Come costruire il rilevamento frodi in tempo reale utilizzando la modalità in tempo reale di Spark e Lakebase
Modernizzare gli Ecosistemi Finanziari con Latenza Inferiore al Secondo e Intelligenza dei Dati Scalabile
di Sixuan He e Navneeth Nair
- I sistemi tradizionali di rilevamento frodi soffrono di ritardi nel rilevamento, affidandosi a elaborazioni batch lente o a motori di streaming complessi e aggiunti a posteriori che non riescono a bloccare le minacce in tempo reale.
- Spark Real-Time Mode e Lakebase consentono ai team di dati di costruire e automatizzare facilmente un workflow di rilevamento frodi end-to-end: elaborando flussi di dati ad alta velocità, eseguendo modelli ML a bassa latenza e fornendo punteggi di frode spiegabili, il tutto all'interno di una piattaforma unificata.
- Le organizzazioni possono ottenere un intervento in meno di un secondo sulle transazioni fraudolente, riducendo la complessità operativa, proteggendo al contempo i ricavi e mantenendo la fiducia dei clienti senza la necessità di infrastrutture esterne.
La frode con carta opera in pochi secondi. Un numero di carta di credito rubato può alimentare decine di acquisti in pochi minuti e, una volta che una transazione si è stabilizzata, recuperare quei fondi diventa esponenzialmente più difficile. Secondo il Nilson Report, le istituzioni finanziarie perdono circa 33 miliardi di dollari all'anno a causa di transazioni fraudolente con carta, e questa cifra è destinata a crescere man mano che il volume delle transazioni digitali accelera.
La sfida non è rilevare le frodi. La maggior parte delle organizzazioni dispone già di modelli di frode capaci e regole ben ottimizzate. La sfida è rilevarle abbastanza velocemente da bloccare una transazione sospetta prima che venga autorizzata, nella finestra di sub-secondo tra autorizzazione e regolamento, e farlo senza aggiungere un motore di streaming separato e specializzato che raddoppi la complessità operativa.
In questo blog, presentiamo un nuovo Acceleratore di Soluzioni: un'implementazione di riferimento open source che puoi clonare e distribuire direttamente nel tuo ambiente Databricks. Dimostra come costruire un sistema completo di rilevamento delle frodi end-to-end, dall'ingestione di transazioni grezze e scoring ML in tempo reale a una dashboard di monitoraggio live costruita con Databricks Apps, interamente sulla piattaforma Databricks. Al suo centro ci sono due tecnologie: Real-Time Mode (RTM) per Apache Spark Structured Streaming su Databricks che offre elaborazione di stream inferiore a 300 ms, e Lakebase, un database Postgres completamente gestito e serverless integrato nella piattaforma Databricks.
Velocità vs. Semplicità: Il Compromesso in Tempo Reale per il Rilevamento delle Frodi
Il rilevamento delle frodi si trova all'intersezione di due esigenze contrastanti.
Da un lato, c'è la velocità. Una transazione fraudolenta deve essere identificata e bloccata entro centinaia di millisecondi prima che si stabilizzi. Sofisticate reti di frode testano carte rubate con micro-acquisti rapidi, sfruttano anomalie geografiche e adattano i loro schemi più velocemente di quanto le regole statiche possano tenere il passo.
Dall'altro lato, c'è la semplicità. I team di dati vogliono costruire, addestrare e distribuire modelli di frode su un'unica piattaforma, con governance unificata, dati condivisi e un unico set di strumenti. Non vogliono mantenere uno stack di streaming separato solo per l'"ultimo miglio" dello scoring in tempo reale.
Fino ad ora, i team sono stati costretti a scegliere. Storicamente, soddisfare questi requisiti di latenza ultra-bassa significava introdurre un motore specializzato accanto a Spark, come Apache Flink. Il risultato è un modello familiare: due sistemi paralleli, dati duplicati, governance divisa e team di ingegneri che dedicano più tempo alla gestione delle pipeline invece di migliorare i modelli di frode. Con l'introduzione di RTM in Spark Structured Streaming, questo compromesso non è più necessario.
RTM: Elaborazione Sub-Secondo Senza il Carico Operativo di Sistemi Multipli
RTM è un'evoluzione del motore Spark Structured Streaming che consente l'elaborazione dei dati in sub-secondo per applicazioni operative sensibili alla latenza, come l'ingegneria delle feature.
