Modernisez votre plateforme de Data Engineering avec Lakeflow sur Azure Databricks
Databricks Lakeflow sur Azure fournit une solution de data engineering moderne, fiable et prête pour l'entreprise.
par Joanna Zouhour et Katie Cummiskey
- Lakeflow fournit une solution unifiée de bout en bout pour les data engineer travaillant sur Azure Databricks, couvrant l'ingestion, la transformation et l'orchestration des données
- De la sécurité et de la gouvernance unifiées à l'observabilité intégré, en passant par le compute serverless, le traitement en streaming et une interface utilisateur « code-first », les utilisateurs d'Azure Databricks peuvent bénéficier d'un large éventail de fonctionnalités Lakeflow, en combinaison avec leur plateforme de données Azure.
- Les data engineer qui utilisent Lakeflow sur Azure Databricks peuvent créer et déployer des pipelines de données prêts pour la production jusqu'à 25 fois plus rapidement, bénéficier de performances accrues et constater une réduction des coûts ETL pouvant atteindre 83 %.
Les data engineers sont de plus en plus frustrés par le nombre d'outils et de solutions disparates qu'ils doivent utiliser pour créer des pipelines prêts pour la production. Sans une plateforme centralisée d'intelligence des données ou une gouvernance unifiée, les équipes sont confrontées à de nombreux problèmes, notamment :
- Performances inefficaces et longs starts
- Interface utilisateur décousue et changements de contexte constants
- Manque de sécurité et de contrôle granulaires
- CI/CD complexe
- Visibilité limitée de la data lineage
- etc.
Les résultats Des équipes plus lentes et moins de confiance dans vos données.
Avec Lakeflow sur Azure Databricks, vous pouvez résoudre ces problèmes en centralisant tous vos efforts de Data Engineering sur une seule plateforme native Azure.

Une solution d'ingénierie des données unifiée pour Azure Databricks
Lakeflow est une solution de data engineering moderne de bout en bout, basée sur la plateforme Databricks Data Intelligence sur Azure, qui intègre toutes les fonctions essentielles de data engineering. Avec Lakeflow, vous bénéficiez de :
- Ingestion, transformation et orchestration des données intégrées en un seul endroit
- Connecteurs d'ingestion gérés
- ETL déclaratif pour un développement plus simple et plus rapide
- Traitement incrémentiel et en streaming pour des SLA plus rapides et des insights plus récents
- Gouvernance et lignage natifs via Unity Catalog, la solution de gouvernance intégrée de Databricks
- Observabilité intégrée pour la qualité des données et la fiabilité des pipelines
Et bien plus encore ! Le tout dans une interface flexible et modulaire qui peut s'adapter aux besoins de tous les utilisateurs, qu'ils souhaitent coder ou utiliser une interface de type « point-and-click ».
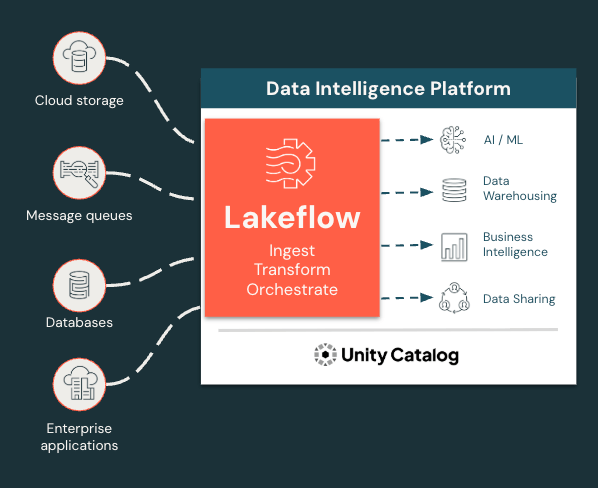
Ingérez, transformez et orchestrez toutes les charges de travail en un seul endroit
Lakeflow unifie l'expérience d'ingénierie des données afin que vous puissiez avancer plus rapidement et de manière plus fiable.
