Dal caos a Scale: creazione di modelli per pipeline dichiarative di Spark con DLT-META
Un framework di metadati per creare pipeline coerenti, automatizzate e governate su larga scala
di Ravi Gawai e Phoebe Weiser
- La scalabilità delle pipeline di dati introduce overhead, drift e logiche incoerenti tra i team.
- Queste lacune rallentano la delivery, aumentano i costi di manutenzione e rendono difficile applicare standard condivisi.
- Questo blog mostra come la metaprogrammazione basata sui metadati elimini la duplicazione e crei pipeline di dati automatizzate e coerenti su larga scala.
Le pipeline dichiarative offrono ai team un modo basato sugli intenti per creare flussi di lavoro batch e di streaming. Definisci cosa deve accadere e lascia che il sistema gestisca l'esecuzione. Questo riduce il codice personalizzato e supporta modelli di ingegneria ripetibili.
Con la crescita dell'utilizzo dei dati da parte delle organizzazioni, le pipeline si moltiplicano. Gli standard si evolvono, vengono aggiunte nuove fonti e sempre più team partecipano allo sviluppo. Anche piccoli aggiornamenti dello schema si ripercuotono su decine di notebook e configurazioni. La metaprogrammazione basata sui metadati risolve questi problemi spostando la logica della pipeline in Template strutturati generati in fase di esecuzione.
Questo approccio mantiene la coerenza dello sviluppo, riduce la manutenzione e scala con uno sforzo di ingegneria limitato.
In questo blog scoprirai come creare pipeline basate sui metadati per Spark Declarative Pipelines utilizzando DLT-META, un progetto di Databricks Labs che applica modelli di metadati per automatizzare la creazione di pipeline.
Per quanto utili siano le Declarative Pipelines, il lavoro necessario per supportarle aumenta rapidamente quando i team aggiungono più fonti e ne espandono l'utilizzo all'interno dell'organizzazione.
Perché le pipeline manuali sono difficili da gestire su larga scala
Le pipeline manuali funzionano su piccola scala, ma l'impegno di manutenzione cresce più velocemente dei dati stessi. Ogni nuova fonte aggiunge complessità, portando a un drift della logica e a rilavorazioni. I team finiscono per applicare patch alle pipeline invece di migliorarle. I data engineer affrontano costantemente queste sfide di scalabilità:
- Troppi artefatti per sorgente: ogni set di dati richiede nuovi Notebook, configurazioni e script. Il sovraccarico operativo cresce rapidamente con ogni feed integrato.
- Gli aggiornamenti della logica non si propagano: le modifiche alle regole di business non vengono applicate alle pipeline, causando un drift della configurazione e output incoerenti tra le pipeline.
- Qualità e governance incoerenti: i team creano controlli e lignaggio personalizzati, rendendo difficile l'applicazione di standard a livello aziendale e i risultati molto variabili.
- Contributo sicuro limitato da parte dei team di dominio: gli analisti e i team aziendali vogliono aggiungere dati; tuttavia, l'ingegneria dei dati continua a rivedere o a riscrivere la logica, rallentando la consegna.
- La manutenzione si moltiplica a ogni modifica: semplici modifiche o aggiornamenti dello schema creano un enorme arretrato di lavoro manuale in tutte le pipeline dipendenti, rallentando l'agilità della piattaforma.
Questi problemi dimostrano l'importanza di un approccio basato sui metadati. Riduce l'impegno manuale e mantiene le pipeline coerenti con la scalabilità.
Come DLT-META gestisce la scalabilità e la coerenza
DLT-META risolve i problemi di scalabilità e coerenza delle pipeline. È un framework di metaprogrammazione basato su metadati per le Declarative Pipeline di Spark. I team di dati lo utilizzano per automatizzare la creazione di pipeline, standardizzare la logica e scalare lo sviluppo con una quantità minima di codice.
Con la metaprogrammazione, il comportamento della pipeline deriva dalla configurazione anziché da notebook ripetuti. Questo offre ai team chiari vantaggi.
- Meno codice da scrivere e gestire
- Onboarding più rapido di nuove sorgenti di dati
- Pipeline pronte per la produzione fin dall'inizio
- Pattern coerenti su tutta la piattaforma
- Best practice scalabili con team snelli
Spark Declarative Pipelines e DLT-META lavorano insieme. Le pipeline dichiarative Spark definiscono l'intento e gestiscono l'esecuzione. DLT-META aggiunge un livello di configurazione che genera e scala la logica della pipeline. Insieme, sostituiscono la codifica manuale con pattern ripetibili che supportano governance, efficienza e crescita su larga scala.
