Modernizza la tua piattaforma di data engineering con Lakeflow su Azure Databricks
Databricks Lakeflow su Azure fornisce una soluzione di data ingegneria moderna, affidabile e pronta per l'uso aziendale
- Lakeflow fornisce una soluzione end-to-end unificata per i Data Engineer che lavorano su Azure Databricks, che include ingestione, trasformazione e orchestrazione dati
- Dalla sicurezza e governance unificate all'osservabilità integrata, al compute serverless, all'elaborazione in streaming e a un'interfaccia utente code-first, gli specialisti di Azure Databricks possono beneficiare di un'ampia gamma di funzionalità di Lakeflow, in combinazione con la loro piattaforma dati Azure.
- I data engineer che utilizzano Lakeflow su Azure Databricks possono creare e distribuire pipeline di dati pronte per la produzione fino a 25 volte più velocemente, riscontrare prestazioni più elevate e ottenere una riduzione dei costi ETL fino all'83%.
I data engineer sono sempre più frustrati dal numero di strumenti e soluzioni frammentati di cui hanno bisogno per costruire pipeline pronte per la produzione. Senza una piattaforma di data intelligence centralizzata o una governance unificata, i team si trovano ad affrontare molti problemi, tra cui:
- Prestazioni inefficienti e start lenti
- UI frammentata e continui cambi di contesto
- Mancanza di sicurezza e controllo granulari
- CI/CD complessi
- Visibilità limitata della provenienza dei dati
- ecc.
Il risultato? Team più lenti e minore fiducia nei dati.
Con Lakeflow su Azure Databricks, puoi risolvere questi problemi centralizzando tutte le tue attività di ingegneria dei dati su un'unica piattaforma nativa di Azure.

Una soluzione di data engineering unificata per Azure Databricks
Lakeflow è una soluzione moderna end-to-end di data ingegneria basata sulla Data Intelligence Platform di Databricks su Azure che integra tutte le funzioni essenziali di data ingegneria. Con Lakeflow, ottieni:
- Acquisizione, trasformazione e orchestrazione dei dati integrate in un unico posto
- Connettori di acquisizione gestiti
- ETL dichiarativo per uno sviluppo più rapido e semplice
- Elaborazione incrementale e in streaming per SLA più rapidi e approfondimenti più aggiornati
- Governance e lineage nativi tramite Unity Catalog, la soluzione di governance integrata di Databricks
- Osservabilità integrata per la qualità dei dati e l'affidabilità delle pipeline
E molto altro! Il tutto in un'interfaccia flessibile e modulare che si adatta alle esigenze di ogni utente, che preferisca programmare o utilizzare un'interfaccia punta e clicca.
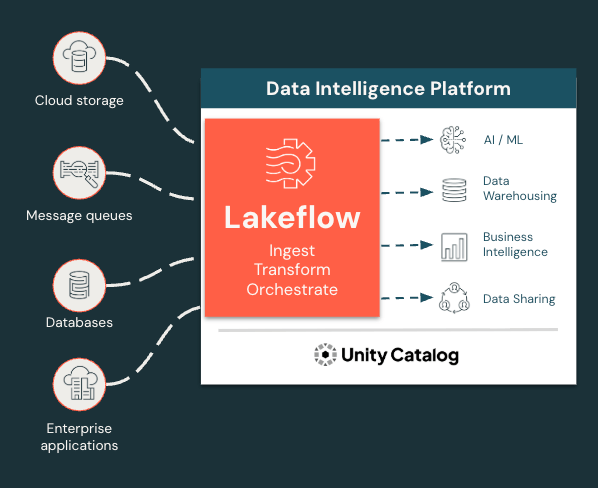
Acquisisci, trasforma e orchestra tutti i carichi di lavoro in un unico posto
Lakeflow unifica l'esperienza di ingegneria dei dati per consentirti di procedere in modo più rapido e affidabile.
