Plateforme ouverte, pipelines unifiés : pourquoi dbt sur Databricks accélère
Exécutez dbt sur un lakehouse ouvert et unifié avec une gouvernance intégrée et de solides performances à un prix avantageux
par Srilekha Dornadula et Ramiz Bozai
- Les fondations ouvertes empêchent le verrouillage propriétaire. Créez des flux de travail dbt avec des formats de table ouverts et la gouvernance ouverte du catalogue Unity.
- Une plateforme unifiée élimine la prolifération des outils. Exécutez dbt aux côtés de l'ingestion et de la BI en un seul endroit avec une gouvernance et une orchestration intégrées.
- Obtenez de solides performances/prix avec un réglage minimal et une surcharge opérationnelle réduite.
dbt apporte une structure aux flux de transformation de données. Les équipes l'utilisent pour transformer des données brutes en jeux de données organisés qui alimentent les consommations en aval telles que les tableaux de bord de BI, les modèles d'IA/ML et les rapports interfonctionnels.
Mais voici la réalité : dbt n'est aussi puissant que la plateforme de données sur laquelle il s'exécute.
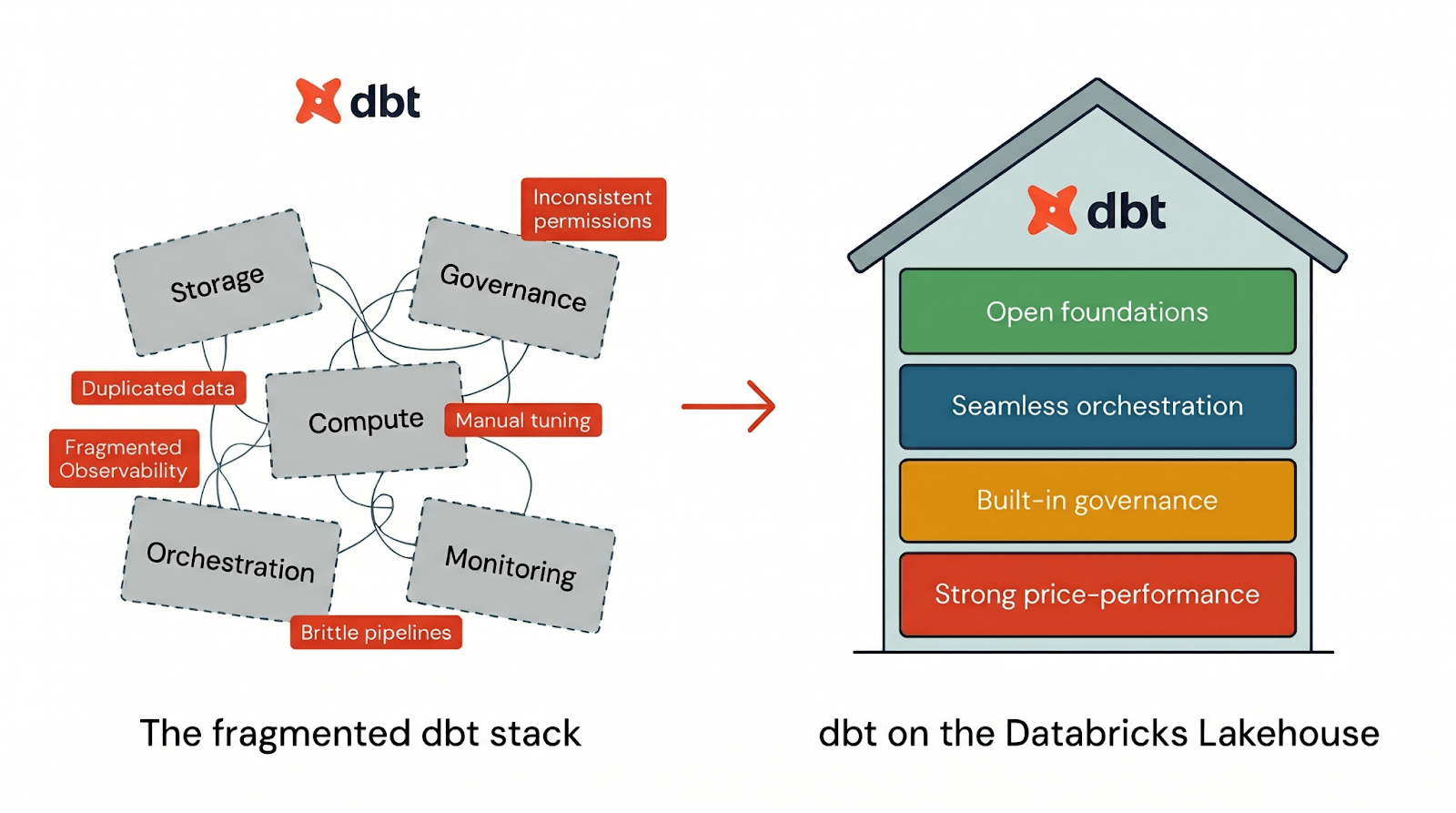
La plupart des architectures de données vous obligent à assembler le stockage, le calcul, la gouvernance, l'orchestration et la surveillance sur plusieurs systèmes. Le résultat ? Des données dupliquées, des autorisations incohérentes, une observabilité fragmentée et une optimisation des performances qui devient un travail à temps partiel. C'est pourquoi un nombre croissant d'équipes consolident leurs flux dbt sur Databricks.
