MemEx : un bloc-notes programmable pour les agents LLM
En 1945, Vannevar Bush a imaginé une machine de la taille d'un bureau qui prolongerait la mémoire d'un scientifique en stockant chaque document, annotation et fil de pensée pour les rappeler à la demande. Il l'a appelée le MemEx. Bush résolvait un problème humain : des esprits submergés par des informations qu'ils ne pouvaient pas garder à portée de main. Huit décennies plus tard, les agents LLM se heurtent à un mur remarquablement similaire.
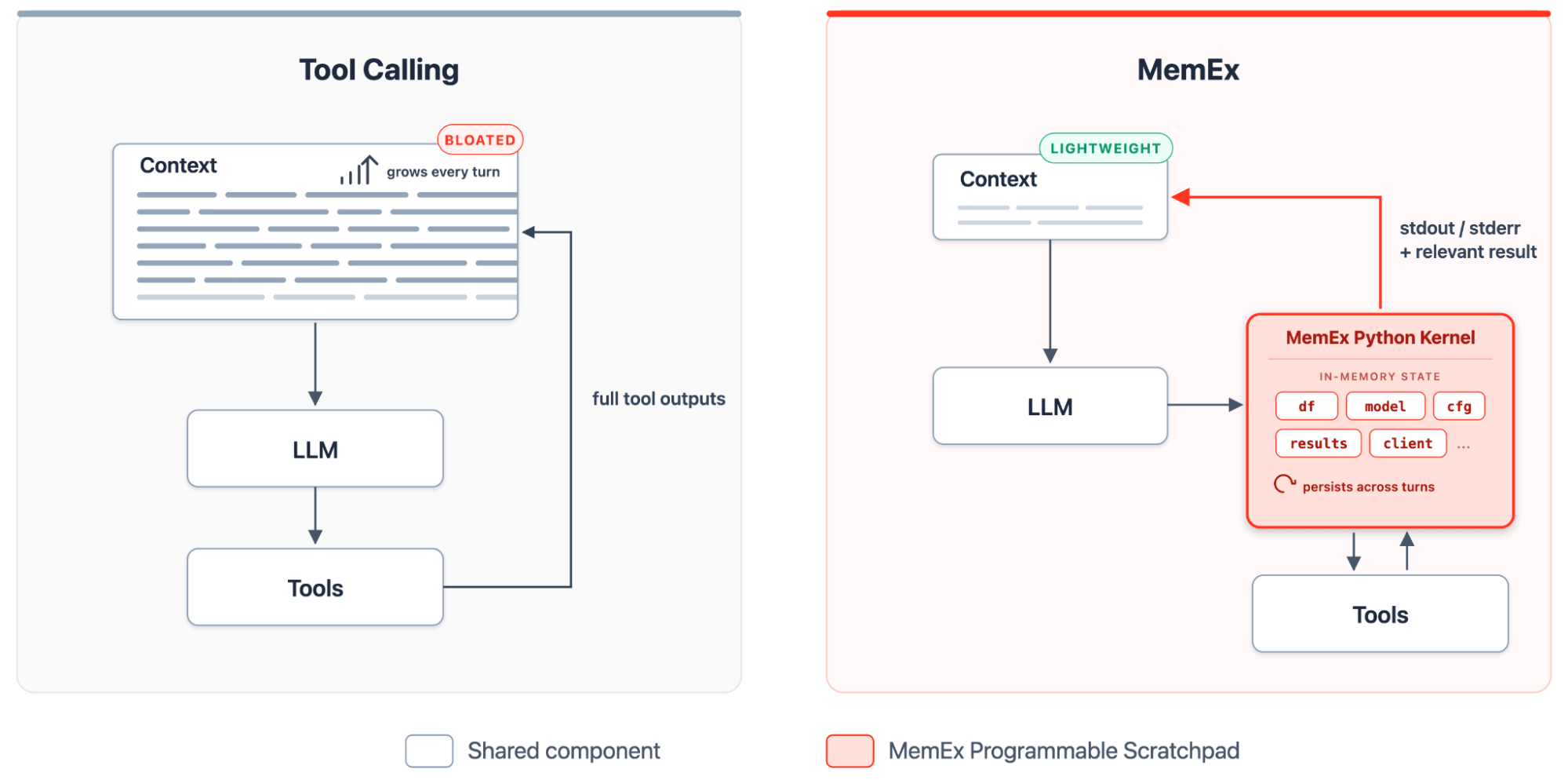
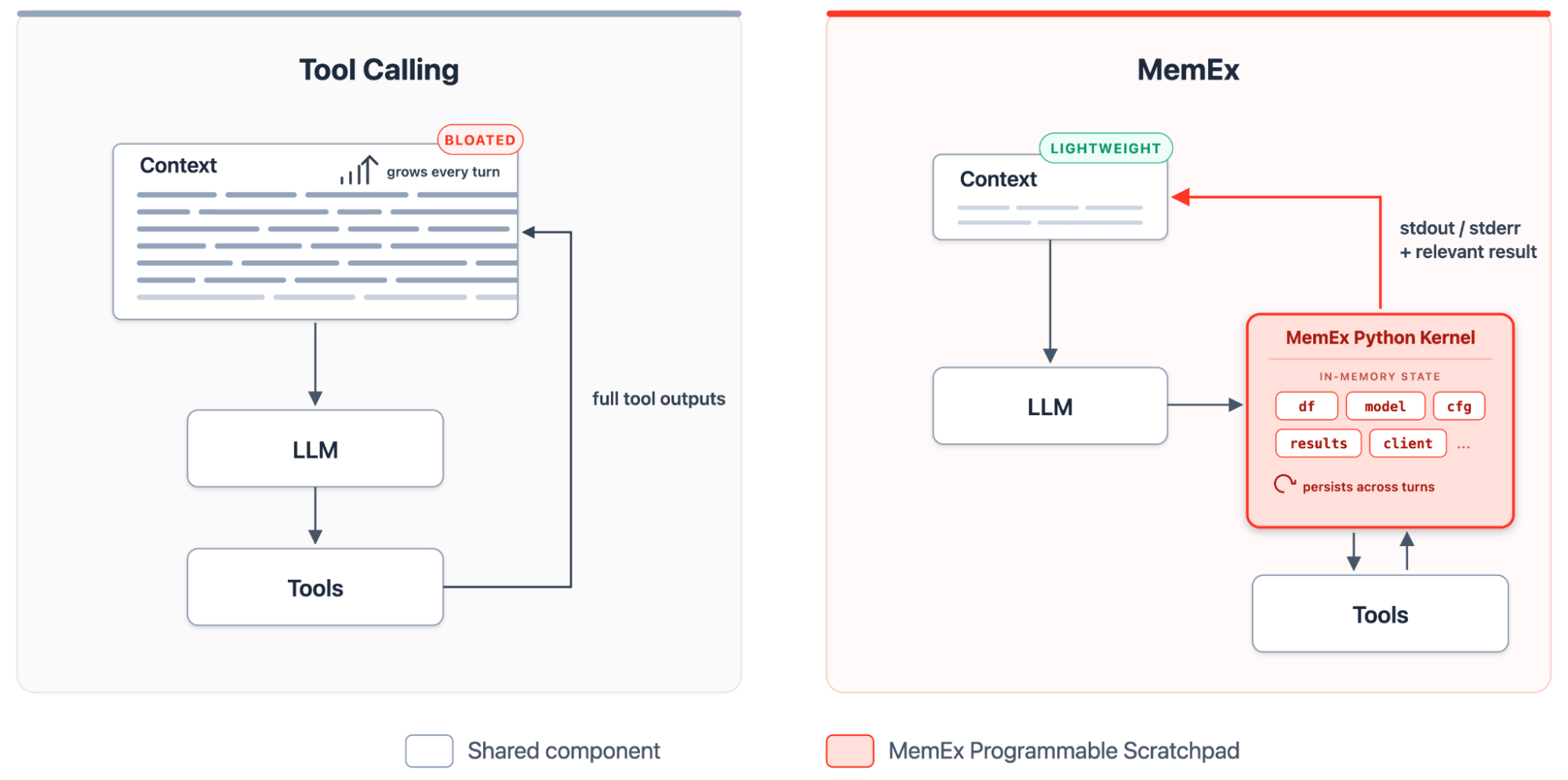
Dans le paradigme actuel d'appel d'outils agentique (Agentic Tool Calling), la fenêtre de contexte est le seul substrat persistant sur lequel le modèle peut opérer. C'est un espace partagé contenant le prompt système, la requête de l'utilisateur, le raisonnement du modèle, les appels d'outils et les sorties brutes des outils. Les sorties d'outils sont les pires coupables : une seule requête SQL peut renvoyer des millions de lignes, et dans les architectures actuelles, ces lignes sont transportées à chaque étape suivante, même si une seule cellule était importante. L'agent n'a aucun moyen de découper, de résumer ou de stocker le résultat avant qu'il n'inonde la fenêtre.
