Amministrazione di Databricks Workspace – Best Practice per amministratori di account, workspace e metastore
Una storia di tre amministratori
Questo blog fa parte della nostra serie Admin Essentials, in cui trattiamo argomenti pertinenti per gli amministratori Databricks. Altri blog includono le nostre Best Practice per l'Organizzazione dello Spazio di Lavoro, Strategie di DR con Terraform e molti altri! Tieni d'occhio i prossimi contenuti. Nei blog precedenti focalizzati sugli amministratori, abbiamo discusso come stabilire e mantenere una solida organizzazione dello spazio di lavoro attraverso una progettazione iniziale e l'automazione di aspetti quali DR, CI/CD e controlli di integrità del sistema. Un aspetto ugualmente importante dell'amministrazione è come ci si organizza all'interno dei propri spazi di lavoro, specialmente quando si tratta dei molti diversi tipi di persona amministrativa che possono esistere all'interno di un Lakehouse. In questo blog parleremo delle considerazioni amministrative sulla gestione di uno spazio di lavoro, come ad esempio:
- Impostare policy e guardrail per rendere a prova di futuro l'onboarding di nuovi utenti e casi d'uso
- Governare l'utilizzo delle risorse
- Garantire l'accesso ai dati consentito
- Ottimizzare l'utilizzo del compute per massimizzare il tuo investimento
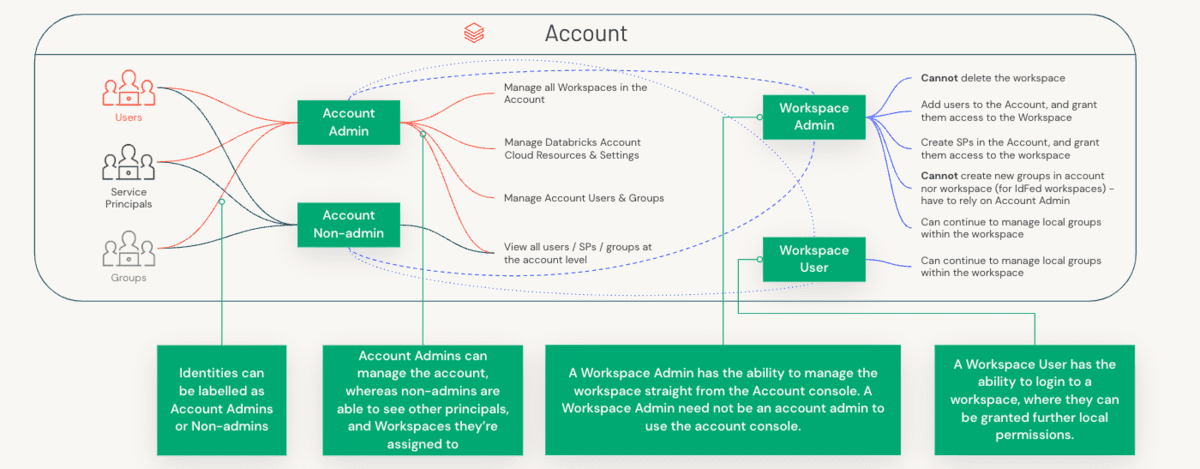
Per comprendere la delineazione dei ruoli, dobbiamo prima capire la distinzione tra un Amministratore di Account e un Amministratore dello Spazio di Lavoro, e i componenti specifici che ciascuno di questi ruoli gestisce.
Amministratori di Account Vs Amministratori dello Spazio di Lavoro Vs Amministratori di Metastore
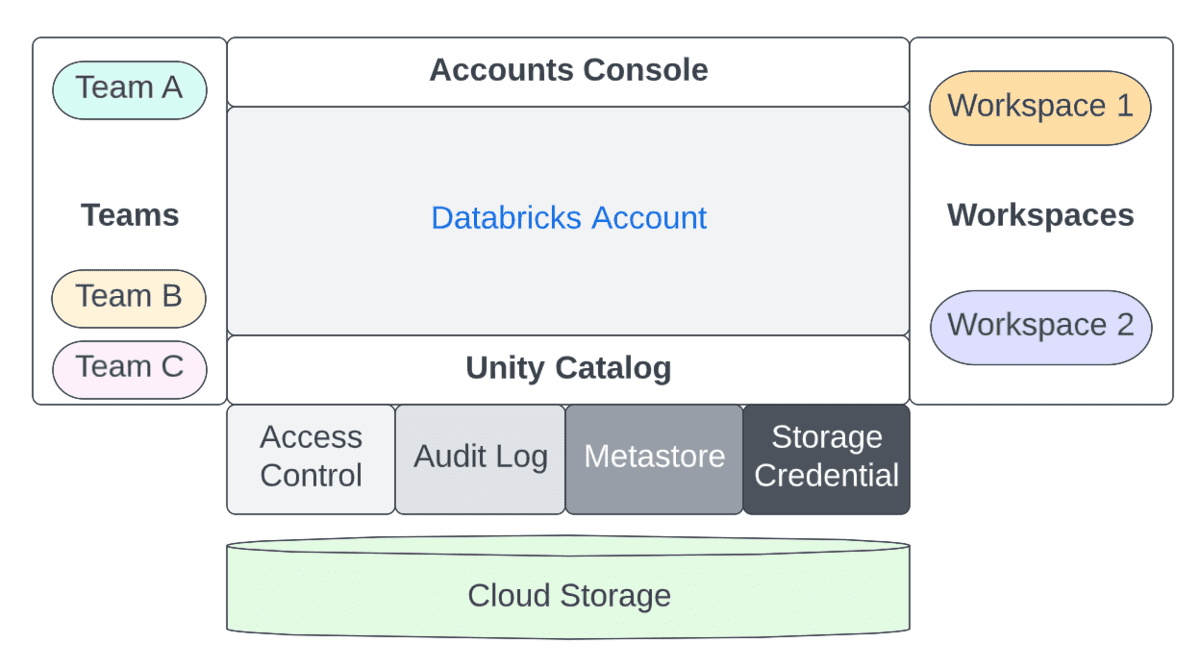
Le preoccupazioni amministrative sono divise tra account (un costrutto di alto livello spesso mappato 1:1 con la tua organizzazione) e spazi di lavoro (un livello di isolamento più granulare che può essere mappato in vari modi, ad esempio per LOB). Diamo un'occhiata alla separazione dei compiti tra questi tre ruoli.
