Creazione di prodotti dati affidabili e di alta qualità con Databricks
di Amr Ali, Bernhard Walter, Fran Medina Castro, Glenn Wiebe, Karthik Subbarao, Lexy Kassan, Magnus Pierre e Pawarit Laosunthara
Introduzione
Le organizzazioni che mirano a diventare data-driven e basate sull'AI spesso devono fornire ai propri team interni prodotti di dati affidabili e di alta qualità. La creazione di tali prodotti di dati garantisce che le organizzazioni stabiliscano standard e una base affidabile di verità aziendale per i loro obiettivi di dati e AI. Un approccio per mettere la qualità e l'usabilità in primo piano è attraverso l'uso del paradigma data mesh per democratizzare la proprietà e la gestione degli asset di dati. I nostri post sul blog (Parte 1, Parte 2) offrono indicazioni su come i clienti possono sfruttare Databricks nella loro azienda per affrontare i pilastri fondamentali del data mesh, uno dei quali è "data as a product".
Sebbene l'idea di trattare i dati come prodotti possa aver guadagnato popolarità con l'emergere del data mesh, abbiamo osservato che l'applicazione del pensiero di prodotto risuona anche con i clienti che non hanno scelto di adottare il data mesh. Indipendentemente dalla struttura organizzativa o dall'architettura dei dati, il processo decisionale basato sui dati rimane un principio guida universale. La qualità e l'usabilità dei dati sono fondamentali per garantire che queste decisioni basate sui dati vengano prese su informazioni valide. Questo blog delineerà alcune delle nostre raccomandazioni per la creazione di prodotti di dati pronti per l'enterprise, sia in generale che specificamente con Databricks.
I prodotti di dati offrono valore in definitiva quando utenti e applicazioni hanno i dati giusti al momento giusto, con la qualità giusta, nel formato giusto. Mentre questo valore è stato tradizionalmente realizzato sotto forma di operazioni più efficienti attraverso costi inferiori, processi più veloci e rischi mitigati, i moderni prodotti di dati possono anche aprire la strada a nuove offerte a valore aggiunto e opportunità di condivisione dei dati all'interno del settore di un'organizzazione o dell'ecosistema dei partner.
