Creazione di un Copilot per il rischio normativo con Databricks Agent Bricks (Parte 1: Estrazione di informazioni)
Scopri come trasformare le lettere di rifiuto non strutturate della FDA in informazioni dettagliate utilizzando le funzioni di Databricks AI e Agent Bricks.
di Guanyu Chen e Diego Malaver
- Analizza PDF complessi: a differenza degli approcci tradizionali che richiedono team e migliaia di righe di codice, è sufficiente utilizzare la funzione ai_parse_document() per analizzare in modo affidabile testo e immagini da documenti PDF complessi come le Complete Response Letter (CRL) della FDA.
- Estrai informazioni dettagliate in modo collaborativo: scopri come utilizzare gli Information Extraction Agent Brick per consentire a esperti di business e ingegneri IA di definire, testare e perfezionare in modo collaborativo l'estrazione di dati strutturati in tempo reale.
- Metti in produzione con SQL: effettua il deployment con un solo clic del tuo agent perfezionato come endpoint serverless e utilizza la funzione ai_query() per creare una pipeline scalabile e pronta per la produzione per l'elaborazione di nuovi documenti direttamente all'interno del tuo Lakehouse.
Nel luglio 2025, la FDA statunitense ha reso pubblico un primo batch di oltre 200 lettere di risposta completa (CRL), ovvero lettere di decisione che spiegano perché le richieste di approvazione di farmaci e prodotti biologici non sono state approvate alla prima valutazione, segnando una svolta importante in termini di trasparenza. Per la prima volta, sponsor, clinici e team di dati possono analizzare il settore industriale attraverso il linguaggio stesso dell'agenzia in merito a carenze in ambito clinico, CMC, di sicurezza, di etichettatura e di bioequivalenza, tramite PDF FDA aperti, centralizzati e scaricabili.
Man mano che la FDA continua a rilasciare nuovi CRL, la capacità di generare rapidamente conoscenza da questi e altri dati non strutturati e di aggiungerli alla propria intelligence/dati interni diventa un importante vantaggio competitivo. Le organizzazioni che riescono a sfruttare efficacemente queste informazioni dettagliate provenienti da dati non strutturati, sotto forma di PDF, documenti, immagini e altro, possono ridurre il rischio delle proprie sottomissioni, identificare le insidie più comuni e, in definitiva, accelerare il loro percorso verso il mercato. La sfida è che questi dati, come molti altri dati normativi, sono bloccati in PDF, notoriamente difficili da elaborare su larga scala.
Questa è esattamente la tipologia di sfida che Databricks è stato creato per risolvere. Questo blog dimostra come utilizzare gli ultimi strumenti di AI di Databricks per accelerare l'estrazione di informazioni chiave intrappolate nei PDF, trasformando queste lettere critiche in una fonte di informazioni strategiche.
Cosa serve per avere successo con l'AI
Data la profondità tecnica richiesta, gli ingegneri spesso guidano lo sviluppo in un silo, creando un ampio divario tra la build dell'AI e i requisiti aziendali. Quando un esperto in materia (SME) vede il risultato, spesso non è quello di cui aveva bisogno. Il ciclo di feedback è troppo lento e il progetto perde slancio.
Nelle prime fasi di test, è fondamentale stabilire una baseline. In molti casi, gli approcci alternativi comportano mesi di lavoro sprecato in assenza di ground truth, basandosi invece su osservazioni soggettive e "sensazioni". Questa mancanza di prove empiriche rallenta i progressi. Al contrario, gli strumenti di Databricks forniscono funzionalità di valutazione pronte all'uso e consentono ai clienti di porre immediatamente l'accento sulla qualità, utilizzando un framework iterativo per ottenere una fiducia matematica nell'estrazione. Il successo dell'IA richiede un nuovo approccio basato su un'iterazione rapida e collaborativa.
Databricks offre una piattaforma unificata in cui gli esperti di settore (SME) e gli ingegneri AI possono collaborare in tempo reale per creare, testare e implementare agenti di qualità professionale. Questo framework si basa su tre principi chiave:
- Perfetto allineamento tra business e tecnologia: gli esperti di settore e i responsabili tecnici collaborano sulla stessa UI per ottenere un feedback istantaneo, sostituendo i lenti scambi di email.
- Valutazione ground truth: le etichette "ground truth" definite dal business sono integrate direttamente nel flusso di lavoro per un punteggio formale.
- Approccio a piattaforma completa: non si tratta di un ambiente di prova o di una soluzione specifica, ma di un sistema completamente integrato con pipeline automatizzate, valutazione LLM-as-a-Judge, throughput GPU affidabile per la produzione e governance end-to-end di Unity Catalog.
