Du savoir tribal aux réponses instantanées : la création de Reffy sur Databricks
par Rafi Kurlansik, Gavin Edgley et Sara Steffen
- Pourquoi trouver la bonne référence client au bon moment représentait un défi permanent pour les équipes Ventes et Marketing de Databricks.
- Comment nous avons créé Reffy, une application agentique full-stack utilisant RAG, AI Search, AI Functions et Lakebase, pour rendre plus de 2 400 témoignages clients instantanément consultables.
- Depuis son lancement en décembre 2025, plus de 1 800 employés de Databricks ont exécuté plus de 7 500 requêtes sur Reffy.
Trouver le bon témoignage client au bon moment s'avère étonnamment plus difficile que cela ne le devrait. Pour améliorer la productivité des employés, nous avons créé Reffy, une application qui permet aux utilisateurs de découvrir et d'analyser plus de 2 400 références client Databricks, en fournissant des réponses personnalisées, des analyses croisées, des citations, et plus encore. Au cours de ses deux premiers mois, plus de 1 800 personnes des équipes Ventes et Marketing de Databricks ont exécuté plus de 7 500 requêtes sur Reffy. Cela se traduit par un storytelling plus pertinent et cohérent, une exécution plus rapide des campagnes et l'assurance que les preuves client sont utilisées à grande échelle. En rendant ces témoignages faciles à trouver et à assimiler, nous avons résolu le problème du savoir tribal qui entoure les références client et avons valorisé le travail précieux des nombreuses personnes qui les ont collectées au fil des ans.
