Concentrez-vous sur les workloads de données, et non sur l'infrastructure
Spark entièrement managé et sans version pour toutes vos charges de travail liées aux données et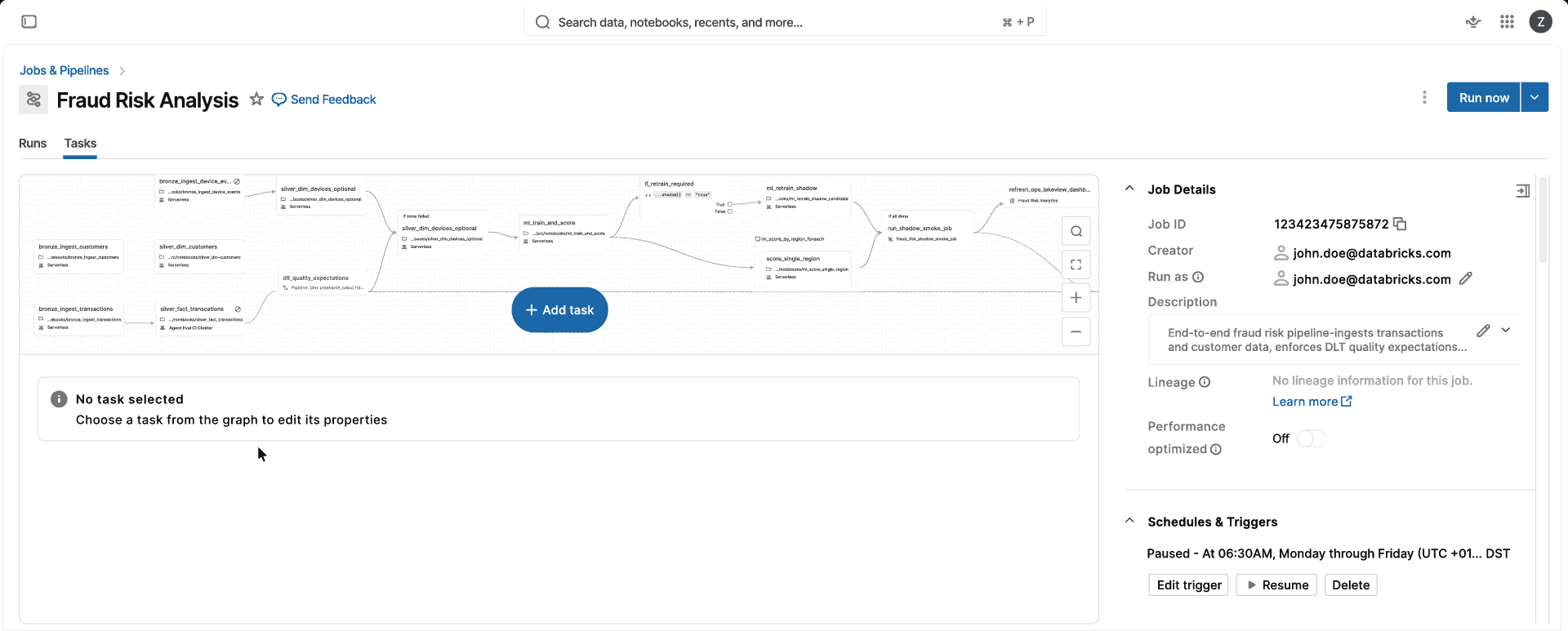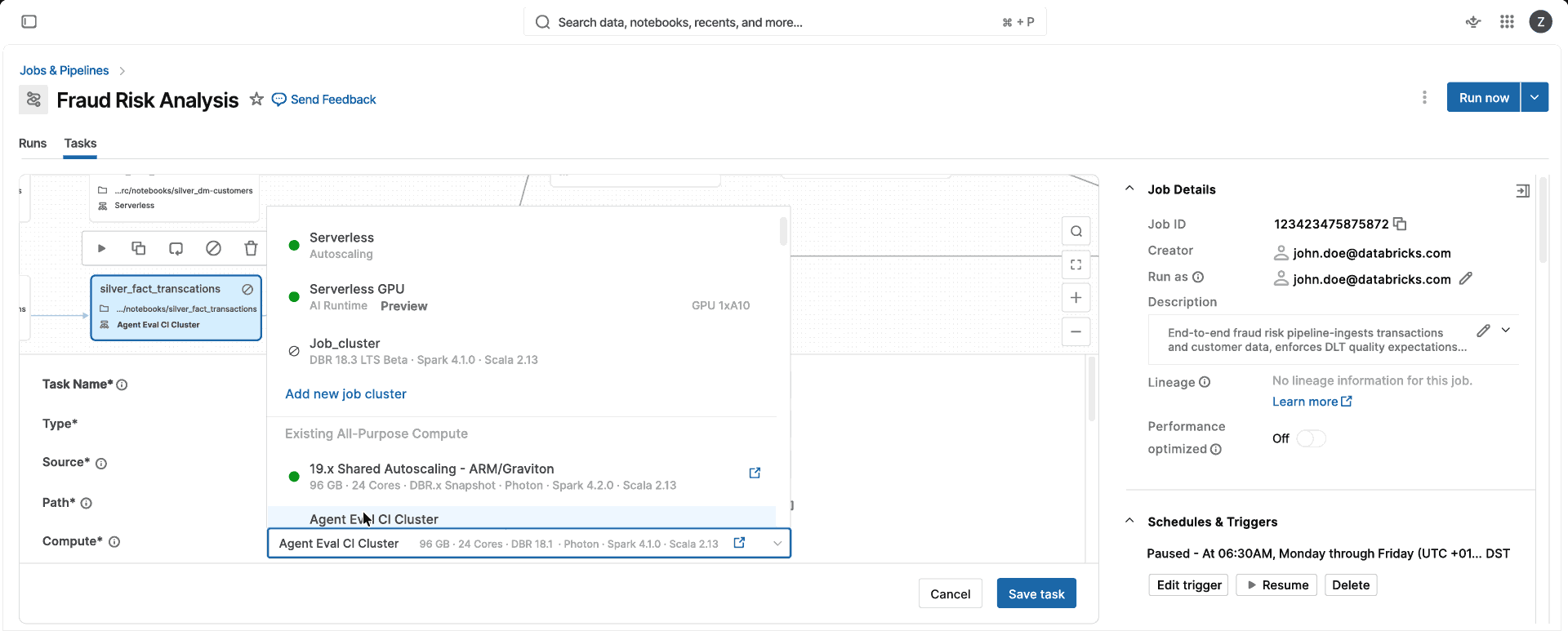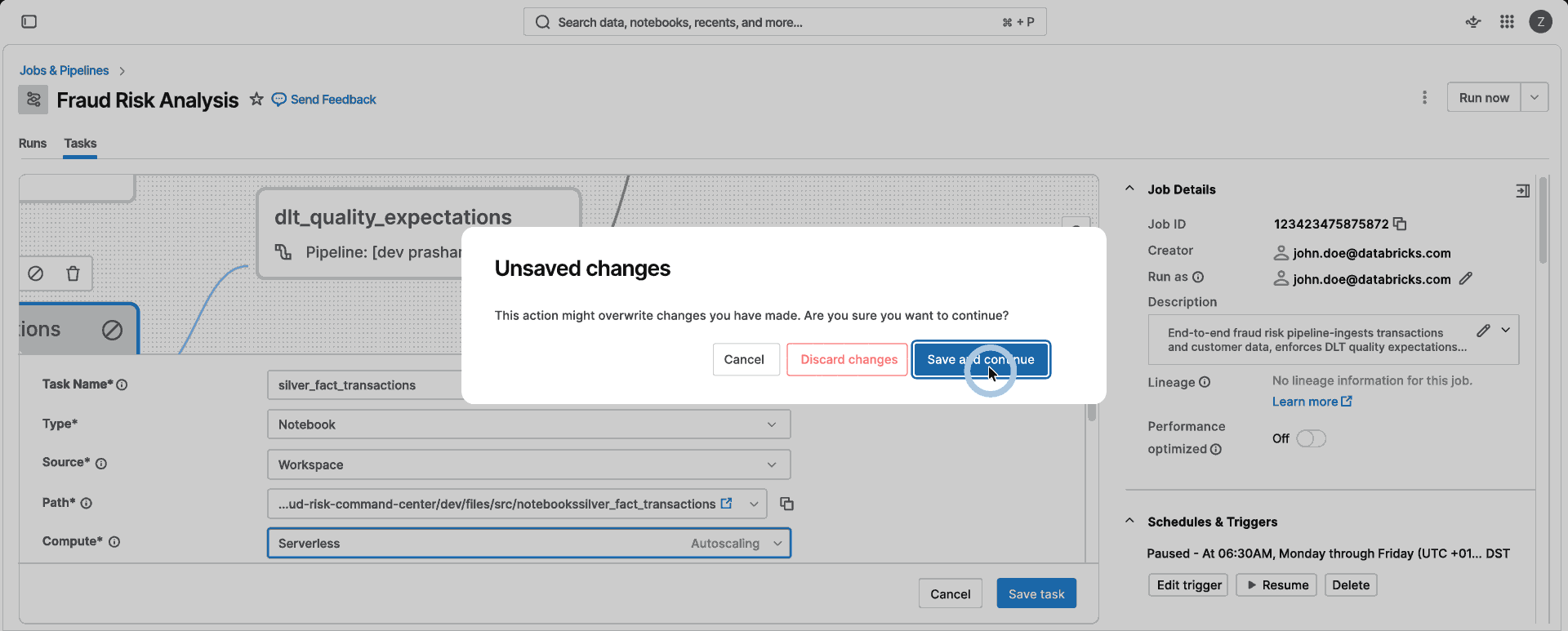