How Data Lakehouses Solve Common Issues With Data Warehouses
di Ryan Boyd
Leggi Rise of the Data Lakehouse per scoprire perché i lakehouse sono l'architettura dei dati del futuro con il padre del data warehouse, Bill Inmon.
Nota della redazione: questo è il primo di una serie di post in gran parte basato sul paper CIDR Lakehouse: A New Generation of Open Platforms that Unify data warehousing and Advanced analitiche, con il permesso degli autori.
Gli analisti di dati, i data scientist e gli esperti di intelligenza artificiale sono spesso frustrati dalla fondamentale mancanza di dati di alta qualità, affidabili e aggiornati disponibili per il loro lavoro. Alcune di queste frustrazioni sono dovute ai noti svantaggi dell'architettura dei dati a due livelli che oggi vediamo prevalere nella stragrande maggioranza delle aziende Fortune 500. L'architettura open lakehouse e la tecnologia sottostante possono migliorare notevolmente la produttività dei team di dati e quindi l'efficienza delle aziende che li impiegano.
Sfide con l'architettura dei dati a due livelli
In questa diffusa architettura, i dati provenienti da tutta l'organizzazione vengono estratti dai database operativi e caricati in un data lake grezzo, a volte definito data swamp a causa della scarsa cura nel garantire che questi dati siano utilizzabili e affidabili. Successivamente, un altro processo ETL (Extract Transform Load (ETL)) viene eseguito in base a una pianificazione per spostare importanti sottoinsiemi di dati in un data warehouse per la Business Intelligence e il processo decisionale.
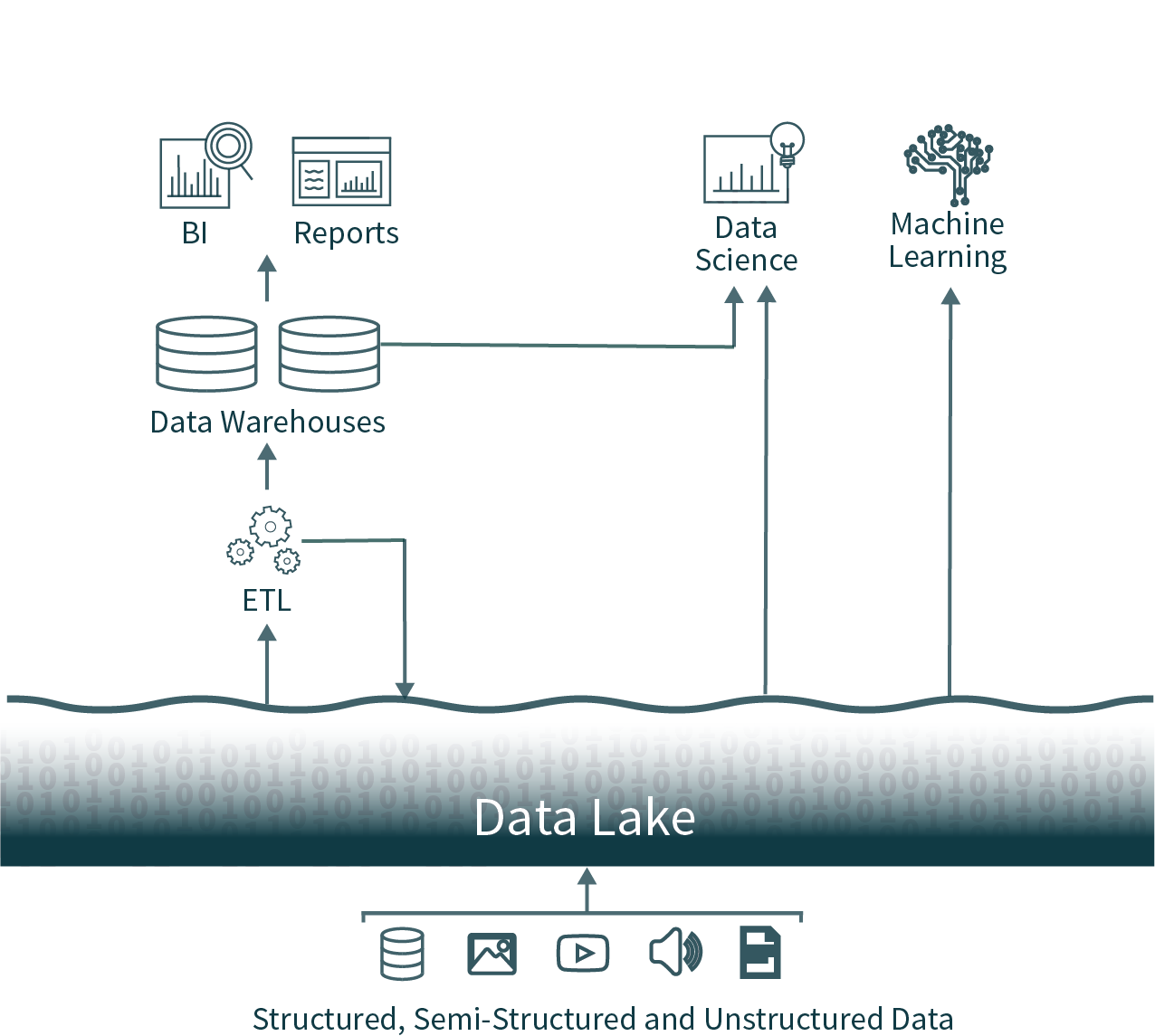
Questa architettura pone gli analisti di dati di fronte a una scelta quasi impossibile: utilizzare dati tempestivi e inaffidabili dal data lake o dati obsoleti e di alta qualità dal data warehouse. A causa dei formati chiusi delle popolari soluzioni di data warehousing, è anche molto difficile utilizzare i principali framework di analisi dei dati open-source su sorgenti di dati di alta qualità senza introdurre un'altra attività operativa ETL e aumentare l'obsolescenza dei dati.
