Creazione di prodotti di dati geospaziali
di Milos Colic
Questo post del blog è obsoleto. Fare riferimento a questo post del blog su Spatial SQL per approcci aggiornati all'archiviazione e all'elaborazione di dati geospaziali all'interno del Databricks Lakehouse.
I dati geospaziali guidano l'innovazione da secoli, attraverso l'uso di mappe, cartografia e più recentemente attraverso contenuti digitali. Ad esempio, la mappa più antica è stata trovata incisa su un pezzo di zanna di mammut e risale a circa 25000 a.C.. Questo rende i dati geospaziali una delle più antiche fonti di dati utilizzate dalla società per prendere decisioni. Un esempio più recente, etichettato come la nascita dell'analisi spaziale, è quello di Charles Picquet nel 1832 che ha utilizzato dati geospaziali per analizzare le epidemie di colera a Parigi, un paio di decenni dopo John Snow nel 1854 seguì lo stesso approccio per le epidemie di colera a Londra. Questi due individui hanno utilizzato dati geospaziali per risolvere uno dei problemi più difficili del loro tempo e, di fatto, salvare innumerevoli vite. Velocemente proiettandoci al XX secolo, il concetto di Sistemi Informativi Geografici (GIS) è stato introdotto per la prima volta nel 1967 a Ottawa, Canada, dal Dipartimento di Silvicoltura e Sviluppo Rurale.
Oggi siamo nel mezzo della rivoluzione dell'industria del cloud computing: supercalcolo su larga scala disponibile per qualsiasi organizzazione, virtualmente scalabile all'infinito sia per lo storage che per il calcolo. Concetti come data mesh e data marketplace stanno emergendo nella comunità dei dati per affrontare questioni come la federazione delle piattaforme e l'interoperabilità. Come possiamo adottare questi concetti per i dati geospaziali, l'analisi spaziale e i sistemi GIS? Adottando il concetto di data product e approcciando la progettazione dei dati geospaziali come un prodotto.
In questo post del blog forniremo un punto di vista su come progettare data product geospaziali scalabili, moderni e robusti. Discuteremo come la Databricks Lakehouse Platform può essere utilizzata per sbloccare il pieno potenziale dei prodotti geospaziali che sono tra gli asset più preziosi per risolvere i problemi più difficili di oggi e del futuro.
Cos'è un data product? E come progettarne uno?
La definizione più ampia e concisa di "data product" è stata coniata da DJ Patil (il primo U.S. Chief Data Scientist) in Data Jujitsu: The Art of Turning Data into Product: "un prodotto che facilita un obiettivo finale attraverso l'uso dei dati". La complessità di questa definizione (come ammesso da Patil stesso) è necessaria per racchiudere l'ampiezza dei possibili prodotti, per includere dashboard, report, fogli di calcolo Excel e persino estratti CSV condivisi via email. Potreste notare che gli esempi forniti si deteriorano rapidamente in termini di qualità, robustezza e governance.
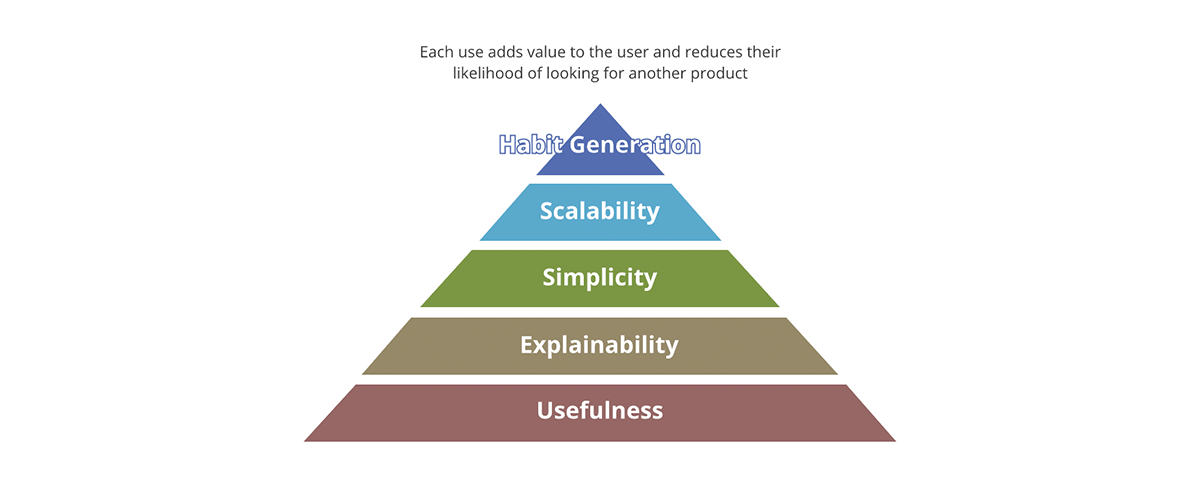
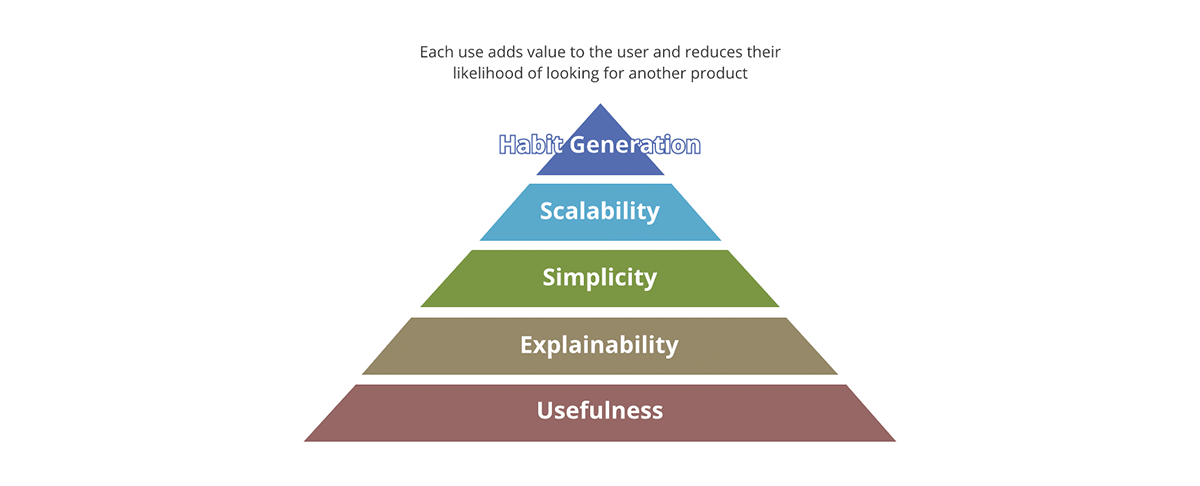
Quali sono i concetti che differenziano un prodotto di successo da uno non riuscito? È il packaging? È il contenuto? È la qualità del contenuto? O è solo l'adozione del prodotto sul mercato? Forbes definisce i 10 requisiti essenziali di un prodotto di successo. Un buon framework per riassumere questo è attraverso la piramide del valore.
