Debito tecnico nascosto dei sistemi GenAI
I costi nascosti dell'IA generativa: gestione della proliferazione degli strumenti, delle pipeline opache e delle valutazioni soggettive
di Jeanne Choo e Conor Murphy
- Gli sviluppatori che lavorano su ML classico e IA generativa allocano il loro tempo in modo molto diverso
- L'IA generativa introduce nuove forme di debito tecnico che devono essere ripagate
- È necessario introdurre nuove pratiche di sviluppo per affrontare queste nuove forme di debito tecnico
Introduzione
Se confrontiamo in linea generale i flussi di lavoro del machine learning classico e dell'IA generativa, scopriamo che le fasi generali del flusso di lavoro rimangono simili tra i due. Entrambi richiedono la raccolta dei dati, la feature ingegneria, l'ottimizzazione del modello, il deployment, la valutazione, ecc., ma i dettagli di esecuzione e l'allocazione del tempo sono fondamentalmente diversi. L'aspetto più importante è che l'IA generativa introduce fonti uniche di debito tecnico che possono accumularsi rapidamente se non gestite correttamente, tra cui:
- Proliferazione degli strumenti - difficoltà a gestire e selezionare tra il numero crescente di strumenti per agenti
- Prompt stuffing - prompt eccessivamente complessi che diventano ingestibili
- Pipeline opache: la mancanza di un tracciamento adeguato rende difficile il debug
- Sistemi di feedback inadeguati - incapacità di acquisire e utilizzare in modo efficace il feedback umano
- Coinvolgimento insufficiente degli stakeholder: mancata comunicazione regolare con gli utenti finali
In questo blog, affronteremo una per una tutte le forme di debito tecnico. In definitiva, i team che passano dall'ML classico all'IA generativa devono essere consapevoli di queste nuove fonti di debito e adattare di conseguenza le loro pratiche di sviluppo, dedicando più tempo alla valutazione, alla gestione degli stakeholder, al monitoraggio soggettivo della qualità e alla strumentazione piuttosto che alla pulizia dei dati e all'ingegneria delle funzionalità che hanno dominato i progetti di ML classico.
In che modo i flussi di lavoro del Machine Learning (ML) classico e dell'AI generativa sono diversi?
Per apprezzare lo stato attuale del settore, è utile confrontare i nostri flussi di lavoro per l'IA generativa con quelli che utilizziamo per i problemi di machine learning classici. Quella che segue è una panoramica generale. Come rivela questo confronto, le fasi generali del flusso di lavoro rimangono le stesse, ma ci sono differenze nei dettagli di esecuzione che portano a porre l'accento su fasi diverse. Come vedremo, l'AI generativa introduce anche nuove forme di debito tecnico, che hanno implicazioni sul modo in cui manteniamo i nostri sistemi in produzione.
| Passaggio del flusso di lavoro | ML classico | AI generativa |
|---|---|---|
| Raccolta dei dati | I dati raccolti rappresentano eventi del mondo reale, come le vendite al dettaglio o i guasti alle apparecchiature. Vengono spesso utilizzati formati strutturati, come CSV e JSON. | I dati raccolti rappresentano la conoscenza contestuale che aiuta un modello linguistico a fornire risposte pertinenti. È possibile utilizzare sia dati strutturati (spesso in tabelle in tempo reale) sia dati non strutturati (immagini, video, file di testo). |
