Mise à l'échelle de la mémoire pour les agents d'IA
La mise à l'échelle de l'inférence a permis aux LLM de raisonner sur la plupart des situations pratiques, à condition qu'ils disposent du bon contexte. Pour de nombreux agents du monde réel, le goulot d'étranglement n'est plus la capacité de raisonnement, mais l'ancrage de l'agent dans les bonnes informations : fournir au modèle ce dont il a besoin pour la tâche à accomplir.
Cela suggère un nouvel axe pour la conception d'agents. Plutôt que de se concentrer uniquement sur des modèles plus performants ou de meilleures invites, nous pouvons nous demander : l'agent s'améliore-t-il à mesure qu'il accumule plus d'informations ? Nous appelons cela la mise à l'échelle de la mémoire : la propriété selon laquelle les performances de l'agent s'améliorent avec la quantité de conversations passées, de retours d'utilisateurs, de trajectoires d'interaction (réussies et échouées) et de contexte métier stockés dans sa mémoire. L'effet est particulièrement prononcé dans les environnements d'entreprise, où les connaissances internes sont abondantes et où un seul agent sert de nombreux utilisateurs.
Mais cela n'est pas évident a priori. Plus de mémoire ne rend pas automatiquement un agent meilleur : des traces de faible qualité peuvent enseigner de mauvaises leçons, et la récupération devient plus difficile à mesure que le stockage augmente. La question centrale est de savoir si les agents peuvent utiliser des mémoires plus grandes de manière productive plutôt que de simplement les accumuler.
Nous avons fait les premiers pas dans cette direction chez Databricks grâce à ALHF et MemAlign, qui ajustent le comportement de l'agent en fonction des retours humains, et à l'Instructed Retriever, qui permet aux agents de recherche de traduire des instructions complexes en langage naturel et des schémas de sources de connaissances en requêtes de recherche précises et structurées. Ensemble, ces systèmes démontrent que les agents peuvent être plus utiles grâce à une mémoire persistante. Ce billet présente les résultats expérimentaux démontrant le comportement de mise à l'échelle de la mémoire, discute de l'infrastructure nécessaire pour la supporter en production et offre une vision prospective des agents basés sur la mémoire.
Qu'est-ce que la mise à l'échelle de la mémoire ?
La mise à l'échelle de la mémoire est la propriété selon laquelle les performances d'un agent s'améliorent à mesure que sa mémoire externe grandit. Ici, « mémoire » fait référence à un stockage persistant d'informations avec lequel l'agent peut interagir au moment de l'inférence, distinct des poids du modèle ou de la fenêtre de contexte actuelle.
Cela fait de la mise à l'échelle de la mémoire un axe distinct et complémentaire à la mise à l'échelle paramétrique et à la mise à l'échelle au moment de l'inférence, comblant les lacunes en matière de connaissances du domaine et d'ancrage que ni la taille du modèle ni la capacité de raisonnement ne peuvent combler à elles seules. Les améliorations dues à la mise à l'échelle de la mémoire ne se limitent pas à la qualité des réponses. Lorsqu'un agent a mémorisé les schémas pertinents, les règles du domaine ou les actions passées réussies pour un environnement, il peut éviter une exploration redondante et résoudre les requêtes plus rapidement. Dans nos expériences, nous observons une mise à l'échelle de la précision et de l'efficacité.
Relation avec l'apprentissage continu
L'apprentissage continu se concentre généralement sur la mise à jour des paramètres du modèle au fil du temps, ce qui fonctionne bien dans des paramètres bornés mais devient coûteux en calcul et fragile avec de nombreux utilisateurs simultanés, agents et projets en évolution rapide. La mise à l'échelle de la mémoire pose une question différente : un agent avec des milliers d'utilisateurs obtient-il de meilleurs résultats qu'un agent avec un seul utilisateur ? En élargissant l'état externe partagé d'un agent tout en gardant les poids du LLM figés, la réponse peut être oui — un modèle de flux de travail appris d'un utilisateur peut être récupéré et appliqué immédiatement à un autre, sans aucun réentraînement. C'est une propriété que l'apprentissage continu, axé sur les mises à jour des paramètres du modèle d'un seul utilisateur, n'a jamais été conçu pour fournir.
Relation avec le contexte long
Les grandes fenêtres de contexte peuvent sembler être un substitut à la mémoire, mais elles résolvent des problèmes différents. L'intégration de millions de jetons bruts dans une invite augmente la latence, augmente les coûts de calcul et dégrade la qualité du raisonnement à mesure que les jetons non pertinents entrent en compétition pour l'attention. La mise à l'échelle de la mémoire repose plutôt sur une récupération sélective — décidant non seulement quelle quantité de contexte inclure, mais aussi quoi inclure, en ne présentant que les informations à fort signal pertinentes pour la tâche actuelle.
