Feature Flagging ad alta disponibilità in Databricks
Come abbiamo creato un sistema di feature flag a zero downtime per l'infrastruttura globale di Databricks
- SAFE è la piattaforma di feature flagging interna di Databricks che consente agli ingegneri di disaccoppiare l'implementazione del codice dall'abilitazione delle funzionalità, permettendo rollout più sicuri e una più rapida mitigazione degli incidenti su centinaia di servizi
- Questo post descrive l'architettura di SAFE, che gestisce >25.000 flag attivi e oltre 300 milioni di valutazioni al secondo con latenza su scala dei microsecondi attraverso tecniche come la pre-valutazione della dimensione statica e la distribuzione globale a più livelli.
- Il sistema raggiunge un'elevata affidabilità attraverso meccanismi di resilienza stratificati, tra cui il comportamento fail-static, i percorsi di distribuzione out-of-band e i pacchetti di configurazione di avvio a freddo (cold-start) che assicurano che i servizi continuino a funzionare anche durante i guasti della pipeline di distribuzione.
Rilasciare software rapidamente mantenendo al contempo l'affidabilità è una tensione costante. Con la crescita di Databricks, è aumentata anche la complessità di implementare in modo sicuro le modifiche su centinaia di servizi, più cloud e migliaia di carichi di lavoro dei clienti. I feature flag ci aiutano a gestire questa complessità separando la decisione di distribuire il codice dalla decisione di attivarlo. Questa separazione consente agli ingegneri di isolare i guasti e mitigare gli incidenti più rapidamente, senza sacrificare la velocità di rilascio.
Uno dei componenti chiave della strategia di stabilità di Databricks è la nostra piattaforma interna di sperimentazione e feature flagging, chiamata "SAFE". Gli ingegneri di Databricks utilizzano SAFE quotidianamente per il rollout di funzionalità, per controllare dinamicamente il comportamento dei servizi e per misurare l'efficacia delle loro funzionalità con esperimenti A/B.
Sfondo
SAFE è iniziato con l'obiettivo primario di disaccoppiare completamente le release dei binari dei servizi dall'abilitazione delle funzionalità, consentendo ai team di implementare le funzionalità indipendentemente dalla distribuzione dei binari. Questo offre molti vantaggi collaterali, come la possibilità di estendere in modo affidabile una funzionalità a un numero progressivamente maggiore di utenti e di mitigare rapidamente gli incidenti causati da un'implementazione.
Su una scala come quella di Databricks, servendo migliaia di clienti enterprise su più cloud con un'area di prodotto in rapida crescita, avevamo bisogno di un sistema di feature flag che potesse soddisfare i nostri requisiti unici:
- Standard elevati per la sicurezza e la gestione delle modifiche. La principale proposta di valore di SAFE era migliorare la stabilità e la posizione operativa di Databricks, quindi quasi tutti gli altri requisiti ne sono derivati.
- Distribuzione globale multi-cloud e trasparente su Azure, AWS e GCP, con una latenza di valutazione dei flag inferiore al millisecondo per supportare servizi di produzione ad alto throughput e sensibili alla latenza.
- Supporto trasparente per tutti gli ambienti in cui gli ingegneri di Databricks scrivono codice, inclusi il nostro piano di controllo, l'interfaccia utente di Databricks, Databricks Runtime Environment e il data plane Serverless di Databricks.
- Un'interfaccia sufficientemente strutturata riguardo alle pratiche di rilascio di Databricks per rendere i rilasci di flag comuni "sicuri per default", ma abbastanza flessibile da supportare un'ampia gamma di casi d'uso più specifici.
- Requisiti di disponibilità estremamente rigorosi, in quanto i servizi non possono avviarsi in sicurezza senza che le definizioni dei flag siano state caricate.
Dopo un'attenta valutazione di questi requisiti, abbiamo infine optato per la creazione di un sistema di feature flagging personalizzato e interno. Avevamo bisogno di una soluzione che potesse evolversi insieme alla nostra architettura e che fornisse i controlli di governance necessari per gestire in sicurezza i flag su centinaia di servizi e migliaia di ingegneri. Raggiungere con successo i nostri obiettivi di scalabilità e sicurezza ha richiesto una profonda integrazione con il nostro modello di dati dell'infrastruttura, i framework dei servizi e i sistemi CI.
A fine 2025, SAFE ha circa 25.000 flag attivi, con 4.000 attivazioni di flag a settimana. Nei momenti di picco, SAFE esegue oltre 300 milioni di valutazioni al secondo, mantenendo una latenza p95 di circa 10μs per le valutazioni dei flag.
Questo post esplora come abbiamo creato SAFE per soddisfare questi requisiti e le lezioni che abbiamo appreso lungo il percorso.