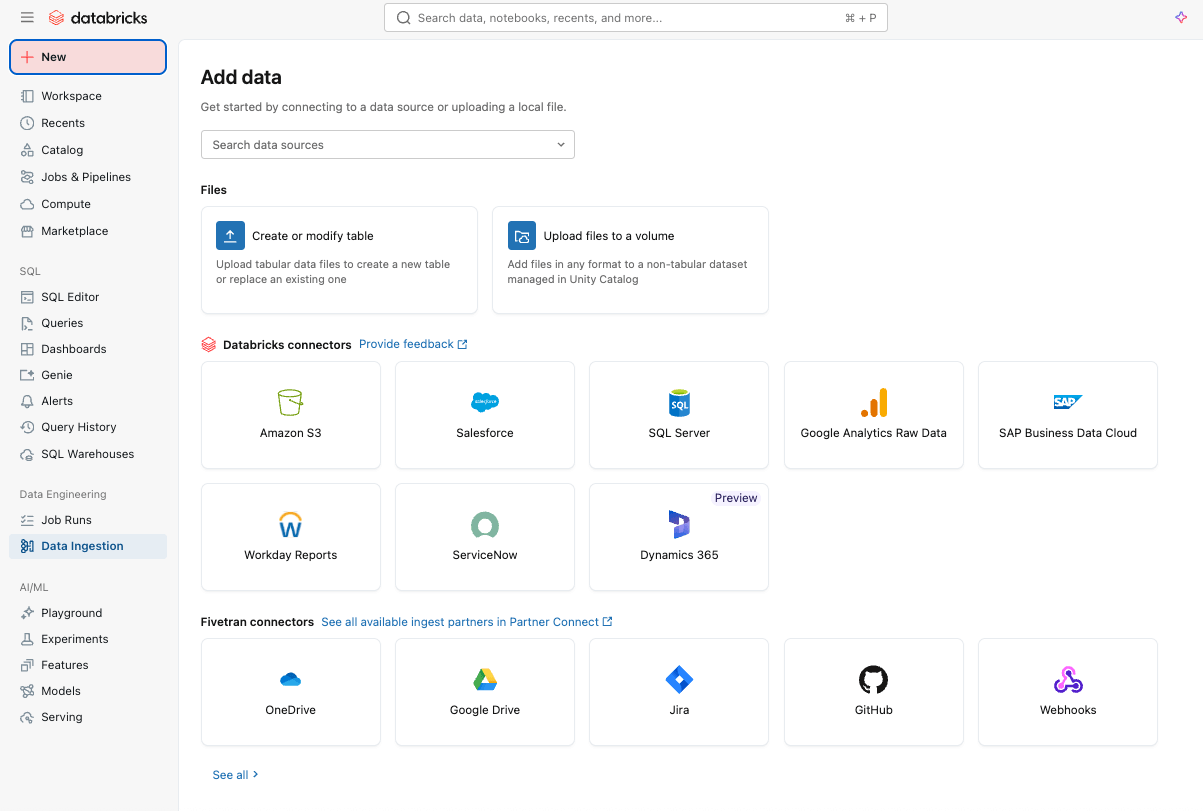
Ingestion de données simple et efficace avec Lakeflow Connect
Vous pouvez commencer par ingérer facilement des données dans votre plateforme avec Lakeflow Connect à l'aide d'une interface pointer-cliquer ou d'une simple API.
Vous pouvez ingérer des données à la fois structurées et non structurées depuis un large éventail de sources prises en charge dans Azure Databricks, y compris des applications SaaS populaires (par ex., Salesforce, Workday, ServiceNow), des bases de données (par ex., SQL Server), du stockage cloud, des bus de messages, et plus encore. Lakeflow Connect prend également en charge les modèles de réseau Azure, tels que Private Link et le déploiement de passerelles d'ingestion dans un VNet pour les bases de données.
Pour l'ingestion en temps réel, découvrez Zerobus Ingest, une API d'écriture directe sans serveur dans Lakeflow sur Azure Databricks. Elle envoie les données d'événement directement dans la plateforme de données, éliminant le besoin d'un bus de messagerie pour une ingestion plus simple et à plus faible latence.
