Nouveautés : Zerobus et autres annonces améliorent l'ingestion de données pour Lakeflow Connect
Lakeflow Connect étend sa couverture de sources de données, et Zerobus introduit une API d'écriture directe à haut débit avec une faible latence
par Elise Georis, Peter Pogorski, Victoria Bukta et Giselle Goicochea
- Lakeflow Connect élargit la gamme de sources d'ingestion de données, y compris de nouveaux connecteurs basés sur des requêtes pour les bases de données.
- Zerobus est une API d'écriture directe qui simplifie l'ingestion pour l'IoT, le clickstream, la télémétrie et d'autres cas d'utilisation similaires.
- Lakeflow Connect dans Jobs offre une intégration transparente et intuitive entre les deux outils, aidant les utilisateurs à gagner du temps grâce à une expérience unifiée de bout en bout.
Tout commence par de bonnes données, l'ingestion est donc souvent votre première étape pour découvrir des informations. Cependant, l'ingestion présente des défis, comme la montée en compétence sur les complexités de chaque source de données, le suivi de ces sources lorsqu'elles changent, et la gouvernance de tout cela en cours de route.
Lakeflow Connect facilite une ingestion de données efficace, avec une interface utilisateur en pointer-cliquer, une API simple et des intégrations approfondies avec la Data Intelligence Platform. L'année dernière, plus de 2 000 clients ont utilisé Lakeflow Connect pour extraire de la valeur de leurs données.
Dans ce blog, nous passerons en revue les bases de Lakeflow Connect et récapitulerons les dernières annonces du Data + AI Summit 2025.
