L'intelligenza delle operazioni cliniche appartiene al Lakehouse
Come Databricks Apps, Lakebase e AI/BI Genie eliminano lo stack di integrazione tra dati clinici e applicazioni di supporto decisionale — e perché quel cambiamento architetturale è ciò che le operazioni cliniche stavano perdendo.
- Cos'è: Il Site Feasibility Workbench è un'app Databricks open-source che esegue la selezione dei siti per studi clinici interamente all'interno dell'area di lavoro Databricks — combinando punteggi dei siti basati su ML, Lakebase per lo stato operativo e AI/BI Genie per l'accesso ai dati in linguaggio naturale, senza chiamate API esterne o pipeline di sincronizzazione.
- La sfida che risolve: il 37% dei siti investigatori non raggiunge gli obiettivi di arruolamento e la causa principale è architetturale — i dati delle operazioni cliniche e le applicazioni che li utilizzano risiedono in sistemi disconnessi, costringendo le decisioni in fogli di calcolo e creando overhead di integrazione, diffusione di credenziali e ritardo di sincronizzazione che erode la fiducia nei dati.
- Risultati e esiti: i modelli LightGBM segmentati per TA addestrati sulla cronologia del tuo CTMS, EDC e IRT — non sulle medie del settore — producono punteggi che migliorano man mano che il tuo portafoglio cresce, con spiegazioni guidate da SHAP archiviate come tabelle Delta governate e versionate. Ogni previsione porta un'attribuzione guidata da SHAP archiviata come tabella Delta governata, rendendo la logica del modello auditabile e versionata quanto il punteggio stesso.
Il problema dei dati clinici non è un problema di archiviazione. La maggior parte delle organizzazioni dispone già di un data warehouse, un CTMS, un EDC e, a valle, un livello di BI. Il problema è che nessuno di questi sistemi comunica tra loro in modo da supportare le decisioni effettive che i team clinici devono prendere, e quindi le decisioni vengono prese invece nei fogli di calcolo.
Oggi rilasciamo il Site Feasibility Workbench come Databricks App completamente open-source, per mostrare come appare l'intelligenza delle operazioni cliniche quando l'applicazione, i modelli e i dati risiedono sulla stessa piattaforma. Il Tufts Center for the Study of Drug Development ha documentato che il 37% dei siti investigatori attivati ha reclutato meno pazienti dei propri obiettivi, e un ulteriore 11% non ha reclutato alcun paziente, con l'effetto combinato che il 53% degli studi ha superato le tempistiche di reclutamento pianificate, con un sesto che ha richiesto più del doppio del tempo previsto (Lamberti et al.; successivi report di impatto CSDD continuano a monitorare la sottoperformance a livelli simili). Fino a $500.000 al giorno di vendite di farmaci non realizzate e $40.000 al giorno di costi diretti dello studio, la sottoperformance cronica dei siti è uno dei driver di costo più consequenziali nello sviluppo di farmaci. Questo tasso di sottoperformance combinato è rimasto essenzialmente invariato per almeno due decenni. Gli strumenti non sono il problema. L'architettura lo è.
I team di operazioni cliniche non hanno bisogno di più dashboard collegati ai sistemi esistenti. Hanno bisogno che le loro applicazioni di supporto decisionale risiedano dove risiedono i loro dati e modelli, in modo che il ciclo di feedback tra una previsione e il risultato operativo che la convalida si chiuda effettivamente.
L'Argomento Architettonico
L'approccio convenzionale al supporto decisionale clinico è questo: i dati analitici risiedono in un data warehouse o Lakehouse. Un database applicativo separato contiene lo stato operativo. Una pipeline li mantiene debolmente sincronizzati. Un'applicazione web si posiziona di fronte a entrambi, aggiungendo armonizzazione semantica nello strato Silver. Ogni strato introduce overhead di integrazione, superficie di credenziali e un ritardo di sincronizzazione che erode la fiducia nei dati mostrati dall'applicazione.