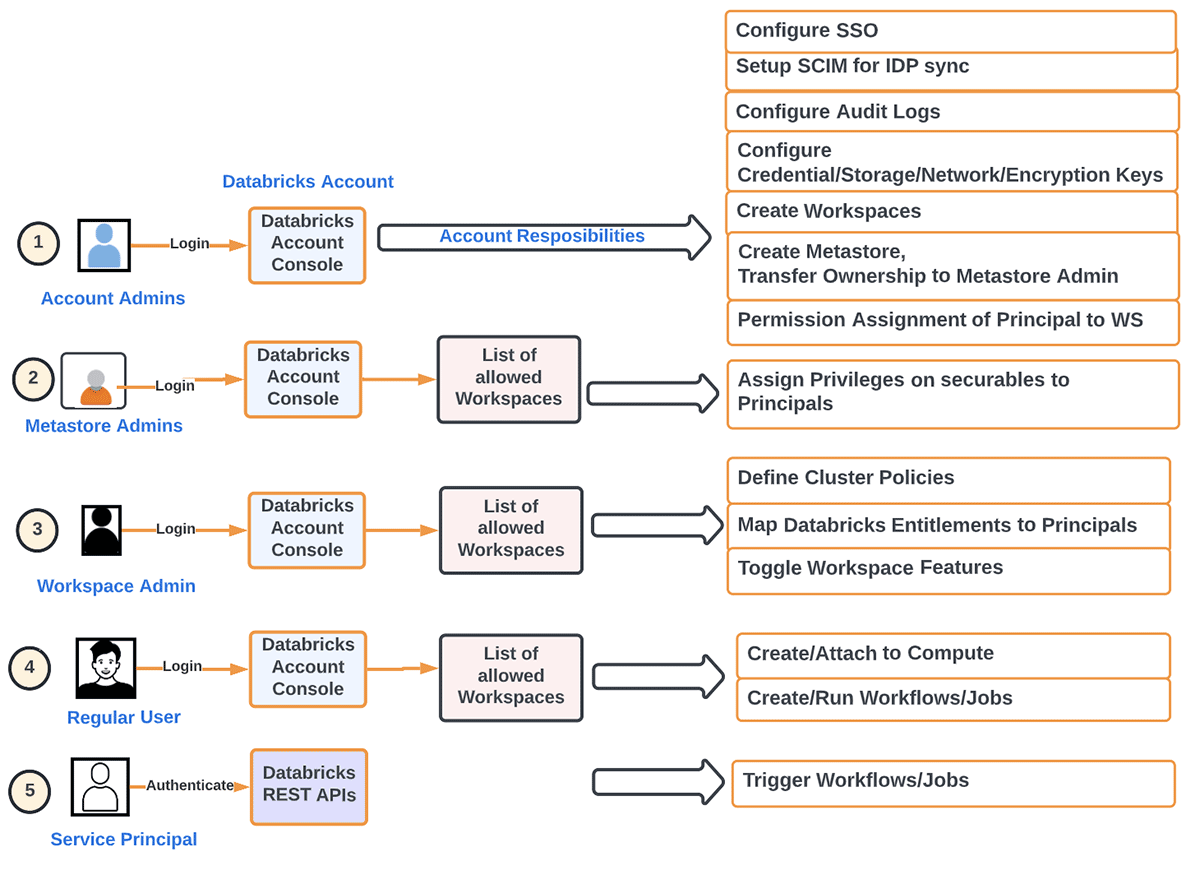
Per dirla in un altro modo, possiamo scomporre le responsabilità primarie di un Amministratore di Account come segue:
- Provisioning di Principal (Gruppi/Utenti/Servizi) e SSO a livello di account. Identity Federation si riferisce all'assegnazione di Identità a Livello di Account l'accesso agli spazi di lavoro direttamente dall'account.
