Un Open Lakehouse in Tempo Reale con Redpanda e Databricks
Gli investimenti di Redpanda nell'integrazione basata su principi fondamentali con Iceberg e Unity Catalog creano un'architettura sostenibile per offrire agilità dallo stream alla tabella e alimentare un lakehouse aperto in tempo reale.
di Matt Schumpert e Jason Reid
- Trasforma i tuoi stream Kafka in tabelle Iceberg completamente gestite da Unity Catalog in un unico passaggio, offrendo analisi del lakehouse in tempo reale senza connettori complessi o processi ETL personalizzati.
- Esegui ingestione di Apache Iceberg™ con latenza inferiore a 10 ms e alto throughput sullo stesso cluster Redpanda con Iceberg Topics che gestiscono il batching Parquet, commit exactly-once e ottimizzazioni predittive di Unity, riducendo drasticamente costi e sforzi operativi.
- Distribuisci ovunque (SaaS, BYOC o self-managed) e costruisci su standard aperti con API Kafka, Iceberg V2 e REST Catalog; semplici configurazioni dichiarative ti offrono partizionamento personalizzato, evoluzione dello schema e DLQ integrate pronte all'uso.
Ogni lakehouse dovrebbe essere "alimentato da stream"
Il concetto di "open lakehouse" pioniere di Databricks anni fa è stato realizzato più ampiamente attraverso il recente aumento di Apache Iceberg™, guidato dagli investimenti dei principali fornitori nell'integrazione dei framework, negli strumenti, nel supporto dei cataloghi e nell'interoperabilità dei dati, impegnandosi a utilizzare Iceberg come substrato comune per un lakehouse aperto. Avanzamenti come la capacità di esporre le tabelle Delta Lake al crescente ecosistema Iceberg tramite UniForm, il supporto di Unity Catalog per funzionalità avanzate come l'ottimizzazione predittiva e Iceberg REST con Tabelle Iceberg gestite, e la recente unificazione del livello dati Delta/Iceberg in Iceberg V3 significano che le organizzazioni possono ora adottare una strategia dati "Iceberg-forward" con fiducia, e senza compromettere l'uso dei ricchi set di funzionalità dei prodotti lakehouse maturi come Databricks.
Uno dei principali attori mancanti in questa storia di accesso ubiquo ai dati residenti nel cloud attraverso la lingua franca di Iceberg sono stati gli stream, in particolare gli argomenti Kafka. Oggi, qualsiasi dato strutturato a riposo può essere facilmente caricato nativamente o "decorato" come Iceberg. Al contrario, i dati di alto valore in movimento che fluiscono attraverso una piattaforma di streaming che alimenta app in tempo reale devono ancora essere "ETLed" nel lakehouse di destinazione tramite un job di integrazione dati punto-punto, per stream, o eseguendo un costoso connettore infrastruttura sul proprio cluster. Entrambi gli approcci utilizzano un Kafka Consumer pesante, mettendo sotto pressione le pipeline di consegna dati in tempo reale, e creano un componente infrastrutturale intermedio da scalare, gestire e osservare con competenze Kafka specializzate. Entrambi gli approcci equivalgono all'inserimento di un pedaggio molto costoso sia tra i vostri data estate in tempo reale e quelli analitici, uno che in realtà non ha bisogno di esistere.
Poiché l'uso degli object store cloud per il backup degli stream è maturato (Redpanda ha guidato questa carica diversi anni fa) e poiché i formati di tabella aperti sono diventati centrali nei lakehouse, questo matrimonio tra stream e tabelle è sia conveniente che "destinato ad essere". Databricks e Redpanda offrono due piattaforme dati di livello mondiale che fanno brillare questo approccio e attirano l'attenzione. Insieme, creano un substrato dati che abbraccia il decisioning in tempo reale, l'analisi e l'AI che è difficile da battere. Praticamente, questo approccio unisce stream e tabelle con la facilità di un flag di configurazione. Agisce come una diga a più camere, instradando stream selezionabili in un data lake unificato su richiesta, fornendo insight aggiornati e sbloccando la stessa inclusione arbitraria di dati all'interno di nuove pipeline analitiche che l'architettura lakehouse ci ha fornito per le tabelle, e ora attraverso l'apertura allargata che l'ecosistema Iceberg fornisce.
