La latenza scende al di sotto del secondo in Apache Spark Structured Streaming
Miglioramento della gestione degli offset in Project Lightspeed
di Jerry Peng, Pranav Anand, Sourav Gulati, Karthik Ramasamy, Michael Armbrust e Matei Zaharia
Apache Spark Structured Streaming è la principale piattaforma di stream processing open source. È anche la tecnologia di base che alimenta lo streaming sulla Databricks Lakehouse Platform e fornisce un'API unificata per l'elaborazione batch e in streaming. Con la rapida crescita dell'adozione dello streaming, diverse applicazioni vogliono sfruttarlo per il processo decisionale in tempo reale. Alcune di queste applicazioni, in particolare quelle di natura operativa, richiedono una latenza più bassa. Sebbene la progettazione di Spark consenta un throughput elevato e facilità d'uso a un costo inferiore, non è stata ottimizzata per una latenza inferiore al secondo.
In questo blog, ci concentreremo sui miglioramenti che abbiamo apportato alla gestione degli offset per ridurre la latenza di elaborazione intrinseca di Structured Streaming. Questi miglioramenti si rivolgono principalmente a casi d'uso operativi come il monitoraggio e gli avvisi in tempo reale, che sono semplici e stateless.
Una valutazione approfondita di questi miglioramenti indica che la latenza è migliorata del 68-75%, ovvero fino a 3 volte, passando da 700-900 ms a 150-250 ms per throughput di 100.000 eventi/sec, 500.000 eventi/sec e 1 milione di eventi/sec. Structured Streaming può ora raggiungere latenze inferiori a 250 ms, soddisfacendo i requisiti SLA per una grande percentuale di carichi di lavoro operativi.
Questo articolo presuppone che il lettore abbia una conoscenza di base di Spark Structured Streaming. Per saperne di più, consultare la seguente documentazione:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Motivazione
Apache Spark Structured Streaming è un motore di elaborazione di flussi distribuito basato sul motore Apache Spark SQL. Fornisce un'API che consente agli sviluppatori di elaborare flussi di dati scrivendo query di streaming allo stesso modo delle query batch, semplificando la logica e il test delle applicazioni di streaming. Secondo i download di Maven, Structured Streaming è oggi il motore di streaming distribuito open source più utilizzato. Uno dei motivi principali della sua popolarità sono le prestazioni: throughput elevato a un costo inferiore con una latenza end-to-end inferiore a pochi secondi. Structured Streaming offre agli utenti la flessibilità di bilanciare il compromesso tra throughput, costo e latenza.
Con la rapida crescita dell'adozione dello streaming in ambito aziendale, c'è il desiderio di consentire a un'ampia gamma di applicazioni di utilizzare un'architettura di dati di streaming. Nelle nostre conversazioni con molti clienti, abbiamo riscontrato casi d'uso che richiedono una latenza costante inferiore al secondo. Tali casi d'uso a bassa latenza derivano da applicazioni come l'avviso operativo e il monitoraggio in tempo reale, noti anche come "carichi di lavoro operativi". Per integrare questi carichi di lavoro in Structured Streaming, nel 2022 abbiamo lanciato un'iniziativa per il miglioramento delle prestazioni nell'ambito del Project Lightspeed. Questa iniziativa ha individuato aree e tecniche potenziali che possono essere utilizzate per migliorare la latenza di elaborazione. In questo blog, descriviamo in dettaglio una di queste aree di miglioramento: la gestione degli offset per il monitoraggio dei progressi e come questa consente di ottenere una latenza inferiore al secondo per i carichi di lavoro operativi.
Cosa sono i carichi di lavoro operativi?
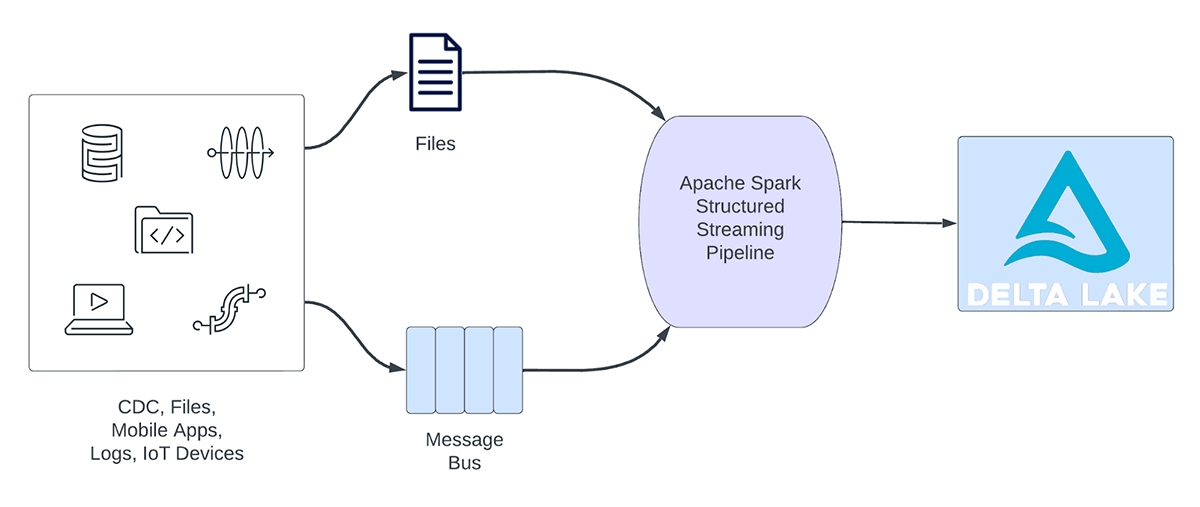
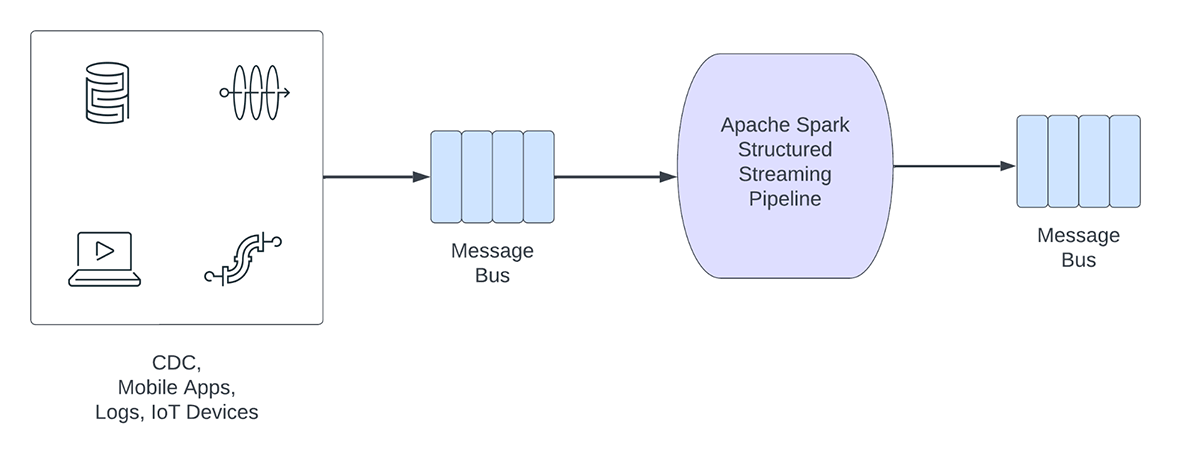
I carichi di lavoro di streaming possono essere ampiamente suddivisi in carichi di lavoro analitici e operativi. La figura 1 illustra sia i carichi di lavoro analitici che quelli operativi. I carichi di lavoro analitici in genere acquisiscono, trasformano, elaborano e analizzano i dati in tempo reale e scrivono i risultati in Delta Lake, supportato da un archivio di oggetti come AWS S3, Azure Data Lake Gen2 e Google Cloud Storage. Questi risultati vengono utilizzati da motori di data warehousing e strumenti di visualizzazione a valle.
{kind=link}
{kind=link}
Figura 1. Carichi di lavoro analitici e operativi
Alcuni esempi di carichi di lavoro analitici includono:
- Analisi del comportamento dei clienti: un'azienda di marketing può utilizzare l'analisi in streaming per analizzare il comportamento dei clienti in tempo reale. Elaborando i dati di clickstream, i feed dei social media e altre fonti di informazioni, il sistema è in grado di rilevare modelli e preferenze che possono essere utilizzati per raggiungere i clienti in modo più efficace.
- Analisi del sentiment: un'azienda potrebbe utilizzare i dati di streaming dai propri account di social media per analizzare il sentiment dei clienti in tempo reale. Ad esempio, l'azienda potrebbe cercare i clienti che esprimono un sentiment positivo o negativo sui prodotti o servizi dell'azienda.
- Analitiche IoT: una città intelligente può utilizzare l'analisi in streaming per monitorare il flusso del traffico, la qualità dell'aria e altri parametri in tempo reale. Elaborando i dati provenienti da sensori integrati in tutta la città, il sistema è in grado di rilevare tendenze e prendere decisioni sui modelli di traffico o sulle politiche ambientali.
D'altra parte, i carichi di lavoro operativi acquisiscono ed elaborano i dati in tempo reale e attivano automaticamente un processo aziendale. Alcuni esempi di tali carichi di lavoro includono:
- Sicurezza informatica: un'azienda potrebbe utilizzare i dati in streaming della propria rete per monitorare problemi di sicurezza o di prestazioni. Ad esempio, l'azienda potrebbe cercare picchi di traffico o accessi non autorizzati alle reti e inviare un avviso al reparto sicurezza.
