Sfatare 8 miti sulla struttura dei dati: perché Liquid Clustering supera il partizionamento
Il layout dei dati per il moderno lakehouse
di Jeffrey Gong, Yu Xu e Rahul Mahadev
- Liquid Clustering è il layout dei dati per i formati di tabelle aperte che supera il partizionamento aggirandone i limiti
- 8 miti comuni legano i team al partizionamento, e nessuno di essi è più valido
- I clienti che utilizzano Liquid Clustering segnalano miglioramenti drastici nella latenza delle query, nel throughput di scrittura, nell'efficienza dello storage e nella freschezza dei dati, con i maggiori guadagni che si accumulano su scala petabyte
Introduzione
Organizzare i dati è uno dei problemi più datati dell'informatica.
Da oltre 15 anni, dall'avvento di Hadoop e Hive, il partizionamento è stato il modo standard per organizzare fisicamente i dati per l'elaborazione e l'analisi. Tuttavia, i Lakehouse di oggi servono agenti, pipeline in tempo reale e modelli di query che cambiano più velocemente di quanto qualsiasi essere umano possa ripartizionare.
Liquid Clustering è lo standard moderno e i clienti lo utilizzano su ogni scala, incluse decine di tabelle su scala petabyte in produzione. In questo blog, analizzeremo perché Liquid Clustering vince nel Lakehouse. Lungo il percorso, sfateremo 8 miti comuni sulla disposizione dei dati, esamineremo 3 storie di successo di team che convertono tabelle partizionate in Liquid Clustering, anticiparemo cosa sta arrivando e mostreremo come iniziare.
Perché Liquid Clustering vince nel moderno lakehouse
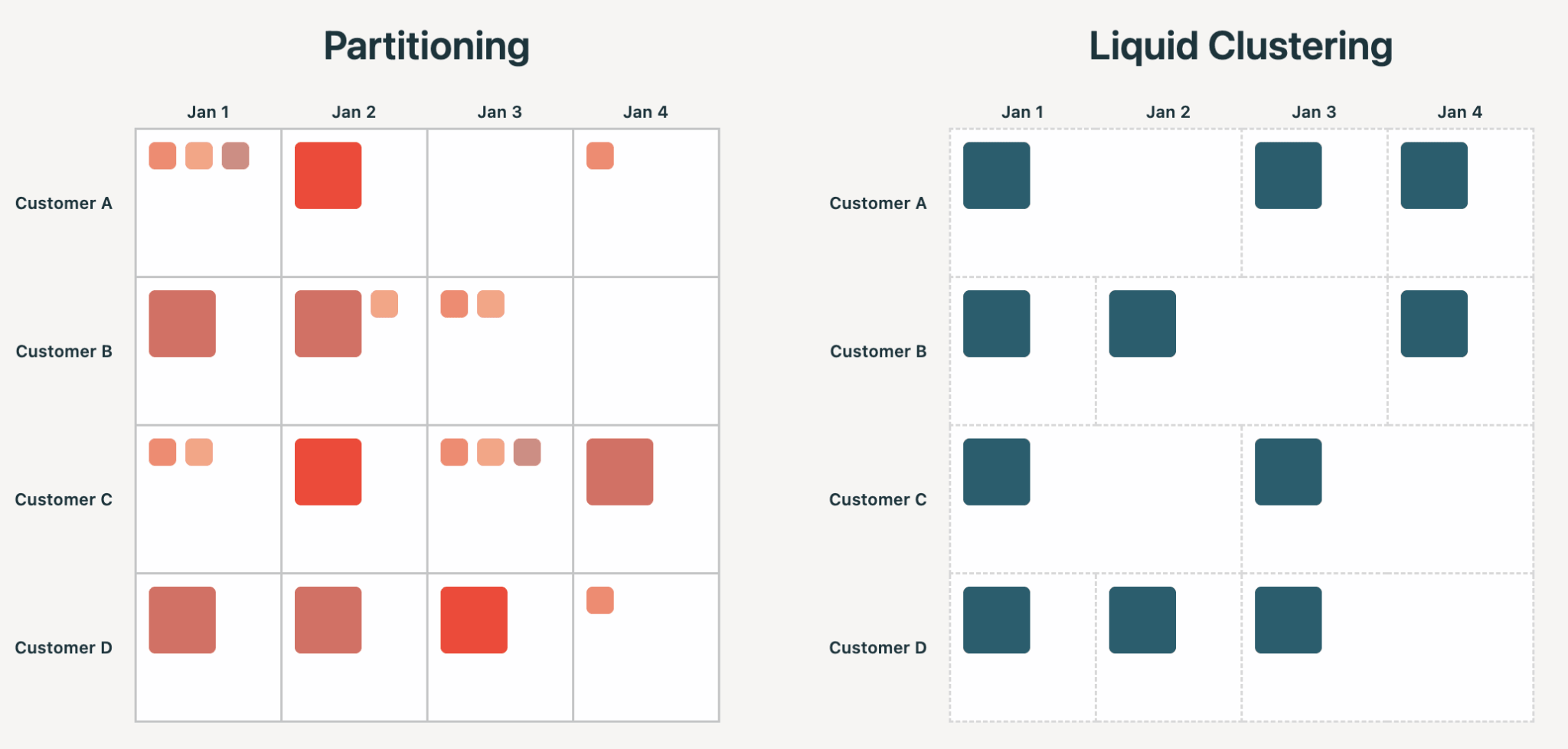
Il partizionamento in stile Hive obbliga gli utenti a impegnarsi, al momento della creazione della tabella, per un'organizzazione fisica dei dati che si manifesta nella struttura dei file. Scegli una colonna con cardinalità troppo elevata e otterrai miliardi di file piccoli. Scegli la colonna sbagliata e le query potrebbero rallentare, non velocizzarsi. In entrambi i casi, sei bloccato a riscrivere la tabella. È facile sbagliare: nella nostra analisi, il partizionamento in stile Hive porta a sovra-partizionamento e problemi di file piccoli in oltre il 75% dei casi.
Liquid tratta le chiavi di clustering come input che il motore utilizza per guidare l'organizzazione ottimale dei file. Le chiavi possono essere modificate in qualsiasi momento, o selezionate in modo intelligente tramite Liquid Clustering Automatico. La cardinalità non è un vincolo e la disposizione può evolvere nel tempo senza riscritture non necessarie.