Prodotti di dati
Sebbene i prodotti di dati possano essere definiti in vari modi, in genere si allineano alla definizione trovata in Data Jujitsu: The Art of Turning Data into Product di DJ Patil: "Per iniziare, ..., una buona definizione di prodotto di dati è un prodotto che facilita un obiettivo finale attraverso l'uso dei dati". Come tali, i prodotti di dati non sono limitati ai dati tabulari; possono anche essere modelli ML, dashboard, ecc. Per applicare tale pensiero di prodotto ai dati, è fortemente raccomandato che ogni prodotto di dati abbia un proprietario del prodotto di dati.
{kind=link}
I proprietari dei prodotti di dati gestiscono lo sviluppo e monitorano l'uso e le prestazioni dei loro prodotti di dati. Per fare ciò, devono comprendere il business sottostante ed essere in grado di tradurre i requisiti dei consumatori di dati in una progettazione per un prodotto di dati di alta qualità e facile da usare. Insieme ad altri nell'organizzazione, colmano il divario tra colleghi aziendali e tecnici come i data engineer. Il proprietario del prodotto di dati è responsabile di garantire che i prodotti nel loro portafoglio siano allineati agli standard organizzativi per quanto riguarda le caratteristiche di affidabilità.
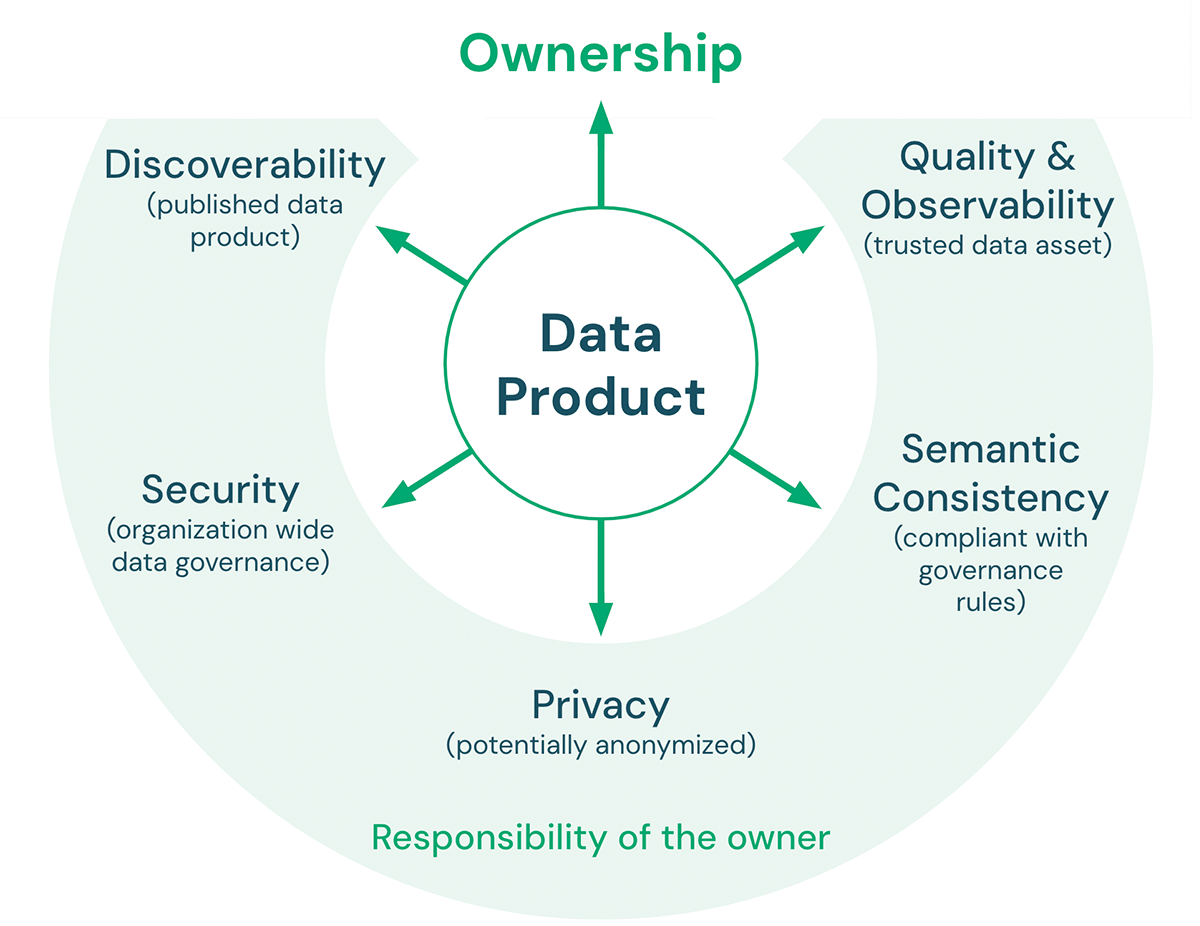
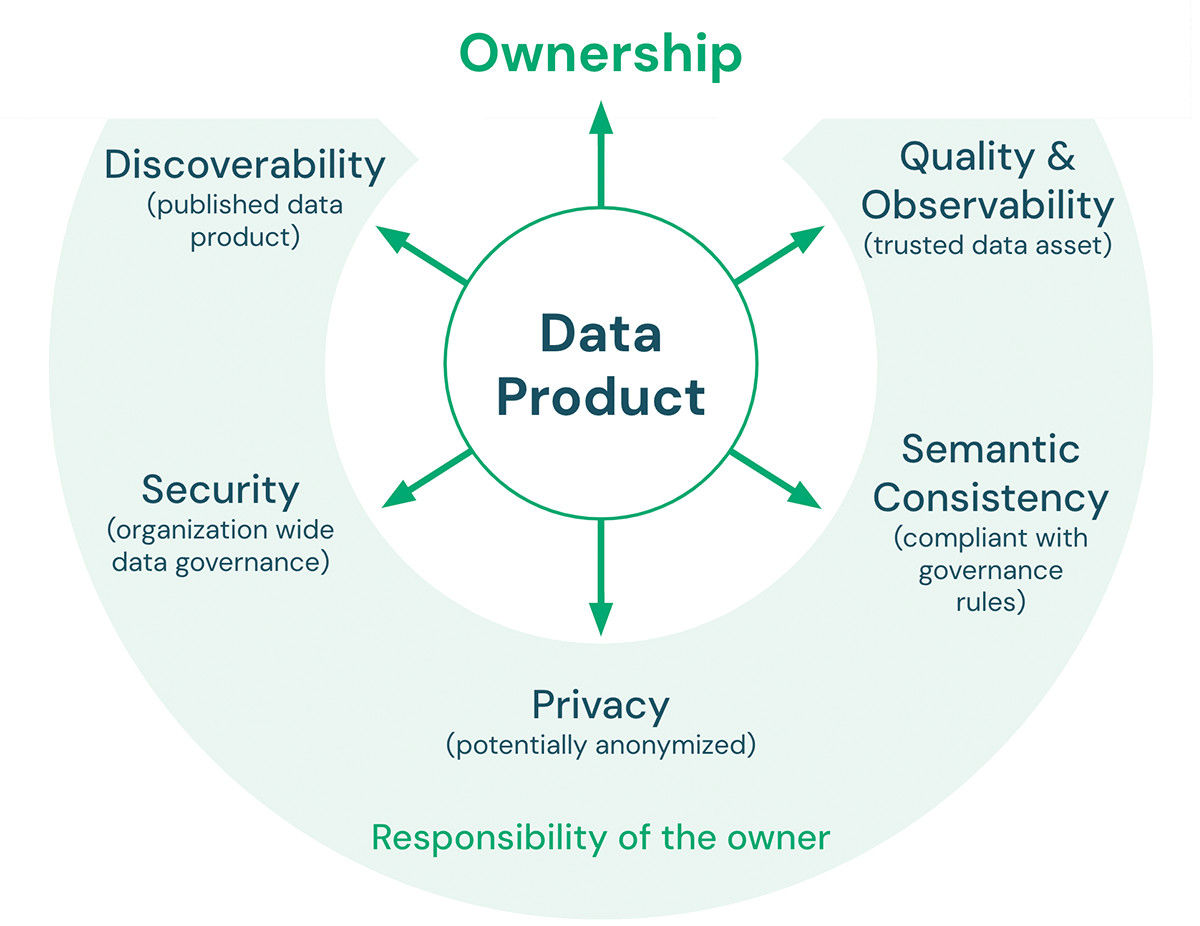
Ci sono cinque caratteristiche chiave che un prodotto di dati deve soddisfare:
- Qualità e Osservabilità: La qualità dei dati include accuratezza, coerenza, affidabilità, tempestività, nonché chiarezza della documentazione. Le metriche di qualità definite sul prodotto di dati possono essere monitorate ed esposte per garantire che la qualità dei dati prevista venga mantenuta nel tempo. L'obiettivo generale è rendere il prodotto di dati una fonte affidabile per i consumatori di dati.
