Presentazione di Databricks Vista Anteprima Pubblica della Ricerca Vetoriale
Dopo l'annuncio fatto ieri riguardo al Retrieval Augmented Generation (RAG), oggi siamo entusiasti di annunciare l'anteprima pubblica di Databricks AI Search. Abbiamo annunciato l'anteprima privata a un numero limitato di clienti al Data + AI Summit di giugno, ora disponibile per tutti i nostri clienti. Databricks AI Search consente agli sviluppatori di migliorare l'accuratezza delle loro applicazioni Retrieval Augmented Generation (RAG) e generative AI attraverso la ricerca di somiglianza su documenti non strutturati come PDF, Office Documents, Wiki e altro ancora. La ricerca vettoriale fa parte della Databricks Data Intelligence Platform, rendendo facile per le tue applicazioni RAG e Generative AI utilizzare rapidamente e in modo sicuro i dati proprietari memorizzati nella tua Lakehouse e fornire risposte accurate.
Abbiamo progettato Databricks AI Search per essere veloce, sicuro e facile da usare.
- Fast con basso TCO - La ricerca vettoriale è progettata per offrire alte prestazioni a un TCO più basso, con una latenza fino a 5 volte inferiore rispetto ad altri fornitori
- Esperienza semplice e veloce per gli sviluppatori - La ricerca vettoriale rende possibile sincronizzare qualsiasi Tabella Delta in un indice vettoriale con un solo clic - senza bisogno di pipeline di ingestione/sincronizzazione dati complesse e personalizzate.
- Governance Unificata - AI Search utilizza gli stessi strumenti di sicurezza e governance dei dati basati su Unity Catalog che già alimentano la tua Data Intelligence Platform, il che significa che non devi costruire e mantenere un insieme separato di politiche di governance dei dati per i tuoi dati non strutturati
- Serverless Scaling - La nostra infrastruttura Serverless scala automaticamente al tuo flusso di lavoro senza dover configurare istanze e tipi di server.
Cos'è la ricerca vettoriale?
La ricerca vettoriale è un metodo utilizzato nelle applicazioni di recupero delle informazioni e Recupero Aumentato (RAG) per trovare documenti o record in base alla loro somiglianza con una query. La ricerca vettoriale è il motivo per cui puoi digitare una query in un linguaggio semplice come "scarpe blu che sono adatte per venerdì sera" e ricevere risultati rilevanti.
I giganti tecnologici hanno utilizzato la ricerca vettoriale per anni per alimentare le loro esperienze di prodotto - con l'avvento del AIgenerativo, queste capacità sono finalmente state democratizzate in tutte le organizzazioni.
Ecco una panoramica di come funziona la Ricerca Vetoriale:
Embedding: Nella ricerca vettoriale, dati e query sono rappresentati come vettori in uno spazio multidimensionale chiamato embedding da un modello di AI generativa.
Prendiamo un esempio semplice in cui vogliamo usare la ricerca vettoriale per trovare parole semanticamente simili in un grande corpus di parole. Quindi, se query il corpus con la parola 'cane', vuoi che termini come 'cucciolo' vengano restituiti. Ma, se cerchi 'auto', devi recuperare parole come 'van'. Nella ricerca tradizionale, dovrai mantenere una lista di sinonimi o "parole simili" che è difficile da generare o scalare. Per usare la ricerca vettoriale, puoi invece utilizzare un modello AI generativo per convertire queste parole in vettori in uno spazio n-dimensionale chiamato embedding. Questi vettori avranno la proprietà che parole semanticamente simili come 'cane' e 'cucciolo' saranno più vicine l'una a l'altra nello spazio n-dimensionale rispetto alle parole 'cane' e 'auto'.