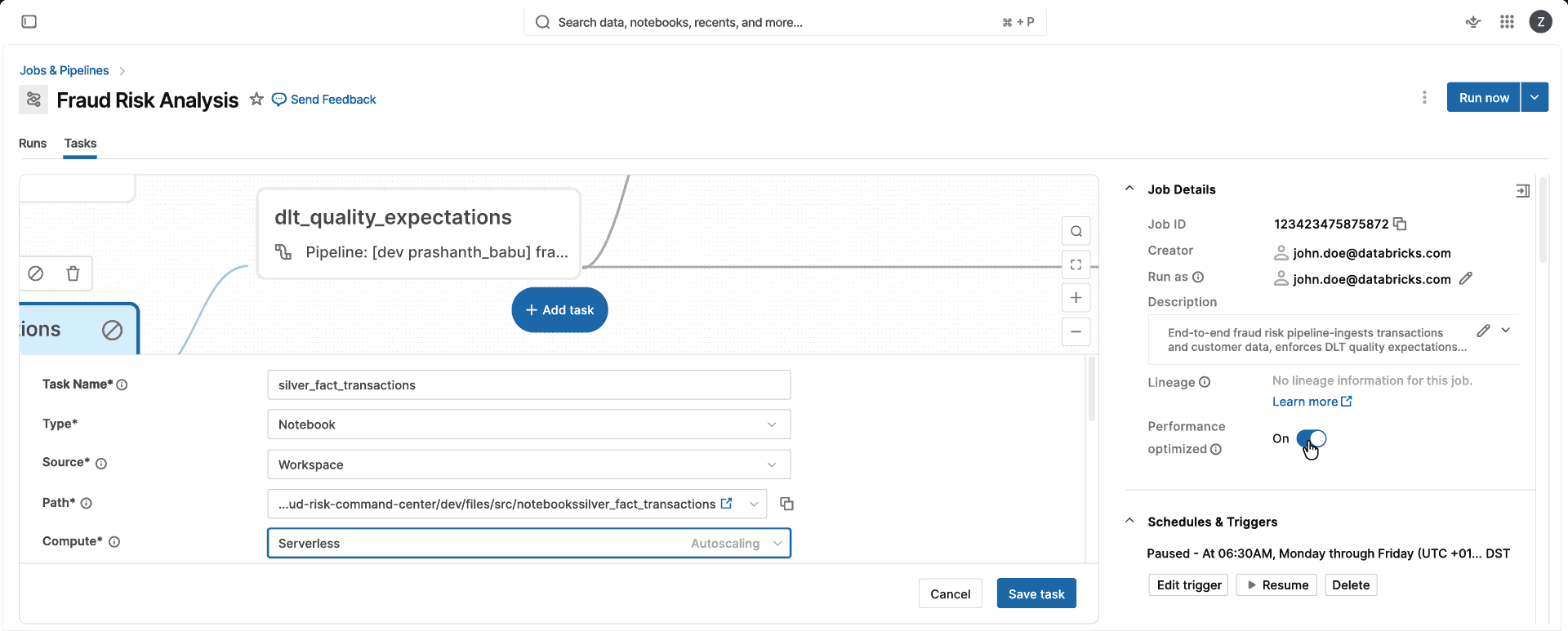
LES PLUS GRANDES ENTREPRISES UTILISENT LE Serverless CALCUL
Choisissez votre objectif métier, pas l'infra.