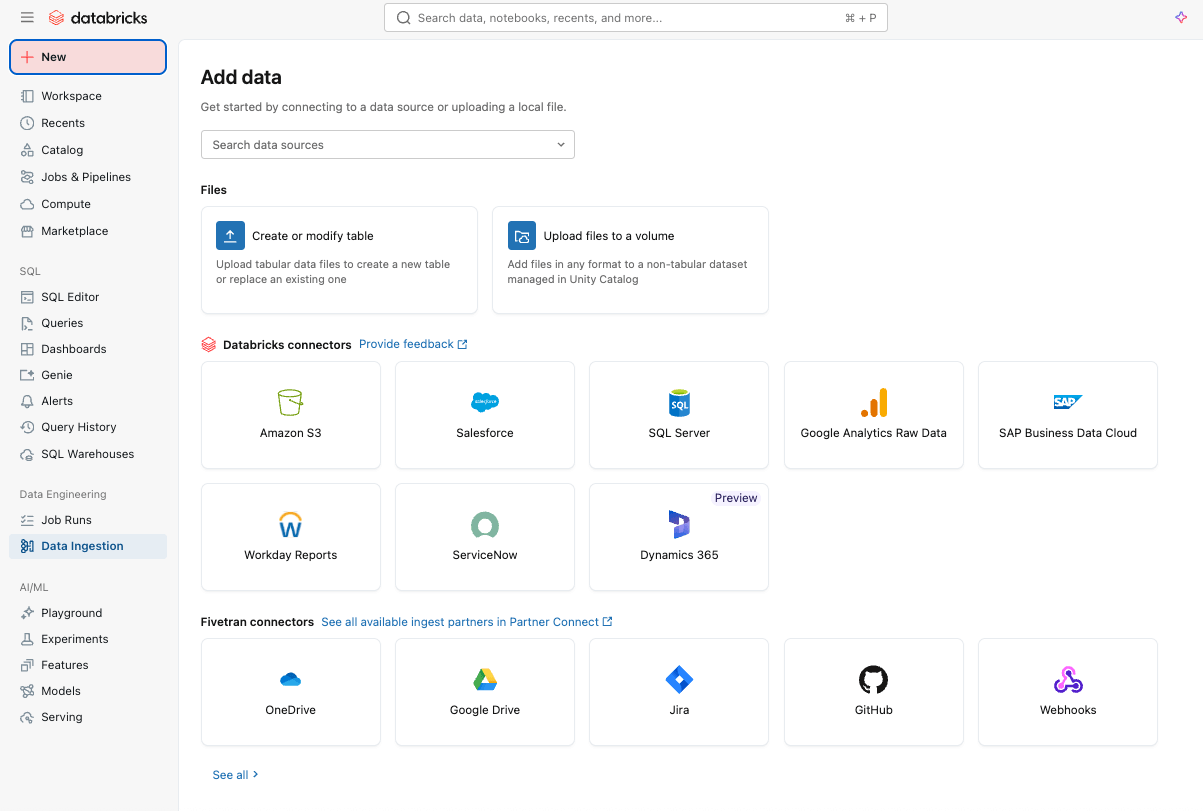
Ingestione dei dati semplice ed efficiente con Lakeflow Connect
Per iniziare, puoi acquisire facilmente i dati nella tua piattaforma con Lakeflow Connect, utilizzando un'interfaccia point-and-click o una semplice API.
È possibile eseguire l'ingestione di dati sia strutturati che non strutturati da un'ampia gamma di origini supportate in Azure Databricks, incluse le applicazioni SaaS più diffuse (ad esempio, Salesforce, Workday, ServiceNow), database (ad esempio, SQL Server), storage cloud, bus di messaggi e altro ancora. Lakeflow Connect supporta inoltre i modelli di rete di Azure, come Private Link e la distribuzione di gateway di ingestione in una VNet per i database.
Per l'ingestione in tempo reale, scopri Zerobus Ingest, un'API serverless a scrittura diretta in Lakeflow su Azure Databricks. Invia i dati degli eventi direttamente nella piattaforma dati, eliminando la necessità di un bus di messaggi per un'ingestione più semplice e a latenza ridotta.