Fondere senza soluzione di continuità l'infrastruttura dati in tempo reale e analitica per rendere un "lakehouse alimentato da stream" un'operazione "push-button" non solo sblocca un valore enorme, ma risolve anche un problema ingegneristico difficile che richiede un approccio ponderato per essere affrontato correttamente nel caso generale. Come speriamo di illustrare di seguito, non abbiamo tagliato gli angoli per affrettare questa capacità sul mercato. Lavorando con dozzine di partner di progettazione (e Databricks) per oltre un anno, abbiamo esteso la codebase singola di Redpanda in un modo che preserva le opzioni di distribuzione preferite dai nostri clienti (incluso BYOC su più cloud), mantiene la piena compatibilità Kafka (non lasciare indietro alcun carico di lavoro) ed evita la duplicazione di artefatti e passaggi per gli utenti ove possibile. Speriamo che questa completezza di visione emerga mentre esponiamo i principi guida per la costruzione di Redpanda Iceberg Topics, che sono ora disponibili con Databricks Unity Catalog su AWS e GCP!
Esegui la tua piattaforma stream-to-lakehouse ovunque
Il nostro primo principio è stato quello di mantenere la scelta e incontrare gli utenti dove si trovano. Redpanda ha già offerte mature multi-cloud SaaS, BYOC e self-managed, opzioni di rete sovrana private come BYOVPC, e generalmente non costringe i suoi clienti a spostare cloud, reti, object store, IdP, o qualsiasi altra cosa che potrebbe ostacolare l'adozione o impedire ai proprietari di piattaforme di posizionare la loro distribuzione di piattaforme di streaming (inclusi sia dati che piani di controllo), dove ha più senso per loro. Indipendentemente da tale scelta, gli utenti ottengono tutte le funzionalità della piattaforma e un'esperienza utente coerente sia per gli sviluppatori che per gli amministratori. Questa strategia di prodotto a piattaforma singola è ciò che ci consente di annunciare che Iceberg Topics per Databricks sono generalmente disponibili oggi nei cloud AWS, GCP e Azure, e che le organizzazioni possono distribuire con la certezza di sapere che se e quando cambieranno cloud o passeranno a nuovi form factor, stanno distribuendo lo stesso prodotto con lo stesso motore sottostante, compatibilità Kafka, modello di sicurezza, caratteristiche di performance e strumenti di gestione. Questa ampiezza di flessibilità e coerenza contrasta nettamente con altre opzioni sul mercato.
Unity Catalog, incontra la piattaforma di streaming più unificata
In secondo luogo, eravamo fermi sulla costruzione di questo come un unico sistema, e uno che effettivamente lo sembri. Semplicemente non si possono fondere bene due concetti insieme unendo due architetture software completamente diverse. Si possono coprire alcune cose con una patina SaaS, ma le architetture gonfie traspaiono nei modelli di prezzo, nelle prestazioni e nel TCO, almeno, e nei casi peggiori nell'esperienza utente. Abbiamo fatto del nostro meglio per evitarlo.
