Chatbot sul football auto-ottimizzante guidato da esperti di dominio su Databricks
Una guida pratica per progettare, distribuire e migliorare un assistente agentico che aiuta i coordinatori difensivi ad anticipare le tendenze avversarie e a ottimizzarsi continuamente grazie al feedback degli esperti del settore.
- Scopo: creare un assistente agentico rivolto agli allenatori che risponda a domande come "Cosa farà questa squadra in attacco?" utilizzando strumenti governati e di livello produttivo su dati play-by-play, sulla partecipazione e sul roster.
- Approccio: creare un agente che chiama strumenti con le funzioni di Unity Catalog (analisi SQL su Delta) e distribuirlo tramite l'Agent Framework con MLflow Tracing. Implementa un ciclo di auto-ottimizzazione in cui il feedback degli SME (esperti di dominio) acquisito nelle sessioni di etichettatura di MLflow addestra giudici allineati (align()) che guidano il miglioramento automatico dei prompt (optimize_prompts()), codificando la conoscenza esperta sul football direttamente nel sistema.
- Risultato: i coordinatori ottengono tendenze consapevoli della situazione (down and distance, formation/personnel, two-minute drill, screen rates) con iterazioni rapide e controlli di qualità pronti per le installazioni della settimana della partita. Gli sviluppatori ottengono un'architettura riutilizzabile per qualsiasi dominio: acquisisci il feedback degli esperti, allinea i giudici a ciò che significa "buono" per il tuo caso d'uso e lascia che il sistema migliori continuamente con l'ottimizzazione dei prompt guidata dai giudici allineati.
I giudici LLM generici e i prompt statici non riescono a cogliere le sfumature specifiche del dominio. Stabilire cosa rende "buona" un'analisi difensiva nel football richiede una profonda conoscenza del football: schemi di copertura, tendenze di formazione, contesto situazionale. I valutatori generici non colgono questo aspetto. Lo stesso vale per la revisione legale, il triage medico, la due diligence finanziaria o qualsiasi altro ambito in cui conta il giudizio di un esperto.
Questo post illustra un'architettura per agenti auto-ottimizzanti basata sul Databricks Agent Framework, in cui le competenze umane specifiche dell'azienda migliorano continuamente la qualità dell'AI utilizzando MLflow e gli sviluppatori controllano l'intera esperienza. In questo post utilizziamo come esempio un assistente per il coordinatore della difesa (DC) del football americano: un agente che richiama strumenti in grado di rispondere a domande come "Chi riceve la palla in una formazione '11 personnel' su un '3rd-and-6'" o "Cosa fa l'avversario negli ultimi 2 minuti di ogni tempo?" L'esempio seguente mostra questo agente che interagisce con un utente tramite le Databricks Apps.

Da Agent a sistema auto-ottimizzante
La soluzione prevede due fasi: costruire l'agente, quindi ottimizzarlo continuamente con il feedback degli esperti.
Costruzione
- Acquisizione dati: caricare i dati di dominio (cronaca dettagliata, partecipazione, roster) in tabelle Delta gestite in Unity Catalog.
- Abbiamo acquisito due anni (2023–2024) di dati sulla partecipazione e play-by-play del football americano da
nflreadpycome dati per questo agente.
- Abbiamo acquisito due anni (2023–2024) di dati sulla partecipazione e play-by-play del football americano da
- Crea strumenti: definisci le funzioni SQL come strumenti di Unity Catalog che l'agente può chiamare, sfruttando i dati estratti.
- Definisci e implementa l'agente: collega gli strumenti a un
ResponsesAgent, registra un prompt di sistema di base nel Registro dei prompt e implementalo nel Model Serving. - Valutazione iniziale: eseguire la valutazione automatizzata con giudici LLM e registrare le tracce utilizzando versioni di base di giudici personalizzati.
Ottimizza
- Acquisisci il feedback degli esperti: gli SME esaminano gli output dell'agente e forniscono un feedback strutturato tramite sessioni di etichettatura di MLflow.