Possiamo fare di meglio: ecco il Data Lakehouse
Queste architetture di dati a due livelli, oggi comuni nelle aziende, sono estremamente complesse sia per gli utenti che per i Data Engineer che le creano, indipendentemente dal fatto che siano ospitate on-premise o in cloud.
L'architettura Lakehouse riduce la complessità, i costi e l'overhead operativo fornendo molti dei vantaggi di affidabilità e prestazioni del livello del data warehouse direttamente sopra il data lake, eliminando in definitiva il livello del warehouse.
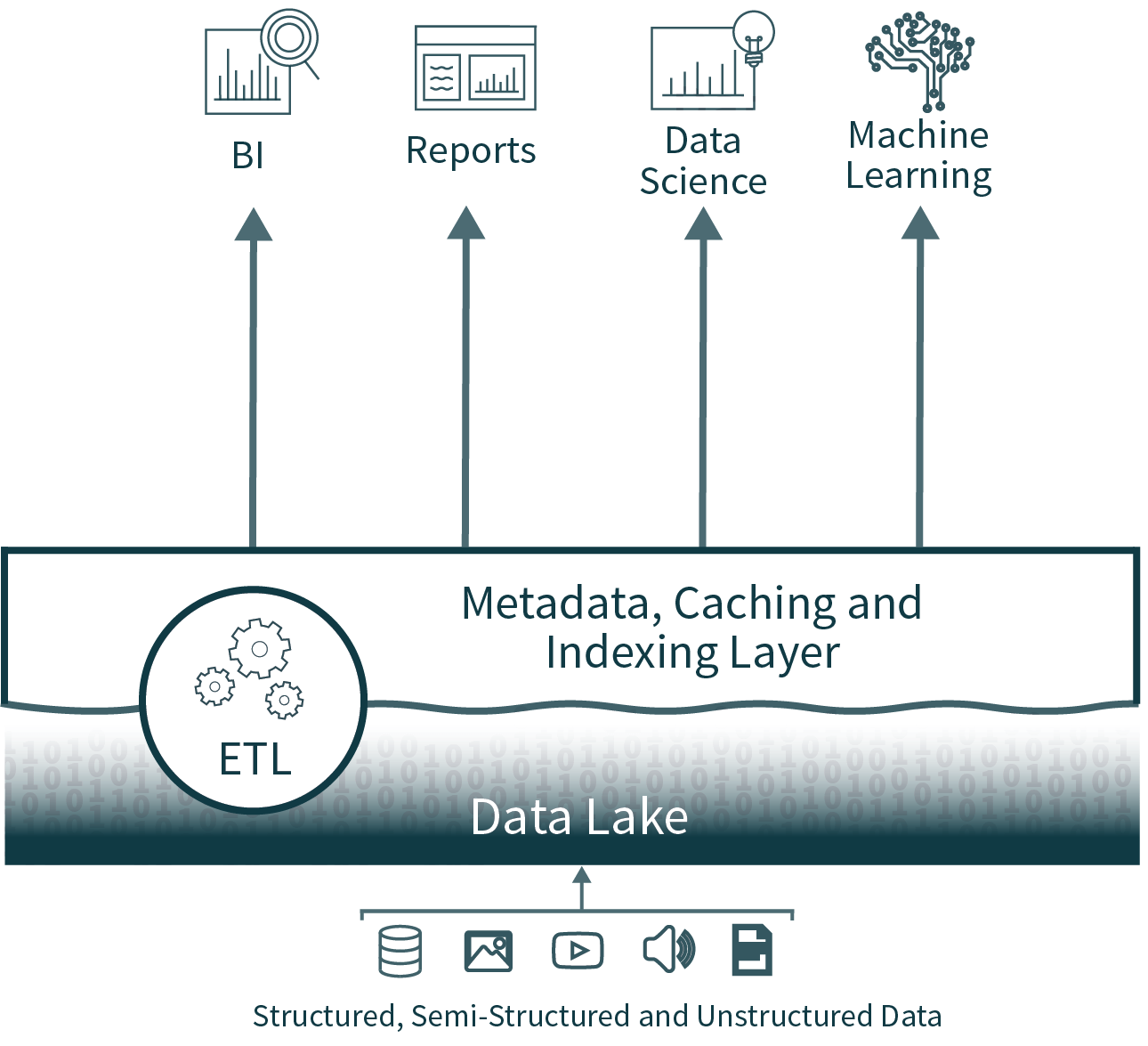
Affidabilità dei dati
La consistenza dei dati è una sfida incredibile quando si hanno più copie di dati da mantenere sincronizzate. Esistono molteplici processi ETL, che spostano i dati dai database operazionali al data lake e poi di nuovo dal data lake al data warehouse. Ogni processo aggiuntivo introduce ulteriore complessità, ritardi e modalità di errore.