Feature flag in azione
Per iniziare, discuteremo un tipico percorso utente per un flag SAFE. In sostanza, un feature flag è una variabile a cui si può accedere nel flusso di controllo di un servizio e che può assumere valori diversi a seconda delle condizioni controllate da una configurazione esterna. Un caso d'uso estremamente comune per i feature flag è l'abilitazione graduale di un nuovo percorso del codice in modo controllato, partendo prima da una piccola porzione di traffico per poi abilitarlo gradualmente a livello globale.
Gli utenti di SAFE iniziano definendo il loro flag nel codice del servizio e lo utilizzano come gate condizionale per la logica della nuova funzionalità:
L'utente quindi accede all'interfaccia utente interna di SAFE, registra questo flag e seleziona un template per eseguirne il rollout. Questo template definisce un piano di implementazione graduale costituito da un elenco di fasi ordinate. Ogni fase viene incrementata lentamente in percentuale. Una volta creato il flag, all'utente viene presentata un'interfaccia utente simile a questa:
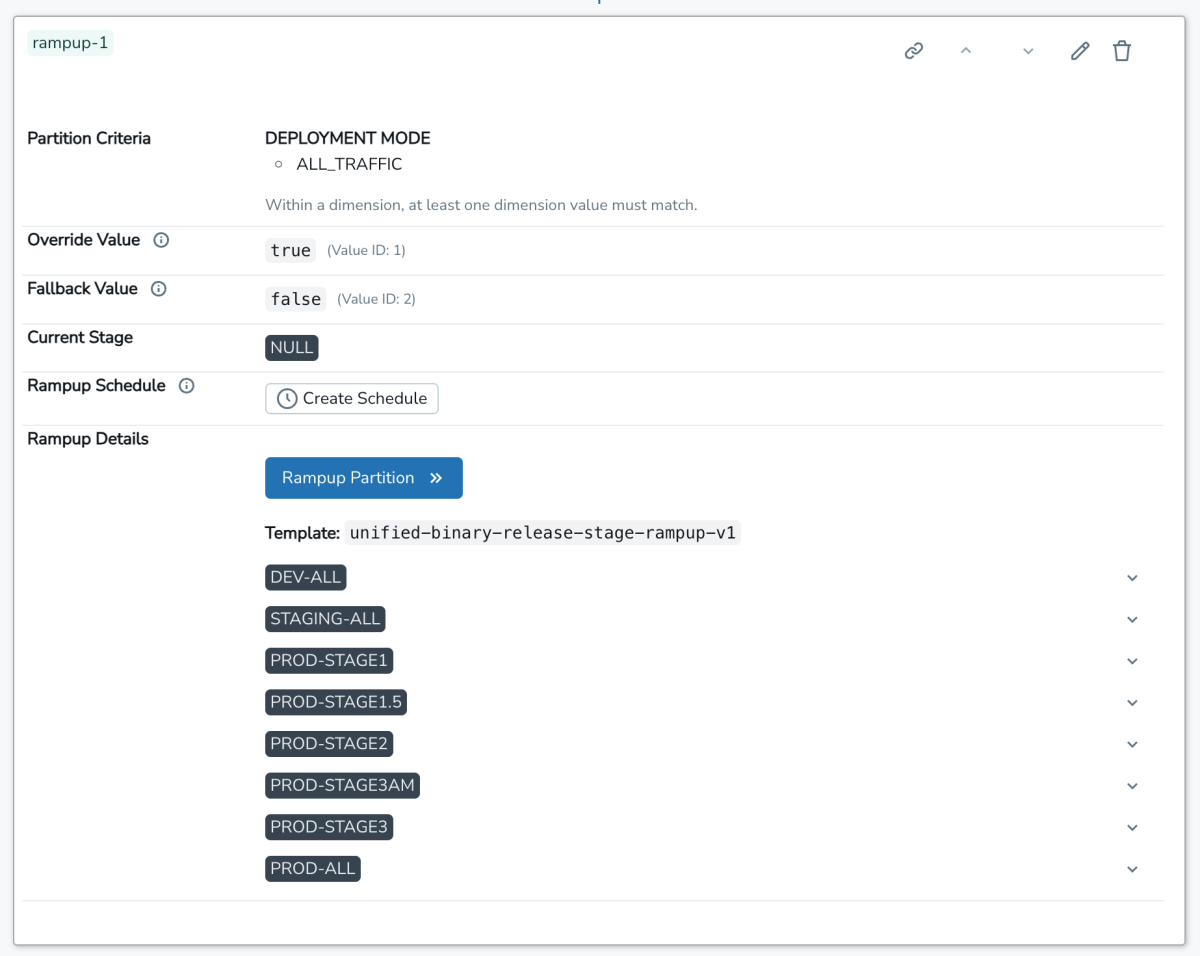
Da qui, l'utente può implementare manualmente il proprio flag una fase alla volta o impostare una pianificazione per la creazione automatica dei cambi di stato dei flag. Internamente, la fonte di verità per la configurazione dei flag è un file jsonnet archiviato nel monorepo di Databricks, che utilizza un leggero linguaggio specifico del dominio (DSL) per gestire la configurazione dei flag:
Quando gli utenti modificano un flag dall'interfaccia utente, l'output di tale modifica è una Pull Request che deve essere revisionata da almeno un altro ingegnere. SAFE esegue anche una serie di controlli pre-merge per proteggersi da modifiche non sicure o non intenzionali. Una volta eseguito il merge della modifica, il servizio dell'utente recepirà la modifica e inizierà a emettere il nuovo valore entro 2-5 minuti dal merge della PR.