Dans cet article, nous aborderons la raison d'être de Reffy, la solution complète de Databricks, son impact sur notre organisation et la manière dont nous prévoyons de la monter en charge encore plus en interne.
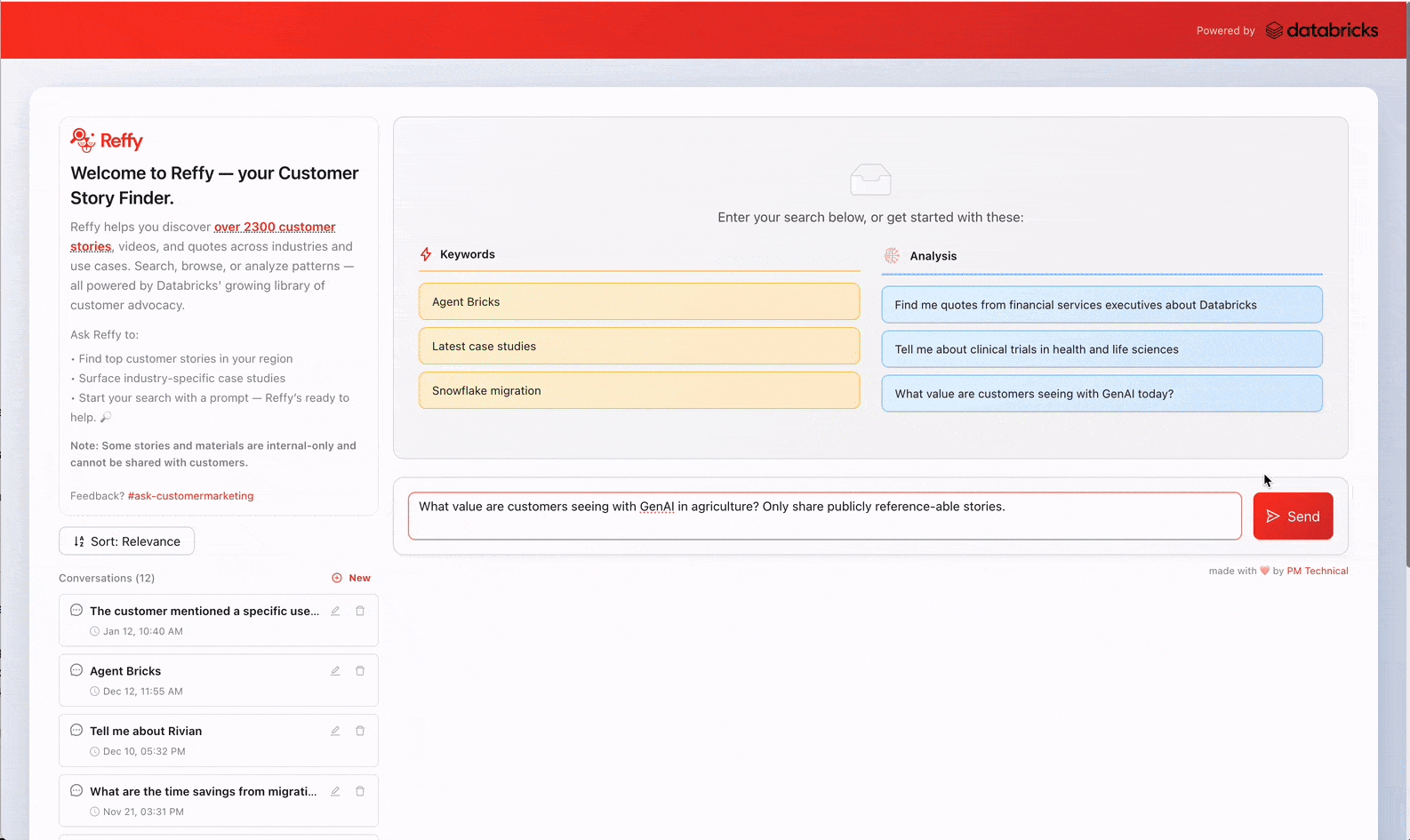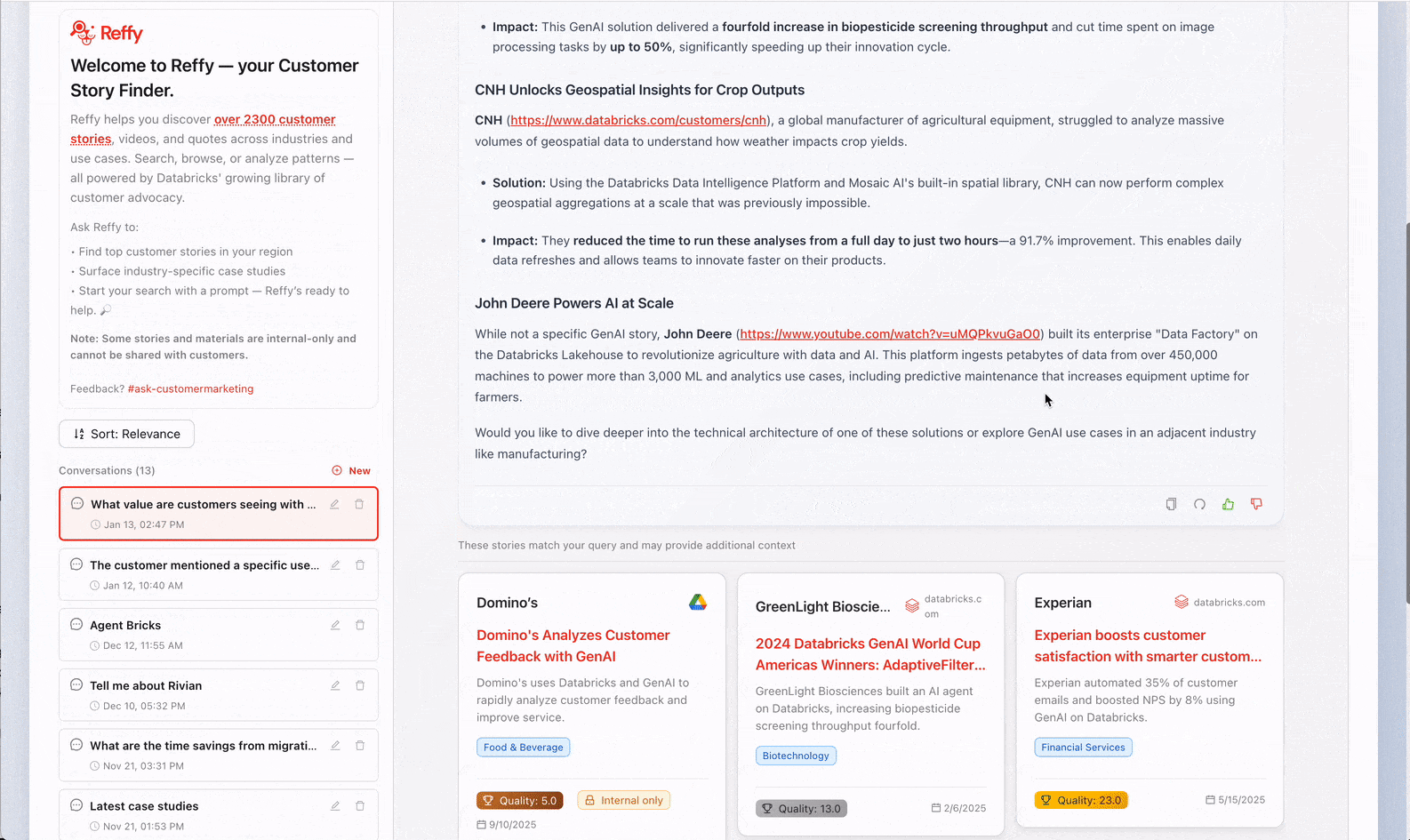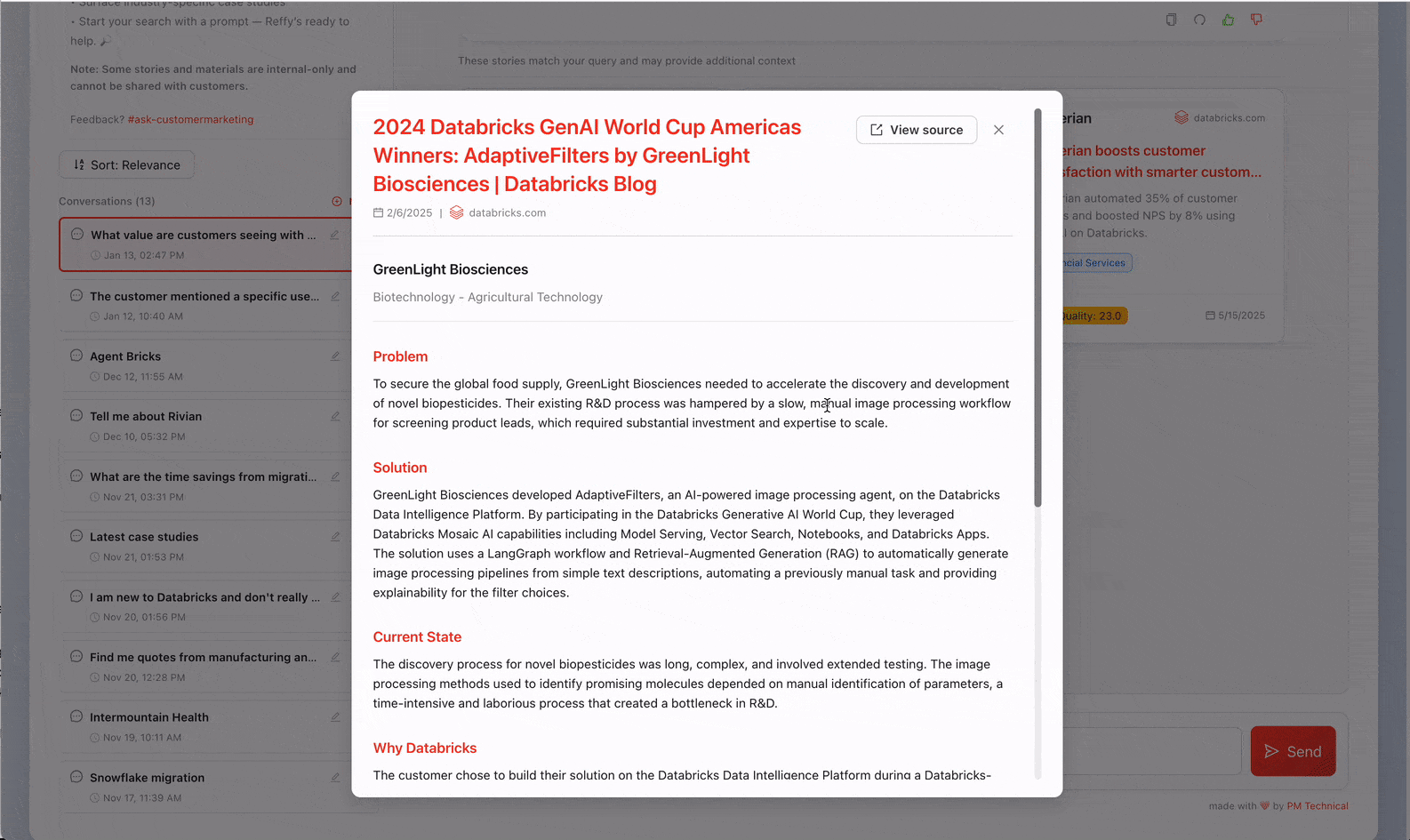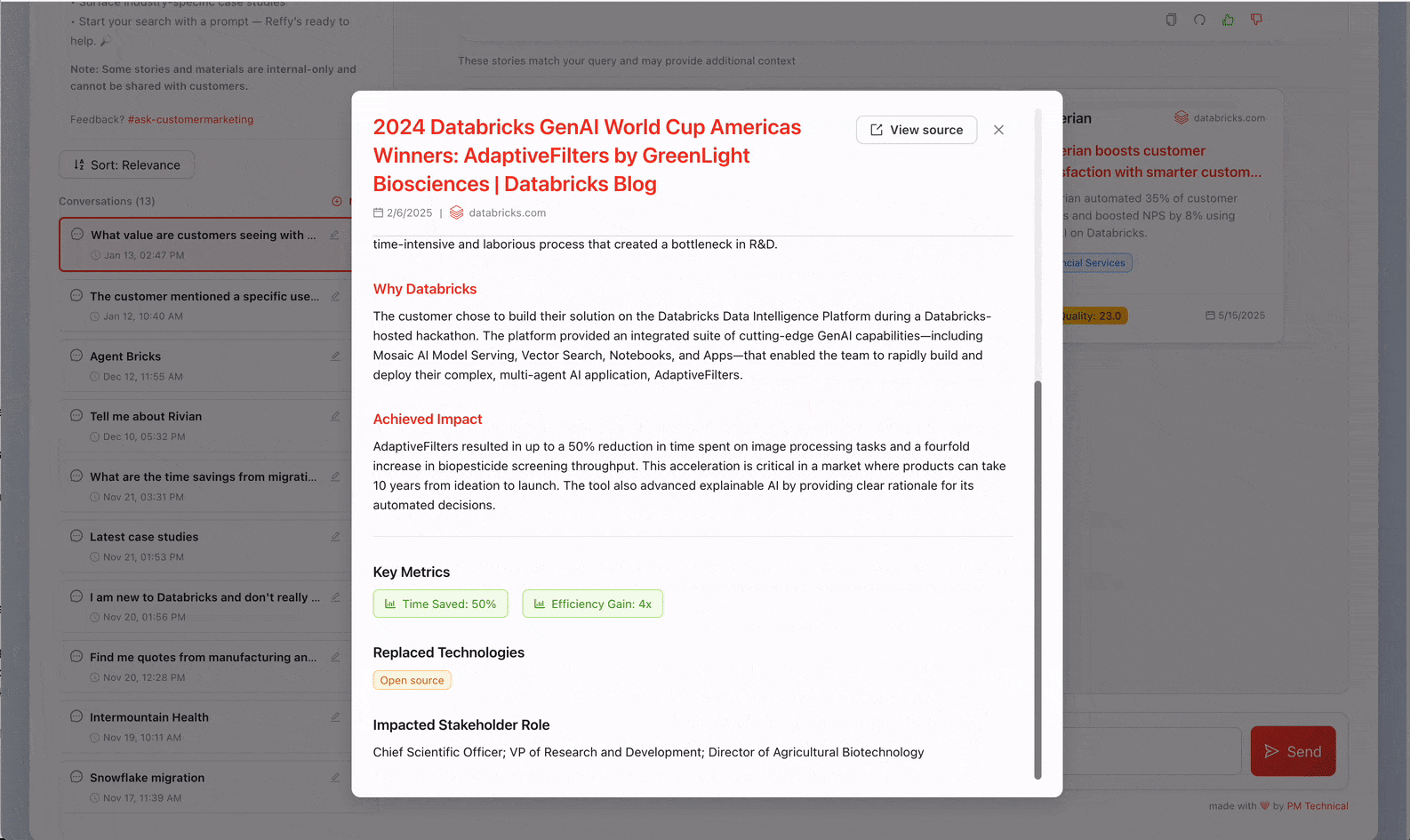
Le défi de la démocratisation des connaissances tribales
« Qui d'autre a fait ça ? » est une question que tous les vendeurs entendent. Un prospect est intrigué par votre pitch, mais avant d'aller de l'avant, il veut une preuve : un client comme lui qui a déjà emprunté cette voie. Il devrait être facile d'y répondre.