Questo approccio a piattaforma unificata è ciò che trasforma un prototipo in un sistema di AI affidabile e pronto per la produzione. Analizziamo i quattro passaggi necessari per crearlo.
Da PDF alla produzione: una guida in quattro passaggi
La creazione di un sistema di AI di qualità production basato su dati non strutturati richiede più di un semplice buon modello; richiede un flusso di lavoro fluido, iterativo e collaborativo. L'informazioni Extraction Agent Brick, in combinazione con le funzioni di AI integrate di Databricks, semplifica l'analisi dei documenti, l'estrazione delle informazioni chiave e l'operativizzazione dell'intero processo. Questo approccio consente ai team di muoversi più velocemente e di fornire risultati di qualità superiore. Di seguito sono illustrati i quattro passaggi chiave della creazione.
Passaggio 1: Parsing di PDF non strutturati in testo con ai_parse_document()
Il primo ostacolo è estrarre testo pulito dai PDF. I CRL possono avere layout complessi con intestazioni, piè di pagina, tabelle e grafici, distribuiti su più pagine e colonne. Una semplice estrazione del testo spesso fallisce, producendo un output impreciso e inutilizzabile.
A differenza delle fragili soluzioni puntuali che hanno difficoltà con il layout, ai_parse_document() sfrutta un'AI multimodale all'avanguardia per comprendere la struttura del documento, estraendo accuratamente il testo in ordine di lettura, preservando le gerarchie irregolari delle tabelle e generando didascalie per le figure.
Inoltre, Databricks offre un vantaggio nell'intelligenza dei documenti, scalando in modo affidabile per gestire volumi di PDF complessi a livello aziendale a un costo da 3 a 5 volte inferiore rispetto ai principali concorrenti. I team non devono preoccuparsi dei limiti di dimensione dei file e l'OCR e il VLM integrati garantiscono un parsing accurato dei PDF storicamente "problematici", contenenti figure dense e irregolari e altre strutture complesse.
Ciò che un tempo richiedeva a numerosi data scientist di configurare e mantenere stack di parsing personalizzati tra più fornitori, ora può essere realizzato con un'unica funzione nativa SQL, consentendo ai team di elaborare milioni di documenti in parallelo senza le modalità di errore che affliggono i parser meno scalabili.
Per iniziare, punta un volume UC sul tuo storage cloud contenente i PDF. Nel nostro esempio, punteremo la funzione SQL ai PDF CRL gestiti da un volume:
Questo singolo comando elabora tutti i PDF e crea una tabella strutturata con il contenuto analizzato e il testo combinato, rendendolo pronto per il passaggio successivo.
Nota: non è stato necessario configurare alcuna infrastruttura, rete o chiamata esterna a LLM o GPU. Databricks ospita le GPU e il back-end del modello, consentendo un throughput affidabile e scalabile senza configurazioni aggiuntive. A differenza delle piattaforme che addebitano costi di licenza, Databricks utilizza un modello di determinazione dei prezzi basato su compute, il che significa che paghi solo per le risorse che utilizzi. Ciò consente potenti ottimizzazioni dei costi tramite la parallelizzazione e la personalizzazione a livello di funzione nelle pipeline di produzione.
Passaggio 2: estrazione iterativa di informazioni con Agent Bricks
Una volta ottenuto il testo, l'obiettivo successivo è estrarre campi specifici e strutturati. Ad esempio: qual era la carenza? Qual era l'ID NDA? Qual era la citazione di rifiuto? È qui che gli ingegneri di IA e gli SME aziendali devono collaborare a stretto contatto. L'SME sa cosa cercare e può collaborare con l'ingegnere per dare rapidamente un prompt al modello su come trovarlo.
Agent Bricks: Information Extraction fornisce un'interfaccia utente collaborativa e in tempo reale per questo esatto flusso di lavoro.
Come mostrato di seguito, l'interfaccia consente a un responsabile tecnico e a un esperto di business di lavorare insieme:
- Lo SME aziendale fornisce i campi specifici da estrarre (ad es.
deficiency_summary_paragraphs, NDA_ID, FDA_Rejection_Citing). - L'agente di estrazione delle informazioni tradurrà questi requisiti in prompt efficaci: queste linee guida modificabili si trovano nel pannello a destra.
- Sia il Tech Lead che il Business SME possono vedere immediatamente l'output JSON nel pannello centrale e verificare se il modello sta estraendo correttamente le informazioni dal documento a sinistra. A questo punto, uno dei due può riformulare un prompt per garantire estrazioni accurate.
