Best Practices for Cost Management on Databricks
di Tomasz Bacewicz e Greg Wood
Questo blog fa parte della nostra serie Admin Essentials, in cui ci concentreremo su argomenti importanti per chi gestisce e mantiene gli ambienti Databricks. Tieni d'occhio ulteriori blog su argomenti aggiuntivi e consulta i nostri blog precedenti sulle best practice di organizzazione funzionale dello spazio di lavoro su Databricks e amministrazione dello spazio di lavoro per amministratori di account, spazi di lavoro e metastore!
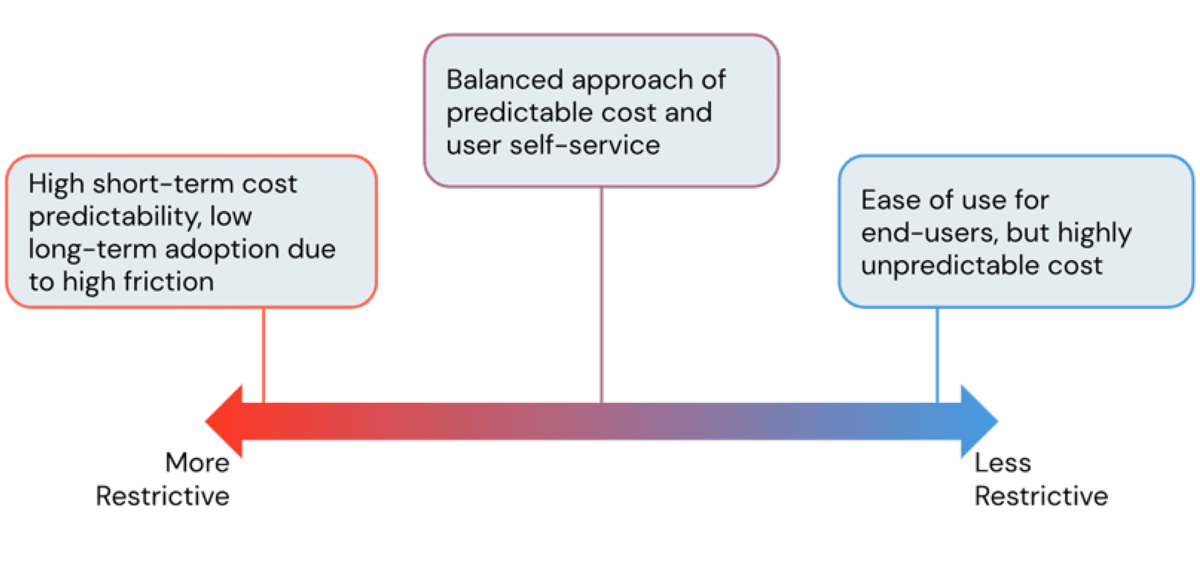
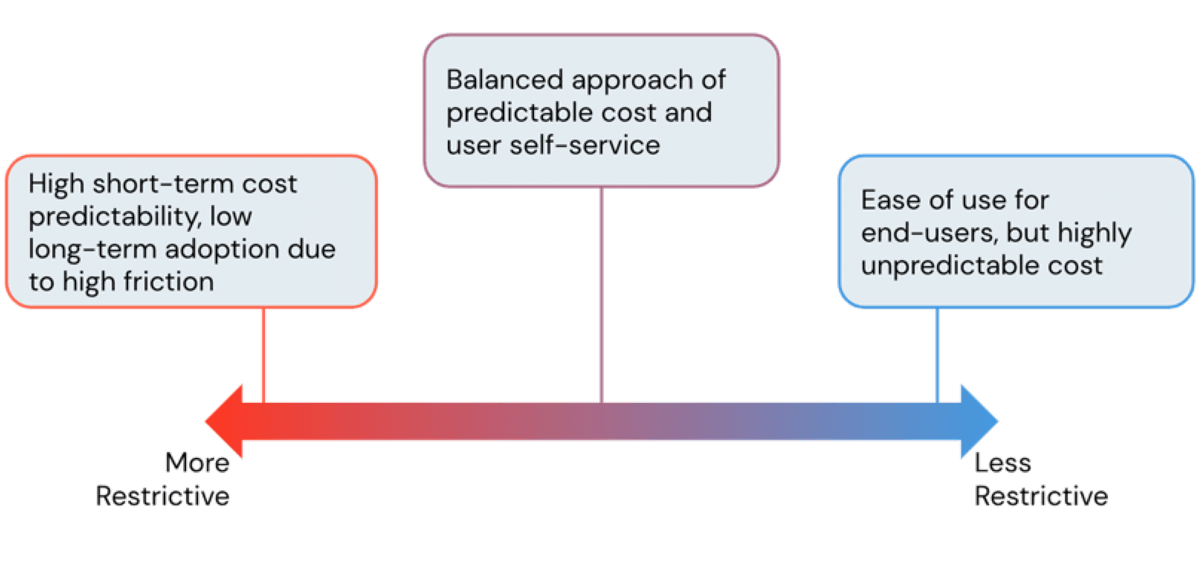
Uno dei principali vantaggi dell'utilizzo di una piattaforma cloud è la sua flessibilità. La Databricks Lakehouse Platform offre agli utenti un accesso facile a calcolo quasi istantaneo e scalabile orizzontalmente. Tuttavia, con questa facilità di creazione di risorse di calcolo, si corre il rischio di costi cloud in aumento quando non viene gestita e senza guardrail. Come amministratori, cerchiamo sempre di trovare il perfetto equilibrio tra evitare costi esorbitanti dell'infrastruttura e consentire agli utenti di lavorare senza attriti inutili. In questo blog, discuteremo degli strumenti di amministrazione Databricks per trovare questo equilibrio e controllare i costi senza limitare la produttività degli utenti.
{kind=link}
Cos'è un DBU?