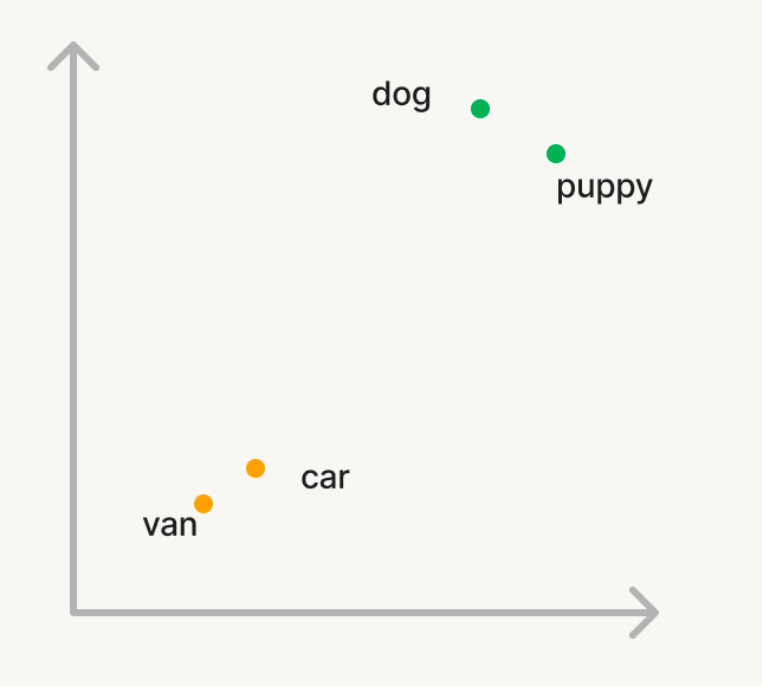
Calcolo della Similarità: Per trovare i documenti rilevanti per una query, la somiglianza tra il vettore di query e ciascun vettore di documento viene calcolata per misurare quanto siano vicini tra loro nello spazio n-dimensionale. Questo viene tipicamente fatto usando la similarità coseno, che misura il coseno dell'angolo tra i due vettori. Esistono diversi algoritmi utilizzati per trovare vettori simili in modo efficiente, con gli algoritmi basati su HNSW che sono costantemente i migliori in classe.
Applicazioni: La ricerca vettoriale ha molti casi d'uso:
- Raccomandazioni - raccomandazioni personalizzate e consapevoli del contesto per gli utenti
- RAG - consegna di documenti non strutturati rilevanti per aiutare un'applicazione RAG a rispondere alle domande degli utenti
- Ricerca semantica - abilitazione di query di ricerca in lingua semplice che forniscono risultati rilevanti
- Documentare clusterizzare - comprendere somiglianze e differenze tra i dati
Perché i clienti amano la ricerca vettoriale di Databricks?
"Siamo entusiasti di sfruttare Databricks'soluzioni potenti per trasformare il nostro cliente operatorio di supporto clienti presso Lippert. Gestire un ambiente di call center dinamico per un'azienda delle nostre dimensioni, la sfida di aggiornare i nuovi agenti in mezzo al tipico rottagliamento degli agenti è significativa. Databricks è la chiave delle nostre soluzioni: creando un'esperienza di assistenza agli agenti basata su AI Search, possiamo permettere ai nostri agenti di trovare rapidamente risposte alle richieste dei clienti. Integrando contenuti da manuali di prodotto, video di YouTube e casi di supporto nella nostra Ricerca Vetoriale, Databricks garantisce ai nostri agenti le conoscenze necessarie a portata di mano. Questo approccio innovativo rappresenta una svolta per Lippert, migliorando l'efficienza e elevando l'esperienza di assistenza clienti."-Chris Nishnick, Intelligenza Artificiale, Lippert
Ingestione automatica dei dati
Prima che un database vettoriale possa memorizzare informazioni, richiede una pipeline di ingestione dati in cui dati grezzi e non elaborati provenienti da varie fonti devono essere puliti, elaborati (analizzati/bloccati) e incorporati con un modello AI prima di essere memorizzati come vettori nel database. Questo processo per costruire e mantenere un altro insieme di pipeline di ingestione dati è costoso e richiede tempo, richiedendo tempo a preziose ingegneria risorse. Databricks AI Search è completamente integrato con il Databricks Data Intelligence Platform, permettendogli di estrarre automaticamente i dati e incorporarli senza dover costruire e mantenere nuovi pipeline di dati.