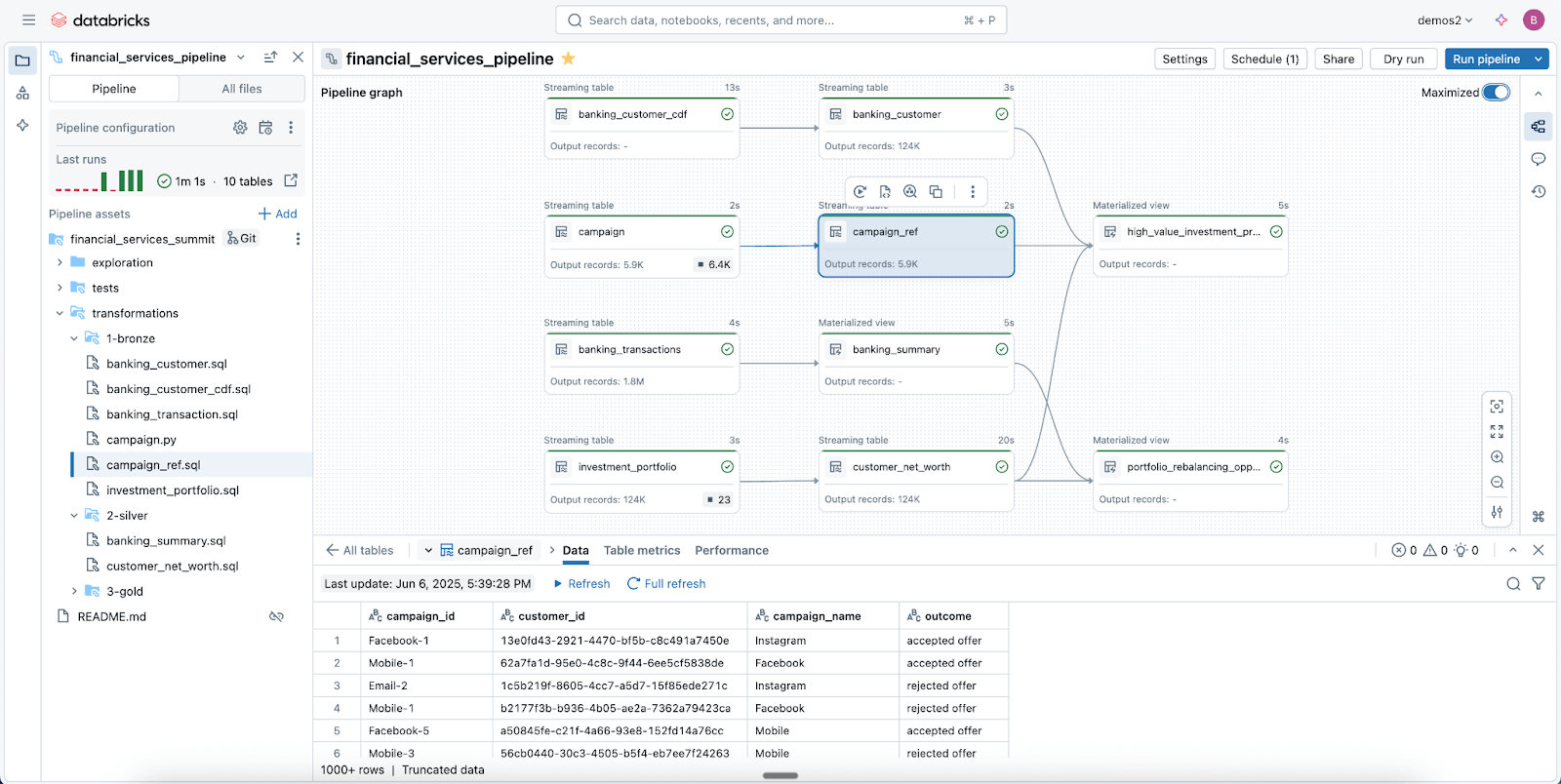
Pipelines de données fiables simplifiés avec Spark Declarative Pipelines
Exploitez Lakeflow Spark Declarative Pipelines (SDP) pour nettoyer, façonner et transformer facilement vos données en fonction des besoins de votre entreprise.
SDP vous permet de créer des ETL fiables par lots et en streaming avec seulement quelques lignes de Python (ou SQL). Il vous suffit de déclarer les transformations dont vous avez besoin, et SDP s'occupe du reste, y compris le mappage des dépendances, l'infrastructure de déploiement et la qualité des données.