- Coerenza semantica: L'obiettivo di un'architettura lakehouse è semplificare il lavoro con i dati. Pertanto, i prodotti di dati destinati all'uso congiunto dovrebbero essere semanticamente coerenti. In altre parole, dovrebbero seguire le regole di governance concordate e avere definizioni condivise di terminologia affinché i consumatori possano combinare questi prodotti di dati in modo significativo e corretto.
- Privacy: La privacy riguarda la riservatezza e la sicurezza delle informazioni, in merito a come i dati vengono raccolti, condivisi e utilizzati. La privacy dei dati è tipicamente regolata da normative e leggi (ad es. GDPR, CCPA). La conformità alle regole sulla privacy dei dati può includere argomenti come l'anonimizzazione, la crittografia, la residenza dei dati, il tagging dei dati (ad es. PII), la limitazione dell'archiviazione ad ambienti specifici e la limitazione dell'accesso a un piccolo numero di dipendenti.
- Sicurezza: Oltre ad avere una piattaforma dati approvata dall'infosec, i proprietari dei prodotti di dati devono comunque definire, ad esempio, le autorizzazioni di accesso (chi può accedere ai dati, con quali partner i dati possono essere condivisi, ecc.) e le policy di utilizzo accettabile per i loro prodotti di dati.
- Discoverability: I prodotti di dati devono essere pubblicati in modo tale che tutti nell'organizzazione possano trovarli. Ciò può includere luoghi come un catalogo dati centrale o un marketplace di dati interno. I proprietari dei prodotti di dati dovrebbero includere asset con il prodotto pubblicato che rendano facile comprendere i dati e come combinarli con altri prodotti di dati (ad es. notebook di esempio, dashboard, ecc.).
Ciclo di vita del prodotto di dati
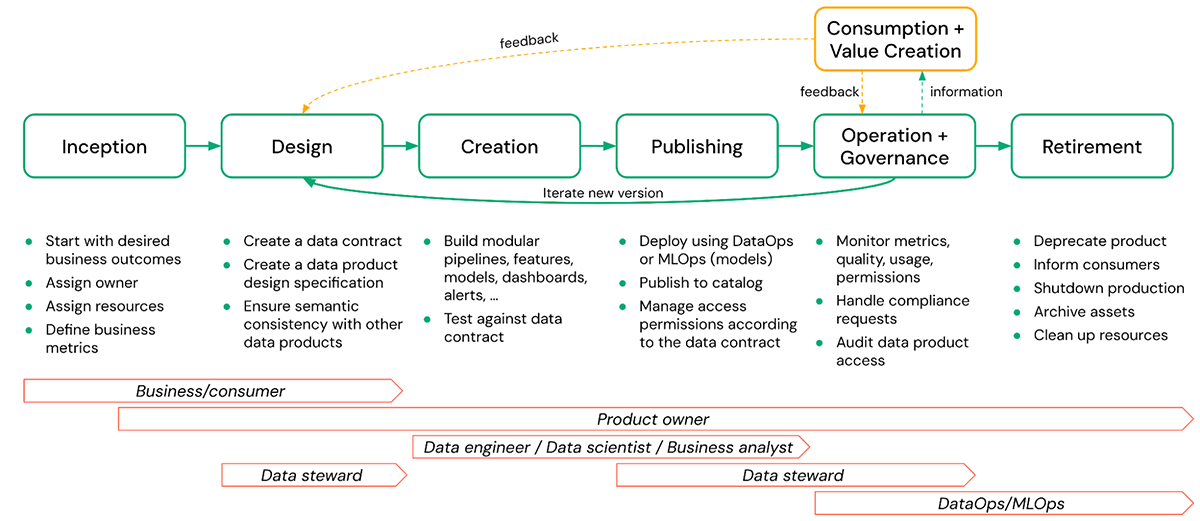
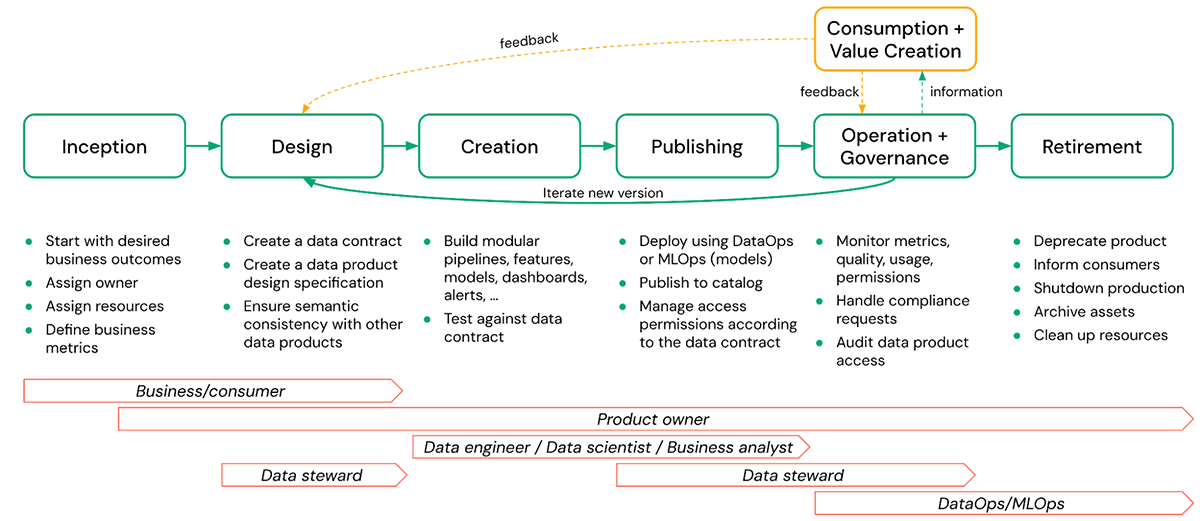
Un tipico ciclo di vita del prodotto di dati è composto dalle seguenti fasi:
- Inception - Qui viene definito il valore aziendale per un prodotto di dati desiderato e viene assegnato un proprietario. Devono essere definite anche metriche di performance e qualità per scopi di monitoraggio.
- Design - In questa fase vengono creati dettagli concreti come la specifica di progettazione e i contratti dati, garantendo la coerenza con altri prodotti di dati.
- Creazione - La creazione del prodotto di dati effettivo può includere schemi, tabelle, viste, modelli, file arbitrari (volumi), dashboard, ecc., insieme alle pipeline che li creano. Questa fase include anche il test del prodotto di dati risultante rispetto al contratto dati definito.
