Costruzione di una Data Mesh basata sul Lakehouse Databricks, Parte 2
di Bernhard Walter, Sharon Richardson, Guillermo Schiava D'Albano, Pawarit Laosunthara, Amr Ali e Fran Medina Castro
Nel precedente articolo "Databricks Lakehouse e Data Mesh", abbiamo introdotto il Data Mesh basato sul Databricks Lakehouse. Questo articolo esplorerà come le funzionalità del Databricks Lakehouse supportano il Data Mesh dal punto di vista architetturale.
Il Data Mesh è un paradigma architetturale e organizzativo, non una tecnologia o una soluzione che si acquista. Tuttavia, per implementare efficacemente un Data Mesh, è necessaria una piattaforma flessibile che garantisca la collaborazione tra le diverse figure professionali che si occupano di dati, fornisca qualità dei dati e faciliti l'interoperabilità e la produttività in tutti i carichi di lavoro di dati e AI.
Vediamo come le funzionalità della piattaforma Databricks Lakehouse rispondono a queste esigenze.
Il blocco fondamentale di un data mesh è il dominio dati, solitamente composto dai seguenti componenti:
- Dati sorgente (di proprietà del dominio)
- Risorse di calcolo self-service e orchestrazione (all'interno di Databricks Workspaces)
- Prodotti dati orientati al dominio forniti ad altri team e domini
- Insight pronti per il consumo da parte degli utenti aziendali
- Aderenza alle politiche di governance computazionale federata
Questo è rappresentato nella figura seguente:
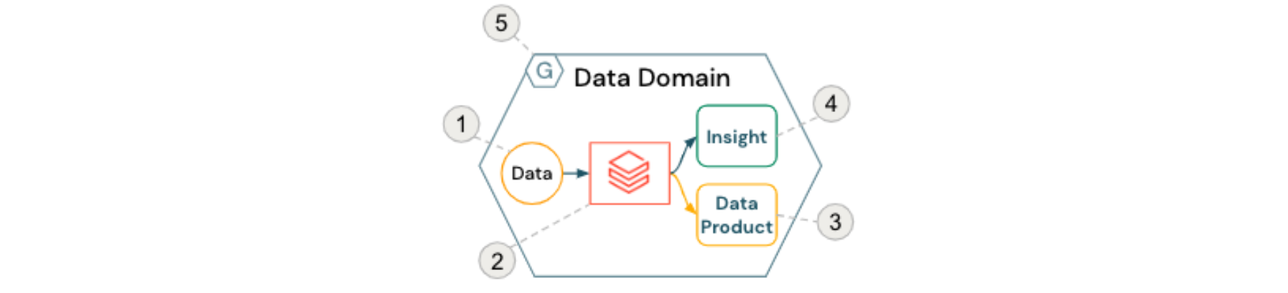
Per facilitare la collaborazione inter-dominio e l'analisi self-service, i servizi comuni relativi ai meccanismi di controllo degli accessi e alla catalogazione dei dati vengono spesso forniti centralmente. Ad esempio, Databricks Unity Catalog fornisce non solo funzionalità di catalogazione informative come la scoperta dei dati e la lineage, ma anche l'applicazione di controlli di accesso granulari e il monitoraggio desiderati da molte organizzazioni oggi.
Il Data Mesh può essere distribuito in una varietà di topologie. Al di fuori delle moderne aziende digital-native, un Data Mesh altamente decentralizzato con domini completamente indipendenti di solito non è raccomandato in quanto porta a complessità e overhead nei team di dominio piuttosto che consentire loro di concentrarsi sulla logica di business e sui dati di alta qualità. Due esempi popolari spesso visti nelle imprese sono il Data Mesh Armonizzato e il Data Mesh Hub & Spoke.