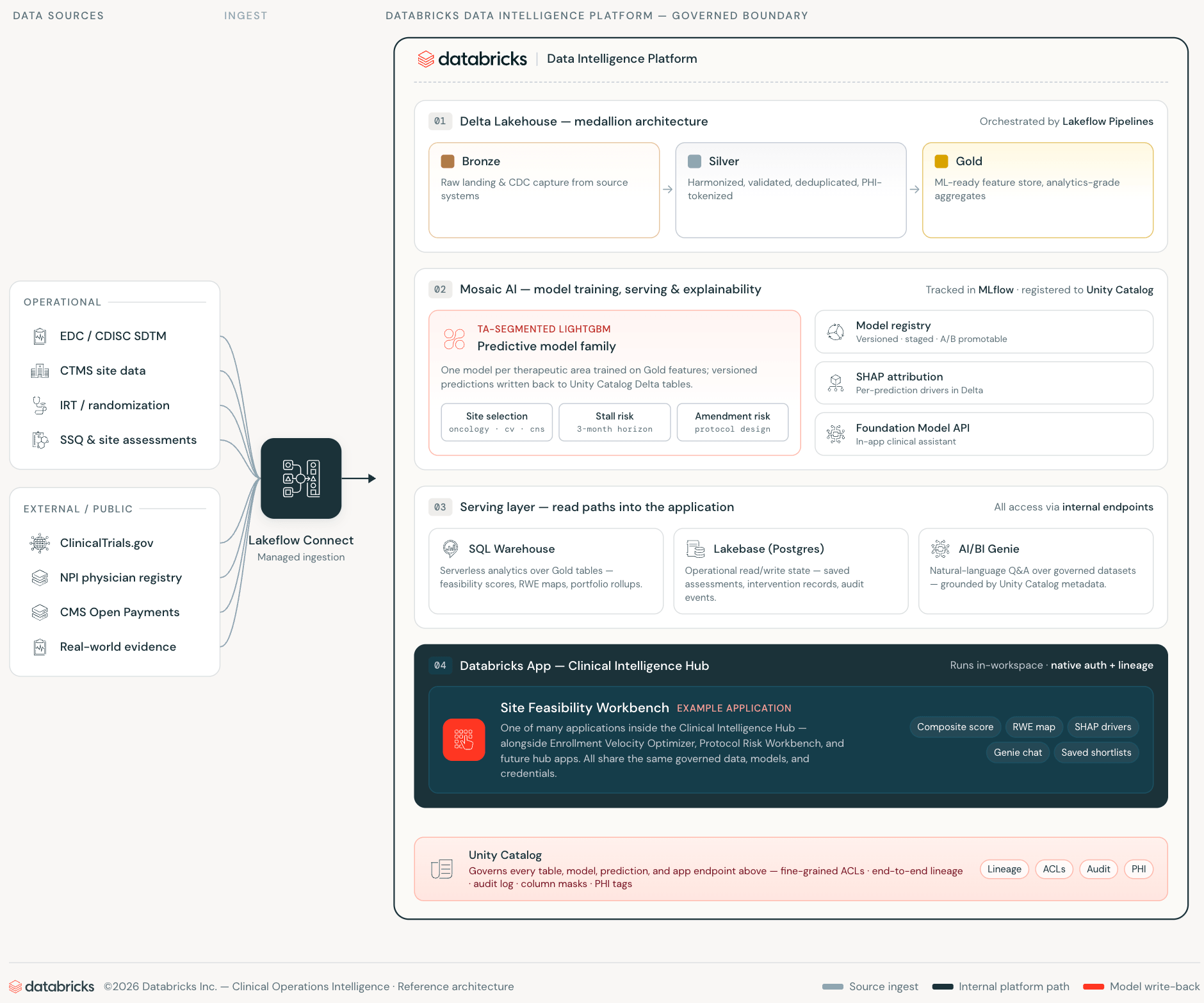
Databricks Apps, Lakebase e AI/BI Genie eliminano ciascuno di questi strati, non astrandoli ma rendendoli non necessari.