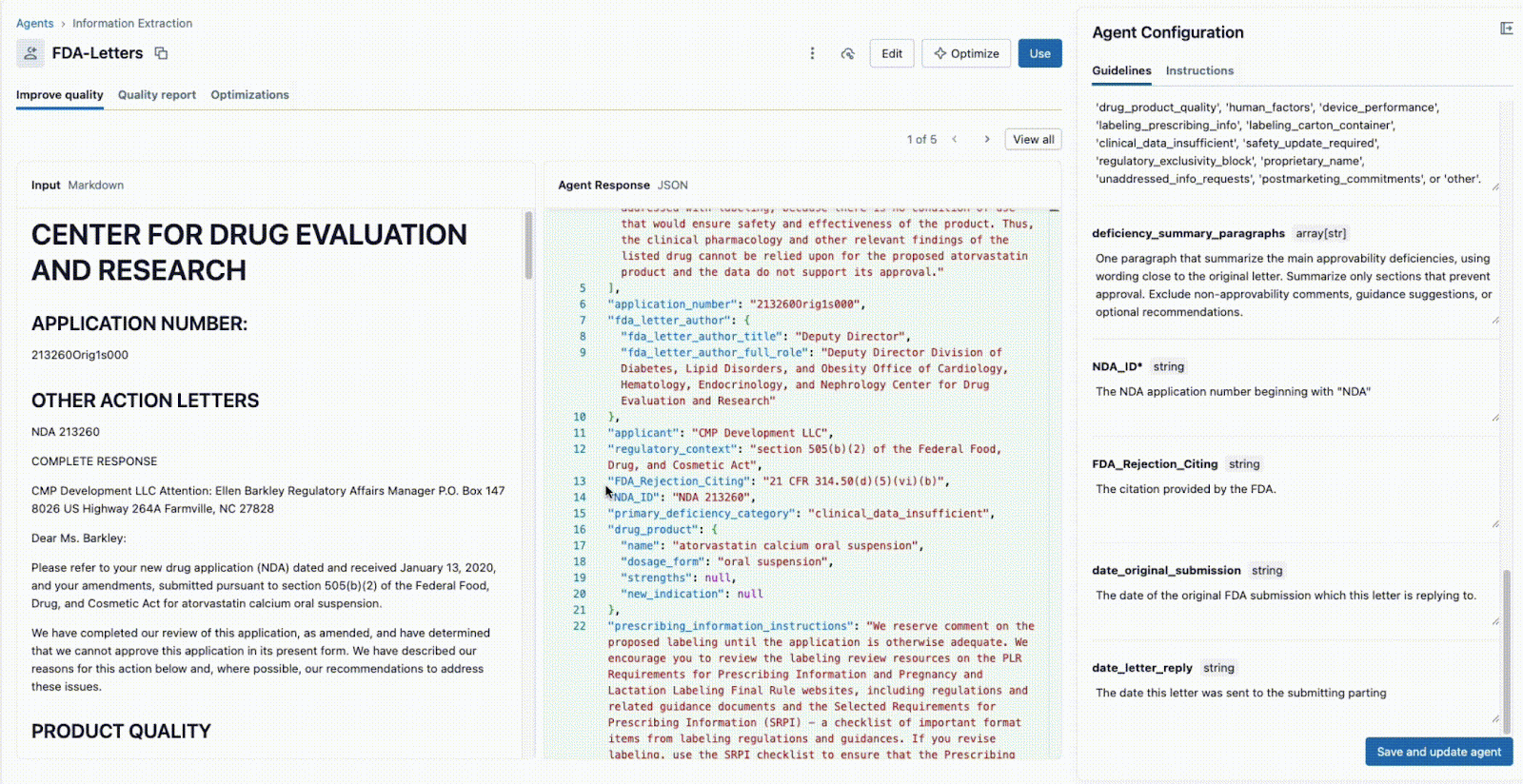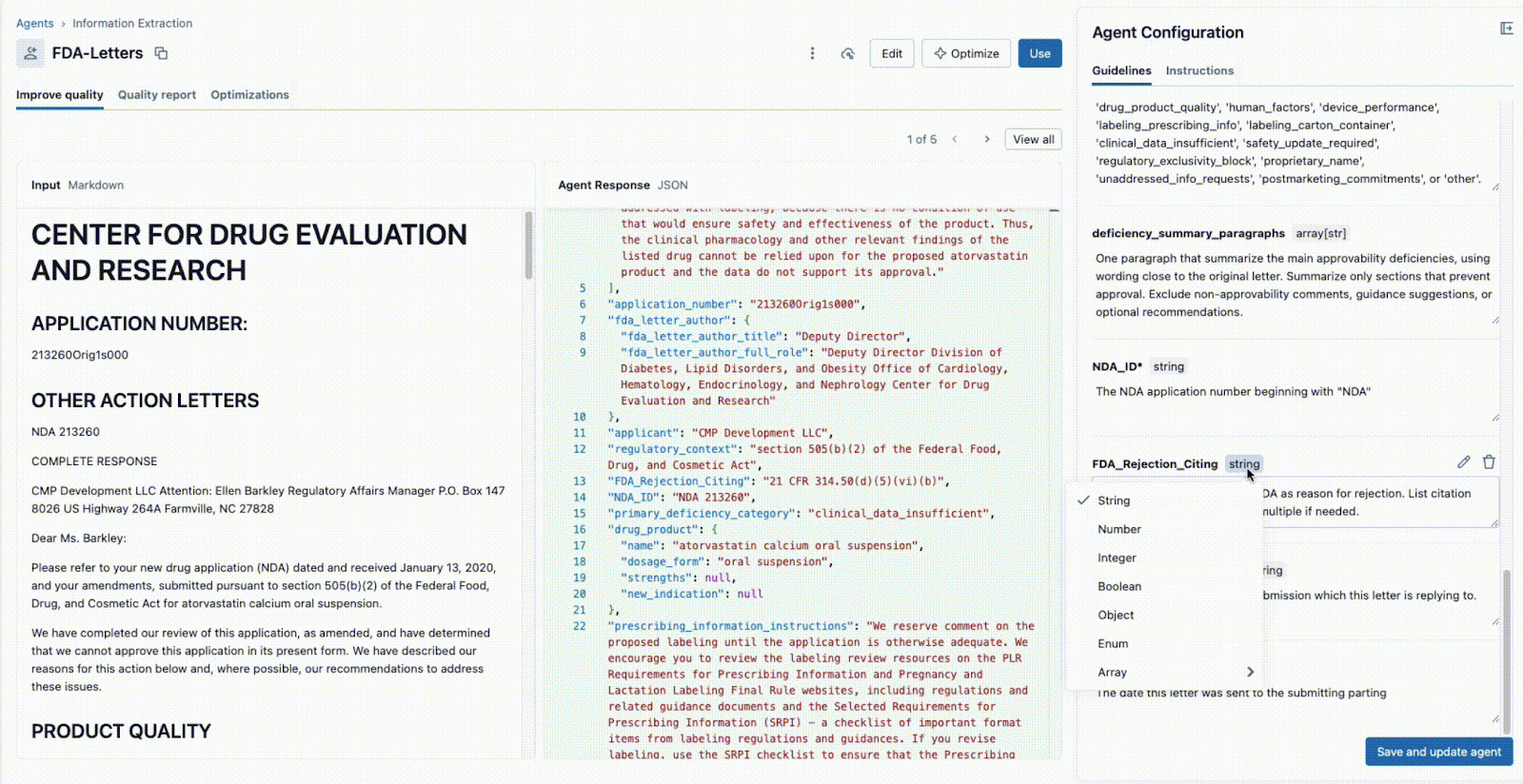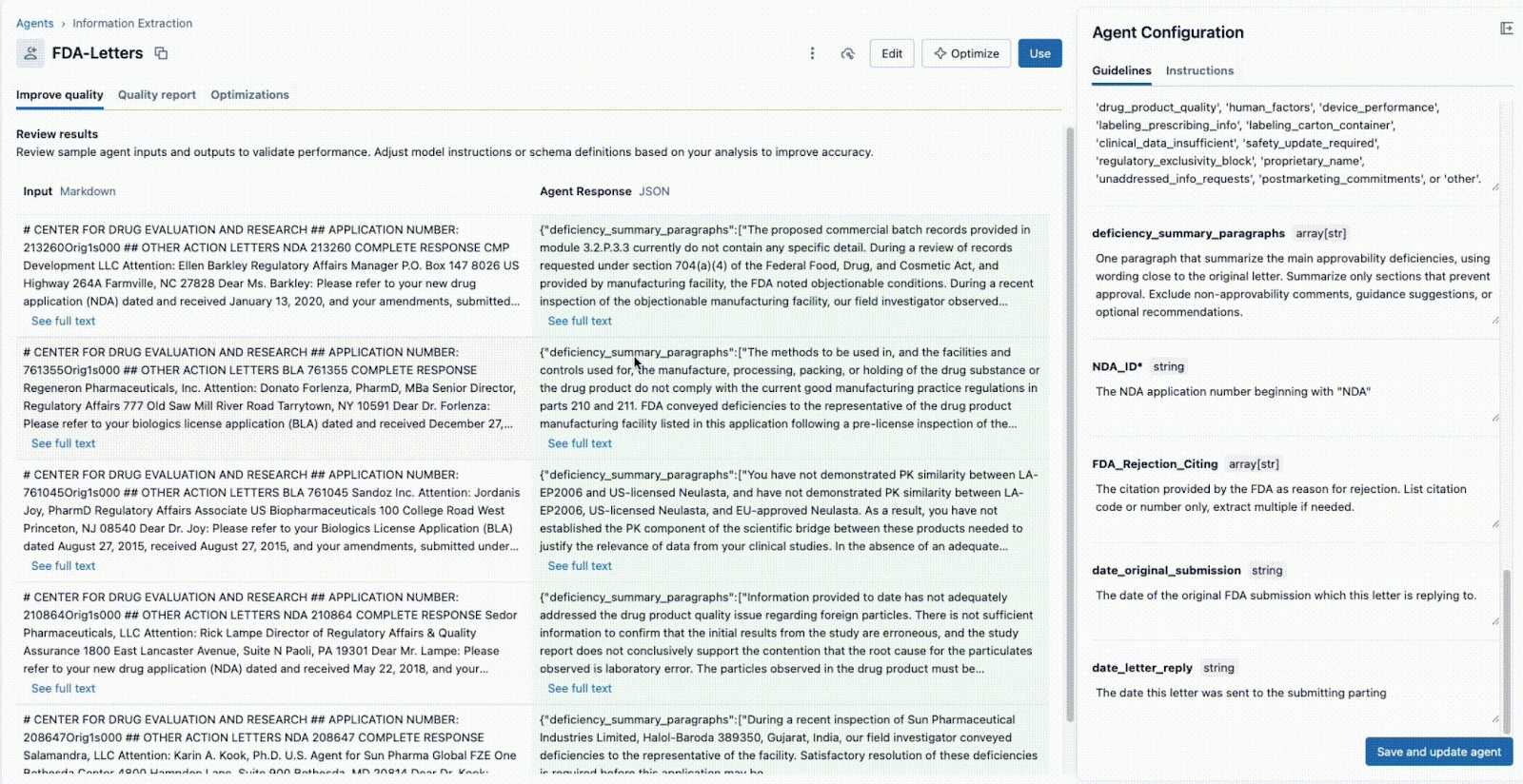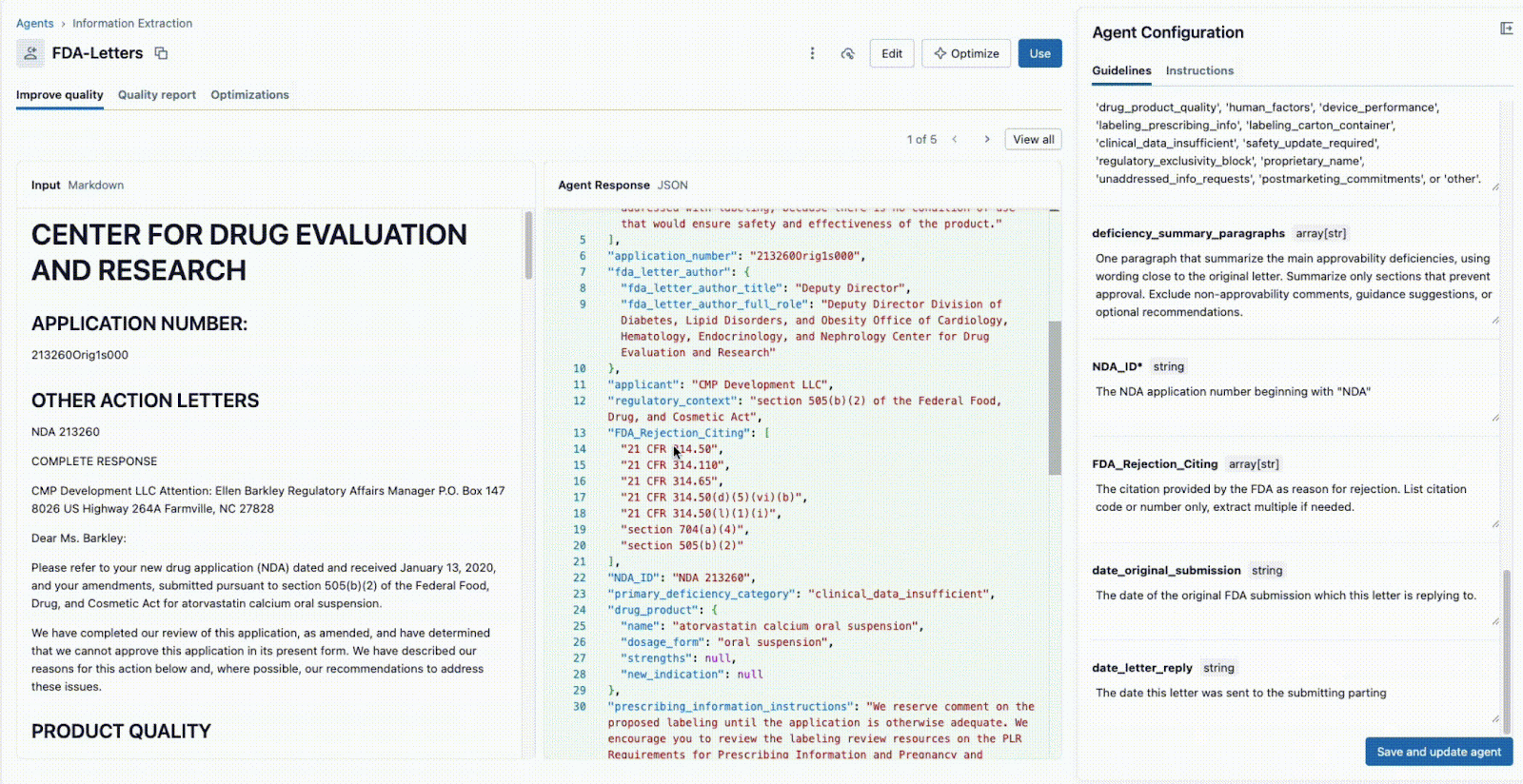
Questo ciclo di feedback istantaneo è la chiave del successo. Se un campo non viene estratto correttamente, il team può modificare il prompt, aggiungere un nuovo campo o perfezionare le istruzioni e visualizzare il risultato in pochi secondi. Questo processo iterativo, in cui più esperti collaborano in un'unica interfaccia, è ciò che distingue i progetti di IA di successo da quelli che falliscono perché isolati.