I vantaggi di Liquid Clustering derivano tutti dal principio sopra menzionato: migliore gestione dello skew, concorrenza a livello di riga, nessun problema di file piccoli, clustering multidimensionale e minore amplificazione di scrittura.
Nel 2026, la disposizione dei dati dovrebbe essere un dettaglio di implementazione della tabella, con ogni motore che legge o scrive che ne trae beneficio. Questo è sempre più importante man mano che gli agenti entrano nel Lakehouse, generando e consumando più dati che mai. Umani e agenti necessitano di interfacce permissive, libere dagli effetti collaterali potenziali del partizionamento in stile Hive.
Sfatare 8 miti comuni sulla disposizione dei dati
Liquid Clustering è diventato Generalmente Disponibile nel 2024. Da allora, lo abbiamo migliorato continuamente con i clienti che lo utilizzano su larga scala. In quel periodo, alcuni miti comuni su Liquid Clustering e sul partizionamento sono persistiti, e oggi vogliamo sfatarli.
Mito #1: Il partizionamento è più veloce perché può eliminare directory invece di file
Il mito dice: Con il partizionamento, Spark o altri motori possono eliminare intere directory senza aprire alcun file al loro interno.
Realtà: L'eliminazione delle directory non esiste nei moderni formati di tabella aperti come Delta e Iceberg. Delta, ad esempio, utilizza un log delle transazioni per tracciare ogni file di dati insieme a statistiche per colonna, e l'eliminazione avviene contro quelle statistiche, non la struttura delle directory. Il motore non elenca mai le directory per pianificare una query. Legge il log delle transazioni, valuta i filtri rispetto alle statistiche e salta i file che non corrispondono. Liquid Clustering utilizza lo stesso meccanismo. Sia che i tuoi dati risiedano in `date=x/hour=y/` o in una directory piatta di file clusterizzati, il motore elimina a granularità di file. Non c'è scorciatoia a livello di directory da perdere.
Mito #2: Il partizionamento è migliore quando si filtra su una colonna a bassa cardinalità
Il mito dice: Per una colonna con un piccolo numero di valori distinti, il partizionamento offre una separazione perfetta dei dati e dimensioni dei file adeguate.