Databricks Apps esegue l'applicazione web all'interno dello workspace. L'app si autentica come principal di servizio di prima classe dello workspace, interroga Unity Catalog tramite l'API SQL Statement e chiama AI/BI Genie tramite l'API REST dello workspace, tutto su connessioni interne. I dati delle operazioni cliniche non attraversano mai un confine dello workspace. L'app eredita i controlli di accesso di Unity Catalog senza alcuna configurazione aggiuntiva.
Lakebase è lo strato del database operativo, PostgreSQL gestito che scala a zero quando inattivo, provisionato e con credenziali interamente all'interno del sistema di identità dello workspace. Dove un'applicazione tradizionale richiederebbe un'istanza RDS gestita separatamente con il proprio schema drift, processi di sincronizzazione e rotazione delle credenziali, Lakebase si trova sulla stessa piattaforma dove risiedono i dati e i modelli.
AI/BI Genie chiude l'ultimo divario: accesso in linguaggio naturale ai dati governati, incorporato direttamente nel flusso di lavoro dell'applicazione. I responsabili dello studio pongono domande in linguaggio naturale sulle stesse tabelle di Unity Catalog su cui sono stati addestrati i modelli ML, con gli stessi controlli di accesso applicati.
Il risultato è un'applicazione di operazioni cliniche che non effettua chiamate API esterne, non mantiene infrastrutture di database operative separate e non richiede alcuna pipeline di sincronizzazione tra gli strati analitici e operativi.
L'Argomento di Auditabilità
L'approccio standard del settore alla fattibilità dei siti si basa su prodotti di punteggio commerciali di fornitori o piattaforme di analisi fornite da CRO. Questi strumenti sono costruiti su dati aggregati del settore, utili come baseline, ma ciechi alle specificità del tuo portafoglio. Uno sponsor con un decennio di cronologia CTMS, EDC e IRT porta segnali significativi su come i propri siti si comportano sui propri protocolli.
Quando lo stack ML risiede su Databricks, quella conoscenza istituzionale diventa i dati di addestramento. I modelli in questo workbench sono addestrati sui tassi di reclutamento storici, sulla cronologia di qualificazione dei siti, sui pattern di fallimento dello screening e sul record di esecuzione del protocollo, non sulle medie del settore. CMS Open Payments aggiunge uno strato di segnale pubblico che, se usato in modo appropriato, correla con l'impegno e l'infrastruttura di ricerca ed è liberamente disponibile. Man mano che il portafoglio di studi cresce, i modelli migliorano sulla stessa infrastruttura. Questo è il ritorno composto che un'architettura a piattaforma singola abilita e che un prodotto di punteggio con licenza non può fornire: ogni nuovo studio rende la previsione migliore e ogni nuova relazione con il sito si riflette nel successivo ciclo di addestramento. MLflow traccia ogni ciclo di addestramento del modello, parametri, metriche e artefatti, consentendo il confronto tra le versioni del modello, la riproducibilità su richiesta e una traccia di audit completa dai record CTMS ed EDC grezzi alla previsione distribuita.
Anche la dimensione normativa è importante qui. 21 CFR Part 11, ICH E6(R3) e la guida Good Machine Learning Practice (GMLP) della FDA, insieme alla crescente enfasi della FDA sulla trasparenza nel supporto decisionale algoritmico, rendono la spiegabilità del modello e la governance dei dati considerazioni materiali, non funzionalità opzionali. Poiché ogni previsione porta un'attribuzione SHAP memorizzata come tabella Delta governata in Unity Catalog, versionata in MLflow, con lineage tramite Unity Catalog, interrogabile, la logica dietro la selezione di un sito è auditabile quanto il punteggio stesso. Un team di affari clinici può rispondere a una domanda di un comitato di monitoraggio dati con una query SQL, non con un report di un fornitore a scatola nera.