| Ingegneria delle feature/ Trasformazione dei dati | Le fasi di trasformazione dei dati comprendono la creazione di nuove feature per riflettere meglio lo spazio del problema (ad es. creando feature per i giorni feriali e per il fine settimana a partire dai dati di timestamp) o l'esecuzione di trasformazioni statistiche in modo che i modelli si adattino meglio ai dati (ad es. standardizzando le variabili continue per il clustering k-means e applicando una trasformazione log ai dati asimmetrici in modo che seguano una distribuzione normale). | Per i dati non strutturati, la trasformazione comporta il chunking, la creazione di rappresentazioni di embedding e (eventualmente) l'aggiunta di metadati come intestazioni e tag ai chunk. Per i dati strutturati, potrebbe essere necessario denormalizzare le tabelle in modo che i modelli linguistici di grandi dimensioni (LLM) non debbano considerare i join delle tabelle. È anche importante aggiungere le descrizioni dei metadati per tabelle e colonne. |
| Progettazione della pipeline del modello | Generalmente si tratta di una pipeline di base con tre passaggi:
| Di solito comporta una fase di riscrittura della query, una qualche forma di recupero delle informazioni, eventualmente la chiamata a strumenti e controlli di sicurezza alla fine. Le pipeline sono molto più complesse, coinvolgono infrastrutture più complesse come database e integrazioni API e a volte vengono gestite con strutture simili a grafi. |
| Ottimizzazione del modello | L'ottimizzazione del modello comporta l'ottimizzazione degli iperparametri utilizzando metodi come la convalida incrociata, la ricerca a griglia e la ricerca casuale. | Mentre alcuni iperparametri, come temperatura, top-k e top-p, possono essere modificati, la maggior parte dello sforzo è dedicata al perfezionamento dei prompt per guidare il comportamento del modello. Poiché una catena LLM può comportare molti passaggi, un ingegnere AI può anche sperimentare la scomposizione di un'operazione complessa in componenti più piccoli. |
| Implementazione | I modelli sono molto più piccoli dei modelli di base come gli LLM. Intere applicazioni di ML possono essere ospitate su una CPU senza la necessità di GPU. Il versionamento, il monitoraggio e il lignaggio del modello sono considerazioni importanti. Le previsioni del modello raramente richiedono catene o grafi complessi, quindi le tracce di solito non vengono utilizzate. | Poiché i modelli di base sono molto grandi, possono essere ospitati su una GPU centrale ed esposti come API a diverse applicazioni di IA rivolte agli utenti. Queste applicazioni agiscono come “wrapper” intorno all'API del modello di base e sono ospitate su CPU più piccole. La gestione delle versioni dell'applicazione, il monitoraggio e la derivazione sono considerazioni importanti. Inoltre, poiché le catene e i grafici degli LLM possono essere complessi, è necessaria una tracciatura adeguata per identificare i colli di bottiglia delle query e i bug. |
| Valutazione | Per le prestazioni del modello, i data scientist possono utilizzare metriche quantitative definite come il punteggio F1 per la classificazione o l'errore quadratico medio per la regressione. | La correttezza dell'output di un LLM si basa su giudizi soggettivi, ad esempio sulla qualità di un riassunto o di una traduzione. Pertanto, la qualità della risposta viene solitamente giudicata con linee guida piuttosto che con metriche quantitative. |
In che modo gli sviluppatori di Machine Learning allocano il loro tempo in modo diverso nei progetti di GenAI?
Per esperienza diretta nel bilanciare un progetto di previsione dei prezzi con un progetto per la creazione di un agente tool-calling, abbiamo riscontrato che ci sono alcune differenze importanti nelle fasi di sviluppo e deployment del modello.
Ciclo di sviluppo del modello
Per ciclo di sviluppo interno si intende in genere il processo iterativo che gli sviluppatori di machine learning seguono per creare e perfezionare le loro pipeline di modelli. Generalmente si verifica prima del test di produzione e del deployment del modello.