Prima di addentrarci nei controlli dei costi disponibili sulla piattaforma Databricks, è importante comprendere innanzitutto la base di costo per l'esecuzione di un carico di lavoro. Un Databricks Unit (DBU) è l'unità di consumo sottostante all'interno della piattaforma. Con l'eccezione di un SQL Warehouse, la quantità di DBU consumati si basa sul numero di nodi e sulla potenza computazionale dei tipi di istanza VM sottostanti che fanno parte del rispettivo cluster (poiché i SQL warehouse sono essenzialmente un gruppo di cluster, il tasso DBU è la somma dei tassi DBU dei cluster che compongono l'endpoint). Al livello più alto, ogni cloud avrà tassi DBU leggermente diversi per cluster simili (poiché i tipi di nodo variano tra i cloud), ma il sito Web Databricks dispone di calcolatori DBU per ogni provider cloud supportato (AWS | Azure | GCP).
Per convertire l'utilizzo dei DBU in importi in dollari, avrai bisogno del tasso DBU del cluster, nonché del tipo di carico di lavoro che ha generato il rispettivo DBU (ad es. Lavoro automatizzato, Calcolo per tutti gli scopi, Delta Live Tables, Calcolo SQL, Calcolo Serverless) e del livello del piano di sottoscrizione (Standard e Premium per Azure e GCP; Standard, Premium e Enterprise per AWS). Ad esempio, uno spazio di lavoro Databricks Enterprise ha un tasso DBU per i lavori di 20 centesimi/DBU su AWS. Con un tipo di istanza che funziona a 3 DBU/ora, un cluster di lavori a 4 nodi verrebbe addebitato $2,40 ($0,2 * 3 * 4) per un'ora. I calcolatori DBU possono essere utilizzati per calcolare gli addebiti totali e i prezzi di listino sono riassunti in una matrice specifica per cloud che include SKU e livello (AWS | Azure | GCP).
Poiché i costi vengono calcolati tramite l'utilizzo delle risorse di calcolo, e più specificamente dei cluster, è fondamentale gestire gli spazi di lavoro Databricks tramite policy dei cluster. La sezione successiva discuterà di come diversi attributi delle policy dei cluster possono limitare il consumo di DBU e gestire efficacemente i costi della piattaforma. Le sezioni successive esamineranno anche alcuni dei costi cloud sottostanti da considerare, nonché come monitorare l'utilizzo e la fatturazione di Databricks.
Gestione dei costi tramite policy dei cluster
Cosa sono le policy dei cluster?
Una policy dei cluster consente a un amministratore di controllare l'insieme di configurazioni disponibili durante la creazione di un nuovo cluster e queste policy possono essere assegnate a singoli utenti o gruppi di utenti. Per impostazione predefinita, tutti gli utenti dispongono dell'autorizzazione "consenti creazione cluster illimitata" all'interno di uno spazio di lavoro. Questa autorizzazione dovrebbe essere usata raramente poiché consente all'utente di creare cluster senza alcuna restrizione al di fuori delle policy assegnate, portando potenzialmente a costi non gestiti e fuori controllo.
All'interno di una policy, un amministratore può limitare ogni impostazione di configurazione tramite un valore fisso immutabile, un intervallo di valori più permissivo e regex, o un valore predefinito completamente aperto. Le policy limitano efficacemente la quantità di DBU che può essere consumata da un singolo cluster attraverso restrizioni su tutto, dalle impostazioni più granulari come i tipi di istanza VM agli attributi "sintetici" di livello superiore come il massimo DBU consentito all'ora o i tipi di carico di lavoro del cluster.
Sebbene a prima vista possa sembrare che cluster più restrittivi portino a costi inferiori, non è sempre così. Policy molto restrittive portano a cluster che non riescono a completare le attività in modo tempestivo, con conseguenti costi più elevati dovuti a lavori di lunga durata. Pertanto, è fondamentale adottare un approccio basato sui casi d'uso quando si formulano le policy dei cluster, fornendo ai team la giusta quantità di potenza di calcolo per i loro carichi di lavoro. Per aiutare in questo, Databricks fornisce funzionalità di prestazioni come runtime Apache Spark ottimizzati e, in particolare, il motore Photon, che portano a risparmi sui costi attraverso tempi di elaborazione più rapidi. Discuteremo le policy per i runtime in una sezione successiva, ma prima iniziamo con le policy che gestiscono lo scaling orizzontale.
Limiti del numero di nodi, auto-scaling e auto-terminazione
Una preoccupazione comune riguardo ai costi di calcolo sono i cluster sottoutilizzati o inattivi. Databricks fornisce funzionalità di auto-scaling e auto-terminazione per alleviare queste preoccupazioni dinamicamente e senza intervento diretto dell'utente. Queste funzionalità possono essere applicate tramite policy senza ostacolare le risorse computazionali disponibili per l'utente.
Limiti del numero di nodi e auto-scaling
Le policy possono imporre che la funzionalità di auto-scaling del cluster sia abilitata con un numero minimo di nodi worker impostato. Ad esempio, una policy come quella seguente garantirà l'uso dell'auto-scaling e consentirà a un utente di avere un cluster con fino a 10 nodi worker, ma solo quando sono necessari:
Poiché il tipo di applicazione è "range" sul numero massimo di worker, può essere modificato in un valore inferiore a 10 durante la creazione. Il numero minimo di worker, tuttavia, è impostato su "fixed" a uno, in modo che il cluster venga sempre ridimensionato a un solo worker quando è sottoutilizzato, garantendo risparmi sui costi di calcolo. Un campo aggiuntivo mostrato qui è "defaultValue" che, come suggerisce il nome, imposta un valore predefinito del numero massimo di worker nella pagina di configurazione del cluster. Questo è utile per ridurre il numero massimo di worker all'interno di un cluster per impostazione predefinita, in modo che il creatore debba essere deliberato nel consentire a un cluster di scalare fino a 10 nodi.