- Fughe di informazioni di identificazione personale: un'azienda potrebbe monitorare i logs dei microservizi, analizzarli e rilevare se vengono divulgate informazioni di identificazione personale (PII) e, in tal caso, informare via email il proprietario del microservizio.
- Gestione ascensori: un'azienda potrebbe utilizzare i dati di streaming dell'ascensore per rilevare quando viene attivato il pulsante di allarme. Se attivato, potrebbe recuperare informazioni aggiuntive sull'ascensore per arricchire i dati e inviare una notifica al personale di sicurezza.
- Manutenzione proattiva: utilizzando i dati in streaming di un generatore di corrente, è possibile monitorarne la temperatura e, quando questa supera una determinata soglia, informare il supervisore.
Le pipeline di streaming operativo condividono le seguenti caratteristiche:
- Le aspettative di latenza sono di solito inferiori al secondo
- Le pipeline leggono da un bus di messaggi
- Le pipeline di solito eseguono calcoli semplici con trasformazione o arricchimento dei dati
- Le pipeline scrivono su un bus di messaggi come Apache Kafka o Apache Pulsar o su archivi di valori-chiave veloci come Apache Cassandra o Redis per l'integrazione a valle con i processi aziendali
Per questi casi d'uso, durante la profilazione di Structured Streaming, abbiamo riscontrato che la gestione degli offset per tracciare l'avanzamento dei micro-batch richiede una notevole quantità di tempo. Nella prossima sezione, esamineremo la gestione degli offset esistente e descriveremo i miglioramenti apportati nelle sezioni successive.
Cos'è la gestione degli offset?
Per tenere traccia del progresso fino al punto in cui i dati sono stati elaborati, Spark Structured Streaming si basa sulla persistenza e sulla gestione degli offset, che vengono utilizzati come indicatori di avanzamento. Tipicamente, un offset è definito concretamente dal connettore di origine, poiché sistemi diversi hanno modi diversi per rappresentare l'avanzamento o le posizioni nei dati. Ad esempio, un'implementazione concreta di un offset può essere il numero di riga in un file per indicare fino a che punto sono stati elaborati i dati nel file. I log durevoli (come illustrato nella Figura 2) vengono utilizzati per memorizzare questi offset e contrassegnare il completamento dei micro-batch.
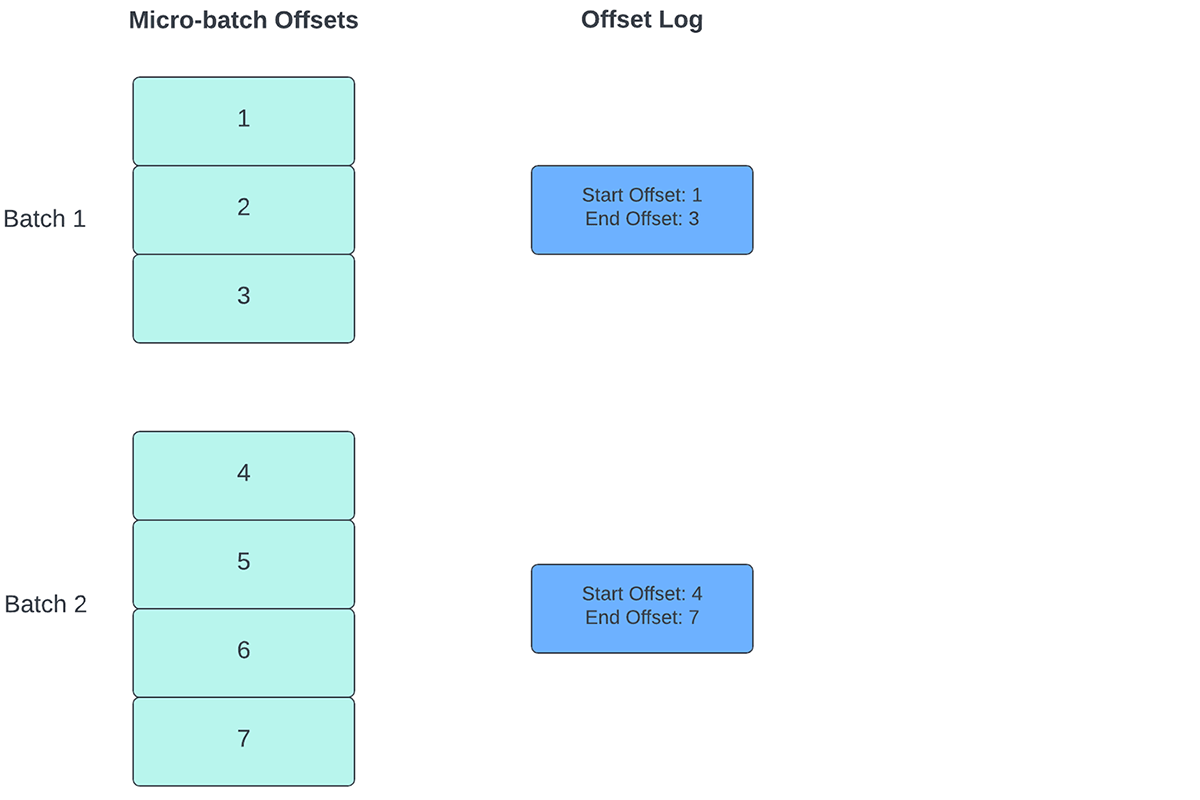
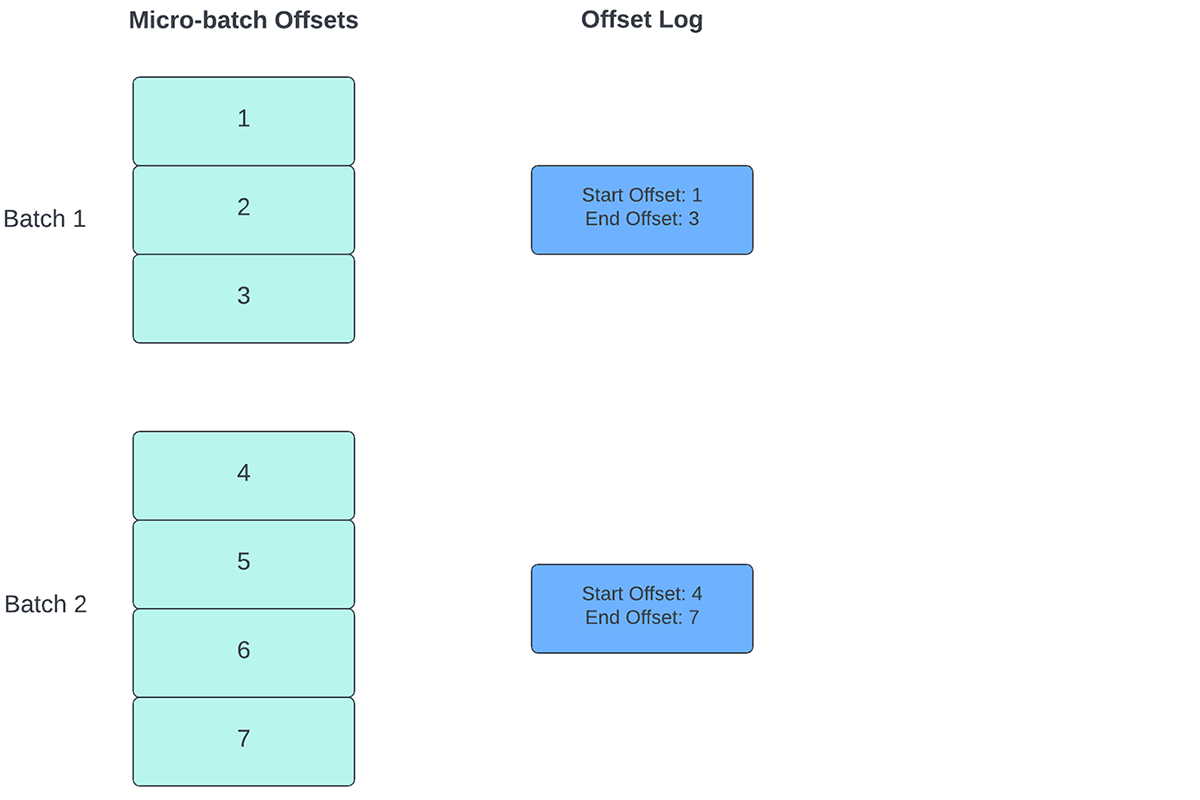{kind=link}
In Structured Streaming, i dati vengono elaborati in unità di micro-batch. Per ogni micro-batch vengono eseguite due attività operative di gestione degli offset. Una all'inizio di ogni micro-batch e una alla fine.
- All'inizio di ogni micro-batch (prima che inizi effettivamente l'elaborazione dei dati), viene calcolato un offset in base ai nuovi dati che possono essere letti dal sistema di destinazione. Questo offset viene reso persistente in un log durevole chiamato "offsetLog" nella directory dei checkpoint. Questo offset viene utilizzato per calcolare l'intervallo di dati che verrà elaborato in "questo" micro-batch.
- Alla fine di ogni micro-batch, una voce viene resa persistente nel log durevole chiamato "commitLog" per indicare che "questo" micro-batch è stato elaborato correttamente.