Sul fronte della velocità, RTM elabora gli eventi in millisecondi ed è fino al 92% più veloce di Apache Flink attraverso carichi di lavoro di trasformazione stateless, arricchimento basato su join e aggregazione. Clienti come Coinbase stanno già utilizzando RTM per calcolare oltre 250 feature ML e hanno raggiunto latenze di elaborazione P99 inferiori a 100 ms.
Sul fronte della semplicità, RTM vive all'interno del motore Spark che già utilizzi, non accanto ad esso. Pertanto, beneficerai immediatamente di:
- Nessuna deriva logica. Le tue regole di scoring delle frodi, l'ingegneria delle feature e la pre-elaborazione ML esistono una sola volta. Lo stesso codice che viene eseguito nella tua pipeline di training offline viene eseguito nel tuo ambiente di scoring in tempo reale. Questo ti consente di mettere in produzione le feature più velocemente e con maggiore precisione.
- Un'unica superficie operativa. Spark UI, monitoraggio del cluster, job, alerting, ecc. Tutti gli strumenti che già utilizzi si applicano. Non c'è una seconda rotazione di reperibilità per il motore di streaming.
- Flessibilità su costo vs. freschezza. Quando la freschezza sub-secondo non vale il costo, tornare a un trigger più lento è la stessa modifica di codice di una riga nella direzione opposta. Non è necessario dedicare tempo all'ottimizzazione manuale del parallelismo o all'orchestrare lo spegnimento e il riavvio delle risorse di calcolo.
Di conseguenza, il team non ha più bisogno di scegliere; ottieni sia la velocità che la semplicità, e le ore di ingegneria tornano all'ottimizzazione dei segnali di frode piuttosto che alla gestione dell'infrastruttura.
Scenario di esempio: Bloccare le frodi nelle transazioni con carta di credito
Per rendere questo concetto concreto, il nostro Acceleratore di Soluzioni implementa un sistema di rilevamento delle frodi in tempo reale per le transazioni con carta di credito. Ecco lo scenario:
Le transazioni arrivano in streaming da un sistema di messaggistica (Kafka, Kinesis, ecc.). Ogni transazione include un ID carta, importo, categoria esercente, coordinate geografiche e canale (online vs. punto vendita). Il sistema deve valutare ogni transazione rispetto a più segnali di frode, assegnare un punteggio di rischio e instradarla all'esito appropriato — approvata, contrassegnata per revisione o bloccata — tutto entro 300 ms.