Comprendere i casi d'uso durante la creazione e l'assegnazione di policy è fondamentale per quanto riguarda i limiti sui conteggi dei nodi e se l'auto-scaling debba essere applicato. Ad esempio, l'applicazione dell'auto-scaling funziona bene per:
- Cluster di calcolo condivisi per tutti gli scopi: un team può condividere un cluster per analisi ad hoc e lavori sperimentali o carichi di lavoro di machine learning.
- Lavori batch di lunga durata con complessità variabile: i lavori possono sfruttare l'auto-scaling in modo che il cluster si adatti al grado di risorse necessarie.
Nota che i lavori che utilizzano l'auto-scaling non dovrebbero essere sensibili al tempo, poiché lo scaling del cluster può ritardare il completamento a causa del tempo di avvio dei nodi. Per aiutare ad alleviare questo problema, utilizzare un instance pool ogni volta che è possibile.
I carichi di lavoro di streaming standard non hanno potuto beneficiare storicamente del ridimensionamento automatico; scalavano semplicemente al numero massimo di nodi e vi rimanevano per la durata del job. Un'opzione più pronta per la produzione per i team che lavorano su questi tipi di carichi di lavoro è sfruttare Delta Live Tables e il ridimensionamento automatico avanzato (i carichi di lavoro DLT possono essere applicati con la policy "cluster_type" discussa più avanti in questo blog). Nonostante DLT sia stato sviluppato tenendo conto dei carichi di lavoro di streaming, è altrettanto applicabile per le pipeline batch sfruttando l'opzione Trigger.AvailableNow che consente aggiornamenti incrementali delle tabelle di destinazione.
Un'altra configurazione comune delle policy di dimensionamento dei cluster è la policy a nodo singolo. I cluster a nodo singolo possono essere utili per nuovi utenti che desiderano esplorare la piattaforma, team di data science che sfruttano librerie ML non distribuite, nonché per utenti che necessitano di eseguire analisi esplorative di dati leggere. Come illustrato nell'esempio di policy per cluster a nodo singolo, le policy possono essere limitate per sfruttare una pool di istanze specifica. Di conseguenza, il team assegnato a questa policy avrà un limite al numero di cluster a nodo singolo che potrà creare in base all'impostazione di capacità massima della pool.
Terminazione automatica
Un altro attributo che può essere impostato durante la creazione di un cluster sulla piattaforma Databricks è il tempo di terminazione automatica, che arresta un cluster dopo un certo periodo di inattività. I periodi di inattività sono definiti dall'assenza di qualsiasi tipo di attività sul cluster, come job Spark, Structured Streaming o chiamate JDBC. Le attività che non sono considerate attività sul cluster includono la creazione di una connessione SSH al cluster e l'esecuzione di comandi bash.
La finestra di terminazione automatica più comune è di un'ora. Ad esempio, ecco la policy impostata su una finestra fissa di un'ora:
In questo esempio, l'attributo "hidden" viene aggiunto anche a questo controllo, il che nasconde il widget dalla pagina di configurazione del cluster dell'utente. Questo attributo è applicabile solo ai cluster all-purpose, poiché i cluster di job e DLT si arrestano automaticamente al completamento di tutte le attività assegnate.
Runtime e Photon dei cluster
I Runtime di Databricks sono una parte importante dell'ottimizzazione delle prestazioni su Databricks; i clienti spesso traggono un beneficio automatico passando a un cluster che esegue un runtime più recente senza molte altre modifiche alla loro configurazione. Per un amministratore che crea policy per i cluster, educare i creatori di cluster sugli effetti dell'esecuzione di un runtime più recente è prezioso per il risparmio sui costi. Man mano che gli utenti passano a runtime più recenti, i runtime più vecchi possono essere eliminati e limitati tramite policy. Per un rapido esempio, ecco l'attributo "spark_version" che limita gli utenti solo ai DB Runtime delle versioni 11.0 o 11.1.
Tuttavia, questa policy potrebbe essere resa più flessibile consentendo altre versioni, runtime ML, runtime Photon o runtime GPU espandendo l'elenco consentito o utilizzando espressioni regolari.
L'altra funzionalità di runtime da considerare quando si ottimizza per le prestazioni al fine di ridurre i costi è l'uso del nostro motore Photon vettorizzato. Photon accelera in modo intelligente parti di un carico di lavoro attraverso un motore Spark vettorizzato con cui i clienti vedono un aumento delle prestazioni da 3 a 8 volte. Il massiccio aumento delle prestazioni porta a job più rapidi e, di conseguenza, a costi totali inferiori.
Tipi di istanze cloud e istanze spot
Durante la creazione del cluster, i tipi di istanze VM possono essere selezionati sia per il nodo driver che per i nodi worker separatamente. I tipi di istanze disponibili hanno un diverso tasso DBU calcolato e possono essere trovati nelle pagine di stima dei prezzi di Databricks per ogni rispettivo cloud (AWS, Azure, GCP). Ad esempio, in AWS il tipo di istanza m4.large con due core e 8 GB di memoria consuma 0,4 DBU all'ora, mentre un tipo di istanza m4.16xlarge con 64 core e 256 GB di memoria consuma 12 DBU all'ora in modalità di calcolo all-purpose. Con una gamma così ampia di utilizzo DBU tra le risorse di calcolo, è fondamentale limitare questo attributo tramite una policy.
I tipi di istanze cloud possono essere controllati più convenientemente dal tipo "allowlist" o altrimenti dal tipo "fixed" per consentire l'uso di un solo tipo di istanza. L'esempio seguente mostra l'attributo "node_type_id" che imposta una policy sui tipi di nodi worker disponibili per l'utente, mentre "driver_node_type_id" imposta una policy sul tipo di nodo driver.