La Figura 3 di seguito descrive le attuali attività operative di gestione dell'offset che si verificano.
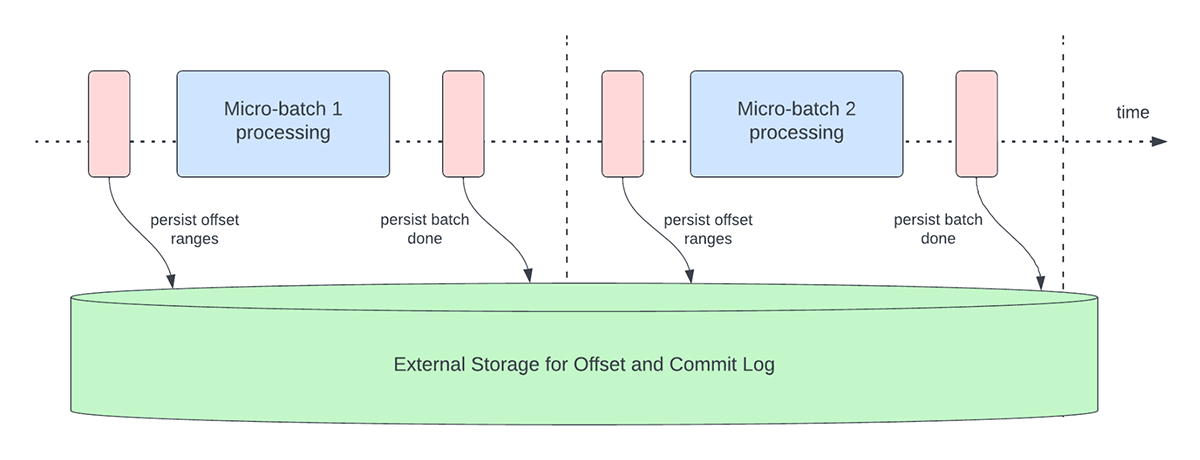
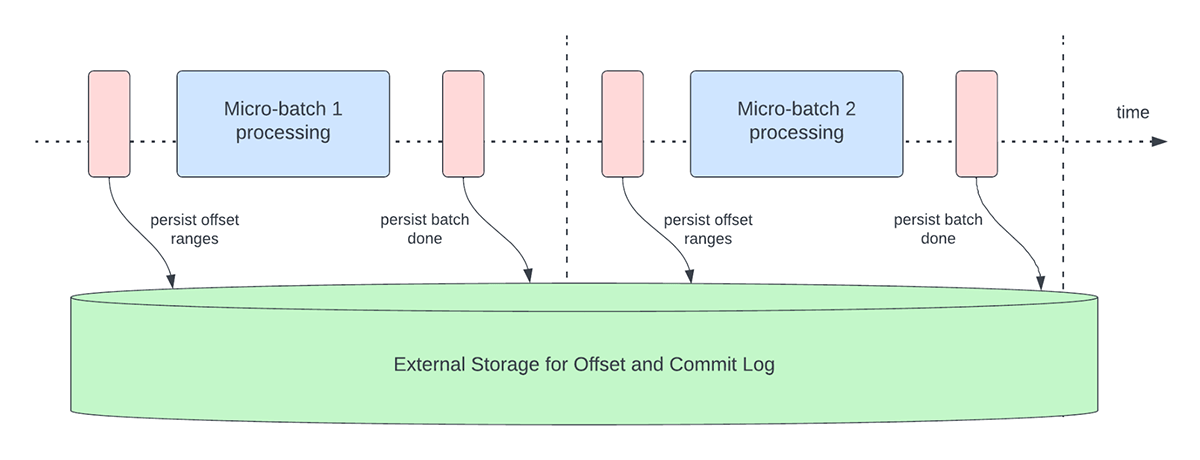{kind=link}
Un'altra attività operativa di gestione degli offset viene eseguita alla fine di ogni micro-batch. Questa operazione è un'operazione di pulizia per eliminare/troncare le voci vecchie e non necessarie sia da offsetLog che da commitLog, in modo che questi log non crescano in modo illimitato.
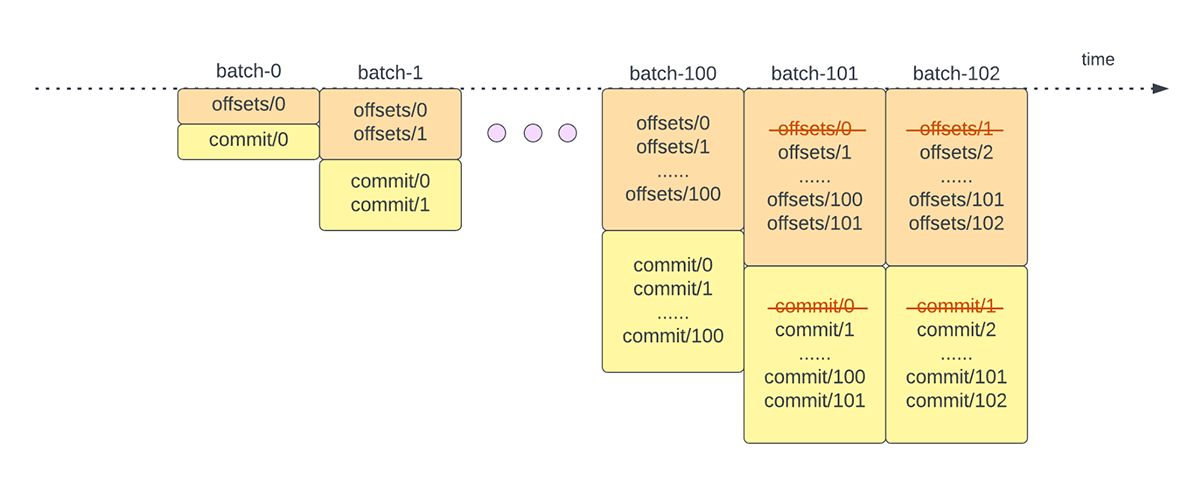
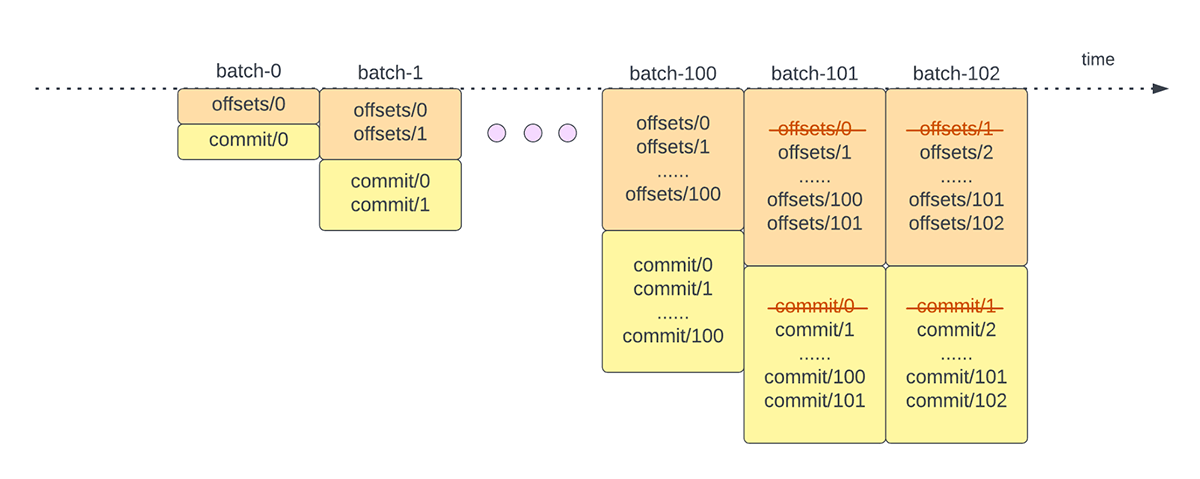{kind=link}
Queste attività operative di gestione dell'offset vengono eseguite sul percorso critico e in linea con l'elaborazione effettiva dei dati. Ciò significa che la durata di queste attività operative influisce direttamente sulla latenza di elaborazione e che nessuna elaborazione dei dati può avvenire finché tali attività operative non sono completate. Questo influisce direttamente anche sull'utilizzo del cluster.
Grazie alle nostre attività operative di benchmarking e profilazione delle prestazioni, abbiamo riscontrato che queste operazioni di gestione degli offset possono richiedere la maggior parte del tempo di elaborazione, soprattutto per le pipeline stateless a stato singolo, spesso utilizzate nei casi d'uso di alerting operativo e monitoraggio in tempo reale.
Miglioramenti delle prestazioni in Structured Streaming
Tracciamento asincrono dell'avanzamento
Questa funzionalità è stata creata per risolvere l'overhead di latenza della persistenza degli offset ai fini del monitoraggio dell'avanzamento. Questa funzionalità, se abilitata, consentirà alle pipeline di Structured Streaming di eseguire il checkpoint dei progressi, ovvero di aggiornare offsetLog e commitLog, in modo asincrono e in parallelo all'effettiva elaborazione dei dati all'interno di un micro-batch. In altre parole, l'elaborazione effettiva dei dati non sarà bloccata da queste attività operative di gestione dell'offset, il che migliorerà in modo significativo la latenza delle applicazioni. La Figura 5 di seguito descrive questo nuovo comportamento per la gestione dell'offset.