{kind=link}
La piramide del valore fornisce una priorità su ogni aspetto del prodotto. Non ogni domanda sul valore che poniamo riguardo al prodotto ha lo stesso peso. Se l'output non è utile, nessuno degli altri aspetti conta: l'output non è veramente un prodotto ma diventa più un inquinante di dati nel pool di risultati utili. Allo stesso modo, la scalabilità ha importanza solo dopo che sono state affrontate la semplicità e la spiegabilità.
Come si relaziona la piramide del valore ai data product? Ogni output di dati, per essere un data product:
- Dovrebbe avere una chiara utilità. La quantità di dati che la società sta generando è rivaleggiata solo dalla quantità di inquinanti di dati che stiamo generando. Questi sono output privi di chiaro valore e utilità, tanto meno una strategia su cosa farne.
- Dovrebbe essere spiegabile. Con l'emergere dell'AI/ML, la spiegabilità è diventata ancora più importante per il processo decisionale basato sui dati. I dati sono buoni quanto i metadati che li descrivono. Pensatela in termini di cibo: il gusto conta, ma un fattore più importante è il valore nutrizionale degli ingredienti.
- Dovrebbe essere semplice. Un esempio di uso improprio di un prodotto è usare una forchetta per mangiare i cereali invece di un cucchiaio. Inoltre, la semplicità è essenziale ma non sufficiente; oltre alla semplicità, i prodotti dovrebbero essere intuitivi. Ove possibile, sia gli usi previsti che quelli imprevisti dei dati dovrebbero essere ovvi.
- Dovrebbe essere scalabile. I dati sono una delle poche risorse che crescono con l'uso. Più dati si elaborano, più dati si hanno. Se sia gli input che gli output del sistema sono illimitati e in continua crescita, allora il sistema deve essere scalabile in termini di potenza di calcolo, capacità di archiviazione e potenza espressiva del calcolo. Le piattaforme dati cloud come Databricks sono in una posizione unica per rispondere a tutti e tre gli aspetti.
- Dovrebbe generare abitudini. Nel dominio dei dati non ci preoccupiamo della fidelizzazione dei clienti come nel caso dei prodotti al dettaglio. Tuttavia, il valore della generazione di abitudini è ovvio se applicato alle best practice. I sistemi e gli output dei dati dovrebbero esibire le best practice e promuoverle - dovrebbe essere più facile usare i dati e il sistema nel modo previsto che il contrario.
I dati geospaziali dovrebbero aderire a tutti gli aspetti sopra menzionati, come dovrebbero fare tutti i data product. Oltre a questo ordine elevato, i dati geospaziali hanno alcune esigenze specifiche.
Standard per i dati geospaziali
Gli standard per i dati geospaziali vengono utilizzati per garantire che i dati geografici vengano raccolti, organizzati e condivisi in modo coerente e affidabile. Questi standard possono includere linee guida per cose come il formato dei dati, i sistemi di coordinate, le proiezioni delle mappe e i metadati. L'adesione agli standard facilita la condivisione dei dati tra diverse organizzazioni, consentendo una maggiore collaborazione e un più ampio accesso alle informazioni geografiche.
La Geospatial Commission (Governo del Regno Unito) ha definito il UK Geospatial Data Standards Register come un repository centrale per gli standard dei dati da applicare nel caso di dati geospaziali. Inoltre, la missione di questo registro è:
- "Garantire che i dati geospaziali del Regno Unito siano più coerenti, coesi e utilizzabili attraverso una gamma più ampia di sistemi." - Questi concetti sono un richiamo all'importanza della spiegabilità, dell'utilità e della generazione di abitudini (possibilmente altri aspetti della piramide del valore).
- "Consentire alla comunità geospaziale del Regno Unito di essere più coinvolta con gli standard e gli organismi di standardizzazione pertinenti." - La generazione di abitudini all'interno della comunità è importante quanto la progettazione robusta e critica dello standard. Se non adottati, gli standard sono inutili.
- "Promuovere la comprensione e l'uso degli standard dei dati geospaziali all'interno di altri settori del governo." - La piramide del valore si applica anche agli standard: concetti come la facilità di adesione (utilità/semplicità), lo scopo dello standard (spiegabilità/utilità), l'adozione (generazione di abitudini) sono critici per la generazione di valore di uno standard.