L'architettura rispecchia l'aspetto dei sistemi di frode di produzione presso le principali istituzioni finanziarie, con tracciamento stateful, arricchimento delle feature da Lakebase come livello di serving online, scoring ML e un'applicazione live Databricks Apps per il monitoraggio degli analisti delle frodi. La differenza è che funziona interamente su un'unica piattaforma.
Come l'abbiamo costruito
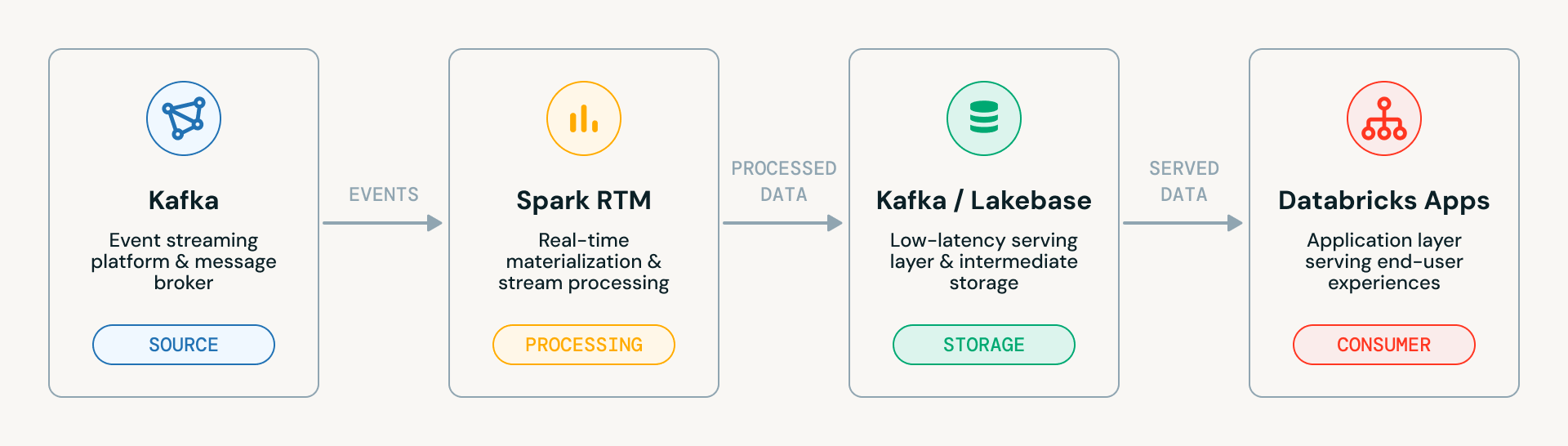
L'acceleratore attraversa quattro fasi progressive, ognuna basata sulla precedente. Ecco il diagramma di architettura di sistema di alto livello. Mostra il flusso di dati pulito attraverso i quattro componenti principali:
- Kafka (Sorgente): La piattaforma di streaming di eventi che acquisisce eventi grezzi
- Spark RTM: Il motore di materializzazione in tempo reale che elabora i dati in streaming
- Kafka / Lakebase: Il livello intermedio dove i dati elaborati atterrano, sia di nuovo in Kafka che in Lakebase (il livello di serving a bassa latenza di Databricks)
- Databricks Apps: Il livello applicativo che serve i dati finali agli utenti finali
Guarda il video dimostrativo completo end-to-end qui sotto, oppure continua a leggere la guida passo dopo passo per scoprire esattamente come l'abbiamo costruito. Inizia con l'Avvio Rapido qui sotto (nessuna dipendenza esterna) e aggiungi complessità man mano che procedi.
Fase 1: Guarda Real-Time Mode in Azione
Per le istituzioni finanziarie che valutano l'infrastruttura di frode in tempo reale, un rapido time-to-value è fondamentale. Il notebook di Avvio Rapido consente al tuo team di sperimentare immediatamente Real-Time Mode e di convalidare i benchmark di latenza principali e l'idoneità della piattaforma in meno di cinque minuti, prima di qualsiasi impegno di produzione. Non è necessario connettersi a Kafka o configurare nulla di esterno. Genera transazioni sintetiche utilizzando la sorgente di frequenza integrata di Spark, applica la logica di scoring delle frodi e visualizza i risultati in tempo reale nel notebook. Questo è il tuo "hello world" per Real-Time Mode. Eseguilo, osserva i numeri di latenza e verifica che il tuo cluster sia configurato correttamente.