In qualità di amministratore che crea queste policy, è importante avere un'idea del tipo di carichi di lavoro che ogni team sta eseguendo e assegnare le policy appropriate. I carichi di lavoro con quantità di dati minori dovrebbero richiedere solo tipi di istanze con memoria inferiore, mentre l'addestramento di modelli di deep learning trarrebbe maggior beneficio dai cluster GPU, che generalmente consumano più DBU. In definitiva, limitare i tipi di istanze può essere un atto di bilanciamento. Quando un team deve eseguire carichi di lavoro che richiedono più risorse di quelle disponibili a causa di restrizioni di policy, il job può richiedere più tempo per essere completato e, di conseguenza, aumentare i costi. Ci sono alcune best practice da seguire durante la configurazione di un cluster per un carico di lavoro definito. Ad esempio, si consiglia di scalare verticalmente (utilizzando tipi di istanze più potenti) rispetto a scalare orizzontalmente (aggiungendo più nodi) per carichi di lavoro complessi costituiti da molte trasformazioni ampie che richiedono lo shuffling dei dati. Detto questo, ai team meno esperti dovrebbero essere assegnate policy limitate a tipi di istanze più piccoli, poiché VM inutilmente potenti non offriranno molti vantaggi per carichi di lavoro più comuni e meno complessi.
Una capacità di risparmio sui costi relativamente nuova della piattaforma Databricks è la possibilità di utilizzare VM abilitate per AWS Graviton, costruite sull'architettura del set di istruzioni Arm64. Sulla base di studi forniti da AWS, oltre ai benchmark eseguiti con Databricks utilizzando Photon, queste istanze abilitate Graviton hanno alcuni dei migliori rapporti prezzo/prestazioni disponibili nel set di tipi di istanze AWS EC2.
Istanze spot
Databricks offre un'altra configurazione che può far risparmiare sui costi, in particolare sui costi di calcolo delle VM sottostanti, con le istanze spot (l'opzione disponibile tramite Databricks su GCP utilizza istanze preemptible che sono simili alle istanze spot). Le istanze spot sono VM di riserva offerte dal provider cloud sottostante che vengono messe all'asta in un marketplace live. Queste istanze possono consentire sconti significativi, offrendo talvolta riduzioni fino al 90% sui costi di calcolo delle istanze. Il compromesso con le istanze spot è che possono essere ritirate dal provider cloud sottostante in qualsiasi momento con un breve preavviso (2 minuti per AWS, 30 secondi per Azure e GCP).
Se si utilizza AWS, è possibile definire una policy del cluster che includa l'uso di istanze spot in questo modo:
Su Azure:
In questi esempi, solo un nodo (in particolare il nodo driver) può essere un'istanza on-demand, mentre tutti gli altri nodi all'interno del cluster saranno istanze spot durante la creazione iniziale del cluster. Poiché l'opzione di fallback è abilitata qui, verrà richiesta un'istanza on-demand per sostituire un'istanza spot che è stata richiesta indietro al provider cloud. Sebbene le policy su GCP non possano attualmente applicare l'attributo "first_on_demand", i nodi preemptible possono comunque essere applicati in questo modo:
Per impostazione predefinita, solo il nodo driver utilizzerà un'istanza on-demand all'avvio del cluster quando sono abilitate le istanze preemptible.
Quando si eseguono processi tolleranti ai guasti come carichi di lavoro sperimentali o query ad hoc in cui l'affidabilità e la durata del carico di lavoro non sono una priorità, le istanze spot possono fornire un modo semplice per ridurre i costi delle istanze. Pertanto, le istanze spot sono più adatte per ambienti di sviluppo e staging.
I tassi di esclusione e i prezzi delle istanze spot possono variare tra le dimensioni delle magliette e le regioni cloud. Pertanto, la pianificazione per configurazioni di cluster ottimali può essere facilitata da strumenti dei rispettivi provider cloud come l'AWS Spot Instance Advisor, la Cronologia e prezzi delle istanze spot di Azure nel portale dell'account Azure, o il Calcolatore dei prezzi di Google Cloud.
Si noti che Azure dispone di una leva aggiuntiva per il controllo dei costi: le istanze riservate possono essere utilizzate da Databricks, fornendo un altro sconto (potenzialmente elevato) senza aggiungere instabilità.
Tagging del cluster
La possibilità di osservare le risorse utilizzate da un team è abilitata dal tagging del cluster. Questi tag si propagano a livello del provider cloud in modo che l'utilizzo e i costi possano essere attribuiti sia dalla piattaforma Databricks che dai costi cloud sottostanti. Tuttavia, senza una policy del cluster, un utente che crea un cluster non è tenuto ad assegnare alcun tag. Pertanto, quando un amministratore crea una policy per un team che richiede l'accesso alla piattaforma Databricks, è fondamentale che la policy includa un enforcement dei tag del cluster specifico per il team a cui verrà assegnata la policy.
Ecco un esempio di creazione di una policy con un tag di centro di costo personalizzato applicato:
Una volta assegnato un tag per identificare il team che utilizza il cluster, gli amministratori possono analizzare i log di utilizzo per collegare i DBU e i costi generati al team che utilizza il cluster. Questi tag si propagheranno anche a livello di utilizzo della VM in modo che anche i costi delle istanze del provider cloud possano essere attribuiti al team o al centro di costo. Le opzioni per il monitoraggio dei log di utilizzo in generale sono discusse in una sezione seguente.
Una distinzione importante riguardo ai tag dei cluster quando si utilizza un pool di cluster è che solo i tag del pool di cluster (e non i tag del cluster) si propagano alle istanze VM sottostanti. La creazione di pool di cluster non è limitata dalle policy dei cluster e, pertanto, un amministratore dovrebbe creare pool di cluster con i tag appropriati prima di assegnare i permessi di utilizzo a un team. Il team può quindi avere accesso tramite policy per collegarsi al rispettivo pool durante la creazione dei propri cluster. Ciò garantisce che i tag associati al team che utilizza il pool vengano propagati a livello di istanza VM per la fatturazione.