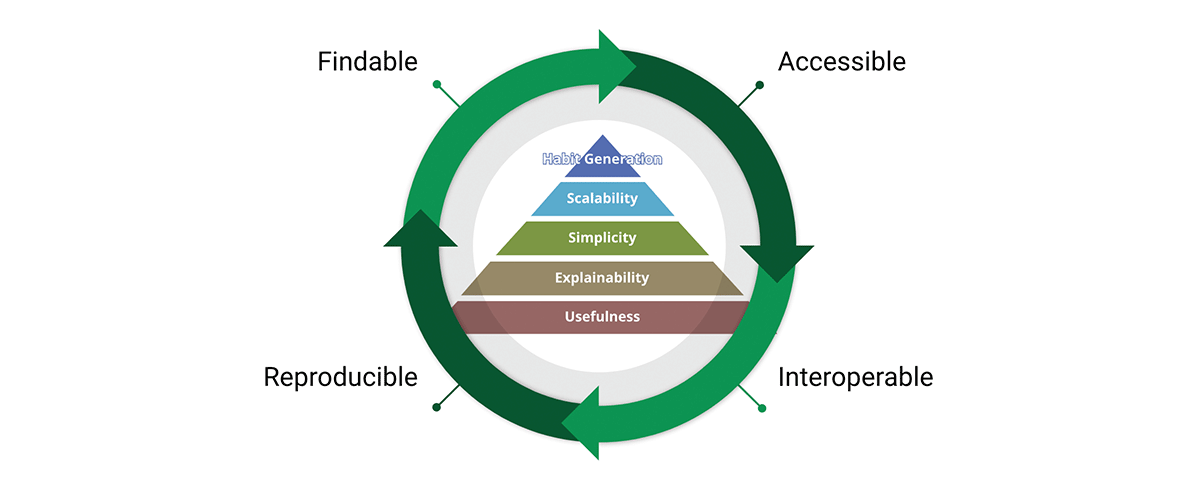
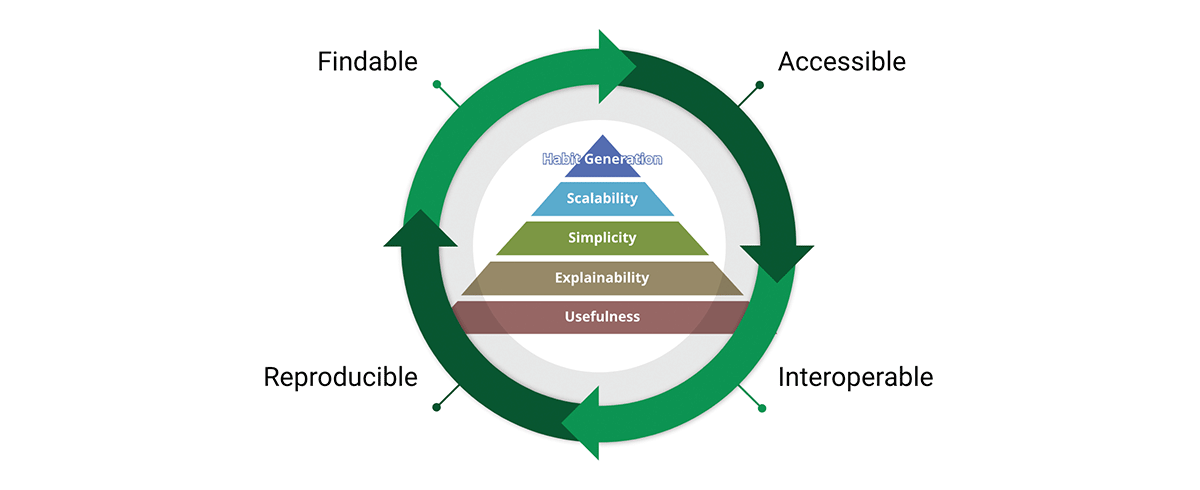
Uno strumento critico per raggiungere la missione degli standard dei dati sono i principi dei dati FAIR:
- Findable (Trovabile) - Il primo passo per (ri)utilizzare i dati è trovarli. Metadati e dati dovrebbero essere facili da trovare sia per gli esseri umani che per i computer. Metadati leggibili dalla macchina sono essenziali per la scoperta automatica di dataset e servizi.
- Accessible (Accessibile) - Una volta che l'utente trova i dati richiesti, deve sapere come accedervi, inclusi eventualmente autenticazione e autorizzazione.
- Interoperabile - I dati di solito devono essere integrati con altri dati. Inoltre, i dati devono interoperare con applicazioni o flussi di lavoro per l'analisi, l'archiviazione e l'elaborazione.
- Riutilizzabile - L'obiettivo finale di FAIR è ottimizzare il riutilizzo dei dati. Per raggiungere questo obiettivo, metadati e dati devono essere ben descritti in modo che possano essere replicati e/o combinati in contesti diversi.
Condividiamo la convinzione che i principi FAIR siano cruciali per la progettazione di prodotti di dati scalabili di cui ci si possa fidare. Per essere chiari, FAIR si basa sul buon senso, quindi perché è fondamentale per le nostre considerazioni? "Ciò che vedo in FAIR non è nuovo in sé, ma ciò che fa bene è articolare, in modo accessibile, la necessità di un approccio olistico al miglioramento dei dati. Questa facilità di comunicazione è il motivo per cui FAIR viene utilizzato sempre più ampiamente come ombrello per il miglioramento dei dati - e non solo nella comunità geospaziale." - A FAIR wind sets our course for data improvement.
Per supportare ulteriormente questo approccio, il Federal Geographic Data Committee ha sviluppato il National Spatial Data Infrastructure (NSDI) Strategic Plan che copre gli anni 2021-2024 ed è stato approvato nel novembre 2020. Gli obiettivi dell'NSDI sono in sostanza i principi FAIR e trasmettono lo stesso messaggio di progettazione di sistemi che promuovono l'economia circolare dei dati - prodotti di dati che fluiscono tra le organizzazioni seguendo standard comuni e in ogni fase della catena di approvvigionamento dei dati sbloccano nuovo valore e nuove opportunità. Il fatto che questi principi stiano permeando diverse giurisdizioni e vengano adottati da diversi regolatori è una testimonianza della robustezza e della solidità dell'approccio.