Per gli sviluppatori, la sensazione di un unico sistema significa un unico ciclo di vita CRUD e un'esperienza utente coerente per i topic come tabelle, e per le cose di cui hanno bisogno per funzionare (ovvero, gli schemi). Con Iceberg Topics non si copiano mai voci o configurazioni, né le si creano due volte utilizzando un'interfaccia utente separata. Si gestisce un'unica entità come fonte di verità sia per i dati che per lo schema, utilizzando sempre gli stessi strumenti. Per noi, ciò significa che si gestisce il CRUD tramite gli strumenti che si utilizzano già: qualsiasi strumento dell'ecosistema Kafka, la nostra CLI rpk, le API REST di Cloud o qualsiasi strumento di automazione del deployment di Redpanda come le nostre CR K8s o il provider Terraform. Per gli schemi, c'è il nostro Schema Registry integrato con la sua API ampiamente accettata, che definisce lo schema della tabella Iceberg implicitamente o esplicitamente, come si preferisce. Tutto è guidato dalla configurazione e adatto al DevOps. E con le nuove tabelle Iceberg gestite di Unity Catalog, tutti i flussi sono individuabili tramite gli strumenti Databricks sia come tabelle Iceberg che Delta Lake per impostazione predefinita.
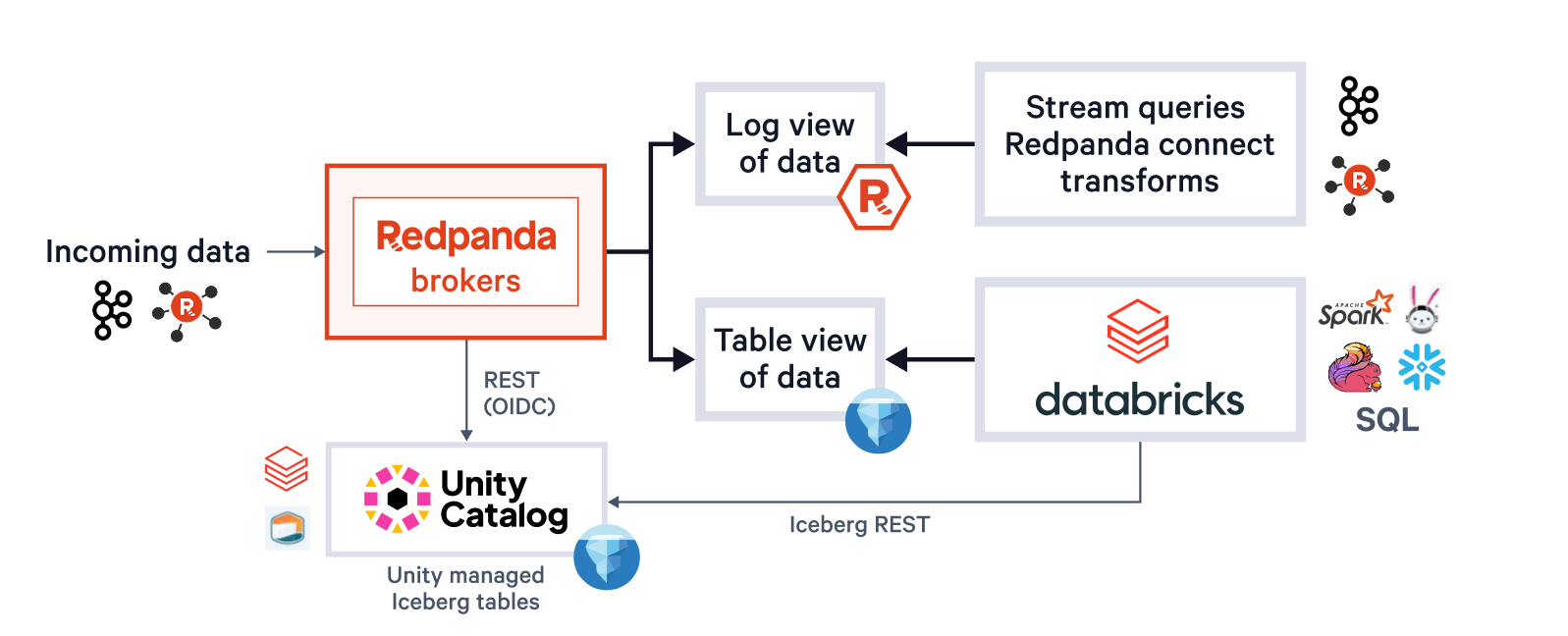
Un unico sistema riguarda anche l'operatore della piattaforma, che non dovrebbe preoccuparsi di gestire più bucket o cataloghi, ottimizzare le dimensioni dei file Parquet, i topic in ritardo rispetto ai flussi quando i cluster hanno risorse limitate, o i guasti dei nodi che compromettono la consegna exactly-once. Con Redpanda Iceberg Topics, tutto questo è automatico. Gli operatori beneficiano di scritture Parquet raggruppate dinamicamente e commit Iceberg transazionali che si adattano ai SLA di arrivo dei dati, monitoraggio automatico del ritardo che genera backpressure per i Producer Kafka quando necessario e consegna exactly-once tramite il tagging degli snapshot Iceberg (evitando lacune o duplicati dopo guasti infrastrutturali).