- Configurazione dei Metastore
- Impostazione del Log di Audit
- Monitoraggio dell'Utilizzo a livello di Account (DBU, Fatturazione)
- Creazione di spazi di lavoro secondo il metodo di organizzazione desiderato
- Gestione di altri oggetti a livello di spazio di lavoro (storage, credenziali, rete, ecc.)
- Automazione dei carichi di lavoro di sviluppo utilizzando IaaC per rimuovere l'elemento umano nei carichi di lavoro di produzione
- Attivazione/disattivazione di funzionalità a livello di Account come carichi di lavoro serverless, Delta sharing
D'altra parte, le preoccupazioni primarie di un Amministratore dello Spazio di Lavoro sono:
- Assegnazione di Ruoli appropriati (Utente/Amministratore) a livello di spazio di lavoro ai Principal
- Assegnazione di Autorizzazioni appropriate (ACL) a livello di spazio di lavoro ai Principal
- Impostazione opzionale di SSO a livello di spazio di lavoro
- Definizione di Cluster Policies per autorizzare i Principal a consentire loro di
- Definire risorse di compute (Cluster/Warehouse/Pool)
- Definire Orchestrazione (Job/Pipeline/Workflow)
- Attivazione/disattivazione di funzionalità a livello di Spazio di Lavoro
- Assegnazione di autorizzazioni ai Principal
- Accesso ai Dati (quando si utilizza un metastore hive interno/esterno)
- Gestire l'accesso dei Principal alle risorse di compute
- Gestione di URL esterni per funzionalità come Repos (incluso l'allow-listing)
- Controllo della sicurezza e della protezione dei dati
- Disattivare/limitare DBFS per prevenire l'esposizione accidentale di dati tra team
- Impedire il download dei dati dei risultati (da notebook/DBSQL) per prevenire l'esfiltrazione di dati
- Abilitare Controllo degli Accessi (Oggetti dello Spazio di Lavoro, Cluster, Pool, Job, Tabelle ecc.)
- Definizione della consegna dei log a livello di cluster (ad esempio, impostazione dello storage per i log dei cluster, idealmente tramite Cluster Policies)
Per riassumere le differenze tra l'amministratore di account e quello dello spazio di lavoro, la tabella seguente cattura la separazione tra queste due persone per alcune dimensioni chiave:
| Amministratore di Account | Amministratore di Metastore | Amministratore dello Spazio di Lavoro | |
|---|---|---|---|
| Gestione dello Spazio di Lavoro | - Creazione, Aggiornamento, Eliminazione di spazi di lavoro - Può aggiungere altri amministratori |
Non Applicabile | - Gestisce solo gli asset all'interno di uno spazio di lavoro |
| Gestione Utenti | - Creazione di utenti, gruppi e service principal o utilizzo di SCIM per sincronizzare i dati dagli IDP. - Autorizzazione dei Principal agli Spazi di Lavoro tramite l'API di Assegnazione Permessi |
Non Applicabile | - Raccomandiamo l'uso di UC per la governance centralizzata di tutti i tuoi asset di dati (securables). L'Identity Federation sarà attiva per qualsiasi spazio di lavoro collegato a un Metastore Unity Catalog (UC). - Per gli spazi di lavoro abilitati sull'Identity Federation, impostare SCIM a livello di Account per tutti i Principal e interrompere SCIM a livello di Spazio di Lavoro. - Per gli Spazi di Lavoro non-UC, è possibile utilizzare SCIM a livello di spazio di lavoro (ma questi utenti verranno promossi anche a identità a livello di account). - I gruppi creati a livello di spazio di lavoro saranno considerati gruppi "locali" dello spazio di lavoro e non avranno accesso a Unity Catalog |