Casi d'uso
Oltre al caso d'uso descritto sopra per l'implementazione delle funzionalità, SAFE viene utilizzato anche per altri aspetti della configurazione dinamica dei servizi, come: configurazioni dinamiche di lunga durata (ad es. timeout o limiti di velocità), controllo della macchina a stati per le migrazioni dell'infrastruttura o per distribuire piccoli blob di configurazione (ad es. criteri di logging mirati).
Architettura
Librerie client
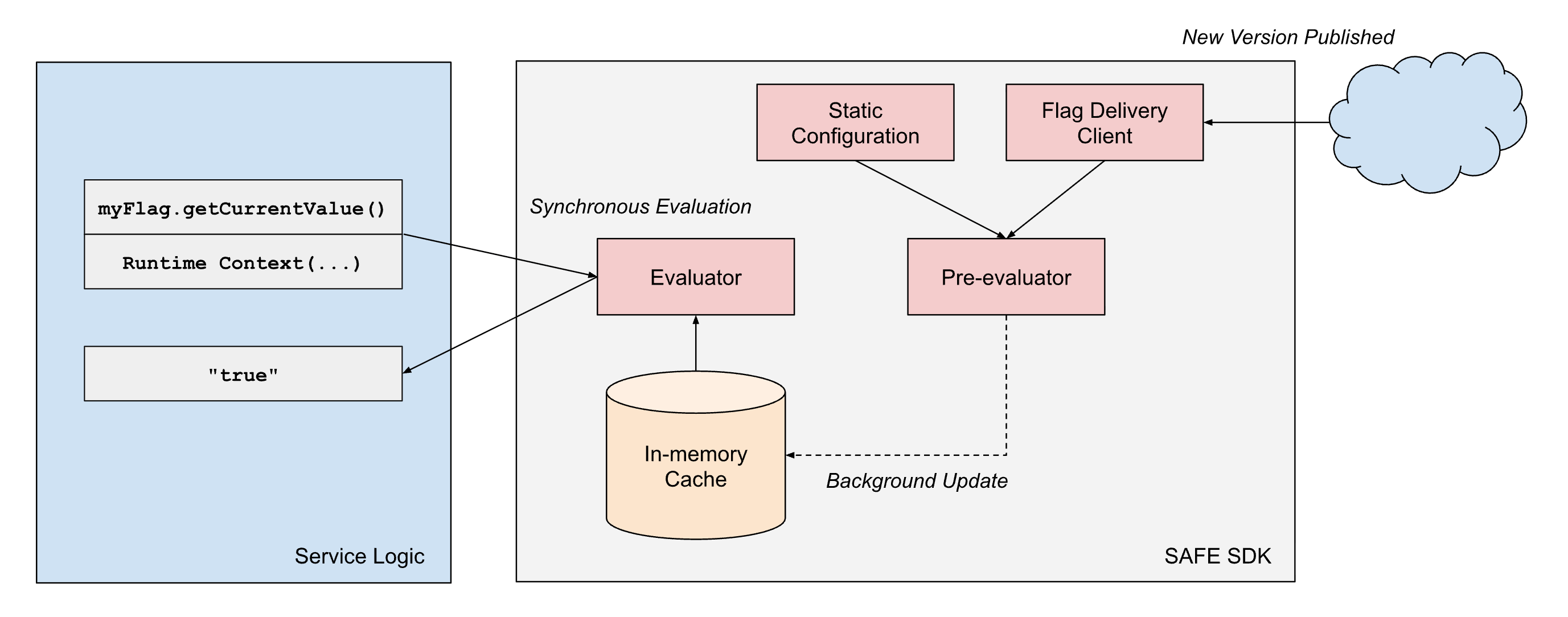
SAFE fornisce "SDK" client in più linguaggi supportati internamente; l'SDK di Scala è il più maturo e ampiamente adottato. L'SDK è essenzialmente una libreria di valutazione dei criteri, combinata con un componente di caricamento della configurazione. Per ogni flag, esiste un set di criteri che controllano quale valore l'SDK deve restituire in fase di esecuzione. L'SDK gestisce il caricamento del set di configurazione più recente e deve restituire rapidamente il risultato della valutazione di tali criteri in fase di esecuzione.