Pour exécuter dbt efficacement, une plateforme a besoin de quatre choses :
- Des fondations ouvertes afin que vos flux dbt ne soient pas verrouillés dans une architecture propriétaire
- Une orchestration transparente pour exécuter les pipelines dbt de bout en bout en un seul endroit
- Une gouvernance intégrée qui fait partie du flux de travail dbt par défaut
- Une forte performance par rapport au coût afin que dbt s'exécute rapidement dès le premier jour sans réglage manuel
Databricks fournit ces quatre piliers intégrés nativement dans une seule plateforme. Lorsque vous exécutez dbt sur Databricks, vous bénéficiez de l'expérience développeur dbt sur une architecture lakehouse conçue pour l'ouverture, la gouvernance, la performance et la simplicité opérationnelle dès le premier jour. Examinons comment chacun de ces éléments fonctionne en pratique :
L'exécution de dbt sur Databricks nous a permis de consolider un héritage tentaculaire de notebooks et plus de 7 systèmes sources en une seule plateforme de données gouvernée. Avec Unity Catalog, nous gérons 341 locataires, plusieurs environnements et le partage de données avec des partenaires externes grâce à l'isolation au niveau du catalogue. Notre documentation dbt s'écoule directement dans UC, permettant aux analystes de s'auto-servir sans goulots d'étranglement. En publiant dans des formats ouverts et Delta Sharing, les partenaires et les équipes en aval peuvent facilement consommer les jeux de données générés par dbt sur différents outils et environnements. C'est une plateforme pour construire, mais une plateforme ouverte pour consommer. —Sohan Chatterjee, Head of Data and Analytics, iSolved
Exécutez dbt sur des fondations ouvertes sans verrouillage propriétaire
Le verrouillage propriétaire est l'un des risques stratégiques les plus importants pour la stratégie de données d'une organisation. dbt est construit avec un framework d'adaptateurs ouverts, ce qui signifie que votre logique de transformation n'est pas verrouillée sur une seule plateforme. dbt est ouvert par conception, et Databricks fournit une plateforme ouverte pour l'exécuter. De nombreuses architectures de données modernes sont centrées sur une couche de stockage propriétaire qui offre une commodité à court terme mais introduit des frictions à long terme. Au fil du temps, cela entraîne des données dupliquées et des pipelines d'exportation pour servir différents consommateurs, des formats de stockage qui limitent l'interopérabilité et des coûts de changement croissants à mesure que les exigences de la plateforme évoluent.
Databricks est un lakehouse ouvert : une plateforme unifiée où vos données résident dans des formats de table ouverts et sont accessibles via des interfaces ouvertes, garantissant que le stockage et la gouvernance ne sont pas liés à un seul moteur de requête. Sur Databricks, les modèles dbt deviennent des tables dans des formats ouverts, Delta Lake et Apache Iceberg, garantissant que vos données transformées restent accessibles sur l'ensemble du paysage de données sans exportation ni maintenance de copies parallèles. Cette ouverture est particulièrement importante pour les flux dbt. Vos tables silver et gold soigneusement modélisées deviennent des produits de données réutilisables que les utilisateurs en aval peuvent consommer via n'importe quel moteur de requête, pas seulement via la plateforme où s'exécute dbt.
Cette ouverture s'étend au-delà du stockage. Unity Catalog est construit autour de normes ouvertes de catalogue et d'accès qui prennent en charge les lectures et écritures gouvernées à partir de moteurs externes. Databricks SQL suit les normes ANSI, garantissant que vos requêtes restent portables sur différentes plateformes pour réduire les réécritures spécifiques au fournisseur. Cela signifie que vos flux dbt s'exécutent sur une architecture conçue pour la portabilité, pas pour le verrouillage.
Orchestrez les pipelines dbt de bout en bout avec Lakeflow Jobs
L'orchestration est là où la complexité opérationnelle s'accumule. Associer dbt à un orchestrateur externe en plus de Databricks signifie deux systèmes à exploiter, deux endroits pour déboguer, et des transferts fragiles entre eux.