Exécutez des charges de travail de données et d'IA sur un compute qui monte en charge, se met à jour et s'optimise automatiquement, sans gestion de l'infrastructure.Entièrement géré
Un compute. Aucune décision à prendre concernant l'optimisation pour le processeur, pour la mémoire ou la classe d'instance, aucune configuration de cluster à gérer. Choisissez le mode Standard ou Optimisé pour les performances, et Databricks sélectionne automatiquement pour vous l'instance et les types de compute appropriés (VM unique ou cluster Spark), afin que votre équipe puisse livrer des produits de données plutôt que de gérer le compute.
Performant
Serverless démarre en quelques secondes, et non en quelques minutes, charge les environnements depuis le cache et s'ajuste automatiquement à la demande de la charge de travail. Le mode Standard offre un traitement par batch rentable, tandis que le mode Performances optimisées exécute généralement les Jobs sensibles à la latence 2 fois plus rapidement que les clusters classiques.
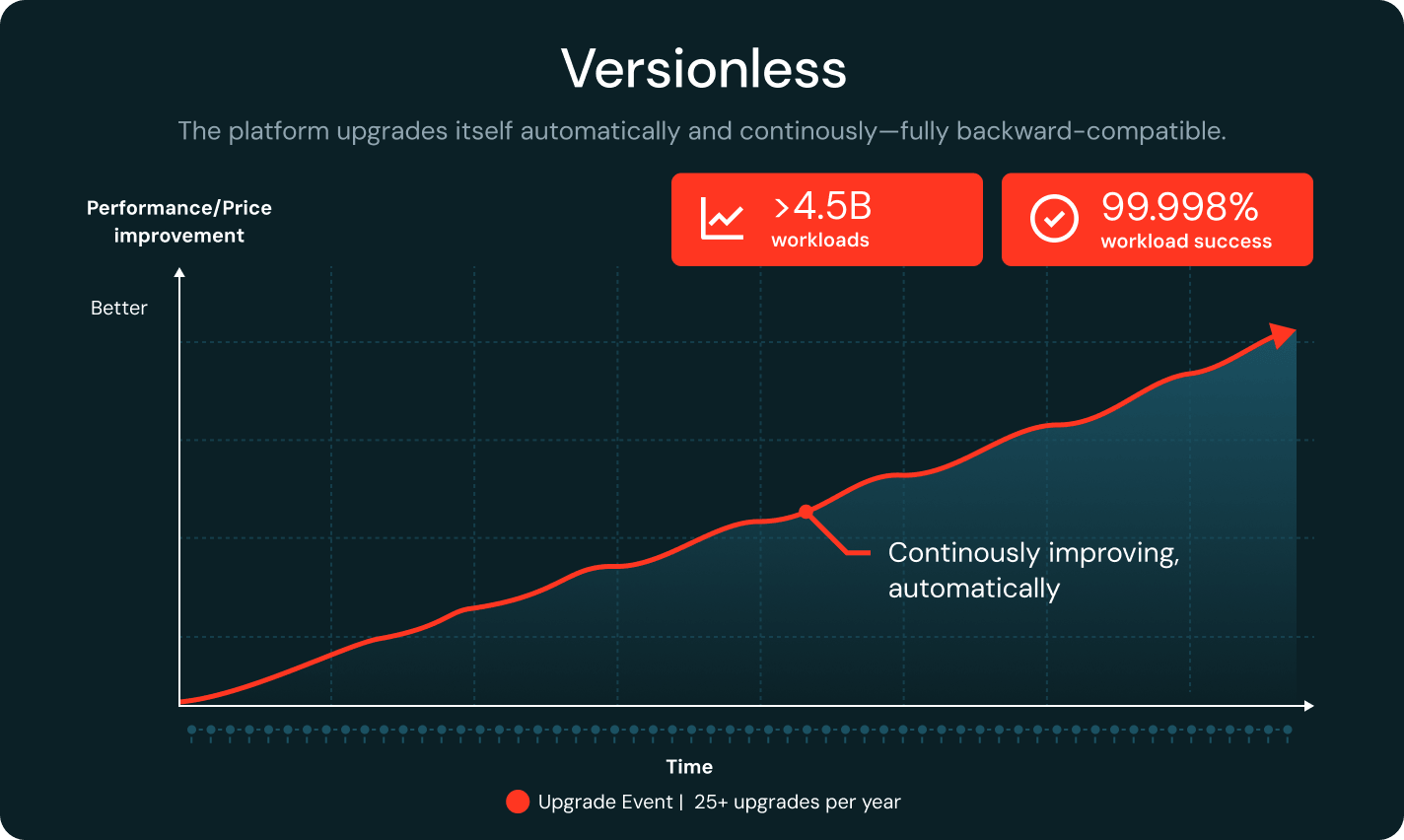
Sans version
Databricks met à jour en continu l'environnement d'exécution tout en restant entièrement rétrocompatible. La détection de régression pins automatiquement les charges de travail à des versions stables. Avec plus de 25 mises à niveau par an et un taux de réussite des charges de travail de 99,998 %, les équipes économisent jusqu'à 20 % de leur temps d'ingénierie.
Le calcul qui fonctionne, tout simplement
Arrêtez de gérer l'infrastructure et start à exécuter vos charges de travail de données et d'IA sur une compute entièrement managée, sans version et à mise à l'échelle automatique.Serverless se met à jour en continu et automatiquement tout en restant entièrement rétrocompatible, assurant ainsi le fonctionnement des charges de travail sans intervention.