Cosa Abbiamo Costruito
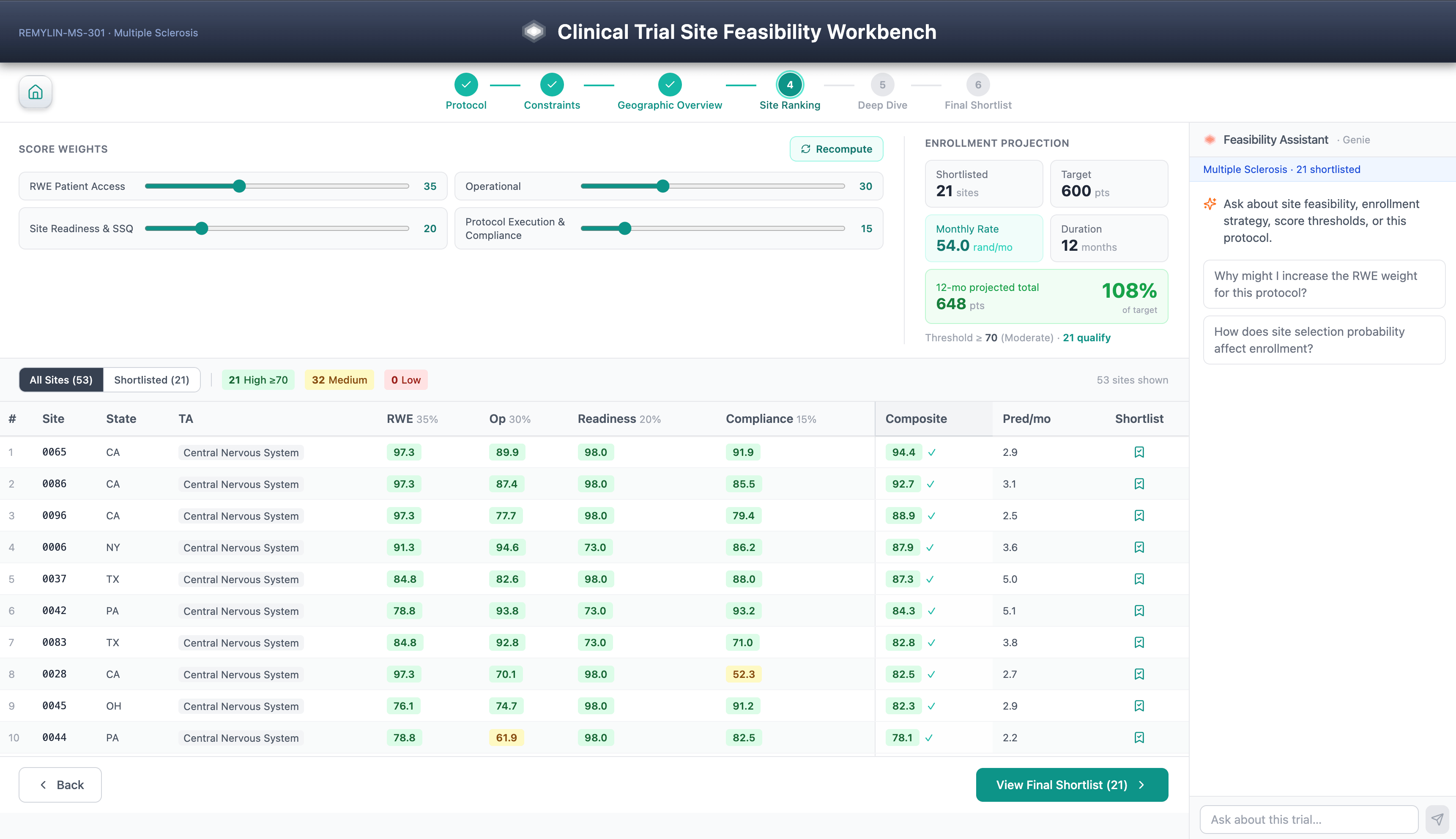
Il Site Feasibility Workbench è un flusso di lavoro guidato in sei passaggi per la selezione dei siti di studi clinici: selezione del protocollo, vincoli di punteggio, panoramica geografica, classificazione dei siti, approfondimento dei siti basato su SHAP e short list finale. Le considerazioni sulla diversità sono una dimensione di punteggio di prima classe, allineata alle aspettative del Piano d'Azione per la Diversità della FDA ai sensi del FDORA 2022.