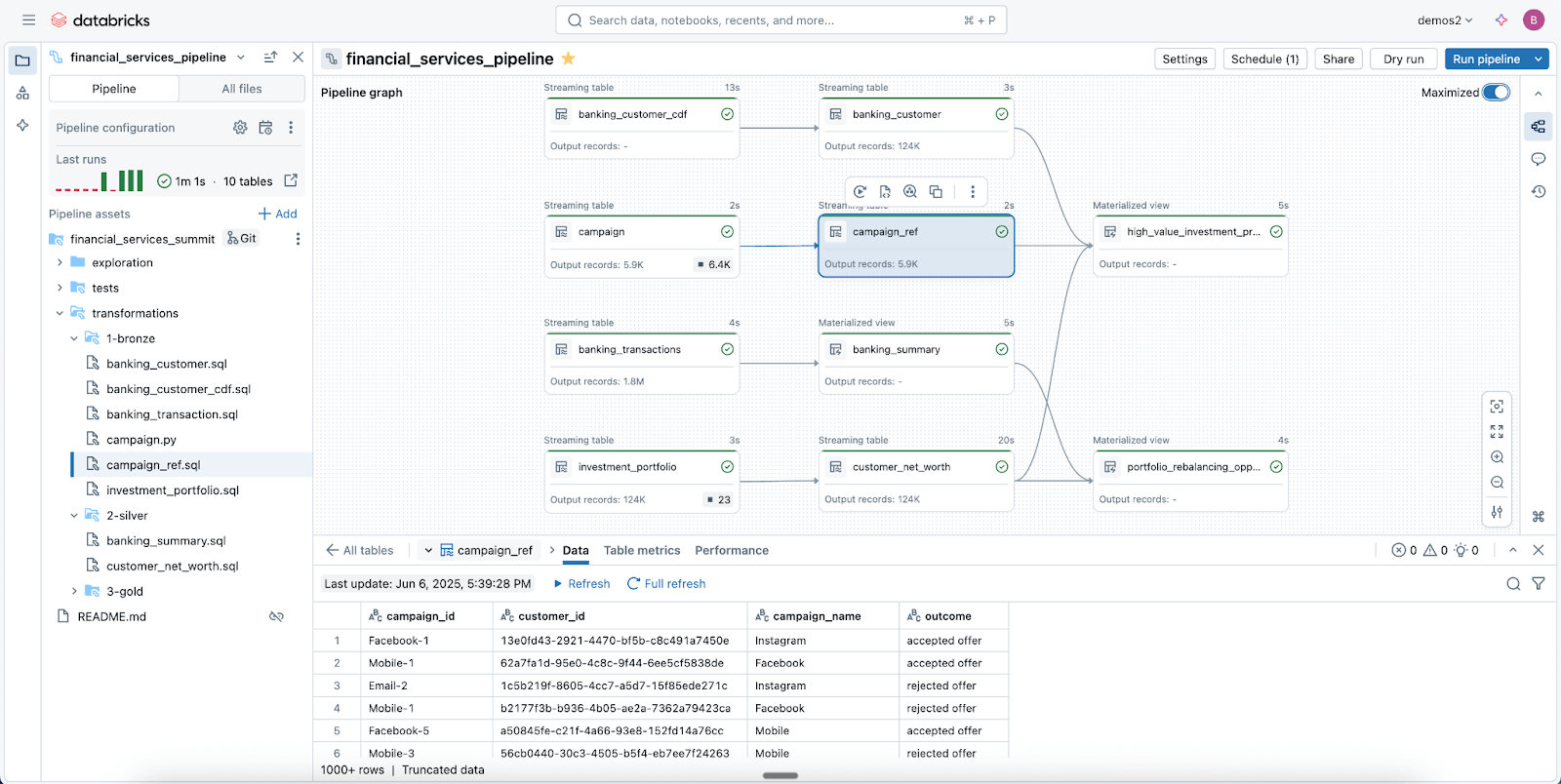
Pipeline di dati affidabili semplificate con le pipeline dichiarative di Spark
Sfrutta le Lakeflow Spark Declarative Pipelines (SDP) per pulire, modellare e trasformare facilmente i tuoi dati nel modo in cui la tua azienda ne ha bisogno.