Realtà: Liquid Clustering rileva automaticamente quando applicare ottimizzazioni a bassa cardinalità. Ad esempio, se esegui il clustering per (date, user_id), e date ha bassa cardinalità, il sistema mira a far sì che ogni file contenga righe di una singola data. Colonne a cardinalità più elevata, come user_id, vengono quindi utilizzate automaticamente per un ordinamento più granulare all'interno dei file di ciascuna data, senza dover ricorrere ad altre tecniche di ordinamento come Z-Ordering.
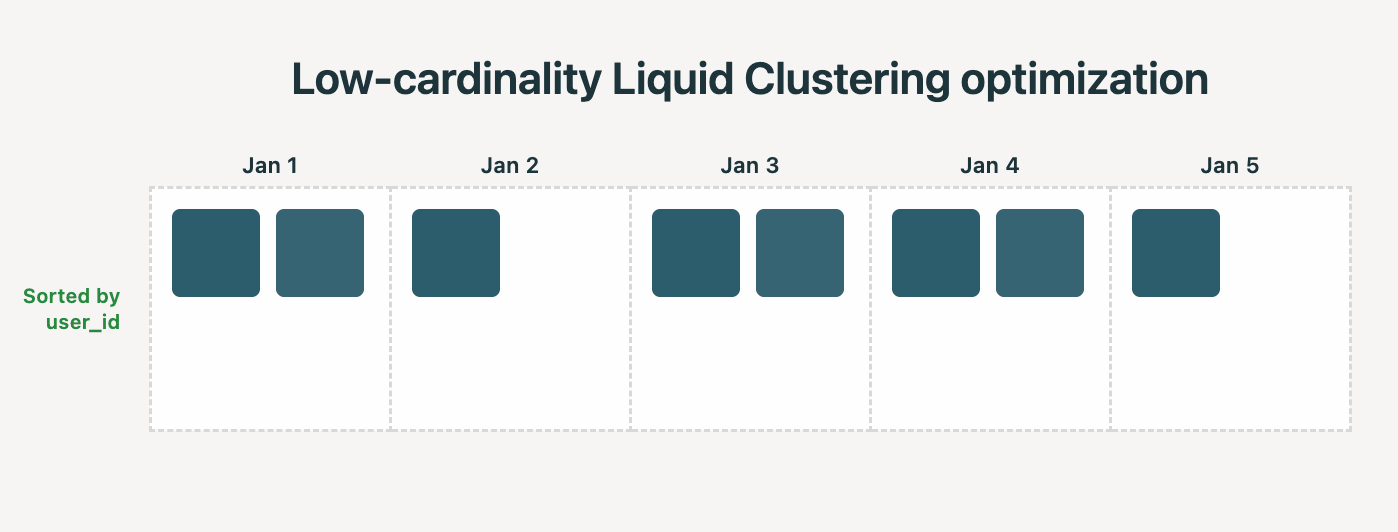
Abbiamo osservato i seguenti miglioramenti durante il benchmarking di questa ottimizzazione Liquid su un benchmark di data warehousing reale: 35% in meno di tempo per il clustering e 22% più veloci i tempi di query.
Inoltre, Liquid Clustering è progettato per essere migliore del partizionamento quando si effettua il clustering su una colonna ad alta cardinalità, poiché cerca sempre di creare file di buone dimensioni.
Mito #3: Liquid Clustering non supporta operazioni solo sui metadati
Il mito dice: Le operazioni solo sui metadati sono supportate in modo univoco dal partizionamento. Un DELETE allineato con i confini delle partizioni aggiorna solo i metadati della tabella, e gli aggregati sulle colonne di partizione possono essere calcolati senza scansionare i file. Liquid Clustering non può fare lo stesso.
Realtà: Liquid Clustering supporta anche operazioni solo sui metadati, inclusi DELETE, COUNT, DISTINCT e query GROUP BY. Il motore utilizza le stesse statistiche min/max per file che utilizza per lo skip dei dati per determinare quando la risposta di una query può essere calcolata solo dai metadati. Nei nostri benchmark, i DELETE solo sui metadati su tabelle clusterizzate con Liquid sono stati eseguiti ~90% più velocemente rispetto ai DELETE con riscrittura completa. Altre query aggregate solo sui metadati hanno visto accelerazioni fino a 27 volte.
Mito #4: Liquid Clustering non funziona bene su scala petabyte
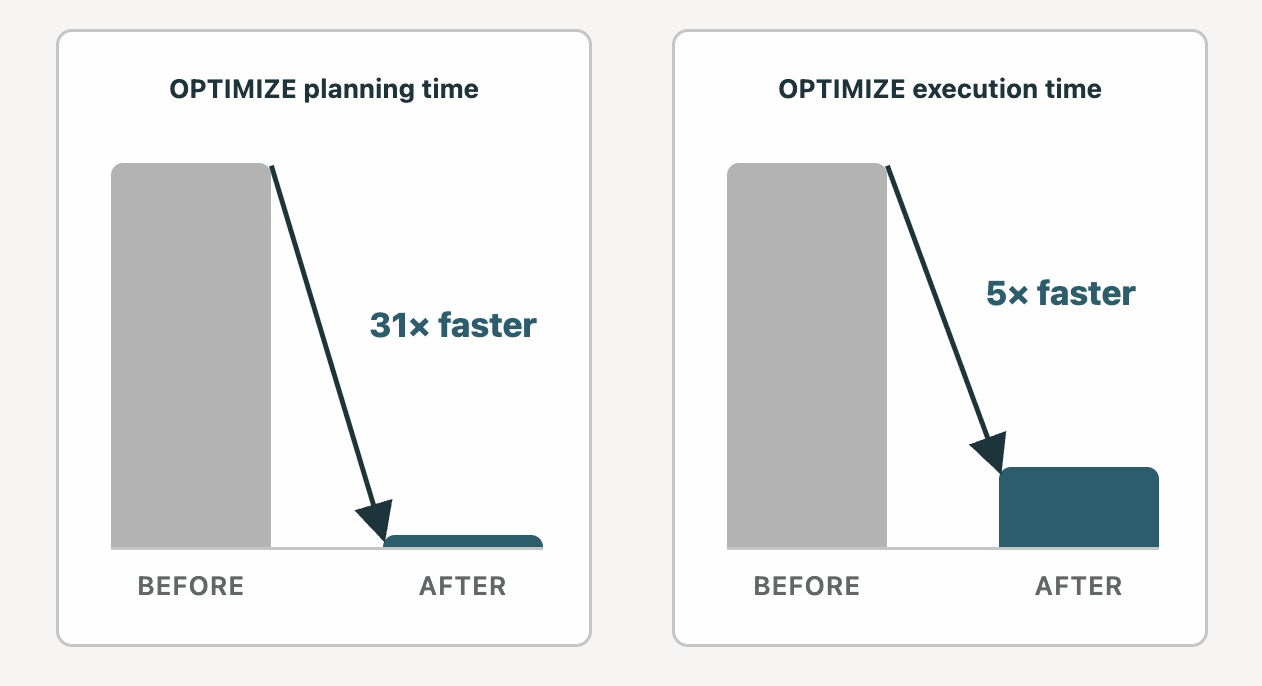
Il mito dice: OPTIMIZE su una tabella di dimensioni PB può richiedere ore e il costo di manutenzione è troppo elevato.
Realtà: Abbiamo apportato una serie di miglioramenti significativi a OPTIMIZE, e decine di clienti hanno ora tabelle Liquid clusterizzate su scala PB in produzione. Due anni fa, la pianificazione, la prima fase di OPTIMIZE, poteva richiedere fino a 12 ore su una tabella Liquid da 10 PB in alcuni casi. Abbiamo impiegato il tempo da allora per ridurre il tempo di pianificazione a 23 minuti. L'esecuzione, la seconda fase di OPTIMIZE, è diventata 5 volte più veloce su un cluster DBSQL medio.
Mito #5: Liquid Clustering avvantaggia solo un sottoinsieme di lettori
Il mito dice: Liquid Clustering è vantaggioso solo per i lettori Databricks su tabelle Delta gestite da UC.
Realtà: Liquid Clustering è un'ottimizzazione lato scrittura. È il modo in cui il motore organizza i file per uno skip efficiente dei dati. L'output sono file Parquet standard con statistiche min/max, scritti in formati di tabella aperti come Delta/Iceberg. Qualsiasi lettore compatibile (ad es. Apache Spark open-source, DuckDB, ecc.) può utilizzare tali statistiche per saltare i file. Liquid Clustering è disponibile sia su tabelle esterne/gestite che su tabelle Delta/ Iceberg, e il vantaggio è applicabile indipendentemente dal lettore.
