Ragionamento agentivo in pratica: dare un senso ai dati strutturati e non strutturati
I dati aziendali raramente sono utili isolati. Rispondere a domande come: "Quali dei nostri prodotti hanno registrato un calo delle vendite negli ultimi tre mesi e quali problemi correlati sono emersi nelle recensioni dei clienti su vari siti di rivenditori?" richiede un ragionamento che attraversa un mix di origini dati strutturate e non strutturate, inclusi data lake, dati di recensioni e sistemi di gestione delle informazioni sui prodotti. In questo blog, dimostriamo come Databricks Agent Bricks Supervisor Agent (SA) possa aiutare in questi compiti complessi e realistici attraverso un ragionamento multi-step basato su un ibrido di dati strutturati e non strutturati.
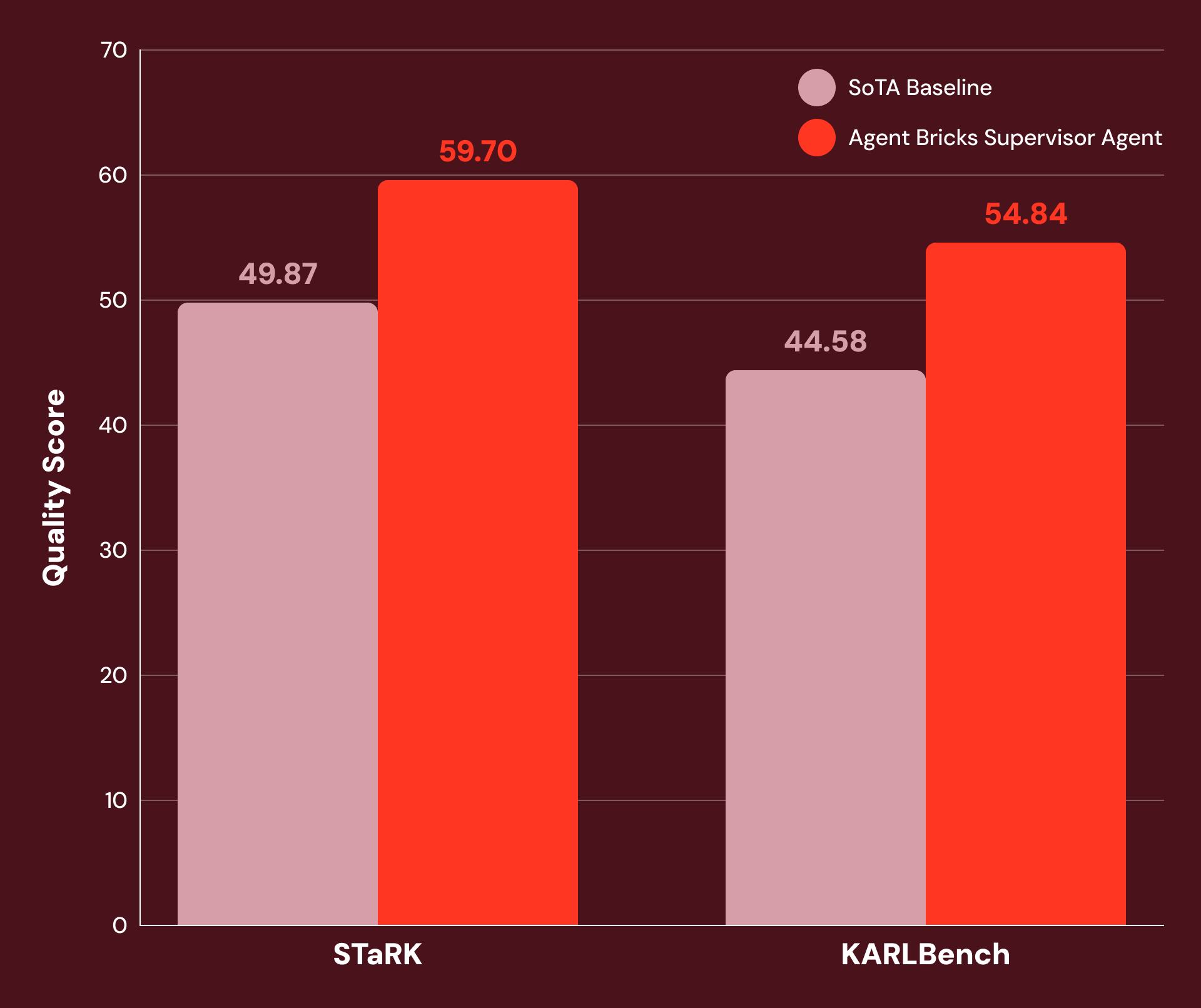
Con istruzioni ottimizzate e un'attenta configurazione degli strumenti, troviamo che SA è altamente performante su una vasta gamma di attività aziendali ad alta intensità di conoscenza. La Figura 1 mostra che SA ottiene un miglioramento del 20% o più rispetto ai baseline SoTA su:
- STaRK: una suite di tre attività di recupero semi-strutturato pubblicate da ricercatori di Stanford.