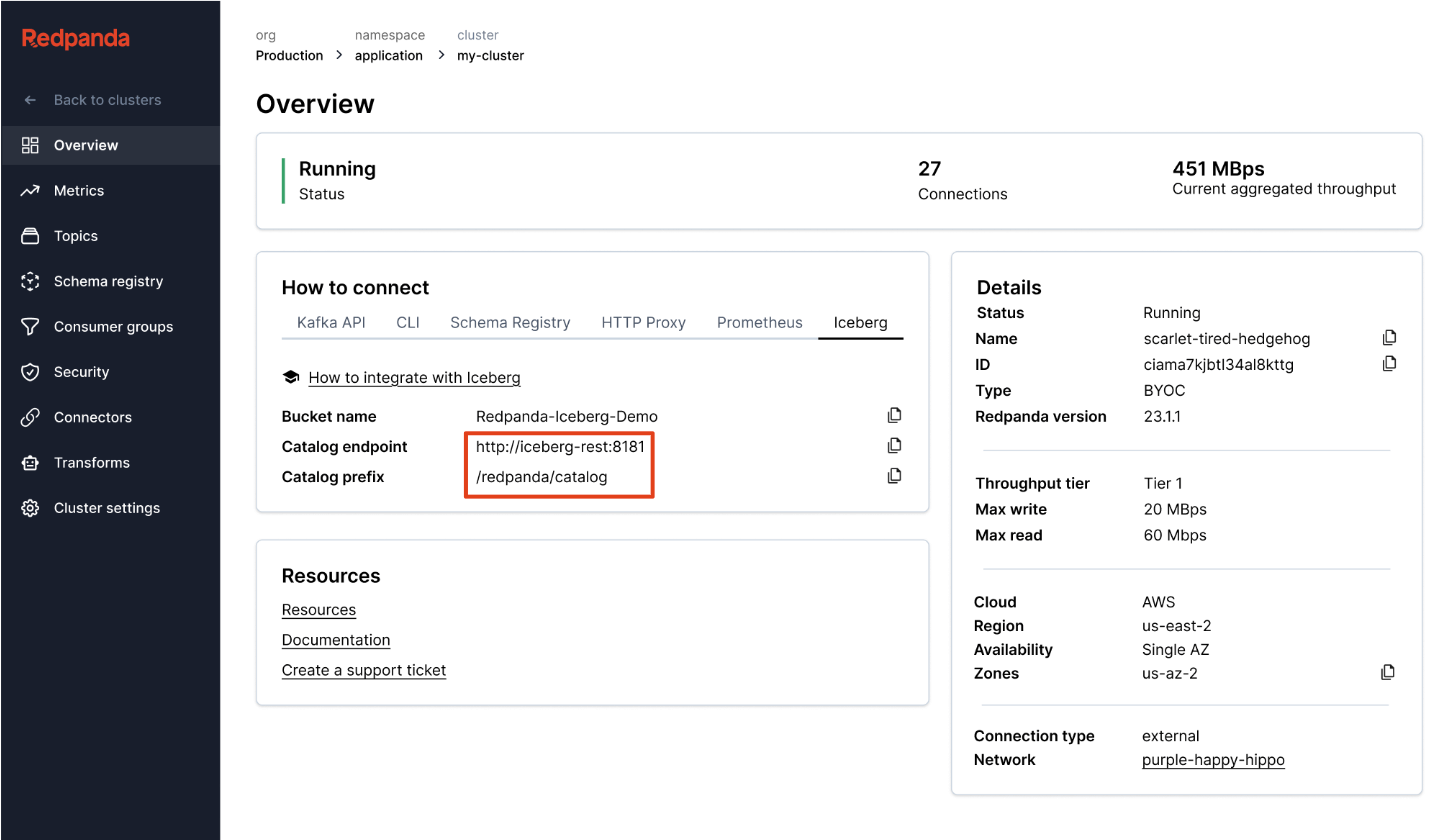
Redpanda gestisce tutti i dati in un unico bucket/container, utilizza un unico catalogo Iceberg in Unity Catalog (che Redpanda monitora per un recupero graduale) e rende le tabelle facilmente individuabili mostrando l'endpoint REST di Iceberg di Unity Catalog direttamente nell'interfaccia utente di Redpanda Cloud. E ora, con le tabelle Iceberg gestite di Unity Catalog, le operazioni di manutenzione delle tabelle come la compattazione, la scadenza dei dati e l'ottimizzazione predittiva sono integrate ed eseguite automaticamente da Unity Catalog in background, mentre Redpanda si occupa delle operazioni di manutenzione minime appropriate al suo ruolo (attualmente pulizia degli snapshot Iceberg e creazione/eliminazione di