Lakeflow Jobs élimine cette complexité en traitant dbt comme un type de tâche de première classe au sein d'un pipeline unifié. Au lieu de maintenir une couche d'orchestration séparée, les équipes exécutent dbt aux côtés de l'ingestion en amont et des actions en aval dans un seul flux de travail. Par exemple, vous pouvez ingérer des données brutes avec Auto Loader, transformer les données avec des modèles dbt, puis déclencher des actualisations de tableaux de bord ou un réentraînement de modèles ML, le tout dans un seul pipeline avec une logique de nouvelle tentative et une gestion des dépendances unifiées. dbt sur Databricks permet également l'ingestion directe via les tables de streaming. Pour les utilisateurs de dbt Platform, la tâche dbt Platform (en version bêta) permet à Lakeflow de déclencher et de gérer les flux dbt s'exécutant dans dbt Platform.
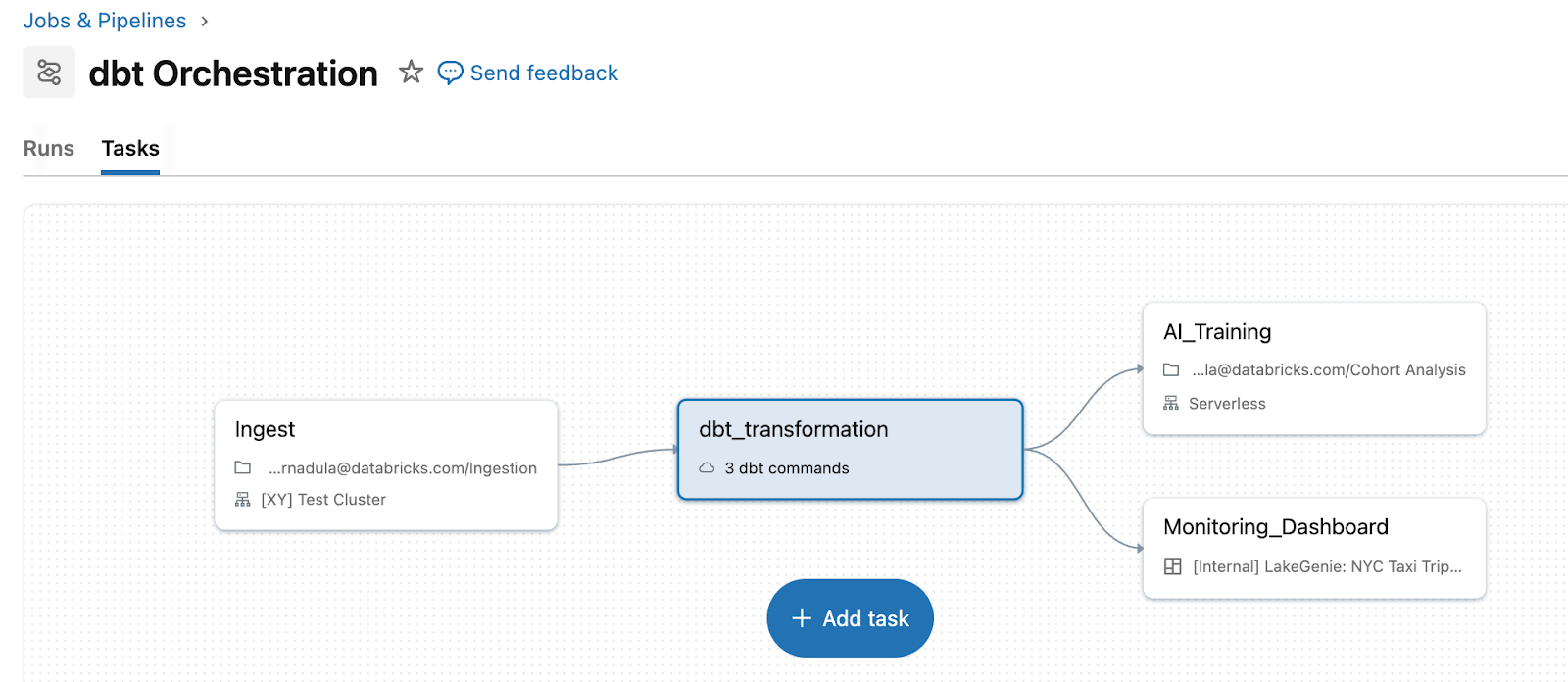
Lorsque dbt est orchestré via Lakeflow, les échecs, les nouvelles tentatives et le contexte sont visibles en un seul endroit. Au lieu de basculer entre un orchestrateur dbt séparé et les journaux Databricks, vous pouvez voir l'échec, les tâches en aval affectées et les tableaux de bord impactés directement dans la même vue d'exécution du travail.