- KARLBench: una suite di benchmark per il ragionamento complesso basato sulla conoscenza, pubblicata di recente da Databricks.
Supervisor Agent dimostra guadagni significativi su una vasta gamma di attività economicamente preziose: dal recupero accademico (+21% su STaRK-MAG) al ragionamento biomedico (+38% su STaRK Prime) all'analisi finanziaria (+23% su FinanceBench).
Configurazione dell'Agente
Agent Bricks Supervisor Agent è un costruttore di agenti dichiarativo che orchestra agenti e strumenti. È costruito su aroll — un framework interno per la costruzione, valutazione e distribuzione di flussi di lavoro LLM multi-step su larga scala.1 aroll e SA sono stati progettati specificamente per i casi d'uso avanzati degli agenti che i nostri clienti incontrano frequentemente.
aroll consente di aggiungere nuovi strumenti e istruzioni personalizzate tramite semplici modifiche di configurazione, può gestire migliaia di conversazioni simultanee ed esecuzioni parallele di strumenti, e incorpora tecniche avanzate di orchestrazione degli agenti e gestione del contesto per raffinare le query e recuperare da risposte parziali. Tutto ciò è difficile da ottenere oggi con i sistemi single-turn SoTA.
Poiché SA è costruito su questa architettura flessibile, la sua qualità può essere continuamente migliorata tramite una semplice curatela dell'utente, come la modifica delle istruzioni di primo livello o il perfezionamento delle descrizioni degli agenti, senza la necessità di scrivere codice personalizzato.