1) Approccio per un Data Mesh armonizzato
Un data mesh armonizzato enfatizza l'autonomia all'interno dei domini:
- I domini dati creano e pubblicano prodotti dati specifici del dominio
- La scoperta dei dati è abilitata automaticamente da Unity Catalog
- I prodotti dati vengono consumati in modo peer-to-peer
- L'infrastruttura di dominio è armonizzata tramite
- blueprint della piattaforma, garantendo sicurezza e conformità
- servizi di piattaforma self-service (automazione del provisioning dei domini, catalogazione dei dati, pubblicazione dei metadati, policy sui dati e sulle risorse di calcolo)
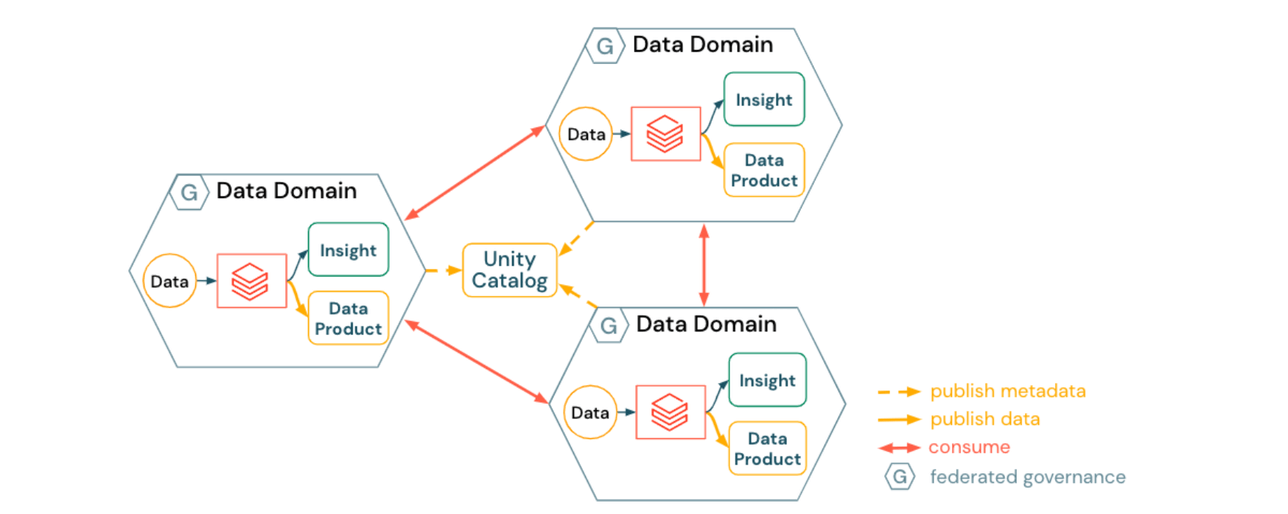
Le implicazioni di un approccio armonizzato possono includere:
- Ogni Dominio Dati deve aderire a standard e best practice per l'interoperabilità e la gestione dell'infrastruttura
- Ogni Dominio Dati spende in modo indipendente più tempo e sforzi su argomenti come i controlli di accesso, i conti di archiviazione sottostanti o persino l'infrastruttura (ad esempio, broker di eventi per prodotti dati in streaming)
Questo approccio può essere impegnativo nelle organizzazioni globali in cui team diversi hanno ampiezza e profondità di competenze diverse e potrebbero trovare difficile rimanere completamente in linea con le pratiche e le policy più recenti.
2) Approccio per un Data Mesh Hub & Spoke
Un Data Mesh Hub & Spoke incorpora una posizione centralizzata per la gestione degli asset di dati condivisibili e dei dati che non rientrano logicamente in un singolo dominio:
- I domini dati (spokes) creano prodotti dati specifici del dominio
- I prodotti dati vengono pubblicati nel data hub, che possiede e gestisce la maggior parte degli asset registrati in Unity Catalog
- Il data hub fornisce servizi generici di operazioni di piattaforma per i domini dati come:
- pubblicazione dati self-service in posizioni gestite
- catalogazione dati, lineage, audit e controllo accessi tramite Unity Catalog
- servizi di gestione dati come il time travel e i processi GDPR tra domini (ad esempio, richieste di diritto all'oblio)
- Il data hub può anche fungere da dominio dati. Ad esempio, pipeline o strumenti per set di dati generici o acquisiti esternamente come dati meteorologici, ricerche di mercato o dati macroeconomici standard.