{kind=link}
I concetti FAIR si intrecciano molto bene con la progettazione di prodotti di dati. Infatti, FAIR attraversa l'intera piramide del valore del prodotto e forma un ciclo di valore. Adottando sia la piramide del valore che i principi FAIR, progettiamo prodotti di dati con una prospettiva sia interna che esterna. Questo promuove il riutilizzo dei dati anziché l'accumulo di dati.
{kind=link}
Perché i principi FAIR sono importanti per i dati geospaziali e i prodotti di dati geospaziali? FAIR è trascendente ai dati geospaziali, è in realtà trascendente ai dati, è un sistema di principi guida semplice ma coerente per una buona progettazione - e che una buona progettazione può essere applicata a qualsiasi cosa, inclusi i dati geospaziali e i sistemi geospaziali.
Sistemi di indicizzazione a griglia
Nelle soluzioni GIS tradizionali, le prestazioni delle operazioni spaziali sono solitamente ottenute costruendo strutture ad albero (KD trees, ball trees, Quad trees, ecc.). Il problema degli approcci ad albero è che alla fine infrangono il principio di scalabilità - quando i dati sono troppo grandi per essere elaborati per costruire l'albero e il calcolo richiesto per costruire l'albero è troppo lungo e vanifica lo scopo. Ciò influisce negativamente anche sull'accessibilità dei dati, se non possiamo costruire l'albero non possiamo accedere ai dati completi e di fatto non possiamo riprodurre i risultati. In questo caso, i sistemi di indicizzazione a griglia forniscono una soluzione.
I sistemi di indicizzazione a griglia sono costruiti fin dall'inizio tenendo conto degli aspetti di scalabilità dei dati geospaziali. Invece di costruire alberi, definiscono una serie di griglie che coprono l'area di interesse. Nel caso di H3 (pionierizzato da Uber), la griglia copre l'area della Terra, nel caso di sistemi di indicizzazione a griglia locali (ad es. British National Grid) possono coprire solo l'area specifica di interesse. Queste griglie sono composte da celle che hanno identificatori univoci. Esiste una relazione matematica tra la posizione e la cella nella griglia. Ciò rende i sistemi di indicizzazione a griglia molto scalabili e intrinsecamente paralleli.
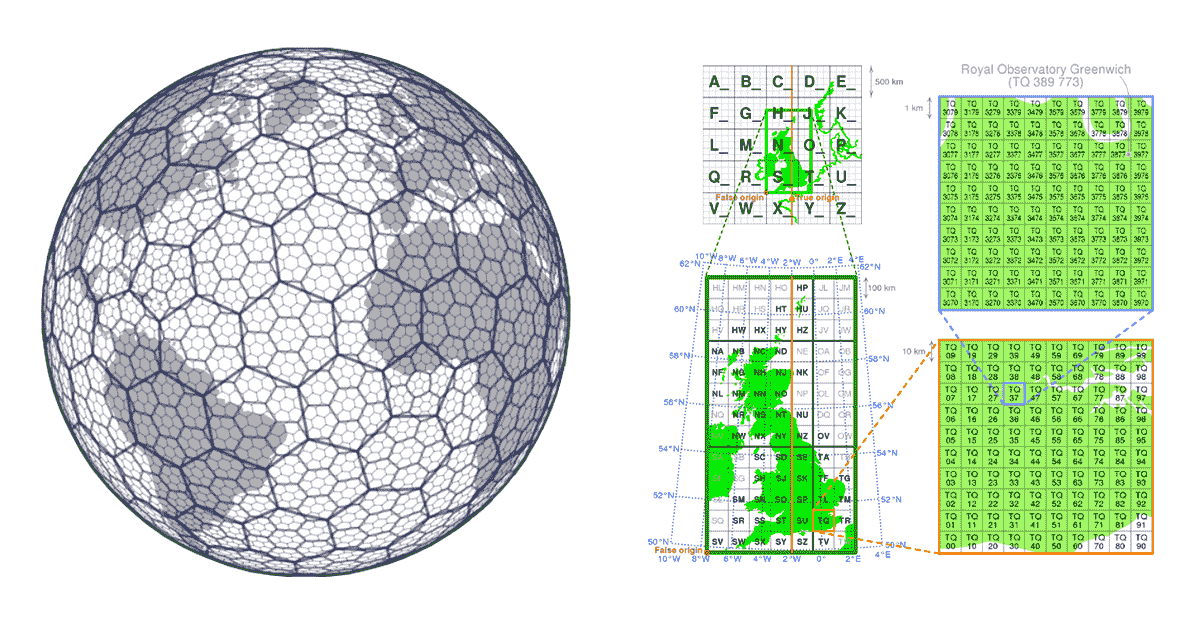
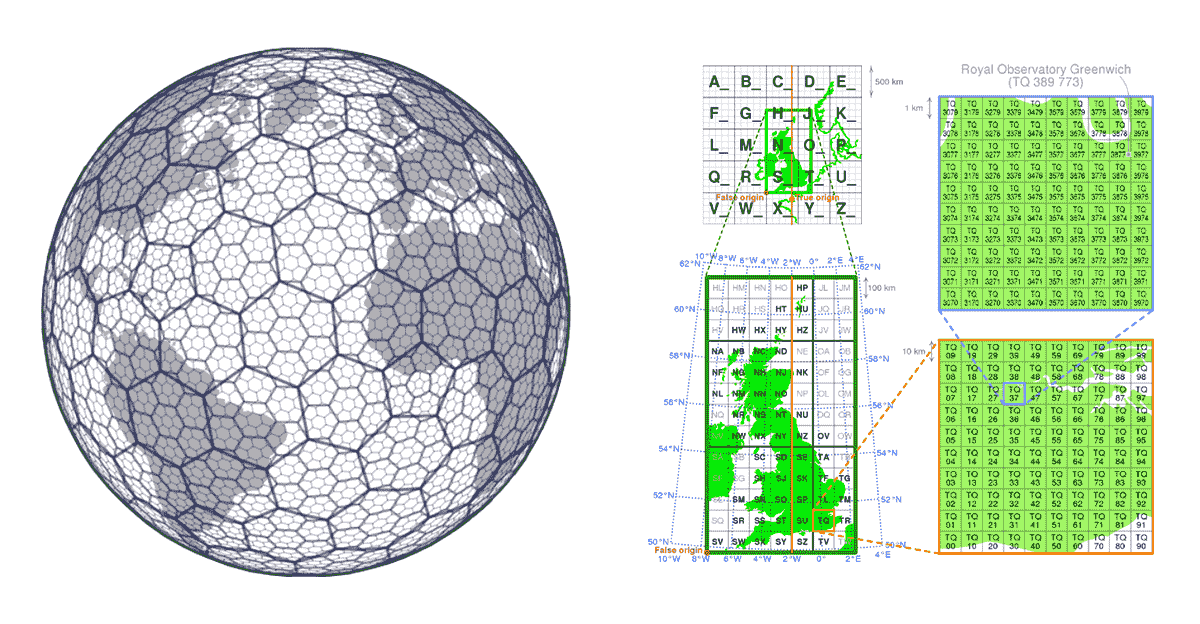{kind=link}
