Costruzione con Databricks Document Intelligence e Lakeflow
Trasforma la conoscenza aziendale bloccata in intelligenza affidabile e interrogabile
- La maggior parte della conoscenza aziendale è inaccessibile in documenti non strutturati, mentre l'attuale elaborazione intelligente dei documenti (IDP) è spesso fragile e inaffidabile
- Databricks Document Intelligence e Lakeflow consentono agli ingegneri dei dati di creare e automatizzare facilmente un flusso di lavoro IDP end-to-end: ingestione di dati non strutturati, analisi con intelligenza artificiale basata sul contesto aziendale e orchestrazione su larga scala, il tutto all'interno di una piattaforma governata
- I team di dati possono far emergere documenti precedentemente nascosti in set di dati affidabili e interrogabili che aiutano a sbloccare nuove intuizioni, flussi di lavoro agenti e valore per la loro attività
Nonostante decenni di perfezionamento delle pipeline di dati strutturati, l'80% della conoscenza aziendale rimane funzionalmente invisibile, intrappolato in PDF, immagini e documenti d'ufficio.
Tradizionalmente, l'Intelligent Document Processing (IDP) è stato un incubo frammentato. Prima dell'era dell'IA generativa, le organizzazioni erano costrette a fare affidamento su API NLP e computer vision disconnesse che si trovavano al di fuori delle loro piattaforme dati primarie. Questi fornitori di OCR (riconoscimento ottico dei caratteri) isolati offrivano un'accuratezza limitata e mancavano di protocolli di governance formali, creando un attrito significativo. Per mantenere la promessa dell'Enterprise AI, abbiamo bisogno di un approccio unificato che integri l'intelligenza dei dati direttamente nel ciclo di vita dei dati.
Oggi, mostriamo come gli ingegneri dei dati possono sfruttare Lakeflow, la soluzione unificata di ingegneria dei dati di Databricks, e Databricks Document Intelligence per sbloccare quei dati e trasformarli in intelligenza che impatta sul business costruendo IDP autonomi di livello di produzione sulla loro Databricks Platform.

Passaggio 1: Ingestione sicura con Lakeflow Connect
I documenti aziendali vivono in depositi isolati, accessibili solo tramite integrazioni API fragili e codificate su misura che si rompono nel momento in cui una cartella viene rinominata. Lakeflow Connect, la soluzione di Databricks per l'ingestione di dati nel lakehouse, cambia le regole del gioco con connettori integrati per molte applicazioni aziendali popolari, database e origini file, tra cui SharePoint e Google Drive.
Questa soluzione offre un'ingestione a manutenzione zero rimuovendo la necessità di gestire complessi flussi OAuth o script Python personalizzati. I documenti atterrano direttamente in Unity Catalog Volumes e tabelle, quindi il controllo degli accessi, la lineage e l'auditing si applicano non appena il file è nel lakehouse, e puoi riutilizzare le stesse policy basate sugli attributi e granulari su cui fai già affidamento per i dati strutturati.
Ottieni anche un'ingestione rapida ed efficiente su larga scala grazie alle robuste capacità di Lakeflow Connect, incluse letture e scritture incrementali che evitano ri-estrazioni complete di grandi librerie sia per i backfill batch che per i flussi di documenti quasi in tempo reale se combinati con lo streaming downstream.
Passaggio 2: Iniziare con Databricks Document Intelligence
Questi documenti aziendali contengono alcune delle informazioni più preziose della tua organizzazione, ma sono intrinsecamente disordinati, variabili e incoerenti. Pagine scansionate, note scritte a mano e tabelle annidate intrappolano le tue informazioni più preziose. Per risolvere questo problema, non hai solo bisogno di un altro strumento di estrazione documenti; come osserva Forrester, hai bisogno di una "evoluzione architetturale basata sul ragionamento". Con questo approccio, Gartner prevede che GenAI ridurrà del 70% la necessità di modelli di documenti addestrati su misura.
Oggi, con Databricks Document Intelligence, puoi portare la comprensione dei documenti allo stato dell'arte direttamente ai tuoi dati. I tuoi team di ingegneria dei dati possono sfruttare funzioni AI appositamente progettate che possono in modo affidabile analizzare, strutturare e arricchire documenti complessi proprio accanto alle tue pipeline di dati esistenti, il tutto governato in modo trasparente da Unity Catalog.