tabelle). Gli amministratori Databricks possono quindi proteggere e governare queste tabelle utilizzando tutti i normali privilegi di Unity Catalog.
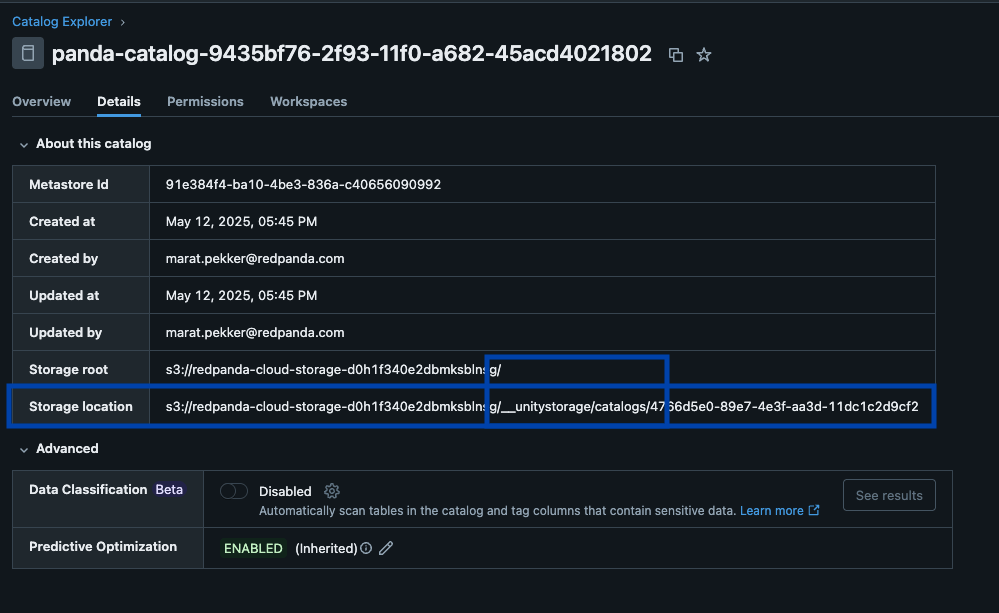
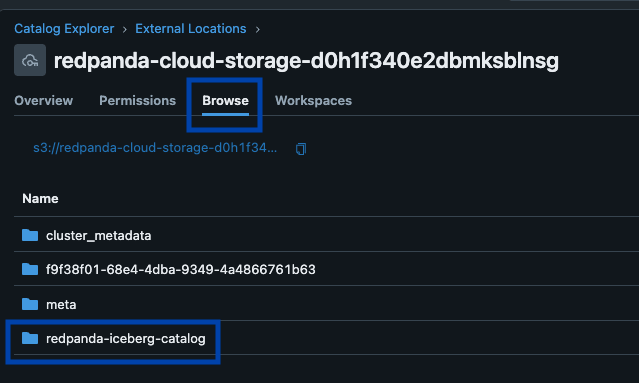
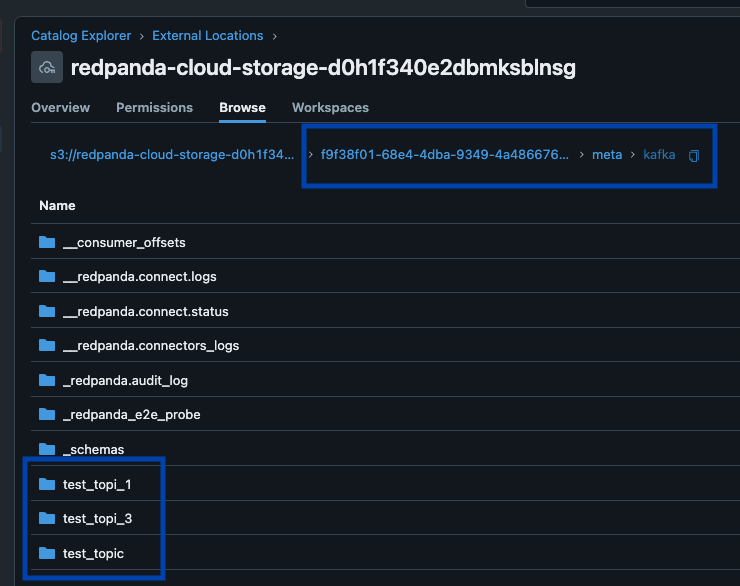
Un unico cluster per dominarli tutti
Soprattutto, grazie al nostro motore di streaming multimodale R1 che utilizza un'architettura thread-per-core e integra funzionalità come il write caching e il bilanciamento dati e workload multilivello, gli amministratori possono eseguire questo ingest Iceberg ad alto throughput nello stesso cluster, e con gli stessi topic che alimentano i workload Kafka a bassa latenza esistenti con SLA inferiori a 10 ms. Utilizzando operazioni asincrone e in pipeline bloccate sugli stessi core CPU che gestiscono le richieste Produce/Consume, gestiamo entrambi i workload con la massima efficienza in un unico processo. Soprattutto, Iceberg Topics può sfruttare l'intero set di semantiche Kafka, incluse le transazioni Kafka e i topic compattati, dove il livello Iceberg riceve solo record da transazioni confermate. Questa combinazione di un'architettura fondamentalmente efficiente che risolve i problemi complessi delle semantiche sofisticate porta enormi vantaggi nel ridurre i costi operativi perché, beh, un unico cluster per dominarli tutti. Nessun prodotto aggiuntivo. Nessun cluster separato. Nessuna pipeline da supervisionare. Distribuisci ovunque. Mantieni la calma e vai avanti, amministratori di piattaforme di streaming.