Nous nous heurtons constamment à ce mur chez Databricks. Nos agents de production, de Genie à Agent Bricks, rencontrent à un moment donné les mêmes limites de contexte. Genie en est un excellent exemple : une seule requête effectue une recherche dans l'ensemble de l'espace de travail d'un client, en appelant de nombreux outils pour extraire des données de tables, d'indices vectoriels et de tableaux de bord. Pour y remédier, nous avons construit notre propre MemEx et l'avons validé au sein de plusieurs agents internes et de production.
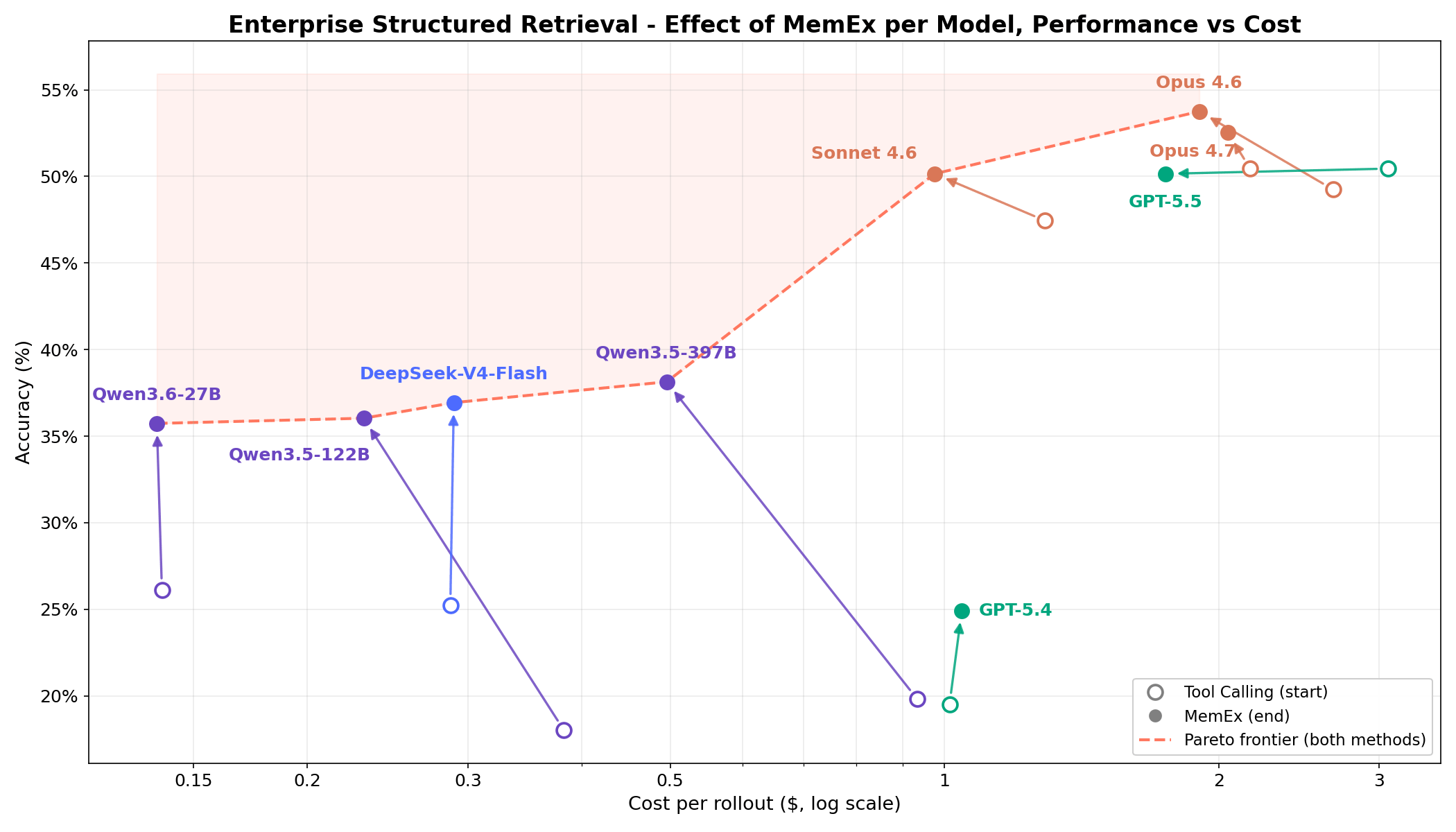
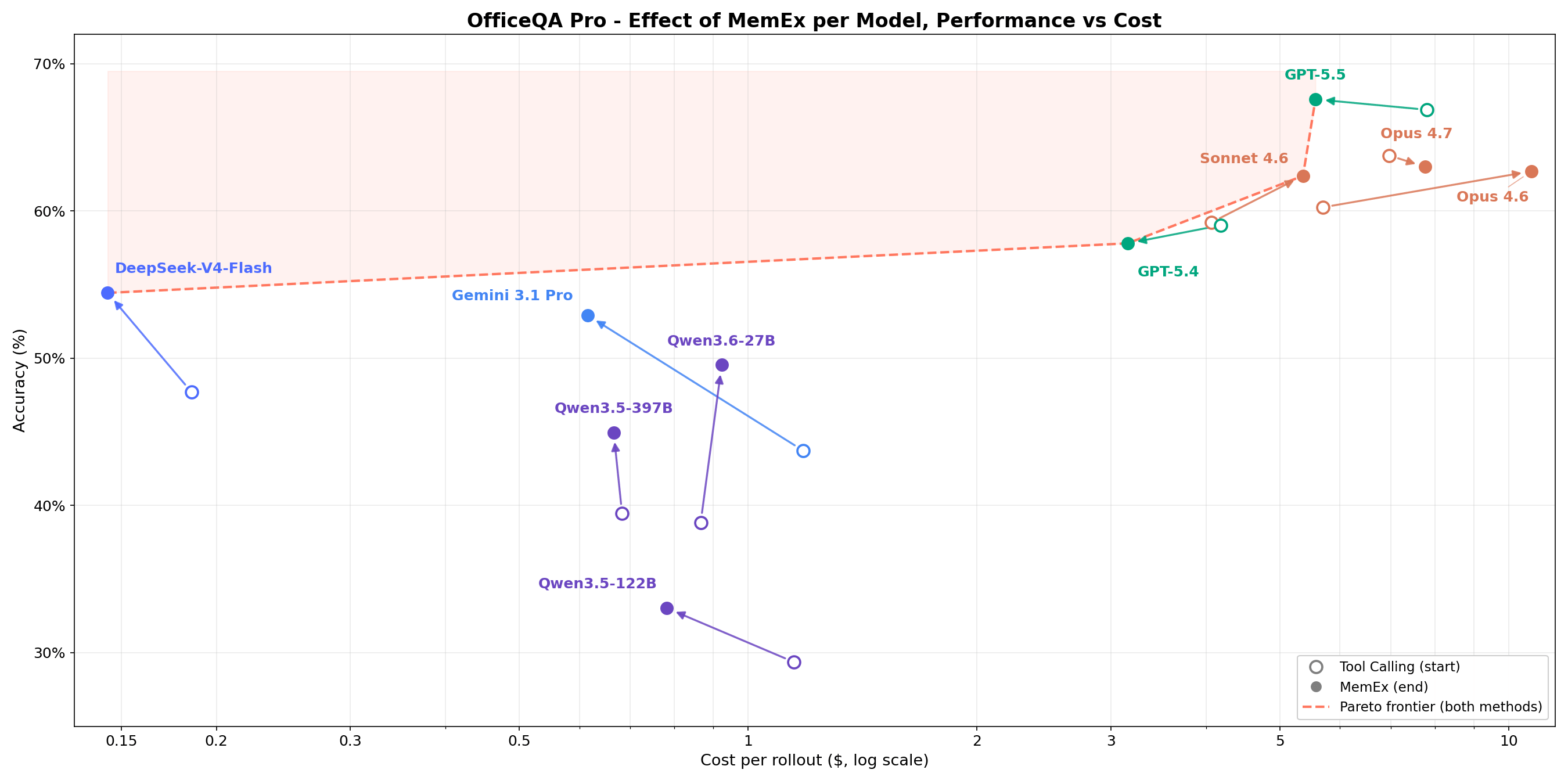
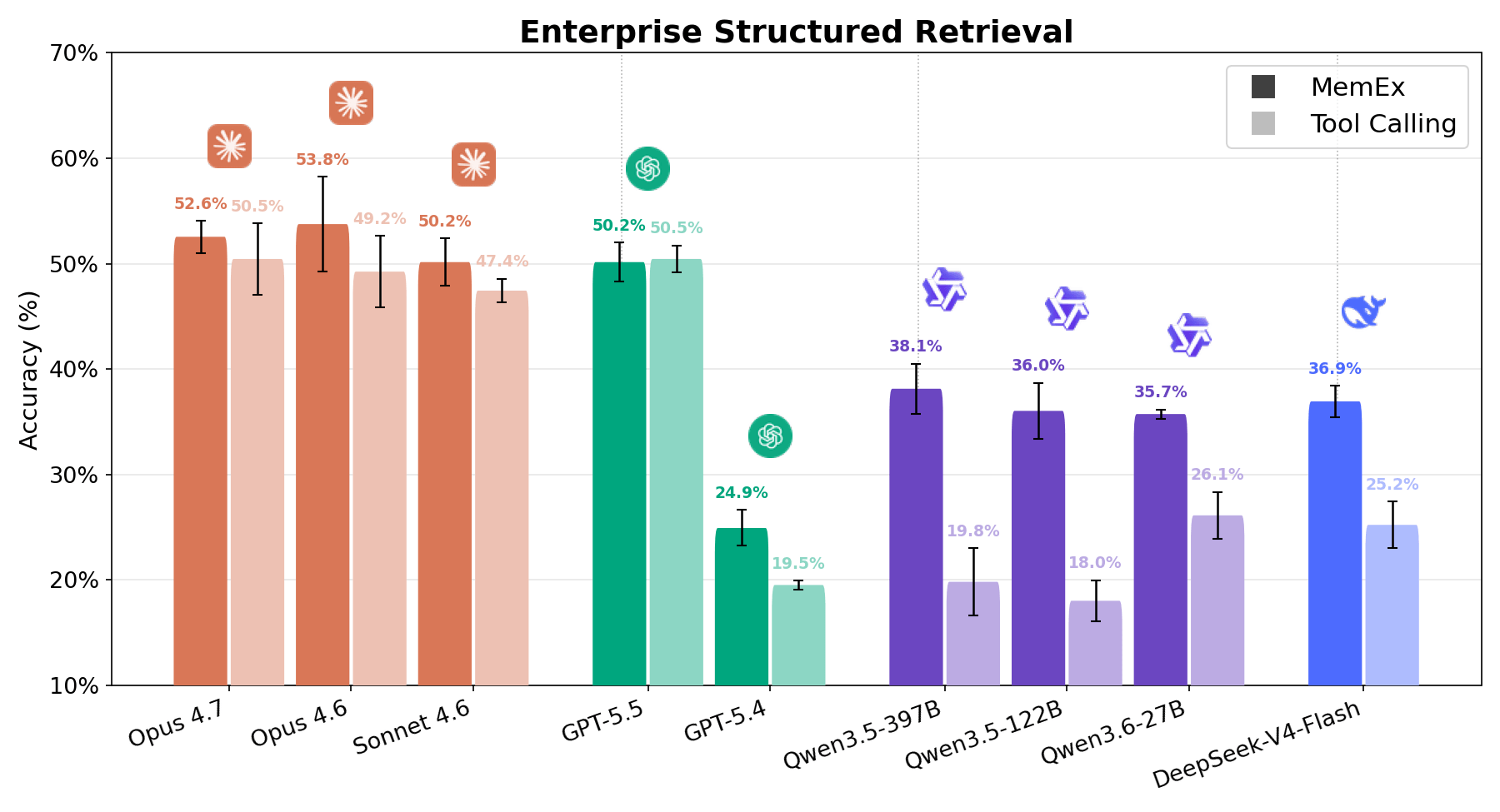
Sur des tâches complexes de recherche structurée d'entreprise, la figure 1 montre que MemEx repousse la frontière coût-précision pour chaque modèle. Les modèles de pointe comme Opus 4.6 et Sonnet 4.6 gagnent 2 à 5 points de pourcentage pour un coût en tokens inférieur de 25 à 30 %. Les modèles à poids ouverts comme Qwen3.5-122B (18 % → 36 %) et Qwen3.5-397B (20 % → 38 %) doublent presque leur précision pour un coût en tokens inférieur de 40 à 50 %. Comme MemEx peut opérer sur des entrées arbitrairement longues, il ouvre également la voie à deux autres applications : l'audit des trajectoires d'agents, y compris celle de MemEx, qui ne tiendraient normalement pas dans une seule fenêtre de contexte, et la pensée parallèle à travers plusieurs trajectoires.