Mito #6: Il partizionamento è necessario per ETL concorrenti
Il mito dice: L'ETL concorrente necessita di confini di scrittura. Senza partizionamento, due writer che aggiornano la stessa tabella rischiano di collidere, e il controllo della concorrenza di Delta/Iceberg costringe uno di loro a ritentare o fallire. Partiziona e assegna a ciascun writer la propria fetta della tabella, in modo che due pipeline non tocchino mai gli stessi file.
Realtà: Operare a livello di partizione era una soluzione temporanea per un modello di concorrenza più vecchio. A differenza del partizionamento che ha solo concorrenza a livello di file, Liquid offre concorrenza a livello di riga. Due scrittori che aggiornano righe diverse non entrano più in conflitto, anche se tali righe si trovano nello stesso file. Ciò elimina uno dei motivi principali per cui i team partizionavano le tabelle: mantenere i confini di scrittura per evitare la serializzazione. Con Liquid Clustering, ETL può operare facilmente in modo concorrente sulla stessa tabella.
Mito #7: Z-Ordering compensa le carenze del partizionamento
Il mito: Il partizionamento gestisce i filtri della colonna di partizione e Z-Ordering gestisce il resto. Eseguendo OPTIMIZE ZORDER BY, il motore ordina i dati per uno skipping ottimale sui filtri che non si allineano allo schema di partizione.
Realtà: Z-Ordering non salva il partizionamento. Infatti, ha i suoi problemi strutturali.
- Il primo è la scarsa qualità del clustering. Z-Order non mantiene un vero ordinamento nella tabella. I valori della stessa colonna possono essere distribuiti su molti file, quindi gli intervalli min/max per file sono più ampi e le query saltano meno file rispetto a quanto accadrebbe con Liquid.
- Il secondo è la riscrittura non necessaria. Z-Order deve essere rieseguito periodicamente man mano che arrivano nuovi dati, e ogni riesecuzione riscrive grandi quantità di dati vecchi, potenzialmente già clusterizzati, per ripristinare la qualità del clustering. Con l'ingestione continua, il costo per mantenere i dati ben clusterizzati con Z-Order cresce insieme alla tabella.
Liquid clusterizza in modo incrementale, anche al momento della scrittura, quindi il layout rimane ottimale senza riscriture non necessarie.
Mito #8: Il partizionamento è necessario per le sovrascritture selettive dei dati
Il mito: La possibilità di sovrascrivere selettivamente i dati è disponibile solo tramite Dynamic Partition Overwrites.
Realtà: Le sovrascritture selettive funzionano nativamente sulle tabelle Liquid. Databricks supporta REPLACE USING e REPLACE ON, due sintassi SQL per sovrascrivere selettivamente i dati su qualsiasi layout di dati: tabelle Liquid Clustered, partizionate o semplici non clusterizzate. A differenza di Dynamic Partition Overwrite che richiede una configurazione Spark, REPLACE USING e REPLACE ON possono essere utilizzati su qualsiasi calcolo: cluster classici, warehouse SQL e Serverless. L'operazione è atomica e corrisponde a qualsiasi colonna scelta.
Storie di successo: migrazione dal partizionamento a Liquid Clustering
Accelerazione delle query di 7,7x sulla tabella di telemetria di sicurezza da 3,8 PB di Arctic Wolf
Arctic Wolf gestisce una tabella di telemetria di sicurezza da 3,8+ PB che ingerisce oltre 1 trilione di eventi al giorno, dove i cacciatori di minacce dipendono da dati aggiornati per rilevare attacchi attivi.