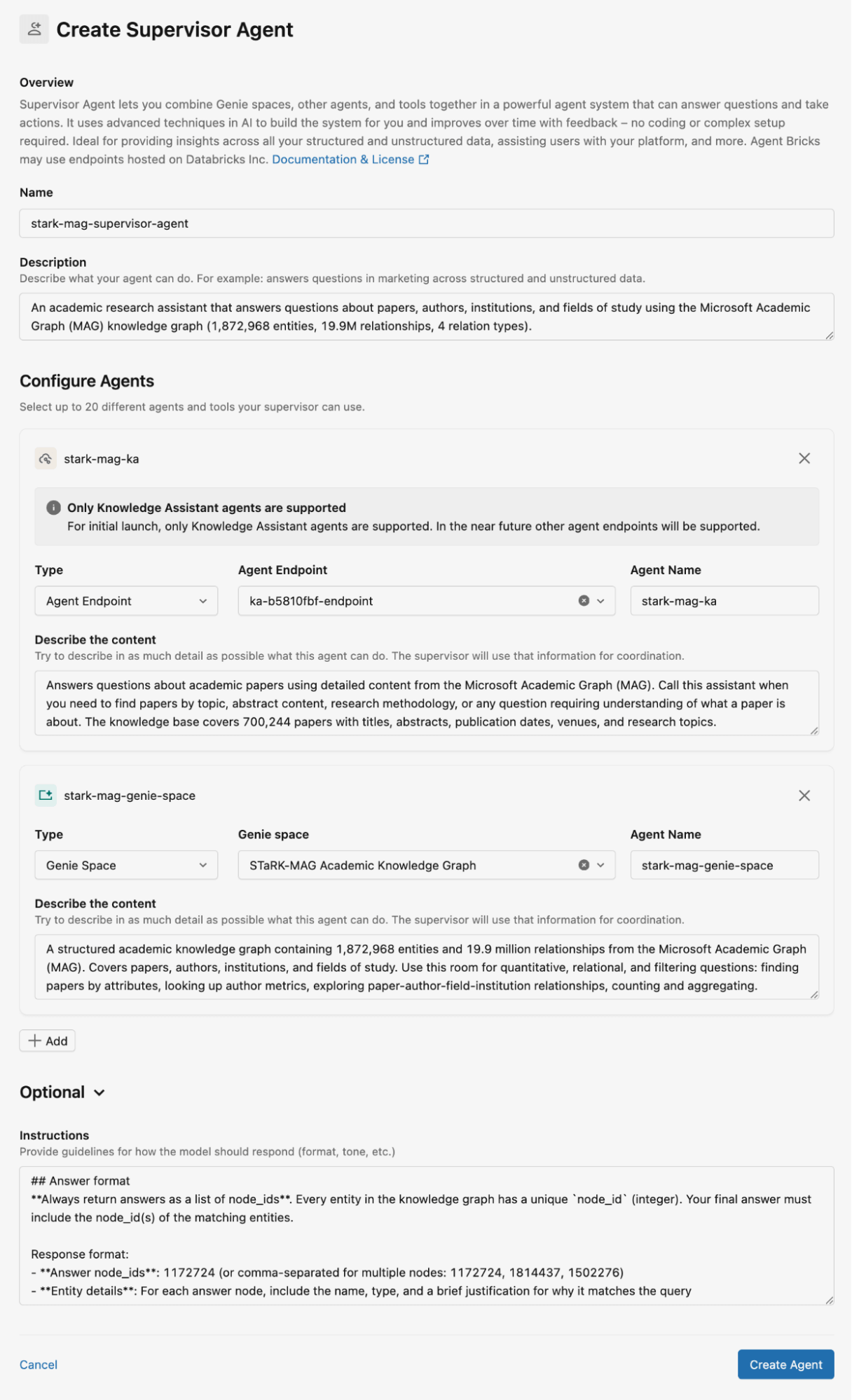
La Figura 2 mostra come abbiamo configurato il Supervisor Agent per il dataset STaRK-MAG. In questo blog, utilizziamo gli spazi Genie per archiviare le basi di conoscenza relazionali e i Knowledge Assistant per archiviare documenti non strutturati per il recupero. Forniamo descrizioni dettagliate per tutti i Knowledge Assistant e gli spazi Genie, nonché istruzioni per le risposte dell'agente.
Ragionamento Ibrido: Strutturato Incontra Non Strutturato
Per valutare il ragionamento basato su dati strutturati e non strutturati, utilizziamo il benchmark STaRK, che include tre domini:
- Amazon: attributi dei prodotti (strutturati) e recensioni (non strutturate)
- MAG: reti di citazioni (strutturate) e articoli accademici (non strutturati)
- Prime: entità biomediche (strutturate) e letteratura (non strutturata)
Ad esempio, "Trovami un articolo scritto da un coautore con 115 articoli e che riguardi l'atomo di Rydberg" richiede al sistema di combinare il filtraggio strutturato ("coautore con 115 articoli") con la comprensione non strutturata ("riguardo all'atomo di Rydberg"). I migliori baseline pubblicati utilizzano la ricerca di similarità vettoriale con un reranker basato su LLM — un forte approccio single-turn, ma che non può scomporre le query tra diversi tipi di dati. Per garantire un confronto equo, abbiamo rieseguito questo baseline con il modello fondamentale SoTA attuale, fornendo un baseline sostanzialmente più forte.