Il nostro Delta Sync APIs sincronizza automaticamente i dati sorgente con gli indici vettoriali. Quando i dati di origine vengono aggiunti, aggiornati o eliminati, aggiorniamo automaticamente l'indice vettoriale corrispondente per corrispondere. Sotto il cofano, AI Search gestisce i fallimenti, gestisce i tentativi e ottimizza le dimensioni di Batch per offrirti le migliori prestazioni e throughput senza alcun lavoro o input. Queste ottimizzazioni riducono il costo totale di proprietà grazie all'aumento dell'utilizzo del modello di embedding Endpoint.
Diamo un'occhiata a un esempio in cui creiamo un indice vettoriale in tre semplici passaggi. Tutte le funzionalità di Ricerca Vetoriale sono disponibili tramite REST APIs, il nostro Python SDKo all'interno dell'interfaccia Databricks .
Passo 1. Crea un Endpoint di ricerca vettoriale che verrà utilizzato per creare e query un indice vettoriale usando l'interfaccia utente o il nostro REST API/SDK.
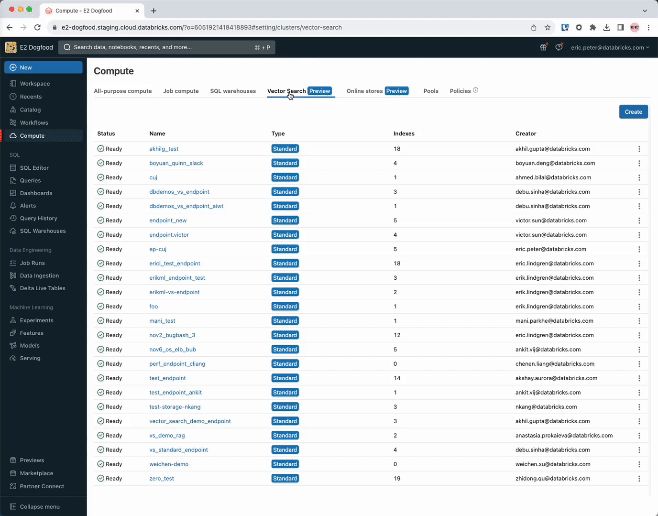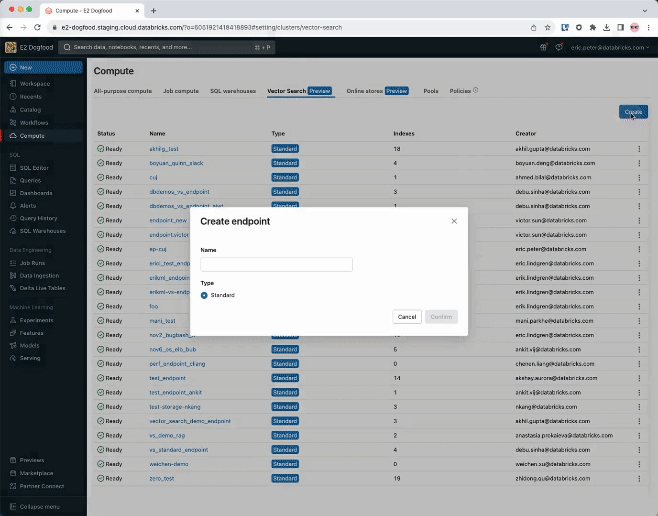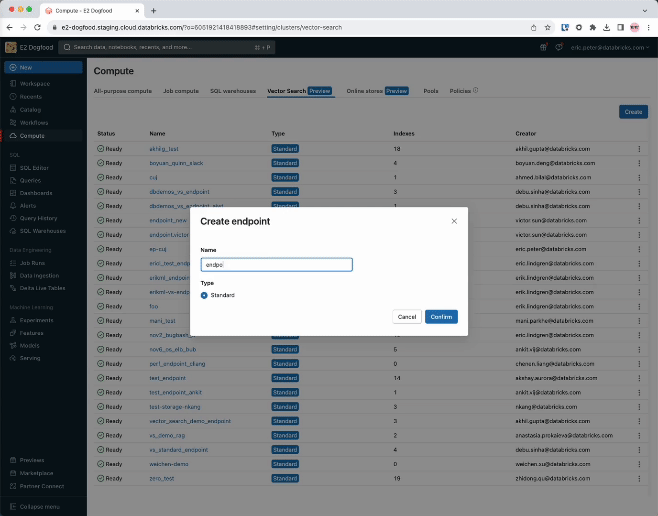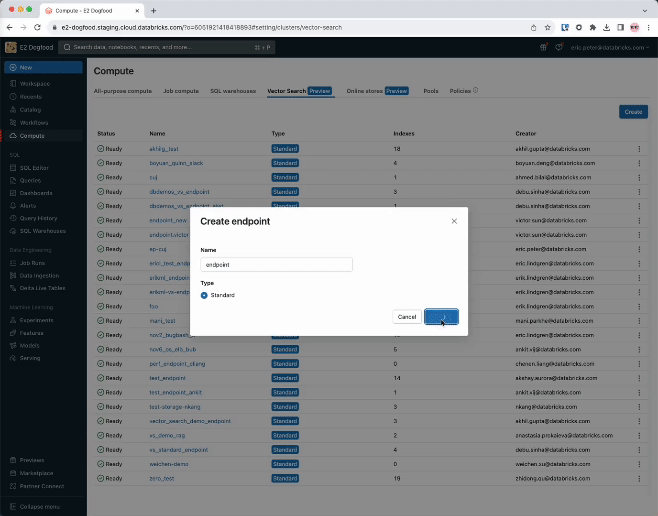