Ingérez toutes vos données en un seul endroit avec Lakeflow Connect
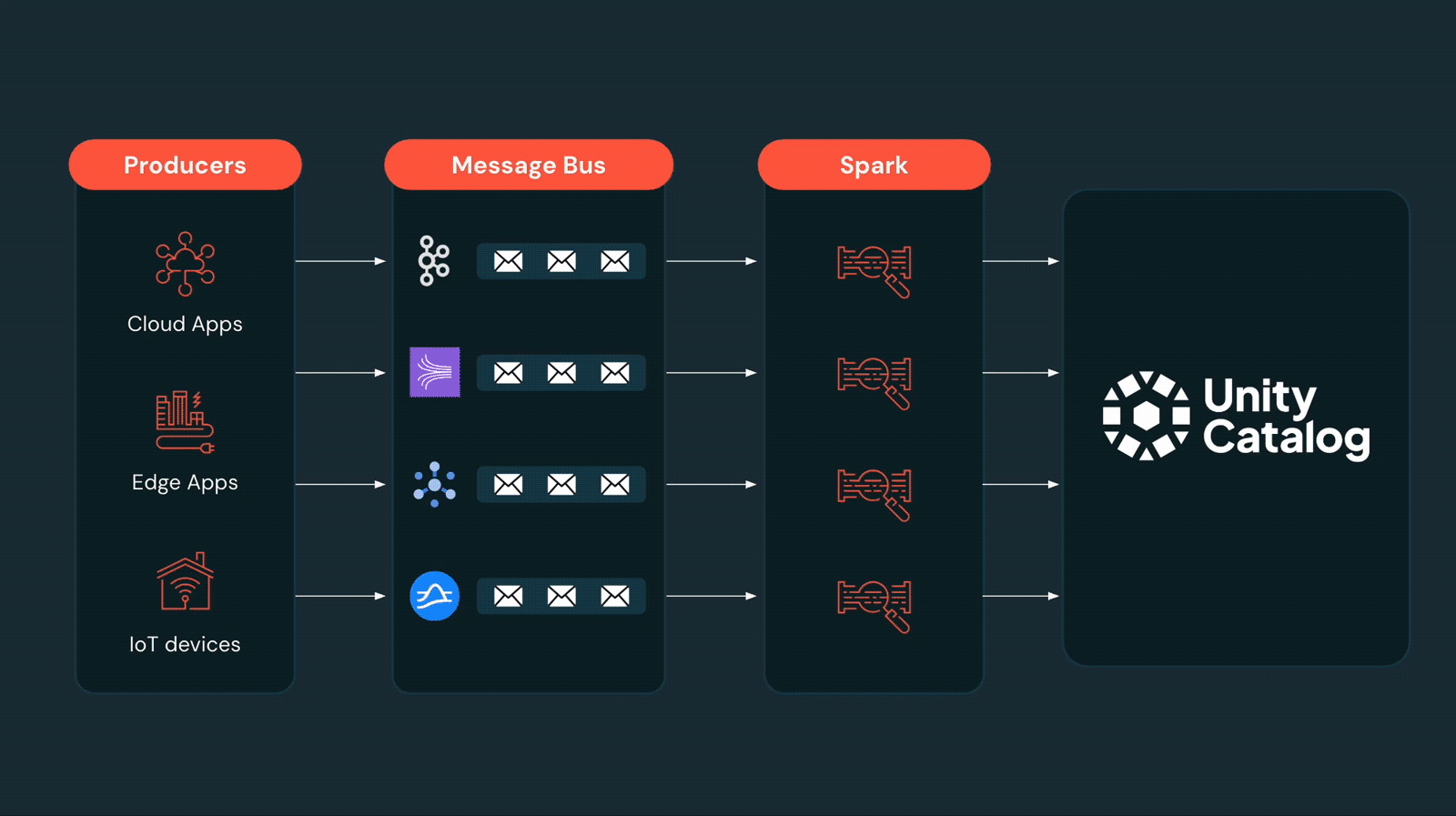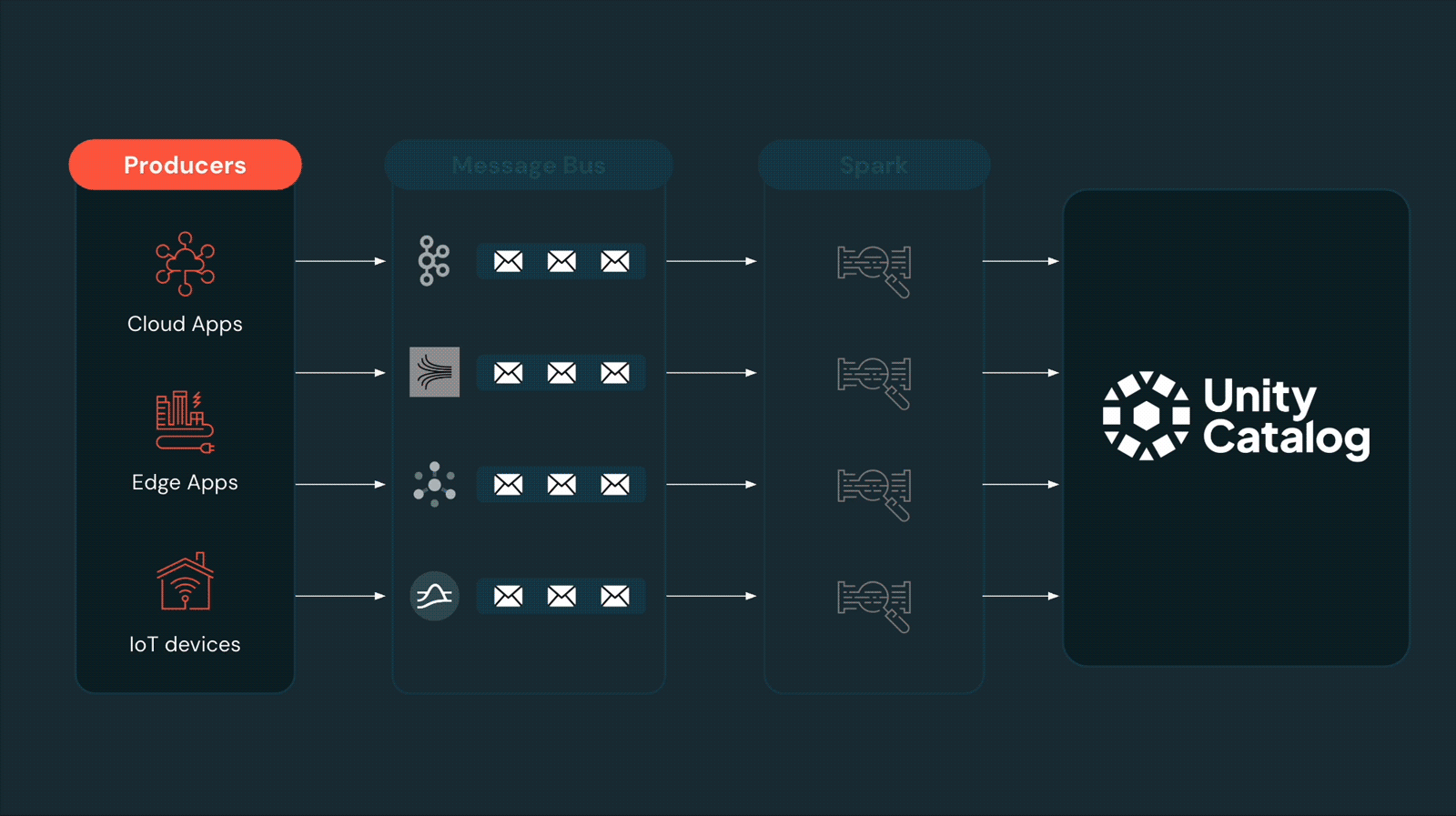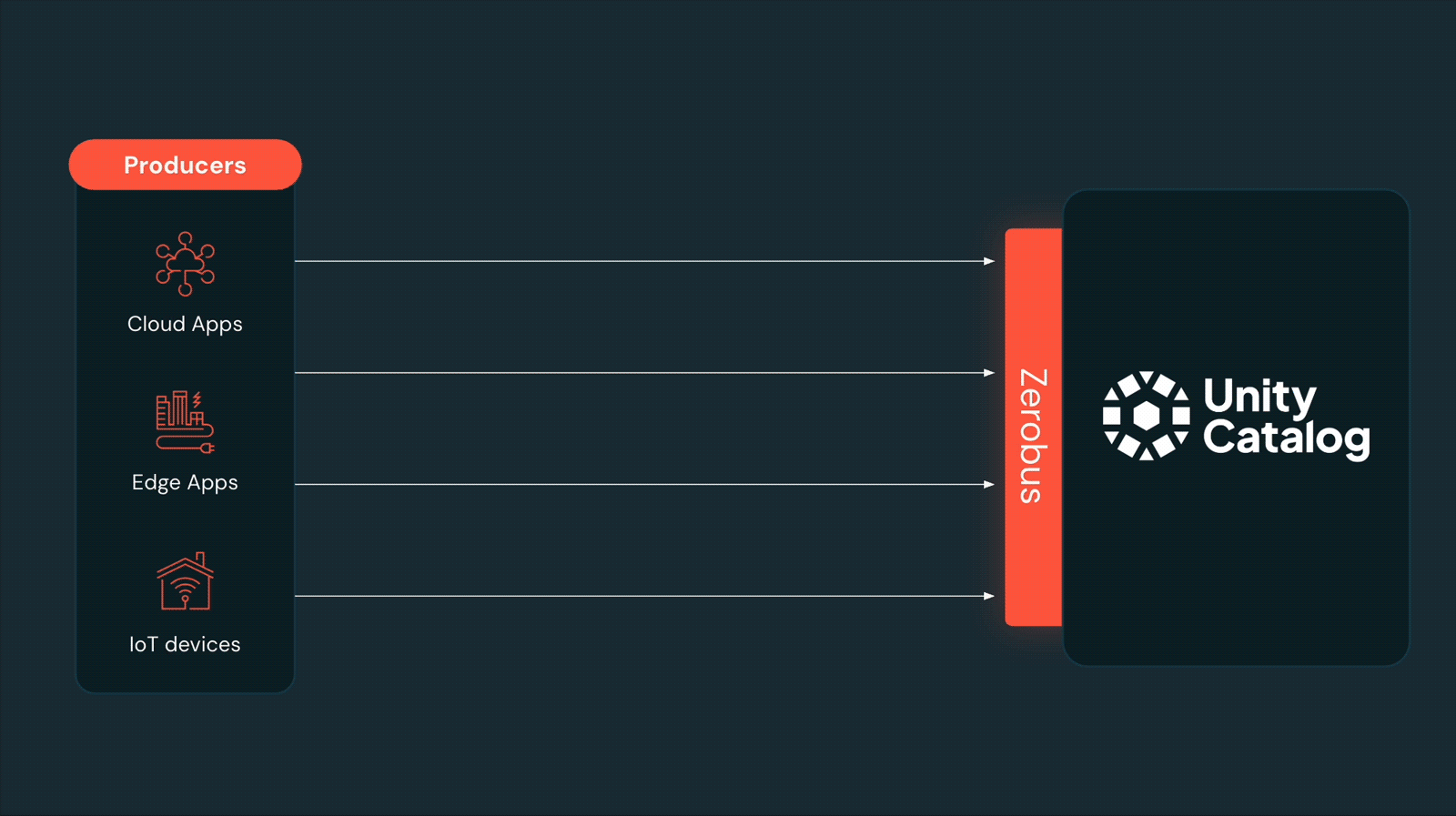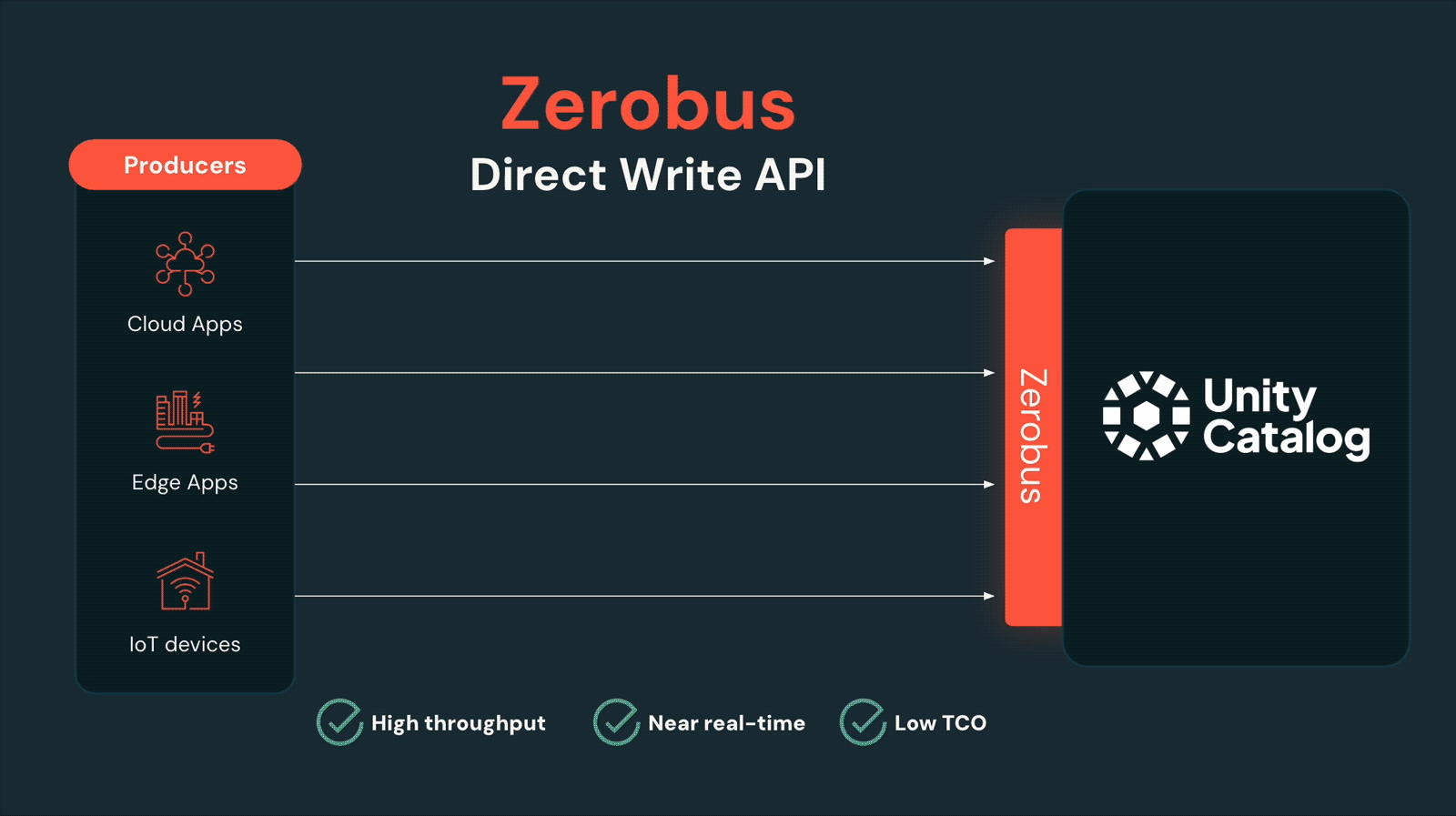
Lakeflow Connect offre des connecteurs d'ingestion simples pour les applications, les bases de données, le stockage cloud, les bus de messages, et plus encore. Sous le capot, l'ingestion est efficace, avec des mises à jour incrémentielles et une utilisation optimisée de l'API. Pendant que vos pipelines gérés s'exécutent, nous nous occupons de l'évolution des schémas, des mises à niveau transparentes des API tierces et d'une observabilité complète avec des alertes intégrées.