Fase 2: Costruire la Pipeline di Rilevamento delle Frodi
Con Real-Time Mode convalidato, il notebook successivo costruisce una pipeline di rilevamento delle frodi di livello produttivo che rispecchia il modo in cui le principali istituzioni finanziarie operativizzano il decision-making sulle frodi in tempo reale. Elabora le transazioni end-to-end, fornendo lo scoring spiegabile richiesto sia dai team operativi antifrode che di compliance. Le transazioni fluiscono da Kafka attraverso cinque fasi, ognuna in esecuzione continua, ognuna aggiungendo intelligenza:
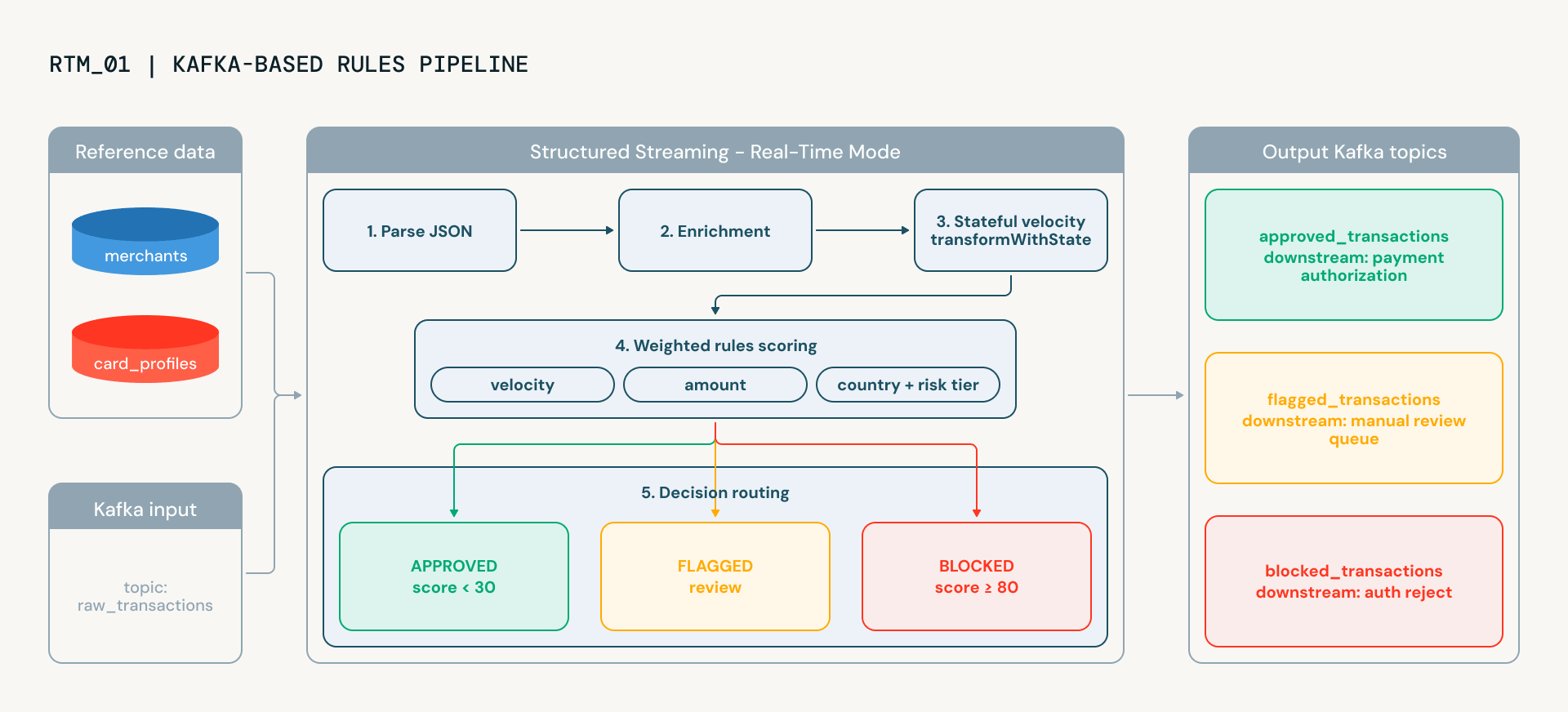
- Parsing acquisisce il JSON grezzo da Kafka e lo struttura in colonne tipizzate
- Tracciamento della velocità è dove le cose si fanno interessanti. Utilizzando transformWithState (il potente operatore di Spark per la creazione di trasformazioni stateful arbitrarie o personalizzate), la pipeline mantiene lo stato per carta attraverso lo stream: quante transazioni ha effettuato questa carta negli ultimi 60 secondi? Una carta che improvvisamente effettua cinque transazioni in un minuto mostra un classico comportamento di test delle carte. Lo stato scade automaticamente tramite TTL, quindi non c'è crescita illimitata della memoria e nessuna pulizia manuale.
- Arricchimento aggiunge contesto dai profili di rischio del commerciante e dai dati del titolare della carta. Si tratta di una categoria di commercianti ad alto rischio (carte regalo, gioielli)? Il titolare della carta spende normalmente $50 o $5.000? Queste ricerche utilizzano dizionari Python anziché join broadcast, evitando l'overhead di BroadcastExchange che può aggiungere latenza nelle pipeline di streaming.
- Scoring combina cinque segnali di frode ponderati: velocità, anomalia geografica, deviazione dell'importo, rischio della categoria del commerciante e rischio del paese, in un unico punteggio da 0 a 100. Ogni segnale è calcolato da una UDF dedicata e i pesi sono configurabili. Il risultato è un punteggio spiegabile: puoi vedere esattamente quali segnali hanno contribuito e in che misura.
- Instradamento prende la decisione finale. Le transazioni sono classificate come approvate, segnalate per revisione manuale o bloccate automaticamente, e scritte nell'argomento Kafka di output appropriato.