Un altro aspetto importante dei sistemi di indicizzazione a griglia è che sono open source, consentendo ai valori degli indici di essere sfruttati universalmente sia dai produttori che dai consumatori di dati. I dati possono essere arricchiti con le informazioni dell'indice a griglia in qualsiasi fase del loro percorso attraverso la catena di approvvigionamento dei dati. Ciò rende i sistemi di indicizzazione a griglia un esempio di standard di dati guidati dalla comunità. Gli standard di dati guidati dalla comunità per natura non richiedono applicazione, il che aderisce pienamente all'aspetto della generazione di abitudini della piramide del valore e affronta in modo significativo i principi di interoperabilità e accessibilità di FAIR.
{kind=link}
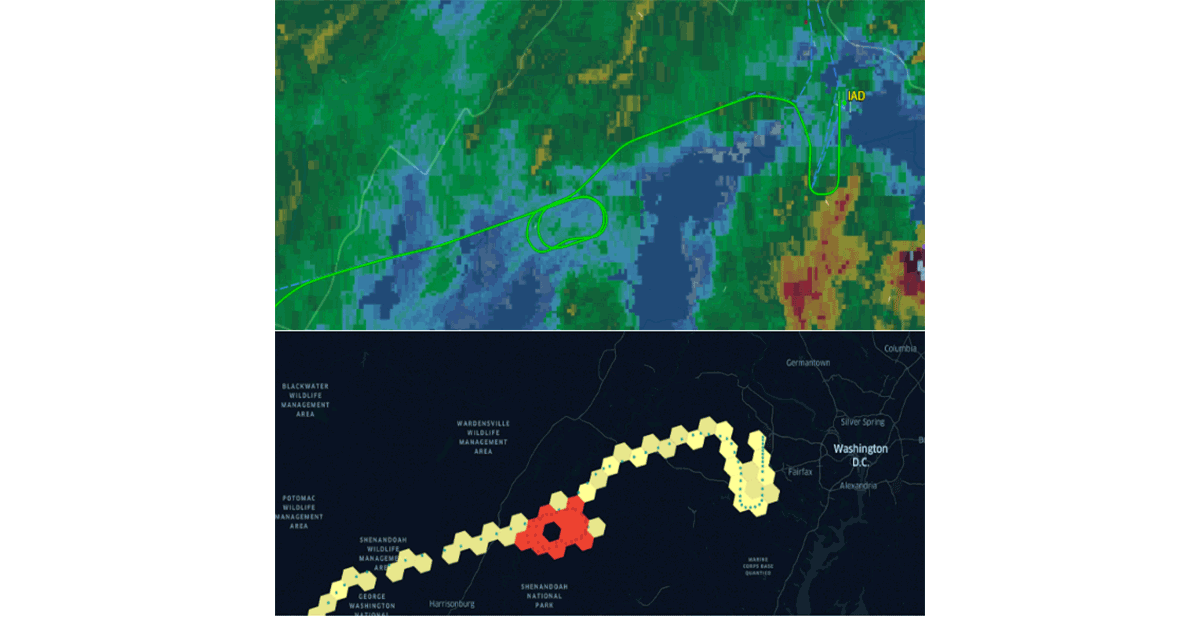
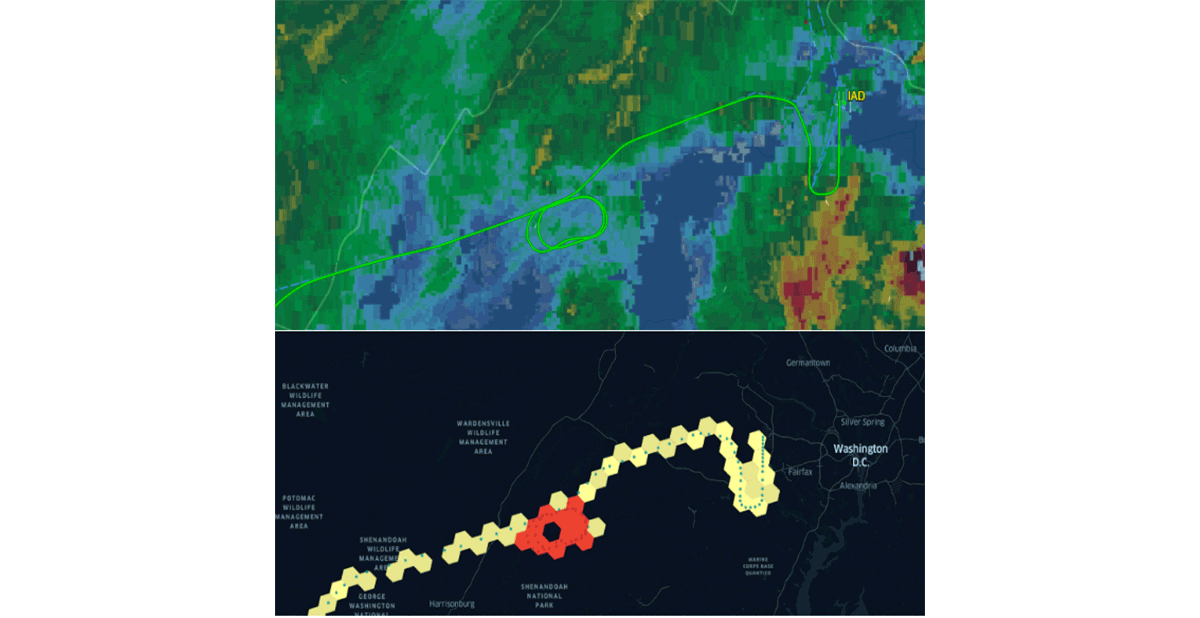
Databricks ha recentemente annunciato il supporto nativo per il sistema di indicizzazione a griglia H3 seguendo la stessa proposta di valore. Adottare standard comuni del settore guidati dalla comunità è l'unico modo per guidare correttamente la generazione di abitudini e l'interoperabilità. Per rafforzare questa affermazione, organizzazioni come CARTO , ESRI e Google hanno promosso l'uso di sistemi di indicizzazione a griglia per la progettazione di sistemi GIS scalabili. Inoltre, il progetto Databricks Labs Mosaic supporta il British National Grid come sistema di indicizzazione a griglia standard ampiamente utilizzato nel governo del Regno Unito. I sistemi di indicizzazione a griglia sono fondamentali per la scalabilità dell'elaborazione dei dati geospaziali e per la corretta progettazione di soluzioni per problemi complessi (ad es. figura 5 - schemi di attesa di volo utilizzando H3).
Diversità dei dati geospaziali
Gli standard dei dati geospaziali dedicano un notevole sforzo alla standardizzazione dei formati dei dati e il formato, peraltro, è una delle considerazioni più importanti quando si tratta di interoperabilità e riproducibilità. Inoltre, se la lettura dei tuoi dati è complessa, come possiamo parlare di semplicità? Sfortunatamente, i formati dei dati geospaziali sono tipicamente complessi, poiché i dati possono essere prodotti in una serie di formati, inclusi formati open source e proprietari. Considerando solo i dati vettoriali, possiamo aspettarci che i dati arrivino in WKT, WKB, GeoJSON, web CSV, CSV, Shape File, GeoPackage e molti altri. D'altra parte, se consideriamo i dati raster, possiamo aspettarci che i dati arrivino in qualsiasi numero di formati come GeoTiff, netCDF, GRIB o GeoDatabase; per un elenco completo dei formati si prega di consultare questo blog.
