Da Legacy a Lakehouse: Come Mazda ha accelerato GenAI per le operazioni di assistenza tecnica
Come un team snello ha creato un assistente GenAI governato utilizzando RAG, Unity Catalog e AI Search
di Tim Marx (Mazda), Foon Hoe Campbell-Wong (Mazda), Jiayi Wu, Arthur Dooner e Olivia Zhang
- Come Mazda ha utilizzato il Databricks Lakehouse per unire cronologia di assistenza, diagnostica e documenti come base per GenAI
- Come il team ha progettato l'assistente GenAI, inclusa la ricerca nei documenti corretti e la logica di condivisione tra l'interfaccia utente e l'agente
- Come Mazda è passata da test GenAI ad hoc a valutazioni e casi di test ripetibili utilizzando MLflow
Le organizzazioni di assistenza automobilistica sono sotto pressione. I volumi di chiamate continuano ad aumentare, i veicoli elettrici introducono nuova complessità diagnostica e le auto connesse generano più dati di quanti gli agenti della hotline di assistenza possano realisticamente analizzare. Ogni anno porta centinaia di documenti di informazioni di servizio (SI), ognuno con procedure e condizioni uniche. Quando qualcosa cambia, gli agenti della hotline di assistenza hanno bisogno di tempo per assimilarlo prima di poter guidare con sicurezza i tecnici attraverso problemi sconosciuti. Quel ritardo è importante quando un cliente è in attesa.
Mazda aveva già gli ingredienti grezzi per risolvere questo problema: un crescente lakehouse di garanzie, richiami, codici diagnostici, storico di assistenza e veicoli, nonché una libreria in costante aggiornamento di documenti di servizio. La sfida era riunire questi asset in un modo che migliorasse la capacità degli agenti di svolgere il proprio lavoro con accuratezza, coerenza e fiducia.
È qui che è intervenuto Databricks. Il team di data science di Mazda si è mosso velocemente e ha imparato facendo, passando dal kickoff a un concetto funzionante in circa otto settimane. Non c'è stata una lunga fase di pianificazione. Il team ha costruito, testato, rotto cose e aggiustato man mano, fornendo un pilota che ha avuto un impatto e un valore reali per Mazda.
Punto di partenza: un team snello con grandi ambizioni
Questo progetto è stata una delle prime iniziative GenAI end-to-end di Mazda costruita interamente sulla sua nuova piattaforma dati cloud. Il team era piccolo, due data scientist che iteravano rapidamente, e gli strumenti erano agli inizi. Le pipeline di dati dovevano essere costruite. I documenti dovevano essere estratti e trasformati in indici di ricerca vettoriale. Gli esperimenti vivevano in notebook isolati e il successo dipendeva più dalla memoria che dalla tracciabilità.
Per un team così snello, l'overhead dell'infrastruttura doveva essere minimo. Questo è stato un fattore importante nella scelta di Databricks. La piattaforma ha permesso agilità: niente gestione di database vettoriali, niente configurazione di framework di calcolo distribuiti, niente orchestrazione personalizzata, niente servizi di collante per mettere tutto insieme. L'attenzione è sulla creazione di valore, non sull'infrastruttura.
Costruzione del pilota
All'inizio del pilota, il team si è concentrato su un design di Retrieval Augmentation Generation (RAG), con l'obiettivo principale di collegare un LLM con il nostro corpus personalizzato. Presto, Mazda ha notato che i tester volevano spesso che gli agenti avessero prima un quadro completo del veicolo: la sua storia di assistenza, i richiami aperti, le precedenti escalation della hotline, lo stato della garanzia.
Questa osservazione ha plasmato una scelta architetturale deliberata: il frontend e l'agente condividono codice e strumenti. L'accesso ai dati del veicolo, la trasformazione e la logica di prompting sono implementate una volta e utilizzate in modo identico sia dall'interfaccia Streamlit che dall'endpoint dell'agente distribuito.
Quando un agente di assistenza inserisce un VIN all'inizio di una sessione, il frontend pre-carica il contesto completo del veicolo (storia delle riparazioni, escalation della hotline, dati di garanzia, stato dei richiami) e lo inietta nel prompt di sistema prima che venga inviato il primo messaggio. Questo elimina le chiamate agli strumenti e fornisce interattività immediata.
D'altra parte, se l'agente AI viene invocato senza quel contesto pre-caricato, utilizzerà la stessa cassetta degli attrezzi con cui gli utenti interagiscono. L'output è strutturalmente identico in entrambi i casi, e il prompt di sistema gestisce entrambi i percorsi esplicitamente: usa il contesto iniettato se presente, chiama gli strumenti se no. Un prompt, due modalità di esecuzione, nessun comportamento anomalo tra le superfici.