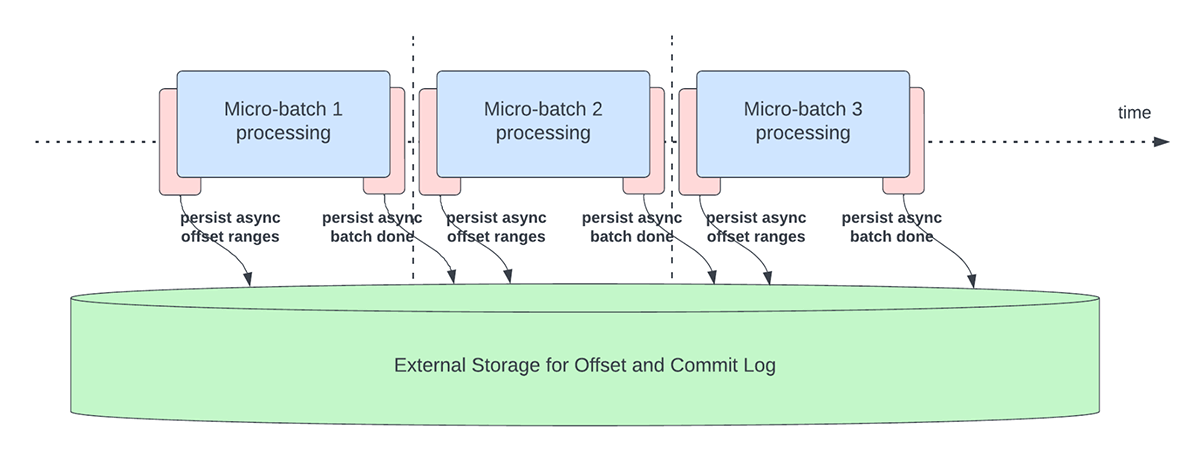
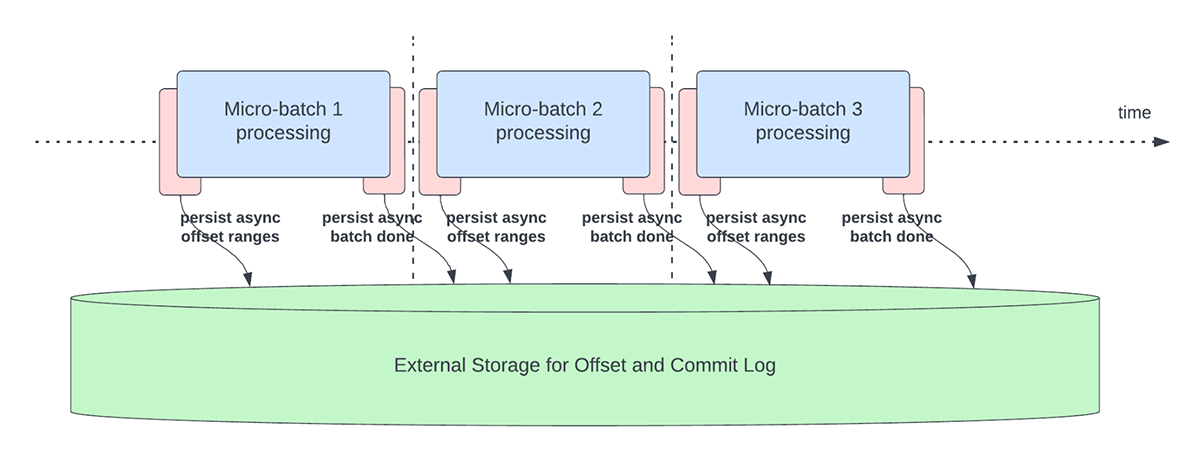{kind=link}
Insieme all'esecuzione asincrona degli aggiornamenti, gli utenti possono configurare la frequenza con cui viene eseguito il checkpoint dell'avanzamento. Ciò sarà utile per gli scenari in cui le attività operative di gestione degli offset si verificano a una velocità superiore a quella con cui possono essere elaborate. Ciò si verifica nelle pipeline quando il tempo impiegato per l'effettiva elaborazione dei dati è significativamente inferiore rispetto a queste attività operative di gestione degli offset. In tali scenari, si verificherà un arretrato sempre crescente di gestione delle attività operative degli offset. Per arginare questo arretrato crescente, l'elaborazione dei dati dovrà essere bloccata o rallentata, il che riporterà essenzialmente il comportamento di elaborazione a essere lo stesso di come se queste attività operative di gestione degli offset fossero eseguite inline con l'elaborazione dei dati. Un utente in genere non dovrà configurare o impostare la frequenza dei checkpoint, poiché verrà impostato un valore default adeguato. È importante notare che il tempo di ripristino in caso di errore aumenterà con l'aumentare dell'intervallo di tempo dei checkpoint. In caso di errore, una pipeline deve rielaborare tutti i dati precedenti all'ultimo checkpoint riuscito. Gli utenti possono considerare questo compromesso tra una latenza inferiore durante l'elaborazione regolare e il tempo di ripristino in caso di errore.
Vengono introdotte le seguenti configurazioni per abilitare e configurare questa funzionalità:
asyncProgressTrackingEnabled - abilita o disabilita il monitoraggio asincrono dell'avanzamentoDefault: false
asyncProgressCheckpointingInterval - l'intervallo in cui eseguiamo il commit degli offset e i commit di completamentoDefault: 1 minuto
L'esempio di codice seguente illustra come abilitare questa funzionalità:
Si noti che questa funzionalità non funzionerà con Trigger.once o Trigger.availableNow, poiché questi trigger eseguono le pipeline in modalità manuale/pianificata. Pertanto, il tracciamento asincrono dei progressi non sarà rilevante. La query non riuscirà se inviata utilizzando uno dei trigger sopra menzionati.
Applicabilità e limitazioni
Ci sono un paio di limitazioni nelle versioni attuali che potrebbero cambiare con l'evoluzione della funzionalità:
- Attualmente, il tracciamento asincrono dell'avanzamento è supportato solo nelle pipeline stateless che utilizzano Kafka Sink.
- L'elaborazione end-to-end "exactly once" non sarà supportata con questo tracciamento asincrono dell'avanzamento, perché gli intervalli di offset per un batch possono essere modificati in caso di errore. Tuttavia, molti sink, come il sink Kafka, supportano solo garanzie "at-least once", quindi questa potrebbe non essere una nuova limitazione.
Eliminazione asincrona dei log
Questa funzionalità è stata creata per risolvere l'overhead di latenza delle pulizie dei log eseguite in linea all'interno di un micro-batch. Rendendo asincrona e in background questa operazione di pulizia/eliminazione dei Logs, è possibile rimuovere l'overhead di latenza che questa operazione comporterebbe sull'effettiva elaborazione dei dati. Inoltre, queste eliminazioni non devono essere eseguite a ogni micro-batch e possono avvenire con una pianificazione più flessibile.
Si noti che questa funzionalità/miglioramento non presenta alcuna limitazione sul tipo di pipeline o carichi di lavoro che possono utilizzarla, pertanto questa funzionalità sarà abilitata in background per impostazione predefinita per tutte le pipeline di Structured Streaming.
Benchmark
Per comprendere le prestazioni del tracciamento asincrono dei progressi e dell'eliminazione asincrona dei log, abbiamo creato alcuni benchmark. Il nostro obiettivo con i benchmark è comprendere la differenza di prestazioni offerta dalla gestione degli offset migliorata in una pipeline di streaming end-to-end. I benchmark sono suddivisi in due categorie:
- Da Rate Source a Stat Sink - In questo benchmark, abbiamo utilizzato un source e un sink di base, stateless e per la raccolta di statistiche, utile a determinare la differenza nelle prestazioni del motore principale senza dipendenze esterne.
- Da origine Kafka a sink Kafka - Per questo benchmark, spostiamo i dati da un'origine Kafka a un sink Kafka. Questo è simile a uno scenario reale per vedere quale sarebbe la differenza in uno scenario di produzione.
Per entrambi questi benchmark, abbiamo misurato la latenza end-to-end (50° percentile, 99° percentile) a diverse velocità di input dei dati (100.000 eventi/sec, 500.000 eventi/sec, 1 milione di eventi/sec).
Metodologia di benchmark
La metodologia principale consisteva nel generare dati da un'origine a un throughput costante specifico. I record generati contengono informazioni su quando sono stati creati. Sul lato sink, usiamo la libreria Apache DataSketches per raccogliere la differenza tra il momento in cui il sink elabora il record e il momento in cui è stato creato in ogni batch. Questo viene utilizzato per calcolare la latenza. Abbiamo utilizzato lo stesso cluster con lo stesso numero di nodi per tutti gli esperimenti.
Nota: per il benchmark di Kafka, abbiamo riservato alcuni nodi di un cluster per l'esecuzione di Kafka e la generazione dei dati da fornire a Kafka. Calcoliamo la latenza di un record solo dopo che il record è stato pubblicato con successo in Kafka (sul sink)
Benchmark da Rate Source a Stat Sink
Per questo benchmark, abbiamo utilizzato un cluster Spark di 7 nodi worker (i3.2xlarge - 4 core, 61 GiB di memoria) utilizzando il Databricks runtime (11.3). Abbiamo misurato la latenza end-to-end per i seguenti scenari per quantificare il contributo di ogni miglioramento.
