Perché i tuoi agenti non possono leggere i documenti aziendali e come risolvere il problema
Introduzione di Document Intelligence su Databricks
- Gli agenti Frontier ottengono ancora meno del 50% nei compiti reali sui documenti aziendali. Il collo di bottiglia non è il ragionamento, ma la lettura.
- L'elaborazione dei documenti è il limite di accuratezza per ogni flusso di lavoro agentico.
- Stiamo annunciando Document Intelligence per colmare questo divario: offrendo accuratezza basata sulla ricerca, scalabilità aziendale e semplicità end-to-end.
Le più importanti informazioni di business non sono solo archiviate nei data warehouse, ma risiedono nei milioni di documenti che alimentano i flussi di lavoro aziendali principali ogni giorno: contratti, richieste, fatture e altro ancora. Per un decennio, l'Intelligent Document Processing (IDP) è stato considerato un problema di automazione ristretto e di back-office. Nell'era degli agenti, la posta in gioco è fondamentalmente diversa: l'IDP è la base fondamentale che determina se i tuoi agenti prenderanno decisioni di cui ti fiderai veramente.
Prendiamo l'elaborazione delle richieste assicurative. Sulla carta, è un flusso di lavoro ideale per agenti: ingestire una richiesta, estrarre i dettagli, segnalare anomalie e instradarla. Gli agenti all'avanguardia di oggi gestiscono facilmente il ragionamento. Dove falliscono è nella lettura dei documenti: PDF scansionati con layout incoerenti, tabelle nidificate, note scritte a mano e variazioni di formato tra ogni fornitore. Un "10.000 $" viene allucinato come "3.000 $", l'agente prende una decisione errata e l'importo sbagliato viene pagato silenziosamente.
Stiamo vedendo questo schema ovunque: gli agenti ragionano bene su testo pulito ma falliscono quando si trovano di fronte a documenti aziendali reali. Qualche mese fa, Databricks AI Research ha rilasciato OfficeQA, un benchmark basato su flussi di lavoro aziendali reali. Abbiamo scoperto che anche gli agenti all'avanguardia altamente capaci hanno ottenuto un'accuratezza inferiore al 50% nei compiti di ragionamento sui documenti. Il collo di bottiglia non era il ragionamento, ma la lettura.
Ecco perché siamo entusiasti di annunciare Document Intelligence, costruito su tre pilastri fondamentali: accuratezza basata sulla ricerca, scalabilità enterprise e semplicità end-to-end.
In Intercontinental Exchange, elaboriamo milioni di documenti finanziari complessi e altamente variabili ogni mese. Document Intelligence ci aiuta a trasformare quella complessità in informazioni di mercato strutturate, consentendoci di muoverci più velocemente, fornire maggior valore ai nostri clienti e sbloccare flussi di lavoro agenti che accelerano l'analisi e il processo decisionale su larga scala." —Anand Pradhan, CTO e Head of AI, Mortgage Data presso Intercontinental Exchange (NYSE)
Migliorare la qualità degli agenti su documenti aziendali reali
L'elaborazione dei documenti è il limite di accuratezza per ogni agente. Per fare questo correttamente, il team di Databricks AI Research si è prefissato di costruire sistemi specializzati progettati per la realtà disordinata di ciò che le aziende affrontano realmente: layout incoerenti, tabelle nidificate, immagini e scrittura a mano.
Questa ricerca alimenta una serie di Funzioni AI concatenabili che suddividono l'elaborazione dei documenti in passaggi componibili: ai_parse_document (ora Generalmente Disponibile) converte scansioni grezze in testo strutturato arricchito dal layout, mentre a valle, ai_classify instrada correttamente i documenti e ai_extract estrae le informazioni strutturate chiave che contano di più. Insieme, formano una pipeline di intelligenza documentale che puoi assemblare con facilità: analizza una volta, quindi classifica, estrai ed estrai di nuovo senza rielaborare il documento originale.
Quindi, una migliore elaborazione dei documenti rende effettivamente gli agenti più accurati? Quando abbiamo confrontato i documenti di obbligazioni del tesoro reali tramite OfficeQA, il pre-processing con ai_parse_document ha fornito un guadagno medio di performance del 16% in tutti i framework di agenti che abbiamo testato. L'imbracatura di ragionamento dell'agente non è cambiata affatto, ma lo strato di dati del documento sottostante sì.