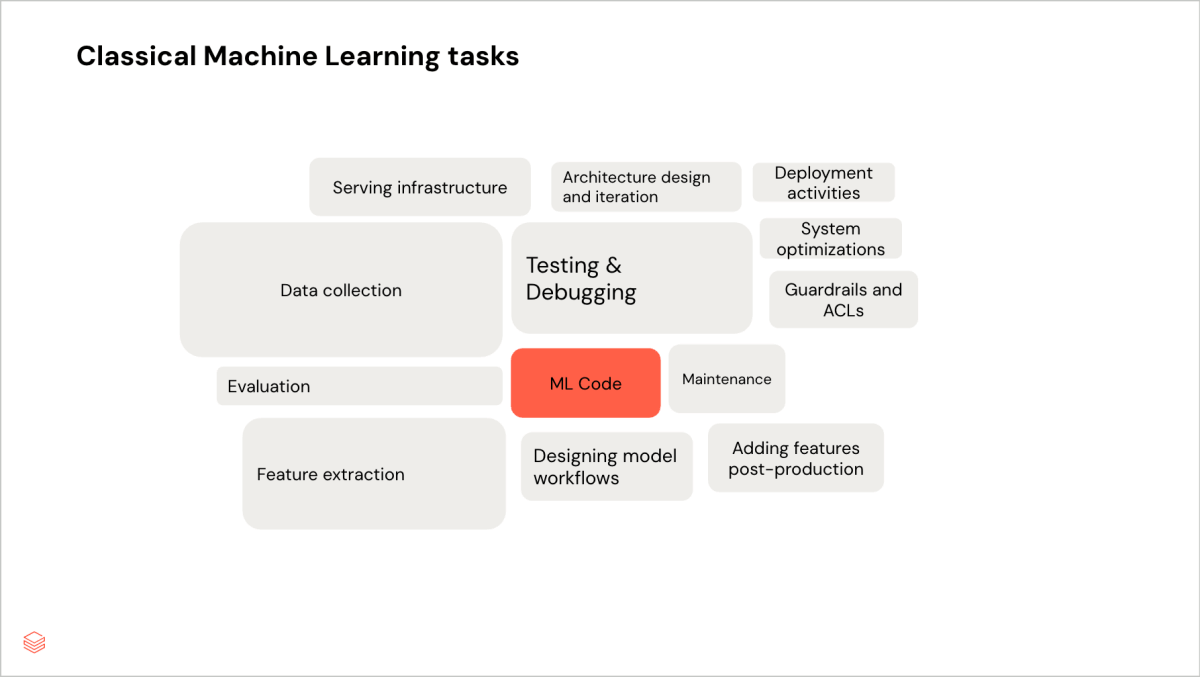
Ecco come i professionisti del ML classico e della GenAI impiegano il loro tempo in modo diverso in questa fase:
Perdite di tempo nello sviluppo di modelli di ML classici
- Raccolta dei dati e perfezionamento delle caratteristiche: in un progetto di machine learning classico, la maggior parte del tempo viene dedicata al perfezionamento iterativo delle caratteristiche e dei dati di input. Uno strumento per la gestione e la condivisione delle caratteristiche, come Databricks negozio di funzionalità, viene utilizzato quando sono coinvolti molti team o ci sono troppe caratteristiche per poterle gestire facilmente in modo manuale.
Al contrario, la valutazione è semplice: si esegue il modello e si verifica se c'è stato un miglioramento nelle metriche quantitative, prima di tornare a considerare come una migliore raccolta dei dati e delle caratteristiche possa migliorare il modello. Ad esempio, nel caso del nostro modello di previsione dei prezzi, il nostro team ha osservato che la maggior parte delle previsioni errate derivava da una mancata considerazione dei dati anomali. Abbiamo quindi dovuto considerare come includere caratteristiche che rappresentassero questi dati anomali, consentendo al modello di identificare tali pattern.
Perdite di tempo nello sviluppo di modelli e pipeline di IA generativa
- Valutazione: in un progetto di IA generativa, la ripartizione relativa del tempo tra la raccolta e la trasformazione dei dati e la valutazione è invertita. La raccolta dei dati consiste solitamente nel reperire un contesto sufficiente per il modello, che può essere sotto forma di documenti o manuali di una base di conoscenza non strutturata. Questi dati non richiedono una pulizia approfondita. Ma la valutazione è molto più soggettiva e complessa e, di conseguenza, richiede più tempo. Non solo si eseguono iterazioni sulla pipeline del modello, ma è anche necessario eseguire iterazioni sul set di valutazione. Inoltre, si dedica più tempo alla gestione dei casi limite rispetto al ML classico.
