Architettura di Liquid Clustering di Arctic Wolf ottimizzata per la Scale a livello di petabyte
- Arctic Wolf elabora oltre 1 bilione di eventi di sicurezza ogni giorno, generando oltre 260 miliardi di osservazioni arricchite mantenute in un Delta Lake su scala petabyte. La nostra architettura è progettata per fornire un accesso quasi in tempo reale a tali dati.
- Di recente siamo passati a utilizzare la clusterizzazione liquida su tabelle gestite da Unity Catalog con Predictive Optimization (PO), integrando le nostre tabelle esterne partizionate con una clusterizzazione incrementale e basata sul carico di lavoro per migliorare le prestazioni delle query.
- Insieme, il clustering liquido e PO mantengono le tabelle ottimizzate per query fino a 8 volte più veloci e una migliore freschezza dei dati, passando da ore a minuti.
Ogni giorno, Arctic Wolf elabora oltre un trilione di eventi, distillando miliardi di record arricchiti in informazioni dettagliate rilevanti per la sicurezza. Ciò si traduce in oltre 60 TB di telemetria compressa, che alimenta il rilevamento e la risposta alle minacce basati sull'AI, 24 ore su 24, 7 giorni su 7, senza interruzioni. Per potenziare la ricerca delle minacce in tempo reale, avevamo bisogno che questi dati fossero disponibili per i clienti e per il Security Operation Center il più rapidamente possibile, con l'obiettivo che la maggior parte delle query restituisca risultati in 15 secondi.
In passato, abbiamo dovuto sfruttare altri datastore veloci per fornire l'accesso ai dati recenti, poiché il partizionamento e lo z-ordering non riuscivano a tenere il passo. Quando rileviamo un'attività sospetta, il nostro team può esaminare immediatamente tre mesi di contesto storico per comprendere i modelli di attacco, i movimenti laterali e l'intera portata della compromissione. Questa analisi storica in tempo reale su oltre 3,8 PB di dati compressi è fondamentale nella moderna ricerca delle minacce: la differenza tra il contenimento di una violazione in ore anziché in giorni può significare milioni di danni evitati.
Quando ogni secondo conta, la velocità e l'attualità dei dati sono fondamentali. Arctic Wolf doveva accelerare l'accesso a enormi set di dati senza aumentare i costi di inserimento o aggiungere complessità. Questo modello presenta un problema: Le indagini erano rallentate da un I/O dei file pesante e da dati obsoleti. Ripensando l'organizzazione dei dati, la nostra architettura gestisce in modo efficiente l'asimmetria dei dati multi-tenant, in cui una piccola parte di clienti genera la maggior parte degli eventi, gestendo al contempo i dati che arrivano in ritardo e che possono comparire fino a settimane dopo l'acquisizione iniziale. I vantaggi misurabili includono la riduzione del numero di file da oltre 4 milioni a 2 milioni, la drastica riduzione dei tempi di query di circa il 50% su tutti i percentili e la riduzione dei tempi delle query a 90 giorni da 51 a soli 6,6 secondi. La rapidità di aggiornamento dei dati è passata da ore a minuti, consentendo un accesso quasi immediato alla telemetria di sicurezza.
Continua a leggere per scoprire come il liquid clustering e le tabelle gestite di Unity Catalog hanno reso possibile tutto ciò, offrendo prestazioni costanti e insight quasi in tempo reale su larga scala.
Colli di bottiglia legacy: perché Arctic Wolf ha ricostruito
La nostra tabella legacy, partizionata per data-ora di occorrenza e con z-ordered in base all'identificatore del tenant, non poteva essere sottoposta a query quasi in tempo reale a causa del gran numero di file di piccole dimensioni suddivisi tra le partizioni. Inoltre, i dati sono disponibili solo al di fuori delle ultime 24 ore, poiché dovevamo eseguire OPTIMIZE con Z-ordering prima che i dati potessero essere interrogati.
Anche in quel caso, i problemi di prestazioni persistevano a causa dei dati in arrivo in ritardo. Ciò si verifica quando un sistema va offline prima di trasmettere i dati, il che comporterebbe l'inserimento di nuovi dati in partizioni più vecchie, con un impatto sulle prestazioni.
I dati obsoleti ci accecano. Quel ritardo fa la differenza tra contenere un avversario e permettergli di muoversi lateralmente.
Per mitigare queste sfide prestazionali e fornire la freschezza dei dati di cui avevamo bisogno per duplicare i nostri hot data in un acceleratore di dati e unirli tramite query con i dati del nostro Data Lake per soddisfare i nostri requisiti di business. Il funzionamento di questo sistema era costoso e richiedeva un notevole impegno di ingegneria per la manutenzione.