- Structured Streaming attuale - questa è la latenza di base senza nessuno dei miglioramenti sopra menzionati
- Eliminazione asincrona dei log: misura la latenza dopo aver applicato solo l'eliminazione asincrona dei log
- Avanzamento asincrono - misura la latenza dopo l'applicazione del tracciamento asincrono dell'avanzamento
- Avanzamento asincrono + Eliminazione asincrona del log - misura la latenza dopo l'applicazione di entrambi i miglioramenti
I risultati di questi esperimenti sono mostrati nelle Figure 6, 7 e 8. Come puoi vedere, l'eliminazione asincrona dei log riduce costantemente la latenza di circa il 50%. Allo stesso modo, il tracciamento asincrono dei progressi da solo migliora la latenza di circa il 65%. Combinati, la latenza si riduce dell'85-86% e scende al di sotto dei 100 ms.
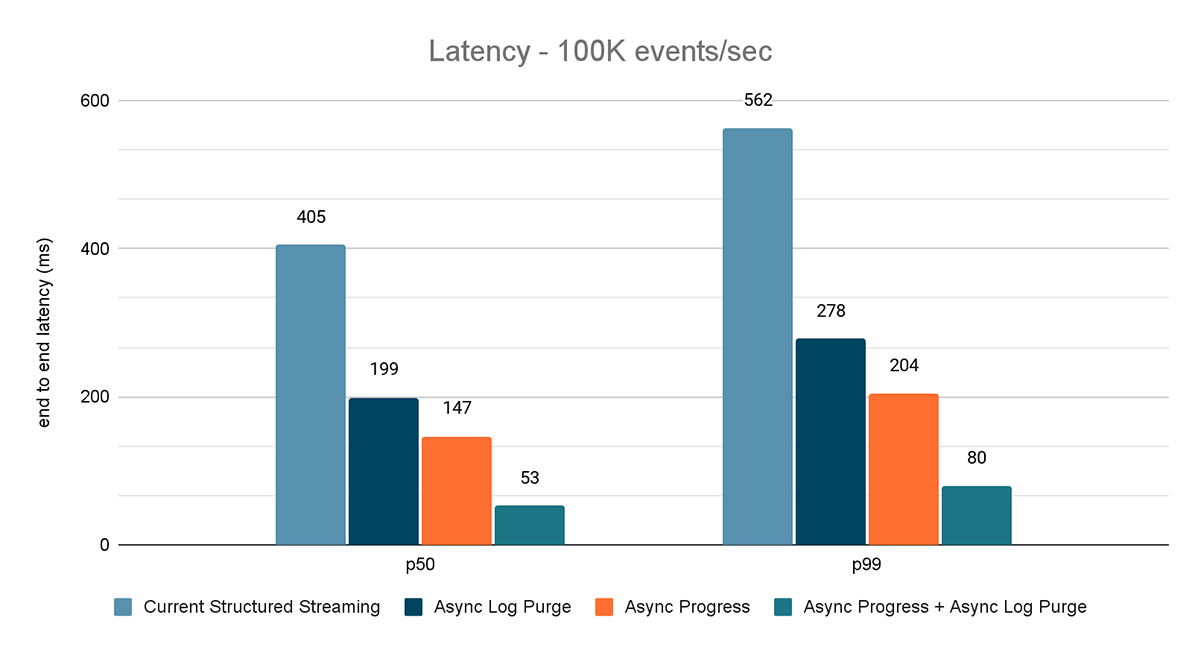
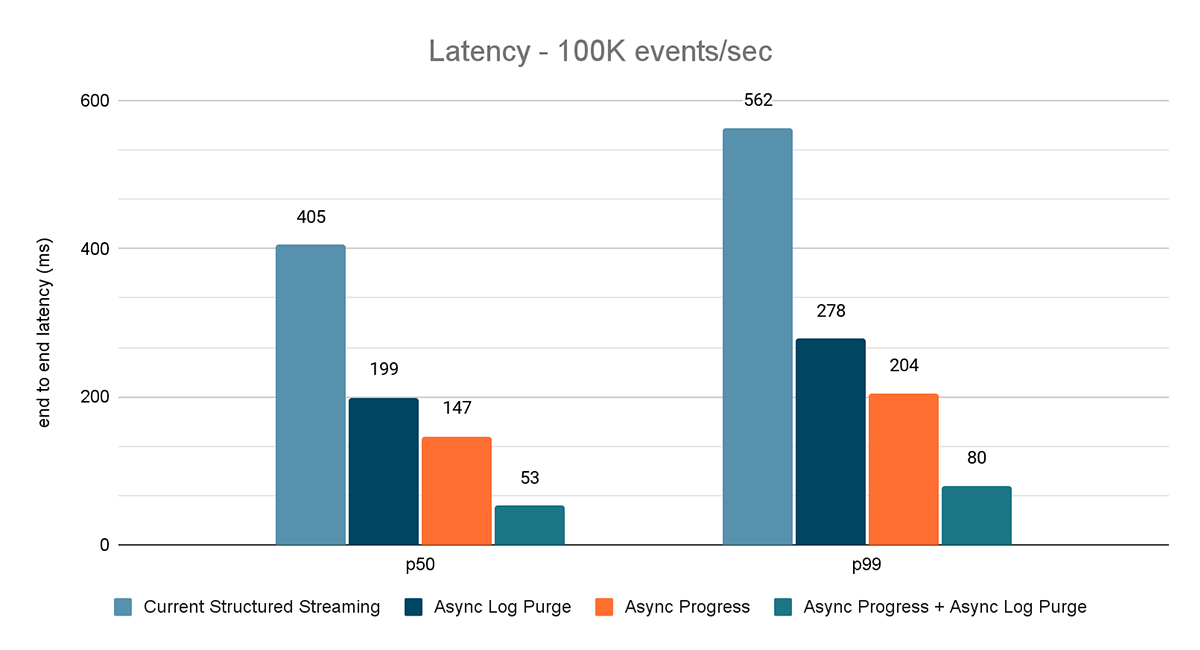{kind=link}
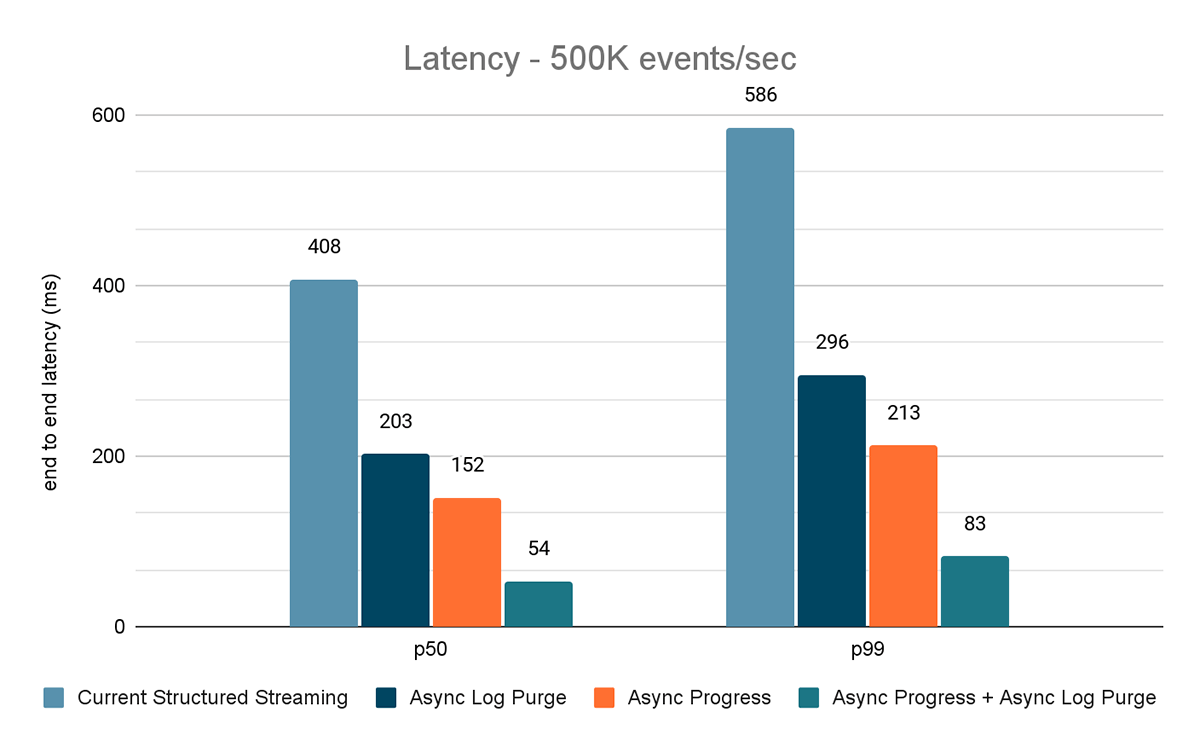
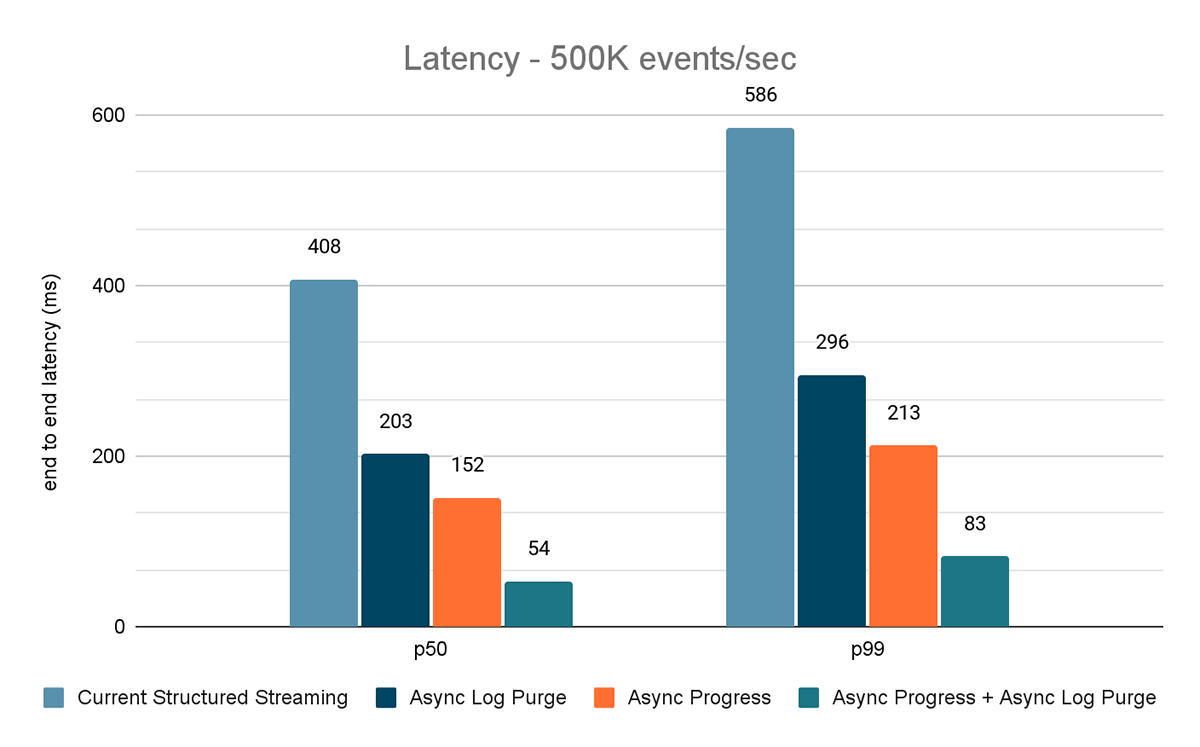{kind=link}
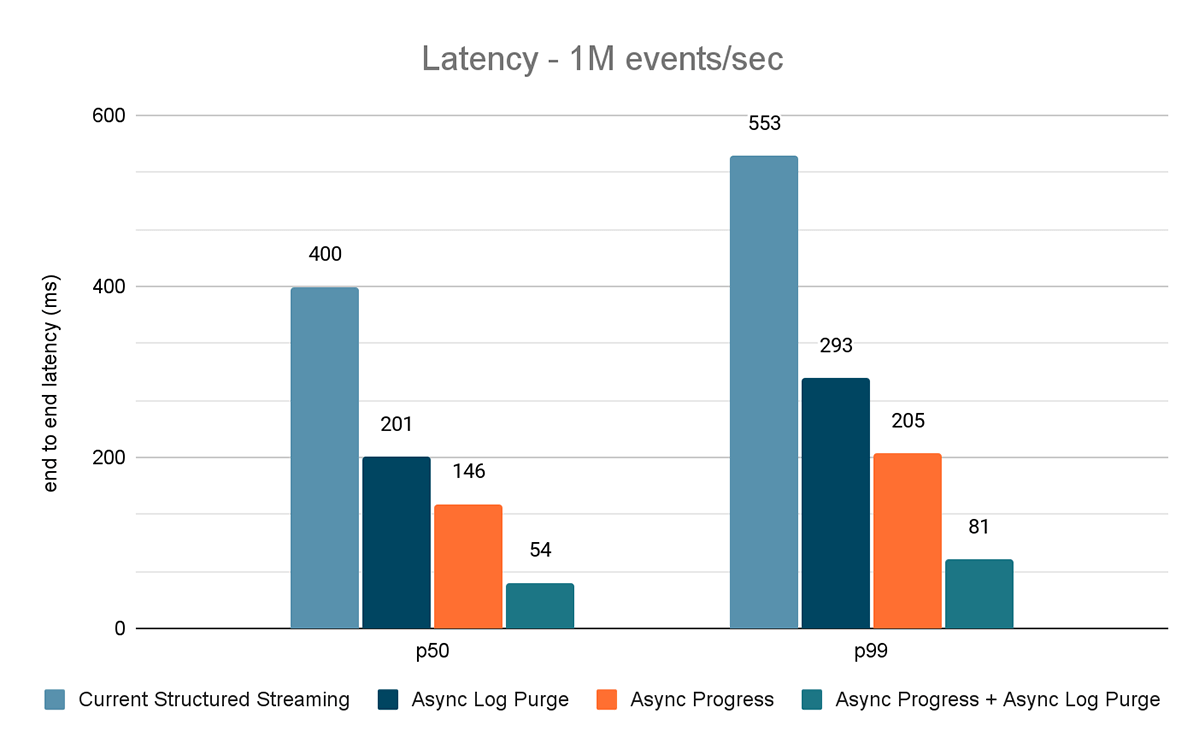
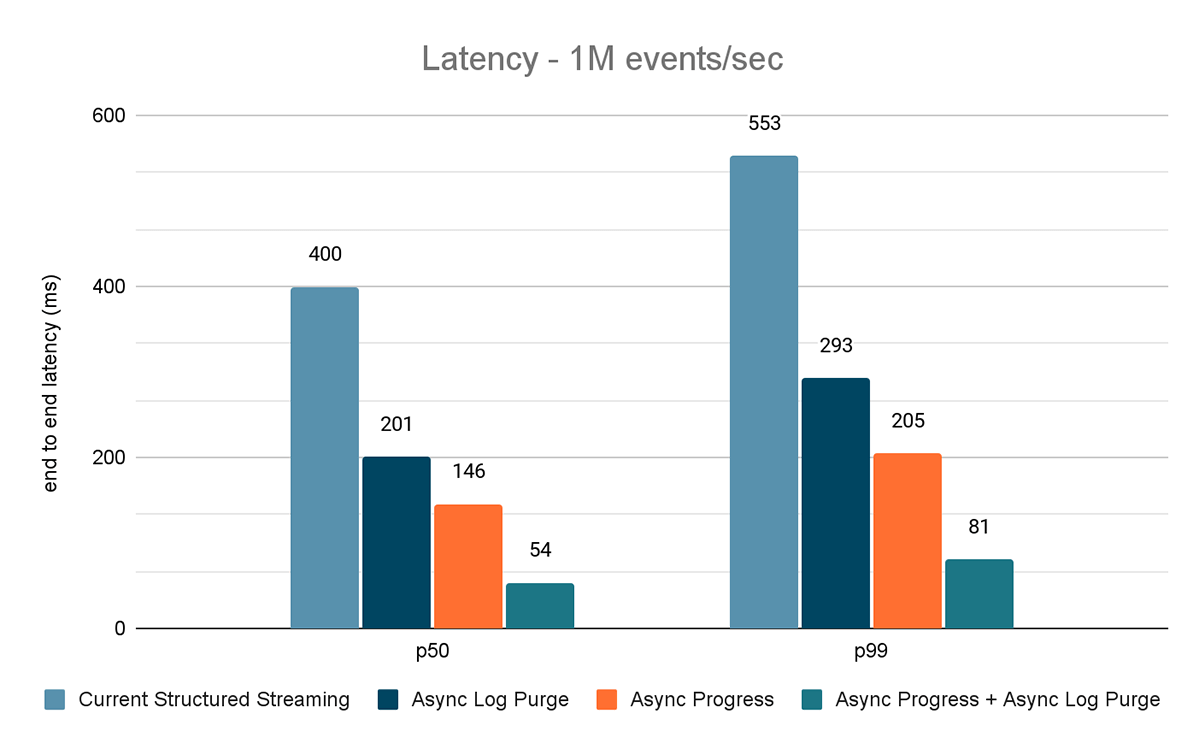{kind=link}
Benchmark da Kafka Source a Kafka Sink
Per i benchmark di Kafka, abbiamo utilizzato un cluster Spark di 5 nodi worker (i3.2xlarge - 4 core, 61 GiB di memoria), un cluster separato di 3 nodi per eseguire Kafka e altri 2 nodi per generare i dati aggiunti al source Kafka. Il nostro topic Kafka ha 40 partizioni e un fattore di replica di 3.