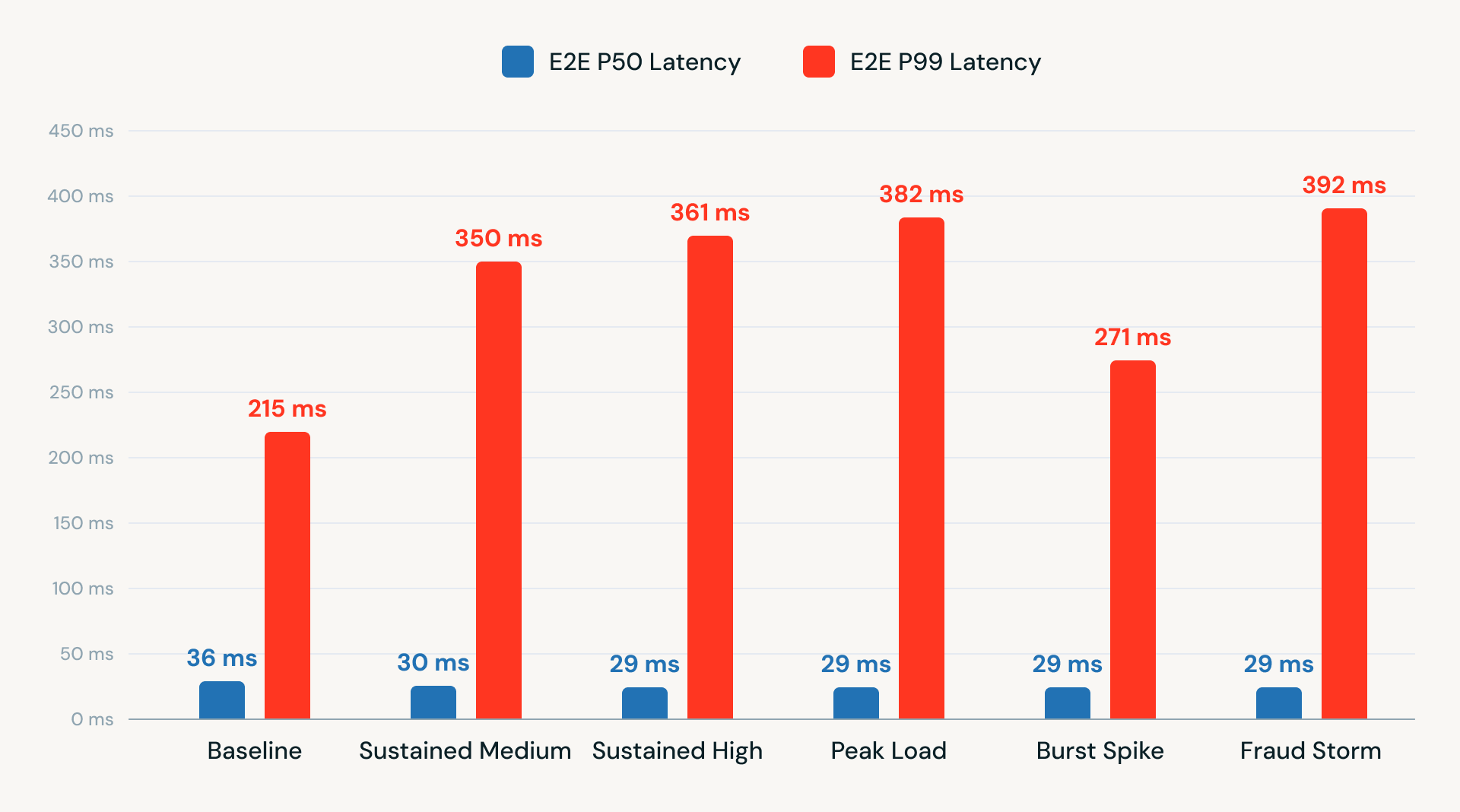
Abbiamo anche condotto test di latenza end-to-end su vari livelli di TPS. I risultati hanno mostrato prestazioni costanti, con una latenza P50 inferiore a 40 ms e una latenza P99 compresa tra 215 e 392 ms. Questi risultati dimostrano che un'architettura Kafka-in, Kafka-out che utilizza RTM sulla piattaforma Databricks può offrire prestazioni a bassa latenza e pronte per la produzione senza fare affidamento su API esterne o infrastrutture aggiuntive.
Passo 3: Aggiornamento al Machine Learning
Il rilevamento delle frodi basato su regole statiche crea sistemi facili da controllare ma fragili. Le soglie sono arbitrarie: perché cinque transazioni in 60 secondi sono "sospette"? Perché non quattro o sei? E poiché non c'è apprendimento, il sistema non migliora mai dalle decisioni passate.