Choisissez le mode Standard pour les charges de travail par batch optimisées en termes de coût ou le mode Performances optimisées pour les tâches sensibles à la latence, qui exécute généralement les tâches 2 fois plus vite que les clusters classiques.
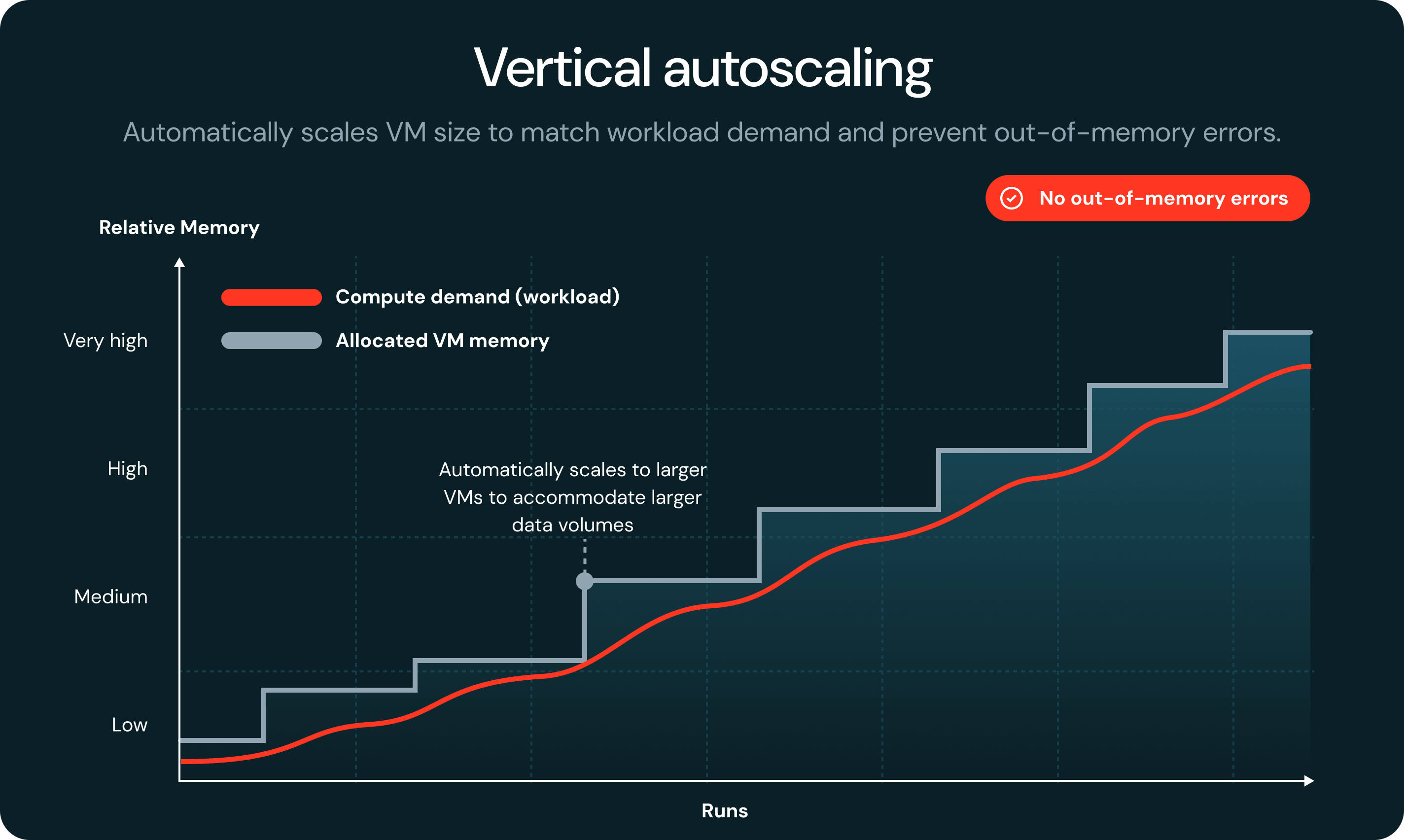
Lorsqu'une tâche manque de mémoire, la technologie serverless détecte automatiquement la défaillance et la redémarre sur une VM plus grande, sans entraîner d'échec du job ni nécessiter d'intervention manuelle.
Les environnements de bibliothèque sont mis en cache de manière globale. Ainsi, lorsqu'un utilisateur de votre organisation exécute un ensemble de packages spécifique, l'environnement est prêt en quelques secondes pour tous les autres.
Le Serverless met à l'échelle la puissance de calcul à la hausse ou à la baisse en quelques secondes, et non en minutes, l'adaptant automatiquement à la charge de travail sans configuration de cluster.