- ai_parse_document (nuovo - GA): Questa funzione converte file non strutturati in rappresentazioni strutturate utilizzando il tipo di dati Variant. Gestisce nativamente la complessità dell'input che in genere confonde i parser tradizionali, come immagini scansionate, scrittura a mano e layout variabili, preservando al contempo la struttura critica del documento (ad es. tabelle annidate, sezioni ed intestazioni) che l'estrazione di testo piatto perderebbe. Ciò consente di evolvere gli schemi nel tempo senza interrompere le pipeline. A valle, si tratta l'output VARIANT come una rappresentazione flessibile bronze/silver, proiettandola in colonne Delta nei livelli silver/gold utilizzando SQL o PySpark in Lakeflow Spark Declarative Pipelines.
Oltre alla struttura analizzata, puoi concatenare ulteriori funzioni AI ottimizzate per la ricerca:
- ai_extract (PuPr) per estrarre informazioni strutturate come date di efficacia e scadenza dei contratti, controparti, totali delle fatture, tasse, valuta e numeri d'ordine d'acquisto.
- ai_classify (PuPr) per instradare i documenti per tipo (fattura, ordine d'acquisto, SOW, NDA), urgenza/rischio o unità aziendale di appartenenza.
- ai_prep_search (nuovo - Beta) per dividere intelligentemente i documenti in blocchi per un embedding downstream di alta qualità, preparandoli per casi d'uso di recupero o ricerca
Di seguito un semplice esempio di concatenazione di ai_parse_document e ai_extract.
Nota: questo esempio mostra PySpark, ma puoi anche usare SQL (vedi documentazione).
Poiché si tratta di funzioni AI gestite integrate nella Databricks Platform, Document Intelligence può combinarle con il tuo contesto aziendale (metadati del catalogo, semantica aziendale, tabelle esistenti) per alimentare flussi di lavoro agenti che ragionano sui tuoi dati con alta precisione, radicati nel contesto del tuo dominio aziendale.
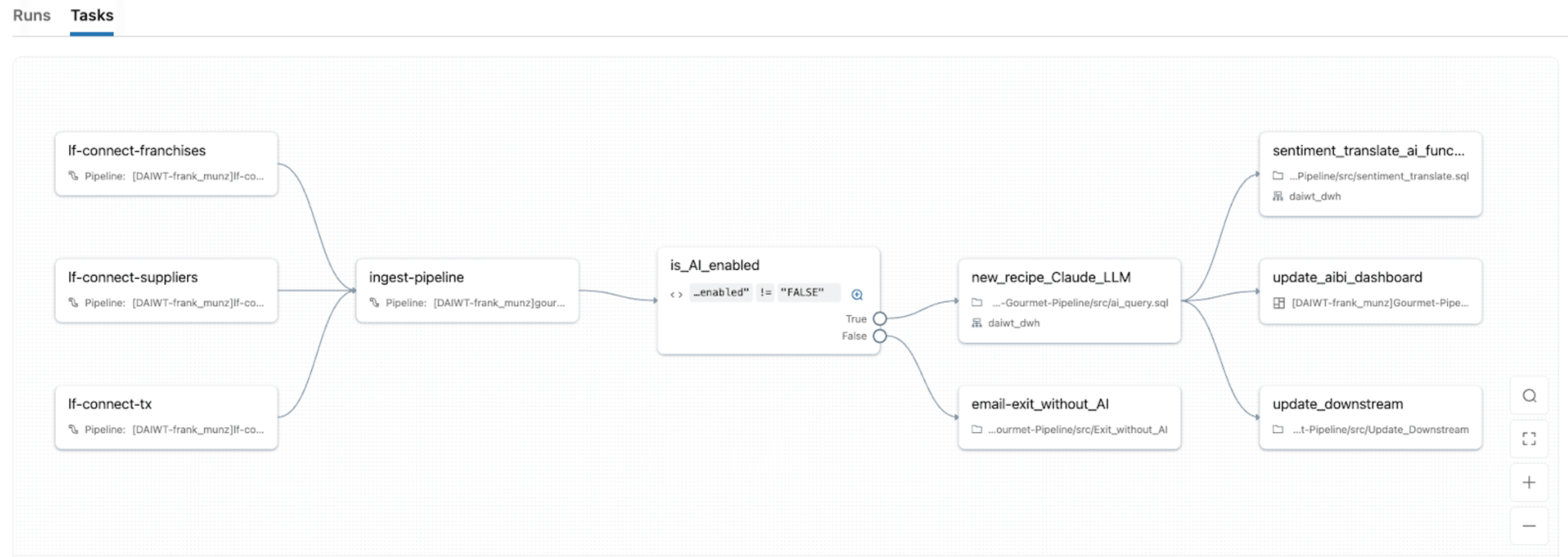
Passaggio 3: Produzione di carichi di lavoro IDP su larga scala
Una volta che l'ingestione e l'analisi funzionano nei notebook, devi produrre il tuo IDP: orchestrare l'ingestione, l'analisi, l'arricchimento e il serving. Ma vuoi anche monitorare SLA, fallimenti e tentativi in CI/CD per garantire che le pipeline rimangano integre.