- Pubblicazione - La creazione e la pubblicazione di un prodotto di dati sono spesso trattate come la stessa cosa, ma sono piuttosto diverse. Questa fase include attività come il deployment dei modelli, la pubblicazione di uno schema in un catalogo condiviso, la gestione delle autorizzazioni di accesso secondo il contratto dati, ecc. La pubblicazione dovrebbe comportare la gestione delle release per versionare le modifiche ai prodotti di dati pubblicati.
- Operare e Governare - Le operazioni comportano attività persistenti come il monitoraggio della qualità, delle autorizzazioni e delle metriche di utilizzo. La parte di governance include la gestione delle richieste relative alla conformità e l'audit dell'accesso ai prodotti di dati, ecc.
- Consumare e Creare Valore - Il prodotto di dati viene utilizzato nel business per risolvere una varietà di problemi. I consumatori possono fornire feedback al proprietario del prodotto di dati in base alla loro esperienza nell'utilizzo del prodotto e raccomandare miglioramenti che potrebbero facilitare ulteriore creazione di valore in futuro.
- Ritiro - Ci possono essere diverse ragioni per ritirare un prodotto di dati, come la mancanza di utilizzo, il prodotto di dati non essere più conforme, ecc. In ogni caso, il prodotto di dati dovrebbe essere ritirato con grazia. Ciò significa deprecate il prodotto, informare i consumatori, archiviare gli asset e pulire le risorse. Qui, la visibilità sull'utilizzo downstream sarà spesso importante ed è notevolmente facilitata se la lineage viene acquisita automaticamente.
{kind=link}
Nella figura sopra, il proprietario del prodotto di dati è responsabile di tutte le fasi, dall'inception fino al ritiro di un prodotto di dati. Ciononostante, la responsabilità per i singoli compiti può essere condivisa con altri stakeholder come data steward, data engineer, ecc.
Best practice per l'implementazione di prodotti di dati
L'implementazione di prodotti di dati di alta qualità con Databricks richiede un approccio ponderato oltre la semplice esecuzione tecnica. Inizia stabilendo una chiara proprietà, con proprietari di prodotti di dati dedicati che comprendono sia le esigenze aziendali che i requisiti tecnici. Definisci contratti dati completi in anticipo che includano metriche di qualità, definizioni di schema, policy di utilizzo e parametri di sicurezza per garantire l'allineamento tra produttori e consumatori.
Quando costruisci pipeline, utilizza Delta Live Tables (DLT) con controlli di qualità implementati direttamente nel tuo codice, sfruttando le aspettative e i vincoli integrati per convalidare i dati in ogni fase. Implementa un approccio di sviluppo a fasi con ambienti di sviluppo, test e produzione separati per garantire la qualità prima della pubblicazione. Automatizza il monitoraggio utilizzando Lakehouse Monitoring, impostando avvisi per le soglie delle metriche di qualità per individuare i problemi precocemente.