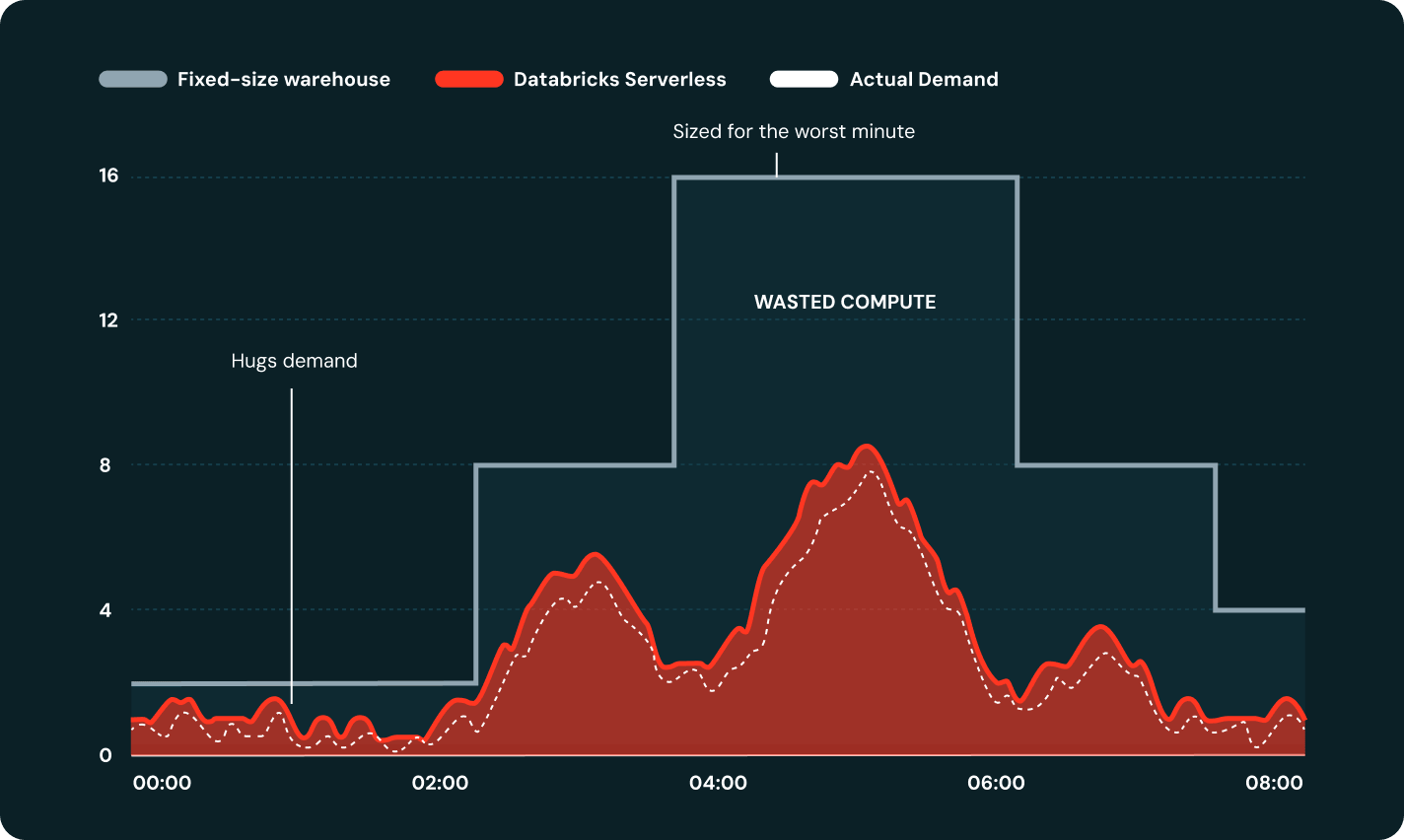
Serverless relance automatiquement les tâches qui ont échoué et contourne les défaillances au niveau du cloud, ce qui permet de respecter le calendrier des pipelines sans intervention d'astreinte.