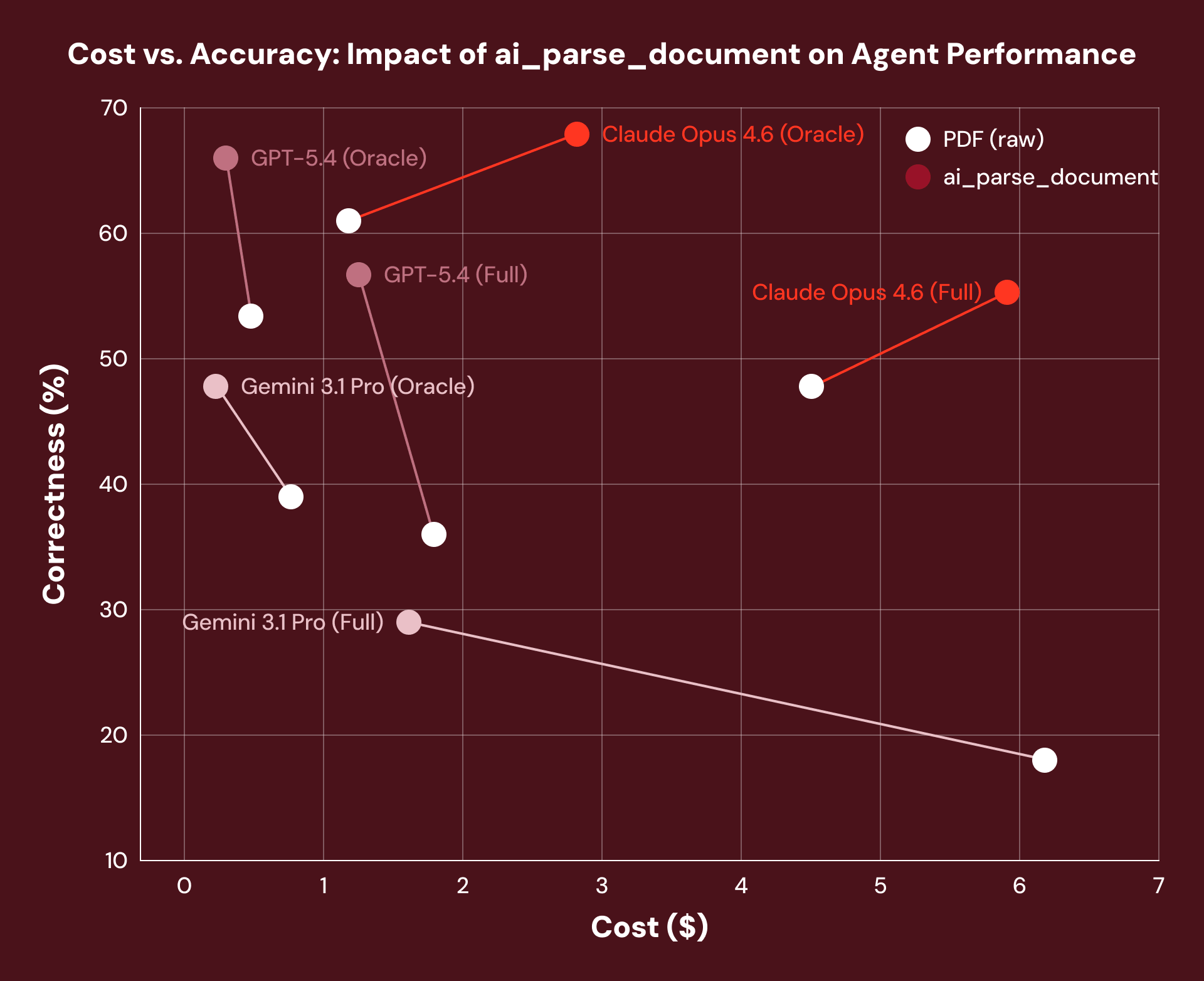
Nota: Abbiamo osservato un aumento dei costi di Claude Opus 4.6 a causa della tendenza del modello a recuperare più token quando gli viene fornito il testo strutturato del layout di un documento.
Questo è esattamente il motivo per cui costruiamo Document Intelligence come fondamento dei tuoi flussi di lavoro agenti: i guadagni di qualità e costo dell'elaborazione dei documenti si accumulano attraverso tutto ciò che vi si basa.
Con Document Intelligence, stiamo ponendo le basi per una pipeline di elaborazione intelligente dei documenti che sblocca informazioni strutturate chiave da milioni di PDF tecnici non strutturati ogni anno, provenienti da migliaia di organizzazioni e che coprono formati altamente incoerenti. —Graham Lammers, Executive Director of Data Intelligence, Accuris
Sbloccare l'intelligenza documentale su scala enterprise
Anche quando la qualità è risolta, il cimitero dell'IDP enterprise è pieno di progetti che hanno superato la fase pilota ma non sono riusciti a sopravvivere all'economia della produzione. Questo è dovuto a costi che salgono a sei cifre e a processi batch che richiedono giorni invece di ore.
