Lakeflow : Une nouvelle ère pour l'ingénierie des données agentique
La fondation de données unifiée et en temps réel de confiance pour votre entreprise
par Bilal Aslam, Ray Zhu, Manish Dalwadi, Saad Ansari et Giselle Goicochea
- Socle unifié pour l'AI agentique : Lakeflow unifie l'ingestion, la transformation et l'orchestration sous Unity Catalog, éliminant ainsi le fossé causé par la prolifération des outils et offrant aux agents AI une source unique de contexte fiable et en temps réel.
- Ingestion et streaming haute performance : connectez-vous à plus de 100 sources de données d'entreprise avec Lakeflow Connect, diffusez des données d'événements à grand volume via plusieurs interfaces sur Zerobus Ingest, et profitez d'une latence de l'ordre de la milliseconde avec le Real-Time Mode pour les pipelines déclaratifs Spark.
- Développement et opérations agentiques : créez des pipelines de manière visuelle avec Lakeflow Designer, accélérez la rédaction de code avec Genie Code, réduisez les tâches opérationnelles fastidieuses avec Genie ZeroOps, et consolidez les orchestrateurs existants avec Lakeflow Jobs.
Toutes les analyses, l'IA et les applications commencent par les données. Au cours des dernières décennies, les outils d'ingénierie des données se sont multipliés pour répondre à de nombreux cas d'usage et profils d'utilisateurs. C'est pourquoi la plupart des entreprises se retrouvent avec une infrastructure de données très complexe et fragmentée, difficile à intégrer, à maintenir ou à gouverner. Avec l'IA qui alimente toutes les données et les professionnels de l'IA, une pression encore plus forte sera exercée sur ces infrastructures de données fragiles.
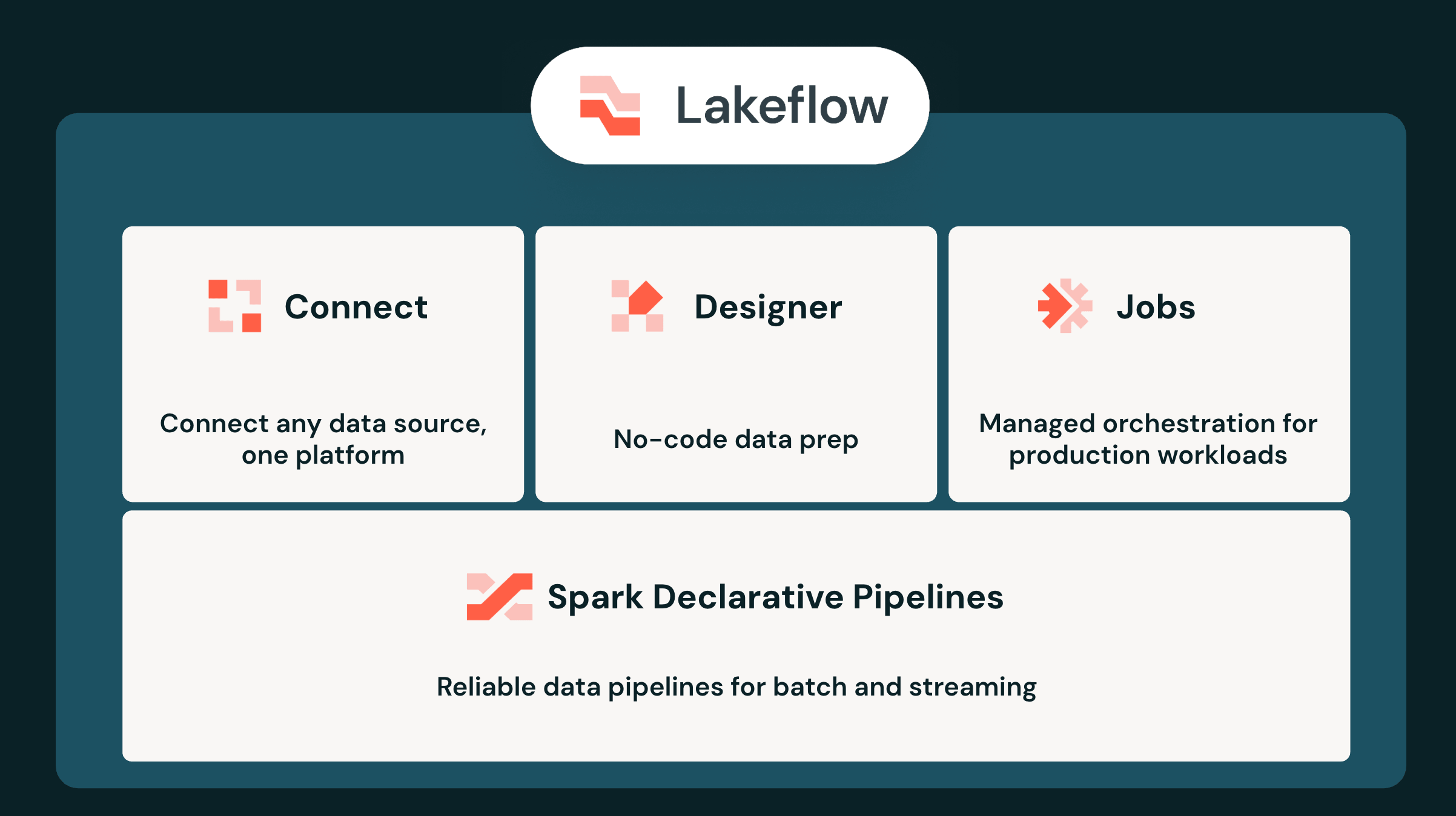
C'est pourquoi nous avons entrepris de concevoir Databricks Lakeflow, une plateforme unifiée pour l'ensemble de l'ingénierie des données, de l'ingestion à la transformation et à l'orchestration. Toutes les fonctionnalités de Lakeflow sont entièrement intégrées et gouvernées de manière centralisée par Unity Catalog. À l'ère des agents, cette architecture unifiée offre des avantages considérables, permettant aux agents non seulement de créer, mais aussi de gérer vos pipelines de données. Aujourd'hui, lors du Data + AI Summit, nous annonçons la prochaine évolution majeure de Databricks Lakeflow.
Genie Code et Lakeflow Designer : développement de pipelines basé sur les agents
Genie Code est désormais profondément intégré à chaque aspect de l'expérience utilisateur de Lakeflow. Vous pouvez utiliser Genie Code pour créer des connecteurs d'ingestion, concevoir des pipelines en Python et SQL, et développer des jobs avec des tâches, des déclencheurs et des dépendances. Tout cela est rendu possible par l'infrastructure d'ingénierie des données unifiée, qui fournit à Genie Code un contexte complet de bout en bout pour vos charges de travail d'ingestion, de transformation et d'orchestration.