Attributi virtuali della policy
Oltre alle impostazioni visibili nella pagina di configurazione del cluster, ci sono anche attributi "virtuali" che possono essere limitati dalle policy. Nello specifico, i due attributi disponibili in questa categoria sono "dbus_per_hour" e "cluster_type".
Con l'attributo "dbus_per_hour", i creatori di cluster possono avere una certa flessibilità nella configurazione, purché l'utilizzo dei DBU rientri nella restrizione impostata nella policy. Questo attributo di per sé non limita direttamente i costi attribuiti alle istanze VM sottostanti come gli attributi discussi in precedenza (sebbene le tariffe dei DBU siano spesso correlate alle tariffe delle istanze VM). Ecco un esempio di definizione di policy che limita l'utente alla creazione di cluster che utilizzano meno di 10 DBU all'ora:
L'altro attributo virtuale disponibile è "cluster_type", che può essere utilizzato per limitare gli utenti ai diversi tipi di cluster. I tipi consentiti tramite questo attributo sono "all-purpose", "job" e "dlt", quest'ultimo si riferisce a Delta Live Tables. Ecco un esempio di utilizzo di questa policy:
Le restrizioni sul tipo di cluster sono particolarmente preziose quando si lavora con team distinti impegnati nel ciclo di vita dello sviluppo e del deployment. Un team che lavora allo sviluppo di una nuova pipeline ETL o di machine learning richiederebbe tipicamente l'accesso solo a un cluster all-purpose, mentre i team di ingegneria di deployment utilizzerebbero cluster di job o Delta Live Tables (DLT). Queste policy possono applicare le best practice garantendo che il tipo di cluster corretto venga utilizzato per ogni fase specifica del ciclo di vita di sviluppo e deployment.
Una cattiva pratica comune è il deployment di carichi di lavoro automatizzati che condividono un cluster all-purpose. A prima vista, questa potrebbe sembrare l'opzione più economica poiché il consumo può essere ricondotto a un singolo cluster. Tuttavia, questo tipo di configurazione porta a contesa di risorse che prolunga il tempo di esecuzione del cluster, aumentando i costi di calcolo. Invece, l'utilizzo di cluster di job isolati per eseguire un job alla volta riduce la durata del calcolo necessaria per completare un set di job. Ciò porta a un minor utilizzo di DBU Databricks e a costi inferiori per le istanze cloud sottostanti. Prestazioni migliori insieme a tariffe di costo inferiori per DBU offerte dai cluster di job portano a risparmi sui costi drastici. Abbiamo visto clienti risparmiare decine di migliaia di dollari semplicemente spostando solo il dieci percento dei loro carichi di lavoro da cluster all-purpose a cluster di job. Il riutilizzo dei cluster di job può essere sfruttato per garantire il completamento tempestivo di un set di job rimuovendo il tempo di avvio del cluster tra ogni attività.
Per formulare policy che consentano ai team di creare cluster per il carico di lavoro corretto, ci sono alcune best practice da seguire. Alcuni modelli di policy restrittive tipici sono cluster a nodo singolo, cluster solo per job o cluster all-purpose con auto-scaling da condividere tra i team. Esempi di policy complete sono disponibili qui.
Costi del provider cloud
Dal punto di vista del consumo Databricks (DBU), tutti i costi possono essere ricondotti alle risorse di calcolo utilizzate. Tuttavia, dovrebbero essere considerati anche i costi attribuiti alla rete e allo storage del cloud sottostante.
Storage
Il vantaggio di utilizzare una piattaforma come Databricks è che funziona in modo impeccabile con storage cloud relativamente economici come ADLS Gen2 su Azure, S3 su AWS o GCS su GCP. Ciò è particolarmente vantaggioso quando si utilizza il formato Delta Lake, poiché fornisce governance dei dati per un livello di storage altrimenti difficile da gestire, nonché ottimizzazioni delle prestazioni quando utilizzato in combinazione con Databricks.