Pour notre équipe marketing, les témoignages clients sont un élément essentiel de presque toutes nos actions : campagnes, lancements de produits, publicité, relations publiques, briefings d'analystes et communications de dirigeants. Lorsque ces témoignages ne sont pas faciles à trouver ou à évaluer, de réels problèmes s'aggravent : les références de grande valeur sont surexploitées, les nouveaux cas d'usage ou secteurs d'activité sont manqués, et l'efficacité du marketing est limitée par les connaissances tribales.
Databricks propose des milliers de présentations YouTube, d'études de cas sur databricks.com, des présentations internes, des articles LinkedIn, des publications Medium. Quelque part là-dedans se trouve la référence parfaite : une entreprise de services financiers au Canada qui fait de la détection de fraude en temps réel, un détaillant qui a remplacé un legacy data warehouse, un fabricant qui déploie la GenAI à grande échelle. Mais pour les trouver ? C'est là que les choses se compliquent. Les témoignages sont répartis sur une douzaine de plateformes sans recherche unifiée, et lorsque vous trouvez quelque chose, vous ne pouvez pas immédiatement dire s'il est solide : a-t-il des résultats commerciaux crédibles ou seulement des affirmations vagues ?
Les gens ont donc les réflexes habituels : ils envoient un message à l'équipe marketing sur Slack, fouillent dans des dossiers dont ils se souviennent à moitié, ou demandent autour d'eux jusqu'à ce que quelqu'un déniche quelque chose d'utilisable. Parfois, ils trouvent de l'or. Le plus souvent, ils se contentent d'une solution « acceptable » ou abandonnent complètement, sans jamais savoir si le témoignage parfait était à leur portée depuis le début.
De toute évidence, il nous fallait un meilleur moyen pour que les Ventes et Marketing découvrent les témoignages clients les plus pertinents.
Reffy : une solution full-stack sur Databricks
Pour résoudre ce problème, nous regroupons tous les témoignages dans une table unique, les catégorisons, puis utilisons un agent basé sur RAG pour alimenter la recherche, le tout accessible via une application Databricks au design personnalisé. L'architecture s'étend sur toute la plateforme Databricks : Lakeflow Jobs orchestre nos pipelines ETL, Unity Catalog gère nos données, AI Search alimente l'extraction, Model Serving héberge notre agent, Lakebase gère les lectures et écritures en temps réel, et Databricks Apps fournit le frontend. Entrons dans les détails.
Sources de données & ETL
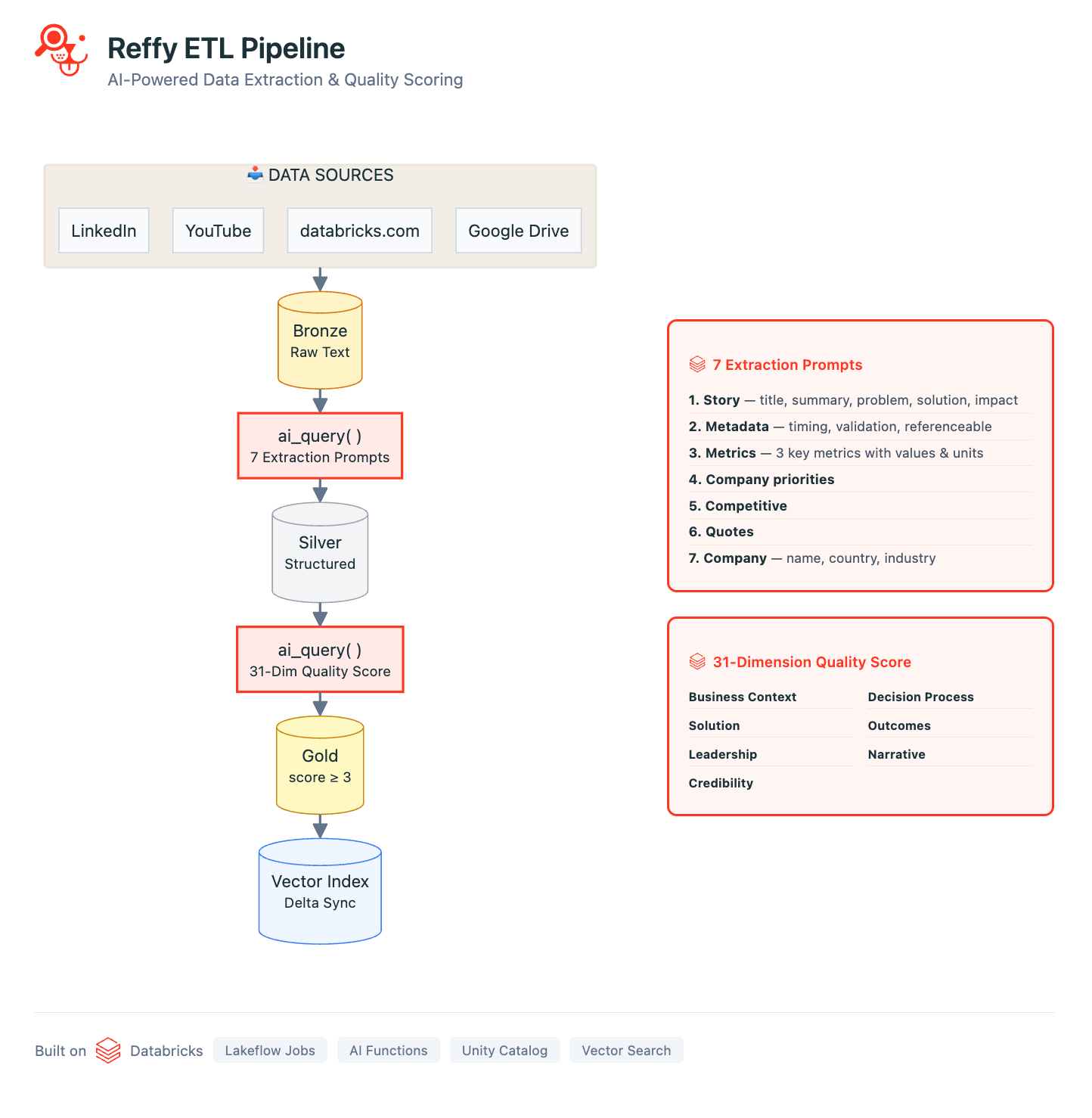
Notre pipeline est défini dans une série de Notebooks Databricks orchestrés avec Lakeflow Jobs. Le pipeline commence par la collecte du texte des témoignages provenant de toutes nos sources de données : nous utilisons des biblioth�èques de web scraping Python standard pour recueillir les transcriptions YouTube, les articles LinkedIn/Medium et tous les témoignages clients publics sur databricks.com. À l'aide de scripts Google Apps, nous consolidons également le texte de centaines de présentations et de documents Google internes dans une seule feuille de calcul Google Sheet. Toutes ces sources sont traitées avec des métadonnées de base et enregistrées dans une table Delta Lake « Bronze » dans Unity Catalog (UC).