Désormais disponible en version générale (GA), Lakeflow Designer démocratise l'ingénierie des données dans toute l'entreprise. Cette interface visuelle, sans code et optimisée par l'IA, permet aux équipes de créer des pipelines à l'aide d'un canevas glisser-déposer et de requêtes en langage naturel. Les analystes métier et les utilisateurs non techniques peuvent créer des pipelines ETL prêts pour la production sans écrire de code. Chaque Flow visuel créé dans Designer s'exécute nativement sur un Spark Declarative Pipeline prêt pour la production, garantissant une fidélité totale sans transferts complexes. Les ingénieurs de données peuvent facilement réviser et affiner ce code directement sur place, sans changer de contexte ni réécrire la logique.
Genie ZeroOps : mettez les opérations de données et d'IA sur pilote automatique
Annoncé aujourd'hui, Genie ZeroOps aide les équipes de données à gérer les ressources de données et d'IA en production. Genie ZeroOps est un agent d'IA en arrière-plan spécialement conçu pour surveiller et gérer les ressources de données et d'IA. ZeroOps détecte les défaillances et effectue des analyses de cause racine pour identifier l'origine des erreurs à l'aide de métriques de qualité des données, de journaux d'erreurs et de données de lignage issues d'Unity Catalog. De plus, il propose des corrections et les valide dans un environnement sandbox sécurisé et isolé, gouverné par Unity Catalog. L'application d'un correctif se fait avec une intervention humaine (human-in-the-loop), de sorte que Genie ZeroOps se charge du travail difficile tout en vous laissant le contrôle. Tout comme le développement basé sur les agents, les fonctionnalités de Genie ZeroOps ne sont possibles que grâce à la connaissance complète du contexte et à la gouvernance de bout en bout offertes par une infrastructure de données unifiée avec Lakeflow.
Lakeflow Connect : un écosystème en pleine croissance avec plus de 100 connecteurs intégrés
Les pipelines automatisés n'ont de valeur que si les données qui y circulent sont de qualité. Pour construire une « mémoire d'entreprise » complète et ancrer les agents d'IA comme Databricks Genie, vous devez disposer d'un accès fluide au contexte gouverné le plus récent dans tous les domaines de votre entreprise. Lakeflow Connect simplifie ce processus en ingérant de manière incrémentielle des données fraîches provenant d'une liste toujours plus longue de systèmes d'entreprise, directement dans des tables Delta gouvernées par Unity Catalog.