Con Lakeflow Jobs, l'orchestratore nativo di Databricks, puoi trasformare i carichi di lavoro IDP in pipeline robuste e automatizzate con lo stesso sistema di orchestrazione che utilizzi per ETL, analisi e ML. Fornisce un'orchestrazione unificata per ogni attività nel DAG IDP, quindi puoi concatenare notebook, script Python, query SQL, pipeline, LLM o chiamate agent in un singolo job e modellare l'intero flusso dall'ingestione dei documenti.
Lakeflow Jobs viene fornito anche con flusso di controllo avanzato integrato (incluse condizioni if/else, for each, tentativi, ecc.) e trigger (aggiornamento tabella, arrivo file, continuo, ecc.). Ciò rende facile 1) rielaborare solo le partizioni fallite o i batch di documenti specifici e 2) gestire i job per adattarli a pianificazioni specifiche, trigger basati su eventi o modalità continua per flussi di documenti in tempo reale.
Con il calcolo serverless di Lakeflow Jobs con osservabilità nativa, ottieni anche scalabilità automatica con picchi nel volume dei documenti, mostrando al contempo monitoraggio in tempo reale, metriche e avvisi in modo da poter individuare i colli di bottiglia e riparare i fallimenti senza dover rieseguire i task riusciti.
Radicare l'IA nel Contesto Aziendale
L'IDP è più prezioso quando è supportato dal contesto aziendale: i tuoi schemi unici, le definizioni aziendali e la semantica personalizzata.
Unity Catalog
Unity Catalog fornisce governance e discovery unificate su dati strutturati, file non strutturati, modelli ML e metriche aziendali su qualsiasi cloud. Per l'IDP, ciò significa:
- Un unico posto per definire policy di accesso, lineage e audit sia per documenti grezzi che per tabelle strutturate derivate
- Supporto per formati aperti (Delta, Apache Iceberg, Hudi, Parquet) per evitare il blocco in una rappresentazione proprietaria del documento
- Semantica di business e metadati a livello di catalogo che gli agenti possono utilizzare per denominare e interpretare in modo coerente entità come "Fornitore", "Cliente" o "Valore del Contratto".
Intelligenza Documentale
Intelligenza Documentale utilizza questo contesto per creare agenti AI di produzione che sanno quali tabelle, strumenti e modelli utilizzare per un dato compito IDP, sono governati end-to-end in modo da non accedere mai più di quanto dovrebbero, e migliorano continuamente tramite punteggio di qualità basato su LLM, benchmark specifici per il compito e cicli di apprendimento. Per gli sviluppatori, Databricks fornisce API e SDK in modo da poter definire questi agenti come codice e integrarli nelle pipeline CI/CD esistenti, proprio come qualsiasi altro asset di dati o ML.
Best Practice per lo Stack Moderno di IDP
Per passare da pilota a piattaforma, tieni a mente queste best practice:
- Arricchimento Dati: Non limitarti a estrarre un "Nome Fornitore". Uniscilo con i tuoi Master Data interni o fonti di terze parti (come Dun & Bradstreet) per fornire un contesto di business completo.
- Eccellenza Operativa: Utilizza Service Principal per i Job Lakeflow per garantire la stabilità della pipeline.
- Monitoraggio: Utilizza Lakehouse Monitoring per tracciare il model drift e l'accuratezza dell'estrazione nel tempo.
Il Percorso verso l'Intelligenza Dati Moderna
Con Databricks, puoi gestire l'intero ciclo di vita dell'Intelligent Document Processing su una moderna piattaforma dati. La combinazione di Lakeflow e funzioni AI ti consente di trasformare dati non strutturati e nascosti in dataset affidabili e interrogabili ed eseguire senza problemi pipeline documentali osservabili accanto al tuo ETL e ML principale.
Ora che abbiamo trattato il valore strategico dell'intelligenza documentale autonoma, è il momento di costruirla. Dai un'occhiata al nostro post di accompagnamento, From PDF to Insights, per una guida tecnica passo-passo sull'implementazione di questa esatta architettura utilizzando Databricks.
Puoi anche esplorare la documentazione di Intelligenza Documentale e Lakeflow per iniziare a costruire la tua prima pipeline IDP oggi stesso!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.