Ad esempio, un set iniziale di 10 domande di valutazione potrebbe non coprire l'intero spettro di domande che un utente potrebbe porre a un bot di supporto; in tal caso, sarà necessario raccogliere più valutazioni, oppure i giudici LLM impostati potrebbero essere troppo severi, per cui sarà necessario riformulare i loro prompt per evitare che le risposte pertinenti falliscano i test. I set di dati di valutazione di MLflow sono utili per il controllo delle versioni, lo sviluppo e l'audit di un "golden set" di esempi che devono funzionare sempre correttamente. - Gestione degli stakeholder: inoltre, poiché la qualità della risposta dipende dall'input dell'utente finale, gli ingegneri dedicano molto più tempo a incontrare gli utenti finali aziendali e i manager di prodotto per raccogliere i requisiti e definirne le priorità, nonché per eseguire iterazioni in base al feedback degli utenti. Storicamente, l'ML classico spesso non era rivolto a un vasto pubblico di utenti finali (ad es. previsioni di serie temporali) o era meno esposto a utenti non tecnici, quindi le esigenze di gestione del prodotto dell'AI generativa sono molto più elevate. La raccolta di feedback sulla qualità della risposta può essere effettuata tramite una semplice interfaccia utente ospitata su Databricks Apps che richiama l'API di feedback di MLflow. Il feedback può quindi essere aggiunto a un trace MLflow e a un set di dati di valutazione MLflow, creando un circolo virtuoso tra feedback e miglioramento del modello.
I diagrammi seguenti confrontano le allocazioni di tempo per l'ML classico e l'AI generativa per il ciclo di sviluppo del modello.

Ciclo di deployment del modello
A differenza del ciclo di sviluppo del modello, il ciclo di deployment del modello non si concentra sull'ottimizzazione delle prestazioni del modello. Gli ingegneri si concentrano invece su test sistematici, deployment e monitoraggio negli ambienti di produzione.
Qui, gli sviluppatori potrebbero spostare le configurazioni in file YAML per semplificare gli aggiornamenti del progetto. Potrebbero anche rifattorizzare le pipeline di elaborazione di dati statici per l'esecuzione in streaming, utilizzando un framework più robusto come PySpark anziché Pandas. Infine, devono considerare come impostare processi di test, monitoraggio e feedback per mantenere la qualità del modello.
A questo punto, l'automazione è essenziale e l'integrazione e la distribuzione continue sono un requisito non negoziabile. Per la gestione di CI/CD per progetti di dati e AI su Databricks, i Databricks Asset Bundles sono di solito lo strumento preferito. Permettono di descrivere le risorse di Databricks (come Job e pipeline) come file di origine e forniscono un modo per includere metadati accanto ai file di origine del progetto.
Come nella fase di sviluppo del modello, le attività che richiedono più tempo nei progetti di IA generativa rispetto a quelli di ML classico in questa fase non sono le stesse.
Perdite di tempo nell'implementazione di modelli di ML classici
- Refactoring: in un progetto di machine learning classico, il codice del notebook può essere piuttosto disordinato. Diverse combinazioni di set di dati, feature e modelli vengono continuamente testate, scartate e ricombinate. Di conseguenza, potrebbe essere necessario dedicare uno sforzo significativo al refactoring del codice del notebook per renderlo più robusto. Avere una struttura di cartelle predefinita per il repository di codice (come il template Databricks Asset Bundles MLOps Stacks) può fornire l'impalcatura necessaria per questo processo di refactoring.
Alcuni esempi di attività di refactoring includono:- Astrazione del codice ausiliario in funzioni
- Creazione di librerie di supporto in modo che le funzioni di utilità possano essere importate e riutilizzate più volte
- Spostamento delle configurazioni dai notebook ai file YAML
- Creazione di implementazioni di codice più efficienti che vengono eseguite in modo più rapido ed efficiente (ad esempio, rimuovendo i cicli
fornidificati)
- Monitoraggio della qualità: il monitoraggio della qualità è un'altra attività che richiede molto tempo, perché gli errori nei dati possono assumere molte forme ed essere difficili da rilevare. In particolare, come notano Shreya Shankar et al. nel loro articolo “Operationalizing Machine Learning: An Interview Study,” “gli errori soft, come alcune feature con valori nulli in un data point, sono meno dannosi e possono comunque produrre previsioni ragionevoli, rendendoli difficili da individuare e quantificare.” Inoltre, tipi diversi di errori richiedono risposte diverse e determinare la risposta appropriata non è sempre facile.