Autres fonctionnalités
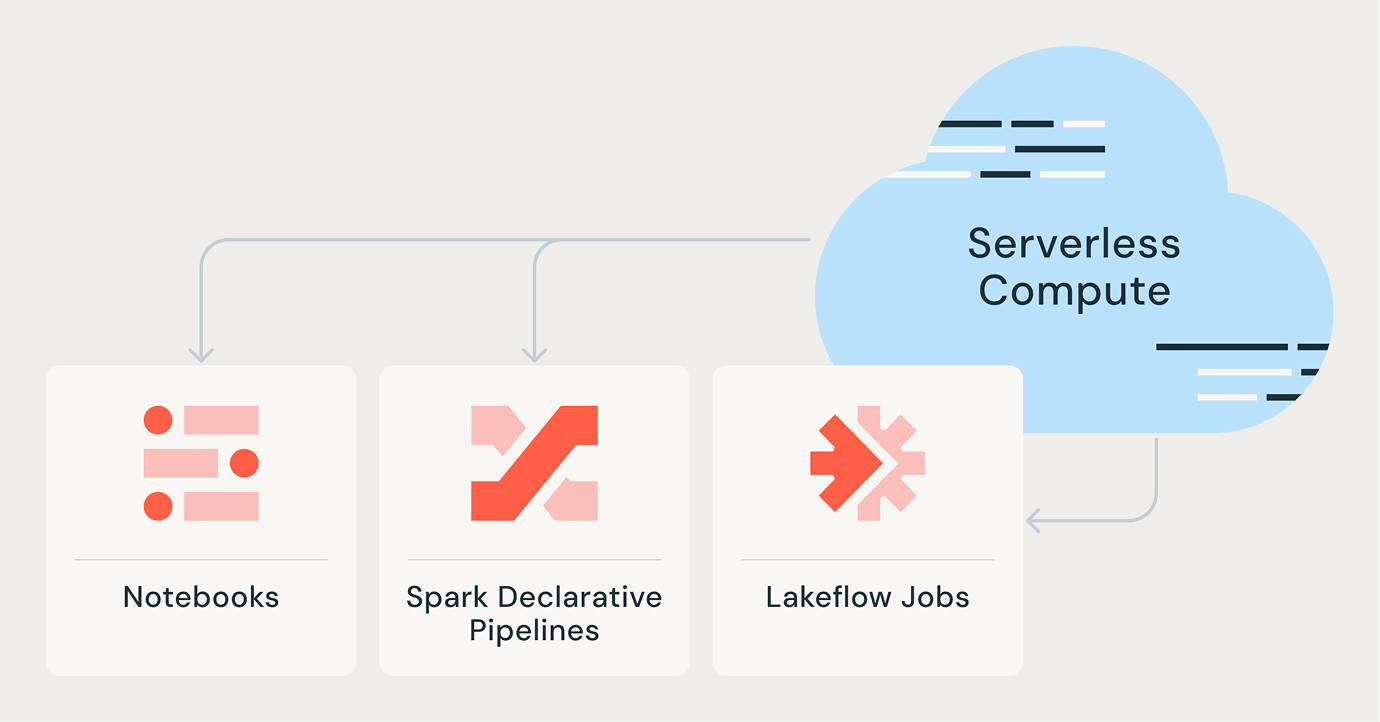
Le serverless pour toutes les charges de travail

Query data without managing warehouse compute
Les SQL Warehouses Serverless de Databricks startent en quelques secondes et montent en charge automatiquement à la demande, si bien que les analystes disposent toujours du compute nécessaire. Ni décisions de dimensionnement, ni clusters inactifs, ni surcharge d'infrastructure. Just fast, reliable query.




Les tarifs basés sur l'utilisation permettent de maîtriser les dépenses
Ne payez que les produits que vous utilisez, à la seconde près.En savoir plus
En savoir plus sur les produits basés sur le Serverless compute
Tâches Lakeflow
Donnez aux équipes les moyens de mieux automatiser et orchestrer tous les workflows d'ETL, d'analytique et d'IA grâce à une observabilité approfondie, une haute fiabilité et la prise en charge d'un large éventail de tâches.

Databricks SQL
Un data warehouse intelligent avec optimisation automatique, reposant sur une architecture de data lake pour offrir le meilleur rapport performance / prix du marché.

Pipelines déclaratifs Spark
Simplifiez l'ETL par batch et en streaming grâce à la qualité de données automatisée, la change data capture (CDC), l'acquisition et la transformation des données, ainsi que la gouvernance unifiée.

Notebooks
Dopez la productivité de vos équipes avec les notebooks collaboratifs Databricks. Ils facilitent la collaboration en temps réel et simplifient les workflows de data science.

Databricks Apps
Créez des applications en utilisant des frameworks courants, le déploiement serverless et la gouvernance intégrée. Fournissez des solutions puissantes aux utilisateurs sans vous soucier des aspects complexes de la gestion d'infrastructure.

Lakebase
Postgres intégré au lakehouse, conçu pour les charges de travail opérationnelles modernes.
Passez à l'étape suivante
Contenu associé
FAQ sur le compute Serverless
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation data