Ripensare l'ETL SQL per le moderne piattaforme dati
Riduci costi e complessità unificando pipeline SQL frammentate su un'unica piattaforma
di Matt Jones e Shanelle Roman
- L'ETL SQL frammentato genera costi nascosti, pipeline fragili e una lenta risoluzione degli incidenti
- L'esecuzione dell'ETL tra data warehouse, orchestratori e strumenti crea un attrito operativo che scala con ogni pipeline
- Una piattaforma unificata per tutto l'ETL SQL rimuove l'overhead di coordinamento e consente ai team di rilasciare più velocemente su un unico sistema governato
SQL è il fondamento del lavoro moderno sui dati. È così che gli ingegneri di analisi definiscono le trasformazioni, come gli ingegneri dei data warehouse gestiscono le pipeline e come gli analisti esplorano e raffinano i dati.
Ma mentre SQL stesso è standardizzato, i sistemi utilizzati per eseguire SQL ETL non lo sono affatto.
Nella maggior parte delle organizzazioni, le pipeline SQL sono distribuite su una combinazione di strumenti: un data warehouse per l'esecuzione, un framework di trasformazione per la modellazione, un orchestratore per la pianificazione e sistemi separati per il monitoraggio, la lineage e la qualità dei dati. Ogni livello affronta un'esigenza specifica, ma insieme creano un ambiente frammentato che è difficile da gestire e sempre più difficile da scalare.
Man mano che i team di dati scalano, questa frammentazione inizia a manifestarsi nelle operazioni quotidiane. Le pipeline falliscono su più sistemi, le dipendenze sono difficili da tracciare e la risoluzione dei problemi spesso richiede di passare da uno strumento all'altro che non sono mai stati progettati per funzionare insieme. Allo stesso tempo, le aspettative aumentano. Ai team viene chiesto di fornire dati più freschi, supportare più casi d'uso e muoversi più velocemente, senza aumentare l'overhead operativo.
È qui che molte strategie di piattaforma dati iniziano a fallire. Anche se le organizzazioni investono in infrastrutture moderne, SQL ETL rimane spesso distribuito su più sistemi, portando con sé la stessa complessità e gli stessi vincoli.
La sfida non è SQL stesso, ma come viene implementato SQL ETL.
Se SQL ETL fosse progettato da zero per come i team lavorano effettivamente oggi, sarebbe molto diverso. In pratica, significherebbe:
- Una singola piattaforma per ETL
- Supporto per ogni professionista SQL
- Pipeline aperte e pronte per il futuro
Insieme, questi principi definiscono un approccio più semplice e duraturo a SQL ETL, uno che riduce la frammentazione oggi supportando l'evoluzione dei carichi di lavoro dei dati nel tempo.
Esegui e gestisci SQL ETL su un'unica piattaforma
La sfida in SQL ETL non è scrivere trasformazioni, ma gestire pipeline che si estendono su più sistemi.
In pratica, ciò significa coordinare l'esecuzione nel data warehouse, l'orchestrazione in un sistema separato e l'osservabilità stratificata in seguito. Mantenere le pipeline in esecuzione richiede di mettere insieme questi pezzi: tracciare le dipendenze, diagnosticare i fallimenti e gestire i tentativi tra strumenti che non condividono il contesto.
Man mano che le pipeline crescono in numero e importanza, questo coordinamento diventa un onere operativo significativo.
Una piattaforma unificata semplifica questo modello riunendo queste capacità. Quando esecuzione, orchestrazione, osservabilità e governance fanno parte dello stesso sistema, le pipeline diventano più facili da gestire per progettazione. Le dipendenze vengono tracciate automaticamente e i problemi possono essere identificati e risolti più rapidamente perché il contesto pertinente è disponibile in un unico posto.
Su Databricks, SQL ETL viene definito ed eseguito all'interno di un'unica piattaforma. Le pipeline vengono eseguite con orchestrazione integrata, mentre lineage e osservabilità vengono acquisiti automaticamente in ogni fase. I controlli di qualità dei dati e i controlli di governance sono integrati direttamente nell'esecuzione della pipeline anziché essere gestiti tramite strumenti separati.
Questo approccio è ulteriormente rafforzato dall'infrastruttura serverless e dall'ottimizzazione guidata dall'IA. L'ottimizzazione delle prestazioni, la gestione delle risorse e lo scaling vengono gestiti automaticamente, consentendo ai team di concentrarsi sulla fornitura di dati affidabili anziché sulla gestione dei sistemi.
Dopo aver trasferito le nostre pipeline Databricks al calcolo serverless, HP ha realizzato risparmi sui costi cloud superiori al 32% e ha ridotto del 36% il tempo di esecuzione combinato dei job. La gestione dell'infrastruttura senza sforzo fornita dal serverless ha reso questa decisione una scelta ovvia e strategica. —Luis Alonso, Head of Data Strategy & Engineering presso HP Marketing
Il risultato è una base più snella e affidabile per SQL ETL, una che riduce l'overhead operativo migliorando al contempo prestazioni e affidabilità su larga scala.
Supporta il modo in cui i team creano effettivamente pipeline SQL
SQL ETL è frammentato non solo a causa degli strumenti, ma perché i team non creano tutti le pipeline allo stesso modo.
Gli ingegneri di analisi, che si concentrano sulla definizione della logica di business in SQL, spesso desiderano un modo per creare pipeline senza gestire l'infrastruttura sottostante, con test, controllo delle versioni e dipendenze gestiti automaticamente. Gli ingegneri di data warehouse tendono a fare affidamento su script SQL e stored procedure, spesso all'interno di ambienti di esecuzione strettamente controllati. Gli analisti possono creare trasformazioni direttamente all'interno di strumenti no-code o interfacce SQL leggere.
Molte piattaforme favoriscono implicitamente uno di questi approcci. Man mano che le organizzazioni crescono, spesso introducono sistemi aggiuntivi per supportare altre persone, con conseguenti ambienti paralleli difficili da standardizzare e mantenere.
Un approccio più efficace è standardizzare la piattaforma anziché l'interfaccia.
Databricks supporta una gamma di flussi di lavoro SQL ETL nello stesso ambiente. I team possono eseguire flussi di lavoro dbt esistenti direttamente sulla piattaforma, eseguire il lift and shift di SQL in stile warehouse in script e stored procedure, accelerare i carichi di lavoro BI con Viste Materializzate in Databricks SQL, definire pipeline dichiarative che semplificano i flussi di lavoro di produzione, o utilizzare strumenti no-code per analisti aziendali basati sulla stessa piattaforma. Sebbene questi approcci differiscano nel modo in cui vengono create le pipeline, condividono lo stesso motore di esecuzione, modello di governance e framework di osservabilità.

Questa coerenza consente alle organizzazioni di supportare stili di sviluppo multipli senza introdurre frammentazione nel modo in cui vengono eseguite le pipeline. I team possono lavorare al livello di astrazione che si adatta alle loro esigenze, beneficiando comunque di lineage, monitoraggio e controlli operativi condivisi.
Garantisce inoltre che gli script SQL esistenti in stile warehouse e gli approcci più recenti possano coesistere sulla stessa base. I team non devono scegliere tra mantenere ciò che hanno e adottare nuovi modelli: possono fare entrambe le cose all'interno di un unico sistema.
Ognuno di questi flussi di lavoro è riflesso in un'esperienza di authoring dedicata.
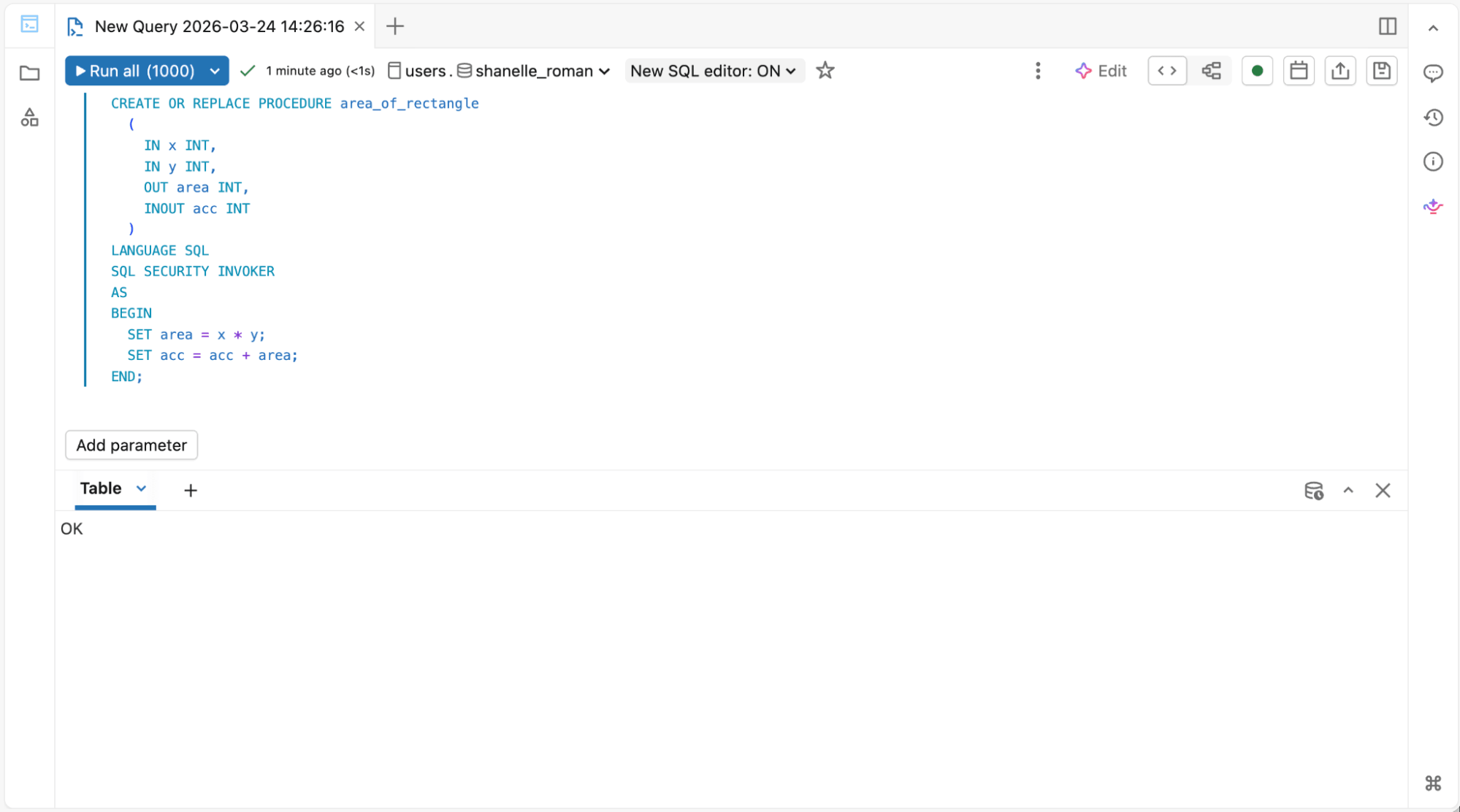
1. Per gli ingegneri di data warehouse che eseguono script SQL e stored procedure:
Editor SQL per Stored Procedure e Viste Materializzate
{kind=link}
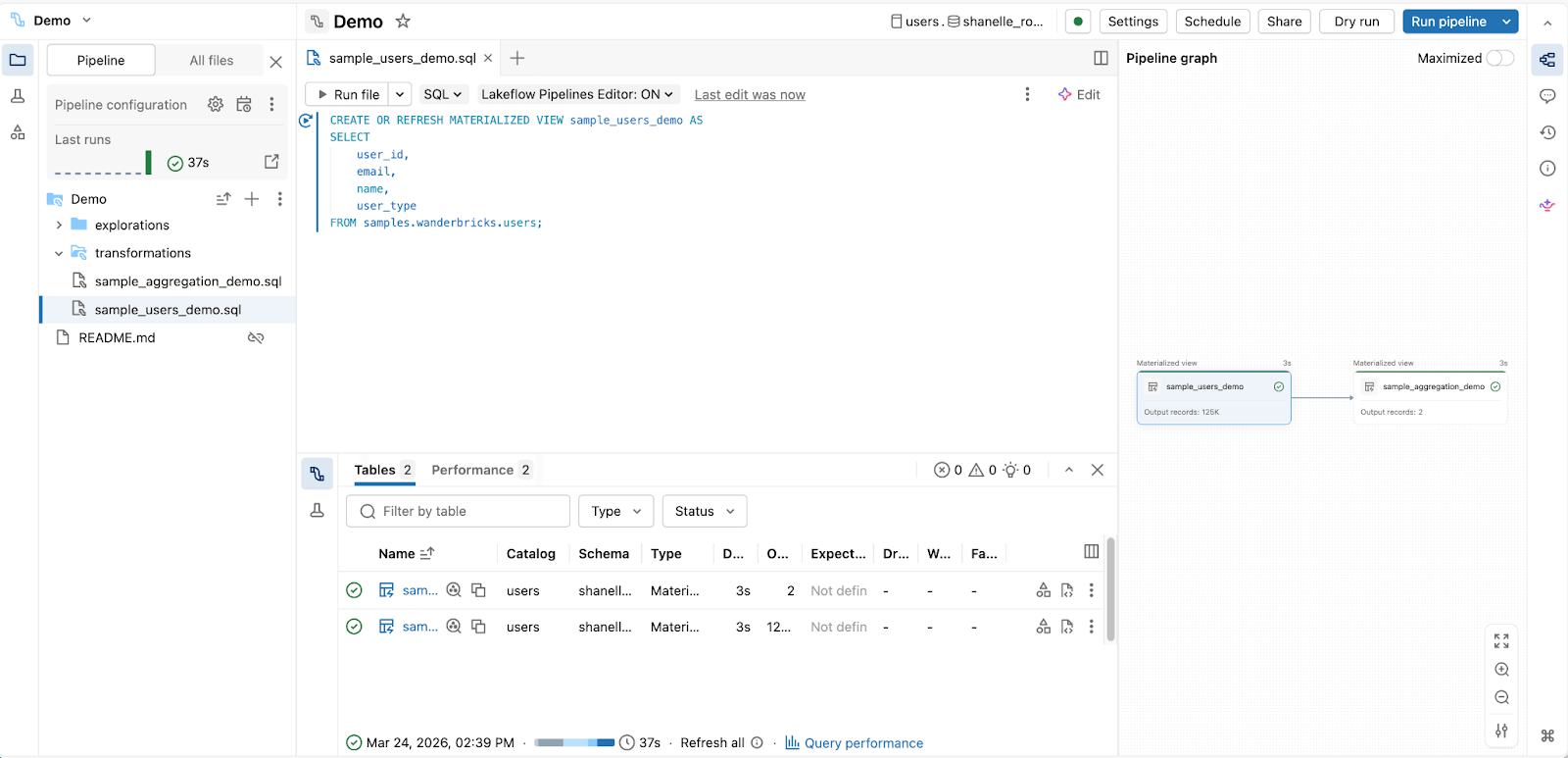
2. Per gli ingegneri di analisi che creano pipeline di produzione con SQL:
Editor Pipeline Dichiarative Spark
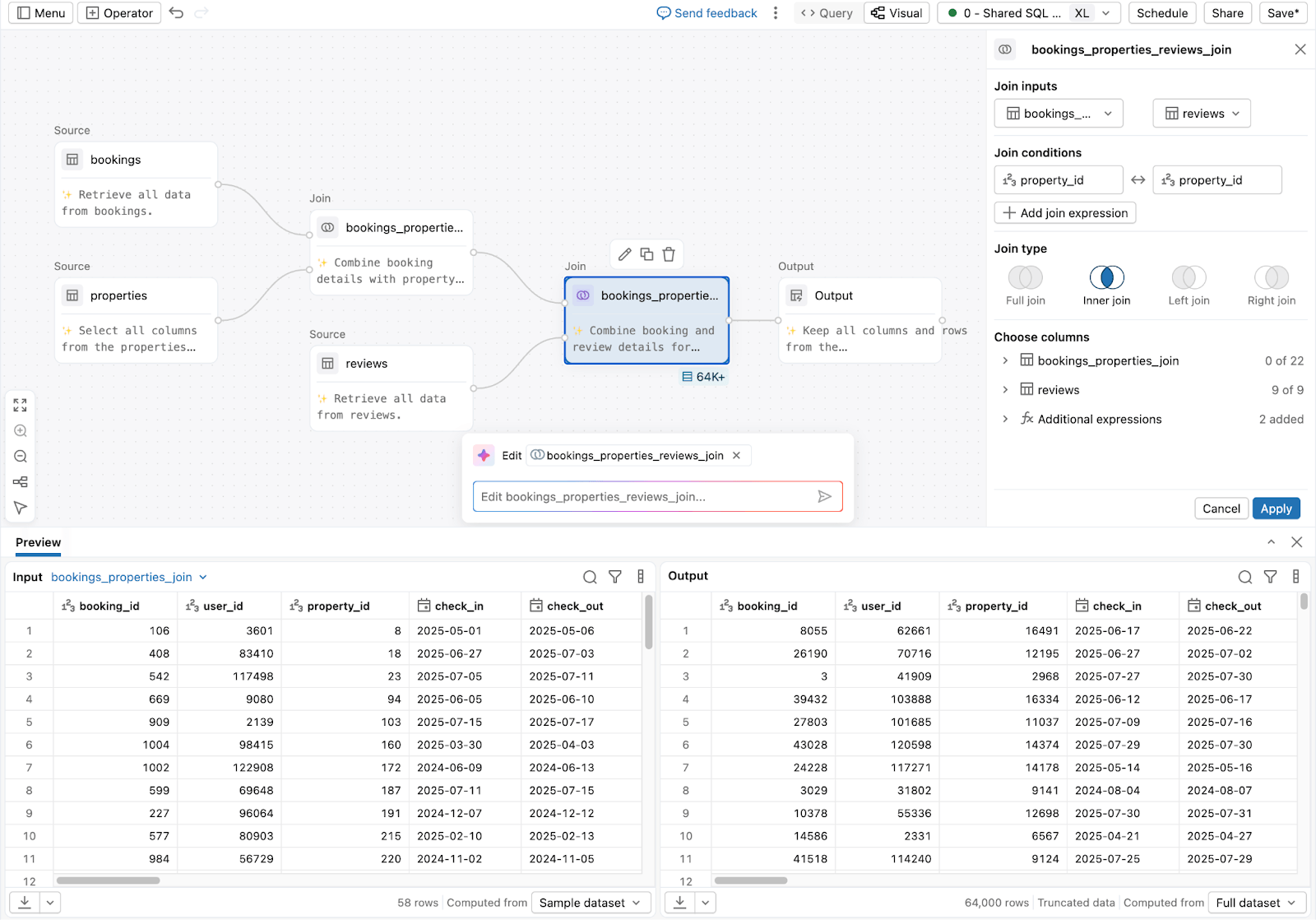
3. Per analisti e utenti aziendali che preparano dati senza codice:
Lakeflow Designer
Il risultato è un ambiente più coeso per SQL ETL, in cui la collaborazione migliora e la complessità operativa non aumenta con la scala.
Crea pipeline SQL che si evolvono con i tuoi carichi di lavoro
Con l'emergere di nuove origini dati, casi d'uso in tempo reale e carichi di lavoro di IA, i team sono spesso costretti a introdurre sistemi aggiuntivi o a riscrivere le pipeline esistenti, aumentando la complessità e i costi nel tempo.
Molte soluzioni SQL ETL introducono questi vincoli attraverso formati proprietari, modelli di esecuzione strettamente accoppiati o presupposti su come verranno elaborati i dati. Questi vincoli potrebbero non essere immediatamente evidenti, ma tendono a emergere man mano che le organizzazioni si espandono in nuovi carichi di lavoro, richiedono dati più freschi o supportano una gamma più ampia di casi d'uso.
Un approccio pronto per il futuro a SQL ETL dà priorità all'apertura e alla flessibilità fin dall'inizio.
Databricks costruisce SQL ETL su formati di tabella aperti e ANSI SQL, contribuendo a garantire che le pipeline rimangano portabili e interoperabili tra i sistemi. Ciò riduce il rischio di lock-in e consente alle organizzazioni di mantenere il controllo sui propri dati e sulla propria logica man mano che la loro architettura si evolve.
Allo stesso tempo, Databricks fornisce un modello SQL unificato che supporta sia i casi d'uso di analisi batch che in tempo reale. Anziché richiedere sistemi separati per carichi di lavoro diversi, lo stesso approccio basato su SQL può essere applicato a un'ampia gamma di casi d'uso.
Questa flessibilità consente alle pipeline di evolversi insieme all'organizzazione. I team possono continuare a eseguire i flussi di lavoro SQL esistenti adottando al contempo pattern più avanzati - come l'elaborazione incrementale o le pipeline dichiarative - quando sono necessari.
La conversione in Materialized Views ha portato a un drastico miglioramento delle prestazioni delle query, con tempi di esecuzione ridotti da 8 minuti a soli 3 secondi. Ciò consente al nostro team di lavorare in modo più efficiente e di prendere decisioni più rapide basate sugli insight ottenuti dai dati. Inoltre, i risparmi sui costi aggiuntivi sono stati davvero d'aiuto. —Karthik Venkatesan, Security Software Engineering Sr. Manager, Adobe
Evitando rigidi vincoli architetturali, questo approccio fornisce una base stabile in grado di supportare sia i requisiti attuali che le esigenze future senza richiedere modifiche dirompenti.
Perché l'ETL SQL dovrebbe plasmare la strategia della tua piattaforma dati
Le discussioni sulla piattaforma dati spesso si concentrano su dove vengono archiviati i dati e su come vengono eseguite le query. In pratica, tuttavia, l'efficacia di una piattaforma dipende tanto da come vengono costruite e mantenute le pipeline di dati, e se sono definite in modi aperti e interoperabili che evitino il lock-in a lungo termine.
Se l'ETL SQL rimane frammentato su più sistemi, è probabile che le organizzazioni portino avanti la stessa complessità operativa e le stesse inefficienze, anche dopo aver adottato una nuova piattaforma. Nel tempo, ciò limita il valore della piattaforma e rende più difficile scalare le operazioni sui dati.
Un approccio più efficace consiste nel valutare quanto bene una piattaforma supporta l'ETL SQL durante l'intero ciclo di vita: dallo sviluppo e l'esecuzione al monitoraggio e alla governance. Ciò include la capacità di supportare diversi stili di lavoro, ridurre l'overhead operativo e adattarsi ai requisiti in evoluzione senza introdurre sistemi aggiuntivi.
Databricks risponde a queste esigenze combinando l'esecuzione SQL, la gestione delle pipeline, la governance e l'ottimizzazione all'interno di un'unica piattaforma. Questo approccio unificato consente ai team di creare e gestire pipeline SQL in modo più efficiente, mantenendo al contempo la flessibilità necessaria per supportare un'ampia gamma di carichi di lavoro.
Conclusione
SQL continuerà a svolgere un ruolo centrale nel modo in cui le organizzazioni lavorano con i dati.
Di conseguenza, il modo in cui viene implementato l'ETL SQL ha un impatto diretto sull'efficacia della piattaforma dati complessiva. Gli approcci frammentati introducono complessità e rallentano i team, mentre gli approcci unificati semplificano le operazioni e migliorano la scalabilità.
Per le organizzazioni che valutano come evolvere le proprie piattaforme dati, l'ETL SQL è una considerazione fondamentale. Databricks fornisce un modello per un ETL SQL unificato e a prova di futuro che riunisce esecuzione, gestione delle pipeline e governance all'interno di un'unica piattaforma, rimanendo aperto e adattabile all'evolversi dei requisiti.
In pratica, la maggior parte delle organizzazioni non parte da zero. La modernizzazione dell'ETL SQL spesso si blocca perché il costo e il rischio di riscrivere le pipeline di produzione sono troppo elevati. Piuttosto che forzare una ricostruzione dirompente, un approccio più efficace è evolvere in modo incrementale: eseguire prima le pipeline esistenti, consolidare i sistemi nel tempo e modernizzare passo dopo passo.
È così che i team possono ridurre la frammentazione oggi, mentre costruiscono nel tempo una piattaforma dati più unificata e a prova di futuro. Approfondiremo questo approccio in un post futuro. Nel frattempo, puoi saperne di più sulla creazione, l'esecuzione e la scalabilità di pipeline SQL su una piattaforma lakehouse unificata in questo ebook, A Guide to Building ETL Pipelines with SQL.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.