- Allineare i giudici: utilizzare la funzione
align()di MLflow per calibrare il giudice LLM di base in modo che corrisponda alle preferenze degli SME, insegnandogli cosa si intende per "buono" in questo dominio. - Ottimizza i prompt: la funzione
optimize_prompts()di MLflow utilizza un ottimizzatore GEPA guidato dal judge allineato per migliorare in modo iterativo il prompt di sistema originale. - Ripeti: ogni sessione di etichettatura di MLflow viene usata per migliorare il judge, che a sua volta viene usato per ottimizzare il prompt di sistema. Questo intero processo può essere automatizzato per promuovere automaticamente nuove versioni di prompt che superano i benchmark delle prestazioni, oppure può servire da base per aggiornamenti manuali all'agente, come l'aggiunta di più strumenti o dati, in base alle modalità di errore osservate.
La fase di creazione porta a un prototipo iniziale e la fase di ottimizzazione accelera il passaggio alla produzione, ottimizzando continuamente l'agente e usando il feedback degli esperti di dominio come motore.
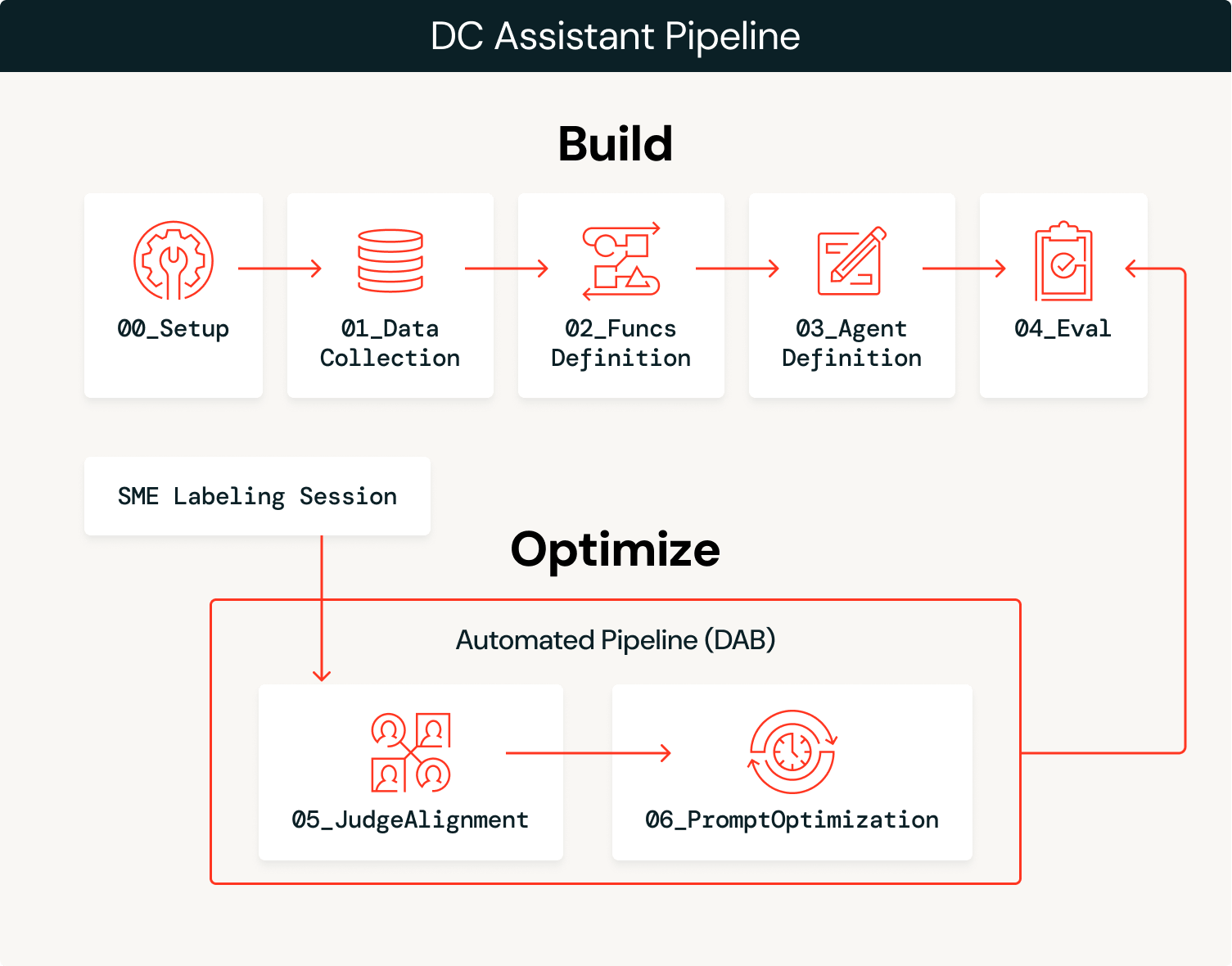
Panoramica dell'architettura
L'agente bilancia probabilismo e determinismo: un LLM interpreta l'intento semantico delle query dell'utente e seleziona gli strumenti giusti, mentre le funzioni SQL deterministiche estraggono i dati con una precisione del 100%. Ad esempio, quando un allenatore chiede “In che modo il nostro avversario attacca il Blitz?”, l'LLM interpreta questa come una richiesta di analisi di pass-rush/copertura e seleziona success_by_pass_rush_and_coverage(). La funzione SQL restituisce statistiche esatte dai dati sottostanti. Utilizzando le funzioni di Unity Catalog, garantiamo che le statistiche siano accurate al 100%, mentre l'LLM gestisce il contesto della conversazione.
| Passaggio | Tecnologia |
|---|---|
| Esegui inserimento dati | Delta Lake + Unity Catalog |
| Crea strumenti | Funzioni Unity Catalog |
| Distribuisci agente | ResponsesAgent + Model Serving tramite agents.deploy() |
| Valuta con un LLM come giudice | MLflow GenAI evaluate() con giudici integrati e personalizzati |
| Raccogli feedback | MLflow sessioni di etichettatura per il feedback degli SME |
| Allineare i giudici | MLflow align() utilizzando un ottimizzatore SIMBA personalizzato |
| Ottimizza i prompt | MLflow optimize_prompts() utilizzando un ottimizzatore GEPA |
Analizziamo ogni passaggio con il codice e gli output dell'implementazione dell'assistente DC.
Costruzione
1. Acquisizione dati.
Un notebook di configurazione (00_setup.ipynb) definisce tutte le variabili di configurazione globali utilizzate nell'intero flusso di lavoro: catalogo/schema dell'area di lavoro, esperimento MLflow, endpoint LLM, nomi dei modelli, set di dati di valutazione, nomi degli strumenti di Unity Catalog e impostazioni di autenticazione. Questa configurazione viene salvata in modo permanente in config/dc_assistant.json e caricata da tutti i notebook a valle, garantendo la coerenza in tutta la pipeline. Questo passaggio è facoltativo ma aiuta con l'organizzazione generale.
Con questa configurazione, carichiamo i dati sul football tramite nflreadpy e applichiamo l'elaborazione incrementale per prepararli per l'utilizzo da parte dell'agente: eliminando le colonne non utilizzate, standardizzando gli schemi e salvando in modo permanente le tabelle Delta pulite in Unity Catalog. Ecco un semplice esempio di caricamento dei dati che non entra nel dettaglio dell'elaborazione dei dati:
Gli output di questo processo sono tabelle Delta gestite in Unity Catalog (play-by-play, partecipazione, roster, squadre, giocatori) pronte per la creazione di strumenti e l'utilizzo da parte dell'agente.
2. Crea strumenti.
L'agente necessita di strumenti deterministici per query i dati sottostanti. Li definiamo come funzioni SQL di Unity Catalog che calcolano le tendenze offensive attraverso varie dimensioni situazionali. Ogni funzione accetta parametri come team e season e restituisce statistiche aggregate che l'agente può utilizzare per rispondere alle domande del coordinatore. In questo esempio utilizziamo solo funzioni basate su SQL, ma è possibile configurare funzioni UC basate su Python, indici di ricerca vettoriale, strumenti del Model Context Protocol (MCP) e spazi Genie come funzionalità aggiuntive che un agente può sfruttare per integrare l'LLM che supervisiona il processo.
L'esempio seguente mostra success_by_pass_rush_and_coverage(), che calcola le suddivisioni passaggio/corsa, l'EPA (Expected Points Added), il tasso di successo e le iarde guadagnate, raggruppati per numero di pass rusher e tipo di copertura difensiva. La funzione include un COMMENT che ne descrive lo scopo, che l'LLM utilizza per determinare quando chiamarla.
Poiché queste funzioni risiedono in Unity Catalog, ereditano il modello di governance della piattaforma: controlli degli accessi per ruoli, tracciamento della derivazione dei dati e reperibilità all'interno della workspace. I team possono trovare e riutilizzare gli strumenti senza duplicare la logica e gli amministratori mantengono la visibilità sui dati a cui l'agente può accedere.
