Annuncio di disponibilità generale di Databricks Model Serving
ML di produzione semplificato sulla Databricks Lakehouse Platform
di Patrick Wendell, Aaron Davidson, Sue Ann Hong, Kasey Uhlenhuth, Ahmed Bilal e Josh Hartman
Evento virtuale ML
Siamo entusiasti di annunciare la disponibilità generale di Databricks Model Serving. Model Serving esegue il deployment di modelli di machine learning come API REST, consentendo di creare applicazioni di ML in tempo reale come suggerimenti personalizzati, chatbot per il servizio clienti, rilevamento di frodi e altro ancora, il tutto senza il fastidio di gestire l'infrastruttura di serving.
Con il lancio di Databricks Model Serving, ora puoi implementare i tuoi modelli insieme ai dati e all'infrastruttura di addestramento esistenti, semplificando il ciclo di vita del ML e riducendo i costi operativi.
"Eseguire il serving dei modelli sulla stessa piattaforma dove risiedono i nostri dati e dove addestriamo i modelli ci ha permesso di accelerare le distribuzioni e di ridurre la manutenzione, il che, in definitiva, ci aiuta a fornire valore ai nostri clienti e a promuovere uno stile di vita più piacevole e sostenibile in tutto il mondo."—Daniel Edsgärd, Head of Data Science, Electrolux
Sfide nella creazione di sistemi di ML in tempo reale
I sistemi di machine learning in tempo reale stanno rivoluzionando il modo in cui operano le aziende, offrendo la possibilità di fare previsioni o agire immediatamente in base ai dati in entrata. Applicazioni come chatbot, sistemi di rilevamento delle frodi e di personalizzazione si basano su sistemi in tempo reale per fornire risposte istantanee e accurate, migliorando l'esperienza dei clienti, aumentando i ricavi e riducendo i rischi.
Tuttavia, l'implementazione di tali sistemi rimane una sfida per le aziende. I sistemi di ML in tempo reale richiedono un'infrastruttura di serving veloce e scalabile, che necessita di conoscenze specialistiche per la sua creazione e manutenzione. L'infrastruttura non deve solo supportare il serving, ma anche includere le ricerche di feature, il monitoraggio, la distribuzione automatizzata e il riaddestramento dei modelli. Ciò spesso porta i team a integrare strumenti eterogenei, il che aumenta la complessità operativa e crea un sovraccarico di manutenzione. Le aziende spesso finiscono per dedicare più tempo e risorse alla manutenzione dell'infrastruttura invece di integrare il ML nei loro processi.
Esecuzione di Model Serving sul Lakehouse
Databricks Model Serving è la prima soluzione di serving serverless e in tempo reale sviluppata su una piattaforma unificata per dati e IA. Questa soluzione di serving esclusiva accelera il percorso dei team di data science verso la produzione, semplificando le distribuzioni e riducendo gli errori attraverso strumenti integrati.
Elimina i costi generali di gestione con il Model Serving in tempo reale
Databricks Model Serving offre un servizio serverless a bassa latenza e ad alta disponibilità per la distribuzione di modelli tramite un'API. Non dovrai più occuparti della complessa e onerosa gestione di un'infrastruttura scalabile. Il nostro servizio completamente gestito si fa carico di tutto il lavoro pesante, eliminando la necessità di gestire istanze, mantenere la compatibilità tra le versioni e applicare patch. Gli endpoint scalano automaticamente verso l'alto o verso il basso per adattarsi alle variazioni della domanda, consentendo di risparmiare sui costi dell'infrastruttura e ottimizzando le prestazioni di latenza.
“La scalabilità automatica in tempi rapidi riduce i costi e, al tempo stesso, ci consente di crescere di pari passo con l'aumento della domanda di traffico. Il nostro team dedica ora più tempo alla costruzione di modelli che risolvono i problemi dei clienti piuttosto che alla risoluzione di problemi legati all'infrastruttura." —Gyuhyeon Sim, CEO di Letsur.ai
Accelera i deployment tramite Lakehouse-Unified Model Serving
Databricks Model Serving accelera la distribuzione dei modelli di ML fornendo integrazioni native con vari servizi. Ora puoi gestire l'intero processo di ML, dall'inserimento e dall'addestramento dei dati fino alla distribuzione e al monitoraggio, tutto su un'unica piattaforma, creando una vista coerente dell'intero ciclo di vita di ML che riduce al minimo gli errori e velocizza il debug. Il Model Serving si integra con vari servizi Lakehouse, tra cui
- Integrazione con il negozio di funzionalità: si integra perfettamente con il negozio di funzionalità di Databricks, fornendo ricerche online automatizzate per prevenire la discrepanza online/offline. Definisci le feature una sola volta durante l'addestramento e noi recupereremo e uniremo automaticamente le feature pertinenti per completare il payload di inferenza.
- Integrazione con MLflow: si connette nativamente a MLflow Model Registry, consentendo un deployment dei modelli facile e veloce. Basta fornirci il modello e prepareremo automaticamente un container pronto per la produzione, distribuendolo su un'infrastruttura serverless compute.
- Qualità & diagnostica (presto disponibile): acquisisce automaticamente richieste e risposte in una tabella Delta per monitorare ed eseguire il debug dei modelli o per generare set di dati di addestramento.