| Accesso e Gestione Dati | - Creazione di Metastore(s) - Collegamento di Spazi di Lavoro a Metastore - Trasferimento della proprietà del metastore all'Amministratore/gruppo di Metastore |
Con Unity Catalog: - Gestione dei privilegi su tutti i securables (catalog, schema, tabelle, viste) del metastore - GRANT (Delega) Accesso a Cataloghi, Schemi (Database), Tabelle, Viste, Posizioni Esterne e Credenziali di Storage a Data Steward/Proprietari |
- Oggi, con i metastore Hive, i clienti utilizzano una varietà di costrutti per proteggere l'accesso ai dati, come Instance Profile su AWS, Service Principal in Azure, ACL di Tabelle, Credential Passthrough, tra gli altri. - Con Unity Catalog, questo viene definito a livello di account e verranno utilizzate le GRANT ANSI per ACL tutti i securables |
| Gestione Cluster | Non Applicabile | Non Applicabile | - Creazione di cluster per varie persone/dimensioni per persone DE/ML/SQL per carichi di lavoro S/M/L - Rimozione dell'autorizzazione allow-cluster-create dal gruppo users predefinito. - Creazione di Cluster Policies, assegnazione di accesso alle policy ai gruppi appropriati - Concessione dell'autorizzazione Can_Use ai gruppi per SQL Warehouse |
| Gestione Workflow | Non Applicabile | Non Applicabile | - Assicurarsi che esistano policy per job/DLT/cluster all-purpose e che i gruppi vi abbiano accesso - Pre-creare cluster per scopi applicativi che gli utenti possono riavviare |
| Gestione Budget | - Impostazione di budget per spazio di lavoro/sku/tag di cluster - Monitoraggio dell'Utilizzo per tag nella Console Account (roadmap) - Tabella di sistema dell'utilizzo fatturabile da interrogare tramite DBSQL (roadmap) |
Non Applicabile | Non Applicabile |
| Ottimizza / Affina | Non applicabile | Non applicabile | - Massimizza il calcolo; Usa l'ultima DBR; Usa Photon - Collabora con i team di Linea di Business/Center Of Excellence per seguire le best practice e le ottimizzazioni per sfruttare al meglio l'investimento in infrastruttura |
Dimensionamento di un workspace per soddisfare le esigenze di calcolo di picco
Il numero massimo di nodi del cluster (indirettamente il job più grande o il numero massimo di job concorrenti) è determinato dal numero massimo di IP disponibili nella VPC e quindi il dimensionamento corretto della VPC è un'importante considerazione di progettazione. Ogni nodo occupa 2 IP (in Azure, AWS). Ecco i dettagli pertinenti per il cloud di tua scelta: AWS, Azure, GCP. Utilizzeremo un esempio da Databricks su AWS per illustrare questo. Usa questo per mappare CIDR a IP. L'intervallo CIDR della VPC consentito per un workspace E2 è da /25 a /16. Devono essere configurati almeno 2 subnet private in 2 diverse zone di disponibilità. Le maschere di subnet devono essere comprese tra /16 e /17. Le VPC sono unità di isolamento logico e finché 2 VPC non hanno bisogno di comunicare, cioè di essere collegate tra loro, possono avere lo stesso intervallo. Tuttavia, se lo fanno, è necessario prestare attenzione per evitare sovrapposizioni di IP. Prendiamo un esempio di una VPC con intervallo CIDR /16:
| VPC CIDR /16 | Max # IP per questa VPC: 65.536 | Cluster a nodo singolo/multi-nodo vengono avviati in una subnet |