Documenta ampiamente all'interno di Unity Catalog, utilizzando sia specifiche tecniche che contesto aziendale per aiutare gli utenti a comprendere e utilizzare correttamente i tuoi prodotti di dati. Per l'efficienza della governance, standardizza le convenzioni di denominazione e i metadati tra i prodotti di dati per migliorare la reperibilità e l'interoperabilità. Infine, implementa un ciclo di feedback formale con i consumatori per migliorare continuamente i tuoi prodotti di dati in base ai modelli di utilizzo effettivi e alle esigenze degli utenti.
La Databricks Data Intelligence Platform può essere sfruttata per diverse attività coinvolte nel ciclo di vita del prodotto di dati:
- Pipeline ETL - Delta Live Tables (DLT) può essere impiegato per costruire pipeline di dati robuste e controllate in termini di qualità. Auto Loader e tabelle di streaming possono essere utilizzate per caricare incrementalmente i dati nello strato Bronze per le pipeline DLT o le query Databricks SQL.
- Governance - Databricks Unity Catalog è ricco di funzionalità ed è stato creato per abilitare una governance semplice e unificata in tutta l'azienda. Catalog Explorer può essere utilizzato per la scoperta dei dati e i meccanismi di controllo degli accessi facilitano la pubblicazione dei prodotti di dati ai consumatori previsti. Lineage e System Tables vengono tracciati automaticamente e sono vitali per la governance operativa.
- Monitoraggio - Lakehouse Monitoring fornisce una soluzione singola e unificata per il monitoraggio della qualità degli asset di dati e AI. Un approccio proattivo di questo tipo è necessario per soddisfare i termini del contratto dati.
Per alcune delle attività del ciclo di vita del prodotto di dati, come la progettazione del prodotto di dati e del contratto dati, Databricks non dispone attualmente di funzionalità per supportarlo. Questi processi dovrebbero essere eseguiti al di fuori della Databricks Platform e i risultati quindi documentati in Unity Catalog una volta pubblicato il prodotto di dati.
Contratti Dati
Un contratto dati è un modo formale per allineare i domini e implementare la governance federata. Il produttore di dati dovrebbe fornirlo; tuttavia, dovrebbe essere progettato tenendo conto del consumatore. Il contratto dovrebbe essere formulato in modo da essere fruibile da tutti i tipi di utenti.
Un tipico contratto dati ha i seguenti attributi:
- Descrizione dei dati (nome, descrizione, sistemi sorgente, selezione degli attributi, ...)
- Schema dei dati (tabelle, colonne, informazioni di anonimizzazione e crittografia, filtri, maschere, ...) e formati dei dati (dati semi-strutturati e non strutturati)
- Policy di utilizzo (tag, PII, linee guida, residenza dei dati, ...)
- Qualità dei dati (controlli di qualità e vincoli applicati, metriche di qualità, ...)
- Sicurezza (chi è autorizzato a utilizzare il prodotto di dati)
- SLA Dati (ultimo aggiornamento, date di scadenza, tempo di conservazione, ...)
- Responsabilità (proprietario, manutentore, contatto per escalation, processo di modifica, ...)
Inoltre, possono essere forniti asset di supporto come notebook, dashboard, ecc. per aiutare il consumatore a comprendere e analizzare il prodotto di dati, facilitando così un'adozione più semplice.
Team di Governance Dati
Un team di governance dati in un'azienda è solitamente composto da rappresentanti di diversi gruppi come proprietari aziendali, esperti di conformità e sicurezza e professionisti dei dati. Questo team dovrebbe agire come Centro di Eccellenza (CoE) per argomenti di conformità e sicurezza dei dati e supportare il proprietario del prodotto di dati che è responsabile del prodotto di dati. Svolgono un ruolo cruciale nella definizione del contratto dati estendendo le policy di utilizzo e influenzando la decisione su chi è autorizzato a utilizzare il prodotto di dati. Per le grandi organizzazioni, un tale team può aiutare a guidare e standardizzare il processo di definizione del contratto dati in allineamento con funzioni globali come un ufficio di gestione dei dati.
Pubblicazione e Certificazione
Nonostante i contratti dati stabiliti, la governance dei prodotti di dati rimane un argomento ampio, che comprende aspetti come i controlli di accesso, la classificazione delle Informazioni di Identificazione Personale (PII) e varie policy di utilizzo, che possono differire tra le organizzazioni. Tuttavia, una tendenza costante che abbiamo osservato riguarda la pubblicazione dei prodotti di dati. Poiché i consumatori incontrano un numero crescente di set di dati, spesso richiedono la garanzia che i dati siano curati, standardizzati e ufficialmente approvati per l'uso. Ad esempio, un caso d'uso di reporting o di gestione dei dati anagrafici all'interno di una grande organizzazione potrebbe richiedere un elevato grado di coerenza semantica e interoperabilità tra diversi asset di dati nell'azienda.
