si la sortie suit les meilleures pratiques selon la documentation officielle de Databricks :
Le Juge de Résultats inspecte la trace pour les sorties et vérifie certaines propriétés. Pour revenir à l'exemple de l'Analyste de Données, identifiez la partie de la trace où le code d'ingénierie a été rédigé et évaluez si le code est approprié pour la tâche à accomplir :
Ce juge est intéressant car il s'attaque de front au problème de la qualité subjective : ce qui constitue une bonne ingénierie de caractéristiques dépend de l'expertise du domaine. Un juge LLM ne peut pas obtenir cela directement. Il est tentant d'essayer de rédiger les critères complets dans l'invite du juge : "préférer l'imputation médiane à la moyenne pour les distributions asymétriques, toujours mettre à l'échelle les caractéristiques avant les modèles basés sur la distance, ..." Mais encoder le jugement complet d'un expert du domaine dans une invite est laborieux et fragile. Il est beaucoup plus facile pour les humains de regarder un exemple et de dire "c'est bien" ou "c'est mal" que de rédiger la spécification complète. C'est exactement pourquoi l'alignement fonctionne, comme nous le verrons bientôt.
En général, notre suite de tests pour un agent unique comprend des juges dans plusieurs catégories :
Vérifications déterministes, choses que nous pouvons vérifier mécaniquement, sans LLM :
- Syntaxe/linting sur le code généré
- Validation du schéma de sortie (les tables attendues existent-elles ? les types de colonnes sont-ils corrects ?)
- Linting de la séquence d'outils (l'agent a-t-il lu les journaux d'erreurs avant d'essayer de corriger le problème, ou a-t-il directement passé à la modification du code ?)
Vérifications basées sur LLM, jugements qui nécessitent la compréhension du contexte :
- Directives de différences de code (l'agent a-t-il modifié des lignes non pertinentes ? a-t-il introduit des API obsolètes ?)
- Respect des meilleures pratiques (le code généré suit-il les conventions pour ce domaine ?)
Métriques opérationnelles, signaux qui ne réussissent/échouent pas individuellement mais suivent la santé au fil du temps :
- Utilisation des jetons (des nombres élevés de jetons signalent souvent que l'agent a des difficultés, réessaie, revient en arrière ou tourne en rond)
- Nombre d'appels d'outils et ratios d'échec (un pic d'appels d'outils échoués indique que quelque chose ne va pas)
- Latence (temps réel pour que l'agent accomplisse la tâche)
Les métriques opérationnelles méritent une note. Elles ne bloquent pas une version comme le font les juges de réussite/échec, mais elles sont essentielles pour la gestion des coûts et l'alerte précoce. Si l'utilisation des jetons double après un changement, quelque chose s'est mal passé même si tous les juges réussissent toujours ; l'agent fait probablement plus de travail qu'il ne le devrait. Nous suivons cela au fil du temps et alertons sur les anomalies.
Développer la suite de tests au fil du temps
Les suites de tests ne sont pas rédigées en une seule fois. Elles évoluent avec le temps. Elles commencent par les vérifications les plus simples qui donnent un signal : la sortie existe-t-elle ? Est-elle analysable ? Ensuite, les vérifications structurelles suivent : la sortie a-t-elle le bon schéma, les bonnes colonnes, les bons types ? Ce n'est que plus tard que viennent les juges de validation de données de bout en bout : la sortie produit-elle réellement des résultats corrects lorsque vous l'exécutez ?
Cela reflète la façon dont les suites de tests mûrissent dans le logiciel traditionnel. Les tests d'intégration exhaustifs ne sont pas là dès le premier jour. Cela commence par des tests de fumée, puis des tests unitaires à mesure que les modes d'échec émergent, pour aboutir à une couverture de bout en bout au fil du temps. La clé est que l'infrastructure prend en charge l'ajout de nouveaux juges à moindre coût, de sorte que la suite de tests se développe parallèlement à l'agent.