SDP ti consente di creare ETL batch e streaming affidabili con poche righe di Python (o SQL). Dichiara semplicemente le trasformazioni di cui hai bisogno e SDP si occupa del resto, inclusi la mappatura delle dipendenze, l'infrastruttura di deployment e la qualità dei dati.
SDP minimizza i tempi di sviluppo e l'overhead operativo, codificando le best practice di ingegneria dei dati out-of-the-box e semplificando l'implementazione dell'incrementalizzazione o di pattern complessi come SCD di tipo 1 & 2 con poche righe di codice. È tutta la potenza di Spark Structured Streaming, resa incredibilmente semplice.
E poiché Lakeflow è integrato in Azure Databricks, puoi utilizzare gli strumenti di Azure Databricks, tra cui Databricks Asset Bundles (DABs), Lakehouse Monitoring e altro ancora, per distribuire pipeline pronte per la produzione e governate in pochi minuti.
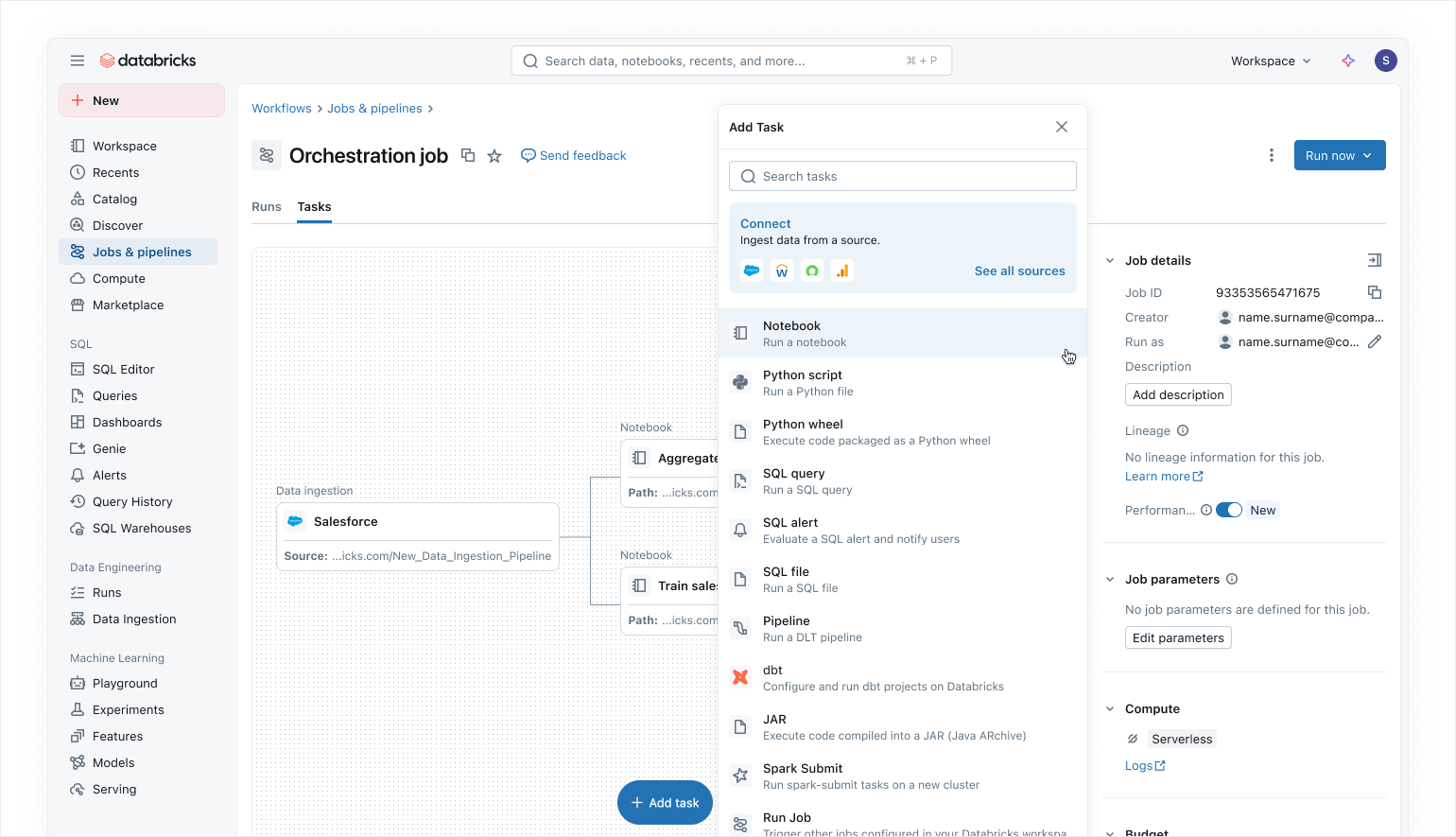
Orchestrazione moderna data-first con Lakeflow Jobs
Utilizza Lakeflow Jobs per orchestrare i tuoi carichi di lavoro di dati e AI su Azure Databricks. Con un approccio moderno, semplificato e data-first, Lakeflow Jobs è l'orchestratore più affidabile per Databricks, che supporta l'elaborazione di dati e AI su vasta scala e le analitiche in tempo reale con un'affidabilità del 99,9%.
In Lakeflow Jobs, puoi visualizzare tutte le tue dipendenze coordinando carichi di lavoro SQL, codice Python,dashboard, pipeline e sistemi esterni in un singolo DAGunificato. L'esecuzione del flusso di lavoro è semplice e flessibile con trigger sensibili ai dati, come gli aggiornamenti delle tabelle o l'arrivo di file, e attività di controllo del flusso. Grazie a esecuzioni di backfill no-code e osservabilità integrata, Lakeflow Jobs semplifica il mantenimento di dati a valle aggiornati, accessibili e accurati.
In qualità di utenti di Azure Databricks, potete anche aggiornare e refresh automaticamente i modelli semantici di Power BI utilizzando l'attività Power BI in Lakeflow Jobs (leggi di più qui), rendendo Lakeflow Jobs un orchestratore perfetto per i carichi di lavoro di Azure.
Sicurezza integrata e governance unificata
Con Unity Catalog, Lakeflow eredita controlli centralizzati di identità, sicurezza e governance per acquisizione, trasformazione e orchestrazione. Le connessioni archiviano le credenziali in modo sicuro, i criteri di accesso vengono applicati in modo coerente a tutti i carichi di lavoro e le autorizzazioni granulari garantiscono che solo gli utenti e i sistemi autorizzati possano leggere o scrivere i dati.
Unity Catalog fornisce anche lineage end-to-end dall'acquisizione tramite i Lakeflow Jobs fino alle analitiche downstream e a Power BI, semplificando la tracciabilità delle dipendenze e la garanzia della conformità. Le tabelle di sistema offrono visibilità operativa e di sicurezza su Job, utenti e utilizzo dei dati per aiutare i team a monitorare la qualità e ad applicare le best practice senza dover assemblare log esterni.
Insieme, Lakeflow e Unity Catalog offrono agli utenti di Azure Databricks pipeline governate per impostazione predefinita, garantendo una consegna dei dati sicura, verificabile e pronta per la produzione di cui i team possono fidarsi.
Leggi il nostro blog su come Unity Catalog supporta OneLake.
Esperienza utente e authoring flessibili per tutti
Oltre a tutte queste funzionalità, Lakeflow è incredibilmente flessibile e facile da usare, il che lo rende la soluzione ideale per chiunque all'interno dell'organizzazione, in particolare per gli sviluppatori.
Gli utenti che preferiscono un approccio code-first adorano Lakeflow per il suo potente motore di esecuzione e gli strumenti avanzati incentrati sugli sviluppatori. Con Lakeflow Pipeline Editor, gli sviluppatori possono sfruttare un IDE e utilizzare solidi strumenti di sviluppo per creare le proprie pipeline. Lakeflow Jobs offre anche la creazione code-first e strumenti di sviluppo con DB Python SDK e DAB per modelli CI/CD ripetibili.