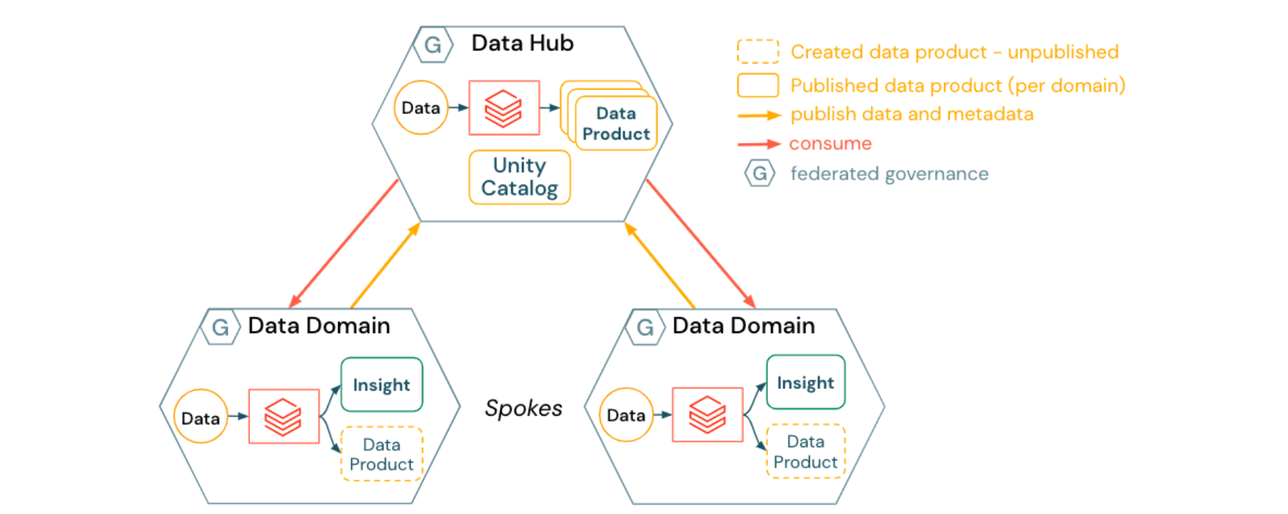
Le implicazioni per un Data Mesh Hub and Spoke includono:
- I domini dati possono beneficiare di servizi dati sviluppati e distribuiti centralmente, consentendo loro di concentrarsi maggiormente sulla logica di business e di trasformazione dei dati
- L'automazione dell'infrastruttura e il calcolo self-service possono aiutare a evitare che il team del data hub diventi un collo di bottiglia per la pubblicazione dei prodotti dati
In entrambi questi approcci, i domini possono anche avere esigenze comuni e ripetibili come:
- Strumenti e connettori per l'ingestione dei dati
- Framework, template o best practice MLOps
- Pipeline per CI/CD, qualità dei dati e monitoraggio
È anche perfettamente fattibile avere alcune variazioni tra un data mesh completamente armonizzato e un modello hub-and-spoke. Ad esempio, avere un data hub globale minimo per ospitare solo gli asset di dati che non rientrano logicamente in un singolo dominio e per gestire i dati acquisiti esternamente che vengono utilizzati in più domini. Unity Catalog svolge il ruolo fondamentale di fornire la scoperta dei dati autenticata ovunque i dati vengano gestiti all'interno di una distribuzione Databricks.
Scalare ed evolvere il Data Mesh
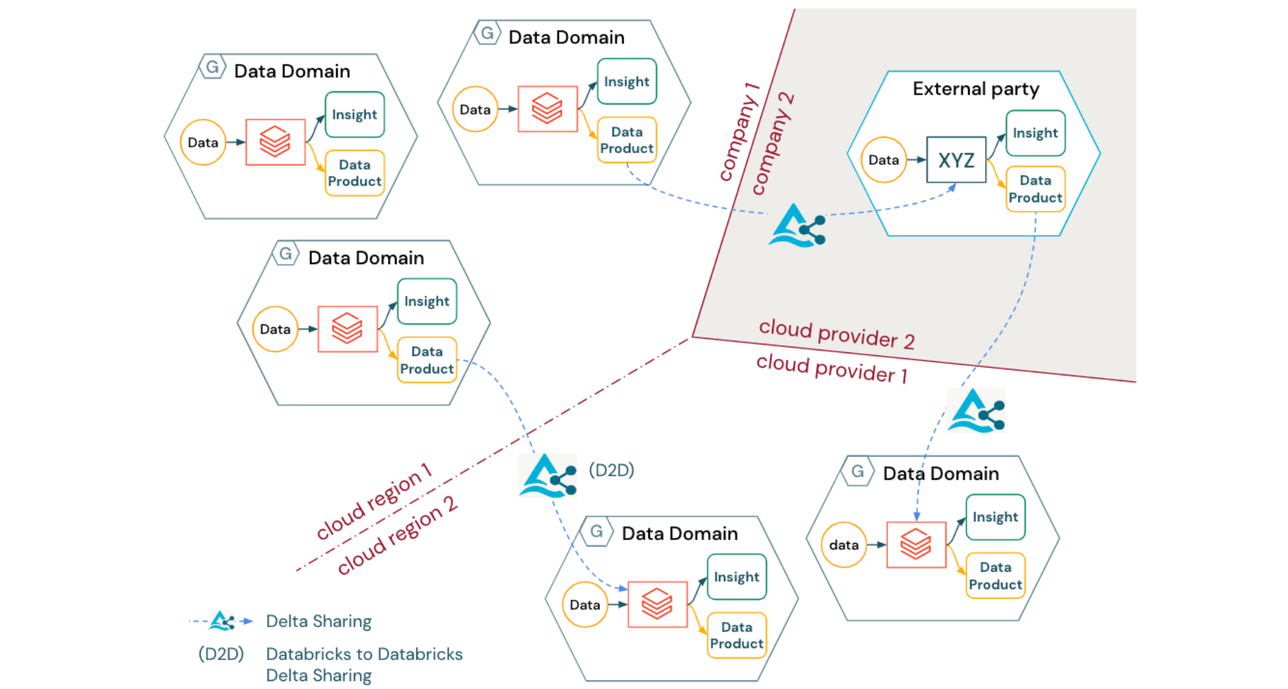
Indipendentemente dal tipo di architettura logica del Data Mesh distribuita, molte organizzazioni affronteranno la sfida di creare un modello operativo che copra regioni cloud, provider cloud e persino entità legali. Inoltre, man mano che le organizzazioni evolvono verso la produttivizzazione (e potenzialmente anche la monetizzazione) degli asset di dati, la condivisione dei dati interoperabile a livello aziendale rimane fondamentale per la collaborazione non solo tra domini interni ma anche tra aziende.
Delta Sharing offre una soluzione a questo problema con i seguenti vantaggi:
- Delta Sharing è un protocollo aperto per condividere in modo sicuro i prodotti dati tra domini attraverso confini organizzativi, regionali e tecnici