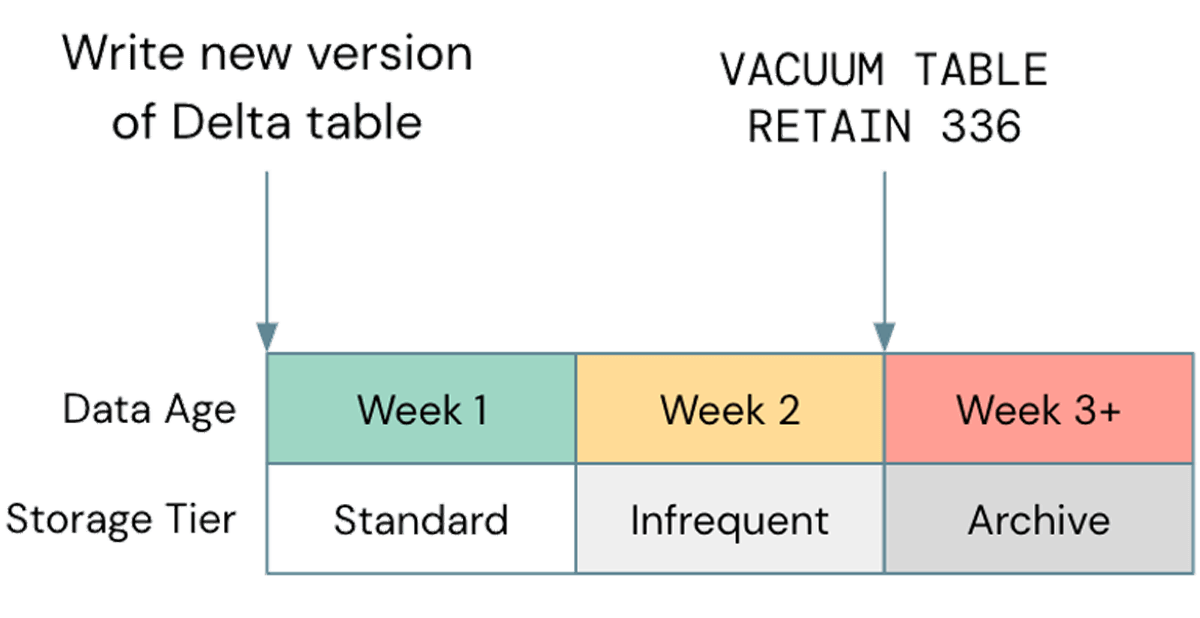
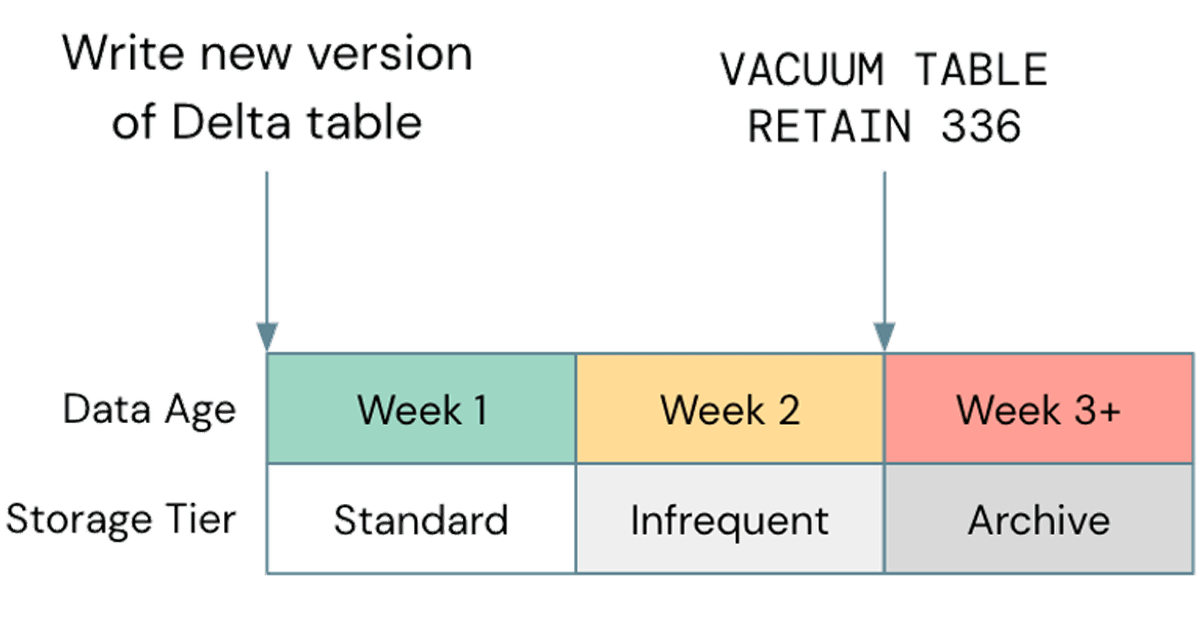
Una comune errata ottimizzazione, per quanto riguarda lo storage, è trascurare l'utilizzo della gestione del ciclo di vita ove possibile; in un caso recente, abbiamo osservato un bucket S3 di un cliente che era di circa 2,5 PB, di cui solo circa 800 TB erano dati effettivi. I restanti 1,7 PB erano dati versionati che non fornivano alcun valore. Sebbene l'eliminazione degli oggetti obsoleti dallo storage cloud sia una best practice generale, è importante allineare questo con il ciclo di Vacuum di Delta. Se il ciclo di vita dello storage elimina gli oggetti prima che possano essere sottoposti a vacuum da Delta, le tue tabelle potrebbero danneggiarsi; assicurati di testare eventuali policy del ciclo di vita su dati non di produzione prima di implementarle più ampiamente. Una policy di esempio potrebbe essere simile a questa:
{kind=link}
Si noti che i livelli di storage non standard, come Glacier su S3 o Archive su ADLS, non sono supportati da Databricks, quindi assicurati di eseguire il Vacuum prima che vengano utilizzati tali livelli.
Networking
I dati utilizzati all'interno della piattaforma Databricks possono provenire da una varietà di fonti diverse, dai data warehouse ai sistemi di streaming come Kafka. Tuttavia, l'utilizzatore di larghezza di banda più comune è la scrittura su livelli di storage come S3 o ADLS. Per ridurre i costi di rete, i workspace Databricks dovrebbero essere distribuiti con l'obiettivo di minimizzare la quantità di dati trasferiti tra regioni e zone di disponibilità. Ciò include la distribuzione nella stessa regione della maggior parte dei tuoi dati, ove possibile, e potrebbe includere il lancio di workspace regionali, se necessario.
Quando si utilizza una VPC gestita dal cliente per un'area di lavoro Databricks su AWS, i costi di rete possono essere ridotti sfruttando i VPC Endpoints, che consentono la connettività tra la VPC e i servizi AWS senza un Internet Gateway o un NAT Device. L'utilizzo di endpoint riduce i costi sostenuti dal traffico di rete e rende anche la connessione più sicura. Gli endpoint Gateway, in particolare, possono essere utilizzati per connettersi a S3 e DynamoDB, mentre gli endpoint di interfaccia possono essere utilizzati in modo simile per ridurre il costo delle istanze di calcolo che si connettono al piano di controllo Databricks. Questi endpoint sono disponibili purché l'area di lavoro utilizzi la Secure Cluster Connectivity.