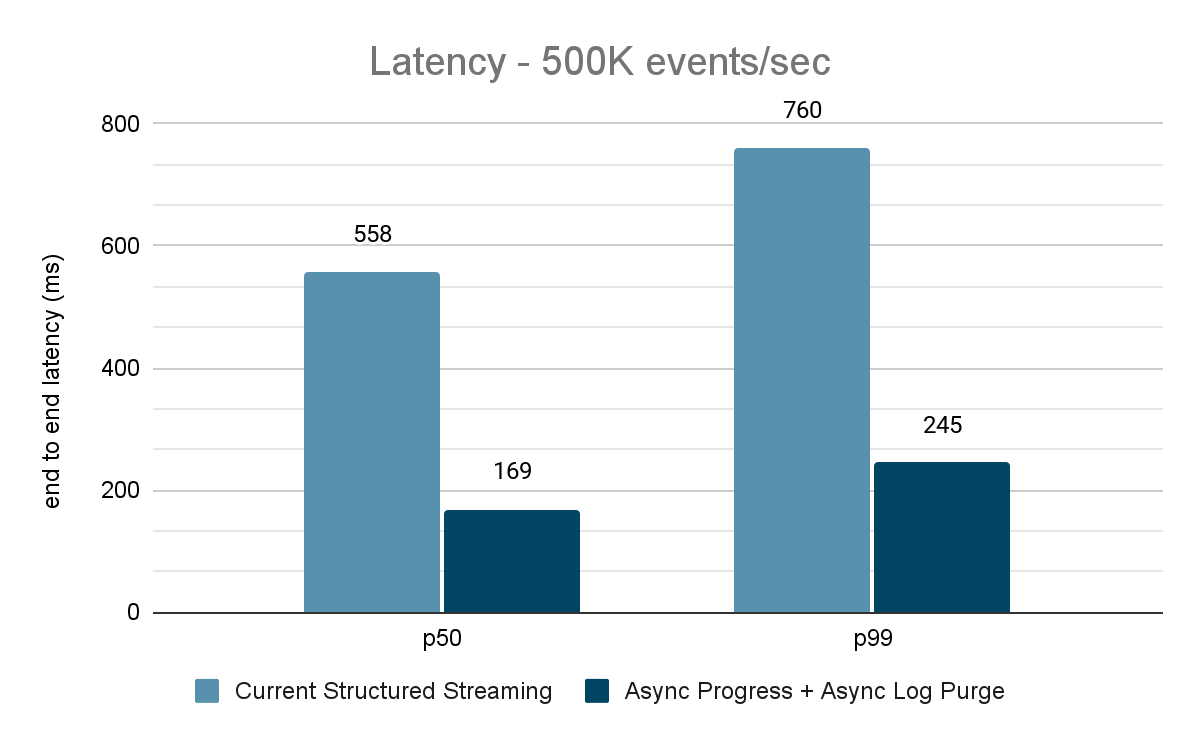
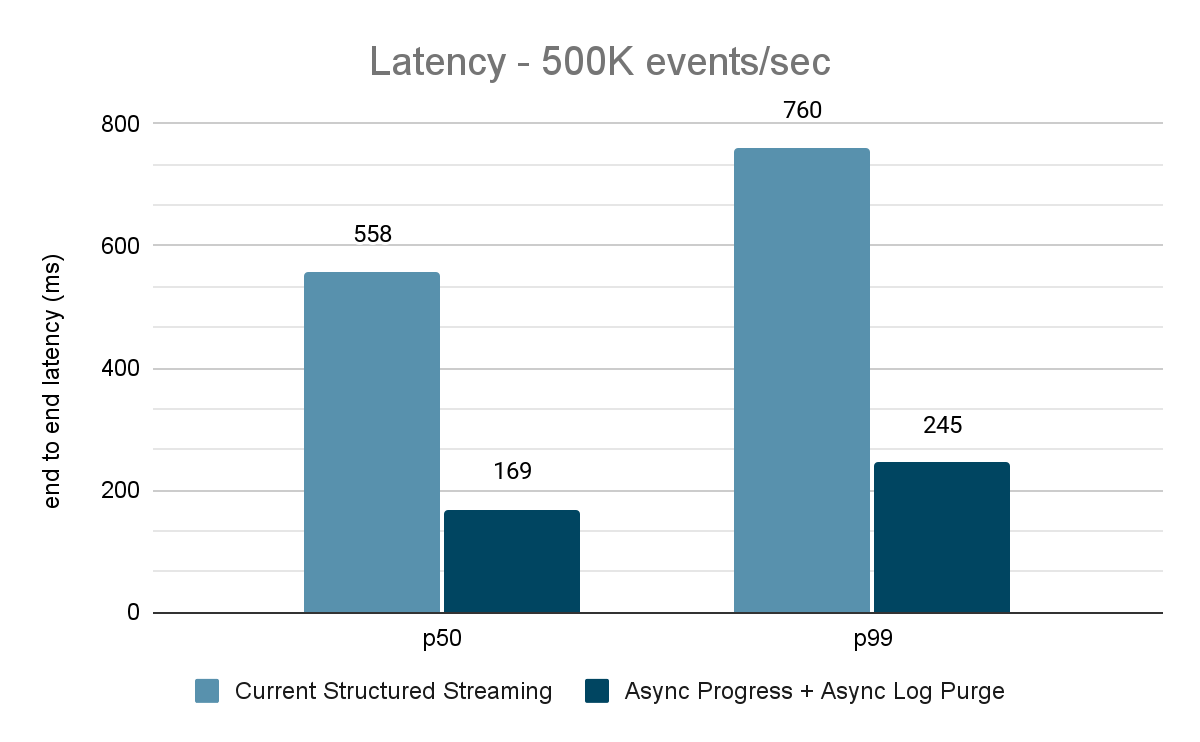
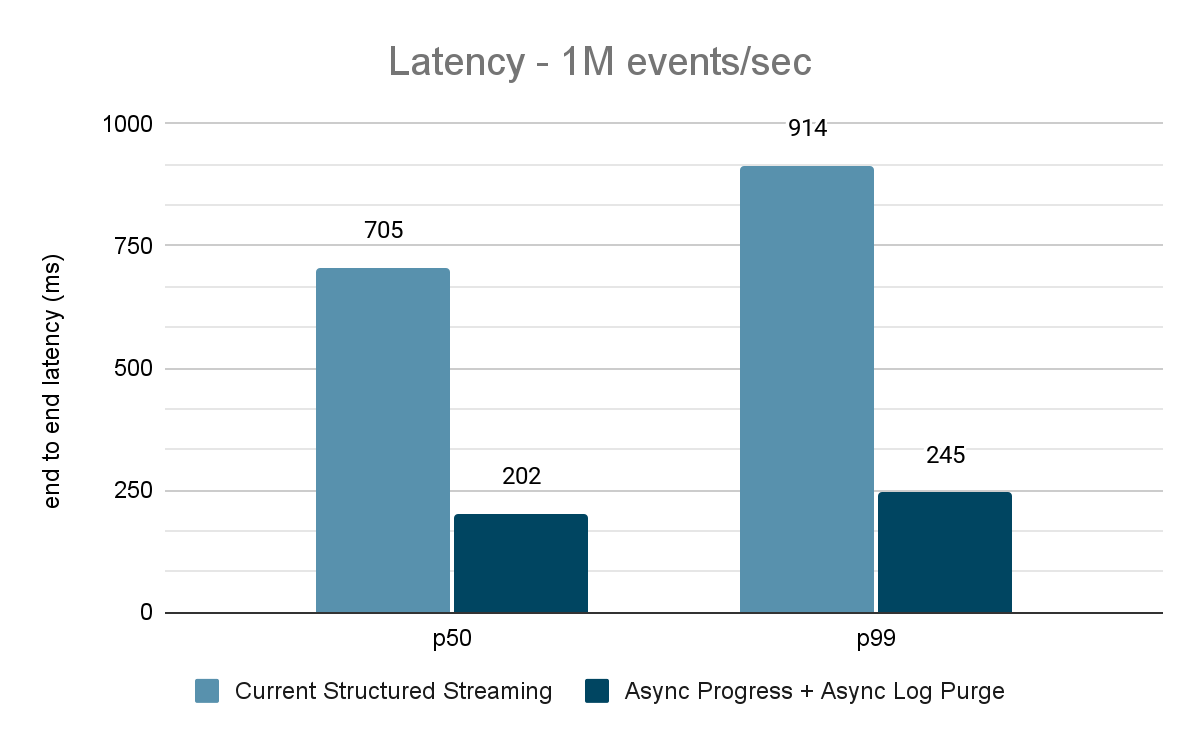
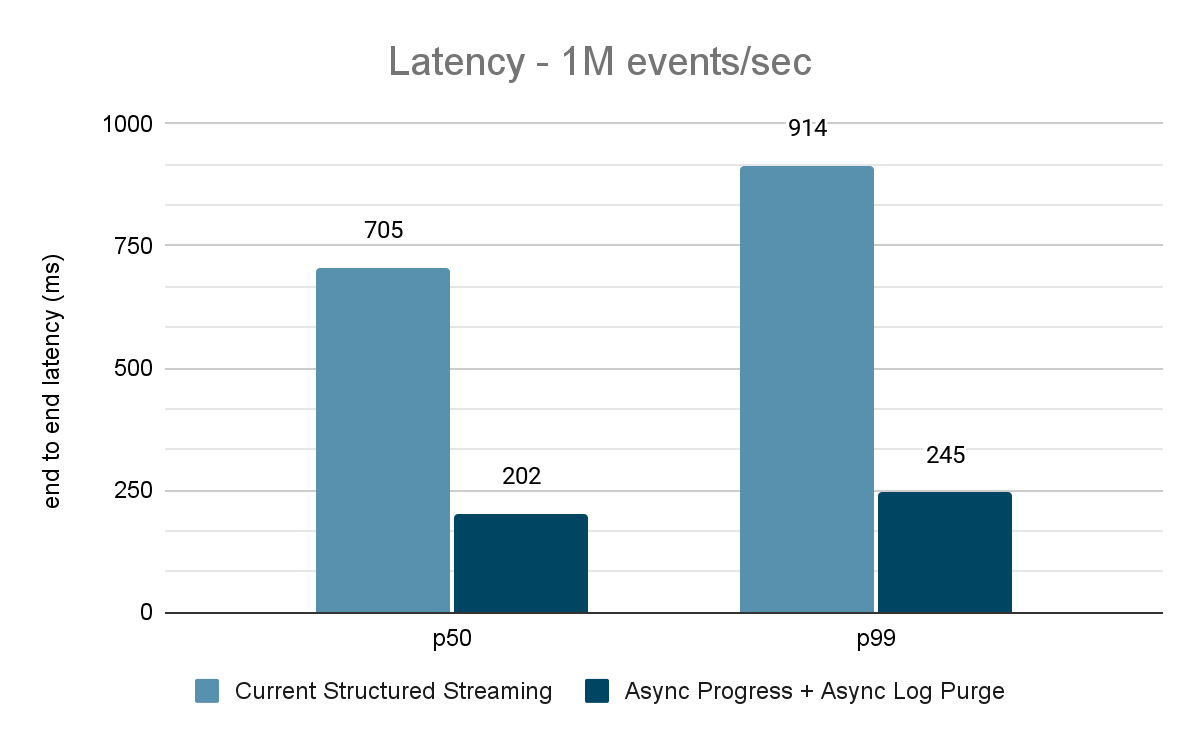
Il generatore di dati pubblica i dati in un topic Kafka e la pipeline di streaming strutturato consuma i dati e li ripubblica in un altro topic Kafka. I risultati della valutazione delle prestazioni sono mostrati nelle Figure 9, 10 e 11. Come si può vedere, dopo aver applicato l'avanzamento asincrono e l'eliminazione asincrona dei log, la latenza si riduce del 65-75%, ovvero di 3-3,5 volte con throughput diversi.