- Governance unificata: gestisci e governa tutti i dati e gli asset di ML, inclusi quelli utilizzati e prodotti dalla distribuzione di modelli, con Unity Catalog.
“Eseguendo il model serving su una piattaforma di dati e AI unificata, siamo riusciti a semplificare il ciclo di vita del ML e ridurre le spese di manutenzione. Ciò ci consente di reindirizzare i nostri sforzi verso l'estensione dell'uso dell'AI a una fetta più grande del nostro business.” —Vincent Koc, Head of Data di hipages Group
Potenzia i team con la distribuzione semplificata
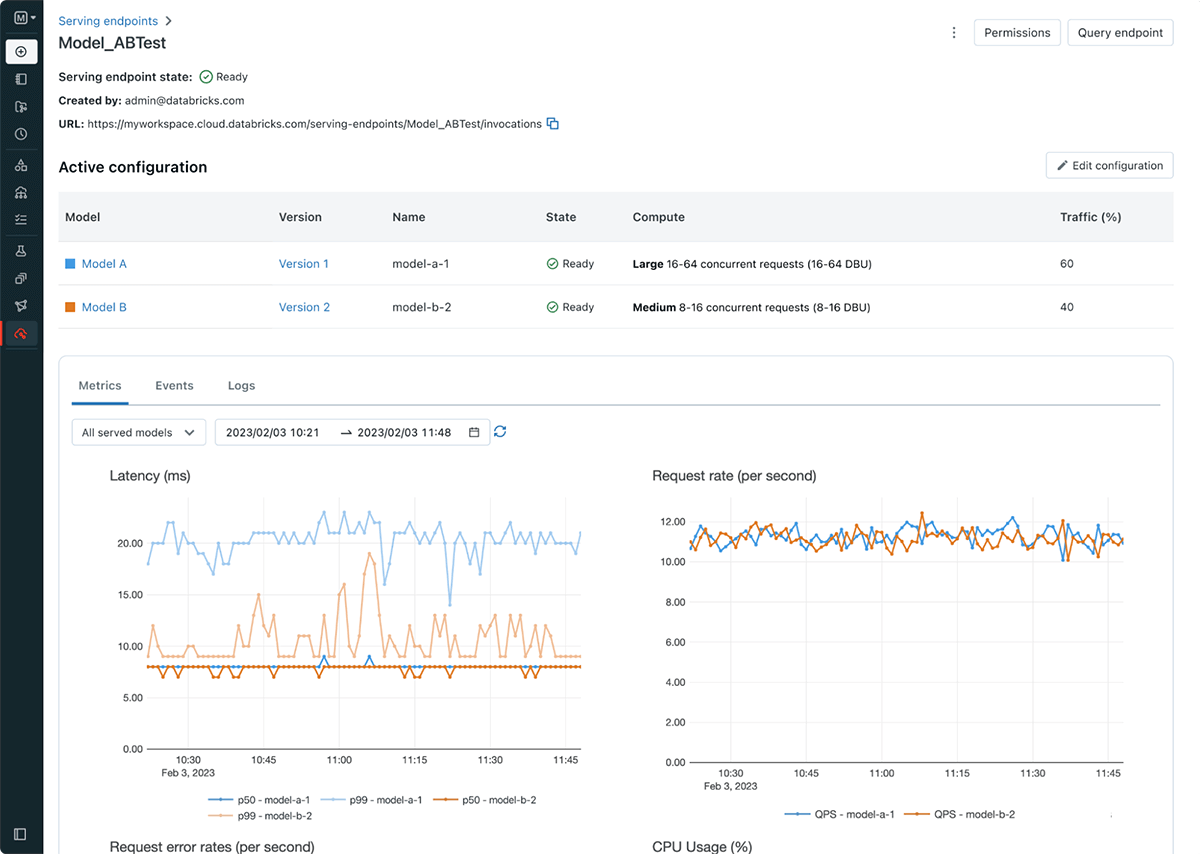
Databricks Model Serving semplifica il flusso di lavoro di distribuzione dei modelli, consentendo ai data scientist di distribuire i modelli senza la necessità di conoscenze o esperienze complesse in materia di infrastruttura. Nell'ambito del lancio, introduciamo anche gli endpoint di serving, che disaccoppiano il registro dei modelli e l'URI di scoring, il che si traduce in distribuzioni più efficienti, stabili e flessibili. Ad esempio, ora è possibile eseguire il deployment di più modelli dietro un singolo endpoint e distribuire il traffico come desiderato tra i modelli. La nuova UI di serving e le APIs rendono semplice creare e gestire gli Endpoint. Gli endpoint forniscono anche metriche e log integrati che è possibile utilizzare per monitorare e ricevere avvisi.
Introduzione al Model Serving di Databricks
- Iscriviti alla prossima conferenza per scoprire come Databricks Model Serving può aiutarti a creare sistemi in tempo reale e a ottenere informazioni dettagliate dai clienti.
- Provalo! Inizia a distribuire i modelli di ML come API REST
- Approfondisci la documentazionesu Databricks Model Serving
- Consulta la guida per migrare da Legacy MLflow Model Serving a Databricks Model Serving
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.