Annonces du Data + AI Summit 2025
Lors du Data + AI Summit de cette année, Databricks a annoncé la disponibilité générale de Lakeflow, l'approche unifiée de l'ingénierie des données pour l'ingestion, la transformation et l'orchestration. Dans ce cadre, Lakeflow Connect a annoncé Zerobus, une API d'écriture directe qui simplifie l'ingestion pour l'IoT, le clickstream, la télémétrie et d'autres cas d'utilisation similaires. Nous avons également élargi la gamme de sources de données prises en charge avec plus de connecteurs intégrés pour les applications d'entreprise, les sources de fichiers, les bases de données et les entrepôts de données, ainsi que les données provenant du stockage objet cloud.
Zerobus : une nouvelle façon de pousser les données d'événements directement vers votre lakehouse
Nous avons fait une annonce passionnante en présentant Zerobus, une nouvelle approche innovante pour pousser les données d'événements directement vers votre lakehouse en vous rapprochant de la source de données. L'élimination des sauts de données et la réduction de la charge opérationnelle permettent à Zerobus d'offrir des écritures directes à haut débit avec une faible latence, offrant des performances quasi en temps réel à l'échelle.
Auparavant, certaines organisations utilisaient des bus de messages comme Kafka comme couches de transport vers le Lakehouse. Kafka offre un moyen durable et à faible latence pour les producteurs de données d'envoyer des données, et c'est un choix populaire lors de l'écriture vers plusieurs destinations. Cependant, il ajoute également une complexité et des coûts supplémentaires, ainsi que la charge de gestion d'une copie de données supplémentaire — il est donc inefficace lorsque votre seule destination est le Lakehouse. Zerobus offre une solution simple pour ces cas.
Joby Aviation utilise déjà Zerobus pour pousser directement les données de télémétrie vers Databricks.
Joby est capable d'utiliser nos agents de fabrication avec Zerobus pour pousser des gigaoctets par minute de données de télémétrie directement vers notre lakehouse, accélérant le temps de découverte des informations — le tout avec Databricks Lakeflow et la Data Intelligence Platform.”
Dans le cadre de Lakeflow Connect, Zerobus est également unifié avec la Databricks Platform, vous pouvez donc exploiter plus largement les capacités d'analyse et d'IA immédiatement. Zerobus est actuellement en aperçu privé ; contactez votre équipe commerciale pour un accès anticipé.
🎥 Regardez et apprenez-en davantage sur Zerobus : Session plénière au Data + AI Summit, avec Joby Aviation, « Lakeflow Connect : éliminer les sauts dans votre architecture de streaming »
Lakeflow Connect étend les capacités d'ingestion et les sources de données
De nouveaux connecteurs entièrement gérés continuent d'être déployés dans divers états de publication (voir la liste complète ci-dessous), notamment Google Analytics et ServiceNow, ainsi que SQL Server – le premier connecteur de base de données, tous actuellement en aperçu public avec une disponibilité générale à venir bientôt.
Nous avons également continué à innover pour les clients qui souhaitent plus d'options de personnalisation et qui utilisent notre solution d'ingestion existante, Auto Loader. Il traite de manière incrémentielle et efficace les nouveaux fichiers de données à mesure qu'ils arrivent dans le stockage cloud. Nous avons publié des améliorations majeures de coût et de performance pour Auto Loader, y compris des listages de répertoires 3 fois plus rapides et un nettoyage automatique avec « CleanSource », tous deux désormais généralement disponibles, ainsi qu'une découverte de fichiers plus intelligente et plus rentable à l'aide des événements de fichiers. Nous avons également annoncé la prise en charge native de l'ingestion de fichiers Excel et de l'ingestion de données à partir de serveurs SFTP, tous deux en aperçu privé, disponibles sur demande pour un accès anticipé.