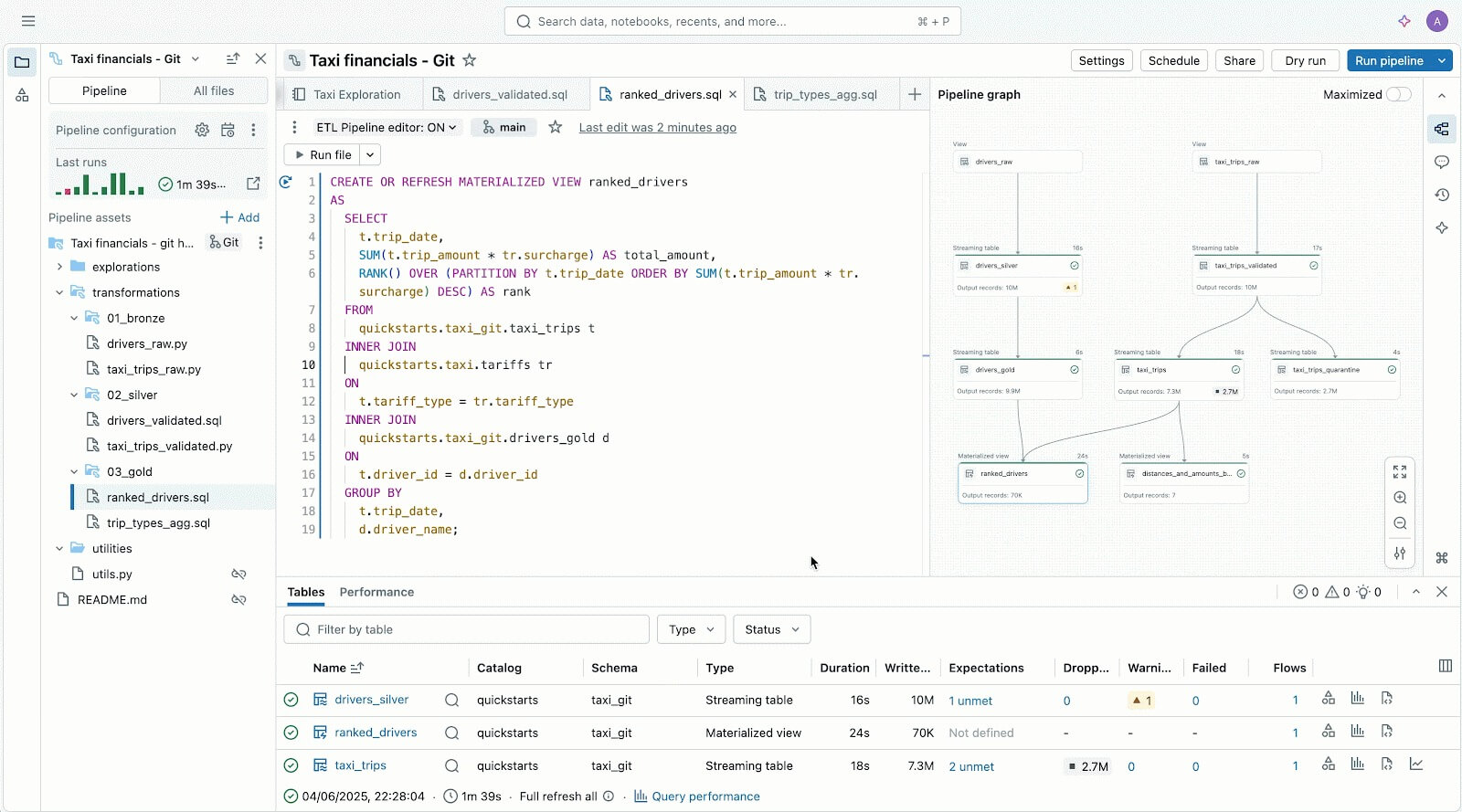
Lakeflow Pipelines Editor per aiutarti a creare e testare pipeline di dati, tutto in un unico posto.
Per i nuovi utenti e gli utenti business, Lakeflow è molto intuitivo e facile da usare, con una semplice interfaccia punta e clicca e un'API per l'acquisizione dei dati tramite Lakeflow Connect.
Meno congetture, risoluzione dei problemi più accurata con l'osservabilità nativa
Le soluzioni di monitoraggio sono spesso isolate dalla piattaforma dati, rendendo l'osservabilità più difficile da rendere operativa e le pipeline più soggette a guasti.