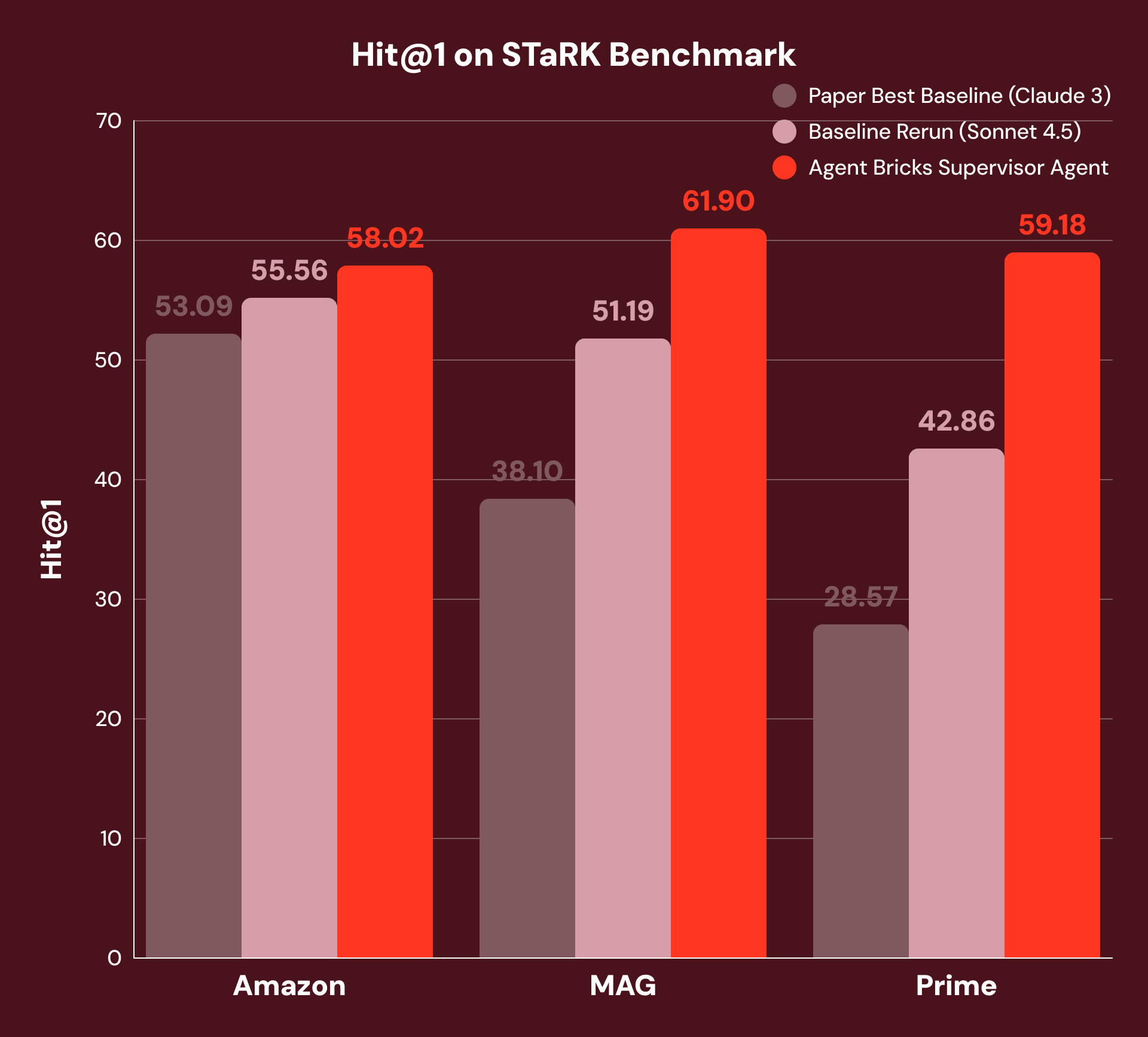
Con il nostro approccio, SA scompone ogni domanda, instrada le sotto-domande allo strumento appropriato e sintetizza i risultati attraverso più passaggi di ragionamento. Come mostra la Figura 3, questo ottiene un +4% di Hit@1 su Amazon, +21% su MAG e +38% su Prime rispetto sia ai migliori baseline originali sia ai nostri baseline rieseguiti con il modello fondamentale SoTA attuale. Vediamo i migliori miglioramenti in MAG e Prime, dove la risposta richiede la più stretta integrazione di dati strutturati e non strutturati.