SDP minimise le temps de développement et les frais opérationnels, tout en codifiant les meilleures pratiques d'ingénierie des données prêtes à l'emploi, ce qui facilite la mise en œuvre de l'incrémentalisation ou de modèles complexes comme les SCD de type 1 et 2 en quelques lignes de code seulement. C'est toute la puissance de Spark Structured Streaming, rendue incroyablement simple.
Et comme Lakeflow est intégré à Azure Databricks, vous pouvez utiliser les outils Azure Databricks, notamment Databricks Asset Bundles (DAB), Lakehouse Monitoring et plus encore, pour déployer des pipelines gouvernés et prêts pour la production en quelques minutes.
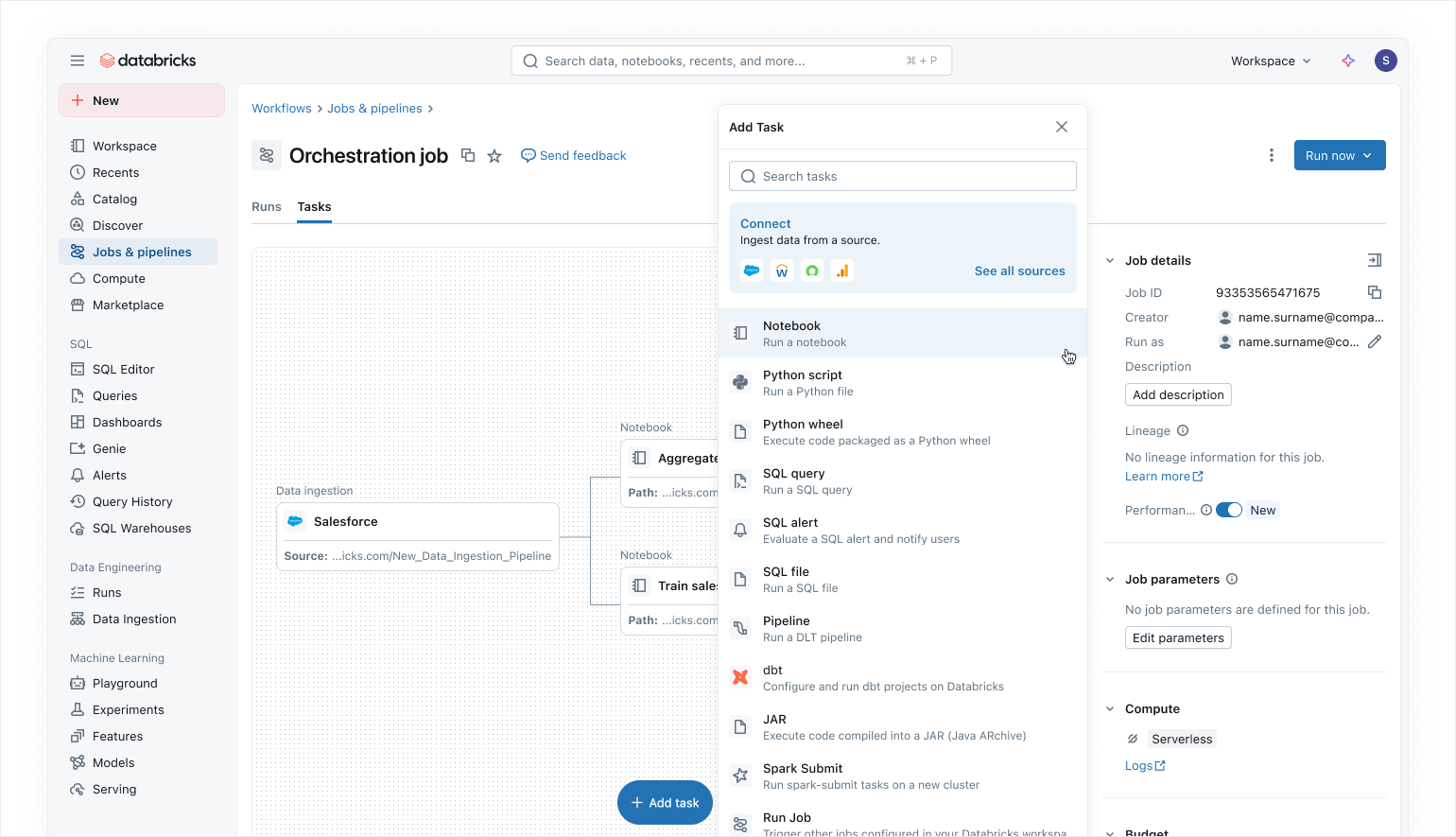
Orchestration moderne axée sur les données avec les jobs Lakeflow
Utilisez les jobs Lakeflow pour orchestrer vos workloads de données et d'IA sur Azure Databricks. Grâce à une approche moderne, simplifiée et axée sur les données, les jobs Lakeflow constituent l'orchestrateur le plus fiable pour Databricks, prenant en charge le traitement de données et d'IA à grande échelle ainsi que l'analytique en temps réel avec une fiabilité de 99,9 %.