Un'ulteriore sfida è rappresentata dal fatto che diversi tipi di drift del modello (come il drift delle feature, il drift dei dati e il drift delle etichette) devono essere misurati con diverse granularità temporali (giornaliera, settimanale, mensile), il che aumenta la complessità. Per semplificare il processo, gli sviluppatori possono usare Databricks Data Quality monitoraggio per monitorare le metriche di qualità dei modelli, la qualità dei dati di input e il potenziale drift di input e previsioni dei modelli all'interno di un framework olistico.
Perdite di tempo nel deployment dei modelli di AI generativa
- Monitoraggio della qualità: con l'IA generativa, anche il monitoraggio richiede una notevole quantit�à di tempo, ma per motivi diversi:
- Requisiti in tempo reale: i progetti di machine learning classici per attività come la previsione dell'abbandono, la previsione dei prezzi o la riammissione dei pazienti possono fornire previsioni in modalità batch, con esecuzioni magari una volta al giorno, una volta alla settimana o una volta al mese. Tuttavia, molti progetti di IA generativa sono applicazioni in tempo reale, come agenti di supporto virtuali, agenti di trascrizione dal vivo o agenti di codifica. Di conseguenza, è necessario configurare strumenti di monitoraggio in tempo reale, il che significa monitoraggio degli endpoint in tempo reale, pipeline di analisi delle inferenze in tempo reale e avvisi in tempo reale.
L'impostazione di gateway API (come Databricks AI Gateway) per eseguire controlli di guardrail sull'API LLM può supportare i requisiti di sicurezza e privacy dei dati. Questo è un approccio diverso dal monitoraggio tradizionale dei modelli, che viene eseguito come processo offline. - Valutazioni soggettive: come accennato in precedenza, le valutazioni per le applicazioni di IA generativa sono soggettive. Gli ingegneri addetti al deployment dei modelli devono considerare come rendere operativa la raccolta di feedback soggettivo nelle loro pipeline di inferenza. Ciò potrebbe assumere la forma di valutazioni "LLM judge" eseguite sulle risposte del modello o della selezione di un sottoinsieme di risposte del modello da sottoporre alla valutazione di un esperto del settore. I fornitori di modelli proprietari ottimizzano i loro modelli nel tempo, quindi i loro "modelli" sono in realtà servizi soggetti a regressioni e i criteri di valutazione devono tenere conto del fatto che i pesi del modello non sono congelati come avviene nei modelli auto-addestrati.
La capacità di fornire feedback in formato libero e valutazioni soggettive assume un ruolo centrale. Framework come Databricks Apps e la MLflow Feedback API abilitano interfacce utente più semplici in grado di acquisire tale feedback e di collegarlo a chiamate LLM specifiche.
- Requisiti in tempo reale: i progetti di machine learning classici per attività come la previsione dell'abbandono, la previsione dei prezzi o la riammissione dei pazienti possono fornire previsioni in modalità batch, con esecuzioni magari una volta al giorno, una volta alla settimana o una volta al mese. Tuttavia, molti progetti di IA generativa sono applicazioni in tempo reale, come agenti di supporto virtuali, agenti di trascrizione dal vivo o agenti di codifica. Di conseguenza, è necessario configurare strumenti di monitoraggio in tempo reale, il che significa monitoraggio degli endpoint in tempo reale, pipeline di analisi delle inferenze in tempo reale e avvisi in tempo reale.