È qui che il concetto di 'certificazione' del prodotto di dati può diventare prezioso per determinati prodotti di dati. In questo processo, i produttori di dati possono prima proporre una specifica del contratto dati, solitamente soggetta alla revisione da parte di uno steward o team di governance dati. Dopo l'approvazione, i processi di Integrazione Continua/Distribuzione Continua (CI/CD) possono essere eseguiti per distribuire pipeline di produzione che scrivono fisicamente i dati negli account di archiviazione cloud del cliente. Questi dati possono quindi essere pubblicati e facilmente scoperti tramite tabelle, viste o anche volumi per dati non tabulari di Unity Catalog. In questo contesto, Unity Catalog supporta l'uso di tag e markdown per indicare lo stato di certificazione e i dettagli di un prodotto di dati.
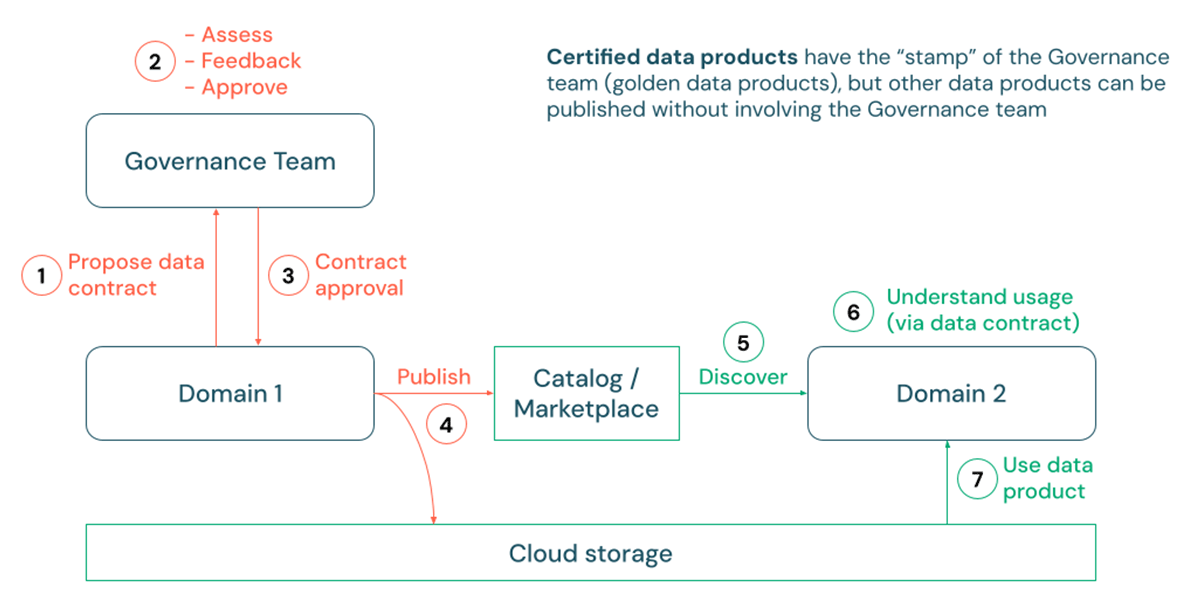
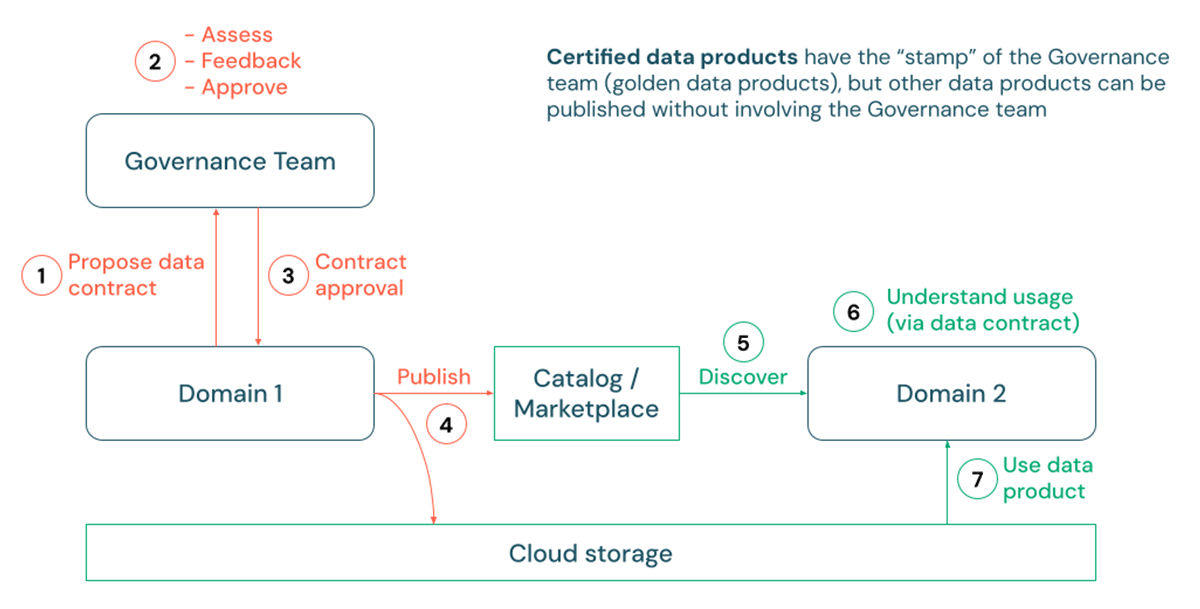{kind=link}
Alcuni clienti potrebbero persino scegliere di promuovere i propri prodotti di dati certificati pubblicando un elenco privato corrispondente nel Databricks Marketplace con guide complete ed esempi di utilizzo. Inoltre, le API REST di Databricks e le integrazioni con soluzioni di catalogo aziendali come Alation, Atlan e Collibra facilitano anche la facile scoperta dei prodotti di dati certificati attraverso più canali, anche quelli esterni a Databricks.