| 2 AZ | Se ogni AZ è /17: => 32.768 * 2 = 65.536 IP nessuna altra subnet è possibile | 32.768 IP => max 16.384 nodi in ogni subnet |
| Se ogni AZ è invece /23: => 512 * 2 = 1.024 IP 65.536 - 1.024 = 64.512 IP rimasti | 512 IP => max 256 nodi in ogni subnet | |
| 4 AZ | Se ogni AZ è /18: 16.384 * 4 = 65.536 IP nessuna altra subnet è possibile | 16.384 IP => max 8192 nodi in ogni subnet |
Bilanciamento tra controllo e agilità per gli amministratori di workspace
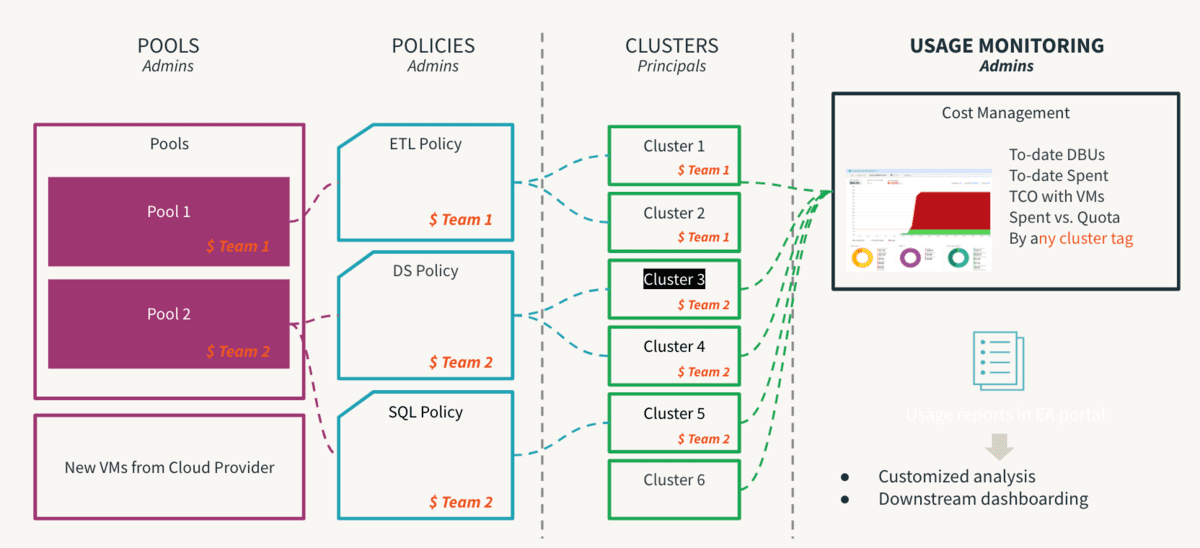
Il calcolo è la componente più costosa di qualsiasi investimento in infrastruttura cloud. La democratizzazione dei dati porta all'innovazione e la facilitazione dell'autoservizio è il primo passo verso l'abilitazione di una cultura basata sui dati. Tuttavia, in un ambiente multi-tenant, un utente inesperto o un errore umano involontario potrebbero portare a costi fuori controllo o a esposizioni involontarie. Se i controlli sono troppo restrittivi, creeranno colli di bottiglia nell'accesso e soffocheranno l'innovazione. Pertanto, gli amministratori devono impostare delle linee guida per consentire l'autoservizio senza i rischi intrinseci. Inoltre, dovrebbero essere in grado di monitorare l'adesione a questi controlli. È qui che le Politiche dei Cluster tornano utili, dove vengono definite le regole e mappati i diritti in modo che l'utente operi all'interno di perimetri consentiti e il suo processo decisionale sia notevolmente semplificato. Va notato che le politiche dovrebbero essere supportate da processi per essere veramente efficaci, in modo che le eccezioni una tantum possano essere gestite dal processo per evitare caos non necessari. Un passo critico di questo processo è rimuovere il diritto di allow-cluster-create dal gruppo users predefinito in un workspace, in modo che gli utenti possano utilizzare solo il calcolo governato dalle Politiche dei Cluster. Di seguito sono riportate le principali raccomandazioni delle Best Practice per le Politiche dei Cluster e possono essere riassunte come segue:
- Utilizza le dimensioni standard (taglie di magliette) per fornire modelli di cluster standard
- Per dimensione del carico di lavoro (piccolo, medio, grande)
- Per persona (DE/ ML/ BI)
- Per competenza (cittadino/ avanzato)
- Gestisci la governance imponendo l'uso di
- Tag: attribuzione per team, utente, caso d'uso
- la denominazione deve essere standardizzata
- rendere alcuni attributi obbligatori aiuta per una reportistica coerente
- Tag: attribuzione per team, utente, caso d'uso
- Controlla il consumo limitando
- Tasso di consumo DBU e scopo della policy
- Timeout di auto-terminazione, dimensione minima/massima di scalabilità
Considerazioni sul calcolo
A differenza dell'infrastruttura di calcolo on-premise fissa, il cloud ci offre elasticità e flessibilità per abbinare il calcolo giusto al carico di lavoro e all'SLA in considerazione. Il diagramma sottostante mostra le varie opzioni. Gli input sono parametri come il tipo di carico di lavoro o ambiente e l'output è il tipo e la dimensione del calcolo che si adatta meglio.
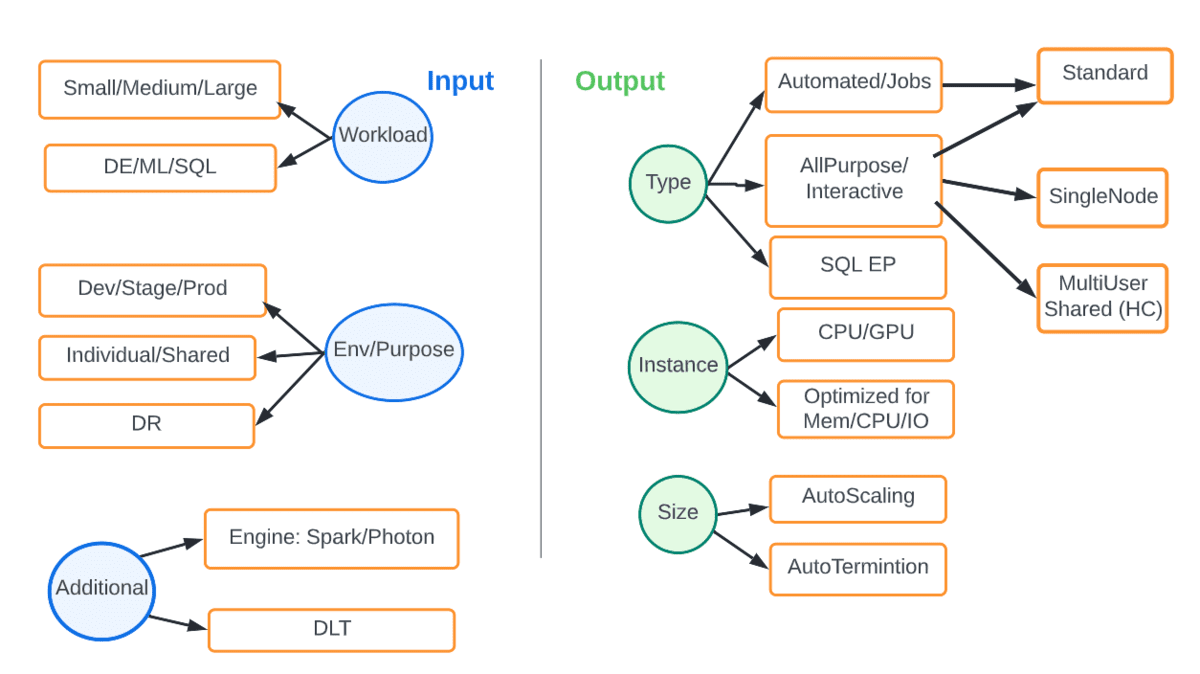
Ad esempio, un carico di lavoro di produzione DE dovrebbe sempre essere su cluster di job automatizzati, preferibilmente con l'ultima DBR, con autoscaling e utilizzando il motore Photon. La tabella seguente cattura alcuni scenari comuni.