Il notebook avanzato aggiorna questa logica a un modello di machine learning governato. Questa transizione consente ai team di rischio di ridurre i falsi positivi, adattarsi ai nuovi schemi di frode emergenti e dimostrare la lineage del modello ai regolatori tramite il tracciamento degli esperimenti e il versioning integrati di MLflow. Questo introduce due nuove capacità della piattaforma:
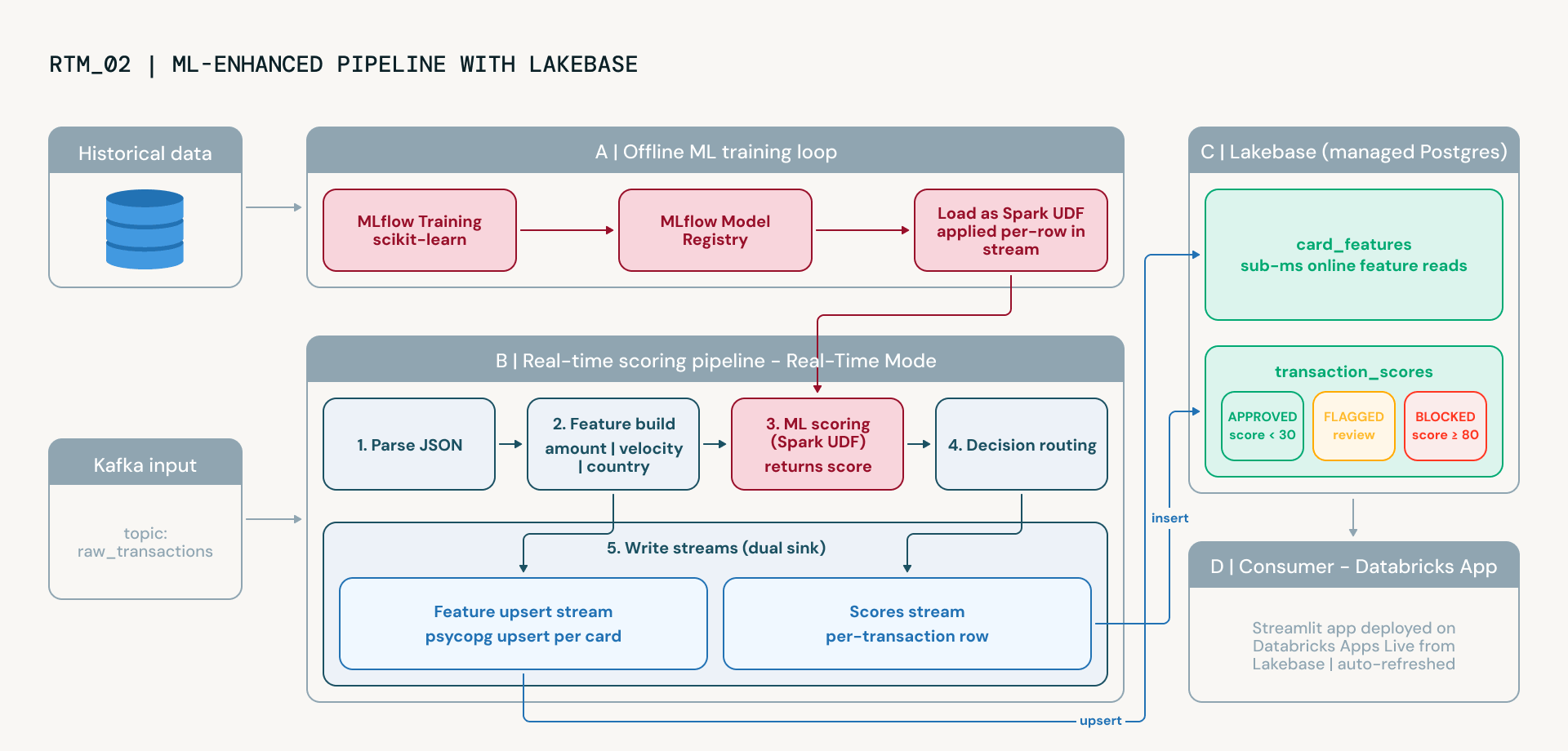
- Lakebase come livello di serving online. Lakebase è il servizio PostgreSQL gestito di Databricks. Utilizzando il sink foreach di Spark Structured Streaming con un LakebaseFeatureWriter personalizzato, la pipeline trasmette continuamente funzionalità per carta, modelli di velocità, importi medi delle transazioni, diffusione geografica, tutto direttamente nelle tabelle Lakebase con semantica upsert. Lakebase fornisce letture in sub-millisecondi, rendendolo ideale per il serving di funzionalità in tempo reale senza gestire infrastrutture esterne.