Per affrontare queste sfide legate all'uso di un acceleratore di dati, abbiamo riprogettato il nostro layout dei dati per distribuirli in modo uniforme e supportare i dati in arrivo in ritardo. Questo ottimizza le prestazioni delle query e consente l'accesso quasi in tempo reale per i casi d'uso attuali ed emergenti dell'AI agentiva.
Costruire le basi per i dati in streaming con il clustering liquido
Con la nostra nuova architettura, il nostro obiettivo principale è poter interrogare i dati più recenti e fornire prestazioni di query costanti per clienti di diverse dimensioni, mentre le query dovrebbero restituire risultati in pochi secondi.
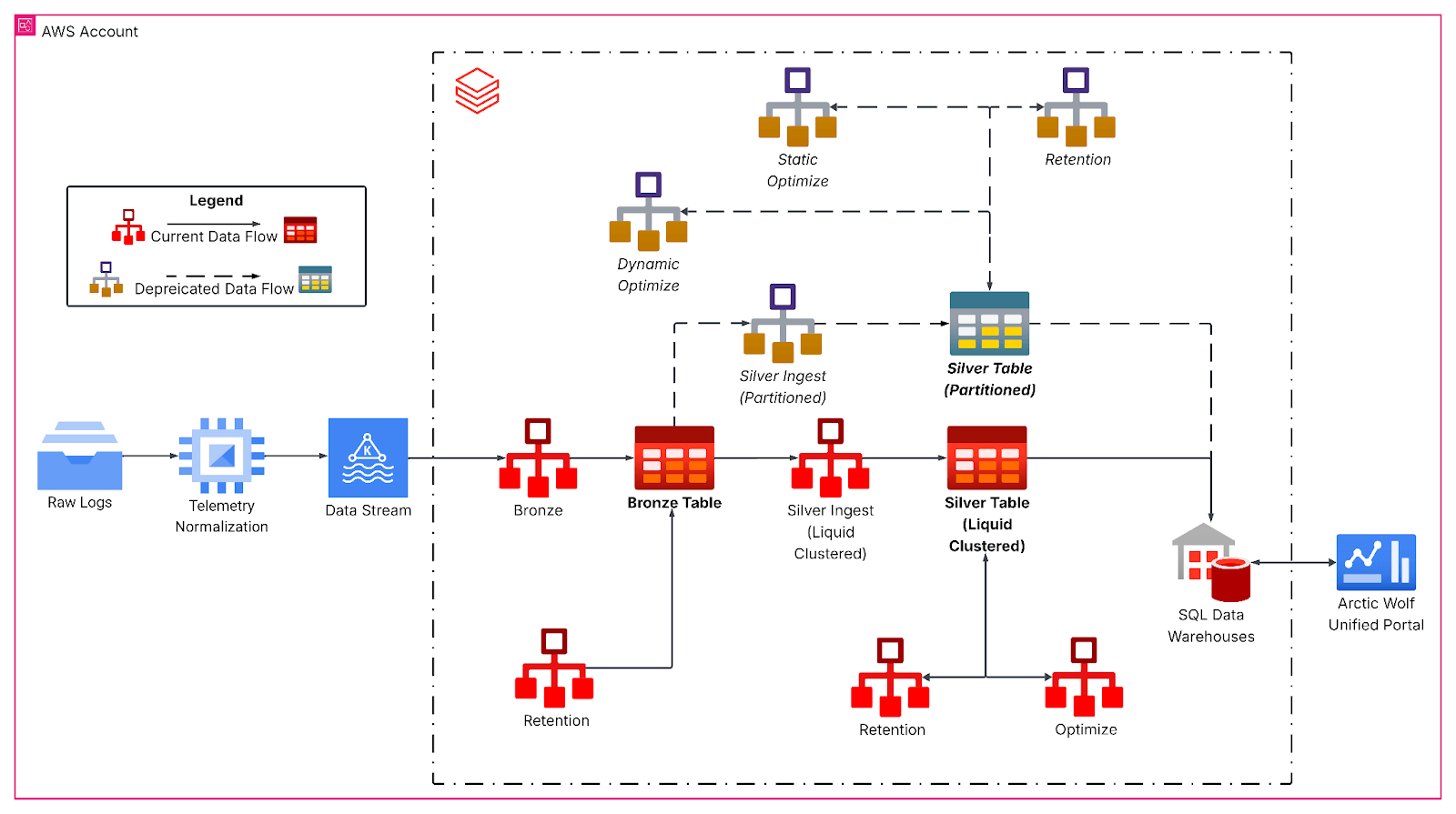
La pipeline riprogettata segue un'architettura medallion, a partire dall'inserimento continuo di Kafka in un livello bronze per i dati degli eventi non elaborati. I Job orari di streaming strutturato appiattiscono quindi i payload JSON nidificati e scrivono su tabelle silver con clustering liquido, formando la base analitica primaria. Qui, le trasformazioni da bronze a silver gestiscono l'evoluzione dello schema, generano colonne temporali derivate e preparano i dati per carichi di lavoro analitici a valle con rigidi SLA di latenza.