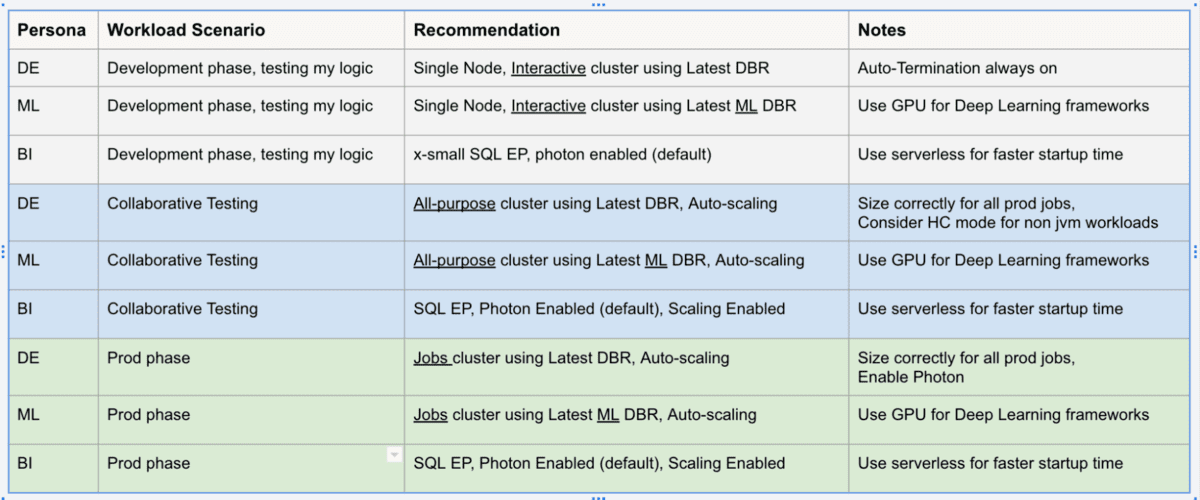
Considerazioni sul flusso di lavoro
Ora che i requisiti di calcolo sono stati formalizzati, dobbiamo esaminare
- Come verranno definiti e attivati i flussi di lavoro
- Come i task possono riutilizzare il calcolo tra di loro
- Come verranno gestite le dipendenze dei task
- Come verranno ritentati i task falliti
- Come verranno applicati gli aggiornamenti di versione (spark, libreria) e le patch
Queste sono considerazioni di Data Engineering e DevOps incentrate sul caso d'uso e sono tipicamente una preoccupazione diretta di un amministratore. Ci sono alcune attività igieniche che possono essere monitorate come
- Un workspace ha un limite massimo sul numero totale di job configurati. Ma molti di questi job potrebbero non essere invocati e devono essere ripuliti per fare spazio a quelli genuini. Un amministratore può eseguire controlli per determinare l'elenco di evacuazione valido dei job inattivi.
- Tutti i job di produzione dovrebbero essere eseguiti come service principal e l'accesso utente a un ambiente di produzione dovrebbe essere altamente limitato. Rivedi le autorizzazioni dei job.
- I job possono fallire, quindi ogni job dovrebbe essere impostato per avvisi di fallimento e opzionalmente per ritentativi. Rivedi le proprietà email_notifications, max_retries e altre qui
- Ogni job dovrebbe essere associato a politiche dei cluster e taggato correttamente per l'attribuzione.
DLT: Esempio di un framework ideale per pipeline affidabili su larga scala
Lavorando con migliaia di clienti, grandi e piccoli, in diversi settori industriali, sono diventate evidenti le sfide comuni relative ai dati per lo sviluppo e l'operatività, motivo per cui Databricks ha creato Delta Live Tables (DLT). È una piattaforma gestita che offre di semplificare lo sviluppo e la manutenzione dei carichi di lavoro ETL consentendo la creazione di pipeline dichiarative in cui si specifica il 'cosa' e non il 'come'. Questo semplifica i compiti di un data engineer, portando a meno scenari di supporto per gli amministratori.