Rendilo semplice
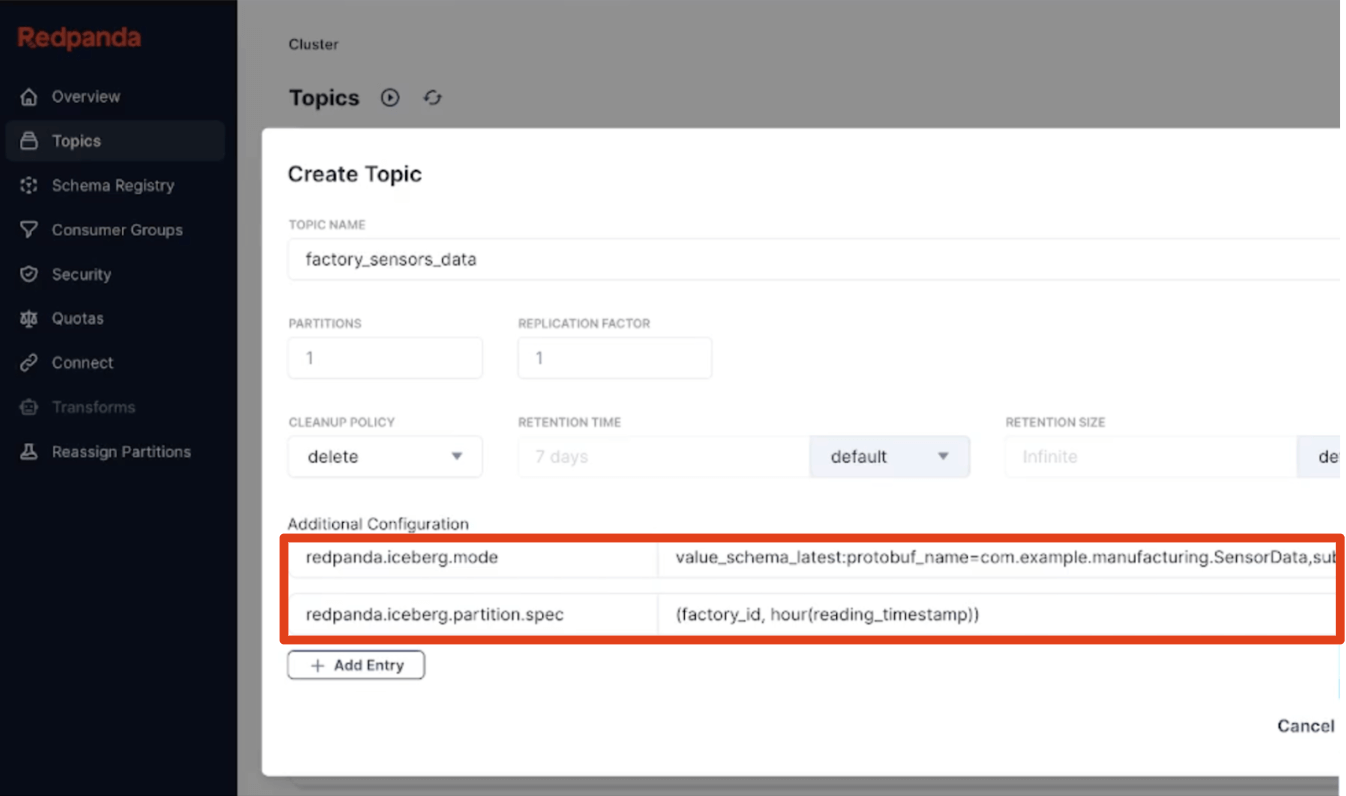
Il nostro terzo principio è stato fare alcune scelte mirate sui comportamenti predefiniti, consentendo agli utenti di apprendere gradualmente il sistema con una configurazione automatica il più intelligente possibile che funziona per la maggior parte dei casi d'uso. Ciò significa partizionamento delle tabelle orario integrato (completamente separato dagli schemi di partizione dei topic Kafka), code di messaggi non recapitati (dead letter queues) sempre attive come tabelle per acquisire dati non validi, e convenzioni semplici e canoniche come ‘versione più recente’ o ‘TopicNameStrategy’ per l'inferenza dello schema facilitano l'adozione. Portiamo anche metadati Kafka come partizioni dei messaggi, offset e chiavi come una Struct Iceberg, in modo che gli sviluppatori abbiano tutta la provenienza per convalidare rapidamente la correttezza delle loro pipeline di streaming in SQL Iceberg.