Comment fonctionne MemEx
{kind=link}
MemEx offre au LLM un bloc-notes programmable : un noyau Python typé qui conserve les sorties d'outils, les transforme avec du code et ne matérialise que les instructions print sous forme de tokens dans le contexte. Dans cet environnement, le déroulement devient un programme Python auto-extensible. À chaque étape, l'agent rédige un nouveau bloc, le noyau maintient l'état actif et le bloc suivant s'appuie sur ce qui a précédé. Les outils sont exposés sous forme de fonctions Python typées avec des paramètres typés et des valeurs de retour typées. Les sorties d'outils arrivent sous forme d'objets Python dans la portée de MemEx, où elles persistent d'une étape à l'autre. L'agent les compose avec du code, définit des fonctions utilitaires lorsqu'un modèle se répète et génère des sous-agents sous forme d'appels de fonction asynchrones sur cette même portée.
MemEx s'inscrit dans la famille du « code comme action » introduite par CodeAct (Wang et al., 2024), avec des variantes de production dans le Programmatic Tool Calling d'Anthropic et le Cloudflare Code Mode. MemEx se distingue en s'intégrant dans un framework agentique existant de style ReAct (Yao et al., 2022), avec une portée persistante, des primitives de sous-agent et des retours typés intégrés. Ensemble, ces éléments débloquent des capacités qui manquent au paradigme d'appel d'outils JSON/XML :
- Gestion d'entrées arbitrairement volumineuses : les documents, jeux de données et autres objets volumineux peuvent être conservés dans la portée Python sous forme de variables.
- Retour d'objets typés : les sorties d'outils sont des objets Python typés conservés en mémoire, et non des chaînes de caractères que le modèle doit matérialiser ou analyser à nouveau à chaque étape.
- Composition d'appels d'outils : la sortie d'un appel alimente directement les arguments de l'appel suivant en une seule ligne de code. Les sorties intermédiaires n'ont pas besoin d'être matérialisées dans le contexte de l'agent.
- Découpage des sorties d'outils : les sorties peuvent être prétraitées, filtrées ou résumées dans le code avant que le modèle ne les voie.
- Génération de sous-agents asynchrones : les agents peuvent générer par programmation des sous-agents qui s'exécutent en parallèle du parent, et agréger leurs résultats sans faire d'aller-retour par le modèle principal.
Exemple d'agent LLM avec MemEx
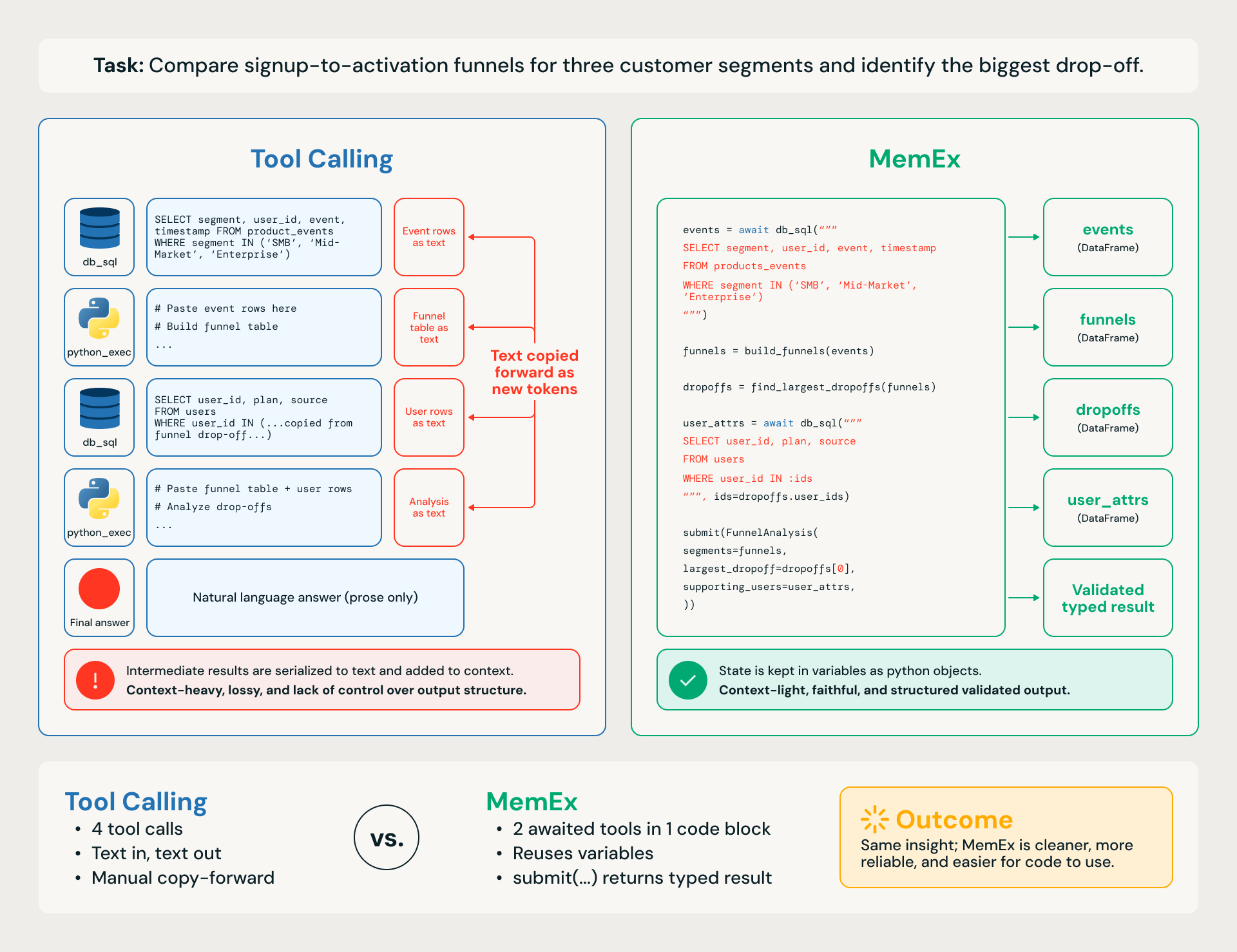
Prenons une tâche d'entreprise concrète, comme la comparaison des entonnoirs d'inscription à l'activation pour trois segments de clients et l'identification de la plus grande baisse (Figure 1). Le flux de travail comporte quatre étapes :
- récupérer les événements d'inscription et d'activation depuis l'entrepôt de données
- les joindre par utilisateur
- calculer les taux de conversion par segment à chaque étape
- classer les baisses d'un segment à l'autre.
Un agent d'appel d'outils (Tool Calling) équipé de python_exec travaille étape par étape. Chaque requête SQL et chaque calcul programmatique est un appel d'outil distinct, avec des DataFrames intermédiaires sérialisés en texte et recollés dans les étapes suivantes. La trace est gourmande en tokens, ce qui la rend sujette aux pertes, lente, coûteuse et sujette à de petites erreurs en cascade dans la tâche en aval.