Passaggio 3: valutazione e convalida dell'agente
Nel passaggio 2, abbiamo creato un agente che, a un primo "controllo di massima", sembrava corretto durante lo sviluppo iterativo. Ma come possiamo garantire un'elevata accuratezza e scalabilità quando si analizzano nuovi dati? Una modifica al prompt che corregge un documento potrebbe comprometterne altri dieci. È qui che entra in gioco la valutazione formale, una parte fondamentale e integrata del flusso di lavoro di Agent Bricks.
Questo passaggio è il tuo controllo di qualità e fornisce due potenti metodi per la convalida:
Metodo A: valutazione con etichette di ground truth (il gold standard)
L'IA, come qualsiasi progetto di Data Science, fallisce nel vacuum senza un'adeguata conoscenza del dominio. Un investimento da parte degli SME per fornire un "golden set" (ovvero ground truth, set di dati etichettati) di informazioni corrette e pertinenti, estratte manualmente e convalidate da esseri umani, contribuisce notevolmente a garantire che questa soluzione generalizzi su nuovi file e formati. Questo perché le coppie chiave:valore etichettate aiutano rapidamente l'agente a mettere a punto prompt di alta qualità che portano a estrazioni accurate e pertinenti per il business. Vediamo nel dettaglio come Agent Bricks utilizza queste etichette per valutare formalmente il tuo agente.
Nell'interfaccia utente di Agent Bricks, fornisci il test set di ground truth e, in background, Agent Bricks verrà eseguito sui documenti di test. L'interfaccia utente fornirà un confronto affiancato dell'output estratto dal tuo agente rispetto alla risposta etichettata "corretta".