Il liquid clustering ha sostituito gli schemi di partizionamento rigidi con chiavi di clustering multidimensionali e sensibili al carico di lavoro, allineate ai modelli di query, in particolare in base all'identificatore del tenant, alla granularità della data, alla dimensione della tabella e alle caratteristiche di arrivo dei dati. La distribuzione più uniforme dei dati ha aumentato, nel nostro caso, la dimensione media dei file a oltre 1 GB, riducendo drasticamente il numero di file scansionati durante le tipiche query a finestra temporale per la nostra tabella.
Approfondimento: Clustering on Write
Inoltre, i nostri processi di streaming strutturato sfruttano il clustering in scrittura per mantenere il layout dei file man mano che arrivano nuovi dati. Funziona come un'operazione OPTIMIZE localizzata, applicando il clustering solo ai dati appena inseriti. Quindi, i dati inseriti sono già ottimizzati. Tuttavia, se i batch di inserimento sono troppo piccoli, producono molti file piccoli ma ben clusterizzati che devono comunque essere clusterizzati durante un'operazione OPTIMIZE globale per ottenere un layout dei dati ideale. Al contrario, se la dimensione del batch in fase di inserimento si avvicina a quella richiesta da Optimize globale, un'ulteriore ottimizzazione è spesso superflua.
Per i carichi di lavoro che inseriscono volumi di dati molto grandi (ad esempio, terabyte), si consiglia di eseguire il batching all'origine, ad esempio utilizzando foreachBatch con maxBytesPerTrigger, per garantire un clustering e un layout dei file efficienti. Con maxBytesPerTrigger, possiamo controllare la dimensione del batch, eliminando molte piccole isole clusterizzate che richiederebbero una riconciliazione tramite l'operazione OPTIMIZE. Con dimensioni prossime a quelle su cui opera l'operazione OPTIMIZE, siamo stati in grado di creare batch ottimali per ridurre l'ulteriore lavoro richiesto da OPTIMIZE.
Impatto sulle analitiche di sicurezza di Arctic Wolf
La migrazione di Arctic Wolf a Liquid Clustering ha apportato miglioramenti sostanziali e quantificabili in termini di prestazioni, aggiornamento dei dati ed efficienza operativa. Le UC Managed Tables con Predictive Optimization hanno anche ridotto la necessità di pianificare la manutenzione.
Il numero di file è sceso da oltre 4M a 2M, riducendo al minimo l'I/O dei file durante le query e mantenendo una buona qualità del cluster. Di conseguenza, le prestazioni delle query sono migliorate drasticamente, consentendo agli analisti della sicurezza di esaminare gli incidenti più rapidamente: ~50% più veloci su tutti i percentili e ~90% più veloci per un gran numero di nostri clienti, con query a 90 giorni che passano da 51 secondi a 6,6 secondi.
Implementando il clustering-on-write, abbiamo ridotto i tempi di aggiornamento dei dati da ore a minuti, accelerando il time-to-approfondimento di circa il 90%. Questo miglioramento consente il rilevamento delle minacce quasi in tempo reale nel Data Lake di Arctic Wolf.
La transizione al liquid clustering e alle tabelle gestite di Unity Catalog ha eliminato il partizionamento legacy, ridotto il debito tecnico e sbloccato funzionalità avanzate di governance e prestazioni. Con un'architettura in grado di elaborare e interrogare oltre 260 miliardi di righe al giorno, offriamo un accesso più rapido ed efficiente ai dati critici di sicurezza provenienti da tutte queste fonti. In combinazione con il nostro Concierge Security® Team, attivo 24 ore su 24, 7 giorni su 7, e il rilevamento delle minacce in tempo reale, ciò consente una risposta e una mitigazione delle minacce più rapide e accurate. Questi elementi di differenziazione aiutano i nostri clienti a ottenere una postura di sicurezza più solida e agile e una maggiore fiducia nella capacità di Arctic Wolf di proteggere i loro ambienti e supportare il successo aziendale continuo.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.