Un agent MemEx écrit le même flux de travail sous la forme d'un seul bloc de code : les requêtes renvoient des DataFrames natifs dans la portée, des fonctions utilitaires les composent, et la réponse finale est renvoyée sous la forme d'un objet validé typé via submit(). Même pensée, espace d'action différent.
Pour les tâches qui se décomposent en sous-problèmes, l'agent peut générer des sous-agents depuis l'intérieur d'un bloc. Lors de la génération de sous-agents, l'agent parent peut transmettre un accès partagé à n'importe quel objet. Les sous-agents s'exécutent activement en parallèle avec le parent et peuvent renvoyer des résultats à l'agent principal une fois terminés. Par exemple :
La décomposition récursive devient une autre expression dans le même programme Python.
MemEx est développé sur la base d'aroll, le framework de déroulements agentiques de Databricks. Aroll alimente déjà des systèmes de production comme Genie, l'Agent Superviseur d'Agent Bricks, et des projets de recherche comme KARL. MemEx s'intègre dans la même boucle d'agent et les mêmes outils qu'aroll utilise déjà pour l'appel d'outils (Tool Calling).
Quelles sont les performances de MemEx dans les tâches agentiques d'entreprise ?
Nous avons effectué des évaluations comparatives sur 9 modèles de pointe où nous avons comparé les appels d'outils structurés parallèles (Tool Calling) aux blocs de code Python (MemEx). Pas d'optimisation des prompts, pas d'adaptation par tâche. Nous comparons deux formes de travail agentique d'entreprise : la lecture ancrée sur un grand corpus de texte (OfficeQA) et la recherche structurée sur un grand espace de travail de données relationnelles diverses (Enterprise Structured Retrieval).
Sur les deux tâches, l'agent MemEx est meilleur et moins cher que l'agent Tool Calling !
{kind=link}
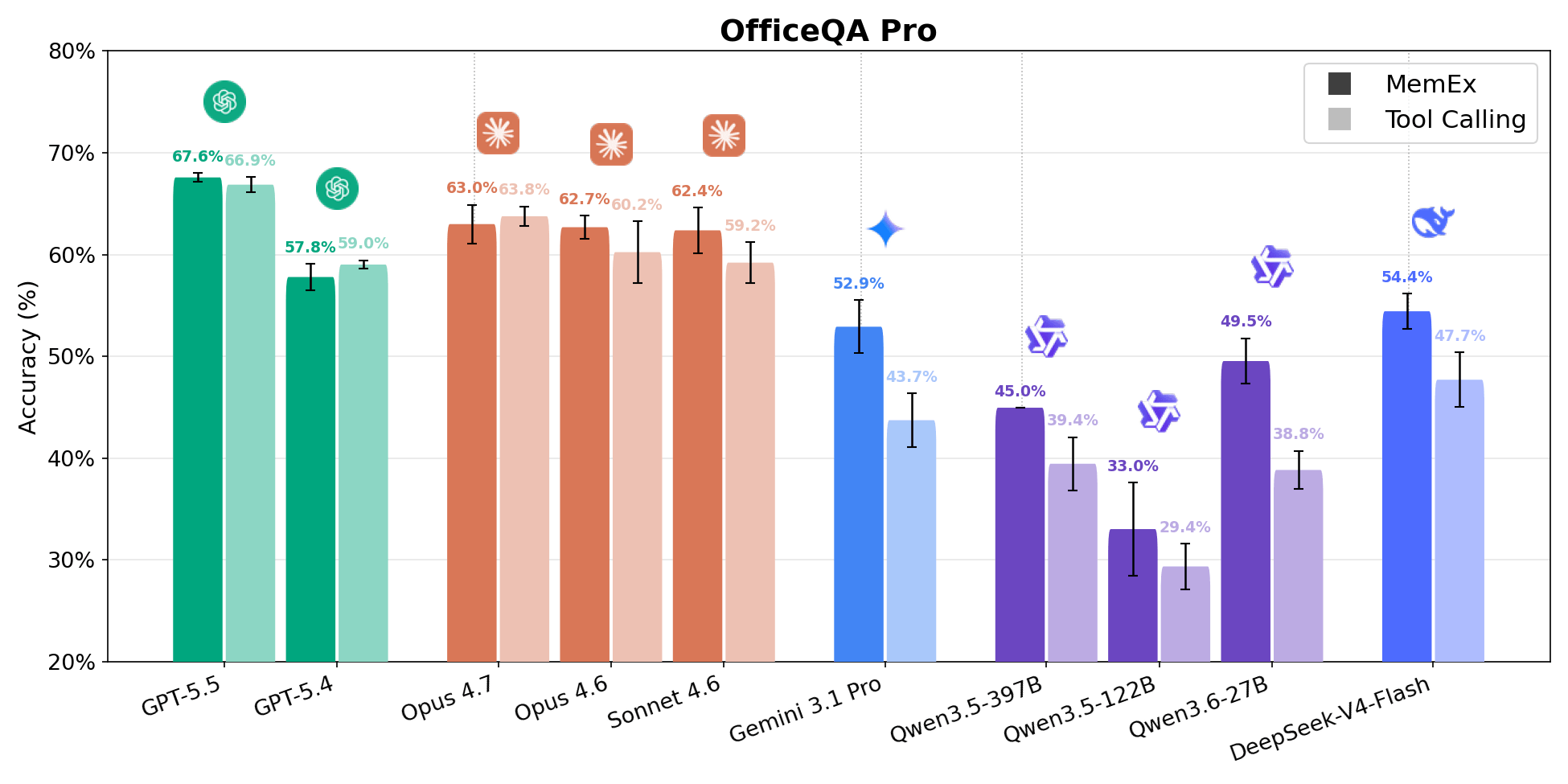
OfficeQA Pro demande à l'agent de répondre à des questions de raisonnement ancré sur le corpus des bulletins du Trésor américain (U.S. Treasury Bulletins), soit environ 89 000 pages allant de 1939 à nos jours. Une question typique nécessite de localiser des preuves dans plusieurs documents, de naviguer dans des tableaux avec des hiérarchies imbriquées et des cellules fusionnées, et d'effectuer des calculs sur les données récupérées. Les réponses sont évaluées par correspondance stricte. Quatre des cinq points de la frontière de Pareto coût-précision sont des configurations MemEx. Gemini 3.1 Pro MemEx est le point de la frontière le moins cher à 0,62 $ par exécution (précision de 52,9 %), et Sonnet 4.6 MemEx s'approche de la précision de GPT-5.5 Tool Calling pour environ 70 % du coût. Sur neuf modèles, MemEx fait match nul ou l'emporte sur chaque modèle. Le milieu du peloton progresse le plus, Qwen 3.6 27B et Gemini 3.1 Pro gagnant environ 10 points de pourcentage.