Il dominio dei dati geospaziali è molto diversificato ed è cresciuto organicamente nel corso degli anni attorno ai casi d'uso che affrontava. L'unificazione di un ecosistema così diversificato è una sfida enorme. Un recente sforzo dell'Open Geospatial Consortium (OGC) per standardizzare su Apache Parquet e la sua specifica di schema geospaziale GeoParquet è un passo nella giusta direzione. La semplicità è uno degli aspetti chiave nella progettazione di un prodotto buono, scalabile e robusto: l'unificazione porta semplicità e affronta una delle principali fonti di attrito nell'ecosistema: l'ingestione dei dati. La standardizzazione su GeoParquet porta molto valore che affronta tutti gli aspetti dei dati FAIR e della piramide del valore.
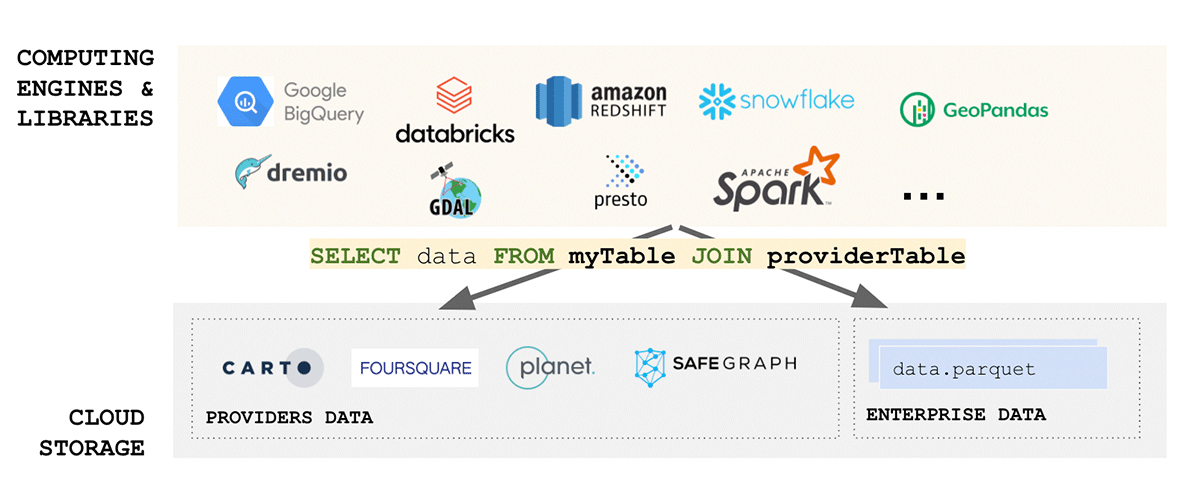
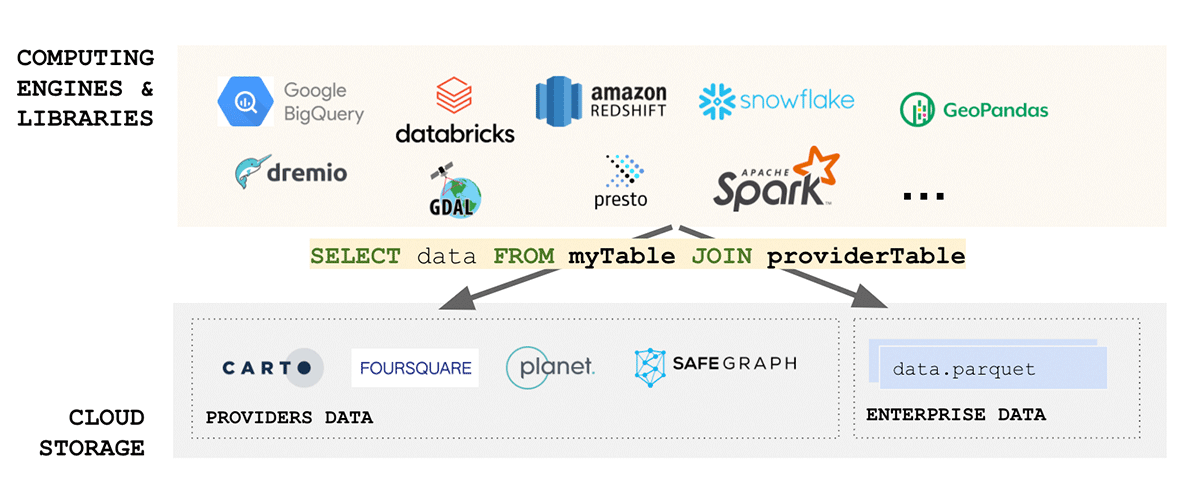{kind=link}
Perché introdurre un altro formato in un ecosistema già complesso? GeoParquet non è un nuovo formato, è una specifica di schema per il formato Apache Parquet, che è già ampiamente adottato e utilizzato dall'industria e dalla community. Parquet come formato di base supporta colonne binarie e consente l'archiviazione di payload di dati arbitrari, allo stesso tempo il formato supporta colonne di dati strutturati che possono archiviare metadati insieme al payload dei dati. Questo lo rende una scelta che promuove l'interoperabilità e la riproducibilità. Infine, il formato Delta Lake è stato costruito su parquet e porta le proprietà ACID alla tabella. Le proprietà ACID di un formato sono cruciali per la riproducibilità e per output affidabili. Inoltre, Delta è il formato utilizzato dalla soluzione di condivisione dati scalabile Delta Sharing. Delta Sharing abilita la condivisione di dati su scala aziendale tra qualsiasi cloud pubblico utilizzando Databricks (opzioni fai-da-te per cloud privati sono disponibili utilizzando blocchi costitutivi open source). Delta Sharing astrae completamente la necessità di API REST personalizzate per esporre dati a terze parti. Qualsiasi asset di dati archiviato in Delta (utilizzando lo schema GeoParquet) diventa automaticamente un prodotto dati che può essere esposto a parti esterne in modo controllato e governato. Delta Sharing è stato costruito da zero tenendo conto delle migliori pratiche di sicurezza.