Abbiamo progettato Document Intelligence per un'economia su scala di produzione fin dall'inizio, non come un ripensamento. Poiché le Funzioni AI come ai_parse_document sono specializzate dalla ricerca, raggiungono un'accuratezza all'avanguardia senza l'overhead computazionale dei modelli generici.
Attraverso varie soluzioni, abbiamo confrontato accuratezza e costi su attività di estrazione di documenti strutturati che identificano entità chiave da fatture aziendali, contratti, note mediche e documenti finanziari. Document Intelligence ha costantemente raggiunto la massima accuratezza a un costo 5-7 volte inferiore rispetto a pipeline comparabili.

Nota: Le offerte contrassegnate (parse + extract) utilizzano un'architettura di pipeline a due passaggi: analizza una volta in uno strato argento riutilizzabile, quindi estrai ed estrai di nuovo senza ri-analizzare. Le offerte basate su VLM rielaborano l'intero documento ad ogni chiamata di estrazione.
È importante notare che, per supportare questa scala, ogni Funzione AI viene eseguita su un'infrastruttura batch serverless costruita per carichi di lavoro ad alto volume: la stessa chiamata SQL di una riga che elabora 100 fatture elabora 100.000 senza riarchitettare la tua pipeline.
Con Document Intelligence, abbiamo ottenuto la stessa estrazione di entità di alta qualità a un costo quasi inferiore del 90% in poche settimane. Quel breakthrough di prezzo-prestazioni ora alimenta le nostre pipeline di produzione, consentendoci di espanderci più velocemente in nuove aree di malattia, elaborare in modo efficiente centinaia di milioni di note cliniche e fornire insight ai nostri clienti su larga scala. —Jerry Dennany, CTO Loopback Analytics
È importante notare che, per l'elaborazione su larga scala, ogni Funzione AI viene eseguita su un'infrastruttura batch serverless costruita per carichi di lavoro ad alto volume: la stessa chiamata SQL di una riga che elabora 100 fatture elabora 100.000 senza riarchitettare la tua pipeline.
Da pipeline frammentate a un flusso di lavoro unificato
Per la maggior parte delle aziende oggi, l'intelligenza documentale non è una capacità della piattaforma. È una raccolta di pipeline una tantum. Per un singolo caso d'uso, un team aggrega un servizio OCR, collega un'API di estrazione distinta e integra un modello di classificazione da un altro provider. In breve tempo, si ritrovano a gestire da tre a cinque API disconnesse tenute insieme da fragili codice personalizzato: una pipeline fragile, costosa da mantenere e quasi impossibile da debuggare quando si rompe alle 3 del mattino. E quando un altro team ha bisogno di elaborare un tipo di documento diverso, non c'è nulla di riutilizzabile su cui costruire. Iniziano da zero.
Questo è il ciclo che mantiene l'intelligenza documentale intrappolata come una serie di progetti una tantum invece che come una capacità aziendale. Document Intelligence rompe quel ciclo. Invece di aggregare servizi disconnessi, ogni passaggio viene eseguito nativamente all'interno del tuo livello di orchestrazione e governance Databricks esistente:
- Ingerisci documenti (ad es. da SharePoint) utilizzando Lakeflow Connect.
- Orchestra l'intera pipeline utilizzando Lakeflow Jobs o Spark Declarative Pipelines, con gestione degli errori integrata, osservabilità e gestione automatica di nuovi documenti.
- Governa la lineage end-to-end, la sicurezza e i controlli di accesso delle tue pipeline e dei tuoi dati, dal documento grezzo all'output della tabella strutturata, con Unity Catalog.
- Costruisci agenti sul nuovo livello di dati documentali arricchito utilizzando la piattaforma Agent Bricks.
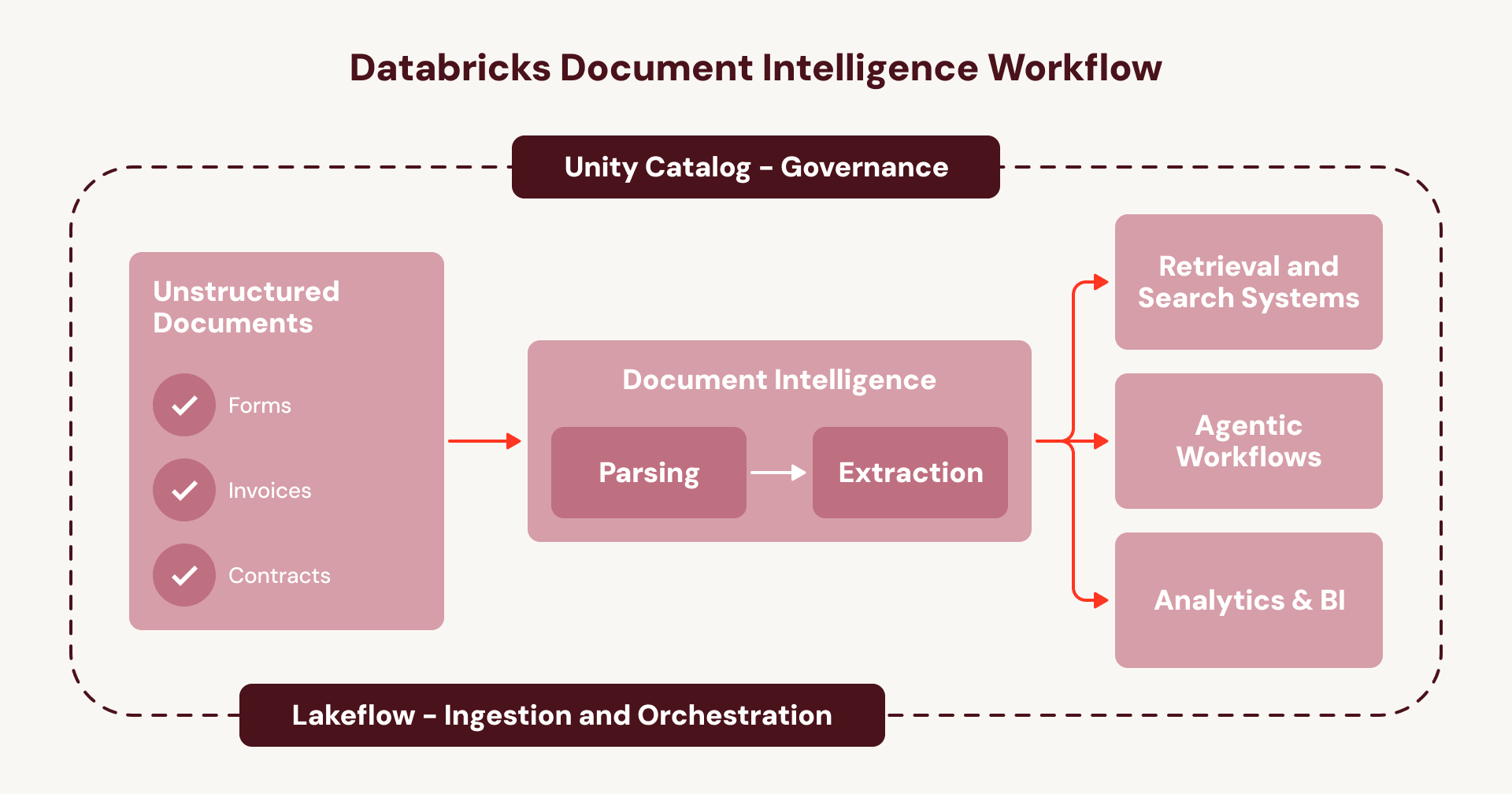
Per le aziende, ciò significa che l'intelligenza documentale viene eseguita su un flusso di lavoro unificato e governato invece che su una rete di servizi opachi e frammentati: un playbook ripetibile per scalare i casi d'uso agenti su tutti i tuoi documenti.
Con Databricks, siamo passati da processi manuali e frammentati a intelligenza automatizzata e scalabile. Quello che prima richiedeva settimane, ora lo facciamo in giorni, sbloccando insight che i nostri clienti non possono ottenere altrove. —Tony Qui, EY-Parthenon Global Innovation Leader, Strategy and Transactions
I tuoi agenti sono validi quanto il tuo livello di elaborazione dei documenti
La promessa degli agenti enterprise si basa su una domanda a cui la maggior parte delle organizzazioni non ha ancora risposto: i tuoi agenti sono in grado di comprendere i milioni di documenti della tua azienda?
Ecco perché siamo entusiasti di annunciare Document Intelligence per colmare questo divario: sufficientemente accurato per flussi di lavoro critici per il business, governato end-to-end in modo che il tuo team di conformità non debba inseguire dati tra i fornitori e costruito per scalare dal tuo primo pilota alla produzione senza modificare una riga di codice.
I tuoi documenti sono la fonte più ricca di intelligenza nella tua impresa. È ora che i tuoi agenti possano leggerli.
- Leggi il nostro blog how-to sulla creazione con Document Intelligence e Lakeflow.
- Iscriviti alla Prova Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.