Tester les Tests : Alignement des Juges
Voici un problème que tout ingénieur connaît : une suite de tests instable ou incorrecte qui valide du code médiocre expédie des bugs avec confiance. De même, les juges qui approuvent de mauvais résultats donnent un faux sentiment de sécurité. C'est là qu'intervient la deuxième boucle du framework coSTAR : les mêmes scénarios et traces qui pilotent l'amélioration de l'agent pilotent également l'amélioration du juge, avec les scores des experts humains comme vérité terrain. Cela est important car, contrairement aux tests traditionnels où la correction des tests peut être vérifiée par inspection, les juges LLM sont stochastiques et peuvent dériver dans leur interprétation des critères en langage naturel. Nous avons donc besoin d'un moyen de les vérifier et de les maintenir alignés avec les experts humains.
Pour réaliser cet alignement, nous curons d'abord un Ensemble d'Or (Golden Set) d'une douzaine d'exemples typiques de sorties d'agents que nos ingénieurs ont évalués manuellement. C'est la vérité terrain avec laquelle les juges doivent être d'accord. Ensuite, nous exploitons les capacités d'alignement de MLflow (alimentées par des techniques comme GEPA et MemAlign) pour affiner automatiquement le juge par rapport à l'Ensemble d'Or. Notez que c'est structurellement la même boucle STAR que celle que nous utilisons pour affiner l'AUT lui-même, mais l'étape d'évaluation est effectuée par des experts humains et l'étape d'affinage s'applique au juge.
R - Affiner
Avec des juges que la boucle de jugement a alignés sur le jugement d'experts humains, nous pouvons maintenant faire confiance à la boucle de l'agent. Un assistant de codage traite l'agent comme sa base de code et les juges comme sa suite de tests. Il lit les échecs, diagnostique les causes profondes, corrige l'agent et relance tout. L'ingénieur reste le réviseur et l'arbitre final des changements proposés à l'agent, mais cette itération automatisée permet d'économiser considérablement d'efforts humains dans l'analyse et l'amélioration de l'agent.
Voici à quoi ressemblait une itération pour l'agent Analyste de Données :
Rouge. Nous avons exécuté la version initiale de l'agent sur notre suite de scénarios. Le juge des meilleures pratiques a signalé une divergence : notre agent générait du code pour des vues logiques qui différait de nos recommandations/documentation officielles. Bien que cette divergence n'affecte pas la correction, elle avait des implications sur la maintenance et le déploiement du code généré. C'est un exemple de régression insidieuse qui serait difficile à détecter par une investigation manuelle.
Vert. L'assistant de codage a analysé les commentaires du juge et identifié l'écart : l'agent utilisait une compétence qui n'était pas prescriptive quant au type de vues à créer (temporaires vs permanentes). Après avoir ajouté les instructions pertinentes à la compétence, les tests ont réussi et la modification a été vérifiée pour ne pas introduire d'autres régressions (basées sur d'autres scénarios de test).
Tests de Régression pour l'Infrastructure, Pas Seulement l'Agent
Jusqu'à présent, nous avons décrit les juges comme des tests pour l'agent, attrapant les régressions lorsque l'implémentation de l'agent change. Mais en pratique, l'agent lui-même n'est pas la seule chose qui change. L'agent dépend d'outils et d'infrastructures externes, et ceux-ci changent aussi.
Nos agents appellent les outils MCP, des interfaces standardisées pour l'accès aux données, l'exécution de code, la configuration de l'environnement, et plus encore. Ces outils ont leurs propres équipes de développement et cycles de publication. Lorsqu'un outil modifie son implémentation (par exemple, un outil d'exécution de code commence à renvoyer stderr dans un format différent, ou un outil d'accès aux données modifie la façon dont il gère les valeurs nulles), l'agent n'a pas du tout changé, mais le comportement de l'agent peut être perturbé.
Étant donné que nous exécutons nos juges sur chaque build nocturne, ils agissent comme des tests de régression sur l'ensemble de la pile, pas seulement sur l'implémentation actuelle de l'agent. Lorsqu'une équipe d'outils expédie un changement qui fait qu'un agent commence à échouer à ses juges, nous attrapons l'erreur immédiatement, avant qu'elle n'atteigne les clients. Plus important encore, l'échec du juge nous indique ce qui a mal tourné (la dimension de qualité spécifique qui a régressé), ce qui rend beaucoup plus facile de déterminer si la cause profonde se situe dans l'agent ou dans un outil dont l'agent dépend.
C'est la même valeur que les tests d'intégration fournissent dans le logiciel traditionnel : ils protègent le contrat entre le code et ses dépendances. La seule différence est qu'ici, le "code" est un agent et les "dépendances" sont des outils MCP.