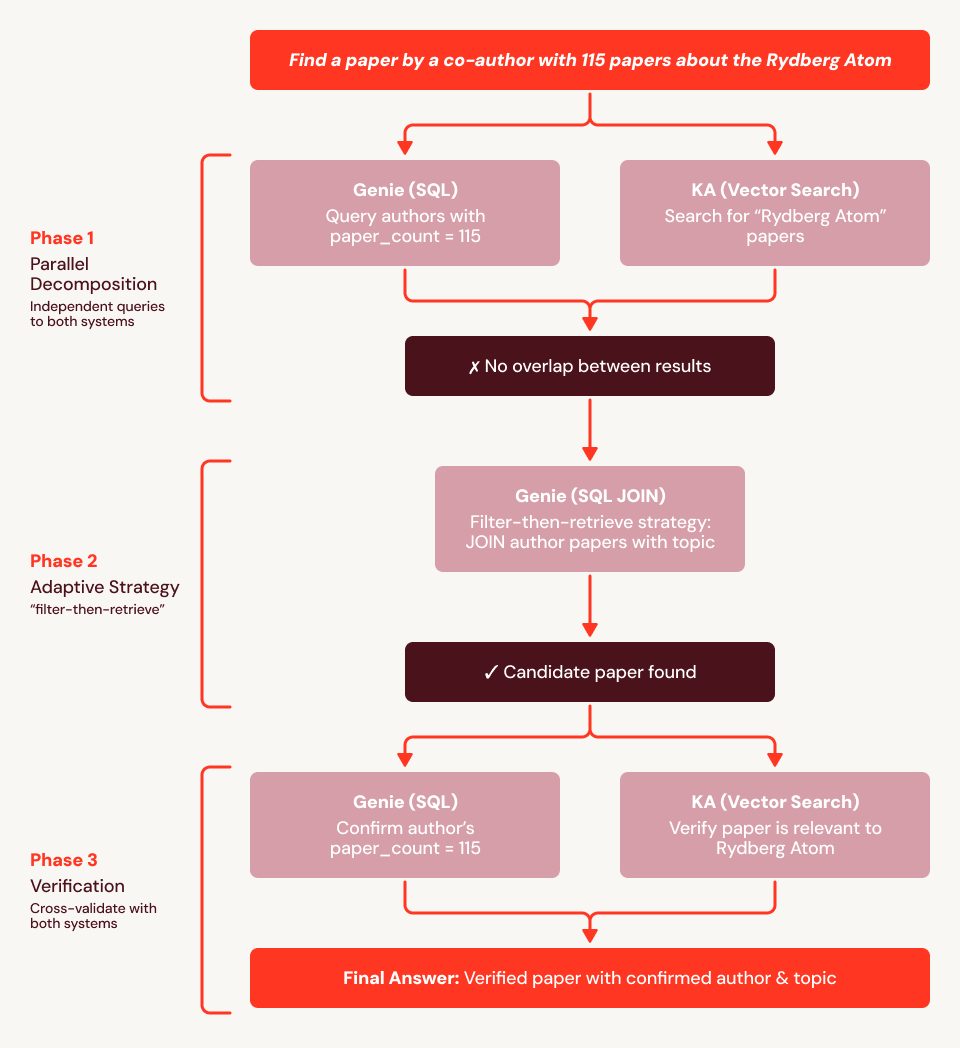
Utilizzando la nostra domanda di esempio sopra riportata ("Trovami un articolo scritto da un coautore con 115 articoli e che riguardi l'atomo di Rydberg"), troviamo che il baseline fallisce perché gli embedding non possono codificare il vincolo strutturale ("coautore con esattamente 115 articoli"). Nella Figura 4, mostriamo una traccia di esecuzione per SA: utilizza prima Genie per trovare tutti i 759 autori con 115 articoli e Knowledge Assistant per recuperare articoli su Rydberg, quindi incrocia i due insiemi. Quando non viene trovato alcun sovrapposizione, SA si adatta: emette un JOIN SQL della lista di autori con 115 articoli contro tutti gli articoli che menzionano "Rydberg" nel titolo o nell'abstract, facendo emergere la risposta direttamente dai dati strutturati. Chiama quindi Knowledge Assistant per verificare la pertinenza e Genie per confermare il numero di articoli dell'autore, e restituisce con successo l'articolo corretto.