I punteggi di fattibilità compositi combinano prove del mondo reale, dati di accesso ai pazienti, prestazioni storiche dei siti, cronologia di qualificazione dei siti, segnale KOL Open Payments e fattori di esecuzione del protocollo, tutti guidati da modelli LightGBM segmentati per TA addestrati sulla cronologia CTMS, EDC e IRT dell'organizzazione stessa.
La parte che vale la pena sottolineare non sono i passaggi del flusso di lavoro o le funzionalità del modello. I dati a livello di paziente ereditano i controlli di accesso di Unity Catalog e la gestione dei dati sensibili (PHI) segue la postura HIPAA Safe Harbor / Expert Determination dello sponsor configurata a livello di catalogo o schema.
È ciò che l'architettura rende possibile: ogni previsione porta una spiegazione SHAP memorizzata come tabella Delta governata accanto alla previsione stessa, rendendo la logica del modello auditabile e versionata quanto il punteggio che spiega. Poiché ogni previsione è scomposta in attribuzioni SHAP governate, gli sponsor possono verificare le raccomandazioni per la sottovalutazione sistematica dei siti della comunità, delle istituzioni che servono minoranze o dei primi investigatori, trasformando la spiegabilità in un controllo di equità.
Le short list salvate persistono in Lakebase per la condivisione del team. L'assistente AI/BI Genie risponde a domande interdominio sulle stesse tabelle di Unity Catalog in linguaggio naturale. Nulla di tutto ciò richiede un'infrastruttura al di fuori dello workspace.
Questo è uno strato di supporto decisionale, non un sistema di origine della registrazione. CTMS/EDC/IRT rimangono autorevoli. Il workbench produce previsioni la cui lineage è governata in Unity Catalog e MLflow.
L'intera applicazione - backend FastAPI, frontend React, notebook seed e script di distribuzione - è pubblicata come repository open-source. La distribuzione in uno workspace Databricks esistente con Unity Catalog richiede circa 30 minuti di tempo tecnico di distribuzione, prima della revisione della sicurezza e della convalida specifiche dello sponsor.
Un Modulo di una Piattaforma Più Ampia
Il Site Feasibility Workbench è la prima versione pubblica di un'architettura più ampia — il Databricks Clinical Operations Intelligence Hub — che copre l'intero ciclo di vita dello studio clinico:
- Fattibilità e Selezione del Sito — ciò che questo repository copre
- Coorte Pazienti e Reclutamento — costruzione di coorti allineate al protocollo da EHR e dati del mondo reale su scala Lakehouse
- Ottimizzatore di Velocità di Arruolamento — predizione di stallo ML per sito al mese con un orizzonte prospettico di 1-3 mesi
- Monitoraggio Basato sul Rischio e Conformità — monitoraggio continuo di anomalie di arruolamento, ritardi nei dati e deviazioni dal protocollo
Tutti e quattro vengono distribuiti come Databricks Apps. Tutti e quattro interrogano direttamente Unity Catalog. Nessuno effettua chiamate API esterne. Quando le applicazioni cliniche vivono dove vivono i tuoi dati e modelli, il ciclo di feedback si chiude. I modelli di selezione del sito apprendono dai risultati dell'arruolamento. I punteggi di rischio si aggiornano man mano che la cronologia delle modifiche cresce. Ogni raccomandazione guidata dall'IA porta una traccia di discendenza ai record CTMS, EDC e IRT che l'hanno prodotta.
Inizia
Clona il repository pubblico. Distribuisci. Dicci cosa cambi.
Per l'intero Clinical Operations Intelligence Hub — guarda la registrazione BrickTalk: Scaling BioPharma Intelligence + Databricks Agentic Clinical Ops.
Lakebase e Databricks Apps in produzione coprono in dettaglio i primitivi della piattaforma.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.