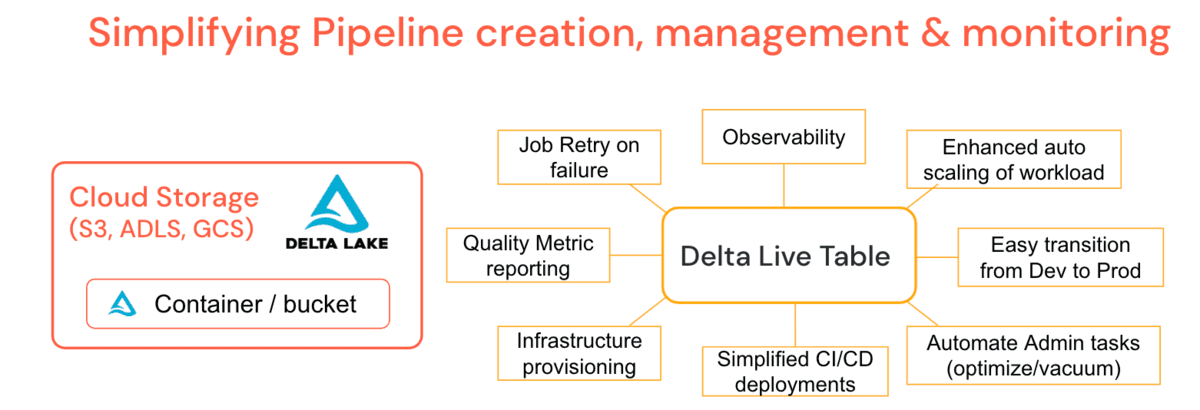
DLT integra funzionalità comuni di amministrazione come i processi periodici di optimize e vacuum direttamente nella definizione della pipeline con un processo di manutenzione che garantisce l'esecuzione senza supervisione aggiuntiva. DLT offre una profonda osservabilità delle pipeline per operazioni semplificate come la lineage, il monitoraggio e i controlli sulla qualità dei dati. Ad esempio, se il cluster si interrompe, la piattaforma riprova automaticamente (in modalità Produzione) invece di fare affidamento sull'ingegnere dei dati che lo ha provisionato esplicitamente. L'Auto-Scaling Avanzato può gestire picchi improvvisi di dati che richiedono un aumento delle dimensioni del cluster e ridursi gradualmente. In altre parole, il ridimensionamento automatico del cluster e la tolleranza ai guasti della pipeline sono funzionalità della piattaforma. Le latenze configurabili consentono di eseguire pipeline in modalità batch o streaming e di spostare le pipeline di sviluppo in produzione con relativa facilità gestendo la configurazione anziché il codice. È possibile controllare il costo delle pipeline utilizzando le Policy Cluster specifiche per DLT. DLT inoltre aggiorna automaticamente il motore di runtime, eliminando la responsabilità dagli amministratori o dagli ingegneri dei dati e consentendo di concentrarsi solo sulla generazione di valore aziendale.
UC: Esempio di un framework ideale di Data Governance
Unity Catalog (UC) consente alle organizzazioni di adottare un modello di sicurezza comune per tabelle e file per tutti gli spazi di lavoro sotto un unico account, cosa che prima non era possibile tramite semplici istruzioni GRANT. Concedendo e controllando tutto l'accesso ai dati, alle tabelle o ai file, da un cluster DE/DS o da un SQL Warehouse, le organizzazioni possono semplificare la propria strategia di audit e monitoraggio senza fare affidamento su primitive per-cloud. Le principali funzionalità offerte da UC includono:
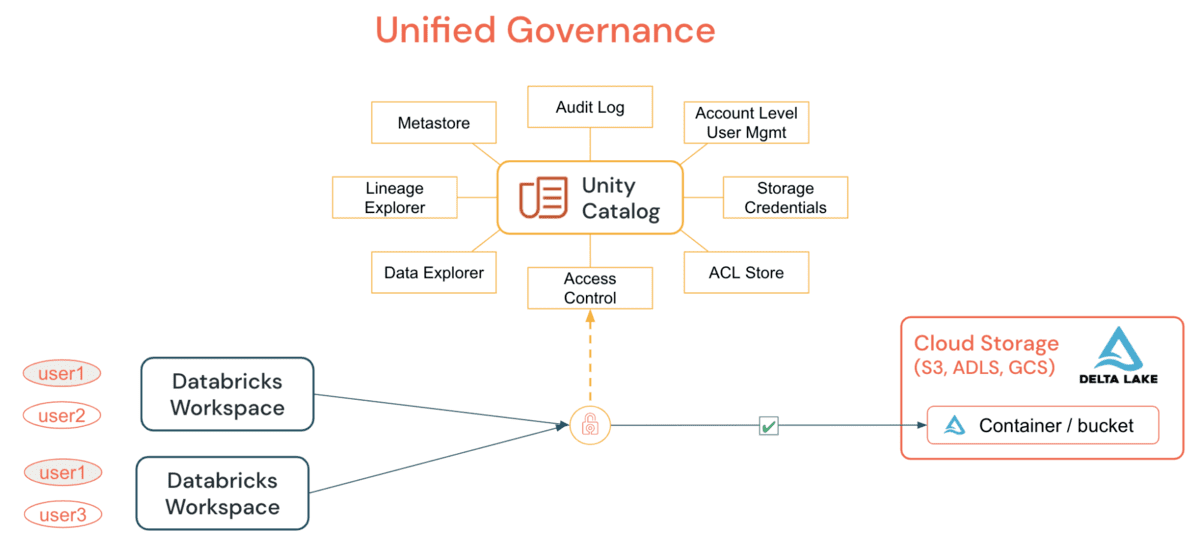
UC semplifica il lavoro di un amministratore (sia a livello di account che di spazio di lavoro) centralizzando le definizioni, il monitoraggio e la reperibilità dei dati attraverso il metastore, e rendendo facile la condivisione sicura dei dati indipendentemente dal numero di spazi di lavoro ad esso collegati. Utilizzando il modello Definisci una volta, Sicuro ovunque, questo ha il vantaggio aggiuntivo di evitare l'esposizione accidentale dei dati nello scenario in cui i privilegi di un utente siano inavvertitamente travisati in uno spazio di lavoro, il che potrebbe fornire loro un backdoor per accedere a dati non destinati al loro consumo. Tutto ciò può essere realizzato facilmente utilizzando le Identità a Livello di Account e le Autorizzazioni sui Dati. L'Audit Logging di UC consente una visibilità completa su tutte le azioni di tutti gli utenti a tutti i livelli su tutti gli oggetti, e se si configura l'audit logging dettagliato, allora ogni comando eseguito, da un notebook o Databricks SQL, viene catturato. L'accesso ai securables può essere concesso da un amministratore del metastore, dal proprietario di un oggetto, o dal proprietario del catalogo o dello schema che contiene l'oggetto. Si raccomanda che l'amministratore a livello di account deleghi il ruolo di metastore nominando un gruppo come amministratori del metastore il cui unico scopo è concedere i giusti privilegi di accesso.