Il Vantaggio Agentico nei Compiti ad Alta Intensità di Conoscenza
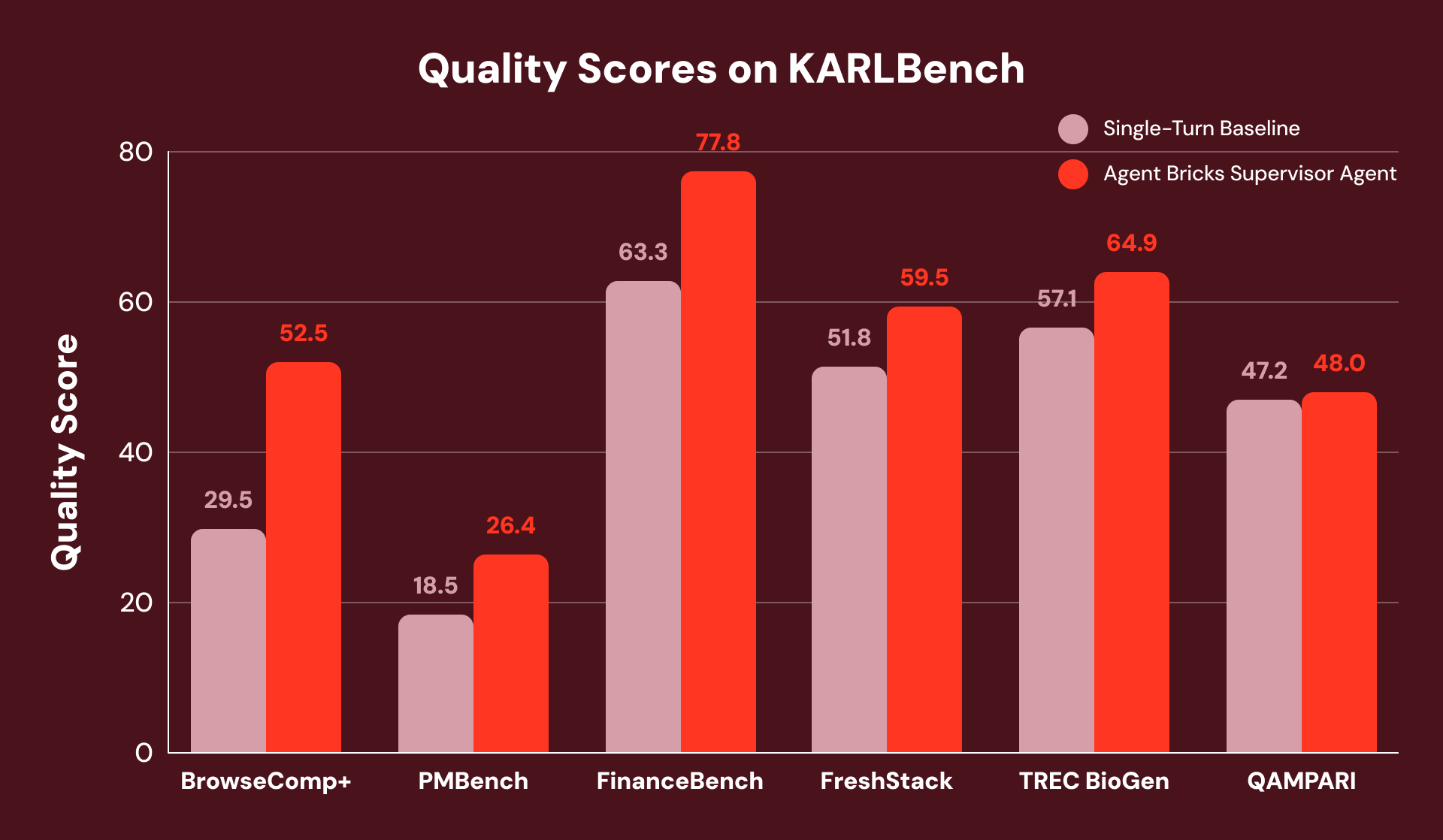
Per confrontare le prestazioni di Agent Bricks SA con un forte baseline single-turn (simile al miglior baseline pubblicato per STaRK) dove non sono richiesti dati strutturati, li valutiamo utilizzando KARLBench, una suite di benchmark per il ragionamento basato sulla conoscenza che stressa collettivamente diverse capacità di recupero e ragionamento:
- BrowseComp+: ricerca di entità per eliminazione
- TREC BioGen: sintesi della letteratura biomedica
- FinanceBench: ragionamento numerico su documenti finanziari
- QAMPARI: recupero esaustivo di entità
- FreshStack: risoluzione di problemi tecnici su documentazione
- PMBench: comprensione di documenti aziendali interni Databricks
Complessivamente, il Supervisor Agent ottiene guadagni costanti su tutti e sei i benchmark, con i maggiori miglioramenti su compiti che richiedono un'analisi esaustiva o l'autocorrezione. Su FinanceBench, recupera da un recupero inizialmente incompleto rilevando lacune e riformulando le query, producendo un miglioramento complessivo del +23%.