Ciò che è semplice dovrebbe essere semplice, ovviamente, ma anche ciò che è complesso dovrebbe essere diretto. Quindi, definire partizionamenti gerarchici personalizzati con l'intero set di trasformazioni di partizione Iceberg o estrarre un tipo di messaggio Protobuf specifico da un subject per diventare lo schema della tabella Iceberg sono, ancora una volta, solo proprietà del topic dichiarative su una singola riga. Gli schemi possono evolversi agevolmente poiché Redpanda applica l'evoluzione della tabella sul posto. E se necessario, esegui una semplice trasformazione (SMT) nella tua lingua preferita che distribuisce messaggi complessi da un topic grezzo in tabelle di fatti Iceberg più semplici utilizzando le trasformazioni dati integrate alimentate da WebAssembly. L'obiettivo finale è l'inserimento dei dati pronti per l'analisi in un unico passaggio. Ecco fatto, benvenuto nel livello Bronze.
Lo sfondo di tutta questa innovazione è, naturalmente, il progetto Apache Iceberg in rapida evoluzione e le sue specifiche, e l'impegno generale di Redpanda verso gli standard aperti. Questo impegno è iniziato con il suo supporto iniziale del protocollo Kafka, del registro degli schemi e delle API proxy HTTP, e persino di altri dettagli come la configurazione standard dei topic che consente alle organizzazioni di migrare senza problemi un'intera infrastruttura di applicazioni Kafka senza modifiche. Nell'ambito Iceberg, Redpanda si è distinta come pioniera nella community, implementando un client Iceberg completo in C++ da zero (qualcosa non disponibile open source). Questo client supporta la specifica completa della tabella Iceberg V2, tutte le regole di evoluzione dello schema e le trasformazioni di partizione. Sul lato del catalogo Iceberg, Redpanda fornisce un catalogo basato su file e comunica tramite Iceberg REST per operazioni come creazione, commit, aggiornamento ed eliminazione in cataloghi remoti come Unity Catalog, e supporta l'autenticazione OIDC, gestendo le tue credenziali Unity Catalog in modo giudizioso come un segreto che è trasparentemente crittografato nel gestore dei segreti del tuo provider cloud. Redpanda ha anche lavorato a stretto contatto con Databricks e altri leader di Iceberg per esplorare come la specifica possa essere estesa per supportare dati di stream semi-strutturati attraverso il tipo Variant, e per rendere la gestione dell'RBAC delle tabelle più fluida sincronizzando le policy tra le due piattaforme. Questa standardizzazione e l'implementazione sempre secondo la specifica significano anche un minimo vendor lock-in. Le organizzazioni sono sempre libere di sostituire qualsiasi componente del sistema se trovano un'opzione migliore: la piattaforma di streaming, il catalogo Iceberg o il lakehouse che interroga/elabora le tabelle.
Se sei arrivato fin qui, speriamo sinceramente che tu abbia avuto un'idea del rigoroso approccio di Redpanda a questa opportunità di mercato scottante, che deriva da una forte cultura ingegneristica e dalla passione per la creazione di prodotti solidi. In quanto tecnologi nel cuore con solide esperienze, e con particolare attenzione al fattore di forma BYOC, Redpanda e Databricks sono perfettamente allineati per fornire due piattaforme best-of-breed che agiscono e si sentono come una sola, e che, per te, risolvono efficacemente il problema dello stream-to-table.
Prova gli argomenti Iceberg con Unity Catalog utilizzando l'offerta unica Bring-Your-Own-Cloud di Redpanda oggi stesso. Oppure, inizia con una prova gratuita della nostra versione self-managed, Redpanda Enterprise!: https://cloud.redpanda.com/try-enterprise.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.