In pseudocodice, i criteri si presentano internamente così:
I criteri possono essere modellati come una sorta di sequenza di alberi di espressioni booleane. Ogni espressione condizionale deve essere valutata in modo efficiente per restituire rapidamente un risultato.
Per soddisfare i nostri requisiti di prestazioni, la progettazione dell'SDK di SAFE si basa su alcuni principi architetturali: (1) separazione tra la distribuzione della configurazione e la valutazione e (2) separazione tra le dimensioni di valutazione statiche e di runtime.
- Separazione della distribuzione dalla valutazione: le librerie client di SAFE trattano sempre la distribuzione come un processo asincrono e non bloccano mai il "percorso critico" (hot path) della valutazione del flag sulla distribuzione della configurazione. Una volta che il client dispone di uno snapshot della configurazione di un flag, continuerà a restituire risultati basati su tale snapshot fino a quando un processo asincrono in background non eseguirà un aggiornamento atomico di tale snapshot a uno più recente.
- Separazione dei tipi di dimensione: la valutazione dei flag in SAFE opera su due tipi di dimensioni:
- Dimensioni statiche: rappresentano le caratteristiche del binario in esecuzione, come il provider cloud, la regione cloud e l'ambiente (dev/staging/prod). Questi valori rimangono costanti per tutta la durata di un processo.
- Runtime dimensions: acquisiscono il contesto specifico della richiesta, come ID workspace, ID dell'account, valori forniti dall'applicazione e altri attributi per richiesta che variano a ogni valutazione.
Per ottenere in modo affidabile una latenza di valutazione inferiore al millisecondo su larga scala, SAFE impiega la prevalutazione delle parti statiche dell'albero delle espressioni booleane. Quando un pacchetto di configurazione SAFE viene distribuito a un servizio, l'SDK valuta immediatamente tutte le dimensioni statiche rispetto alla rappresentazione in memoria della configurazione del flag. Questo produce un albero di configurazione semplificato che contiene solo la logica pertinente a quella specifica istanza del servizio.