In che modo DLT-META risponde alle reali esigenze di ingegneria dei dati
1. Configurazione centralizzata e basata su modelli
DLT-META centralizza la logica delle pipeline in template condivisi per eliminare la duplicazione e la manutenzione manuale. I team definiscono le regole di ingestione, trasformazione, qualità e governance in metadati condivisi utilizzando JSON o YAML. Quando viene aggiunta una nuova fonte o una regola viene modificata, i team aggiornano la configurazione una sola volta. La logica si propaga automaticamente in tutte le pipeline.
2. Scalabilità istantanea e onboarding più rapido
Gli aggiornamenti basati sui metadati semplificano la scalabilità delle pipeline e l'onboarding di nuove origini. I team aggiungono origini o modificano le regole di business modificando i file di metadati. Le modifiche vengono applicate a tutti i carichi di lavoro downstream senza intervento manuale. Le nuove origini passano in produzione in pochi minuti anziché in settimane.
3. Contributo del team di dominio con standard applicati
DLT-META consente ai team di dominio di contribuire in modo sicuro tramite la configurazione. Analisti ed esperti di dominio aggiornano i metadati per accelerare la delivery. I team di piattaforma e di ingegneria mantengono il controllo su convalida, qualità dei dati, trasformazioni e regole di conformità.
4. Coerenza e governance a livello aziendale
Gli standard a livello di organizzazione si applicano automaticamente a tutte le pipeline e a tutti i consumer. La configurazione centrale impone una logica coerente per ogni nuova sorgente. Le regole integrate di audit, lineage e qualità dei dati supportano i requisiti normativi e operativi su larga scala.
Come i team utilizzano DLT-META nella pratica
I clienti usano DLT-META per definire l'acquisizione e le trasformazioni una sola volta e applicarle tramite configurazione. Ciò riduce il codice personalizzato e velocizza l'onboarding.
Cineplex ha riscontrato un impatto immediato.
Utilizziamo DLT-META per ridurre al minimo il codice personalizzato. Gli ingegneri non scrivono più pipeline in modo diverso per le attività semplici. I file JSON di onboarding applicano un framework coerente e si occupano del resto.—Aditya Singh, Data Engineer, Cineplex
PsiQuantum mostra come i piccoli team possano scalare in modo efficiente.
DLT-META ci aiuta a gestire i workload bronze e silver con una bassa manutenzione. Supporta grandi volumi di dati senza notebook o codice sorgente duplicati.—Arthur Valadares, Principal Data Engineer, PsiQuantum
In diversi settori industriali, i team applicano lo stesso pattern.
- Retail: centralizza i dati dei negozi e della supply chain da centinaia di fonti
- Logistica standardizza l'ingestion batch e in streaming per i dati IoT e delle flotte
- I servizi finanziari garantiscono audit e conformità, accelerando l'onboarding dei feed
- Sanità: mantiene la qualità e l'auditabilità in set di dati complessi
- Settore manifatturiero e delle telecomunicazioni scalano l'acquisizione utilizzando metadati riutilizzabili e governati a livello centrale
Questo approccio consente ai team di aumentare il numero di pipeline senza aumentare la complessità.
Come iniziare a usare DLT-META in 5 semplici passaggi
Non è necessario riprogettare la piattaforma per provare DLT-META. Start in piccolo. Usa poche fonti. Lascia che i metadati guidino il resto.
1. Ottenere il framework
Start eseguendo il clone del repository DLT-META. Questo ti fornisce i template, gli esempi e gli strumenti necessari per definire le pipeline utilizzando i metadati.
2. Definisci le tue pipeline con i metadati
Successivamente, definisci cosa dovrebbero fare le tue pipeline. È possibile farlo modificando un piccolo set di file di configurazione.
- Utilizza conf/onboarding.json per descrivere le tabelle di input non elaborate.
- Utilizzare conf/silver_transformations.json per definire le trasformazioni.
- Facoltativamente, aggiungi conf/dq_rules.json se desideri applicare regole sulla qualità dei dati.
A questo punto, stai descrivendo l'intento. Non stai scrivendo il codice della pipeline.
3. Importare i metadati nella piattaforma
Prima che le pipeline possano essere eseguite, DLT-META deve registrare i metadati. Questo passaggio di onboarding converte le configurazioni in tabelle delta Dataflowspec che le pipeline leggono in fase di esecuzione.
È possibile eseguire l'onboarding da un Notebook, un Lakeflow Job o dalla CLI DLT.
a. Onboarding manuale tramite notebook, ad es. qui
Utilizza il Notebook di onboarding fornito per elaborare i metadati e creare gli artefatti della pipeline:
b. Automatizzare l'onboarding tramite Lakeflow Jobs con un Python wheel.