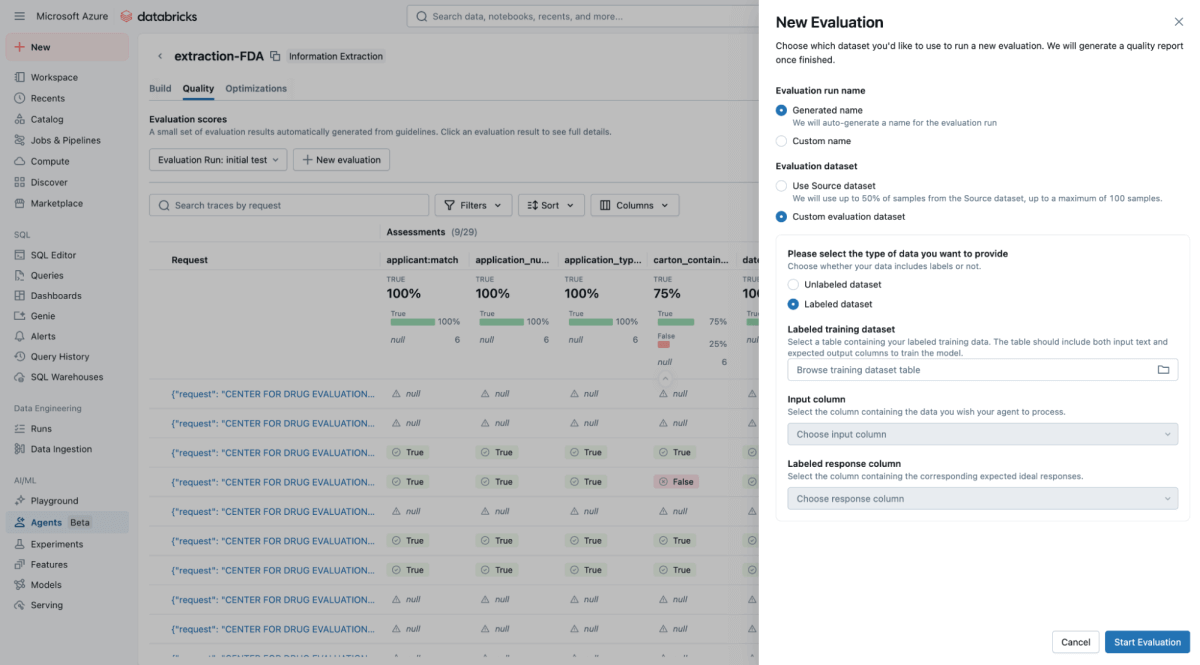
L'UI fornisce un punteggio di accuratezza chiaro per ogni campo di estrazione, che consente di individuare immediatamente le regressioni quando si modifica un prompt. Con Agent Bricks, acquisisci una sicurezza a livello aziendale sul fatto che l'agente opera con un'accuratezza pari o superiore a quella umana.
Metodo B: nessuna etichetta? Utilizza LLM-as-a-Judge
Ma cosa succede se si parte da zero e non si dispone di etichette di ground truth? Questo è un comune problema di "cold start".
La suite di valutazione Agent Bricks fornisce una soluzione potente: LLM-as-a-Judge. Databricks fornisce una suite di framework di valutazione e Agent Bricks sfrutterà i modelli di valutazione per agire come valutatore imparziale. Al modello "Judge" vengono presentati il testo del documento originale e una serie di prompt di campo per ogni documento. Il ruolo del “Judge” è quello di generare una risposta "prevista" e quindi valutarla confrontandola con l'output estratto dall'agente.
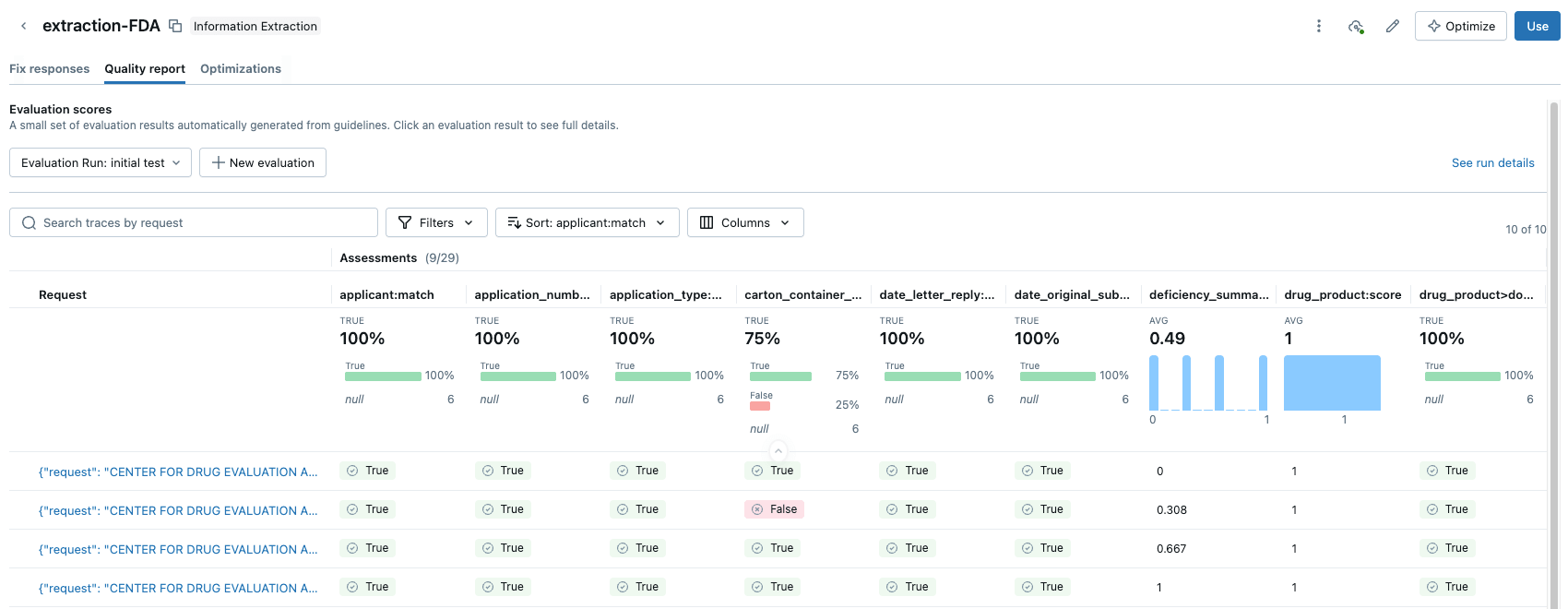
LLM-as-a-Judge consente di ottenere un punteggio di valutazione scalabile e di alta qualità e, nota bene, può anche essere utilizzato in produzione per garantire che gli agenti rimangano affidabili e generalizzabili alla variabilità e alla scalabilità della produzione. Ne parleremo in modo più approfondito in un prossimo blog.
Passaggio 4: integrazione dell'agente con ai_query() nella pipeline ETL
A questo punto, hai creato il tuo agente nel passaggio 2 e ne hai convalidato l'accuratezza nel passaggio 3; ora hai la sicurezza necessaria per integrare l'estrazione nel tuo flusso di lavoro. Con un solo clic, puoi distribuire il tuo agente come endpoint di un modello serverless. La tua logica di estrazione sarà immediatamente disponibile come funzione semplice e scalabile.
Per farlo, utilizza la funzione ai_query() in SQL per applicare questa logica ai nuovi documenti man mano che arrivano. La funzione ai_query() consente di richiamare qualsiasi endpoint di servizio del modello in modo diretto e trasparente nella tua pipeline di dati ETL end-to-end.