Passo 2. Dopo aver creato una Delta Tabella con i dati sorgente, selezioni una colonna nella Tabella Delta da incorporare e poi selezioni un Model Serving Endpoint che viene utilizzato per generare gli embeddings dei dati.
Il modello di embedding può essere:
- Un modello che hai perfezionato
- Un modello open-source pronto all'uso (come E5, BGE, InstructorXL, ecc.)
- Un modello di embedding proprietario disponibile tramite API (come OpenAI, Cohere, Anthropic, ecc.)
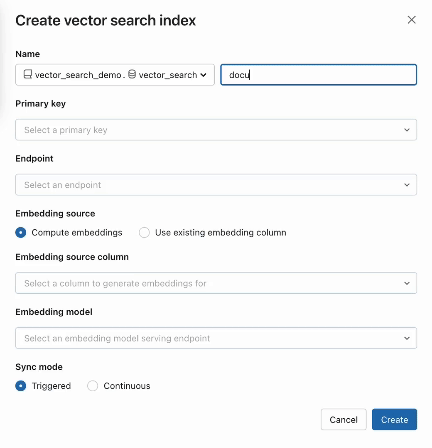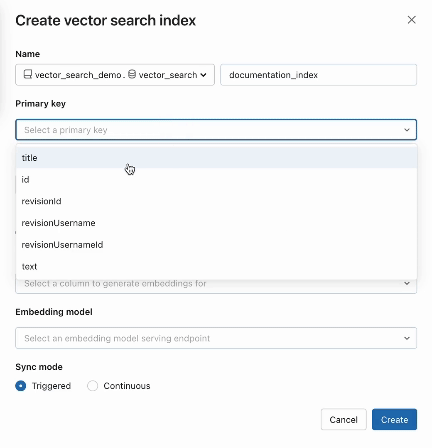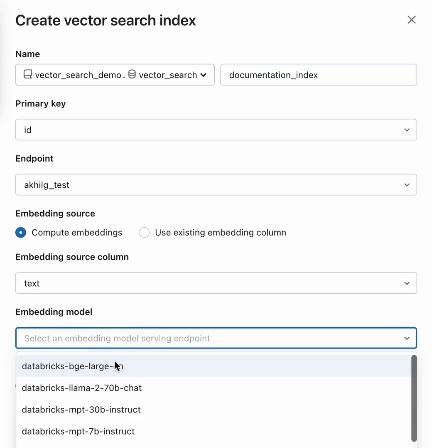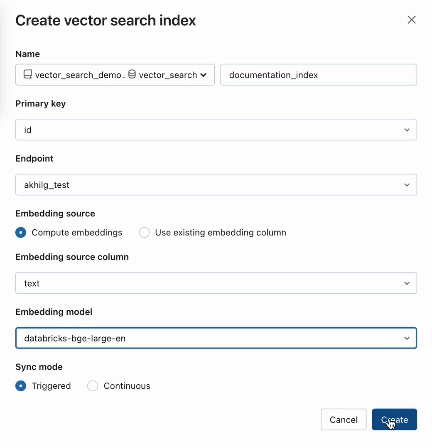
La ricerca vettoriale offre anche modalità avanzate per i clienti che preferiscono gestire i propri embedding in una Delta Table o creare pipeline di ingestione dati utilizzando REST APIs. Per esempi, consulta la documentazione di AI Search.
Passo 3. Una volta che l'indice è pronto, puoi fare query per trovare vettori rilevanti per il tuo query. Questi risultati possono poi essere inviati alla tua applicazione Retrieval Augmented Generation (RAG ).
"Questo prodotto è facile da usare, e siamo rimasti operativi in poche ore. Tutti i nostri dati sono già in Delta, quindi l'esperienza integrata e gestita di AI Search con delta sync è fantastica." —- Alex Dalla Piazza (EQT Corporation)"