L'esempio seguente mostra l'interfaccia utente di Lakeflow Jobs per creare e automatizzare una pipeline DLT-META
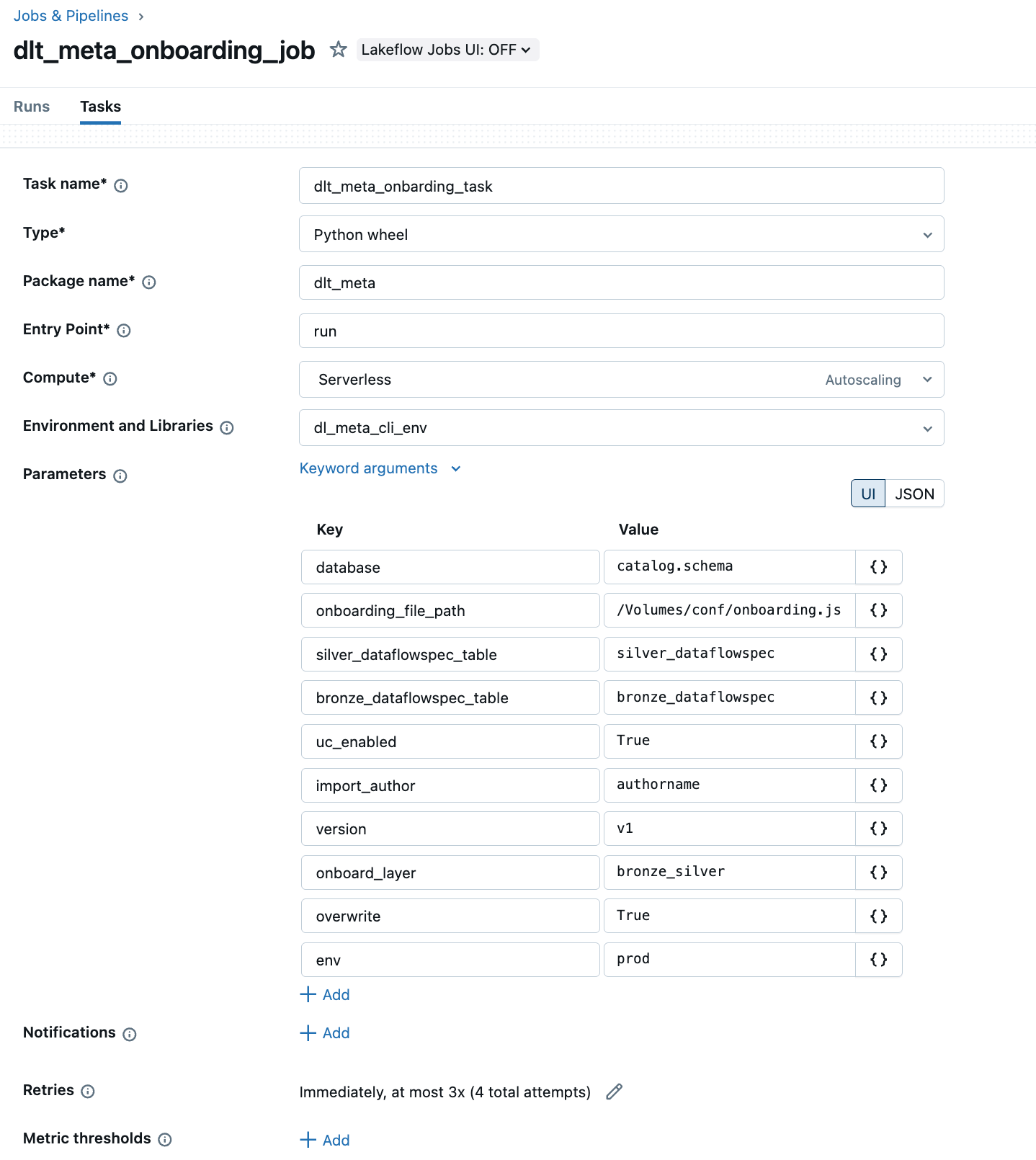
c. Esegui l'onboarding utilizzando i comandi della CLI di DLT-META indicati nel repository: qui.
La CLI DLT-META consente di eseguire l'onboarding e il deployment in un terminale Python interattivo.
4. Creare una pipeline generica
Con i metadati disponibili, si crea un'unica pipeline generica. Questa pipeline legge dalle tabelle Dataflowspec e genera la logica in modo dinamico.
Usa pipelines/dlt_meta_pipeline.py come punto di ingresso e configuralo in modo che faccia riferimento alle tue specifiche bronze e silver.
Questa pipeline rimane invariata man mano che aggiungi origini. I metadati controllano il comportamento.

5. Trigger ed esegui
Ora è tutto pronto per eseguire la pipeline. Attivala come qualsiasi altra pipeline dichiarativa di Spark.
DLT-META crea ed esegue la logica della pipeline in fase di esecuzione.
L'output è costituito da tabelle bronze e silver pronte per la produzione, con trasformazioni coerenti, regole di qualità e lineage applicati automaticamente.