Quando viene richiesta una valutazione del flag durante l'elaborazione della richiesta, l'SDK deve solo valutare le dimensioni di runtime rimanenti rispetto a questa configurazione precompilata. Ciò riduce in modo significativo il costo computazionale di ogni valutazione. Poiché molti flag utilizzano solo dimensioni statiche nei loro alberi di espressioni booleane, molti di essi possono essere di fatto interamente prevalutati.
Distribuzione dei flag
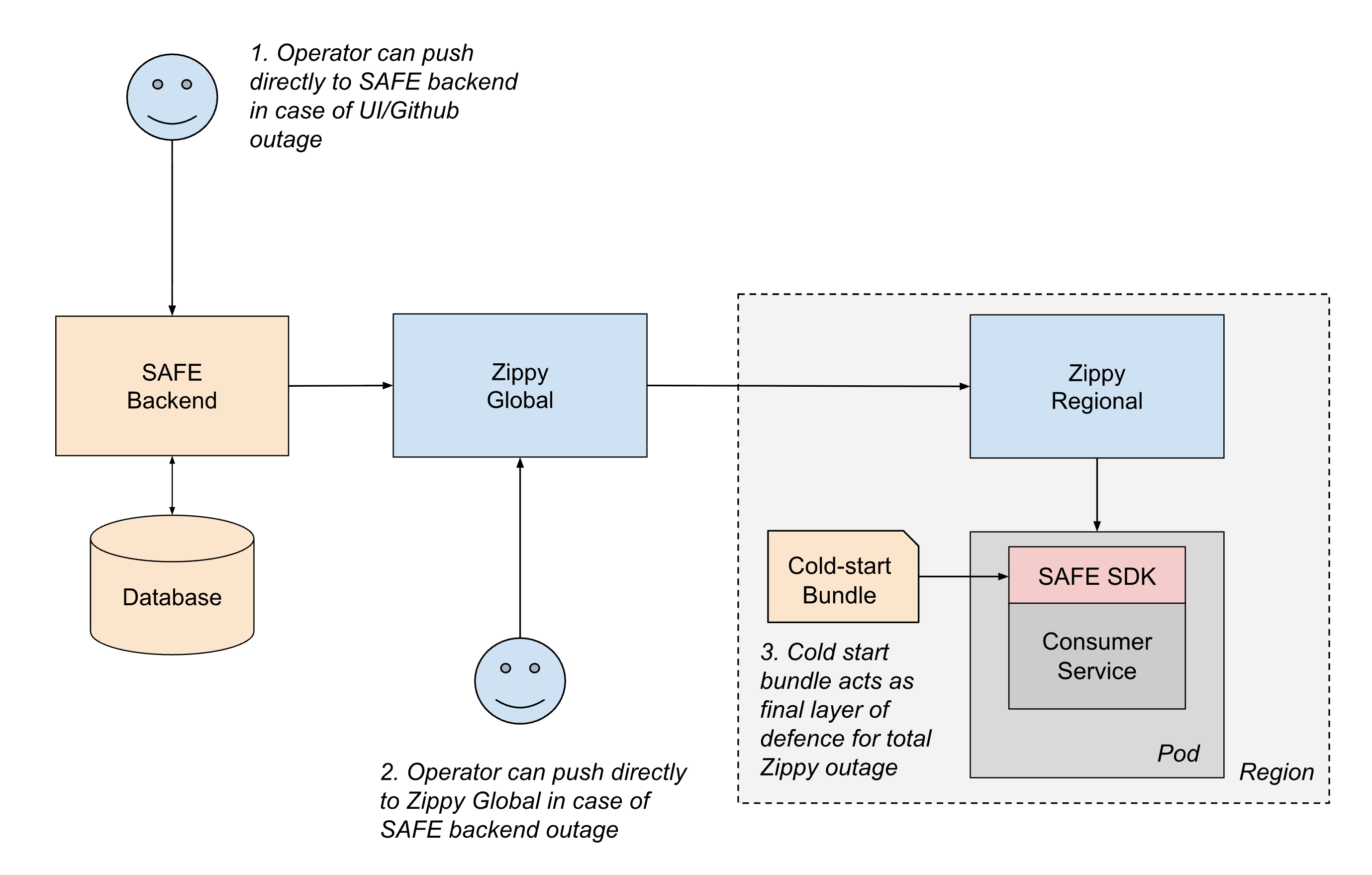
Per distribuire in modo affidabile la configurazione a tutti i servizi di Databricks, SAFE opera in stretta collaborazione con Zippy, la nostra piattaforma interna di distribuzione dinamica della configurazione. Una descrizione approfondita dell'architettura di Zippy è un argomento per un altro post ma, in breve, Zippy utilizza un'architettura globale/regionale a più livelli e uno storage BLOB per ogni cloud per trasportare BLOB di configurazione arbitrari da una fonte centrale a (tra le altre superfici) tutti i pod Kubernetes in esecuzione nel piano di controllo di Databricks.
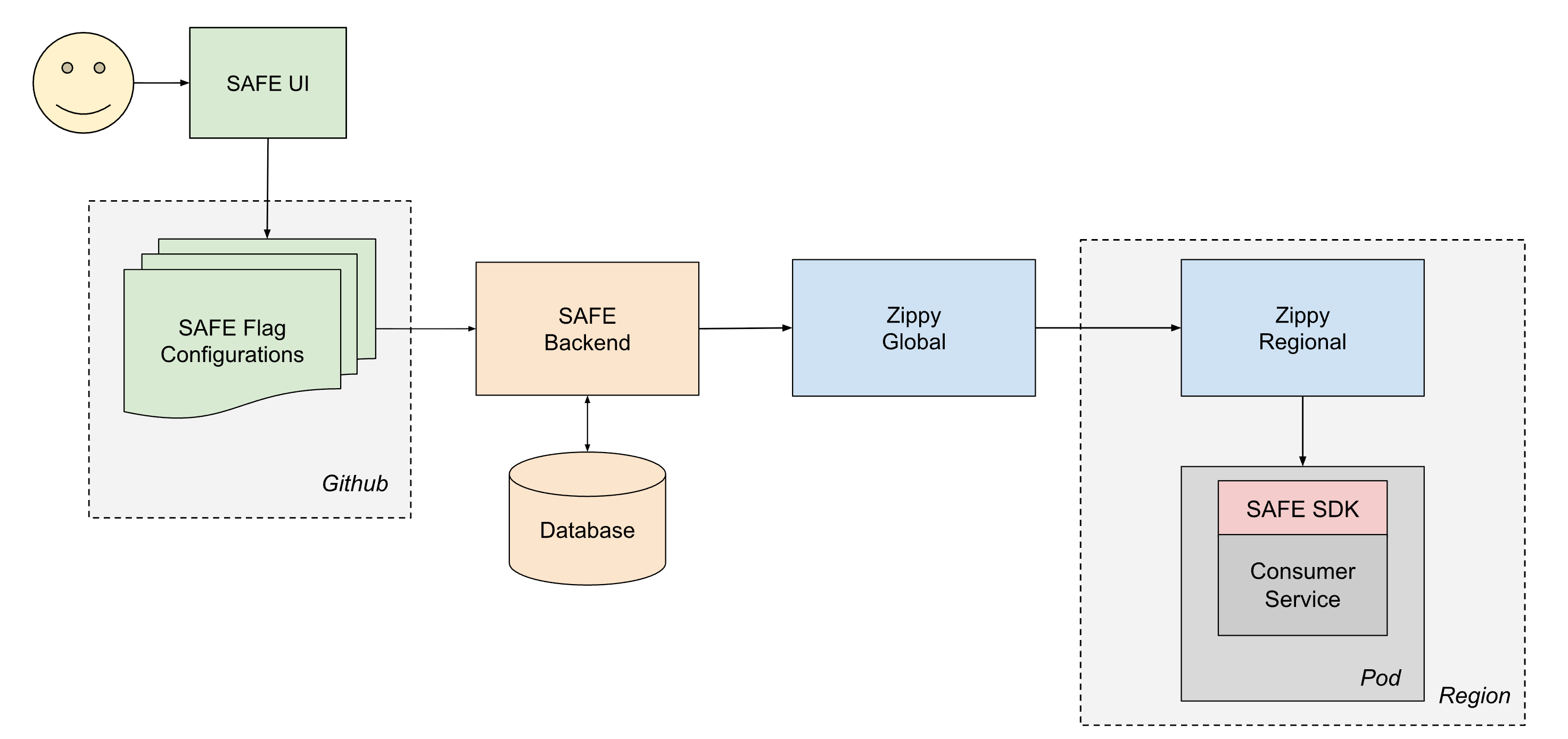
Il ciclo di vita di un flag distribuito è il seguente:
- Un utente crea e fa il Merge di una PR in uno dei suoi file jsonnet di configurazione dei flag, che viene quindi Merge-ata nel monorepo di Databricks in Github.
- Entro circa 1 minuto, un CI post-merge job preleva il file modificato e lo invia al backend di SAFE, che successivamente archivia una copia della nuova configurazione in un database.
- Periodicamente (a intervalli di circa 1 minuto), il backend SAFE raggruppa tutte le configurazioni dei flag SAFE e le invia al backend Zippy Global.