Types de mémoire
Toutes les mémoires ne servent pas le même objectif. Deux distinctions sont importantes en pratique :
Épisodique vs. sémantique. Les mémoires épisodiques sont des enregistrements bruts des interactions passées — journaux de conversation, trajectoires d'appels d'outils, retours d'utilisateurs. Les mémoires sémantiques sont des compétences et des faits généralisés distillés de ces interactions (par exemple, « les utilisateurs dans cet espace signifient toujours le trimestre fiscal lorsqu'ils disent 'trimestre' »). Chaque type nécessite différentes stratégies de stockage, de traitement et de récupération : mémoires épisodiques pour la récupération directe et mémoires sémantiques distillées par un LLM pour une mise en correspondance de modèles plus large.
Personnel vs. organisationnel. Certaines mémoires sont spécifiques aux préférences et aux flux de travail d'un seul utilisateur ; d'autres représentent des connaissances organisationnelles partagées — conventions de nommage, requêtes courantes, règles métier. Le système de mémoire doit organiser la récupération et les mises à jour de manière appropriée : présenter les connaissances organisationnelles de manière large tout en gardant le contexte individuel privé, en respectant les autorisations et les ACL.
Expériences : Magasin de connaissances organisationnelles
MemAlign est notre exploration de ce à quoi pourrait ressembler un cadre de mémoire simple pour les agents IA. Il stocke les interactions passées sous forme de mémoires épisodiques, utilise un LLM pour les distiller en règles et modèles généralisés (mémoires sémantiques), et récupère les entrées les plus pertinentes au moment de l'inférence pour guider l'agent. Pour plus de détails sur le cadre, consultez notre article de blog précédent.
Nous avons testé MemAlign sur les Genie Spaces de Databricks, une interface en langage naturel où les utilisateurs professionnels posent des questions sur les données en anglais simple et reçoivent des réponses basées sur SQL. Un exemple de requête et de réponse est fourni ci-dessous