Ad esempio, le domande di BrowseComp+ hanno ciascuna 5-10 vincoli interconnessi, come “Trova un giocatore che ha lasciato un club russo (2015-2020), naturalizzato europeo (2010-2016), altezza 1,95-2,06 m. Qual è stata la sua percentuale di successo nei blocchi alle Olimpiadi posticipate dal COVID?” La baseline a turno singolo emette una singola query ampia che identifica correttamente il giocatore ma non recupera documenti con statistiche granulari e non soddisfa la domanda.
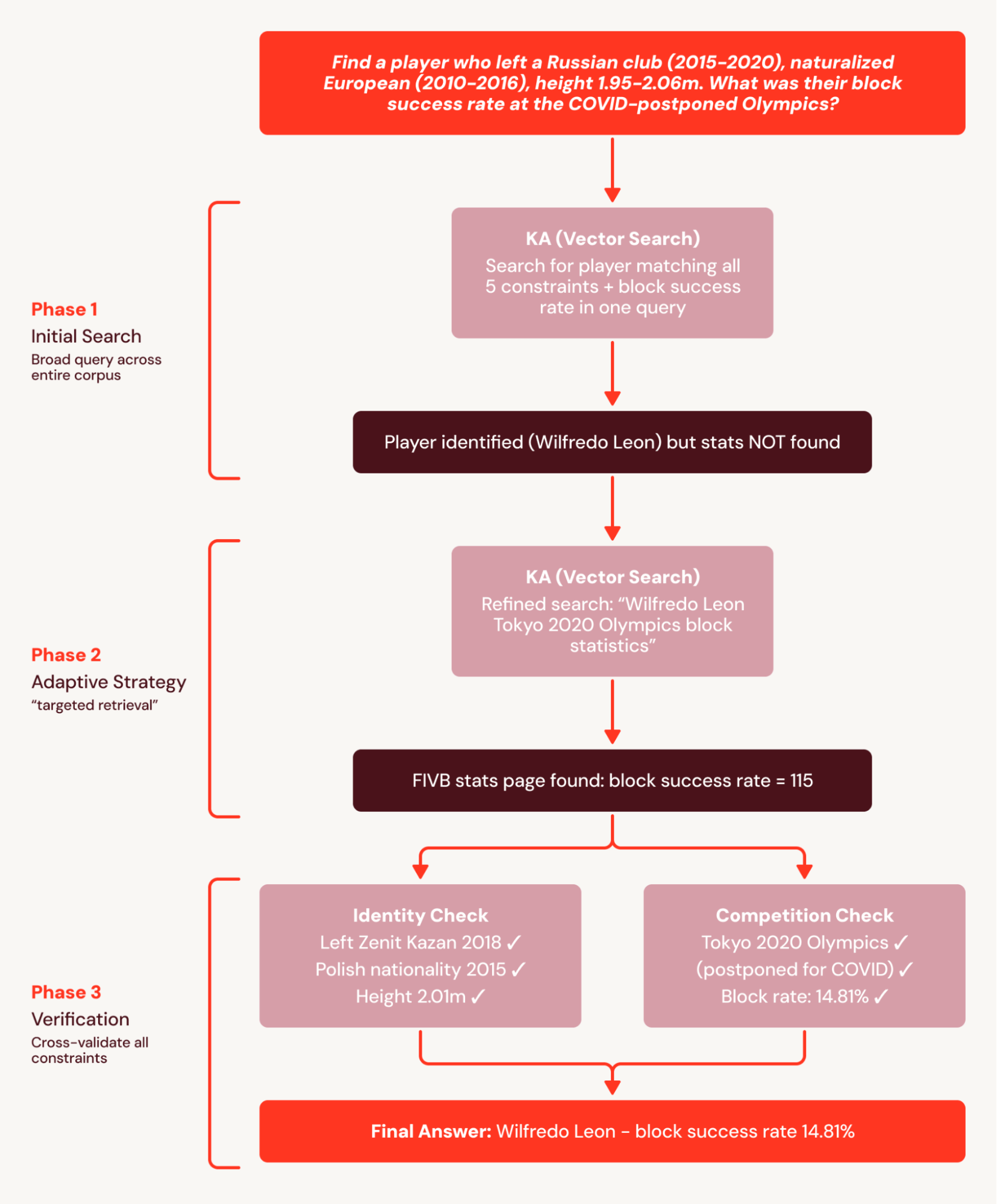
SA scompone questo compito in un piano di ricerca coordinato e lo suddivide in sottoinsiemi ricercabili. Ciò evita il fallimento della baseline a turno singolo in cui le statistiche non vengono trovate perché vengono recuperate in una ricerca successiva. Di conseguenza, SA ottiene un miglioramento relativo del +78%.
In un altro esempio da PMBench, una delle domande è “quali sono i tipi di guardrail utilizzati dai clienti” che richiede 26 nuggets (vedi definizione nel report KARL) in oltre 10 documenti di conversazioni con i clienti per una risposta esaustiva. La baseline a turno singolo trova solo una menzione del cliente perché non può cercare in ogni categoria di guardrail in una singola domanda. SA cerca ogni categoria di guardrail separatamente (“rilevamento PII”, “allucinazione”, “tossicità”, “iniezione di prompt”), e recupera progressivamente sempre più menzioni dei clienti nel processo.
Cosa abbiamo imparato
I risultati dei nostri esperimenti indicano alcuni punti chiave:
- Gli agenti di ragionamento basati su dati concreti possono beneficiare di un mix di recupero di dati strutturati e non strutturati se hanno accesso agli strumenti e alle rappresentazioni dei dati giusti.