I Lakeflow Jobs su Azure Databricks forniscono ai Data Engineer la visibilità approfondita e end-to-end di cui hanno bisogno per comprendere e risolvere rapidamente i problemi nelle loro pipeline. Con le funzionalità di osservabilità di Lakeflow, puoi individuare immediatamente problemi di prestazioni, colli di bottiglia nelle dipendenze e attività non riuscite in un'unica interfaccia utente grazie al nostro elenco unificato delle esecuzioni.
Le System Table di Lakeflow e la provenienza dei dati integrata con Unity Catalog forniscono anche un contesto completo su set di dati, aree di lavoro, query e impatti a valle, rendendo più rapida l'analisi delle cause principali. Con la recente disponibilità generale (GA) delle System Tables in Job, puoi creare dashboard personalizzate per tutti i tuoi Job e monitorarne lo stato di salute in modo centralizzato.
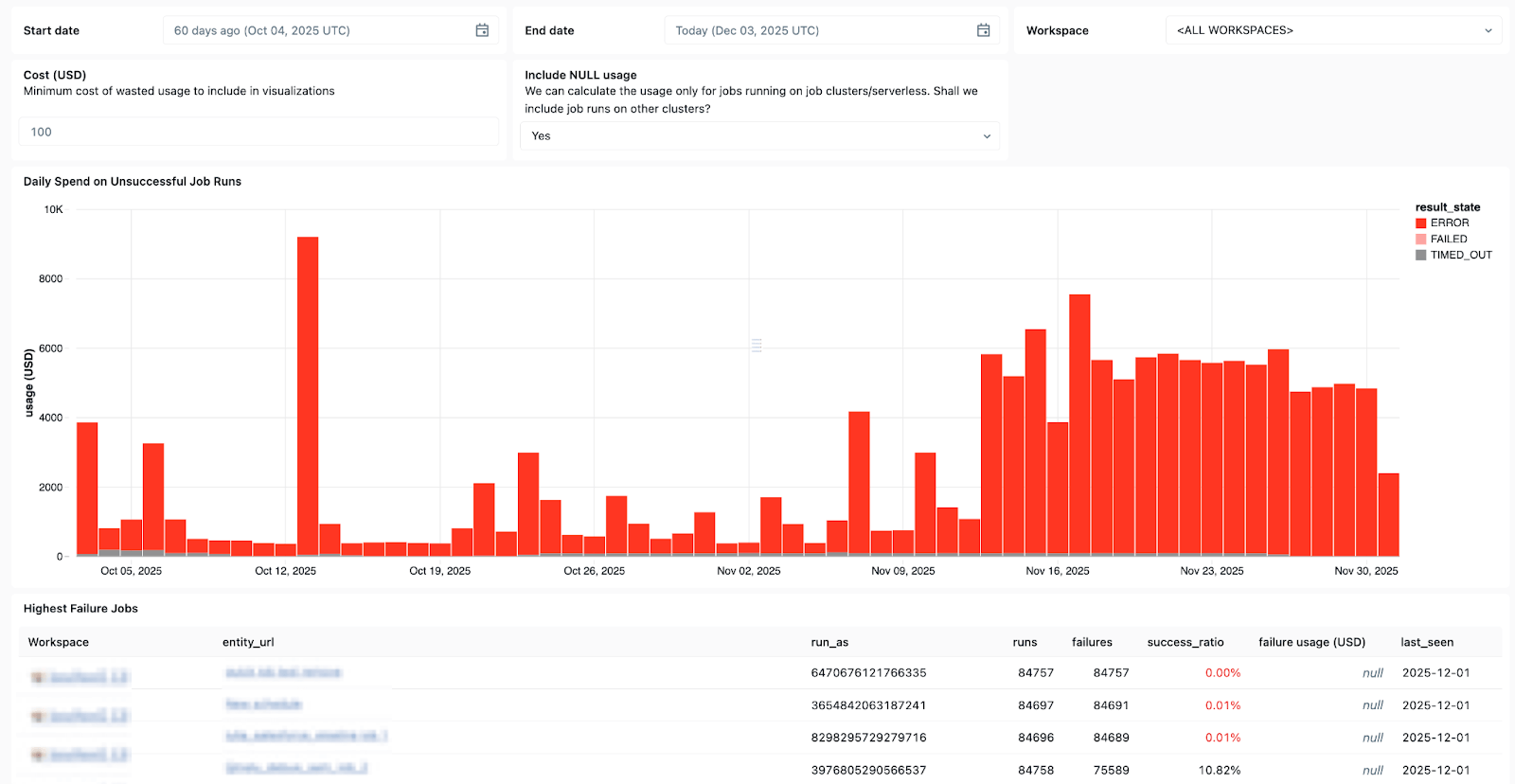
Usa le tabelle di sistema in Lakeflow per vedere quali job falliscono più spesso, le tendenze generali degli errori e i messaggi di errore comuni.