In questo modo, Databricks Lakeflow Jobs ti garantisce una pipeline ETL completamente automatizzata e di livello produttivo. Il tuo Job Databricks prende i PDF grezzi che arrivano nel tuo cloud storage, ne esegue il parsing, estrae informazioni dettagliate strutturate utilizzando il tuo agente di alta qualità e li inserisce in una tabella pronta per l'analisi, la reportistica o per essere referenziata nel recupero di un'applicazione agente a valle.
Databricks è la piattaforma di IA di nuova generazione, che abbatte le barriere tra i team altamente tecnici e gli esperti di dominio che possiedono il contesto necessario per creare un'IA significativa. Il successo con l'IA non si basa solo su modelli o infrastruttura; si tratta della stretta collaborazione iterativa tra ingegneri ed esperti di materia, in cui ognuno affina il pensiero dell'altro. Databricks offre ai team un unico ambiente per sviluppare in modo collaborativo, sperimentare rapidamente, gestire in modo responsabile e riportare la scienza nella data science.
Agent Bricks è l'incarnazione di questa visione. Con ai_parse_document() per analizzare i contenuti non strutturati, l'interfaccia di progettazione collaborativa di Agent Bricks: Information Extraction per accelerare le estrazioni di alta qualità e ai_query() per applicare la soluzione in pipeline pronte per la produzione, i team possono passare da milioni di PDF disordinati a approfondimenti convalidati più velocemente che mai.
Nel nostro prossimo blog, mostreremo come usare queste informazioni dettagliate estratte e creare un agente di chat di livello produttivo in grado di rispondere a domande in linguaggio naturale come: "Quali sono i problemi più comuni di preparazione alla produzione per i farmaci oncologici?"
- Per saperne di più: leggi la documentazione ufficiale per ai_parse_document(), Agent Bricks: estrazione di informazioni e ai_query().
- Per iniziare: Iscriviti a una prova gratuita di Databricks per creare oggi stesso le tue soluzioni basate sull'IA.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.