Maintenant que tous nos témoignages sont réunis au même endroit, nous n'avons toujours aucun insight sur leur qualité. Pour y remédier, nous classifions le texte en appliquant un système de notation rigoureux sur 31 points (développé par notre équipe Value) à chaque récit via les AI Functions. Nous demandons à Gemini 2.5 de juger la qualité globale du récit en identifiant le défi commercial, la solution, la crédibilité du résultat et les raisons pour lesquelles Databricks était particulièrement bien placé pour apporter de la valeur. Évaluer les témoignages de cette manière nous permet également de filtrer ceux de moindre qualité dans Reffy. Le prompt extrait également des métadonnées clés telles que le pays et les secteurs d'activité, les produits utilisés, la concurrence et les citations, et attribue des balises aux témoignages selon qu'ils sont partageables publiquement ou réservés à un usage interne. Cet ensemble de données enrichi est enregistré dans une table « Silver » dans UC.
Les dernières étapes de l'ETL comprennent le filtrage des témoignages à faible score et la création d'une nouvelle colonne « summary » qui concatène les composants essentiels des témoignages. L'idée est simple : nous synchronisons cette table « Gold » avec un index Databricks AI Search, la colonne de résumé contenant toutes les information essentielles dont un LLM aurait besoin pour faire correspondre les témoignages clients aux queries.
IA agentique
En utilisant le framework DSPy, nous définissons un agent d'appel d'outils qui peut rechercher les références clients les plus pertinentes avec une recherche hybride par mots-clés et sémantique. Nous adorons DSPy ! Les agents créés avec sont faciles à tester de manière itérative dans un Notebook Databricks sans avoir à les redéployer sur un endpoint Model Serving à chaque fois, ce qui se traduit par un cycle de développement plus rapide. La syntaxe est très intuitive par rapport à d'autres frameworks populaires, et elle inclut d'excellents composants d'optimisation de prompt. Si ce n'est pas déjà fait, n'hésitez pas à découvrir DSPy.
Nous structurons notre agent de témoignages clients pour faciliter une recherche par mots-clés pure et ultra-rapide et une réponse LLM plus longue avec raisonnement en fonction de l'entrée de l'utilisateur : si vous posez une question, vous obtiendrez une réponse mûrement réfléchie avec des sources, mais si vous entrez simplement quelques mots-clés, Reffy renverra les meilleurs résultats en moins de deux secondes. Nous utilisons également le re-ranker Databricks pour AI Search afin d'améliorer les résultats de RAG.
Pour garantir une réponse équilibrée et professionnelle, nous utilisons l'invite système suivante :
L'agent est journalisé dans MLflow et déployé sur Databricks Model Serving à l'aide de notre Agent Framework. Étant donné que la majeure partie du traitement est effectuée du côté du fournisseur de modèles, nous pouvons nous contenter d'un déploiement sur une petite instance de CPU, ce qui permet de réduire les coûts d'infrastructure par rapport aux GPU.