Notre objectif est de mesurer comment les performances de l'agent évoluent à mesure que nous lui fournissons plus de mémoire, en utilisant deux sources de données : des exemples organisés (étiquetés) et des journaux de conversation bruts d'utilisateurs (non étiquetés).
Mise à l'échelle avec des données étiquetées
Nous avons évalué MemAlign sur des questions inédites réparties sur 10 espaces Genie, en ajoutant progressivement des fragments d'exemples d'entraînement annotés à la mémoire de l'agent. Notre référence est un agent utilisant des instructions Genie organisées par des experts (schémas de table écrits manuellement, règles de domaine et exemples few-shot).
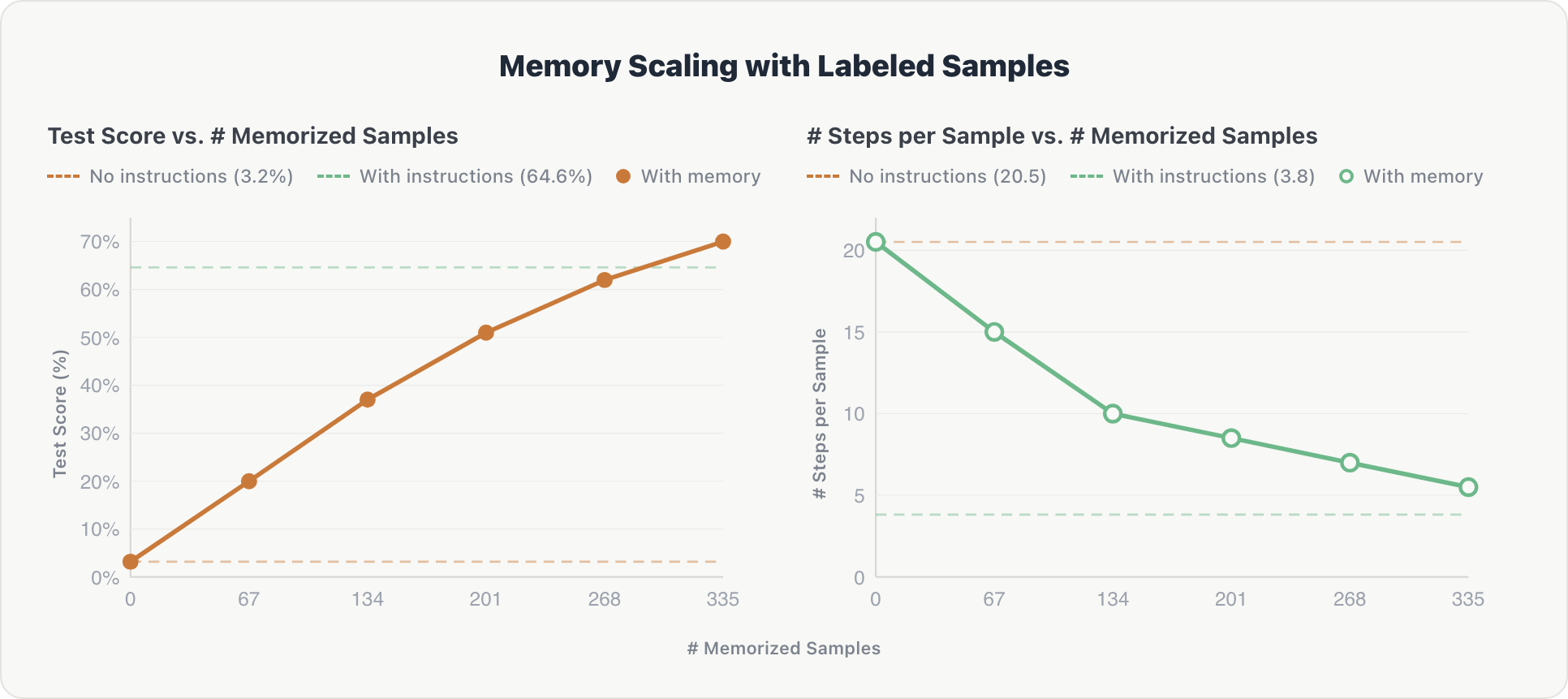
Les résultats montrent une mise à l'échelle cohérente sur les deux dimensions :
Précision. Les scores de test ont augmenté régulièrement à chaque fragment de mémoire supplémentaire, passant de près de zéro à 70 %, dépassant finalement la référence organisée par des experts d'environ 5 %. Après inspection, les données étiquetées par des humains se sont avérées plus complètes et donc plus utiles que les schémas de table et les règles de domaine écrits manuellement.
Efficacité. Le nombre moyen d'étapes de raisonnement par exemple est passé d'environ 20 à environ 5 à mesure que la mémoire augmentait. L'agent a appris à récupérer le contexte pertinent directement plutôt qu'à explorer la base de données à partir de zéro, approchant l'efficacité des instructions codées en dur (environ 3,8 étapes).
L'effet est cumulatif : comme les exemples mémorisés couvrent 10 espaces Genie différents, chaque fragment apporte des informations inter-domaines qui s'appuient sur les connaissances antérieures.
Mise à l'échelle avec des journaux d'utilisateurs non étiquetés
La mémoire peut-elle évoluer avec des données bruitées du monde réel ? Pour le savoir, nous avons exécuté MemAlign dans un espace Genie en direct et lui avons fourni des journaux de conversation d'utilisateurs historiques sans réponses de référence. Un juge LLM a filtré ces journaux pour leur utilité, et seuls ceux de haute qualité ont été mémorisés.