- Per scenari di recupero di alta qualità, è necessario evitare la creazione di pipeline RAG personalizzate su set di dati eterogenei, anche se vengono utilizzati modelli SoTA per la fase di riordino. Il ragionamento multi-passo in cui, ad ogni passo, l'agente seleziona la fonte dati corretta e riflette sulla sua utilità, è cruciale per migliorare le prestazioni.
- Un approccio dichiarativo alla creazione di agenti, come quello implementato dal Databricks Supervisor Agent, offre un buon compromesso tra facilità d'uso e qualità.
Utilizziamo il Databricks Supervisor Agent per creare agenti per tutti e tre i domini STaRK e sei set di dati non strutturati in KARLBench. Le uniche cose che differiscono tra questi nove compiti sono le istruzioni e gli strumenti — non è stato necessario alcun codice personalizzato per elaborare questi diversi set di dati. Pertanto, la creazione di un agente performante per un nuovo compito aziendale è in gran parte una questione di scrittura di istruzioni precise e di dotarlo degli strumenti giusti, piuttosto che costruire un nuovo sistema da zero.
Agent Bricks Supervisor Agent è disponibile per tutti i nostri clienti. Puoi iniziare con Agent Bricks SA semplicemente creando un agente e collegandolo ai tuoi agenti, strumenti e server MCP esistenti. Esplora la documentazione per vedere come Supervisor Agent si inserisce nei tuoi flussi di lavoro di produzione.
Autori: Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky e Matei Zaharia.
1Vedi la nostra recente pubblicazione “KARL: Knowledge Agents via Reinforcement Learning” per maggiori dettagli su come viene utilizzato aroll per la generazione di dati sintetici, l'addestramento RL scalabile e l'inferenza online per compiti agentivi.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.