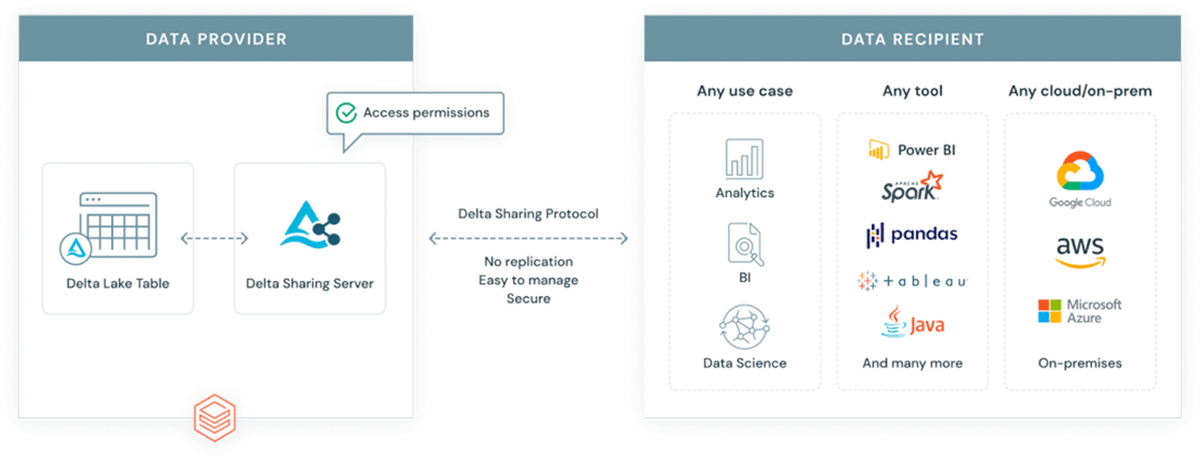
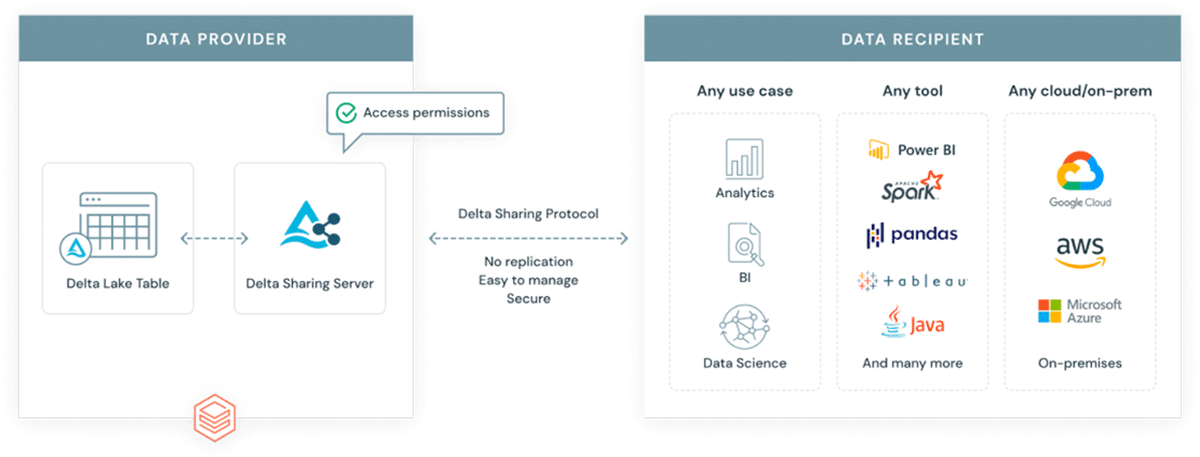{kind=link}
Economia circolare dei dati
Prendendo in prestito concetti dal dominio della sostenibilità, possiamo definire un'economia circolare dei dati come un sistema in cui i dati vengono raccolti, condivisi e utilizzati in modo da massimizzarne il valore, minimizzando al contempo gli sprechi e gli impatti negativi, come tempi di calcolo non necessari, insight inaffidabili o azioni distorte basate su inquinanti dei dati. La riutilizzabilità è il concetto chiave in questa considerazione: come possiamo minimizzare il "reinventare la ruota". Ci sono innumerevoli asset di dati in circolazione che rappresentano la stessa area, gli stessi concetti con solo lievi alterazioni per adattarsi meglio a uno specifico caso d'uso. È dovuto a ottimizzazioni effettive o al fatto che era più facile creare una nuova copia degli asset piuttosto che riutilizzare quelli esistenti? O era troppo difficile trovare gli asset di dati esistenti, o forse era troppo complesso definire i pattern di accesso ai dati.
La duplicazione degli asset di dati ha molti aspetti negativi sia nelle considerazioni FAIR che nelle considerazioni sulla piramide del valore dei dati: avere molti asset di dati simili (ma diversi) e disparati che rappresentano la stessa area e gli stessi concetti può deteriorare le considerazioni sulla semplicità del dominio dei dati: diventa difficile identificare l'asset di dati di cui ci si può effettivamente fidare. Può anche avere implicazioni molto negative sulla generazione di abitudini: emergeranno molte nicchie di community che si standardizzeranno da sole ignorando le migliori pratiche dell'ecosistema più ampio, o peggio ancora, non si standardizzeranno affatto.
In un'economia circolare dei dati, i dati sono trattati come una risorsa preziosa che può essere utilizzata per creare nuovi prodotti e servizi, oltre a migliorare quelli esistenti. Questo approccio incoraggia il riutilizzo e il riciclo dei dati, piuttosto che trattarli come una merce usa e getta. Ancora una volta, utilizziamo l'analogia della sostenibilità in senso letterale: sosteniamo che questo è il modo corretto di affrontare il problema. Gli