E quando si verificano problemi, Databricks Assistant è qui per aiutarti.
Databricks Assistant è un copilota AI sensibile al contesto integrato in Azure Databricks che ti aiuta a recuperare più velocemente dagli errori, consentendoti di creare e risolvere rapidamente problemi relativi a Notebook, query SQL, Job e dashboard utilizzando il linguaggio naturale.
Ma l'Assistente non si limita al debug. Può anche generare codice PySpark/SQL e spiegarlo con funzionalità basate su Unity Catalog, in modo da comprendere il contesto dell'utente. Può anche essere usato per eseguire suggerimenti, individuare pattern ed eseguire l'individuazione dei dati e l'EDA, rendendolo un ottimo compagno per tutte le esigenze di ingegneria dei dati.
Costi e consumi sotto controllo
Più grandi sono le pipeline, più difficile è dimensionare correttamente l'uso delle risorse e tenere i costi sotto controllo.
Con l'elaborazione dati serverless di Lakeflow, il compute viene ottimizzato automaticamente e continuamente da Databricks per ridurre al minimo gli sprechi dovuti all'inattività e l'utilizzo delle risorse. I Data Engineer possono decidere se eseguire il serverless in modalità Performance per i carichi di lavoro mission-critical o in modalità Standard, dove il costo è più importante, per una maggiore flessibilità.
Lakeflow Jobs consente inoltre il riutilizzo dei cluster, in modo che più attività di un flusso di lavoro possano essere eseguite sullo stesso cluster di processi, eliminando i ritardi di avvio a freddo, e supporta un controllo granulare, così ogni attività può avere come destinazione il cluster di processi riutilizzabile o il proprio cluster dedicato. Insieme al compute serverless, il riutilizzo dei cluster riduce al minimo gli avvii, in modo che i data engineer possano ridurre l'overhead operativo e ottenere un maggiore controllo sui costi dei dati.
Microsoft Azure + Databricks Lakeflow: una combinazione vincente e collaudata
Databricks Lakeflow consente ai team di dati di procedere in modo più rapido e affidabile, senza compromettere governance, scalabilità o prestazioni. Con il data engineering perfettamente integrato in Azure Databricks, i team possono beneficiare di un'unica piattaforma end-to-end che soddisfa tutte le esigenze di dati e AI a Scale.
I clienti su Azure hanno già riscontrato risultati positivi dall'integrazione di Lakeflow nel loro stack, tra cui:
- Sviluppo più rapido delle pipeline: i team possono creare e implementare pipeline di dati pronte per la produzione fino a 25 volte più velocemente e ridurre i tempi di creazione del 70%.
- prestazioni e affidabilità superiori: Alcuni clienti stanno riscontrando un miglioramento delle prestazioni di 90 volte e una riduzione dei tempi di elaborazione da ore a minuti.
- Maggiore efficienza e risparmio sui costi: l'automazione e l'elaborazione ottimizzata riducono drasticamente i costi operativi. I clienti hanno registrato risparmi fino a decine di milioni di dollari all'anno e riduzioni dei costi ETL fino all'83%.
Leggi le storie di successo dei clienti Azure e Lakeflow sul nostro blog Databricks.
Vuoi saperne di più su Lakeflow? Prova Databricks gratuitamente per scoprire tutto sulla piattaforma di data engineering.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.