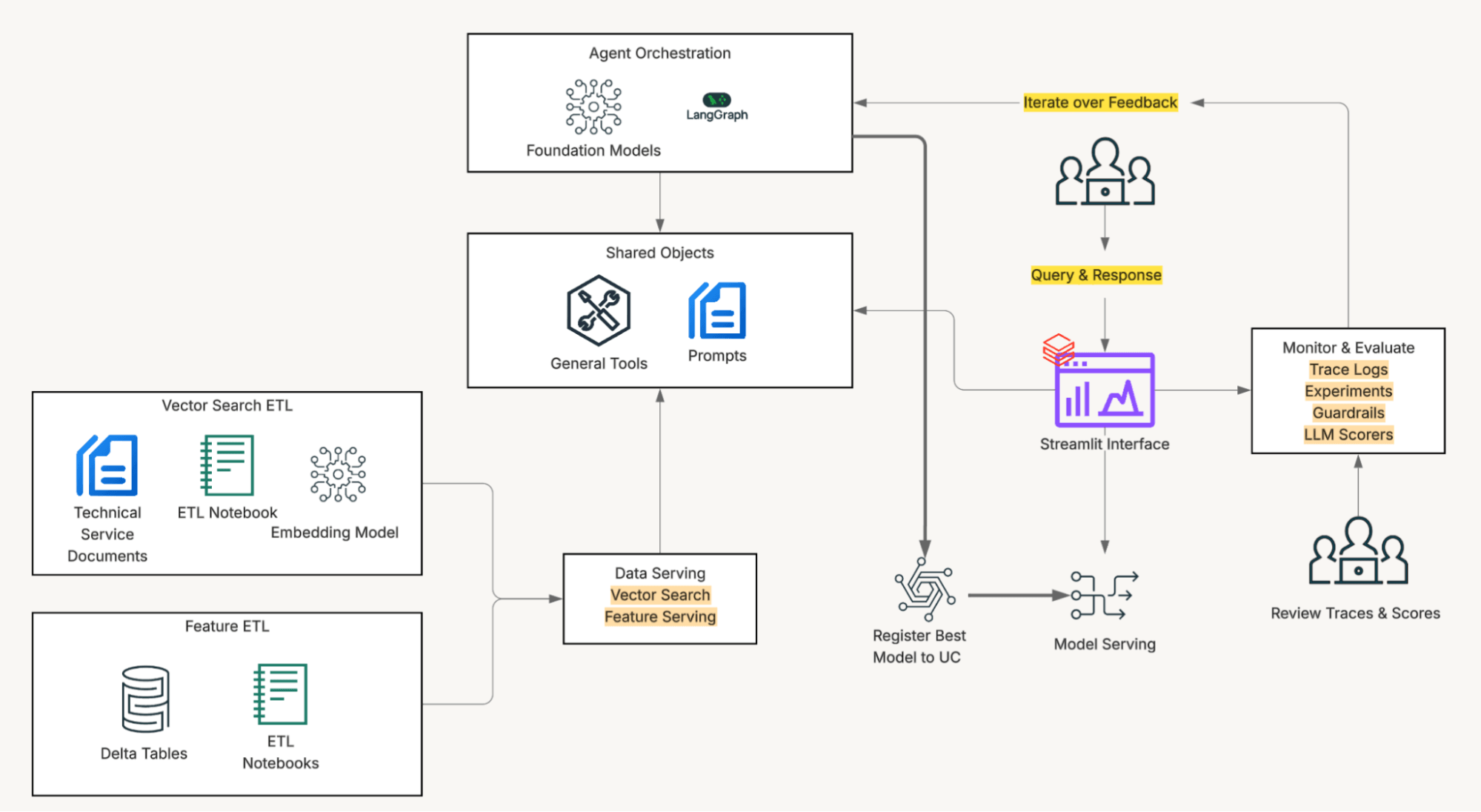
Unity Catalog
La soluzione è alimentata dal Databricks Lakehouse. Unity Catalog fornisce accesso governato ai dati su cui gli agenti di assistenza fanno affidamento ogni giorno, e dove embedding, ricerca vettoriale, chiamate agli strumenti SQL e servizio di modelli vengono eseguiti nello stesso ambiente, semplificando lo sviluppo e rimuovendo l'attrito di integrazione. Mazda ha utilizzato LLM tramite API di modelli foundation (pay-per-token) e modelli di embedding tramite l'endpoint di ricerca vettoriale gestito.
Tutto risiede all'interno di Unity Catalog: documenti SI, tabelle Delta con storico veicoli e codici diagnostici, indici di ricerca vettoriale, trasformazioni dati e modelli. La governance unificata significa la capacità di isolare l'accesso a sottoinsiemi specifici di dati, apportare modifiche al volo e osservarne immediatamente l'impatto. Quindi, Databricks Apps lega tutto insieme con un frontend Streamlit che i team di assistenza possono utilizzare senza nuove formazioni o strumenti.
Filtraggio preciso del corpus, abilitato dalle funzioni di Unity Catalog
Una ricerca vettoriale ingenua sull'intero corpus restituisce risultati semanticamente plausibili ma non necessariamente applicabili al veicolo di fronte al tecnico. Ottenere il recupero corretto significava risolvere un problema di ambito prima di risolvere un problema di pertinenza.
Il team ha implementato il filtraggio tramite funzioni definite dall'utente di Unity Catalog. Prima che venga eseguita una ricerca vettoriale, il sistema chiama una funzione UC che mappa il VIN (o il codice di errore diagnostico) al sottoinsieme dei documenti applicabili per quel veicolo, vincolando la corrispondenza semantica solo ai documenti che si applicano.
Ospitare questa logica come funzione di Unity Catalog anziché come codice applicativo significava che le regole di applicabilità vivono accanto ai dati che governano, sono accessibili sia all'agente che a qualsiasi altra applicazione downstream, e possono essere aggiornate indipendentemente dal ciclo di distribuzione dell'agente.
Dal test ad hoc allo sviluppo guidato dai test
Mazda ha testato l'applicazione con 10 agenti di assistenza tester. All'inizio del pilota, l'iterazione era guidata dal feedback: i tester segnalavano problemi, il team modificava i prompt o la configurazione di recupero e valutava il risultato informalmente. Questo ha funzionato per lo sviluppo iniziale ma non è scalato man mano che il sistema diventava più complesso.
Il framework di valutazione GenAI nativo di MLflow 3 ha cambiato il flusso di lavoro del team. MLFlow 3 fornisce un modo completo per creare set di dati di valutazione e una varietà di punteggi LLM e deterministici. Per test rapidi, i set di dati di valutazione provvisori vengono definiti in YAML prima di essere promossi a set di dati di valutazione standard. Quando i tester segnalavano una lacuna, il team la aggiungeva al set di dati di valutazione e considerava il superamento di quei casi come criterio di accettazione per qualsiasi correzione. Quando venivano aggiunte nuove funzionalità e origini dati, venivano scritti nuovi casi di valutazione prima che l'integrazione fosse accettata.
Il risultato è stato un passaggio da "sembra meglio" a "è meglio, ed ecco le prove". Le tracce degli esperimenti catturavano prompt, strategie di recupero, conteggi di token e metriche di qualità della risposta in modo che le modifiche potessero essere confrontate oggettivamente piuttosto che a memoria.
Capacità multilingue
Il rapido successo iniziale ha sollevato la domanda se la stessa architettura potesse servire altre località. Dopo aver sperimentato modelli di embedding multilingue, il team si è reso conto che l'LLM può tradurre i prompt dell'utente e la risposta finale, senza apportare modifiche all'architettura e agli strumenti principali. Ciò ha implicazioni per i piani più ampi di Mazda di espandere l'applicazione in altri mercati.
Governance
L'allineamento delle autorizzazioni tra App, cluster, warehouse, endpoint e agenti ha comportato una curva di apprendimento, ma una volta standardizzato, ha creato un pattern di governance riutilizzabile che è sicuro e applicabile a future applicazioni GenAI. Il pattern che ha funzionato: instradare tutto l'accesso tramite il principal di servizio dell'endpoint di servizio e definire le concessioni a livello di catalogo e schema ai gruppi di controllo degli accessi basati sui ruoli. Una volta stabilito, è diventato riutilizzabile: l'onboarding di un nuovo modello o origine dati significava concedere l'accesso allo stesso principal di servizio contro lo stesso schema, non rinegoziare la struttura delle autorizzazioni. In combinazione con la connettività privata per il traffico AI, questo offre a Mazda un percorso controllato e sicuro tra applicazioni e dati governati.
La partnership con il team di ingegneria sul campo di Databricks ha permesso a Mazda di muoversi più velocemente, guidata dalle migliori pratiche e anticipando gli ostacoli.
Impatto e prossimi passi
Mazda ora ha una base ripetibile per le applicazioni GenAI che combinano dati strutturati e non strutturati, il tutto all'interno del lakehouse: indici di ricerca vettoriale, servizio di modelli, valutazioni, osservabilità, governance a livello di catalogo e distribuzione frontend tramite un'app web. Avere queste capacità su un'unica piattaforma ha eliminato la necessità di mettere insieme più servizi, accelerando notevolmente lo sviluppo.
Due data scientist che hanno iniziato con notebook isolati ora gestiscono applicazioni e esperimenti AI con piena tracciabilità su Databricks. Il team sta espandendo l'approccio a flussi di lavoro diagnostici aggiuntivi ed esplorando come gli agenti generativi possano supportare tecnici, ingegneri sul campo e assistenza clienti.
Questo cambiamento non è solo tecnico. Sposta Mazda dalla reportistica descrittiva ad applicazioni intelligenti e generative costruite direttamente sui dati aziendali governati.
Takeaway
Non hai bisogno di un grande team o di una pratica MLOps matura per creare applicazioni GenAI significative. Mazda aveva due data scientist, scadenze ravvicinate e molto da imparare. Databricks come Piattaforma ha svolto più del lavoro pesante del previsto e Databricks ci ha aiutato a realizzare qualcosa di concreto, velocemente.
Nel suo nucleo, il progetto è un'espressione di omotenashi — il principio guida di Mazda di ospitalità di tutto cuore. Fornire ai tecnici di assistenza Mazda strumenti migliori li aiuta a prendersi cura meglio dei propri clienti. E ora, con questa base in atto, il team è solo all'inizio.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.