Eliminando il secondo livello, l'architettura data lakehouse rimuove uno dei processi ETL e aggiunge il supporto per l'applicazione di uno schema e l'evoluzione direttamente sul data lake. Supporta anche funzionalità come il time travel per consentire la convalida storica della pulizia dei dati.
Obsolescenza dei dati
Poiché il data warehouse viene popolato dal data lake, i dati sono spesso obsoleti. Secondo un recente sondaggio di Fivetran, questo costringe l'86% degli analisti a utilizzare dati non aggiornati.

Sebbene l'eliminazione del livello di data warehouse risolva questo problema, una lakehouse può anche supportare l'unione efficiente, semplice e affidabile di streaming in tempo reale ed elaborazione batch, per garantire che per l'analisi vengano sempre utilizzati i dati più aggiornati.
Supporto limitato per le analitiche avanzate
Le analitiche avanzate, che includono machine learning e analisi predittiva, richiedono spesso l'elaborazione di set di dati molto grandi. Strumenti comuni, come TensorFlow, PyTorch e XGBoost, semplificano la lettura dei data lake grezzi in formati di dati aperti. Tuttavia, questi strumenti non leggono la maggior parte dei formati di dati proprietari utilizzati dai dati sottoposti a ETL nei data warehouse. I fornitori di warehouse consigliano quindi di esportare questi dati in file per l'elaborazione, il che si traduce in una terza fase ETL, oltre a una maggiore complessità e obsolescenza.
In alternativa, nell'architettura open lakehouse, questi set di strumenti comuni possono operare direttamente su dati tempestivi e di alta qualità archiviati nel data lake.
Costo totale di proprietà
Mentre i costi di archiviazione in cloud sono in calo, questa architettura a due livelli per le analitiche dei dati dispone in realtà di tre copie online di gran parte dei dati aziendali: una nei database operativi, una nel data lake e una nel data warehouse.
Il costo totale di proprietà (TCO) è ulteriormente aggravato quando ai costi di archiviazione si aggiungono i notevoli costi di ingegneria associati al mantenimento della sincronizzazione dei dati.
L'architettura data lakehouse elimina una delle copie più costose dei dati, oltre ad almeno un processo di sincronizzazione associato.
E per quanto riguarda le prestazioni per la business intelligence?
La business intelligence e il supporto decisionale richiedono l'esecuzione ad alte prestazioni di query di analisi esplorativa dei dati (EDA), così come di query che alimentano dashboard, visualizzazioni di dati e altri sistemi critici. Le preoccupazioni relative alle prestazioni erano spesso il motivo per cui le aziende mantenevano un data warehouse oltre a un data lake. La tecnologia per l'ottimizzazione delle query sui data lake è migliorata notevolmente nell'ultimo anno, rendendo superflua la maggior parte di queste preoccupazioni relative alle prestazioni.
Le lakehouse offrono supporto per l'indicizzazione, i controlli di località, l'ottimizzazione delle query e la memorizzazione nella cache dei dati ad accesso frequente per migliorare le prestazioni. Ciò si traduce in prestazioni SQL del data lake che superano quelle dei principali data warehouse in cloud su TPC-DS, offrendo al contempo la flessibilità e la governance previste per i data warehouse.
Conclusioni e prossimi passi
Le aziende e i tecnologi all'avanguardia hanno esaminato l'architettura a due livelli attualmente in uso e si sono detti: "Deve esserci un modo migliore." Questo approccio migliore è ciò che chiamiamo open data lakehouse, che combina l'apertura e la flessibilità del data lake con l'affidabilità, le prestazioni, la bassa latenza e la high concurrency dei data warehouse tradizionali.
Approfondirò i miglioramenti delle prestazioni del data lake in un prossimo post di questa serie.
Naturalmente, puoi barare e portarti avanti leggendo il paper completo del CIDR o guardando una serie di video che approfondisce la tecnologia alla base del moderno lakehouse.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.