Dans Lakeflow Jobs, vous pouvez visualiser toutes vos dépendances en coordonnant les charges de travail SQL, le code Python, les tableaux de bord, les pipelines et les systèmes externes dans un seul DAG unifié. L'exécution du workflow est simple et flexible grâce à des déclencheurs basés sur les données, tels que les mises à jour de tables ou les arrivées de fichiers, et des tâches de flux de contrôle. Grâce aux exécutions de backfill no-code et à l'observabilité intégrée, Lakeflow Jobs facilite le maintien de la fraîcheur, de l'accessibilité et de l'exactitude de vos données en aval.
En tant qu'utilisateurs d'Azure Databricks, vous pouvez également mettre à jour et actualiser automatiquement les modèles sémantiques Power BI en utilisant la tâche Power BI dans Lakeflow Jobs (en savoir plus ici), faisant de Lakeflow Jobs un orchestrateur fluide pour les workloads Azure.
Sécurité intégrée et gouvernance unifiée
Avec Unity Catalog, Lakeflow hérite des contrôles centralisés d'identité, de sécurité et de gouvernance pour l'ingestion, la transformation et l'orchestration. Les connexions stockent les informations d'identification en toute sécurité, les politiques d'accès sont appliquées de manière cohérente à toutes les charges de travail, et les autorisations granulaires garantissent que seuls les utilisateurs et les systèmes autorisés peuvent lire ou écrire des données.
Unity Catalog fournit également un lignage des données de bout en bout, de l'ingestion aux analyses en aval et à Power BI en passant par les Lakeflow Jobs, ce qui facilite le suivi des dépendances et garantit la conformité. Les tables système offrent une visibilité opérationnelle et de sécurité sur les Jobs, les utilisateurs et l'utilisation des données pour aider les équipes à surveiller la qualité et à appliquer les bonnes pratiques sans avoir à assembler des Logs externes.
Ensemble, Lakeflow et Unity Catalog fournissent aux utilisateurs d'Azure Databricks des pipelines gouvernés par défaut, ce qui permet une livraison de données sécurisée, auditable et prête pour la production, à laquelle les équipes peuvent se fier.
Lisez notre article de blog sur la façon dont Unity Catalog prend en charge OneLake.
Expérience utilisateur et création flexibles pour tous
En plus de toutes ces fonctionnalités, Lakeflow est incroyablement flexible et simple d'utilisation, ce qui en fait une solution idéale pour tous les membres de votre organisation, en particulier les développeurs.
Les utilisateurs « code-first » adorent Lakeflow grâce à son puissant moteur d'exécution et à ses outils avancés axés sur les développeurs. Avec Lakeflow Pipeline Editor, les développeurs peuvent tirer parti d'un IDE et utiliser des outils de développement robustes pour créer leurs pipelines. Lakeflow Jobs propose également une création « code-first » et des outils de développement avec DB Python SDK et des DAB pour des modèles CI/CD reproductibles.