- Test: il test richiede spesso più tempo nelle applicazioni di AI generativa, per alcuni motivi:
- Sfide irrisolte: le applicazioni di IA generativa stesse stanno diventando sempre più complesse, ma i framework di valutazione e test non sono ancora al passo. Alcuni scenari che rendono i test impegnativi includono:
- Lunghe conversazioni a più turni
- Output SQL che può o meno cogliere dettagli importanti sul contesto organizzativo di un'impresa
- Tenere conto degli strumenti corretti utilizzati in una catena
- Valutazione di più agenti in un'applicazione
Il primo passo per gestire questa complessità è solitamente quello di catturare nel modo più accurato possibile una traccia dell'output dell'agente (una cronologia di esecuzione delle chiamate agli strumenti, del ragionamento e della risposta finale). Una combinazione di acquisizione automatica delle tracce e strumentazione manuale può fornire la flessibilità necessaria per coprire l'intera gamma di interazioni dell'agente. Ad esempio, il decoratoretracedi MLflow Traces può essere utilizzato su qualsiasi funzione per catturare i suoi input e output. Allo stesso tempo, possono essere creati span personalizzati di MLflow Traces all'interno di blocchi di codice specifici per registrare attività operative più granulari. Solo dopo aver utilizzato la strumentazione per aggregare una fonte di verità affidabile dagli output dell'agente, gli sviluppatori possono iniziare a identificare le modalità di guasto e a progettare test di conseguenza.
- Incorporare il feedback umano: è fondamentale integrare questo input nella valutazione della qualità. Tuttavia, alcune attività richiedono molto tempo. Ad esempio:
- Progettazione di rubriche in modo che gli annotatori abbiano linee guida da seguire
- Progettazione di metriche e giudici diversi per scenari diversi (ad esempio, se un output è sicuro o utile)
Di solito sono necessarie discussioni e workshop in presenza per creare una rubrica condivisa su come ci si aspetta che un agente risponda. Solo dopo che gli annotatori umani sono allineati, le loro valutazioni possono essere integrate in modo affidabile nei giudici basati su LLM, utilizzando funzioni come l'APImake_judgedi MLflow oSIMBAAlignmentOptimizer.
- Sfide irrisolte: le applicazioni di IA generativa stesse stanno diventando sempre più complesse, ma i framework di valutazione e test non sono ancora al passo. Alcuni scenari che rendono i test impegnativi includono:
Debito tecnico dell'AI
Il debito tecnico si accumula quando gli sviluppatori implementano una soluzione rapida e approssimativa a scapito della manutenibilità a lungo termine.
Debito tecnico dell'ML classico
Dan Sculley et al. hanno fornito un ottimo riepilogo dei tipi di debito tecnico che questi sistemi possono accumulare. Nel loro articolo “Machine Learning: The High-Interest Credit Card of Technical Debt,” questi vengono suddivisi in tre aree generali:
- Debito di dati Dipendenze dei dati scarsamente documentate, non considerate o che cambiano silenziosamente
- Debito a livello di sistema: codice collante esteso, "giungle" di pipeline e percorsi "morti" hardcoded
- Cambiamenti esterni Soglie modificate (come la soglia di precisione-richiamo) o rimozione di correlazioni precedentemente importanti
L'AI generativa introduce nuove forme di debito tecnico, molte delle quali potrebbero non essere evidenti. Questa sezione esplora le fonti di questo debito tecnico nascosto.
Proliferazione degli strumenti
Gli strumenti sono un modo potente per estendere le capacità di un LLM. Tuttavia, con l'aumentare del numero di strumenti utilizzati, la loro gestione può diventare difficile.
La proliferazione degli strumenti non rappresenta solo un problema di individuabilità e riutilizzo, ma può anche influire negativamente sulla qualità di un sistema di IA generativa. Quando gli strumenti proliferano, emergono due punti critici di fallimento:
- Selezione dello strumento: L'LLM deve essere in grado di selezionare correttamente lo strumento giusto da chiamare da una vasta gamma di strumenti. Se gli strumenti svolgono funzioni approssimativamente simili, come chiamare APIs di dati per statistiche di vendite settimanali anziché mensili, assicurarsi che venga chiamato lo strumento giusto diventa difficile. Gli LLM inizieranno a commettere errori.