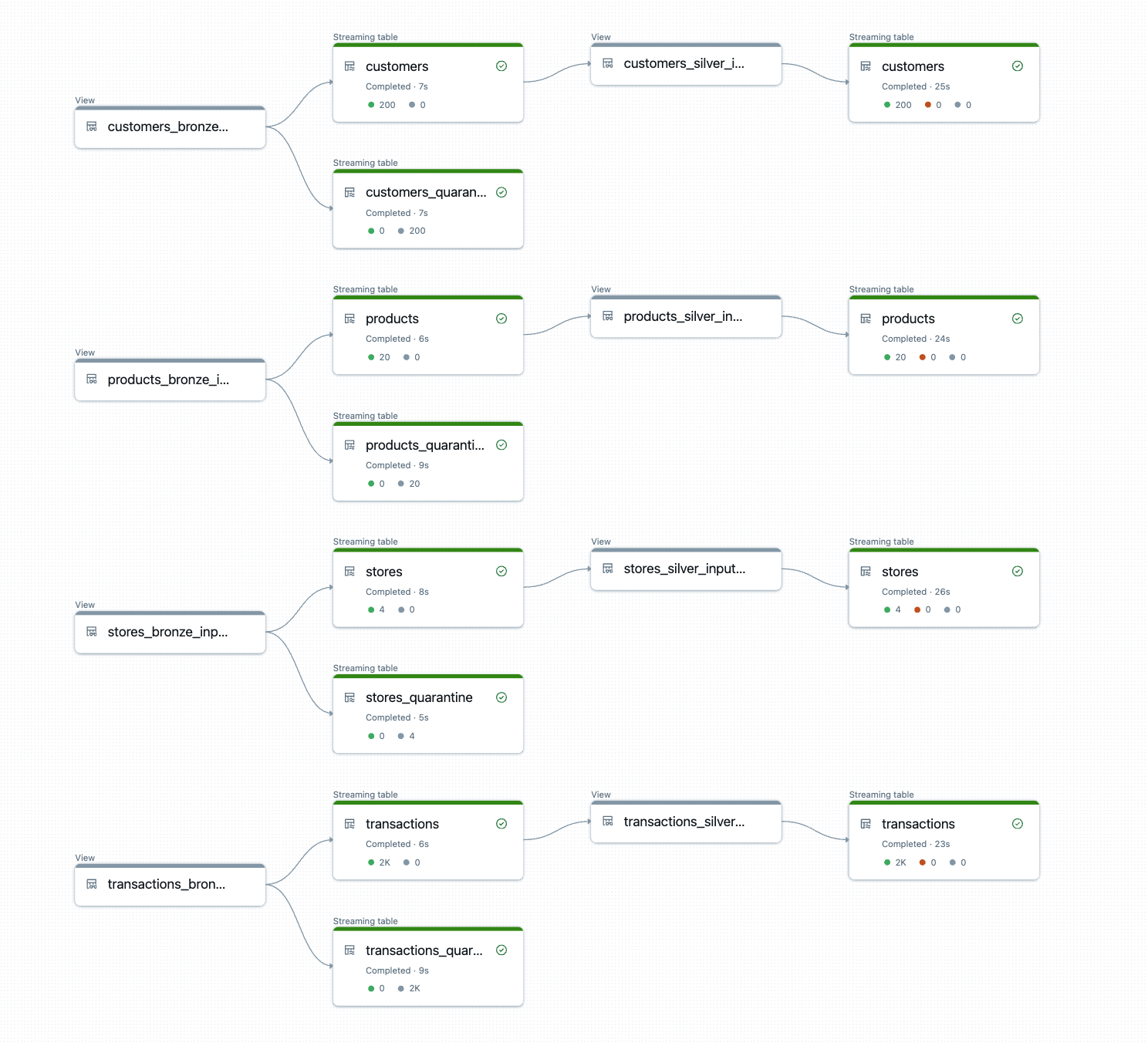
{kind=link}
Provalo oggi
Per iniziare, consigliamo di avviare un proof of concept utilizzando le pipeline dichiarative di Spark esistenti con un numero ridotto di fonti, migrando la logica della pipeline nei metadati e lasciando che DLT-META esegua l'orchestrazione su larga scala. Start con un piccolo proof of concept e osserva come la metaprogrammazione basata su metadati scali le tue capacità di data ingegneria oltre ciò che pensavi fosse possibile.
Risorse di Databricks
- Per iniziare: https://github.com/databrickslabs/DLT-META#getting-started
- GitHub: github.com/databrickslabs/DLT-META
- Documentazione di GitHub: databrickslabs.github.io/DLT-META
- Documentazione di Databricks: https://docs.databricks.com/aws/en/dlt-ref/DLT-META
- Demo: databrickslabs.github.io/DLT-META/demo
- Ultima versione: https://github.com/databrickslabs/DLT-META/releases
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.