- Zippy Global distribuisce queste configurazioni a ciascuna delle sue istanze Zippy Regional, in circa 30 secondi.
- L'SDK SAFE, in esecuzione in ogni pod di servizio, riceve periodicamente i nuovi bundle di versione utilizzando una combinazione di distribuzione basata su push e pull.
- Una volta distribuita, il SAFE SDK può utilizzare la nuova configurazione durante la valutazione.
End-to-end, la modifica di un flag si propaga in genere a tutti i servizi entro 3-5 minuti dal merge di una PR.
Pipeline di configurazione dei flag
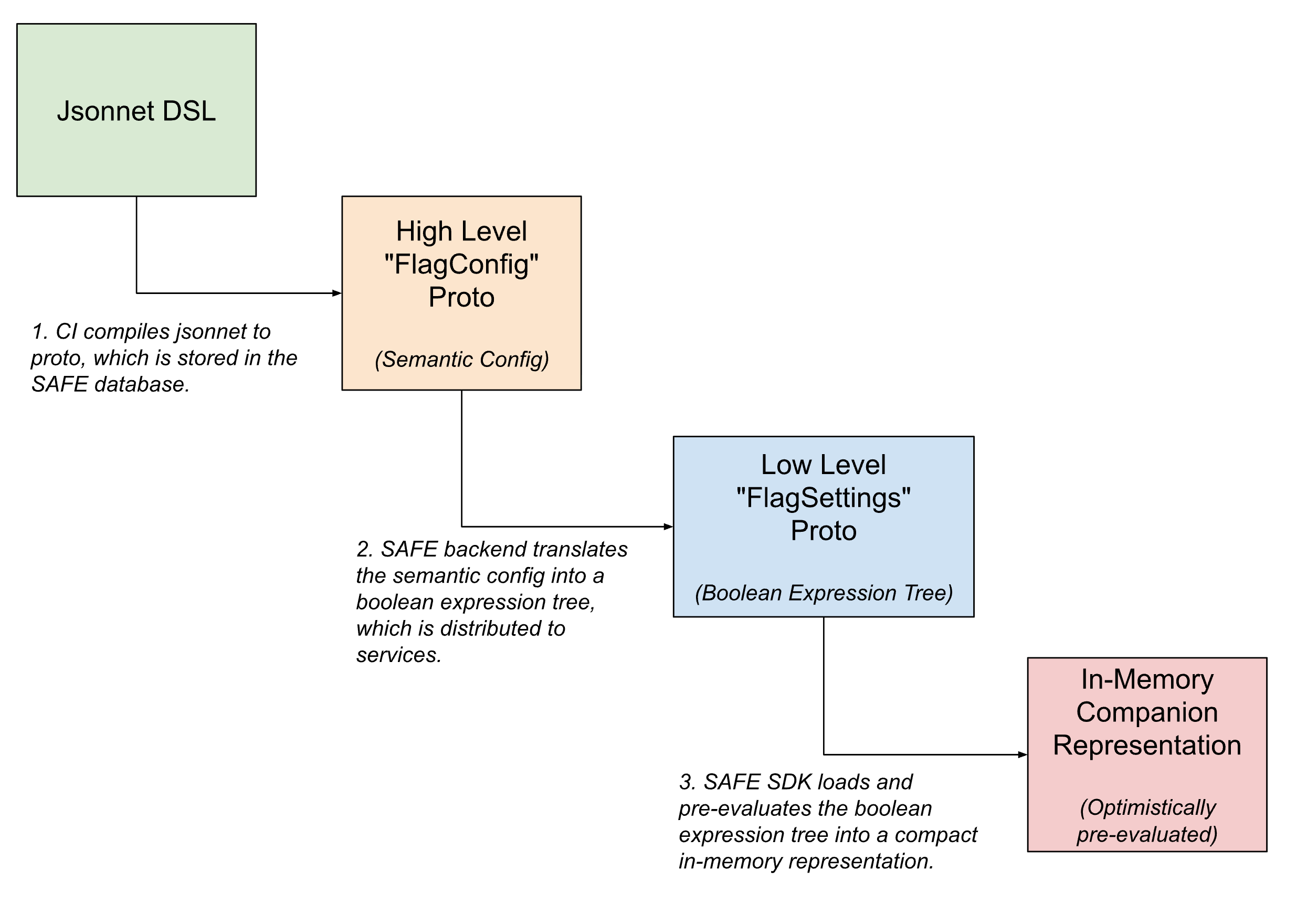
All'interno della pipeline di distribuzione dei flag, le configurazioni dei flag assumono molteplici forme, venendo progressivamente tradotte da configurazioni semantiche di alto livello leggibili dall'uomo a versioni compatte leggibili dalla macchina man mano che il flag si avvicina alla valutazione.
Nell'interfaccia utente, i flag sono definiti utilizzando Jsonnet con un DSL personalizzato per consentire configurazioni dei flag arbitrariamente complesse. Questo DSL prevede funzionalità per i casi d'uso comuni, come la configurazione di un flag per il rollout tramite un template predefinito o l'impostazione di override specifici su segmenti di traffico.
Una volta effettuato il check-in, questo DSL viene tradotto in un equivalente protobuf interno, che acquisisce l'intento semantico della configurazione. Il backend SAFE traduce poi ulteriormente questa configurazione semantica in un albero di espressioni booleane. Una descrizione protobuf di questo albero di espressioni booleane viene inviata all'SDK di SAFE, che la carica in una rappresentazione in-memory ulteriormente compattata della configurazione.
UI