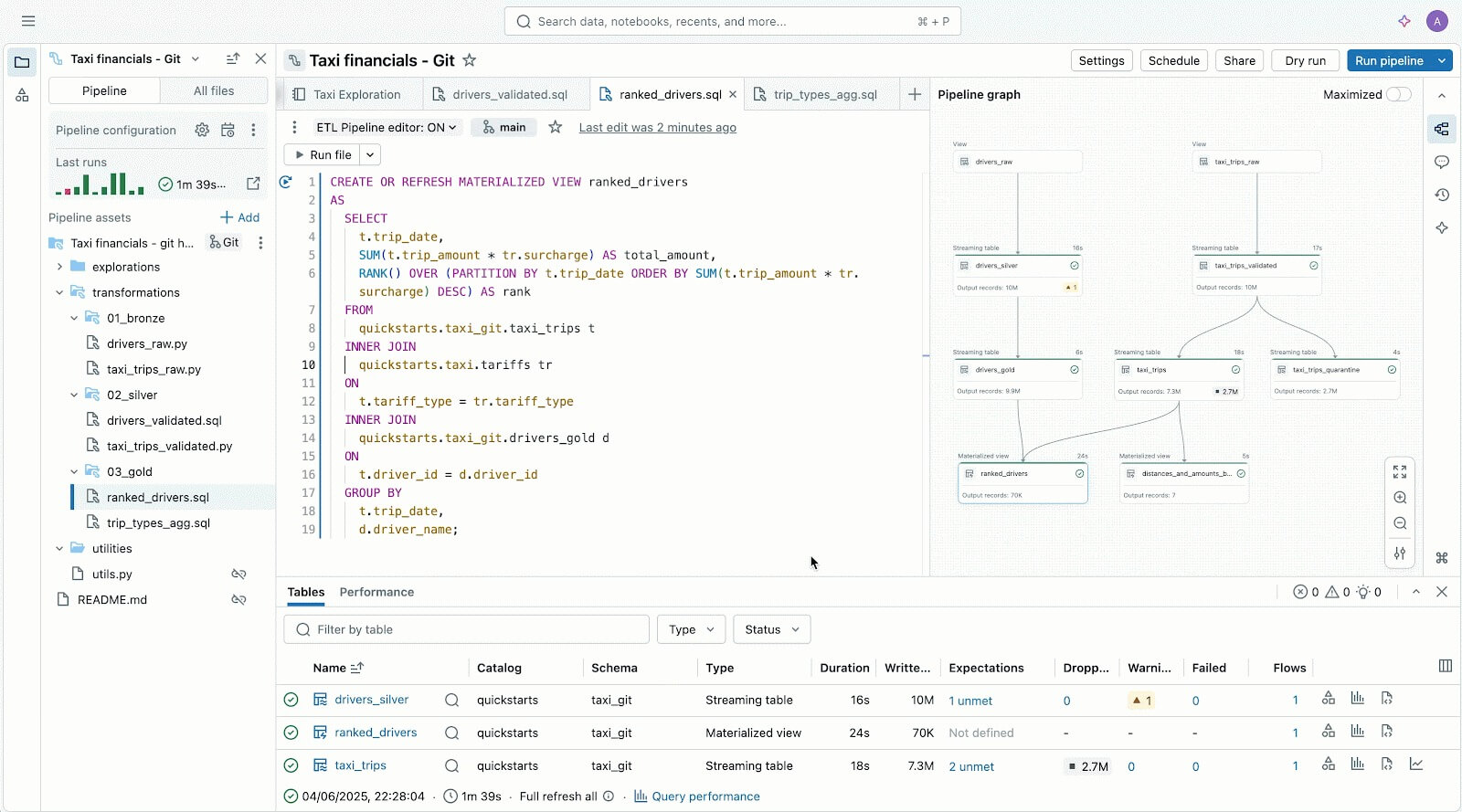
L'éditeur Lakeflow Pipelines pour vous aider à créer et à tester des pipelines de données, le tout au même endroit.
Pour les nouveaux venus et les utilisateurs professionnels, Lakeflow est très intuitif et facile à utiliser, avec une interface simple de type pointer-cliquer et une API pour l'ingestion de données via Lakeflow Connect.