{kind=link}
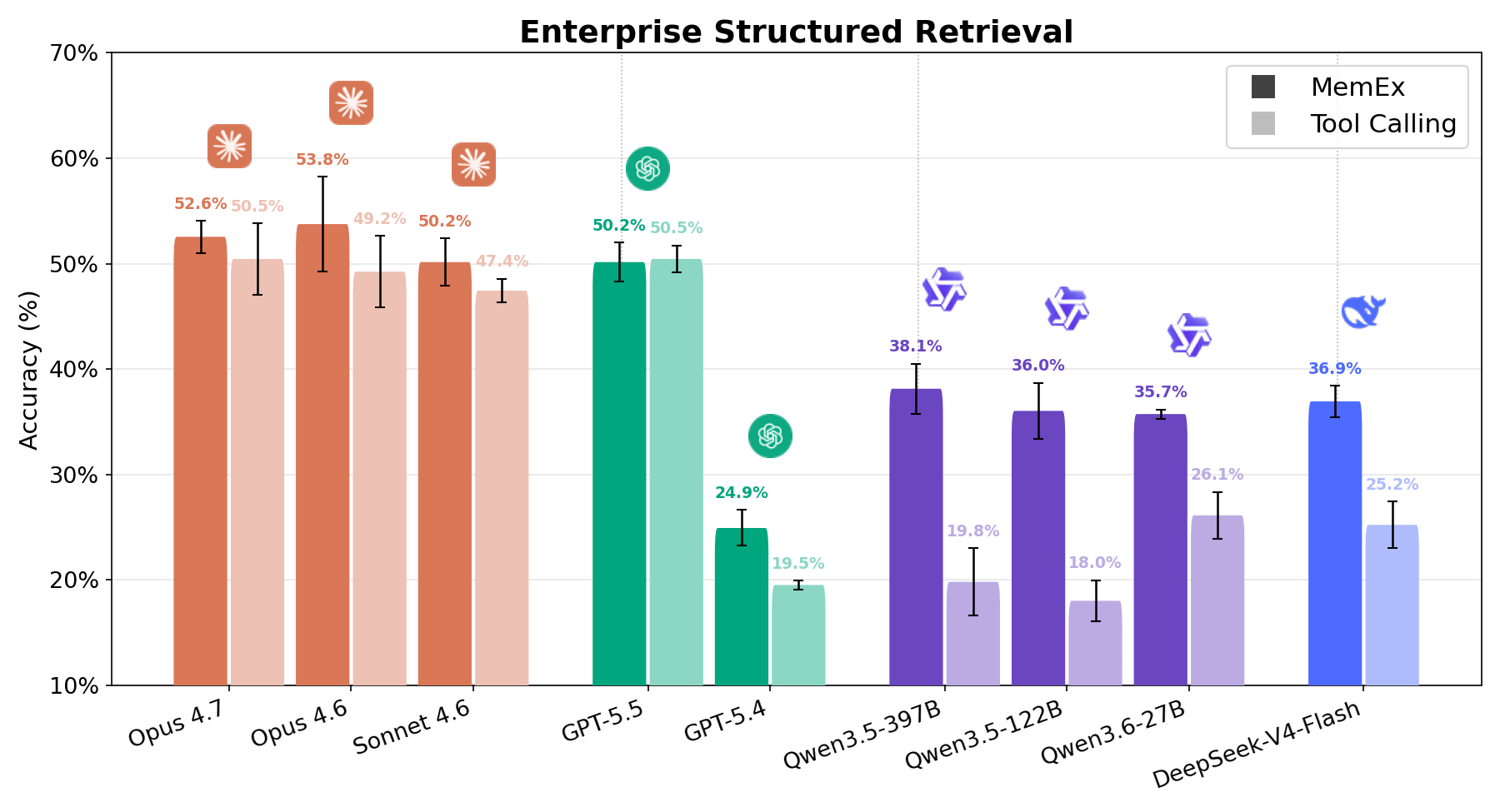
Enterprise Structured Retrieval demande à l'agent de répondre à des questions en langage naturel sur des données relationnelles d'entreprise. L'agent dispose d'outils liés à la découverte de schémas et à l'exécution de requêtes SQL, et doit les utiliser pour accomplir la tâche d'analyse de données demandée par l'utilisateur, généralement avec peu d'informations sur l'endroit où trouver les informations pertinentes dans cet espace de travail diversifié. Les réponses de l'agent sont évaluées par rapport à la vérité terrain à l'aide d'une validation de données déterministe et d'un LLM-as-a-judge. Comme le montrent les figures 1 et 6, chaque modèle affiche une forte progression avec MemEx, à l'exception de GPT 5.5 qui présente des performances équivalentes. Sur le plan des coûts, le constat est tout aussi convaincant. Qwen 122B passe de 56 à 28 appels d'outils par exécution tout en doublant son score ; Sonnet passe de 28 à 17 ; Opus de 33 à 21.1 Cela permet de diviser le coût par deux environ pour la plupart des modèles. Cette tendance fait écho à OfficeQA Pro : plus la tâche est difficile, plus les objets natifs et l'état persistant prouvent leur utilité.
Chaque comparaison a été effectuée sans optimisation des prompts (prompt tuning), sans adaptation par tâche et sans ajustement spécifique au modèle. La boucle de l'agent, les prompts système et les outils sont identiques sur les deux environnements de test. La seule différence réside dans l'espace d'action : les appels d'outils structurés JSON/XML par rapport aux blocs de code Python de MemEx.
Fonctionnement de MemEx sur les traces agentiques
Les trajectoires agentiques sont elles-mêmes des objets volumineux. Dans le paradigme Tool Calling, l'analyse des trajectoires nécessite généralement de les aplatir sous forme de texte, ce qui entraîne des pertes d'informations et s'avère lourd en contexte, et en analyser plusieurs à la fois est souvent impossible. Les trajectoires peuvent même s'étendre sur plusieurs fenêtres de contexte, avec une compression intermédiaire ; comment un LLM peut-il analyser une trace qui, par définition, ne tient pas dans son contexte ? Mais une trajectoire n'est qu'un autre objet Python, MemEx peut donc la charger directement dans sa portée et raisonner dessus. Nous présentons deux applications : d'abord, un agent d'audit basé sur MemEx qui analyse les trajectoires de Qwen 3.6-27B sur OfficeQA-Pro pour expliquer pourquoi MemEx surpasse Tool Calling ; ensuite, la mise à l'échelle au moment du test (test-time scaling) sur OfficeQA-Pro, avec un agent MemEx qui bat un agent Tool Calling équivalent.
MemEx audite MemEx : analyse des traces agentiques
Pour analyser pourquoi le passage à MemEx a entraîné une amélioration des performances pour les modèles open source, tels que Qwen 3.6-27B, nous laissons MemEx nous l'expliquer. En particulier, nous instancions un agent d'audit qui charge une question OfficeQA, sa réponse de vérité terrain et six trajectoires de résolution (3 d'un agent MemEx et 3 d'un agent Tool Calling) directement dans sa portée Python, et demande à un agent Sonnet 4.6 basé sur MemEx de classer chaque trajectoire erronée selon une taxonomie des modes de défaillance à quatre axes.
| Axe de défaillance | Définition | Erreurs MemEx | Erreurs Tool Calling |
|---|---|---|---|
Source Selection | Le modèle cible le mauvais document ou tableau | 32 | 45 |
Interpretation | Le modèle récupère les bonnes données mais en extrait une mauvaise interprétation | 28 | 38 |
Search Strategy | Le modèle s'arrête trop tôt ou s'égare au-delà de la réponse | 6 | 15 |
Execution | Bugs dans les calculs intermédiaires ou le formatage de la sortie finale | 3 | 6 |
Total | - | 69 | 104 |
Notre analyse porte sur 66 questions OfficeQA Pro pour lesquelles les six tentatives n'étaient pas toutes correctes ou incorrectes, ce qui donne 173 trajectoires. Les quatre axes se divisent en deux grands groupes :
- Erreurs d'ancrage (~83 %) : Cas où le modèle récupère une valeur préliminaire au lieu d'un chiffre révisé, interprète mal une terminologie ambiguë (par exemple, la variance de l'échantillon par rapport à la variance de la population, ou la précision de l'arrondi pour les « centièmes »), ou extrait la mauvaise colonne d'un tableau valide.