Aujourd'hui, nous annonçons que Lakeflow Connect s'étend pour prendre en charge plus de 100 connecteurs natifs et gérés pour les applications d'entreprise, les bases de données, les sources de fichiers et le stockage cloud. Vous pouvez désormais éliminer les outils tiers fragiles et exécuter des pipelines d'ingestion optimisés pour les cas d'usage dont les clients ont le plus besoin :
- Gestion des connaissances de l'entreprise : unifiez les données métier de Jira (Beta), GitHub (Beta) et Confluence (GA) avec des documents non structurés, des contrats et des PDF provenant de SharePoint (GA), Google Drive (Beta) et Outlook (Beta). Propulsez des applications d'IA sensibles au contexte, des agents de support et le traitement intelligent des documents sur un socle unique.
- MarTech : ingérez les données de campagne et de clientèle directement depuis Meta Ads (Beta), TikTok Ads (Beta), Google Ads (Beta) et HubSpot (GA) pour piloter la personnalisation en temps réel.
- Opérations informatiques et de sécurité : centralisez les journaux et la télémétrie pour une analyse SIEM robuste.
- Capture basée sur les requêtes pour tous les connecteurs de base de données et les sources Lakehouse Federation (GA) : interrogez directement la base de données pour capturer les modifications sans avoir à analyser les journaux.
Pour les organisations disposant de systèmes spécialisés ou propriétaires, les Community Connectors (Beta) fournissent une solution open source construite sur Databricks. Déployez un connecteur pré-intégré de la communauté ou créez le vôtre pour le partager au sein de votre organisation ou de l'écosystème plus large.
Panasonic a utilisé Lakeflow Connect pour unifier les données de SAP, Workday et SharePoint, remplaçant un ETL hérité et fragile par une plateforme unique pour une intelligence gouvernée en temps réel.
« En passant d'une infrastructure ETL héritée et rigide à la plateforme Databricks, nos équipes BI peuvent désormais facilement découvrir et accéder aux données critiques, réduisant de 50 % les temps de rafraîchissement de Power BI. Nous transformons des données externes et incohérentes en ressources fiables et prêtes pour la production, ce qui permet de dégager de nouvelles perspectives commerciales et de renforcer l'avantage concurrentiel de Panasonic. »—Jerry Deng, Directeur BI, Panasonic
Nous permettons également aux organisations de réduire durablement le TCO de l'ingestion de volumes importants grâce à l'offre gratuite Lakeflow Connect (Free Tier). Les clients reçoivent automatiquement 100 DBUs gratuits par jour, prenant en charge jusqu'à 100 millions d'enregistrements quotidiens sur les connecteurs SaaS et de bases de données managés les plus populaires.
Zerobus Ingest : une ingestion sans Kafka pour vos producteurs de données
Zerobus Ingest change la façon dont les organisations gèrent les données d'événements à volume élevé, sans qu'un bus de messages ne soit nécessaire. Avec des écritures en quasi-temps réel en moins de 5 secondes et un débit élevé allant jusqu'à 100 Mo/s (plus de 10 Go/s par table), Zerobus livre les données directement à votre plateforme, à grande échelle.
Cependant, la performance n'a d'importance que si vos producteurs peuvent se connecter sans friction. Une migration devrait être aussi simple qu'un changement de configuration. Depuis sa disponibilité générale (GA) plus tôt cette année, Zerobus s'est développé pour répondre aux besoins de vos producteurs de données là où ils opèrent déjà :
- APIs compatibles avec Kafka (Beta) : vos producteurs Kafka existants envoient les données directement vers Databricks, sans aucune modification de code.
- APIs gRPC et REST (GA) : des flux gRPC persistants pour les applications haute performance, ou des APIs REST sans état pour les webhooks et les fonctions serverless.
- Écosystème de SDK (GA) : des SDK prêts pour la production pour Python, Java, Rust, Go et TypeScript facilitent l'intégration directe de Zerobus dans vos applications personnalisées.
- OpenTelemetry (Public Preview) : envoyez des métriques, des traces et des journaux directement vers le lakehouse avec un simple changement de configuration.
Cette flexibilité multi-interface offre une passerelle directe et à faible latence vers le cloud pour les entreprises mondiales. Pour exemple, Meta utilise Zerobus Ingest pour relier ses centres de données sur site au cloud, permettant ainsi le développement rapide de solutions basées sur les données à grande échelle.
« Nous avons réduit la latence de notre pipeline de bout en bout à moins d'une minute grâce à Zerobus Ingest et Spark Declarative Pipelines, permettant de générer de la valeur plus rapidement. »—Srikanth Sakhamuri, Responsable de l'ingénierie des données, Meta
Une fois que les données arrivent dans les tables Delta régies par Unity Catalog, elles sont instantanément accessibles aux outils d'AI et de BI en aval, tels que Databricks Genie. Dans le cadre d'une pile analytique en temps réel de bout en bout, Zerobus ingère les données et les traite à l'aide du Real-Time Mode dans Apache Spark™Declarative Pipelines (SDP), les transforme, et Lakehouse//RT, un nouveau type de data warehouse fonctionnant sur un moteur temps réel entièrement natif, les distribue avec des performances de l'ordre de la milliseconde.