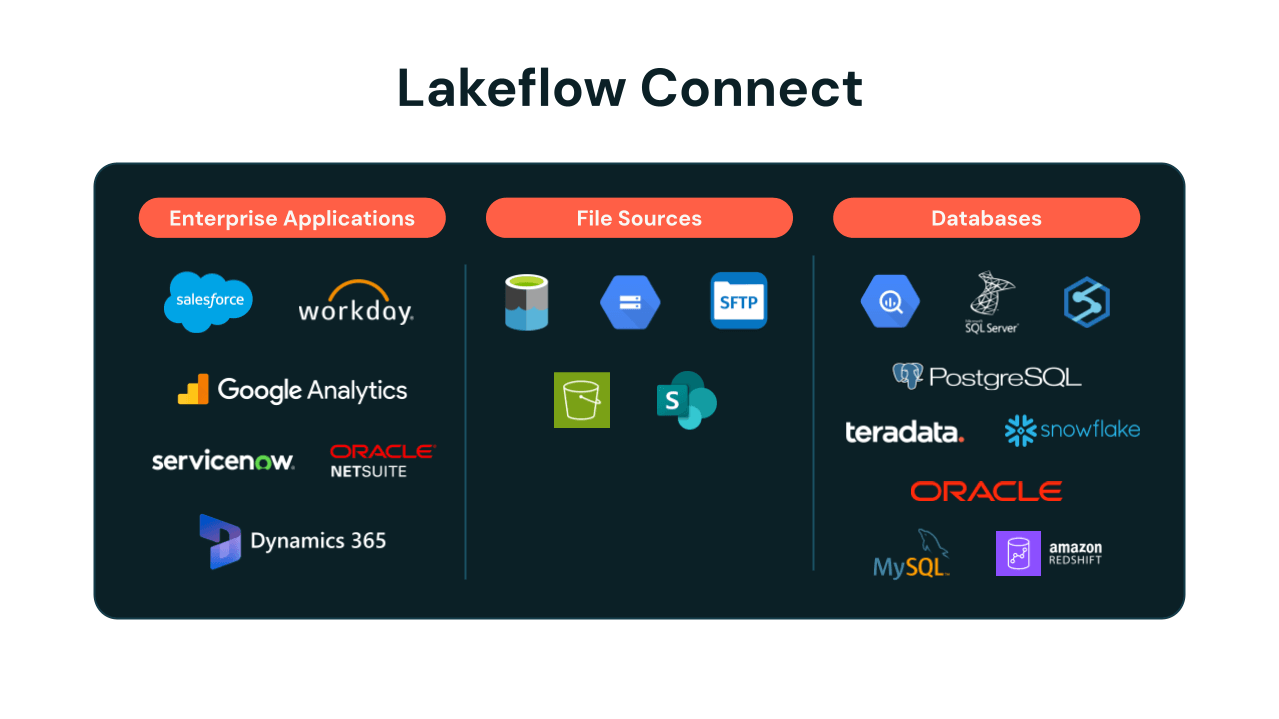
Sources de données prises en charge :
- Applications : Salesforce, Workday, ServiceNow, Google Analytics, Microsoft Dynamics 365, Oracle NetSuite
- Sources de fichiers : S3, ADLS, GCS, SFTP, SharePoint
- Bases de données : SQL Server, Oracle Database, MySQL, PostgreSQL
- Entrepôts de données : Snowflake, Amazon Redshift, Google BigQuery
Dans l'offre de connecteurs élargie, nous introduisons des connecteurs basés sur des requêtes qui simplifient l'ingestion de données. Ces nouveaux connecteurs vous permettent d'extraire des données directement de vos systèmes sources sans modifications de base de données et fonctionnent avec des réplicas de lecture lorsque les journaux de capture de données modifiées (CDC) ne sont pas disponibles. Ceci est actuellement en aperçu privé ; contactez votre équipe commerciale pour un accès anticipé.

🎥 Regardez et apprenez-en davantage sur Lakeflow Connect : Session plénière au Data + AI Summit, « Premiers pas avec Lakeflow Connect »
🎥 Regardez et apprenez-en davantage sur l'ingestion à partir d'applications SaaS d'entreprise : Session plénière au Data + AI Summit avec le client Databricks Porsche Holding, « Lakeflow Connect : ingestion de données transparente à partir d'applications d'entreprise »
🎥 Regardez et apprenez-en davantage sur les connecteurs de base de données : Session plénière au Data + AI Summit, « Lakeflow Connect : ingestion facile et efficace à partir de bases de données »
Lakeflow Connect dans Jobs, maintenant disponible
Nous continuons à développer des fonctionnalités pour vous permettre d'utiliser plus facilement nos connecteurs d'ingestion lors de la création de pipelines de données, dans le cadre de l'expérience unifiée d'ingénierie des données de Lakeflow. Databricks a récemment annoncé Lakeflow Connect dans Jobs, qui vous permet de créer des pipelines d'ingestion au sein de Lakeflow Jobs. Ainsi, si vous avez des jobs au centre de votre processus ETL, cette intégration transparente offre une expérience plus intuitive et unifiée pour la gestion de l'ingestion.