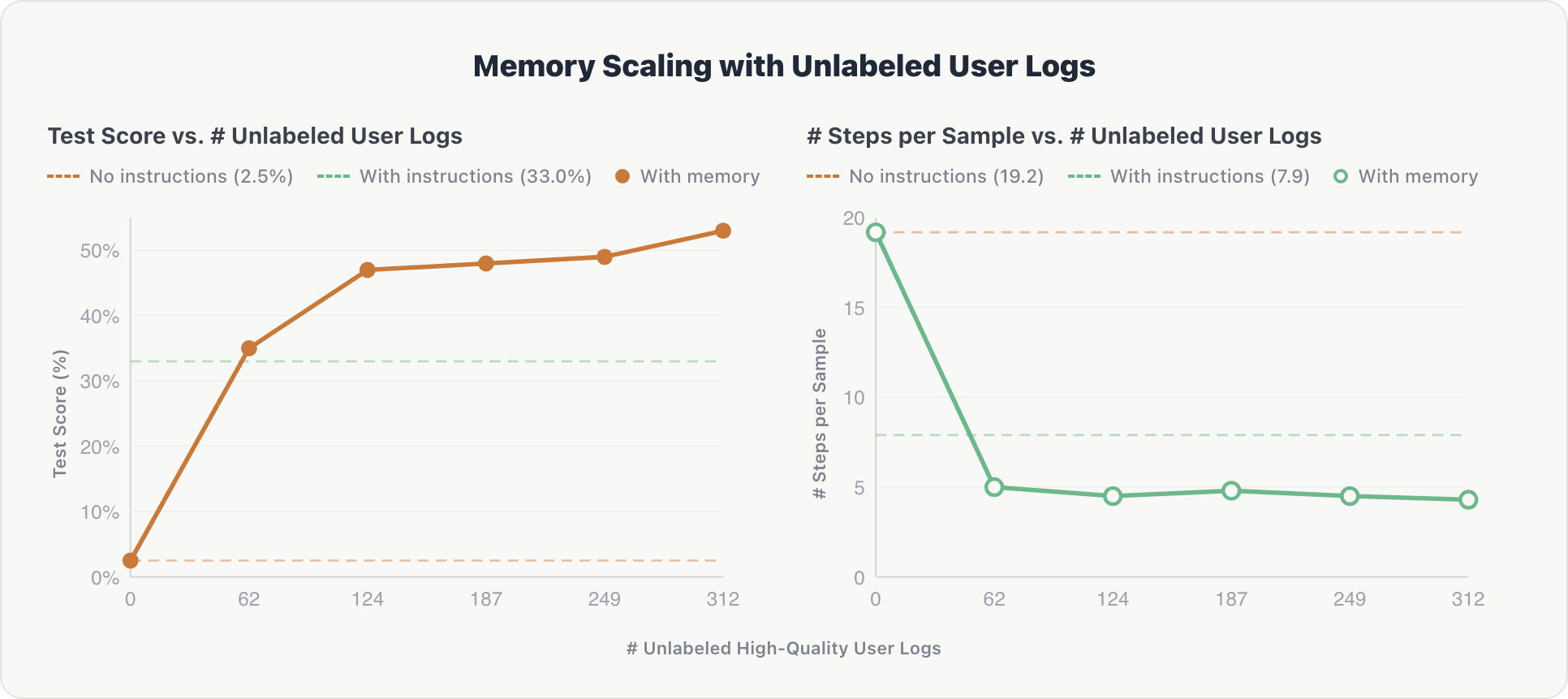
La courbe de mise à l'échelle suit un schéma similaire et est plus abrupte au début :
Précision. L'agent a montré un gain initial rapide. Après le premier fragment de journal, il a extrait des informations clés sur les tables pertinentes et les préférences implicites de l'utilisateur. Les performances sont passées de 2,5 % à plus de 50 %, dépassant la référence organisée par des experts (33,0 %) après seulement 62 enregistrements de journaux.
Efficacité. Les étapes de raisonnement sont passées d'environ 19 à environ 4,3 après le premier fragment et sont restées stables. L'agent a internalisé le schéma de l'espace tôt et a évité l'exploration redondante lors des requêtes ultérieures.
La conclusion : les interactions utilisateur non organisées, filtrées uniquement par un juge automatisé sans référence, peuvent remplacer les instructions de domaine coûteuses et chronophages conçues manuellement. Cela suggère également des agents qui s'améliorent continuellement grâce à une utilisation normale et peuvent évoluer au-delà des limites de l'annotation humaine.
Expériences : Magasin de connaissances organisationnelles
Les expériences ci-dessus montrent comment la mise à l'échelle de la mémoire se produit avec les interactions des utilisateurs. Mais les entreprises disposent également de connaissances existantes antérieures à toute interaction utilisateur : schémas de tables, requêtes de tableaux de bord, glossaires métier et documentation interne. Nous avons testé si le pré-calcul de ces connaissances organisationnelles dans un magasin de mémoire structuré pouvait améliorer les performances de l'agent.
Nous avons évalué ce magasin de connaissances sur un benchmark interne de recherche de données et sur PMBench, qui teste la recherche exhaustive de faits sur des documents internes mixtes tels que des notes de réunion de chefs de produit et des documents de planification.