- Parametri dello strumento: anche dopo aver selezionato con successo lo strumento giusto da richiamare, un LLM deve comunque essere in grado di analizzare la domanda di un utente e trasformarla nel set corretto di parametri da passare allo strumento. Questo è un altro punto di errore di cui tenere conto e diventa particolarmente difficile quando più strumenti hanno strutture di parametri simili.
La soluzione più pulita per la proliferazione degli strumenti è essere strategici e minimali con gli strumenti che un team utilizza.
Tuttavia, la giusta strategia di governance può contribuire a rendere scalabile la gestione di più strumenti e accessi man mano che sempre più team integrano la GenAI nei loro progetti e sistemi. I prodotti Databricks Unity Catalog e AI Gateway sono realizzati per questo tipo di Scale.
Prompt stuffing
Anche se i modelli all'avanguardia possono gestire pagine di istruzioni, i prompt eccessivamente complessi possono introdurre problemi come istruzioni contraddittorie o informazioni non aggiornate. Ciò vale soprattutto quando i prompt non vengono modificati, ma semplicemente aggiunti nel tempo da diversi esperti di dominio o sviluppatori.
Quando si presentano diverse modalità di errore o quando nuove query vengono aggiunte all'ambito, si è tentati di continuare ad aggiungere sempre più istruzioni a un prompt LLM. Ad esempio, un prompt potrebbe iniziare fornendo istruzioni per gestire le domande relative alla finanza, per poi estendersi alle domande relative a prodotti, ingegneria e risorse umane.
Così come una "god class" nell'ingegneria del software non è una buona idea e dovrebbe essere scomposta, i mega-prompt dovrebbero essere suddivisi in prompt più piccoli. Infatti, Anthropic lo menziona nella sua guida all'ingegneria dei prompt e, come regola generale, avere più prompt piccoli piuttosto che uno lungo e complesso aiuta a migliorare chiarezza, accuratezza e risoluzione dei problemi.
I framework possono aiutare a mantenere i prompt gestibili tenendo traccia delle versioni dei prompt e garantendo gli input e gli output previsti. Un esempio di strumento di controllo delle versioni dei prompt è MLflow Prompt Registry, mentre ottimizzatori di prompt come DSPy, eseguibile su Databricks, consentono di scomporre un prompt in moduli autonomi che possono essere ottimizzati singolarmente o nel loro complesso.
Pipeline opache
C'è un motivo per cui il tracciamento ha ricevuto attenzione ultimamente: la maggior parte delle librerie LLM e degli strumenti di monitoraggio offre la possibilità di tracciare gli input e gli output di una catena LLM. Quando una risposta restituisce un errore (il temuto "Mi dispiace, non posso rispondere alla tua domanda"), esaminare gli input e gli output delle chiamate LLM intermedie è fondamentale per individuare la causa principale.
Una volta ho lavorato su un'applicazione in cui inizialmente pensavo che la generazione di SQL sarebbe stata la fase più problematica del flusso di lavoro. Tuttavia, l'analisi delle tracce ha rivelato una situazione diversa: la principale fonte di errori era in realtà una fase di riscrittura della query, in cui aggiornavamo le entità nella domanda dell'utente per farle corrispondere ai valori del nostro database. L'LLM riscriveva le query che non necessitavano di riscrittura o iniziava a riempire la query originale con ogni sorta di informazioni aggiuntive. Questo, a sua volta, comprometteva regolarmente il successivo processo di generazione di SQL. In questo caso, il tracciamento ha permesso di identificare rapidamente il problema.
La tracciatura delle chiamate LLM corrette può richiedere tempo. Non è sufficiente implementare la tracciatura pronta all'uso. Instrumentare correttamente un'app con l'osservabilità, utilizzando un framework come MLflow Traces, è un primo passo per rendere le interazioni dell'agente più trasparenti.