L'application Databricks
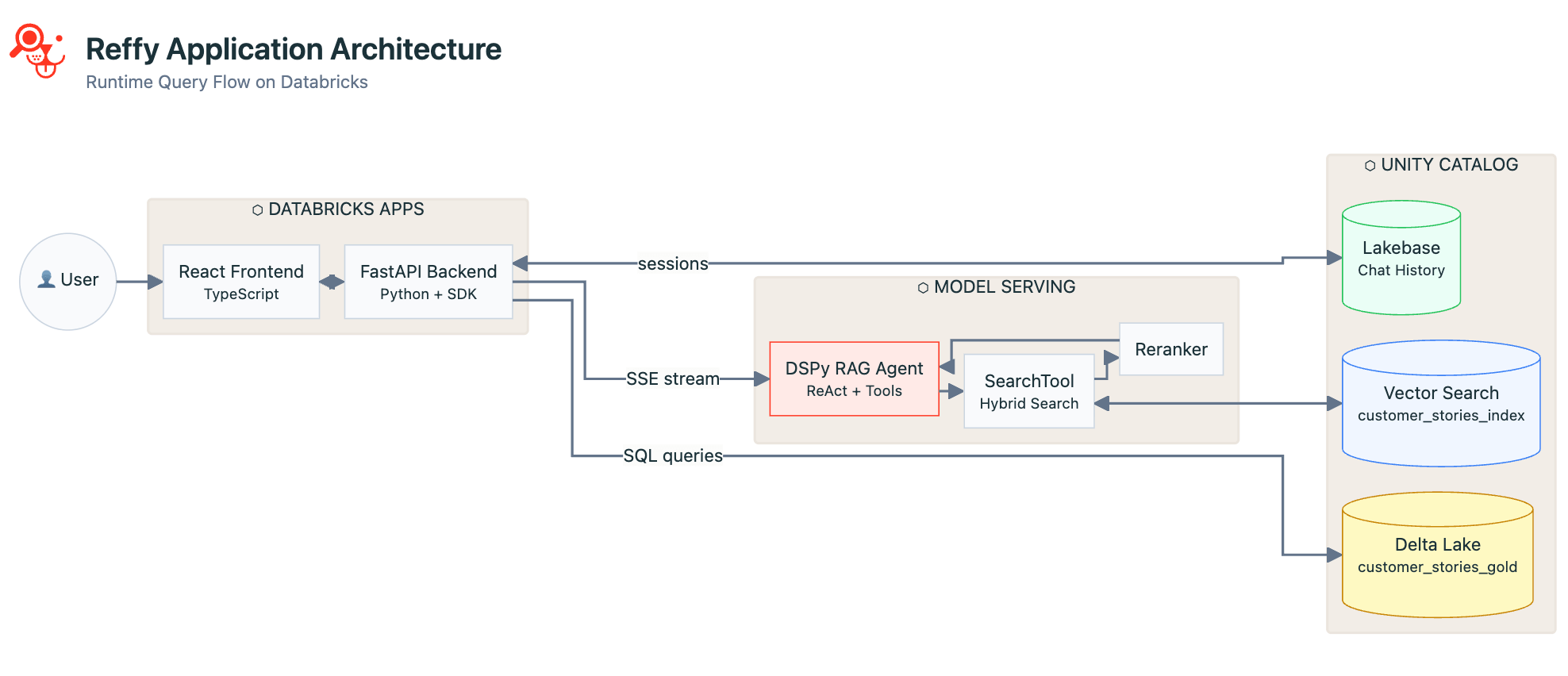
Maintenant que les données sont nettoyées et indexées et que l'agent fonctionne bien, il est temps de créer une application pour lier le tout et la rendre accessible aux utilisateurs non techniques. Nous avons choisi un frontend React avec un backend Python FastAPI. React est esthétique et réactif dans le navigateur et prend en charge la sortie en streaming depuis notre point de terminaison de service de modèle. FastAPI nous permet de tirer parti de tous les avantages du SDK Python de Databricks dans notre application, à savoir :
- Authentification unifiée — aucune modification de code lors de l'authentification locale pendant le développement par rapport au déploiement sur les applications Databricks. Les applications ont les mêmes variables d'environnement que l'authentification locale, de sorte que le code fonctionne de manière transparente.
- Couverture API étendue — nous pouvons appeler Model Serving, exécuter des requêtes SQL, ou tout ce dont nous pourrions avoir besoin depuis un Databricks Workspace, le tout via un seul SDK.
Reffy est principalement une application de chat, nous utilisons donc Lakebase pour conserver tout l'historique des conversations, les journaux et les identités des utilisateurs pour des lectures et des écritures rapides, l'assurance qualité et un suivi réfléchi lorsque les utilisateurs reviennent ou commencent de nouvelles conversations.