Casi d'Uso e Storie di Successo
Automotive: Rivian's Vehicle Intelligence Platform
Rivian, il produttore di veicoli elettrici, utilizza Databricks per elaborare dati di sensori IoT da oltre 25.000 veicoli in circolazione, ognuno dei quali genera terabyte di dati al giorno. Il loro team ADAS (Advanced Driver-Assistance Systems) utilizza questa piattaforma per analizzare dati telemetrici, comprese informazioni su beccheggio, rollio, velocità, sospensioni e attività degli airbag, il che aiuta Rivian a comprendere le prestazioni del veicolo e i modelli di guida. Sfruttando la Databricks Lakehouse Platform, hanno ottenuto un aumento del 30%-50% delle prestazioni di runtime, portando a insight più rapidi e a una maggiore accuratezza dei modelli. Questo approccio basato sui dati consente a Rivian di implementare la manutenzione predittiva, ottimizzare l'affidabilità dei componenti e migliorare continuamente l'esperienza di guida del cliente.
Sanità: Personalizzazione delle Prescrizioni di Walgreens
Walgreens, una delle più grandi catene di farmacie americane, ha trasformato la sua esperienza del paziente utilizzando Databricks per elaborare dati di prescrizione su larga scala. Con oltre 825 milioni di prescrizioni annuali in quasi 9.000 sedi, Walgreens ha costruito la sua piattaforma Information, Data and Insights (IDI) su Databricks per elaborare 40.000 eventi di dati al secondo. Ciò ha ottimizzato la loro catena di approvvigionamento dimensionando correttamente i livelli di inventario per risparmiare milioni di dollari e aumentando la produttività dei farmacisti del 20%. La piattaforma consente ai farmacisti di fornire cure migliori con profili paziente robusti che includono avvisi di interazione farmacologica, modifiche ai profili farmacologici e altre informazioni critiche per una gestione più sicura delle prescrizioni.
Produzione: Analisi basate sull'AI di Mahindra
Mahindra & Mahindra Limited, un conglomerato manifatturiero globale, ha implementato soluzioni AI a livello aziendale utilizzando Databricks per migliorare le operazioni in tutta la loro attività. Il loro bot GenAI per analisti finanziari ha portato a una riduzione del 70% del tempo dedicato alle attività di routine, consentendo ai team di concentrarsi su iniziative strategiche di maggior valore. L'azienda sta sfruttando la Databricks Data Intelligence Platform per molteplici casi d'uso, tra cui un chatbot Voice of the Customer costruito con il LLM open source DBRX di Databricks che integra dati interni tramite Delta Lake e dati esterni da siti web e social media. Questo approccio completo sta aiutando Mahindra a guidare la crescita, migliorare le esperienze dei clienti e ottimizzare l'efficienza operativa.
Telecomunicazioni: Architettura Data Mesh di T-Mobile
T-Mobile ha implementato con successo un'architettura data mesh utilizzando Databricks per democratizzare l'accesso ai dati mantenendo sicurezza e governance. Il gigante delle telecomunicazioni ha integrato il proprio lakehouse in un Data Mesh utilizzando Unity Catalog e Delta Sharing, consentendo ai team di tutta l'azienda di accedere e utilizzare i dati mantenendo un modello di sicurezza razionale e facilmente comprensibile. Questo approccio ha permesso ai team di dominio di creare e gestire i propri data product, garantendo al contempo una governance coerente, accelerando le iniziative di analisi in tutta l'organizzazione e migliorando il processo decisionale basato sui dati.
Tendenze Future nei Data Product
Il futuro dei data product è plasmato da diverse tendenze emergenti che influenzeranno il modo in cui le organizzazioni sfruttano piattaforme come Databricks. I data product in tempo reale stanno guadagnando importanza poiché le aziende richiedono insight sempre più aggiornati, con architetture di streaming che diventano standard per i data product operativi critici. Stiamo anche assistendo all'ascesa della creazione di data product self-service, con esperti di dominio aziendale che utilizzano interfacce low-code/no-code per definire e costruire data product mantenendo i guardrail di governance.