Moins de conjectures, un dépannage plus précis grâce à l'observabilité native
Les solutions de monitoring sont souvent cloisonnées de votre plateforme de données, ce qui rend l'observabilité plus difficile à opérationnaliser et expose vos pipelines à un risque de panne plus élevé
Lakeflow Jobs sur Azure Databricks offre aux ingénieurs de données la visibilité approfondie de bout en bout dont ils ont besoin pour comprendre et résoudre rapidement les problèmes dans leurs pipelines. Grâce aux capacités d'observabilité de Lakeflow, vous pouvez immédiatement repérer les problèmes de performance, les goulots d'étranglement liés aux dépendances et les tâches qui ont échoué dans une interface utilisateur unique avec notre liste d'exécutions unifiée.
Les tables système de Lakeflow et le lignage des données intégré à Unity Catalog fournissent également un contexte complet sur les jeux de données, les espaces de travail, les requêtes et les impacts en aval, ce qui accélère l'analyse des causes profondes. Avec les tables système dans les tâches, récemment passées en disponibilité générale (GA), vous pouvez créer des tableaux de bord personnalisés pour tous vos Jobs et surveiller de manière centralisée leur état de santé.
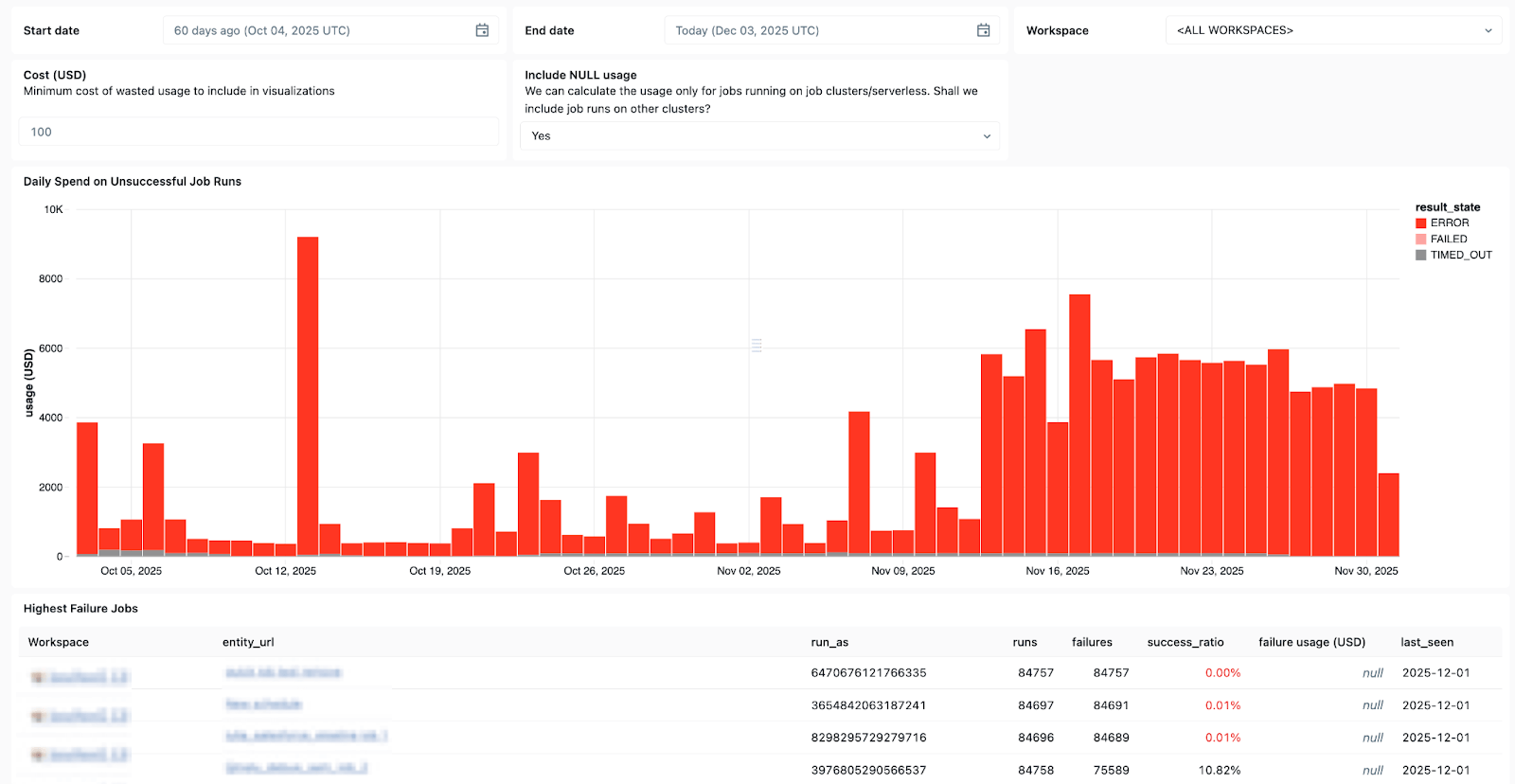
Utilisez les System Tables dans Lakeflow pour voir quels jobs échouent le plus souvent, les tendances générales des erreurs et les messages d'erreur courants.