3. Definisci e distribuisci l'agente.
Creare l'agente può essere semplice come usare l'AI Playground. Seleziona l'LLM che desideri usare, aggiungi i tuoi strumenti di Unity Catalog, definisci il prompt di sistema e fai clic su “Create agent notebook” per esportare un notebook che produce un agente nel formato ResponsesAgent. La seguente schermata mostra questo flusso di lavoro in azione. Il notebook esportato contiene la struttura di definizione dell'agente, collegando le tue funzioni UC all'agente tramite UCFunctionToolkit.
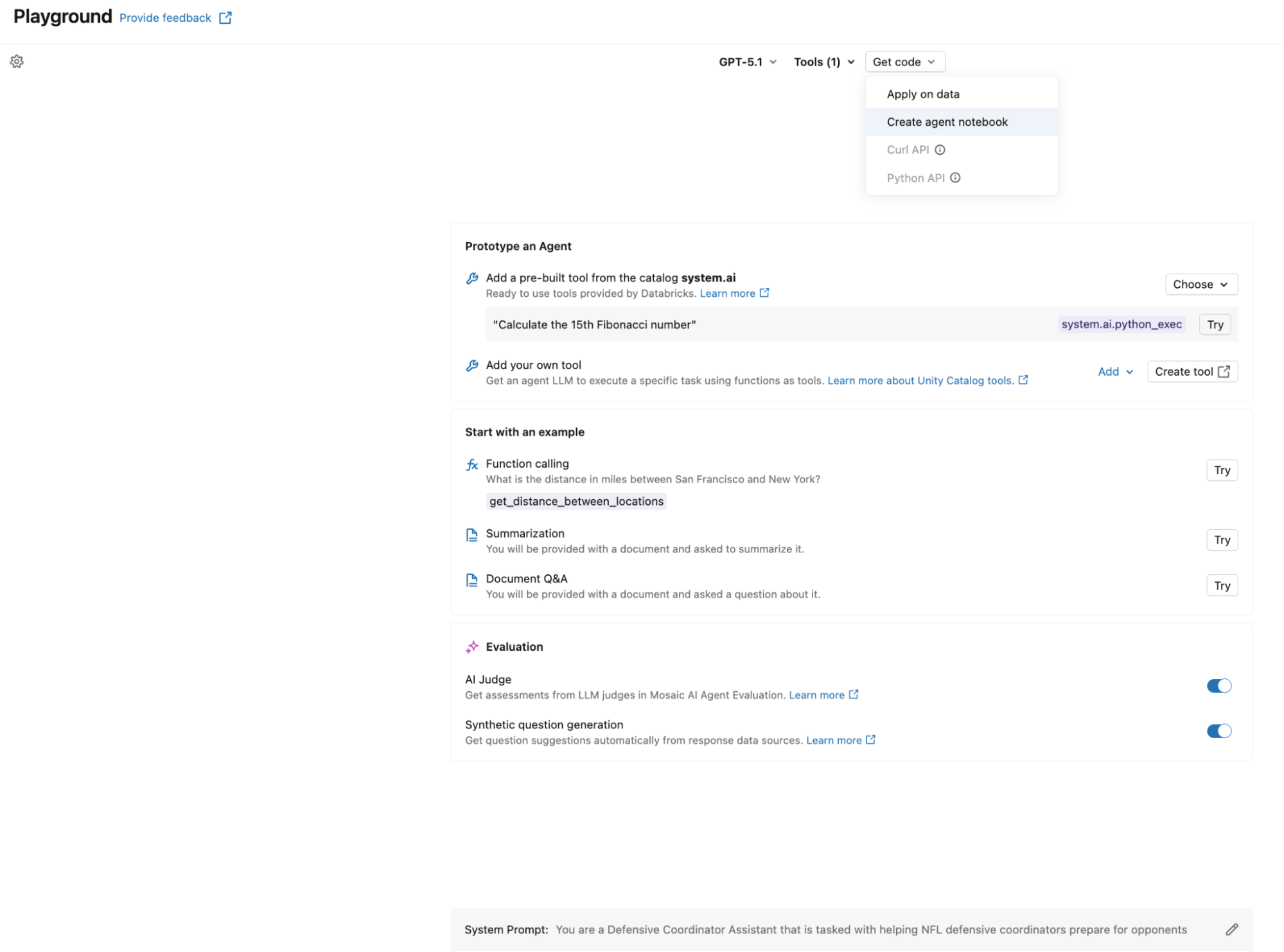
Per abilitare il ciclo di auto-ottimizzazione, registriamo il prompt di sistema nel Registro dei prompt anziché hardcodificarlo. Ciò consente alla fase di ottimizzazione di aggiornare il prompt senza dover rieseguire il deployment dell'agente:
Una volta testato il codice dell'agente e registrato il modello in Unity Catalog, distribuirlo a un endpoint persistente è semplice come il codice riportato di seguito. Questo crea un endpoint di Model Serving con MLflow Tracing abilitato, tabelle di inferenza per la registrazione di richieste/risposte e scalabilità automatica:
Per l'accesso degli utenti finali, l'agente può anche essere distribuito come Databricks App, fornendo un'interfaccia di chat che coordinatori e analisti possono utilizzare direttamente senza la necessità di accedere a notebook o API. Lo screenshot nell'introduzione mostra questa distribuzione basata su app in azione.