I data product arricchiti dall'IA, che incorporano automaticamente funzionalità e insight di machine learning, stanno diventando più comuni, sfumando il confine tra dati tradizionali e asset di IA. Le architetture data mesh stanno maturando, con organizzazioni che implementano una governance computazionale federata che bilancia standard centrali con autonomia di dominio. Stanno emergendo data product cross-organizzativi che attraversano in sicurezza i confini aziendali, con data clean room e computazione che preserva la privacy che abilitano nuovi insight collaborativi.
I data contract si stanno evolvendo per includere garanzie di qualità più sofisticate, controlli sulla privacy e diritti di utilizzo, diventando specifiche eseguibili anziché documentazione statica. L'analisi integrata nelle applicazioni operative è in crescita, con data product progettati specificamente per alimentare insight in-app anziché ambienti analitici separati. Infine, le metriche di sostenibilità vengono incorporate nei data product, tracciando l'impatto ambientale insieme ai KPI aziendali tradizionali per supportare la reportistica ESG e le iniziative green.
Conclusione
La formulazione di data product e data contract può diventare un esercizio complesso all'interno di un'azienda di grandi dimensioni. Data l'emergere di nuove tecnologie per l'interfacciamento con i dati, unite ai moderni requisiti aziendali e normativi, le specifiche per data product e contratti sono in continua evoluzione. Oggi, Databricks Marketplace e Unity Catalog fungono da componenti fondamentali per l'esperienza di scoperta e onboarding dei dati per i data consumer. Per i data producer, Unity Catalog offre funzionalità essenziali di governance aziendale, tra cui lineage, audit e controlli di accesso.
Poiché i data product si estendono oltre semplici tabelle o dashboard per includere modelli di IA, stream e altro ancora, i clienti possono beneficiare di un'esperienza di governance unificata e coerente su Databricks per tutti i principali persona utente.
Gli aspetti chiave dei data product aziendali evidenziati in questo blog possono servire come principi guida nell'approccio all'argomento. Per saperne di più sulla costruzione di data product di alta qualità utilizzando la Databricks Data Intelligence Platform, contatta il tuo rappresentante Databricks.
FAQ
Qual è la differenza tra un data product e un dataset normale?
Un data product va oltre la semplice fornitura di dati; è progettato tenendo conto delle esigenze specifiche dell'utente, include garanzie di qualità, documentazione ed elementi di supporto. A differenza di un dataset normale, un data product ha una proprietà chiara, SLA definiti ed è gestito attivamente durante il suo ciclo di vita per garantire che continui a soddisfare le esigenze dei consumatori.
Chi dovrebbe possedere i data product nella nostra organizzazione?
I data product dovrebbero essere posseduti da individui che comprendono sia il dominio aziendale che gli aspetti tecnici dei dati. Questi proprietari di data product sono responsabili della qualità, dell'usabilità e dell'allineamento con gli obiettivi aziendali. A seconda della struttura organizzativa, potrebbero risiedere all'interno dei domini aziendali (in un approccio data mesh) o all'interno di un team dati centrale.
Come misuriamo il successo dei nostri data product?
Le metriche di successo dovrebbero includere sia aspetti tecnici (qualità, disponibilità, prestazioni) sia misure di impatto aziendale. Traccia i modelli di utilizzo, la soddisfazione dell'utente, il tempo necessario per ottenere insight per i consumatori e i risultati aziendali diretti abilitati dal data product. Stabilisci metriche di base prima dell'implementazione e misura i miglioramenti nel tempo.
Quale ruolo gioca Unity Catalog nella gestione dei data product?
Unity Catalog funge da base per la governance dei data product fornendo gestione centralizzata dei metadati, controlli di accesso, tracciamento della lineage e funzionalità di scoperta. Ti consente di implementare data contract tramite funzionalità come tagging, commenti e definizioni di schema, fornendo al contempo controlli di auditabilità e conformità necessari per i data product aziendali.
Come gestiamo le modifiche ai data product pubblicati?
Implementa processi formali di versioning e gestione delle modifiche per i data product. Comunica in anticipo le modifiche ai consumatori, mantieni la retrocompatibilità ove possibile e fornisci percorsi di migrazione per le modifiche che introducono incompatibilità. Utilizza le funzionalità di Unity Catalog per tracciare le versioni e gestire la transizione tra di esse.
Possiamo creare data product senza adottare un'architettura data mesh completa?
Assolutamente. Mentre il data mesh enfatizza la proprietà di dominio dei data product, puoi applicare il pensiero di prodotto ai tuoi asset di dati indipendentemente dalla tua struttura organizzativa. Concentrati sulle esigenze dell'utente, sulla qualità e sull'usabilità dei tuoi dati e implementa una chiara proprietà e governance: questi principi creano valore anche senza un'implementazione completa del data mesh.
Come garantiamo che i nostri data product rimangano conformi alle normative in evoluzione?
Integra la conformità nel ciclo di vita dei tuoi data product, con revisioni regolari da parte del tuo team di governance. Implementa controlli basati sui metadati in Unity Catalog per applicare le policy automaticamente e utilizza le funzionalità di lineage per comprendere l'impatto delle modifiche normative sui tuoi data product. Documenta i requisiti di conformità nei tuoi data contract e monitora l'adesione tramite i log di audit.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.