monitoring continu et métriques
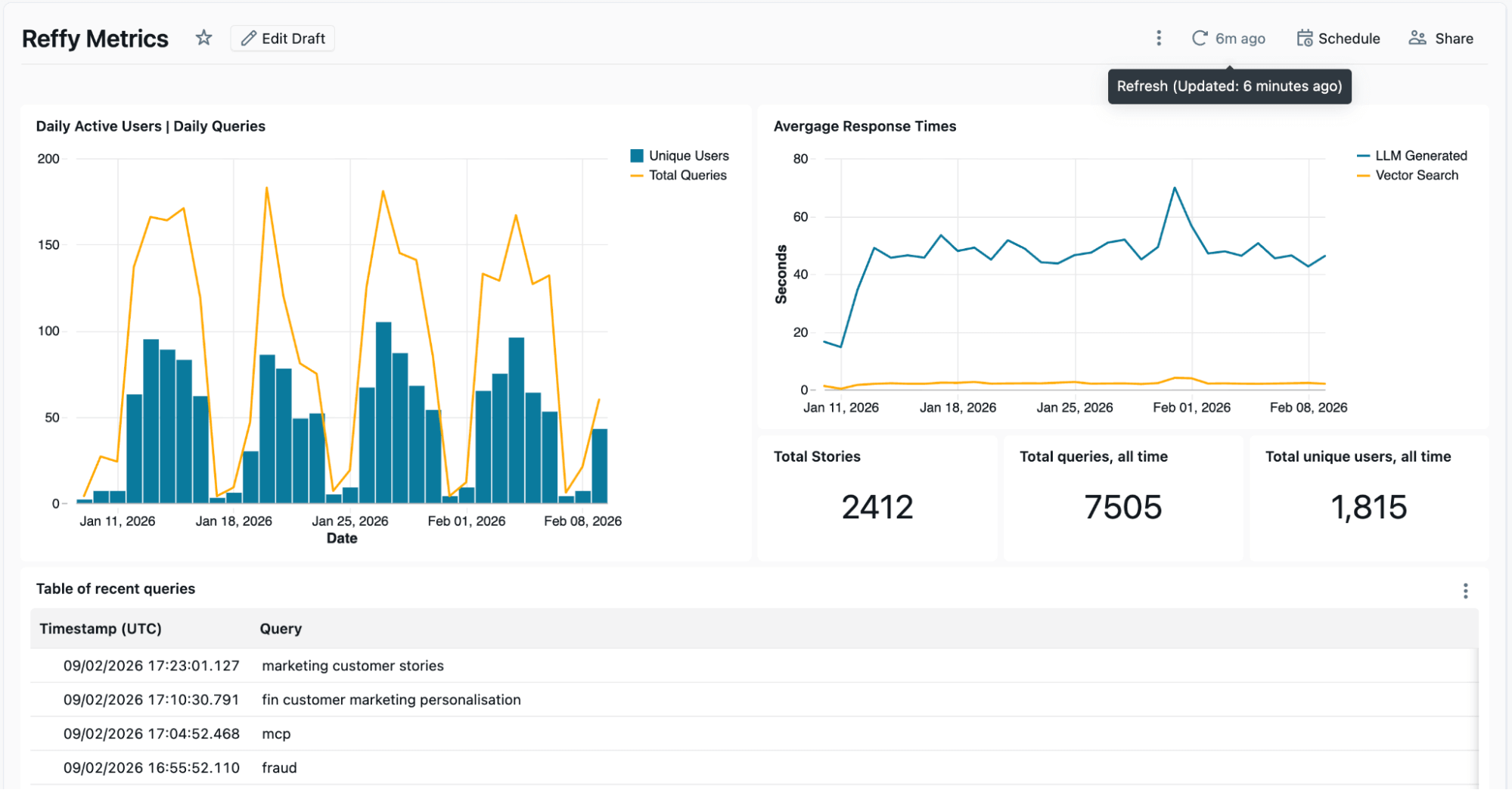
Les logs de Lakebase sont traités dans un Lakeflow Job distinct pour faire ressortir des métriques clés, telles que le nombre d'utilisateurs actifs quotidiens et les temps de réponse moyens, dans un tableau de bord IA/BI. Ce tableau de bord nous montre également les entrées et les réponses récentes, et nous allons plus loin en appliquant une autre fonction d'IA pour résumer ces dernières en thèmes récents et en analyse des écarts. Nous voulons comprendre quels témoignages client sont populaires et où nous pourrions avoir des lacunes, et les logs que nous collectons à partir de Reffy nous y aident. Par exemple, nous avons découvert que les utilisateurs cherchaient tout particulièrement des témoignages sur Agent Bricks et Lakebase, deux des produits les plus récents de Databricks.