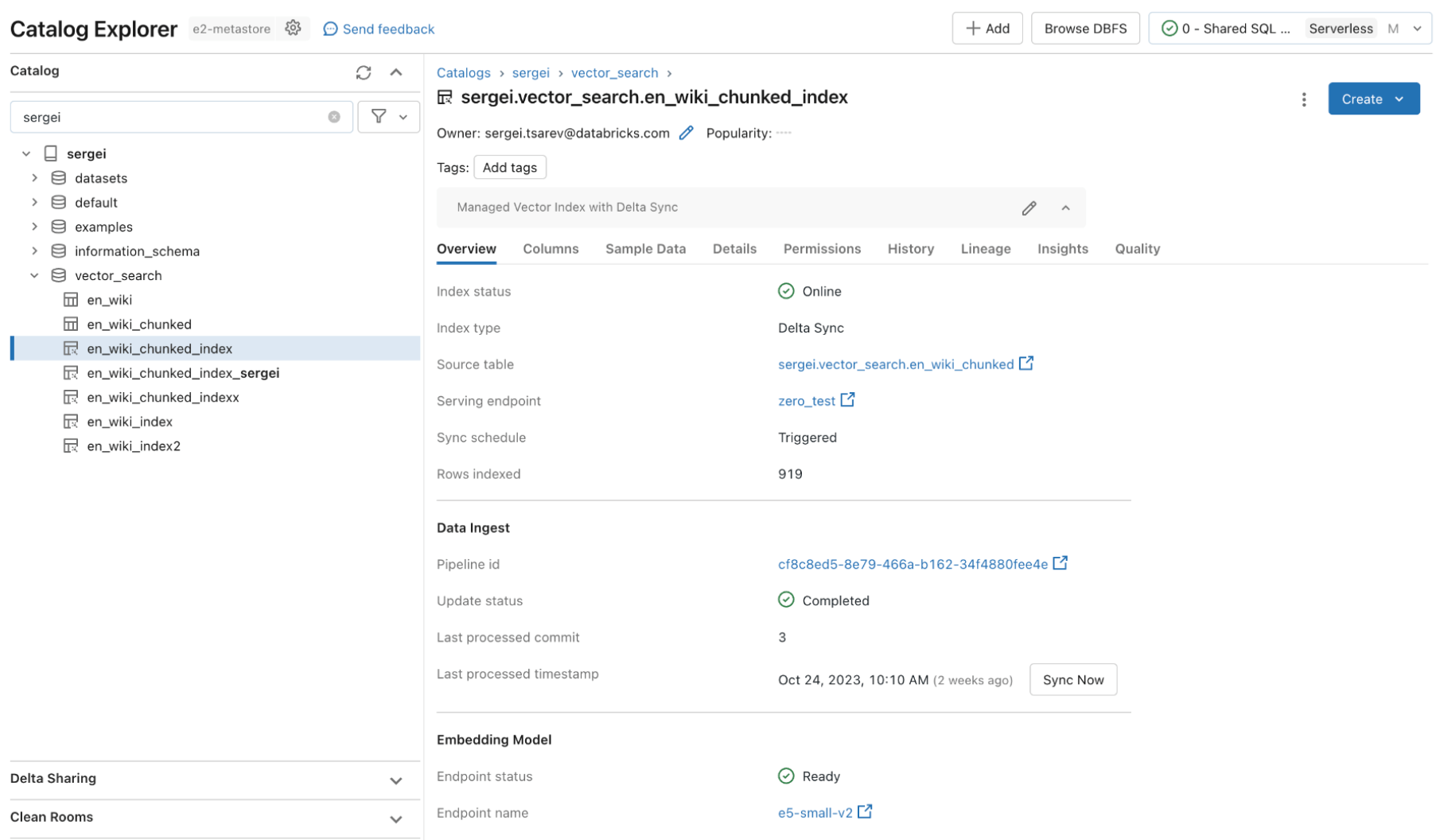
Governance integrato
Le organizzazioni aziendali richiedono rigorosi controlli di sicurezza e accesso sui propri dati, così gli utenti non possono utilizzare modelli di AI generative per fornire dati riservati a cui non dovrebbero avere accesso. Tuttavia, i database Vector attuali o non dispongono di controlli di sicurezza e accessi robusti oppure richiedono alle organizzazioni di costruire e mantenere un insieme separato di politiche di sicurezza separate dalla loro piattaforma dati. Avere più set di sicurezza e governance aggiunge costi e complessità ed è soggetto a errori da mantenere in modo affidabile.
Databricks AI Search sfrutta gli stessi controlli di sicurezza e governance dei dati che già proteggono il resto della Data Intelligence Platform resa possibile dall'integrazione con Unity Catalog. Gli indici vettoriali sono memorizzati come entità all'interno del Unity Catalog e sfruttano la stessa interfaccia unificata per definire politiche sui dati, con un controllo dettagliato sugli embedding.
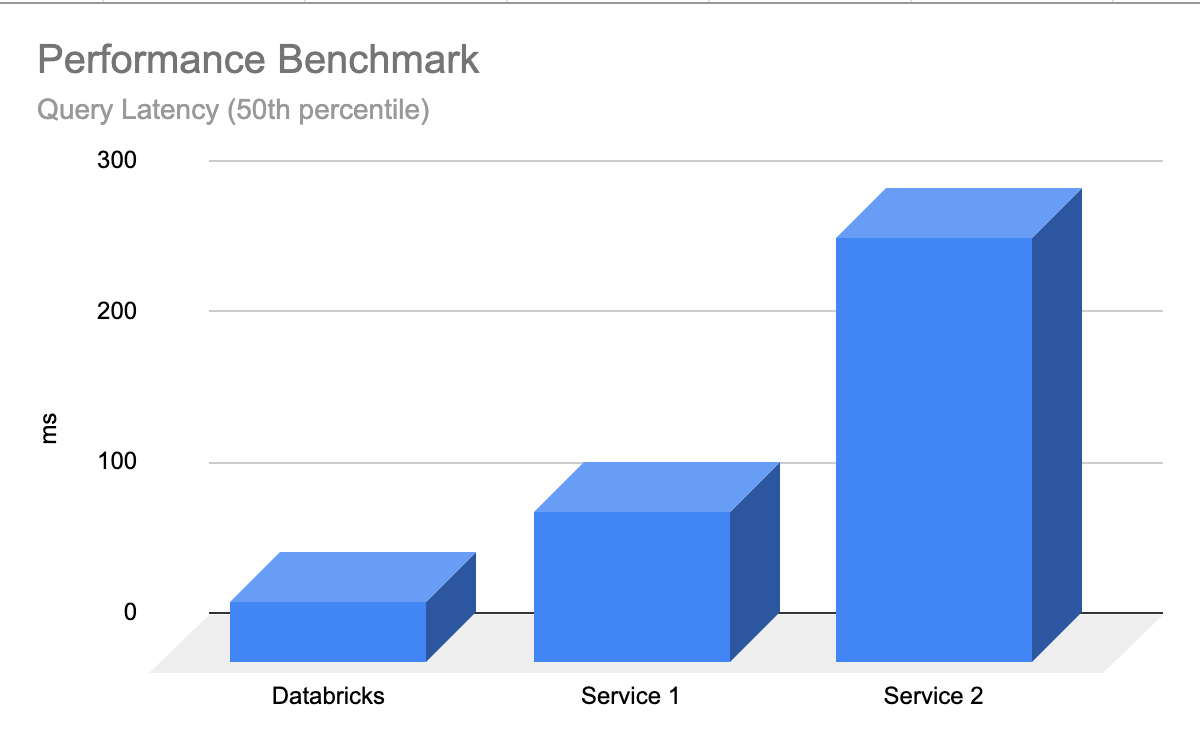