- MLflow per l'addestramento e il serving del modello. Un classificatore RandomForest viene addestrato su dati storici etichettati utilizzando MLflow per il tracciamento degli esperimenti e il versioning del modello. Il modello addestrato viene caricato come UDF di Spark e applicato a ogni transazione nella pipeline di streaming. Combinato con le funzionalità live di Lakebase, il modello apprende relazioni non lineari tra segnali che le regole statiche non rilevano, e migliora nel tempo man mano che nuovi dati etichettati diventano disponibili.
Passo 4: Monitoraggio di tutto in tempo reale
La visibilità operativa è un elemento non negoziabile per i team antifrode che operano sotto obblighi di reporting normativo in tempo reale. Per rendere il sistema osservabile, l'acceleratore include una Databricks Apps basata su Streamlit che legge direttamente da Lakebase per fornire una dashboard di monitoraggio delle frodi in tempo reale. Questo offre agli analisti antifrode e ai gestori del rischio una visione in tempo reale e verificabile di ogni decisione presa dal sistema, senza richiedere il supporto ingegneristico per accedervi. Gli utenti possono tracciare il totale delle transazioni valutate, le suddivisioni delle decisioni (approvate, segnalate, bloccate), i punteggi di frode recenti con dettagli a livello di carta e le distribuzioni di probabilità di frode, il tutto con aggiornamento automatico ogni 10 secondi. Questo è lo strato operativo che rende il sistema utilizzabile nella pratica, non solo tecnicamente funzionale.
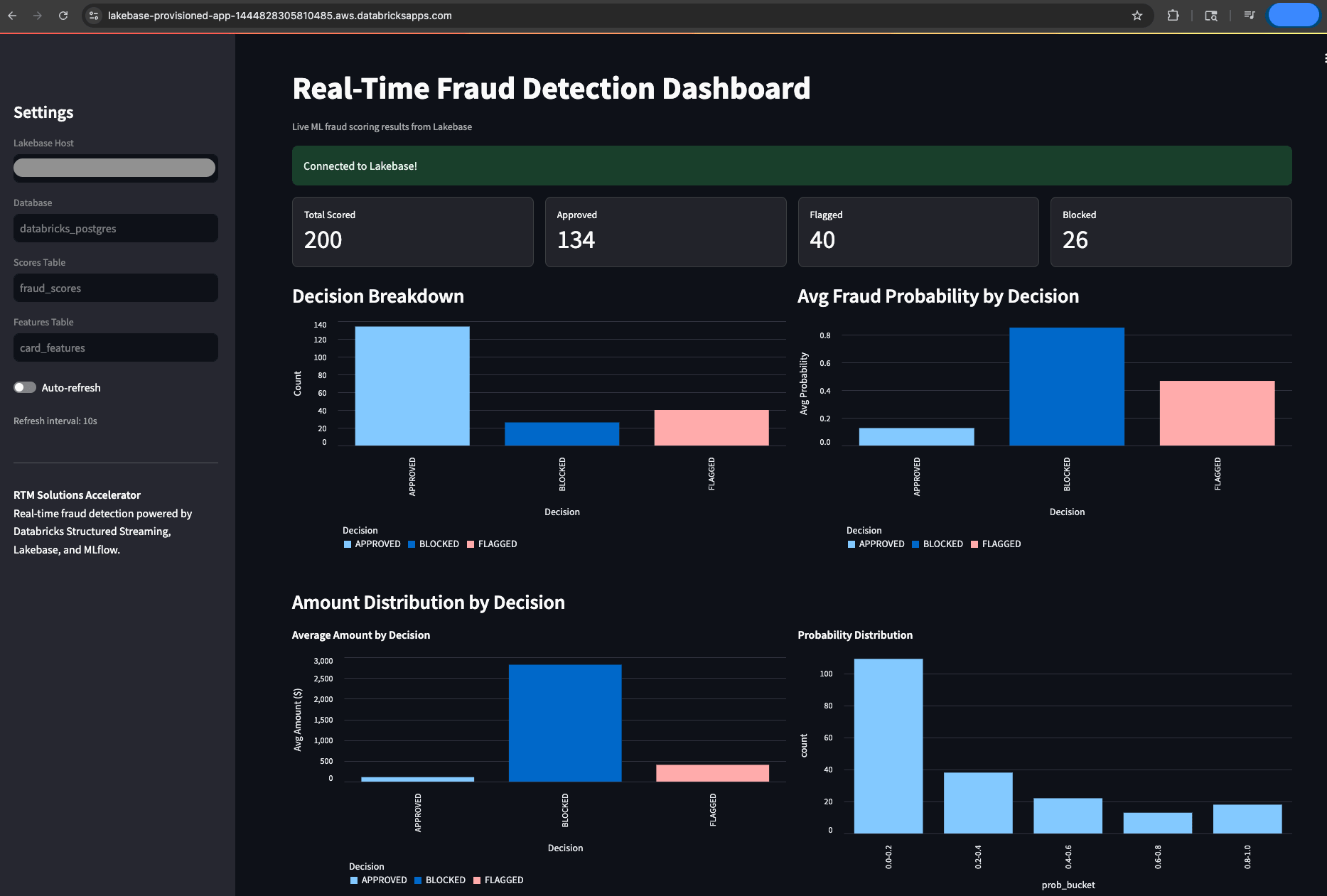
L'intuizione chiave è che tutto funziona su un'unica piattaforma. Lo stesso motore Spark che alimenta il tuo ETL batch e l'addestramento ML ora gestisce lo streaming in meno di 300 ms. Unity Catalog ora governa sia le tue tabelle di streaming che i tuoi dati di addestramento. MLflow ora traccia i tuoi modelli di frode, sia che vengano utilizzati nell'inferenza batch o nello scoring in tempo reale. Non ci sono lacune di integrazione, nessuna divisione della governance e nessun secondo stack da mantenere perché tutto è sulla stessa piattaforma.
Per iniziare