De l'Évaluation au Suivi de Production
Il y a une autre extension de l'analogie de test qui s'est avérée étonnamment précieuse : exécuter les mêmes juges sur le trafic de production.
Dans le logiciel traditionnel, les tests ne s'arrêtent pas à l'intégration continue. La production est également surveillée : taux d'erreurs, percentiles de latence, métriques commerciales sur le trafic en direct. La même logique de test qui valide le code en développement réapparaît souvent sous forme de contrôles de santé et d'alertes en production.
Nous faisons la même chose. Les juges que nous avons construits pour l'évaluation sont conçus pour noter n'importe quelle conversation d'agent, pas seulement les scénarios d'évaluation. Nous les exécutons donc (ou un sous-ensemble échantillonné) sur de vraies conversations de production. Cela nous donne :
- Alerte précoce sur la dérive. Si le taux de réussite des juges sur les conversations de production baisse, quelque chose a changé. Peut-être qu'une mise à niveau du modèle a dégradé la qualité, peut-être que les invites des utilisateurs ont changé d'une manière que l'agent gère mal. Nous le voyons dans les scores des juges avant de le voir dans les plaintes des utilisateurs.
- Signal du monde réel pour la suite de tests. Les conversations de production que les juges signalent comme des échecs deviennent des candidats pour de nouveaux scénarios d'évaluation. C'est ainsi que la suite de tests se développe organiquement : les échecs réels reviennent à l'évaluation, bouclant la boucle entre la production et le développement.
- Suivi des coûts au niveau de l'agent. Nous suivons l'utilisation des jetons et le nombre d'appels d'outils sur les conversations de production. Un changement neutre en termes de qualité qui triple le coût est toujours une régression.
L'idée clé est que la même infrastructure de scoring (juges, métriques, traces enregistrées) remplit une double fonction. Construisez-la une fois pour l'évaluation, et la surveillance de la production en découle comme d'un effet secondaire.
Où nous en sommes
Nous avons adopté cette méthodologie pour plusieurs agents que nous avons publiés sur la plateforme Databricks (par exemple, les capacités d'ingénierie des données, d'apprentissage automatique et d'analyse des traces dans Genie), des agents internes pour la productivité des développeurs, ainsi que d'autres agents destinés aux clients (par exemple, AI Dev Kit, ou l'assistant MLflow OSS). Dans l'ensemble, nous avons constaté des avantages tangibles :
- Comparées aux évaluations manuelles, les suites de tests automatisées ont réduit le temps de vérification des modifications de 2 semaines à quelques heures. Par conséquent, cela a permis à nos équipes de déployer des améliorations plus rapidement.
- Plusieurs suites de tests comptent désormais des centaines de scénarios de test par agent, ce qui augmente notre confiance dans la détection des régressions.
- Les tests d'intégration ont signalé des changements dans l'infrastructure dépendante, ce qui nous a permis d'éviter des régressions en production. Parmi ces changements, citons le comportement de gestion des TODO dans le modèle sous-jacent, les changements impactant la latence ou les changements de modèle.
MLflow a également joué un rôle déterminant en tant que plateforme de test GenAI, aidant nos ingénieurs à standardiser la méthodologie, à accélérer le développement des tests et à partager les meilleures pratiques entre les équipes.
Ce qui ne fonctionne pas (encore)
L'analogie des tests est également utile ici. Nos limites correspondent à des problèmes de test familiers :
La génération de scénarios est manuelle (la rédaction des cas de test est coûteuse). Nous avons automatisé le scoring, l'alignement et l'optimisation, mais la génération des scénarios eux-mêmes reste une tâche humaine. Chaque scénario nécessite de définir un état initial réaliste, une invite significative et des attentes correctes. C'est le goulot d'étranglement qui limite la taille de la suite de tests, et une suite de tests étroite mène directement au problème suivant. L'automatisation de la génération de scénarios (synthèse de cas de test diversifiés et réalistes à partir des modèles de trafic de production ou de la spécification de l'agent) est un domaine de travail actif pour nous.