La maggior parte delle attivazioni dei flag viene avviata da un'interfaccia utente interna per la gestione dei flag di SAFE. Questa interfaccia utente consente agli utenti di creare, modificare e ritirare i flag attraverso un flusso di lavoro che astrae gran parte della complessità di Jsonnet per le modifiche semplici, pur fornendo accesso a quasi tutta la potenza del DSL per i casi d'uso avanzati.
Un'interfaccia utente ricca ci ha anche permesso di implementare funzionalità aggiuntive per migliorare l'esperienza utente, come la possibilità di pianificare i flip dei flag, il supporto per i controlli di integrità post-merge e strumenti di debug per determinare i flip recenti dei flag che hanno avuto un impatto su una determinata regione o servizio.
Revisione della configurazione dei flag
Tutte le modifiche ai flag SAFE vengono create come normali PR di Github e vengono convalidate utilizzando un'ampia serie di validatori pre-merge. Questa serie di validatori è cresciuta fino a includere dozzine di controlli individuali, man mano che abbiamo imparato a proteggerci al meglio da modifiche potenzialmente non sicure dei flag. Durante l'introduzione iniziale di SAFE, le analisi post-mortem degli incidenti causati o mitigati dall'inversione di un flag SAFE hanno ispirato molti di questi controlli. Ora abbiamo controlli che, ad esempio, richiedono una revisione specializzata per le modifiche con un ampio raggio d'impatto (blast radius), richiedono che venga distribuita una particolare versione binaria del servizio prima che un flag possa essere abilitato, prevengono modelli comuni di configurazione errata e così via.
I team possono anche definire i propri controlli pre-merge specifici per flag o team, per garantire gli invarianti per le loro configurazioni.
Gestione delle modalità di errore
Dato il ruolo critico di SAFE nella stabilità del servizio, il sistema è progettato con più livelli di resilienza per garantire il funzionamento continuo anche in caso di guasto di parti della pipeline.