Et lorsque des problèmes surviennent, Databricks Assistant est là pour vous aider.
Databricks Assistant est un copilote IA contextuel intégré à Azure Databricks qui vous aide à vous remettre plus rapidement des pannes en vous permettant de créer et de dépanner rapidement des notebooks, des requêtes SQL, des jobs et des tableaux de bord en langage naturel.
Mais l'Assistant ne se contente pas de debugging. Il peut également générer du code PySpark/SQL et l'expliquer avec des fonctionnalités basées sur Unity Catalog, afin qu'il comprenne votre contexte. Il peut également être utilisé pour exécuter des suggestions, faire émerger des modèles et effectuer la découverte des données et l'EDA, ce qui en fait un excellent compagnon pour tous vos besoins en Data Engineering.
Vos coûts et votre consommation sous contrôle
Plus vos pipelines sont volumineux, plus il est difficile de dimensionner correctement l'utilisation des ressources et de maîtriser les coûts.
Avec le traitement des données sans serveur de Lakeflow, le compute est optimisé automatiquement et en continu par Databricks pour minimiser le gaspillage de ressources inactives et l'utilisation des ressources. Les data engineers peuvent décider d'exécuter le mode serverless en mode Performance pour les charges de travail critiques, ou en mode Standard, où le coût est plus important, pour plus de flexibilité.
Lakeflow Jobs permet également la réutilisation des clusters, de sorte que plusieurs tâches d'un workflow peuvent s'exécuter sur le même cluster Job, éliminant ainsi les délais de démarrage à froid, et prend en charge un contrôle précis, de sorte que chaque tâche peut cibler soit le cluster Job réutilisable, soit son propre cluster dédié. Associée au serverless compute, la réutilisation des clusters minimise les lancements, ce qui permet aux data engineers de réduire les frais opérationnels et de mieux maîtriser les coûts liés à leurs données.
Microsoft Azure + Databricks Lakeflow : une combinaison gagnante éprouvée
Databricks Lakeflow permet aux équipes de données d'avancer plus rapidement et de manière plus fiable, sans compromettre la gouvernance, la scalabilité ou les performances. Avec le data engineering parfaitement intégré à Azure Databricks, les équipes peuvent bénéficier d'une plateforme unique de bout en bout qui répond à tous les besoins en matière de données et d'IA à grande échelle.
Les clients sur Azure ont déjà constaté des résultats positifs en intégrant Lakeflow dans leur pile technologique, notamment :
- Développement de pipelines plus rapide : Les équipes peuvent créer et déployer des pipelines de données prêts pour la production jusqu'à 25 fois plus rapidement, et réduire le temps de création de 70 %.
- Performances et fiabilité accrues : Certains clients constatent une amélioration des performances de 90x et une réduction des temps de traitement de plusieurs heures à quelques minutes.
- Plus d'efficacité et d'économies de coûts : l'automatisation et le traitement optimisé réduisent considérablement les frais opérationnels. Les clients ont déclaré avoir réalisé des économies pouvant atteindre des dizaines de millions de dollars par an et une réduction des coûts ETL allant jusqu'à 83 %.
Lisez les témoignages de réussite de clients Azure et Lakeflow sur notre blog Databricks.
Curieux d'en savoir plus sur Lakeflow ? Essayez Databricks gratuitement pour découvrir tout ce que la plateforme de data engineering a à offrir.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.