Spark Declarative Pipelines : batch et streaming, SQL et Python, et maintenant en temps réel
La réalisation d'un streaming à ultra-faible latence a traditionnellement contraint les équipes de données à gérer des architectures complexes et fragmentées, nécessitant souvent la maintenance d'un second moteur spécialisé, tel qu'Apache Flink, aux côtés de Spark. Databricks a initialement résolu cette complexité liée au double moteur en introduisant le Real-Time Mode (RTM) pour Spark Structured Streaming. En passant du micro-batching périodique au traitement de flux continu, le RTM alimente actuellement les pipelines de marques mondiales telles que Coinbase, DraftKings et MakeMyTrip.
Aujourd'hui, nous apportons cette même puissance à notre produit ETL unifié : le Real-Time Mode (RTM) pour Spark Declarative Pipelines est désormais en Public Preview. Le RTM pour SDP permet d'atteindre des latences de bout en bout d'à peine 5 millisecondes, sans la complexité ni le coût de la gestion de moteurs distincts. Disponible sur les ressources de calcul classiques et serverless, il offre un streaming à ultra-faible latence ainsi que les avantages opérationnels de Spark Declarative Pipelines : exécution sans version, mises à niveau automatisées de l'infrastructure et maintenance avec un temps d'arrêt minimal ou nul.
Ensuite, nous rendons les API déclaratives de Spark Declarative Pipelines — y compris Append, Auto CDC, incremental Replace Where et Materialized View — disponibles partout sur la plateforme Databricks. Cela signifie que les utilisateurs peuvent tirer parti du traitement incrémentiel des données directement depuis le produit, le type de calcul et l'interface utilisateur qu'ils connaissent déjà. Toutes ces API sont désormais disponibles dans Databricks SQL et seront disponibles dans les Notebooks serverless et Lakeflow Designer dans les prochaines semaines.
Lakeflow Jobs : maintenant avec plus de 50 intégrations
L'orchestration ne devrait pas être la partie la plus difficile de la gestion de votre pipeline de données. Que vous exécutiez des DAG de production complexes, de la planification ou le déclenchement d'agents d'AI, Lakeflow Jobs est le moteur d'orchestration natif de Databricks qui gère toutes ces tâches. En apportant une orchestration managée et une observabilité de bout en bout à chaque couche du cycle de vie des données, les équipes de données consolident les orchestrateurs existants, tels qu'Apache Airflow, sur une plateforme unique et unifiée.
Orchestration sensible aux données et au contexte
Chaque planification cron n'est qu'une estimation du moment où les données sont prêtes. Lakeflow Jobs vous permet d'arrêter de deviner et de commencer à déclencher des pipelines en fonction de la disponibilité réelle des données. En utilisant le langage naturel, vous pouvez demander à Genie d'écrire les déclencheurs SQL qui définissent ce que signifie « prêt » pour vos données. Votre tâche se déclenche dès que les conditions sont remplies, respectant vos contrats de données et garantissant que vous ne traitez jamais de données obsolètes.
« Grâce à Lakeflow Jobs, nous avons pu exploiter des données auxquelles les technologies existantes ne pouvaient pas accéder, nous permettant de générer des informations commerciales plus approfondies et plus fiables. »—Sachin Wadhwa, Directeur de l'architecture et des plateformes de données, The Rank Group
Orchestration universelle pour tout, n'importe où
Pour les clients ayant des workflows de données en dehors de Databricks, Lakeflow Jobs fournit l'External Orchestration pour étendre nativement votre portée aux systèmes externes sans vous obliger à reconstruire des intégrations à partir de zéro. En utilisant un framework d'opérateurs ouvert, vous pouvez déclencher de manière transparente des tâches Snowflake, lancer des API REST personnalisées ou gérer des alertes Slack et PagerDuty. Les ressources de calcul sont intelligemment suspendues en attendant des conditions externes qui peuvent survenir plusieurs heures plus tard. Nous publions plus de 40 exemples d'opérateurs sur GitHub et ajouterons des dizaines d'intégrations managées au cours des prochains trimestres. De plus, chaque identifiant transite par Unity Catalog et dispose d'une piste d'audit complète.
Premiers pas avec Lakeflow
Lakeflow fournit le socle de données unifié dont vous avez besoin pour créer des applications d'AI agentiques fiables. Pour approfondir les configurations techniques et voir ces nouvelles fonctionnalités en action, explorez nos tutoriels pratiques ou consultez notre documentation technique pour démarrer votre prochain projet.
Prêt à vous lancer ? Essayez Databricks gratuitement pour découvrir Lakeflow dès aujourd'hui.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.