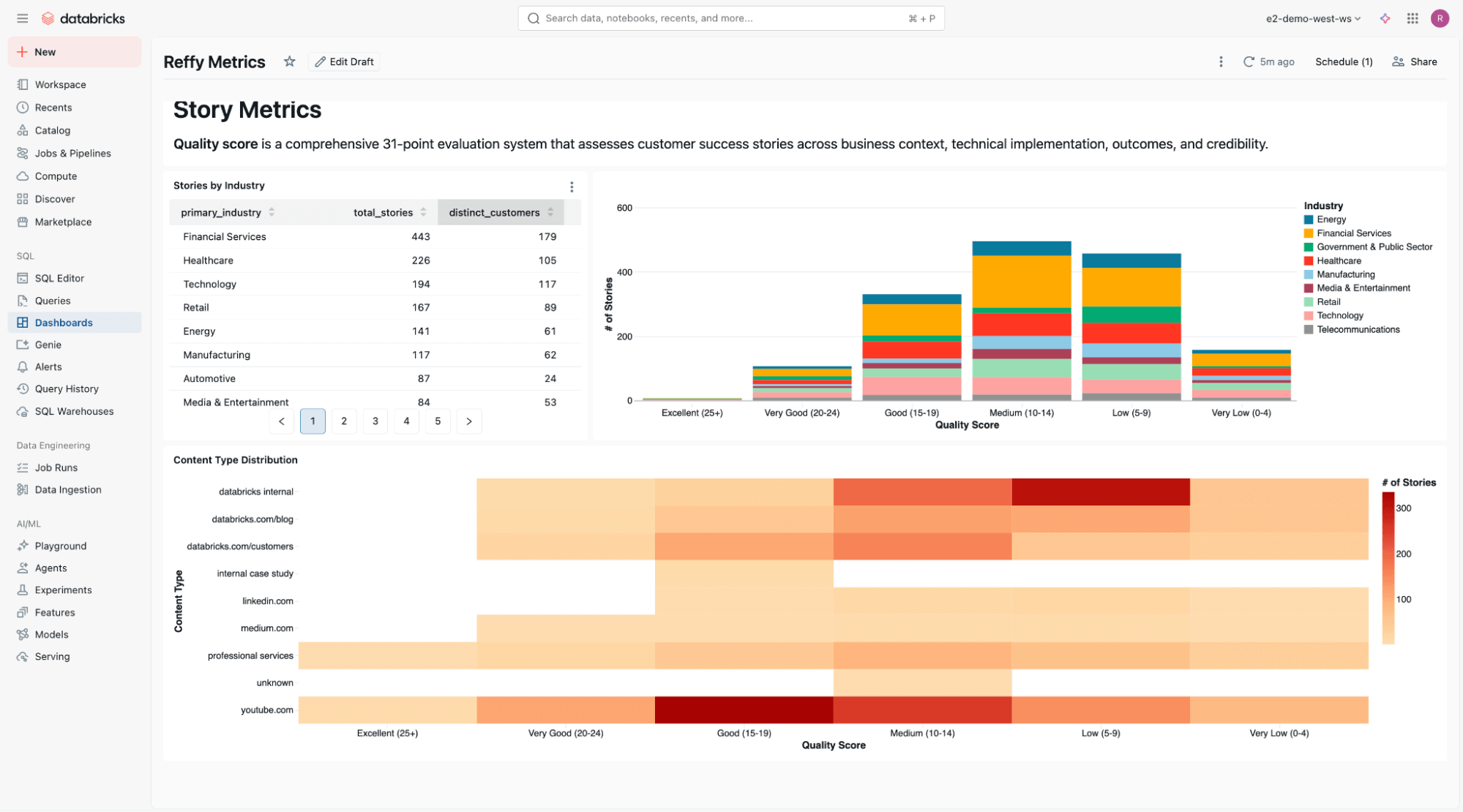
Au bas du tableau de bord, nous incluons une analyse statique de la qualité des témoignages par secteur d'activité et type de contenu.
Remarque sur la configuration du développement
La plupart du développement du projet se fait dans Cursor, et comme mentionné précédemment, l'authentification unifiée entre la CLI de Databricks et le SDK simplifie les choses. Nous nous connectons une seule fois via la CLI, et toutes nos builds locales de Reffy qui utilisent le SDK sont authentifiées. Lorsque nous voulons effectuer des tests dans Databricks Apps, nous utilisons la CLI pour synchroniser le code le plus récent avec notre Workspace, puis nous déployons l'application. Databricks Apps vérifie les mêmes variables d'environnement pour l'authentification que celles que nous avons définies localement, de sorte que nos appels à Model Serving et aux SQL Warehouses qui s'appuient sur le SDK fonctionnent tout simplement ! Notre boucle de développement itérative devient :
- Se connecter au Workspace via la CLI
- Écrire le code dans Cursor
- Tester en local
- Synchroniser le code avec le Workspace et déployer l'application
- Test dans Databricks Apps
Enfin, pour garantir un CI/CD et une portabilité corrects, nous utilisons Databricks Asset Bundles pour lier l'ensemble du code et des ressources utilisés par Reffy dans un seul package. Ce bundle est ensuite déployé via GitHub Actions dans notre Workspace de production cible.
Nos apprentissages
Plusieurs équipes au sein de Databricks avaient déjà résolu des parties de ce problème indépendamment, se tournant naturellement vers le travail le plus passionnant : la couche d'IA. Cependant, la Data Engineering reste au cœur du projet. La bonne mise en œuvre de l'ETL, la notation de la qualité des récits et la structuration des données pour une récupération efficace se sont avérés tout aussi essentiels que l'agent lui-même.
La collaboration était également essentielle. Les témoignages clients concernent presque tous les services de l'entreprise : les ventes, le marketing, l'ingénierie de terrain et PR jouent tous un rôle. L'établissement de partenariats solides avec ces groupes a façonné à la fois le produit et les données qui l'alimentent.
Et ensuite
Bien que le frontend de l'application apporte une valeur immédiate, la véritable puissance émergera de la connexion de Reffy à d'autres solutions au sein de Databricks. Nous prévoyons de fournir cette connectivité via une API et un serveur MCP, permettant aux équipes d'accéder à l'intelligence client directement depuis leurs workflows et outils existants.
Avec Databricks et Lakebase, nous pouvons également comprendre comment des milliers d'utilisateurs interagissent avec Reffy au fil du temps. Ces insights nous permettront d'affiner continuellement l'outil et de façonner judicieusement les récits ajoutés à cet écosystème en pleine croissance.
Pour les équipes de Databricks qui sont aujourd'hui confrontées à la recherche de références clients, Reffy offre un exemple concret de ce qu'il est possible de faire lorsque ces capacités sont réunies. Pour commencer à créer votre propre application agentique sur Databricks, apprenez-en davantage sur Databricks Apps, notre guide RAG, Lakebase et Agent Bricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.