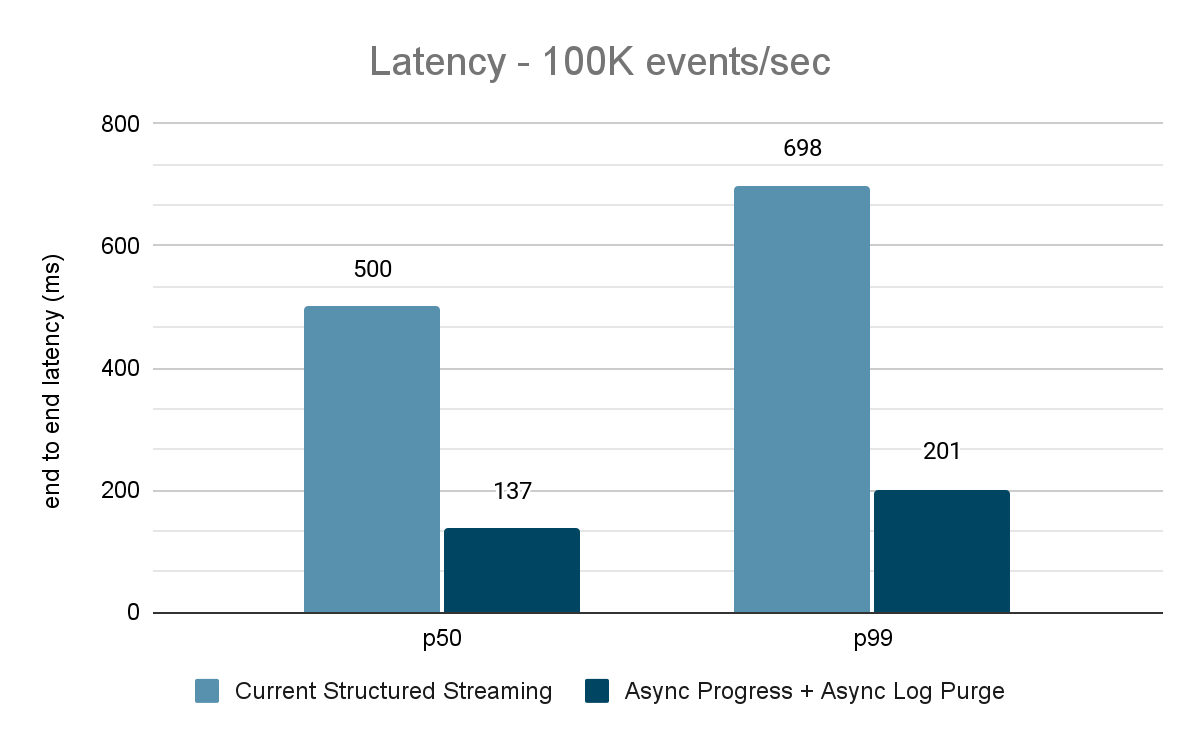
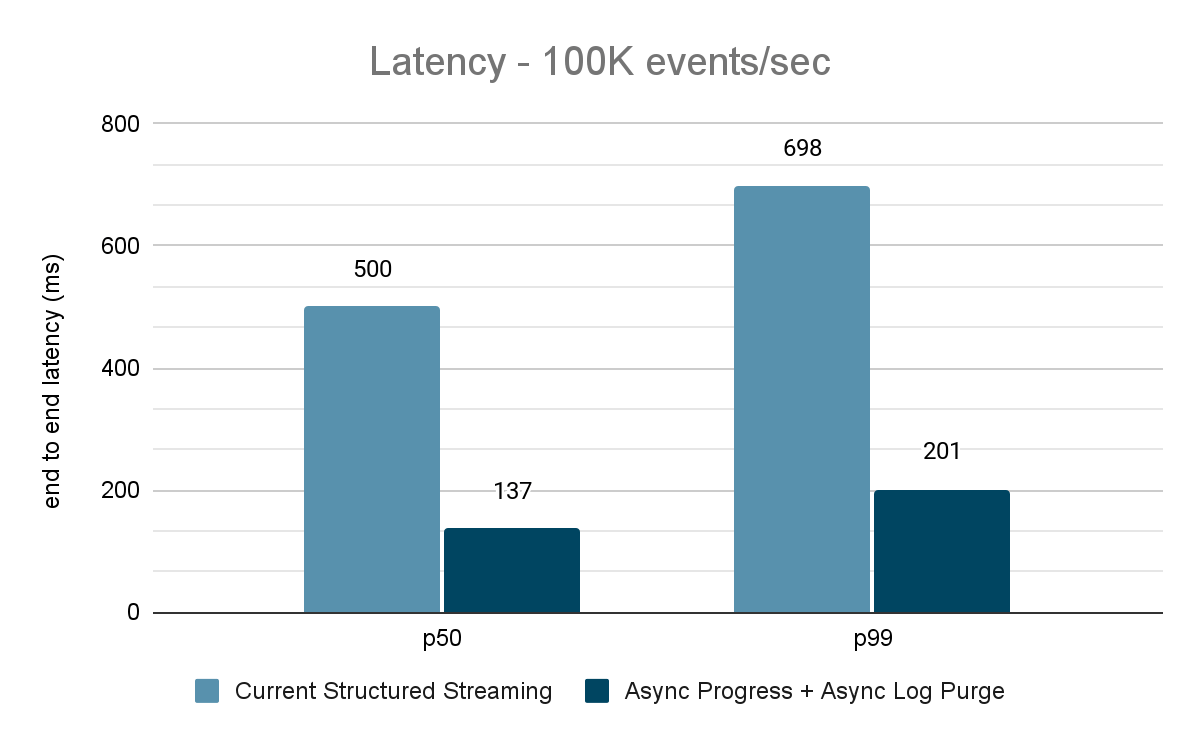{kind=link}
{kind=link}
{kind=link}
Riepilogo dei risultati delle prestazioni
Con il nuovo tracciamento asincrono dell'avanzamento e l'eliminazione asincrona dei log, possiamo vedere che entrambe le configurazioni riducono la latenza fino a 3 volte. Lavorando insieme, la latenza si riduce notevolmente per tutti i throughput. I grafici mostrano anche che la quantità di tempo risparmiata è solitamente una quantità di tempo costante (200 - 250 ms per ogni configurazione) e insieme possono ridurre i tempi di circa 500 ms su tutta la linea (lasciando tempo sufficiente per la pianificazione dei batch e l'elaborazione delle query).
Disponibilità
Questi miglioramenti delle prestazioni sono disponibili nella Databricks Lakehouse Platform da DBR 11.3 in poi. L'eliminazione asincrona dei log è abilitata per default in DBR 11.3 e nelle versioni successive. Inoltre, questi miglioramenti sono stati conferiti a Open Source Spark e sono disponibili da Apache Spark 3.4 in poi.
Lavori futuri
Attualmente esistono alcune limitazioni ai tipi di carichi di lavoro e sink supportati dalla funzionalità di tracciamento asincrono dell'avanzamento. In futuro, prevediamo di supportare più tipi di carichi di lavoro con questa funzionalità.
Questo è solo l'inizio delle funzionalità a bassa latenza prevedibile che stiamo sviluppando in Structured Streaming nell'ambito del Project Lightspeed. Inoltre, continueremo a eseguire benchmark e profiling di Structured Streaming per trovare altre aree di miglioramento. Restate sintonizzati!
Unisciti a noi al Data and AI Summit a San Francisco, dal 26 al 29 giugno, per saperne di più su Project Lightspeed e sullo streaming dei dati sulla Databricks Lakehouse Platform.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.