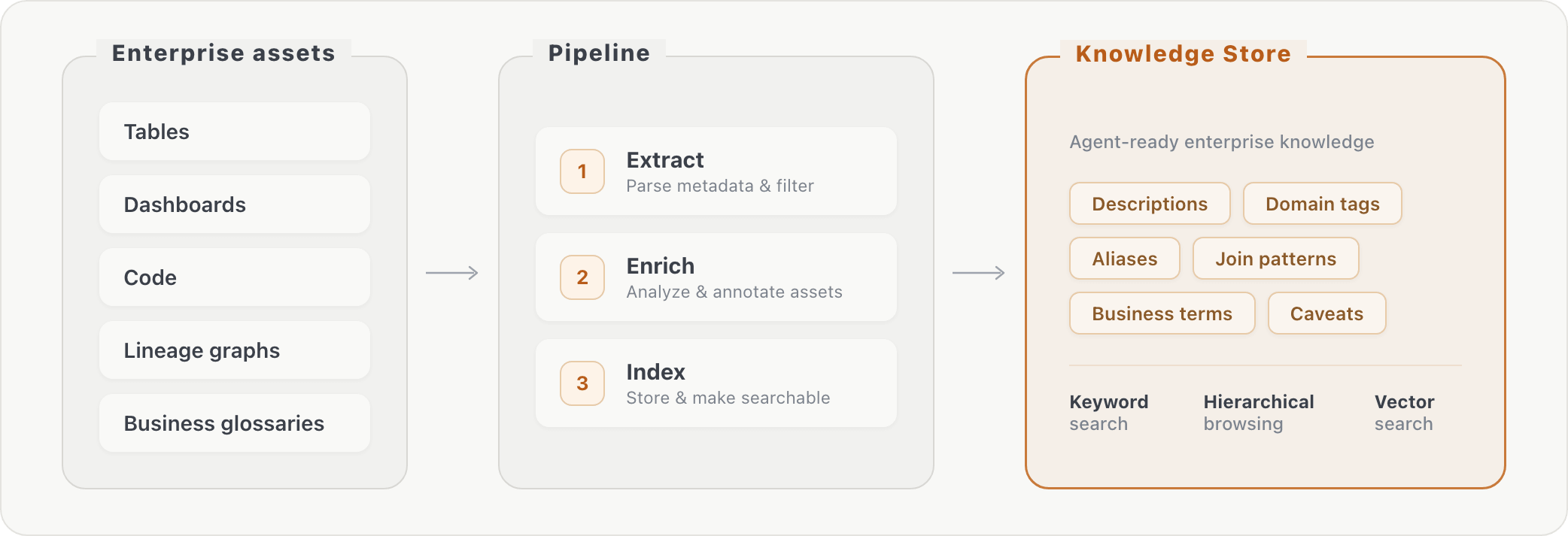
Notre pipeline traite les métadonnées brutes de la base de données en connaissances récupérables en trois étapes : (1) extraction d'informations sur les actifs, (2) enrichissement des actifs via des transformations supplémentaires, et (3) indexation du contenu enrichi. Au moment de la requête, l'agent peut rechercher le contexte de l'entreprise par recherche par mots-clés ou par navigation hiérarchique. Cela comble le fossé entre la façon dont les utilisateurs métier formulent les questions (« consommation d'IA ») et la façon dont les données sont réellement stockées (noms de colonnes spécifiques dans des tables spécifiques).
L'ajout du magasin de connaissances a amélioré la précision d'environ 10 % sur les deux benchmarks évalués. Les gains étaient concentrés sur les questions qui nécessitaient une correspondance de vocabulaire, des jointures de tables et des connaissances au niveau des colonnes, c'est-à-dire des informations que l'agent n'aurait pas pu découvrir par la seule exploration du schéma.
Infrastructure pour la mise à l'échelle de la mémoire
La mise à l'échelle de la mémoire dans les déploiements d'entreprise nécessite une infrastructure robuste au-delà d'un simple magasin vectoriel. Dans ce qui suit, nous discuterons de trois défis clés que cette infrastructure doit relever : le stockage évolutif, la gestion de la mémoire et la gouvernance.
Stockage évolutif
Le stockage de mémoire le plus simple est le système de fichiers : fichiers markdown dans des dossiers hiérarchiques, parcourus et recherchés avec des outils shell standard. La mémoire basée sur des fichiers fonctionne bien à petite échelle et pour les utilisateurs individuels, mais elle manque d'indexation, de requêtes structurées et de recherche de similarité efficace. À mesure que la mémoire atteint des milliers d'entrées pour de nombreux utilisateurs, la récupération se dégrade et la gouvernance devient difficile à appliquer.
Les magasins de données dédiés sont la prochaine étape logique. Les bases de données vectorielles autonomes gèrent bien la recherche sémantique, mais manquent de capacités relationnelles comme les jointures et le filtrage. Les systèmes modernes basés sur PostgreSQL offrent une alternative plus unifiée : ils prennent en charge nativement les requêtes structurées, la recherche plein texte et la recherche de similarité vectorielle dans un seul moteur.