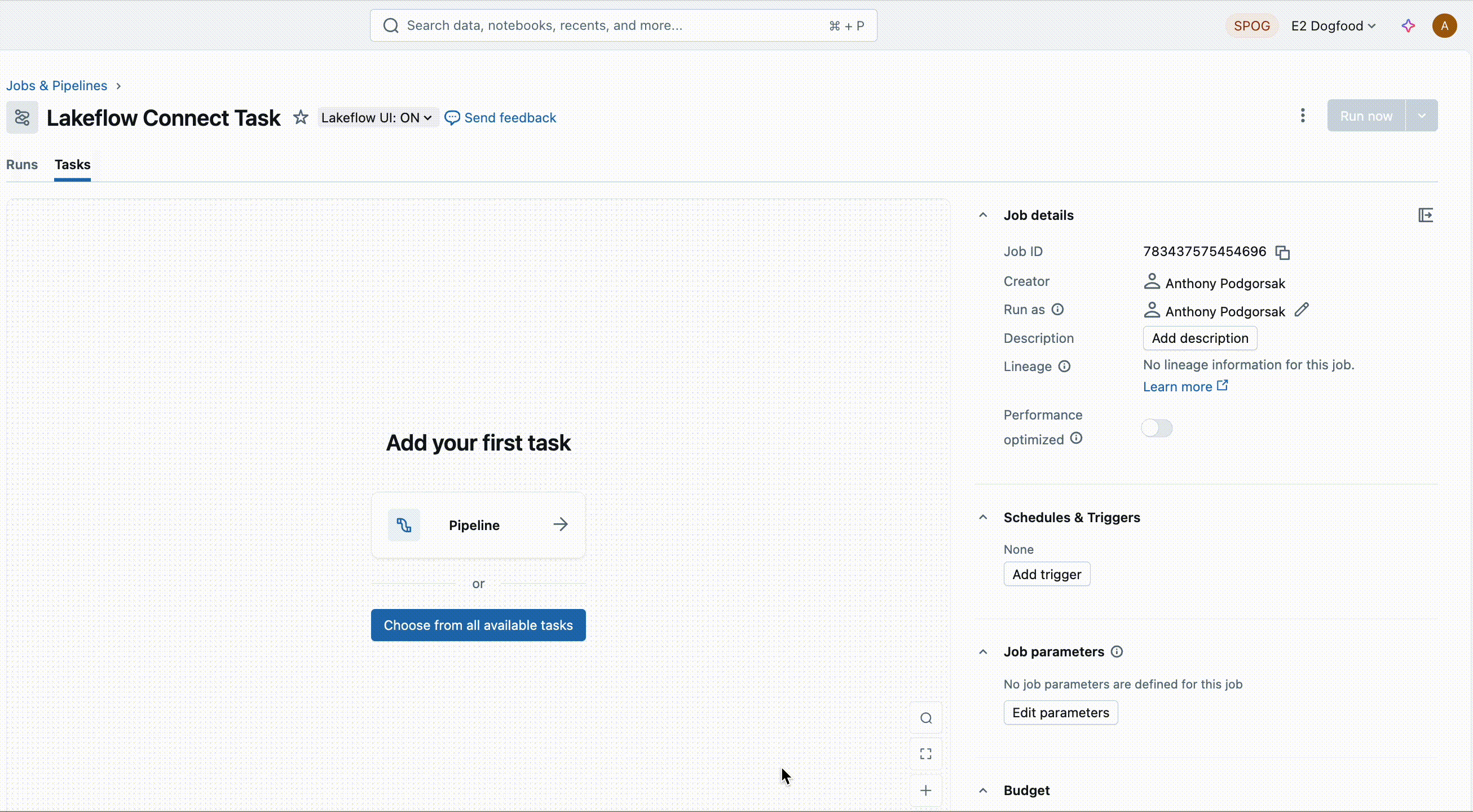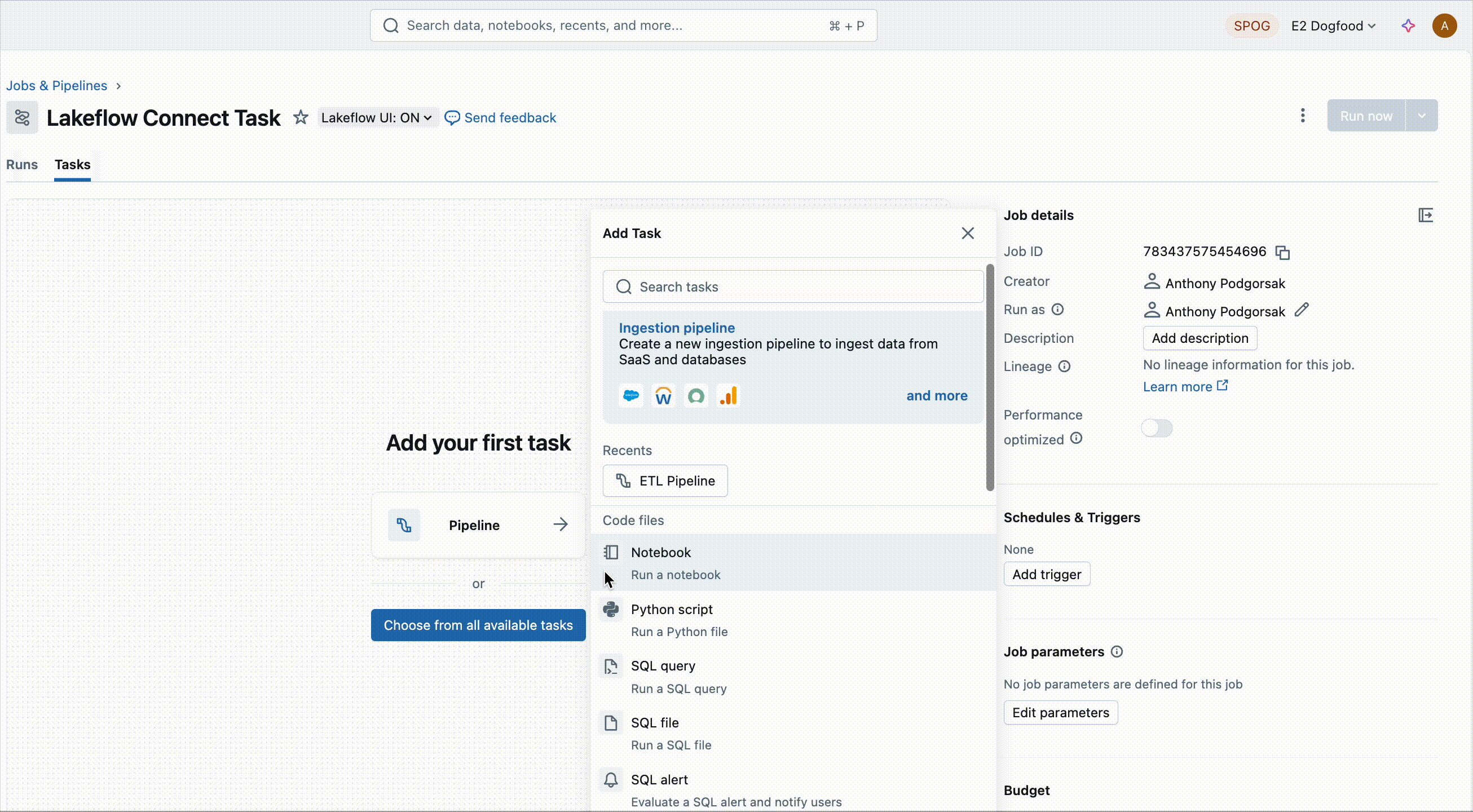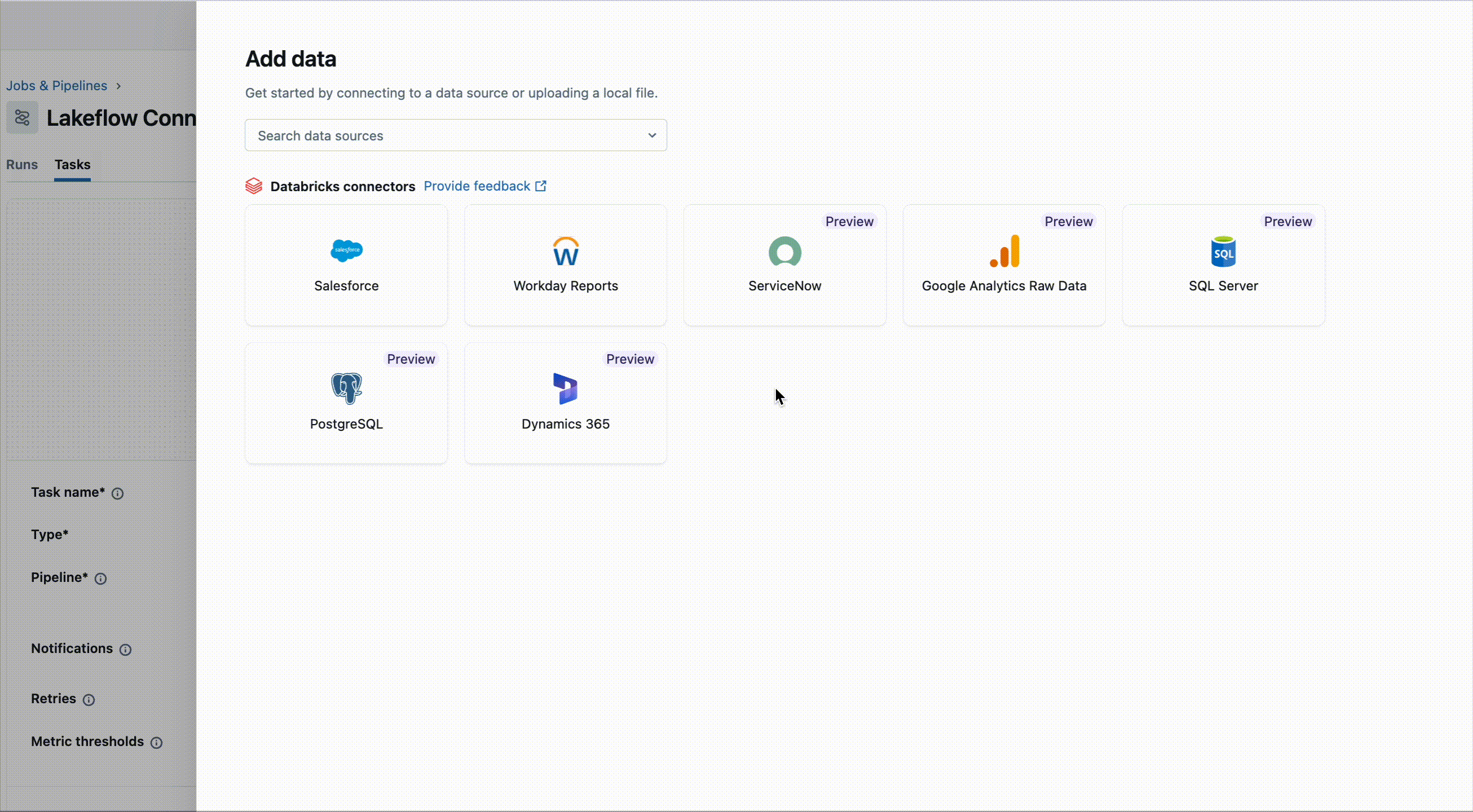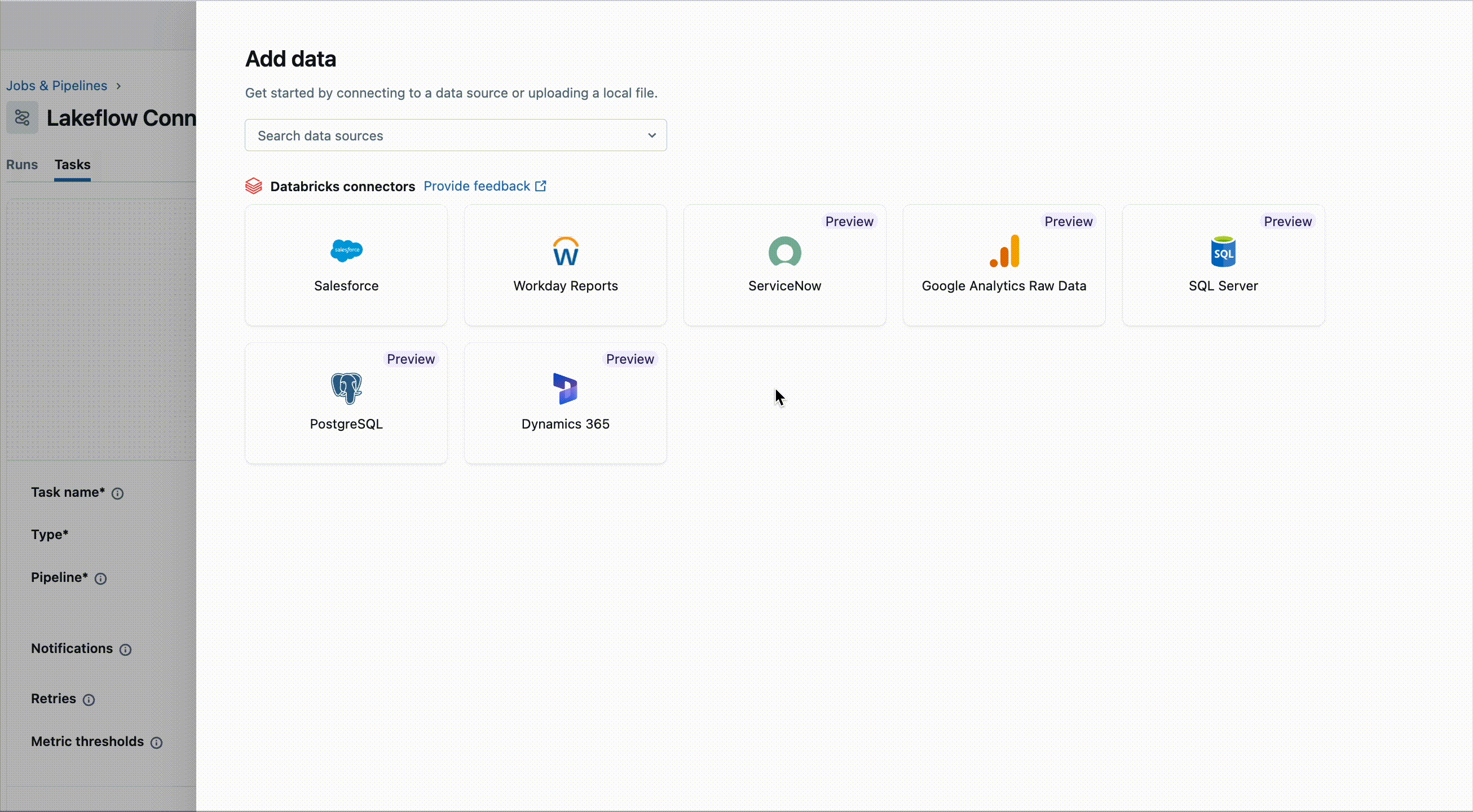
Les clients peuvent définir et gérer leurs charges de travail de bout en bout—de l'ingestion à la transformation—le tout en un seul endroit. Lakeflow Connect dans Jobs est maintenant disponible en général.
🎥 Regardez et apprenez-en davantage sur Lakeflow Jobs : Session plénière au Data + AI Summit "Orchestration avec Lakeflow Jobs" "Orchestration avec Lakeflow Jobs"
Lakeflow Connect : encore plus à venir en 2025 et au-delà
Databricks comprend les besoins des ingénieurs de données et des organisations qui stimulent l'innovation avec leurs données en utilisant des outils d'analyse et d'IA. À cette fin, Lakeflow Connect a continué à développer des capacités d'ingestion robustes et efficaces avec des connecteurs entièrement gérés vers des fonctionnalités et des API plus personnalisables.
Nous ne faisons que commencer avec Lakeflow Connect. Restez à l'écoute pour plus d'annonces plus tard cette année, ou contactez votre équipe de compte Databricks pour rejoindre un aperçu et accéder en avant-première.
Pour essayer Lakeflow Connect, vous pouvez consulter la documentation, ou consulter le Demo Center.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.