- Erreurs de stratégie de recherche et d'exécution : Erreur dans la planification de la séquence de récupération ou incapacité à intégrer correctement les données récupérées dans les calculs finaux.
Pour les erreurs de stratégie de recherche et d'exécution, MemEx constate que l'agent MemEx a réduit les erreurs par 2 par rapport à Tool Calling. En effet, avec MemEx, la récupération peut se faire directement dans des variables Python, ce qui permet au modèle d'éviter de copier les valeurs de la sortie d'un outil vers l'appel d'outil suivant, et plusieurs appels d'outils peuvent être regroupés en un seul tour. Tool Calling ne dispose pas d'un tel raccourci et doit toujours transcrire les valeurs entre les appels, ce qui donne parfois lieu à des erreurs. Par exemple, dans une trajectoire, une valeur de 3 501 provenant d'un document récupéré a été saisie à nouveau sous la forme 3531 dans l'appel suivant.
Pensée parallèle agentique avec MemEx
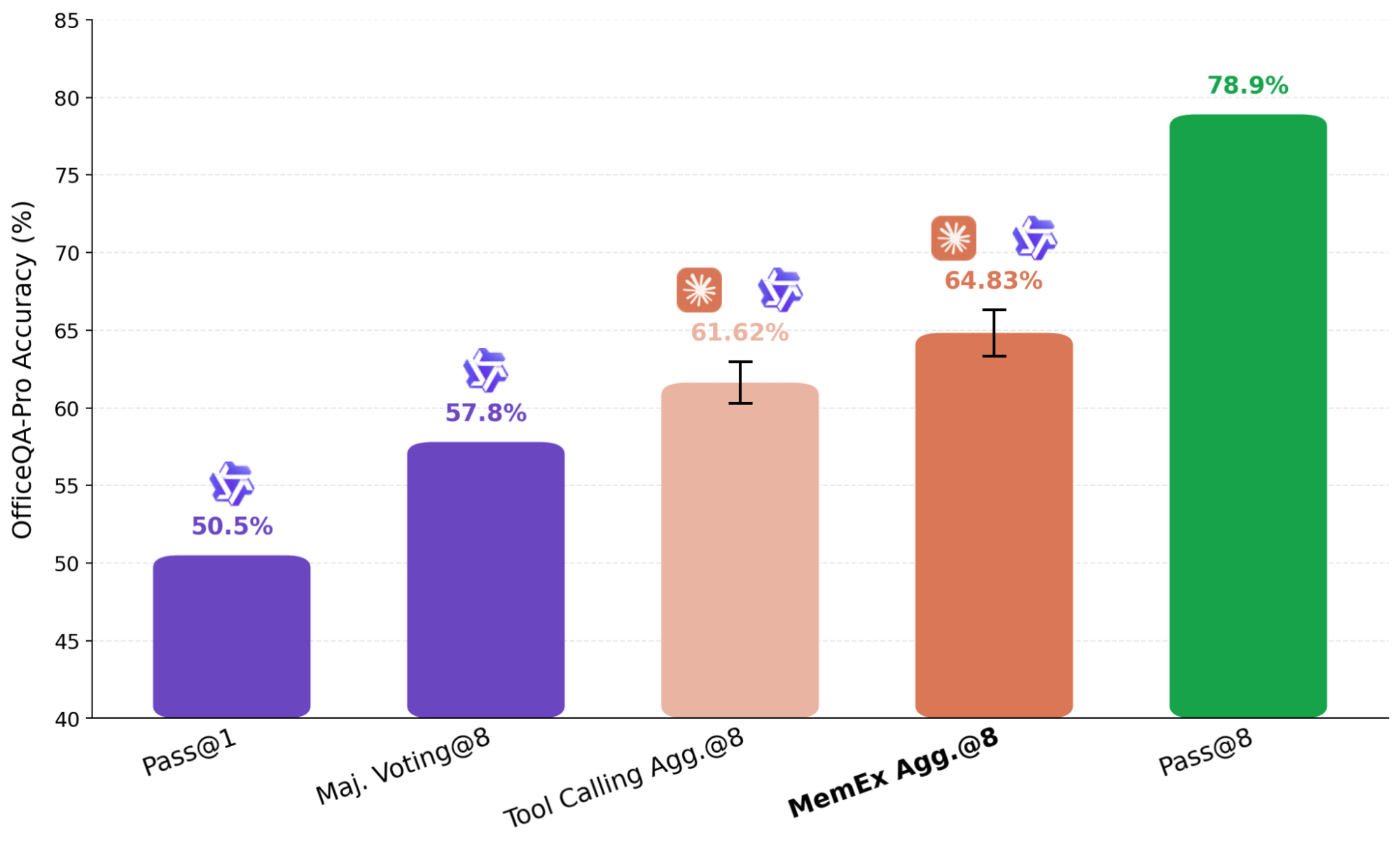
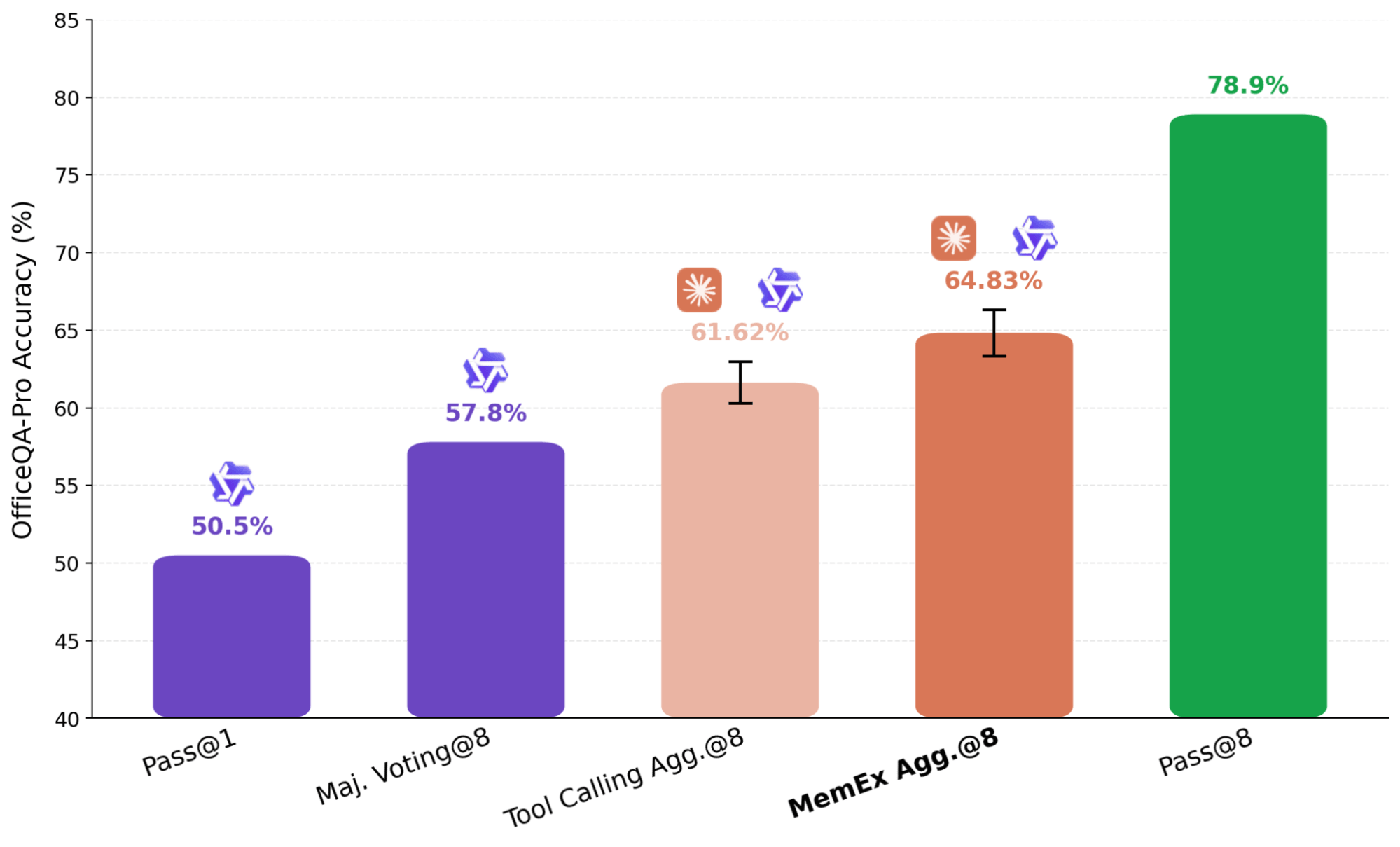
Une approche courante pour mettre à l'échelle le calcul au moment du test est la pensée parallèle, où plusieurs exécutions indépendantes d'une tâche sont agrégées dans une réponse finale. Dans la pensée parallèle agentique, comme l'approche utilisée dans KARL, les résumés des tentatives indépendantes sont transmis à un agent agrégateur. Cette étape de résumé entraîne des pertes mais est inévitable dans la configuration standard, car il n'est pas pratique d'intégrer plusieurs trajectoires complètes dans la fenêtre de contexte d'un modèle. Avec MemEx, nous pouvons plutôt charger ces trajectoires en tant que variables de portée, évitant ainsi complètement cette représentation avec perte.
{kind=link}
Dans le résultat présenté à la Figure 7, nous utilisons Claude Sonnet 4.6 comme agrégateur sur huit trajectoires Qwen-3.6-27B générées de manière indépendante. Pour nous assurer que l'agrégateur ne résout pas simplement le problème par lui-même, nous supprimons ses outils de recherche de fichiers, le limitant à la vérification et à la sélection. L'agent basé sur MemEx, qui reçoit les trajectoires complètes en entrée, surpasse l'agent équivalent de Tool Calling qui ne reçoit que leurs résumés. Dans un cas, l'agrégateur de trajectoires a détecté une erreur de duplication dans un bulletin précédent en lisant les sorties brutes des outils à partir des trajectoires d'entrée ; l'agrégateur de Tool Calling n'a pas pu vérifier l'affirmation de données dupliquées car ses entrées étaient limitées aux résumés, et s'est replié sur un vote majoritaire sur la source corrompue.
Architecture de MemEx