Les variantes sans serveur de cette architecture qui séparent le stockage du calcul et fournissent un stockage durable et peu coûteux sont une solution naturelle. Nous utilisons Lakebase, construit sur le moteur PostgreSQL sans serveur de Neon, grâce à son coût de mise à l'échelle à zéro et à sa prise en charge de la recherche vectorielle et exacte. Le branchement natif de la base de données simplifie également le cycle de développement — les ingénieurs peuvent cloner l'état de la mémoire de l'agent pour les tests sans affecter la production.
Gestion de la mémoire
Le stockage évolutif seul ne suffit pas. Un système de mémoire doit également gérer son contenu :
- Amorçage. Les nouveaux agents souffrent souvent de problèmes de démarrage à froid. L'ingestion d'actifs d'entreprise existants (wikis, documentation, guides internes) via l'analyse et l'extraction de documents fournit une base de mémoire initiale qui peut atténuer certains de ces problèmes, comme démontré par nos expériences sur le magasin de connaissances organisationnelles.
- Distillation. Les mémoires épisodiques brutes sont utiles pour la récupération directe, mais deviennent coûteuses à stocker et à rechercher à grande échelle. Les distiller périodiquement en mémoires sémantiques (règles et modèles compressés) maintient le magasin de mémoire tractable et fournit des informations généralisables à l'agent, qui peuvent ne pas être évidentes à partir de la mémoire épisodique seule.
- Consolidation. À mesure que la mémoire grandit, il est important de maintenir le système cohérent, compact et à jour. Cela nécessite des pipelines qui suppriment les doublons, élaguent les informations obsolètes et résolvent les conflits entre les anciennes et les nouvelles entrées.
Sécurité
La mémoire introduit des exigences de gouvernance qui n'existent pas pour les agents sans état. À mesure que les agents accumulent des connaissances contextuelles approfondies, y compris les préférences des utilisateurs, les flux de travail propriétaires et les modèles de données internes, les mêmes principes de gouvernance qui s'appliquent aux données d'entreprise doivent s'étendre à la mémoire de l'agent.
Les contrôles d'accès doivent être conscients de l'identité : les mémoires individuelles doivent rester privées, tandis que les connaissances organisationnelles peuvent être partagées dans des limites contrôlées par l'accès. Cela correspond naturellement au type d'autorisations granulaires que des plateformes comme Unity Catalog appliquent déjà aux actifs de données, telles que la sécurité au niveau des lignes, le masquage des colonnes et le contrôle d'accès basé sur les attributs.
L'extension de ces contrôles aux entrées de mémoire signifie qu'un agent récupérant le contexte pour un utilisateur ne peut pas afficher par inadvertance les interactions privées d'un autre utilisateur.
Au-delà du contrôle d'accès, la lignée des données et l'auditabilité sont importantes. Lorsque le comportement d'un agent est façonné par sa mémoire, les équipes doivent pouvoir retracer quelles mémoires ont influencé une réponse donnée et quand ces mémoires ont été créées ou mises à jour. Les exigences de conformité et réglementaires, en particulier dans les industries réglementées, exigent que les magasins de mémoire prennent en charge les mêmes garanties d'observabilité que les données sous-jacentes : suivi complet de la lignée, politiques de rétention et capacité de supprimer des entrées spécifiques sur demande.
S'assurer que la bonne mémoire parvient au bon utilisateur, et seulement à cet utilisateur, est un problème de conception central à grande échelle.
Ce qui fait obstacle
Chaque axe de mise à l'échelle rencontre finalement son propre goulot d'étranglement. La mise à l'échelle paramétrique est limitée par l'approvisionnement en données d'entraînement de haute qualité. La mise à l'échelle au moment de l'inférence peut dégénérer en sur-analyse, où des chaînes de raisonnement plus longues ajoutent des coûts sans ajouter de signal, dégradant finalement les performances à mesure que la longueur de la séquence augmente. La mise à l'échelle de la mémoire a des limites analogues : problèmes de qualité, de portée et d'accès.
La qualité de la mémoire est difficile à maintenir. Certaines mémoires sont fausses dès le départ ; d'autres deviennent fausses avec le temps. Un agent sans état commet des erreurs isolées, mais un agent doté de mémoire peut transformer une erreur en une erreur récurrente en la stockant et en la récupérant plus tard comme preuve. Nous avons vu des agents citer des notebooks de courses précédentes qui étaient eux-mêmes erronés, puis réutiliser ces résultats avec encore plus de confiance. L'obsolescence est plus subtile : un agent qui a appris le schéma du trimestre précédent peut continuer à interroger des tables qui ont depuis été renommées ou supprimées. Le filtrage à l'ingestion aide, mais les systèmes de production ont besoin de plus que du filtrage. Ils ont besoin de provenance, d'estimations de confiance, de signaux de fraîcheur et de re-validation périodique.