inquinanti dei dati sono una vera sfida per le organizzazioni sia internamente che esternamente. Un articolo di The Guardian afferma che meno dell'1% dei dati raccolti viene effettivamente analizzato. C'è troppa duplicazione dei dati, la maggior parte dei dati è di difficile accesso e derivare valore effettivo è troppo macchinoso. L'economia circolare dei dati promuove le migliori pratiche e la riutilizzabilità degli asset di dati esistenti, consentendo un'interpretazione e insight più coerenti nell'intero ecosistema dei dati.
{kind=link}
L'interoperabilità è una componente chiave dei principi FAIR sui dati, e dall'interoperabilità nasce la domanda di circolarità. Come possiamo progettare un ecosistema che massimizzi l'utilizzo e il riutilizzo dei dati? Ancora una volta, FAIR insieme alla piramide del valore offre risposte. La reperibilità dei dati è fondamentale per il riutilizzo dei dati e per risolvere il problema dell'inquinamento dei dati. Con asset di dati facilmente scopribili possiamo evitare la ricreazione degli stessi asset di dati in più luoghi con lievi alterazioni, ottenendo invece un ecosistema di dati coerente con dati che possono essere facilmente combinati e riutilizzati. Databricks ha recentemente annunciato il Databricks Marketplace. L'idea alla base del marketplace è in linea con la definizione originale di prodotto dati di DJ Patel. Il marketplace supporterà la condivisione di dataset, notebook, dashboard e modelli di machine learning. Il blocco costitutivo critico per un tale marketplace è il concetto di Delta Sharing: il canale scalabile, flessibile e robusto per la condivisione di qualsiasi dato, inclusi i dati geospaziali.
La progettazione di prodotti dati scalabili che vivranno nel Marketplace è cruciale. Per massimizzare il valore aggiunto di ogni prodotto dati, si dovrebbero considerare attentamente i principi FAIR e la piramide del valore del prodotto. Senza questi principi guida, aumenteremo solo i problemi già presenti nei sistemi attuali. Ogni prodotto dati dovrebbe risolvere un problema unico e farlo in modo semplice, riproducibile e robusto.
Puoi leggere di più su come la Databricks Lakehouse Platform può aiutarti ad accelerare il time to value dai tuoi prodotti dati nell'eBook - Un nuovo approccio alla condivisione dei dati.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.