L'assistant de codage peut sur-apprendre (suite de tests trop étroite). Si la suite de tests ne couvre pas suffisamment de cas, l'assistant de codage concevra une implémentation d'agent qui excelle sur ces entrées spécifiques mais échoue sur des entrées nouvelles. C'est l'équivalent agent d'écrire du code qui réussit les tests unitaires mais échoue en production. Nous atténuons cela en réintégrant les échecs de production dans l'évaluation et en élargissant la couverture au fil du temps, mais tant que la génération de scénarios ne sera pas automatisée, la suite de tests ne progressera pas aussi vite que nous le souhaiterions.
L'alignement des juges est coûteux (la calibration des tests nécessite un travail humain). La construction de l'ensemble de référence (Golden Set) nécessite que des experts du domaine notent manuellement les sorties, le goulot d'étranglement exact que nous essayons d'éliminer. Et ce n'est pas un coût unique : à mesure que les agents évoluent, les juges doivent être recalibrés. Nous explorons des moyens de rendre cela plus intelligent en mesurant l'incertitude du juge, en identifiant les exemples spécifiques où le juge est sous-spécifié et où une étiquette humaine résoudrait l'ambiguïté. L'objectif est l'apprentissage actif pour l'alignement des juges : au lieu de demander aux experts de noter un échantillon aléatoire, ne présenter que les exemples où le juge est incertain et où l'avis d'un expert du domaine affinerait le plus ses critères. L'objectif est l'apprentissage actif pour l'alignement des juges : au lieu de demander aux experts de noter un échantillon aléatoire, ne présenter que les exemples où le juge est incertain et où l'avis d'un expert du domaine affinerait le plus ses critères.
Les échecs en plusieurs étapes sont difficiles à attribuer (analyse des causes profondes). Lorsqu'un agent échoue à l'étape 7 d'un pipeline en 10 étapes, la cause profonde se situe-t-elle à l'étape 7 ou à l'étape 3 ? Nos juges détectent le symptôme, mais l'assistant de codage corrige parfois la mauvaise étape, comme corriger un échec de test en modifiant la mauvaise fonction. Une meilleure traçabilité causale est un domaine de travail actif.
Les nouveaux modes d'échec passent inaperçus (lacunes de couverture). coSTAR optimise dans les dimensions couvertes par les juges. Si une nouvelle classe d'échec apparaît qu'aucun juge ne vérifie, elle est invisible, tout comme un bug dans le code qu'aucun test n'exerce. coSTAR s'améliore *au sein* de sa suite de tests, mais il ne peut pas l'étendre de lui-même. Les humains doivent encore remarquer les nouveaux modes d'échec et ajouter des juges.
Points clés à retenir
- Le développement d'agents pose un problème de test. Sans évaluation automatisée, vous codez sans tests, et vous subirez les régressions que vous méritez.
- Donnez des outils aux juges, pas des traces. Un juge agentique qui appelle des outils ciblés est comme un test unitaire focalisé. Fournir la trace complète à un juge revient à injecter l'état du programme dans une assertion. Cela ne fonctionne pas à grande échelle.
- Testez vos tests. Les juges LLM sont stochastiques. Alignez-les sur des ensembles de référence notés par des humains de la même manière que vous valideriez une suite de tests par rapport à une spécification.
- Bouclez la boucle. Le véritable avantage est la boucle coSTAR complète : scénarios de confiance, traces enregistrées, juges alignés et un assistant de codage qui affine l'agent jusqu'à ce que les tests réussissent. L'évaluation sans raffinement automatisé n'est que la moitié de l'histoire.
- Construisez une fois, surveillez partout. Les mêmes juges qui valident lors de l'évaluation peuvent surveiller la production. Un investissement, deux retours.
- Le couplage est essentiel. Le raffinement de l'agent n'est fiable que dans la mesure où les juges qui le pilotent le sont. Les deux boucles couplées de coSTAR — l'une qui établit la confiance dans les juges, l'autre qui utilise cette confiance pour affiner l'agent — sont ce qui rend le raffinement automatisé significatif plutôt que simplement rapide.
Nous construisons coSTAR dans le cadre de MLflow. Si vous êtes confronté à des problèmes similaires, nous aimerions en discuter.
- Essayez Genie Code pour découvrir les fonctionnalités que nous avons publiées en utilisant la méthodologie coSTAR.
- Suivez les tutoriels sur MLflow pour commencer à définir et utiliser des juges LLM pour le raffinement itératif des agents.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.