La gouvernance doit s'étendre à la distillation. La mise à l'échelle de la mémoire dans une organisation nécessite la distillation des interactions répétées en mémoires sémantiques réutilisables. Mais l'abstraction n'élimine pas la sensibilité. Une mémoire comme « pour l'entreprise Y, joindre les tables CRM, intelligence marché et partenariat » peut sembler inoffensive tout en révélant un intérêt d'acquisition confidentiel. Le défi est de rendre la mémoire largement utile sans transformer les modèles privés en connaissances partagées. Les contrôles d'accès et les étiquettes de sensibilité doivent survivre à la distillation, pas seulement à l'ingestion.
Les mémoires utiles peuvent rester inaccessibles. Même si la mémoire est précise et actuelle, l'agent doit encore découvrir qu'elle existe. La récupération est intrinsèquement métacognitive : l'agent doit décider de ce qu'il faut demander à son magasin de mémoire avant de savoir ce qu'il contient. Lorsqu'il ne parvient pas à anticiper qu'une mémoire pertinente pourrait aider, il n'émet jamais la bonne requête et se rabat sur une exploration lente et redondante. En pratique, le fossé entre les connaissances stockées et les connaissances accessibles peut être le principal facteur limitant la mise à l'échelle de la mémoire.
Ce ne sont pas des arguments contre la mise à l'échelle de la mémoire. Ce sont les problèmes de recherche qui doivent encore être résolus pour rendre la mise à l'échelle de la mémoire robuste. Le problème central n'est pas seulement de stocker plus d'historique ; il s'agit d'apprendre à l'agent à trouver la bonne mémoire, à l'utiliser de manière appropriée et à la maintenir à jour et correctement délimitée.
Regard vers l'avenir : L'agent comme mémoire
Les expériences et l'infrastructure ci-dessus convergent vers un modèle de conception naturel : un agent dont l'identité réside dans sa mémoire, et non dans ses poids de modèle.
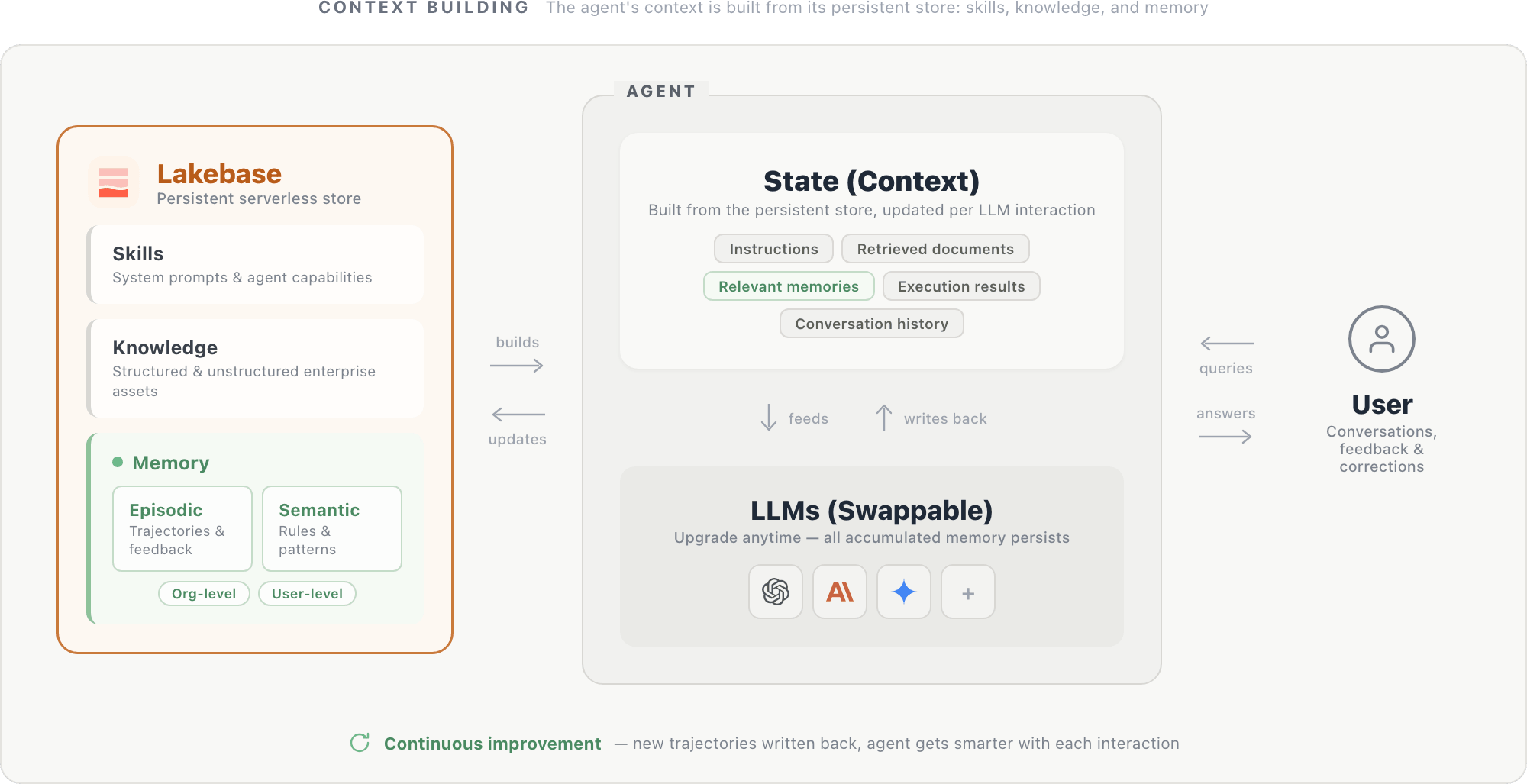
Dans cette conception, le contexte d'un agent est construit à partir d'un magasin persistant hébergé dans une base de données sans serveur comme Lakebase. Le magasin contient trois composants : les invites système et les capacités de l'agent (compétences), les actifs d'entreprise structurés et non structurés (connaissances), et les mémoires épisodiques et sémantiques délimitées au niveau de l'organisation et de l'utilisateur. Ensemble, ces composants forment l'état de l'agent : instructions, documents récupérés, mémoires pertinentes, résultats d'exécution (à partir de requêtes SQL, d'appels API et d'autres outils), et historique de conversation. Cet état est alimenté au LLM à chaque étape et mis à jour après chaque interaction.