Les agents de Tool Calling émettent un ou plusieurs appels d'outils structurés par tour (JSON ou XML), chacun se conformant à un schéma d'outil prédéfini, dans la boucle action-observation introduite par ReAct (Yao et al., 2022). CodeAct (Wang et al., 2024) a remplacé ce format par un noyau Python persistant : l'agent émet du code Python arbitraire, et les variables ainsi que les définitions de fonctions sont conservées d'un tour à l'autre. Les variantes de production de ce même paradigme incluent le Programmatic Tool Calling (PTC) d'Anthropic et le Cloudflare Code Mode ; PTC conserve également l'état d'une requête à l'autre en réutilisant le même conteneur, ce qui n'est pas le cas de Code Mode. MemEx étend ce paradigme avec quatre ajouts supplémentaires :
- Intégration d'outils simplifiée (drop-in) avec préservation des schémas de paramètres.
- Portée (scope) Python active au début du rollout.
submit()typé pour les retours structurés.spawn_agent()non bloquant pour les sous-agents parallèles, généralisant les modèles de langage récursifs (Recursive Language Models) (Zhang et al., 2025).
L'implémentation repose sur trois choix de conception :
Le code comme action, dans un REPL persistant
L'action de l'agent est un bloc de code Python arbitraire, exécuté dans un espace de noms qui persiste d'un tour à l'autre. Les outils, les objets de portée (scope) et les résultats précédents résident tous dans cet espace de noms. L'agent lit les observations (stdout, valeurs de retour, erreurs), puis écrit du code supplémentaire. La même boucle observation-action qui exécute le Tool Calling exécute MemEx ; seul l'espace d'action change.
Intégration simplifiée (Drop-in) pour le Tool Calling
Les outils de Tool Calling existants sont automatiquement injectés sous forme de fonctions Python, y compris les schémas de paramètres et les métadonnées de type de retour. Passer un agent existant du Tool Calling à MemEx se résume à un simple changement de configuration.
Exécution indépendante du backend
Le même code d'agent s'exécute sur trois backends, choisis au moment de la configuration :
- In-process pour une itération rapide pendant la recherche.
- Sous-processus (Subprocess) pour l'isolation pendant l'évaluation.
- Pool pour une génération par lots (batch) à haut débit (données d'entraînement, déploiements à grande échelle).
Pour les déploiements en production, le noyau peut être remplacé par un bac à sable (sandbox) hébergé comme les Managed Agents d'Anthropic. Le code de l'agent reste le même, l'isolation du système de fichiers, les contrôles de sortie réseau et les limites de ressources étant gérés par l'hôte.
Et ensuite ?
MemEx arrive entre les mains de vos agents. Nous le déployons sur les agents natifs de Databricks et sur Agent Bricks : si vous développez aujourd'hui sur les agents Databricks, vous pourrez bientôt utiliser MemEx.
Nous post-entraînons nos modèles pour l'espace d'action de MemEx. MemEx lui-même sert de substrat : il génère des données synthétiques, exécute des vérificateurs d'agents et alimente la boucle d'entraînement.
Auteurs : Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 Dans MemEx, les appels d'outils sont des blocs de code Python qui peuvent comporter des analyses de données ou d'autres outils appelés en tant que fonctions asynchrones (async).
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.