- Il protocollo Delta Sharing è indipendente dal fornitore (incluso un ampio ecosistema di client), fornendo un ponte tra diversi domini o persino diverse aziende senza richiedere loro di utilizzare lo stesso stack tecnologico o provider cloud
Considerazioni conclusive
Data Mesh e Lakehouse sono nati entrambi a causa di punti dolenti e carenze comuni dei data warehouse aziendali e dei data lake tradizionali[1][2]. Il Data Mesh articola in modo completo la visione aziendale e le esigenze per migliorare la produttività e il valore dei dati, mentre il Databricks Lakehouse fornisce una base aperta e scalabile per soddisfare tali esigenze con la massima interoperabilità, efficienza dei costi e semplicità.
In questo articolo, abbiamo enfatizzato due capacità di esempio della piattaforma Databricks Lakehouse che migliorano la collaborazione e la produttività supportando al contempo la governance federata, ovvero:
- Unity Catalog come abilitatore per la pubblicazione indipendente dei dati, la scoperta centralizzata dei dati e la governance computazionale federata nel Data Mesh
- Delta Sharing per organizzazioni grandi e distribuite a livello globale che hanno implementazioni su cloud e regioni. Delta Sharing condivide in modo efficiente e sicuro dati freschi e aggiornati tra domini in diversi confini organizzativi senza duplicazioni
- Workflows e Delta Live Tables per pipeline di dati self-service di alta qualità che supportano carichi di lavoro batch e in streaming
- Databricks SQL che consente query BI & SQL performanti direttamente sul lake, riducendo la necessità per i team di dominio di mantenere copie multiple/data store per i loro prodotti dati
- Databricks Feature Store che promuove la condivisione e il riutilizzo tra i team di Data Science e Machine Learning
- Matei Zaharia: Data Mesh and Lakehouse
- Zalando & Thoughtworks: Data Lakehouse and Data Mesh—Two Sides of the Same Coin
- Databricks: Meshing About with Databricks
Tuttavia, ci sono una miriade di altre funzionalità Databricks che fungono da ottimi abilitatori nel percorso Data Mesh per diverse figure professionali. Ad esempio:
Per saperne di più su Lakehouse per Data Mesh:
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.