Allo stesso modo su Azure, è possibile configurare Private Link o Service Endpoints affinché Databricks comunichi con servizi come ADLS per ridurre i costi NAT. Su GCP, è possibile sfruttare Private Google Access (PGA) in modo che il traffico tra Google Cloud Storage (GCS) e Google Container Registry (GCR) utilizzi la rete interna di Google anziché Internet pubblico, bypassando di conseguenza anche l'uso di un dispositivo NAT.
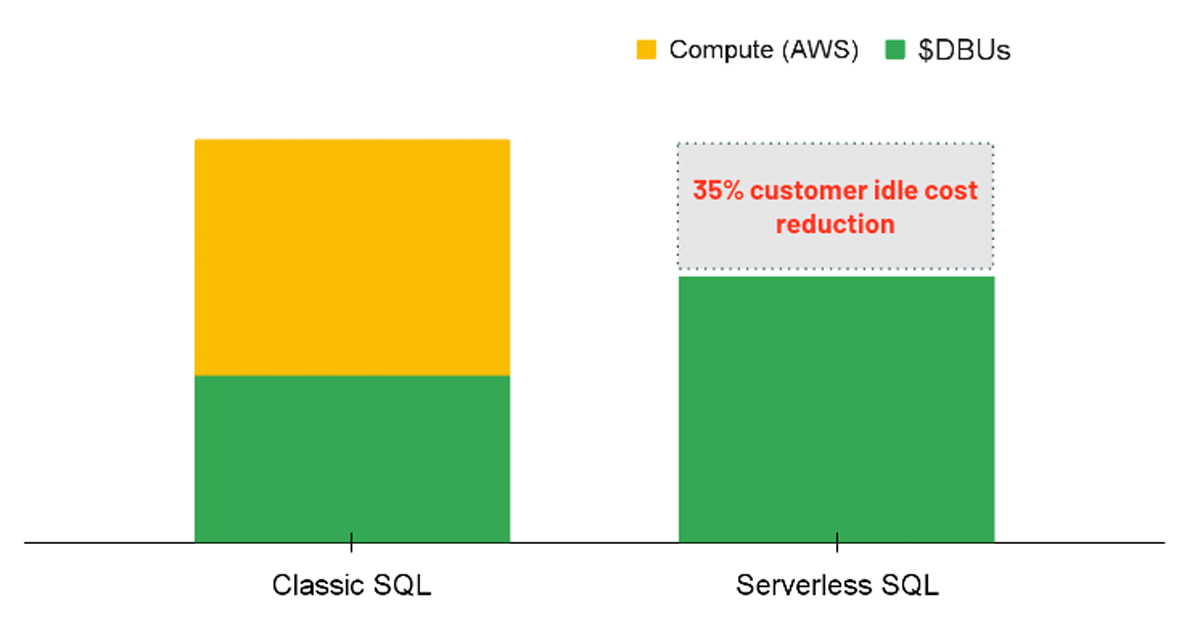
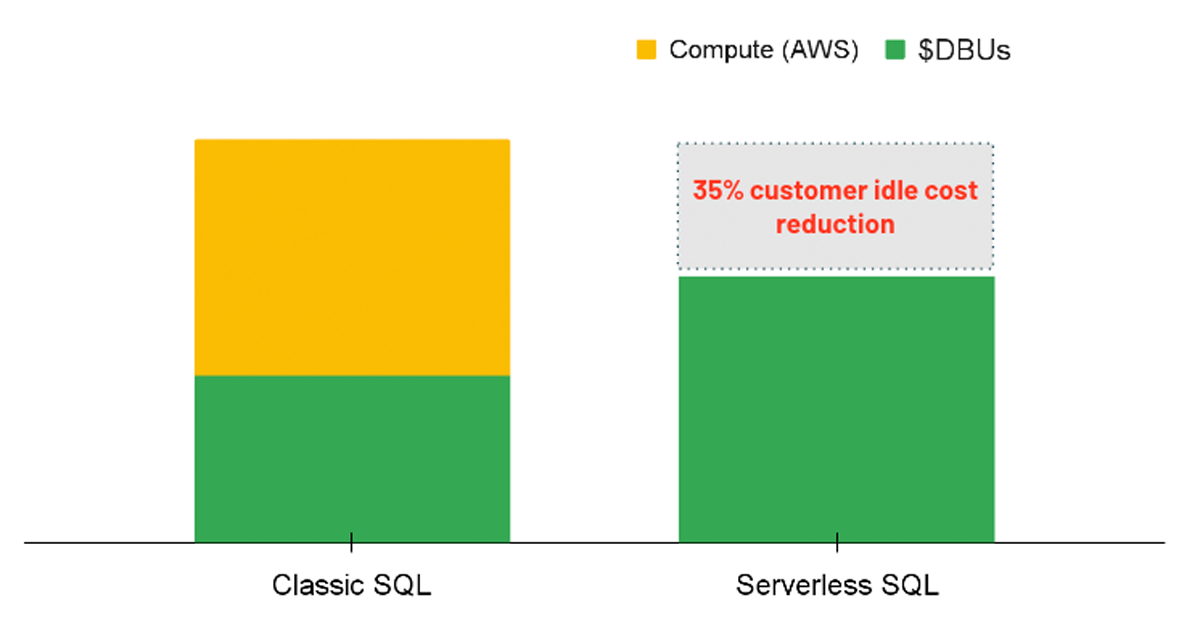
Calcolo serverless
Per i carichi di lavoro di analisi, un'opzione da considerare è l'utilizzo di un SQL Warehouse con l'opzione Serverless abilitata. Con Serverless SQL, la piattaforma Databricks gestisce un pool di istanze di calcolo pronte per essere assegnate a un utente ogni volta che viene avviato un carico di lavoro. Pertanto, i costi delle istanze sottostanti sono interamente gestiti da Databricks anziché avere due addebiti separati (ovvero il costo di calcolo DBU e il costo di calcolo cloud sottostante).