Questo Solution Accelerator è progettato per essere progressivamente adattabile: inizia in modo semplice e aggiungi complessità se necessario.
- Avvio Rapido: Clona il repository, apri `notebooks/RTM_00_Quick_Start.py` e eseguilo su un cluster configurato per la modalità in tempo reale. Vedrai RTM elaborare transazioni sintetiche con una latenza inferiore a 300 ms — senza Kafka, senza alcuna configurazione esterna richiesta.
- Pipeline completa: Configura uno scope segreto Kafka con gli indirizzi dei tuoi broker, quindi esegui `notebooks/RTM_01_Introduction_fraud_detection.py`. Questo ti offre la pipeline completa di parsing-arricchimento-scoring-instradamento che legge e scrive su Kafka. Durante l'esecuzione, vedrai le transazioni fluire attraverso tutte e cinque le fasi e le decisioni confluire nell'argomento di output approvato, segnalato e bloccato. Questo ti offre la pipeline completa di parsing-arricchimento-scoring-instradamento che legge e scrive su Kafka.
- Scoring basato su ML: Crea un'istanza Lakebase, quindi esegui `notebooks/RTM_02_Advanced_fraud_detection_ml.py`. Questo aggiunge lo streaming delle funzionalità a Lakebase, l'addestramento del modello con MLflow e lo scoring basato su ML nella pipeline. Una volta completato, MLflow registrerà il modello addestrato e la pipeline inizierà a emettere punteggi di frode derivati da ML al posto dei pesi basati su regole.
- App di monitoraggio live: Distribuisci l'app Streamlit da `apps/` come Databricks Apps con un binding di risorse Lakebase. L'app si connette automaticamente e inizia a visualizzare i punteggi di frode in tempo reale.
Il percorso più veloce è con Databricks Asset Bundles — basta clonare, distribuire ed eseguire:
Il bundle esegue automaticamente il provisioning di un cluster configurato correttamente ed esegue tutti i notebook in sequenza.
Scopri di più sulla modalità in tempo reale
La modalità in tempo reale è generalmente disponibile su Databricks su AWS, Azure e GCP. Il Solution Accelerator per il rilevamento delle frodi è open-source e pronto per essere distribuito.
- Ottieni il Solution Accelerator su GitHub
- Documentazione della modalità in tempo reale
- Annuncio della GA della modalità in tempo reale
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.