Lo scenario di errore più comune prevede interruzioni nel percorso di distribuzione della configurazione. Se un elemento qualsiasi nel percorso di distribuzione causa un errore nell'aggiornamento delle configurazioni, i servizi continuano semplicemente a utilizzare la loro ultima configurazione nota fino al ripristino del percorso di distribuzione. Questo approccio "fail static" garantisce che il comportamento esistente dei servizi rimanga stabile anche durante le interruzioni dei servizi upstream.
Per gli scenari più gravi, manteniamo più meccanismi di fallback:
- Distribuzione out-of-band: se un qualsiasi componente del percorso di push di CI o Github non è disponibile, gli operatori possono inviare le configurazioni direttamente al backend di SAFE utilizzando strumenti di emergenza.
- Failover a livello di regione: se il backend di SAFE o Zippy Global non sono attivi, gli operatori possono temporaneamente inviare le configurazioni direttamente alle istanze di Zippy Regional. I servizi possono anche eseguire il polling tra regioni per mitigare l'impatto di un'interruzione di una singola istanza di Zippy Regional.
- Bundle per l'avvio a freddo: per gestire i casi in cui Zippy non è disponibile durante lo startup del servizio, SAFE distribuisce periodicamente i bundle di configurazione ai servizi tramite un registro di artefatti. Sebbene questi bundle possano essere obsoleti di qualche ora, forniscono un backup sufficiente per consentire ai servizi di avviarsi in sicurezza, anziché bloccarsi in attesa della distribuzione in tempo reale.
All'interno dell'SDK di SAFE stesso, la progettazione difensiva garantisce che gli errori di configurazione abbiano un raggio d'azione limitato. Se la configurazione di un particolare flag non è valida, ne risentirà solo quel singolo flag. L'SDK mantiene anche il contratto di non generare mai eccezioni e in caso di errore torna sempre al valore default del codice, in modo che gli sviluppatori di applicazioni non debbano considerare la valutazione dei flag come un'operazione che può fallire. L'SDK avvisa inoltre immediatamente i tecnici reperibili in caso di errori di analisi o di valutazione della configurazione. Grazie alla maturità di SAFE e alla convalida estesa pre-merge, tali errori sono ora estremamente rari in produzione.
Questo approccio stratificato alla resilienza garantisce che SAFE esegua una degradazione graduale e riduce al minimo il rischio che diventi un singolo punto di errore.
Lezioni apprese
La riduzione al minimo delle dipendenze e il fallback ridondante a più livelli riducono l'onere operativo. Nonostante sia implementato e ampiamente utilizzato in quasi ogni ambiente compute di Databricks, l'onere operativo della manutenzione di SAFE è stato piuttosto gestibile. L'aggiunta di ridondanze a più livelli, come il cold start bundle e il comportamento "fail static" dell'SDK, ha reso gran parte dell'architettura SAFE auto-riparante.
L'esperienza dello sviluppatore è di fondamentale importanza. Scalare l'"aspetto umano" di un robusto sistema di flagging ha richiesto una forte attenzione alla UX. SAFE è un sistema mission-critical, spesso utilizzato per mitigare gli incidenti. Pertanto, creare una UX di facile utilizzo per l'attivazione dei flag durante le emergenze ha avuto un grande impatto. Adottare una mentalità orientata al prodotto ha portato a meno problemi minori, meno confusione e, in definitiva, a un tempo medio di ripristino (MTTR) a livello aziendale più basso per gli incidenti.
Rendere le "best practice" il percorso a basso attrito. Una delle lezioni più importanti che abbiamo appreso è che non basta documentare le best practice e aspettarsi che gli ingegneri le seguano. Gli ingegneri hanno molte priorità concorrenti durante il rilascio delle funzionalità. SAFE rende il percorso sicuro quello più semplice: le implementazioni graduali richiedono meno sforzo e hanno più funzionalità "quality-of-life" disponibili rispetto a modelli di abilitazione più rischiosi. Quando il sistema incentiva un comportamento più sicuro, la piattaforma può spingere gli ingegneri verso una cultura di gestione responsabile delle modifiche.
Stato attuale e lavori futuri
SAFE è ora una piattaforma interna matura all'interno di Databricks ed è ampiamente utilizzata. Gli investimenti fatti in termini di disponibilità ed esperienza dello sviluppatore stanno dando i loro frutti, come dimostra la continua riduzione del tempo medio di risoluzione e del raggio d'azione degli incidenti di produzione grazie all'utilizzo dei flag di SAFE.
Con la continua espansione della superficie dei prodotti di Databricks, le primitive dell'infrastruttura sottostante a tali prodotti si espandono sia in ampiezza che in complessità. Di conseguenza, sono stati fatti investimenti significativi e continui per garantire che SAFE supporti tutti gli ambienti in cui gli ingegneri di Databricks scrivono e distribuiscono il codice.
Se ti interessa lavorare sulla scalabilità di infrastrutture mission-critical come questa, scopri le posizioni aperte in Databricks!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.