Sistemi inadeguati per l'acquisizione e l'utilizzo del feedback umano
Gli LLM sono straordinari perché è possibile passare loro alcuni semplici prompt, concatenare i risultati e ottenere qualcosa che sembra comprendere molto bene le sfumature e le istruzioni. Ma se ci si spinge troppo in là su questa strada senza basare le risposte sul feedback degli utenti, il debito di qualità può accumularsi rapidamente. È qui che può essere d'aiuto la creazione, il prima possibile, di un "volano di dati", che consiste in tre fasi:
- Decidere le metriche di successo
- Automatizzare la misurazione di queste metriche, magari tramite un'interfaccia utente (UI) che gli utenti possono utilizzare per fornire feedback su ciò che funziona
- Regolare in modo iterativo i prompt o le pipeline per migliorare le metriche
Mi è stata ricordata l'importanza del feedback umano durante lo sviluppo di un'applicazione text-to-SQL per query le statistiche sportive. L'esperto di settore ha spiegato come un appassionato di sport vorrebbe interagire con i dati, chiarendo cosa gli starebbe a cuore e fornendo altre informazioni dettagliate a cui io, che raramente guardo lo sport, non avrei mai pensato. Senza il suo contributo, l'applicazione che ho creato probabilmente non avrebbe soddisfatto le esigenze degli utenti.
Sebbene la raccolta del feedback umano sia preziosissima, di solito richiede un'enorme quantità di tempo. Innanzitutto, è necessario pianificare del tempo con gli esperti del settore, poi creare rubriche di valutazione per riconciliare le differenze tra gli esperti e infine valutare il feedback per apportare miglioramenti. Se l'interfaccia utente di feedback è ospitata in un ambiente a cui gli utenti aziendali non possono accedere, confrontarsi con gli amministratori IT per fornire il giusto livello di accesso può sembrare un processo interminabile.
Sviluppare senza verifiche regolari con gli stakeholder
Consultare regolarmente gli utenti finali, gli sponsor aziendali e i team adiacenti per verificare che si stia costruendo la cosa giusta è la base per qualsiasi tipo di progetto. Tuttavia, con i progetti di AI generativa, la comunicazione con gli stakeholder è più cruciale che mai.
Perché una comunicazione frequente e diretta è importante:
- Responsabilità e controllo: riunioni regolari aiutano gli stakeholder a sentire di avere un modo per influenzare la qualità finale di un'applicazione. Invece di essere critici, possono diventare collaboratori. Naturalmente, non tutti i feedback hanno lo stesso valore. Alcuni stakeholder inizieranno inevitabilmente a richiedere cose che sono premature da implementare per un MVP o che vanno oltre ciò che gli LLM possono attualmente gestire. È importante negoziare e informare tutti su ciò che può e non può essere realizzato. In caso contrario, può sorgere un altro rischio: troppe richieste di funzionalità senza alcun freno.
- Non sappiamo quello che non sappiamo: l'AI generativa è così nuova che la maggior parte delle persone, sia tecniche che non, non sa cosa un LLM può e non può gestire correttamente. Sviluppare un'applicazione LLM è un percorso di apprendimento per tutti i soggetti coinvolti, e i punti di contatto regolari sono un modo per tenere tutti informati.
Esistono molte altre forme di debito tecnico che potrebbero dover essere affrontate nei progetti di IA generativa, tra cui l'applicazione di controlli adeguati sull'accesso ai dati, l'implementazione di meccanismi di protezione per gestire la sicurezza e prevenire le prompt injection, evitare che i costi vadano fuori controllo e altro ancora. Ho incluso solo quelli che sembrano più importanti in questo contesto e che potrebbero essere facilmente trascurati.
Conclusione
L'ML classico e l'AI generativa sono diverse varianti dello stesso dominio tecnico. Sebbene sia importante essere consapevoli delle differenze tra loro e considerare l'impatto di queste differenze su come costruiamo e manteniamo le nostre soluzioni, alcune verità restano immutate: la comunicazione colma ancora le lacune, il monitoraggio previene ancora le catastrofi e i sistemi puliti e manutenibili a lungo termine superano ancora in prestazioni quelli caotici.
Vuoi valutare la maturità dell'IA della tua organizzazione? Leggi la nostra guida: Sblocca il valore dell'AI: la guida aziendale per la preparazione all'AI.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.