Raccomandazioni e best practice
- I ruoli e le responsabilità degli amministratori di account, degli amministratori del metastore e degli amministratori degli spazi di lavoro sono ben definiti e complementari. Flussi di lavoro come automazione, richieste di modifica, escalation, ecc. dovrebbero essere indirizzati ai proprietari appropriati, sia che gli spazi di lavoro siano configurati da LOB o gestiti da un Center of Excellence centrale.
- Le Identità a Livello di Account dovrebbero essere abilitate poiché consentono la gestione centralizzata dei principali per tutti gli spazi di lavoro, semplificando così l'amministrazione. Si consiglia di configurare funzionalità come SSO, SCIM e Audit Logs a livello di account. L'SSO a livello di spazio di lavoro è ancora necessario, fino a quando la funzionalità SSO Federation non sarà disponibile.
- Le Policy Cluster sono uno strumento potente che fornisce guardrail per un self-service efficace e semplifica notevolmente il ruolo di un amministratore di spazio di lavoro. Forniamo alcune policy di esempio qui. L'amministratore di account dovrebbe fornire policy predefinite semplici basate sulla persona principale/taglia, idealmente tramite automazione come Terraform. Gli amministratori degli spazi di lavoro possono aggiungere a quell'elenco per controlli più granulari. Combinato con un processo adeguato, tutti gli scenari di eccezione possono essere gestiti con grazia.
- Il monitoraggio del consumo in corso per tutti i tipi di carico di lavoro in tutti gli spazi di lavoro è visibile agli amministratori di account tramite la console degli account. Si consiglia di configurare la consegna del log di utilizzo fatturabile in modo che tutto vada nel proprio storage cloud centrale per la ripartizione dei costi e l'analisi. L'API Budget (in anteprima) dovrebbe essere configurata a livello di account, il che consente agli amministratori di account di creare soglie a livello di spazi di lavoro, SKU e tag cluster e ricevere avvisi sul consumo in modo che azioni tempestive possano essere intraprese per rimanere entro i budget allocati. Utilizzare uno strumento come Overwatch per monitorare l'utilizzo a un livello ancora più granulare per aiutare a identificare aree di miglioramento per quanto riguarda l'utilizzo delle risorse di calcolo.
- La piattaforma Databricks continua a innovare e semplificare il lavoro delle varie persone dei dati astraendo le funzionalità amministrative comuni nella piattaforma. La nostra raccomandazione è di utilizzare Delta Live Tables per le nuove pipeline e Unity Catalog per tutta la gestione degli utenti e il controllo degli accessi ai dati.
Infine, è importante notare che per la maggior parte di queste best practice, e di fatto, la maggior parte delle cose che menzioniamo in questo blog, coordinamento e lavoro di squadra sono fondamentali per il successo. Sebbene sia teoricamente possibile che gli amministratori di account e workspace esistano in un silo, ciò non solo va contro i principi generali del Lakehouse, ma rende la vita più difficile a tutti i soggetti coinvolti. Forse il suggerimento più importante da trarre da questo articolo è quello di connettere amministratori di account/workspace + responsabili di progetto/dati + utenti all'interno della propria organizzazione. Meccanismi come canali Teams/Slack, un alias di posta elettronica e/o un incontro settimanale hanno dimostrato di avere successo. Le organizzazioni più efficaci che vediamo qui in Databricks sono quelle che abbracciano l'apertura non solo nella loro tecnologia, ma anche nelle loro operazioni. Tieni d'occhio altri blog incentrati sugli amministratori in arrivo, dalle raccomandazioni di logging ed esfiltrazione a entusiasmanti riepiloghi delle nostre funzionalità della piattaforma incentrate sulla gestione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.