Le LLM lui-même est un moteur de raisonnement interchangeable : la mise à niveau vers un modèle plus récent est simple, car le nouveau modèle lit à partir du même magasin persistant et bénéficie immédiatement de tout le contexte accumulé.
Alors que les modèles fondamentaux convergent en termes de capacités, le différenciateur pour les agents d'entreprise sera de plus en plus la mémoire qu'ils ont accumulée plutôt que le modèle qu'ils appellent. Hypothétiquement, un modèle plus petit avec un riche magasin de mémoire peut surpasser un modèle plus grand avec moins de mémoire — si tel est le cas, investir dans l'infrastructure de mémoire pourrait rapporter plus que l'augmentation des paramètres du modèle. Les connaissances du domaine, les préférences de l'utilisateur et les modèles opérationnels spécifiques à votre organisation ne se trouvent dans aucun modèle fondamental. Ils ne peuvent être construits que par l'usage, et contrairement aux capacités du modèle, ils sont uniques à chaque déploiement.
Conclusion
Nous proposons le Memory Scaling, où les performances d'un agent s'améliorent à mesure qu'il accumule plus d'expérience grâce à l'interaction utilisateur et au contexte métier dans sa mémoire. Nos expériences initiales montrent que la précision et l'efficacité augmentent avec la quantité d'informations stockées dans la mémoire externe.
La mise en œuvre en production nécessite des systèmes de stockage qui unifient la recherche structurée et non structurée, des pipelines de gestion qui maintiennent la cohérence de la mémoire et des contrôles de gouvernance qui définissent l'accès de manière appropriée. Ce sont des problèmes résolubles avec la technologie actuelle. La récompense est des agents qui s'améliorent réellement avec une utilisation continue.
Le travail restant est considérable : la mémoire doit rester précise, à jour et accessible à mesure qu'elle grandit. Mais c'est précisément pour cela que le Memory Scaling est intéressant. Il ouvre un programme concret de systèmes et de recherche pour construire des agents qui s'améliorent avec une utilisation continue d'une manière spécifique à chaque organisation et à chaque problème.
Auteurs : Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
Nous tenons à remercier Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh et Patrick Wendell pour leurs précieux commentaires tout au long du projet.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.