Dopo la migrazione dal partizionamento a Liquid Clustering su tabelle gestite da Unity Catalog con Predictive Optimization, Arctic Wolf ha osservato:
- Le query a 90 giorni sono scese da 51 secondi a 6,6 secondi
- Il numero di file è sceso da 4M a 2M
- La freschezza dei dati è migliorata da ore a minuti
Miglioramenti di lettura e scrittura su tabelle CDC critiche per Bolt
Bolt ha recentemente provato Liquid Conversion (attualmente in Private Preview), che converte le tabelle partizionate in Liquid sul posto utilizzando ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY. Hanno osservato i seguenti vantaggi di lettura e scrittura su una tabella CDC su scala TB dopo la conversione a Liquid Clustering:
- Il throughput di scrittura (righe/sec) è aumentato del 138%
- I tempi di lettura sono stati ridotti fino al 63%, con una riduzione media del 21% su 9 query rappresentative
Liquid Clustering ha ridotto drasticamente il lavoro svolto da ogni scrittura, aumentando significativamente il nostro throughput sulla nostra tabella CDC più critica. Anche le letture sono migliorate in generale. La cosa migliore è stata: abbiamo eseguito la conversione dal partizionamento parallelamente all'ingestione live senza tempi di inattività. Con questo, Liquid Clustering ci ha fornito esattamente il tipo di prestazioni e affidabilità di cui avevamo bisogno su scala di piattaforma. —Marcin, un ingegnere di piattaforma senior presso Bolt
Accelerazione di 5,9x dei tempi di query su un carico di lavoro interno su scala petabyte
Gestiamo internamente una tabella da 1,1 PB che viene interrogata migliaia di volte al giorno, principalmente da ingegneri che eseguono indagini di produzione e dashboard di osservabilità. Originariamente era partizionata per data e ora, presumendo che le scansioni di intervalli di tempo avrebbero dominato. Tuttavia, tale ipotesi si è rivelata incompleta. Sebbene le scansioni di intervalli di tempo fossero comuni, la tabella veniva anche interrogata frequentemente per sorgente e id, costringendo il motore a scansionare ogni file nelle partizioni di data e ora pertinenti per trovare una manciata di righe.
L'aggiunta di sorgente e id come partizioni non era praticabile, perché c'erano troppi valori distinti. Ciò avrebbe creato miliardi di piccoli file. Liquid Clustering ha rimosso il compromesso, consentendo il clustering per ora e le colonne identificative aggiuntive contemporaneamente, mantenendo dimensioni di file adeguate.
| Layout | |
|---|---|
| Prima | Partizionato per data,ora |
| Dopo | Raggruppato per date, hour, source, id |
I benchmark hanno mostrato miglioramenti massicci su 16 query di produzione rappresentative:
| Metrica | Prima (partizionata) | Dopo (Liquid) | Miglioramenti |
|---|---|---|---|
| Tempo di clock | 406s | 70s | Accelerazione di 5,9x |
| Byte letti | 3,5 TB | 0,48 TB | 86% in meno di byte letti |
Anche la tabella stessa è diventata più piccola. La dimensione totale è diminuita da 1,1 PB a 0,8 PB, una riduzione del 27% senza modifiche ai dati sottostanti. I file meglio raggruppati si comprimono in modo più efficiente e scompare la penalità dei file piccoli derivante dal sovra-partizionamento.
Cosa riserva il futuro per Liquid Clustering
Ottimizzazione delle join Liquid-to-Liquid: fino al 51% più veloci con l'87% di shuffle in meno
Oggi, l'unione di tabelle Liquid sulle loro colonne di clustering può richiedere uno shuffle completo dei dati, anche quando i dati sono già organizzati in base a tali colonne. Le join co-clusterizzate (ora in anteprima privata) rimuovono automaticamente tale shuffle. Su un benchmark di data warehousing reale, una join Liquid-to-Liquid è stata eseguita il ~51% più velocemente (28 minuti → 14 minuti) e ha effettuato l'87% di shuffle in meno di dati (1,2 TiB → 150 GiB) rispetto alla stessa query senza l'ottimizzazione.
Facile conversione Liquid di tabelle partizionate
In precedenza, la conversione di una tabella partizionata in Liquid Clustering richiedeva una riscrittura completa della tabella e modifiche che interrompevano le operazioni downstream con REPLACE TABLE o un cutover con scritture doppie e tempi di inattività pianificati. Stiamo introducendo un nuovo comando (ora in anteprima privata) che semplifica questa conversione, riducendo al minimo sia i tempi di inattività che le riscritture.
Iniziare con Liquid Clustering
Crea una tabella con Liquid Clustering:
Oppure, se stai utilizzando tabelle gestite da UC con Predictive Optimization, utilizza Automatic Liquid Clustering per selezionare in modo intelligente le chiavi di clustering in base al tuo carico di lavoro e ai pattern di query:
Liquid Clustering è il layout per il Lakehouse moderno. Provalo con la tua prossima tabella o contatta oggi stesso il tuo team di account per provare le anteprime private per la conversione da partizionato a Liquid e le join co-clusterizzate!
Non dimenticare di seguirci a DAIS!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.