Faites de la gouvernance une partie intégrante du flux de travail dbt
À mesure que les flux dbt évoluent, la gouvernance devient le goulot d'étranglement. Les équipes ont besoin de réponses claires sur le contenu des tables, la propriété et les autorisations d'accès. Dans les architectures traditionnelles, ce contexte est fragmenté entre des outils de catalogue séparés, des systèmes d'autorisation et des vues de lignage incomplètes qui ne se connectent pas de bout en bout.
Databricks résout ce problème avec Unity Catalog, qui unifie le contrôle d'accès, la découverte et le lignage pour l'ensemble de votre lakehouse – pas seulement au sein de dbt, mais aussi pour l'ingestion, la BI, le ML/IA, et au-delà. Avec Unity Catalog, vous n'avez pas besoin de réexécuter les instructions d'octroi chaque fois que dbt recrée une table. Les autorisations sont gérées au niveau du schéma et persistent après les reconstructions de tables. Des contrôles granulaires tels que les filtres au niveau des lignes, les masques de colonnes et le contrôle d'accès basé sur les attributs s'appliquent de manière cohérente à travers dbt, les outils de BI et les notebooks.
Par exemple, lorsque vous persistez la documentation dbt dans Unity Catalog en utilisant la fonctionnalité persist_docs de dbt, les descriptions de colonnes et le contexte rédigés dans dbt deviennent découvrables là où les données sont interrogées et consommées. Unity Catalog fournit un lignage de données au niveau des colonnes qui retrace le flux de données depuis l'ingestion brute jusqu'à l'utilisation en aval, en passant par les transformations dbt. Lorsqu'un schéma source change, vous pouvez instantanément voir quels modèles dbt et quels actifs en aval sont affectés. Ce niveau de visibilité est impossible lorsque les pipelines de données couvrent des systèmes déconnectés.
La gouvernance des coûts est aussi importante que la gouvernance des données. Avec les étiquettes de requête, vous pouvez associer un contexte métier aux exécutions dbt et suivre les dépenses par équipe, projet ou environnement via les Tables Système. Les équipes peuvent enfin répondre à la question « combien coûtent nos pipelines dbt d'analyse marketing ? » avec des données réelles au lieu d'estimations. De plus, la surveillance des coûts granulaires de DBSQL (en aperçu privé) fournit également une surveillance des coûts agrégée sur toutes les charges de travail dbt.
Exécutez dbt avec de solides performances à un coût avantageux dès le premier jour
L'optimisation d'un entrepôt de données pour les performances nécessite généralement un travail manuel continu. Les équipes finissent souvent par sacrifier la vélocité des développeurs pour une bonne hygiène de performance.
Databricks abstrait cette complexité en combinant un moteur d'exécution haute performance avec des fonctionnalités qui fonctionnent nativement avec dbt, offrant des améliorations de vitesse sans surcharge manuelle.
Performances intégrées
- Photon, le moteur, accélère les charges de travail SQL grâce à l'exécution vectorisée, offrant des performances jusqu'à 12 fois meilleures en termes de rapport prix/performance par rapport aux entrepôts de données cloud. Les entrepôts SQL Serverless incluent Photon par défaut, ainsi les équipes bénéficient de performances accélérées sans coût supplémentaire.
- L'Optimisation Prédictive utilise l'IA pour surveiller les tables et automatiser la maintenance, atteignant des requêtes jusqu'à 20 fois plus rapides. Cela réduit le besoin de `OPTIMIZE` post-hooks manuels sur lesquels les ingénieurs dbt s'appuyaient historiquement.
Fonctionnalités de performance débloquées via la configuration dbt
- L'intégration de dbt avec le Clustering Liquide remplace les stratégies de partitionnement rigides par une approche flexible qui s'ajuste dynamiquement à mesure que le volume de données augmente, résultant en des vitesses jusqu'à 10 fois plus rapides sans réglage manuel
- Les Vues Matérialisées dans dbt, alimentées par les Pipelines Déclaratifs Spark open-source, gèrent le traitement incrémental automatiquement. Databricks gère la complexité de déterminer ce qui doit être mis à jour et ne traite que les enregistrements nouveaux ou modifiés, plutôt que de recalculer des jeux de données entiers. Cela permet de réduire les coûts de calcul par rapport aux actualisations par lots planifiées inefficaces.
Avec ces fonctionnalités, les utilisateurs passent moins de temps à optimiser et plus de temps à construire des pipelines qui restent performants à mesure que les jeux de données augmentent. Rien qu'en 2025, Databricks SQL a atteint une amélioration des performances de 10 % sur les charges de travail ETL (requêtes avec écritures) sans nécessiter de configurations supplémentaires.
Commencez dès aujourd'hui
Databricks rassemble le stockage ouvert, la gouvernance unifiée, de solides performances à un coût avantageux et des opérations intégrées en un seul endroit pour les flux de travail dbt. Rejoignez les plus de 2900 clients qui exécutent déjà dbt sur Databricks. Commencez en suivant le guide de démarrage rapide.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.