{kind=link}
Serverless porta un vantaggio di costo fornendo risorse di calcolo istantanee quando viene eseguita una query, riducendo i costi di inattività dei cluster sottoutilizzati. Nello stesso modo, serverless consente un auto-scaling più preciso in modo che i carichi di lavoro possano essere completati in modo efficiente, risparmiando di conseguenza sui costi migliorando le prestazioni. Sebbene l'opzione serverless non sia ancora direttamente applicabile tramite una policy, gli amministratori possono abilitare l'opzione per tutti gli utenti con autorizzazioni di creazione di SQL Warehouse.
Monitoraggio dell'utilizzo
Oltre a controllare i costi tramite le policy dei cluster e le configurazioni di distribuzione dell'area di lavoro, è altrettanto importante per gli amministratori avere la possibilità di monitorare i costi. Databricks offre alcune opzioni per farlo con funzionalità per automatizzare notifiche e avvisi basati sull'analisi dell'utilizzo. Nello specifico, gli amministratori possono utilizzare la console dell'account Databricks per una rapida panoramica dell'utilizzo, analizzare i log di utilizzo per una visualizzazione più granulare e utilizzare la nostra nuova API Budget per ricevere notifiche attive quando i budget vengono superati.
Utilizzo della console dell'account
Con l'architettura Databricks Enterprise 2.0, la console dell'account include una pagina di utilizzo che fornisce agli amministratori la possibilità di visualizzare l'utilizzo per DBU o importo in dollari. Il grafico può mostrare il consumo con una visualizzazione aggregata, raggruppata per area di lavoro o raggruppata per SKU. Quando si raggruppa per SKU, l'utilizzo viene mostrato per cluster di job, cluster multiuso o calcolo SQL come esempi. Se il grafico è segmentato per area di lavoro, ci sarà un gruppo mostrato per le prime nove aree di lavoro per consumo DBU con l'ultimo raggruppamento come somma combinata di tutte le altre aree di lavoro. Per comprendere i dettagli più granulari di ogni singola area di lavoro individualmente, una tabella si trova in fondo alla pagina che elenca ogni area di lavoro separatamente insieme agli importi DBU/$USD per SKU. Questa pagina è adatta agli amministratori per ottenere una visione completa dell'utilizzo e dei costi in tutte le aree di lavoro sotto un account.
Poiché Databricks è un servizio di prima parte sulla piattaforma Azure, lo strumento Azure Cost Management può essere sfruttato per monitorare l'utilizzo di Databricks (insieme a tutti gli altri servizi su Azure). A differenza della Console dell'Account per le distribuzioni Databricks su AWS e GCP, le funzionalità di monitoraggio di Azure forniscono dati fino al livello di granularità dei tag. I tag personalizzati su Azure possono essere creati non solo a livello di cluster, ma anche a livello di area di lavoro. Questi tag verranno visualizzati come gruppi e filtri durante l'analisi dei dati di utilizzo. All'interno di questi report, l'utilizzo generato dal calcolo Databricks verrà visualizzato insieme all'utilizzo dell'istanza sottostante comodamente all'interno della stessa vista. I log possono anche essere consegnati a un container di archiviazione secondo una pianificazione e utilizzati per analisi e avvisi più automatizzati, come spiegato nella sezione successiva.
Gli amministratori hanno la possibilità di scaricare manualmente i log di utilizzo dalla console dell'account, dalla pagina di utilizzo o tramite l'Account API. Tuttavia, un processo più efficiente per analizzare questi log di utilizzo è configurare la consegna automatica dei log allo storage cloud (AWS, GCP). Ciò si traduce in un file CSV giornaliero che contiene l'utilizzo per ogni area di lavoro in uno schema granulare.
Una volta configurata la consegna dei log di utilizzo in uno qualsiasi dei tre cloud, una best practice comune è creare una pipeline di dati all'interno di Databricks che ingerirà questi dati giornalmente e li salverà in una tabella Delta utilizzando un flusso di lavoro pianificato. Questi dati possono quindi essere utilizzati per l'analisi dell'utilizzo o per attivare avvisi che notificano agli amministratori o ai team leader responsabili della spesa del centro di costo quando il consumo raggiunge una soglia prestabilita.
API Budget
Una funzionalità imminente per semplificare la definizione del budget sui costi di calcolo Databricks è il nuovo endpoint budget (attualmente in anteprima privata) all'interno dell'Account API. Ciò consentirà a chiunque utilizzi un'area di lavoro Databricks di essere notificato una volta che una soglia di budget viene raggiunta su qualsiasi intervallo di tempo personalizzato filtrato per area di lavoro, SKU o tag del cluster. Pertanto, un budget può essere configurato per qualsiasi area di lavoro, centro di costo o team tramite questa API.
Riepilogo
Sebbene la Databricks Lakehouse Platform copra molti casi d'uso e profili utente, miriamo a fornire un set unificato di strumenti per aiutare gli amministratori a bilanciare il controllo dei costi con l'esperienza utente. In questo blog abbiamo delineato diverse strategie per affrontare questo equilibrio:
- Utilizzare le Cluster Policies per controllare quali utenti sono in grado di creare cluster, nonché le dimensioni e l'ambito di tali cluster
- Progettare l'ambiente per ridurre al minimo i costi non DBU generati dalle aree di lavoro Databricks, come i costi di archiviazione e di rete
- Utilizzare strumenti di monitoraggio per assicurarsi che le aspettative di costo siano soddisfatte e che siano in atto pratiche efficaci
Dai un'occhiata ai nostri altri blog focalizzati sugli amministratori collegati in questo articolo e tieni d'occhio i blog aggiuntivi in arrivo. Assicurati anche di provare nuove funzionalità come Private Link (AWS | Azure) e Budgeting!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.