Prestazioni rapide delle query
Grazie alla maturità del mercato, molti database vettoriali mostrano buoni risultati nelle Proof-of-Concepts (POC) con piccole quantità di dati. Tuttavia, spesso mancano in termini di prestazioni o scalabilità per le implementazioni in produzione. Con scarse prestazioni pronte all'uso, gli utenti dovranno capire come ottimizzare e scalare gli indici di ricerca, il che richiede tempo e è difficile da gestire bene. Sono costretti a comprendere il proprio carico di lavoro e a prendere decisioni difficili su quali compute istanze scegliere e quale configurazione utilizzare.
Databricks AI Search è performante pronta all'uso, dove gli LLM restituiscono rapidamente risultati rilevanti con latenza minima e zero lavoro necessario per ottimizzare e scalare il database. La ricerca vettoriale è progettata per essere estremamente veloce per query con o senza filtraggio. Mostra prestazioni fino a 5 volte migliori rispetto ad alcuni degli altri principali database vettoriali. È facile da configurare: tu ci dici semplicemente la dimensione prevista del carico di lavoro (ad esempio, query al secondo), la latenza richiesta e il numero atteso di embedding: noi ci occupiamo del resto. Non devi preoccuparti dei tipi di istanza, RAM/CPU o di capire il funzionamento interno dei database vettoriali.
Abbiamo dedicato molti sforzi a personalizzare Databricks AI Search per supportare carichi di lavoro AI che migliaia di nostri clienti già utilizzano su Databricks. Le ottimizzazioni includevano benchmarking e l'identificazione dell'hardware migliore adatto alla ricerca semantica, l'ottimizzazione dell'algoritmo di ricerca sottostante e dell'overhead di rete per fornire le migliori prestazioni su scala.
Prossimi passi
Prendi start leggendo la nostra documentazione e creando specificamente un indice di ricerca vettoriale
Leggi di più sui prezzidella ricerca vettoriale
Iniziare a distribuire la propria applicazione RAG (demo)
Iscriviti a un webinar Databricks Generative AI
Vuoi risolvere casi d'uso generative AI ? Partecipa al Databricks & AWS Generative AI Hackathon! Iscriviti qui
Percorso di apprendimento generativo AI ingegnere: segui corsi auto-ritmati, su richiesta e guidati da istruttori su AIgenerativa
Leggi gli annunci riassuntivi fatti all'inizio di questa settimana
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.