4. Valutazione iniziale.
Con l'agente distribuito, eseguiamo una valutazione automatica utilizzando i giudici LLM per stabilire una misura di qualità di base. MLflow supporta diversi tipi di giudici e noi ne usiamo tre in combinazione.
I judge integrati gestiscono i criteri di valutazione comuni pronti all'uso. RelevanceToQuery() verifica se la risposta è pertinente alla domanda dell'utente. I giudici basati su linee guida eseguono la valutazione rispetto a regole testuali specifiche in modalità superato/non superato. Definiamo una linea guida per garantire che le risposte utilizzino la terminologia appropriata del football professionistico:
I giudici personalizzati utilizzano make_judge() per una valutazione specifica del dominio con il pieno controllo sui criteri di punteggio. Questo è il giudice che allineeremo al feedback degli SME nella fase di ottimizzazione:
Una volta definiti tutti i valutatori, possiamo eseguire una valutazione sul set di dati:
Il judge personalizzato football_analysis_base fornisce un punteggio di base, ma riflette solo un tentativo fatto al meglio delle possibilità di fornire una griglia di valutazione da zero che l'LLM può utilizzare per le sue valutazioni, piuttosto che una vera competenza di dominio. L'interfaccia utente di MLflow Experiments ci mostra le prestazioni dell'agente su questo judge di base, nonché la motivazione del punteggio per ogni esempio.
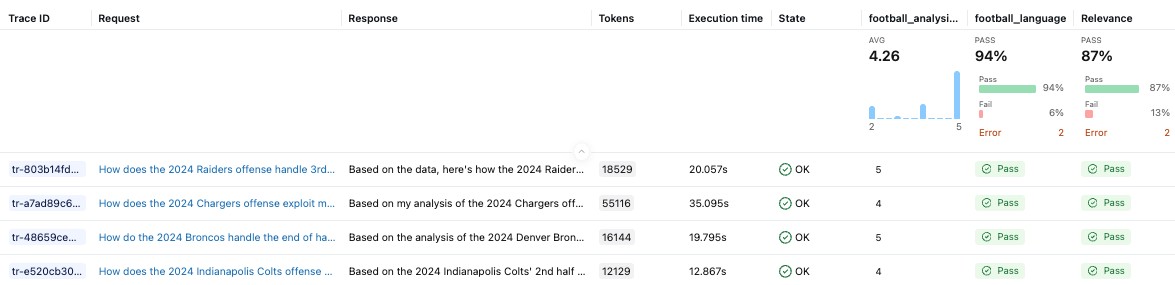

Nella fase di ottimizzazione, allineeremo il giudice di analisi del football con le preferenze degli SME, insegnandogli cosa significa effettivamente “buono” per l'analisi del coordinatore della difesa.
Ottimizza
5. Acquisisci il feedback degli esperti.
Con l'agente distribuito e la valutazione di base completata, entriamo nel ciclo di ottimizzazione. È qui che la competenza di dominio viene codificata nel sistema, prima attraverso i judge LLM allineati, poi direttamente nell'agente attraverso l'ottimizzazione del prompt di sistema guidata dal nostro judge allineato.
Iniziamo creando uno schema di etichette che utilizza le stesse istruzioni e criteri di valutazione del judge di analisi del football che abbiamo creato con make_judge(). Quindi, creiamo una sessione di etichettatura che consente al nostro esperto di dominio di esaminare le risposte per le stesse tracce utilizzate nel evaluate() job e di fornire i propri punteggi e feedback tramite la Review App (illustrata di seguito).
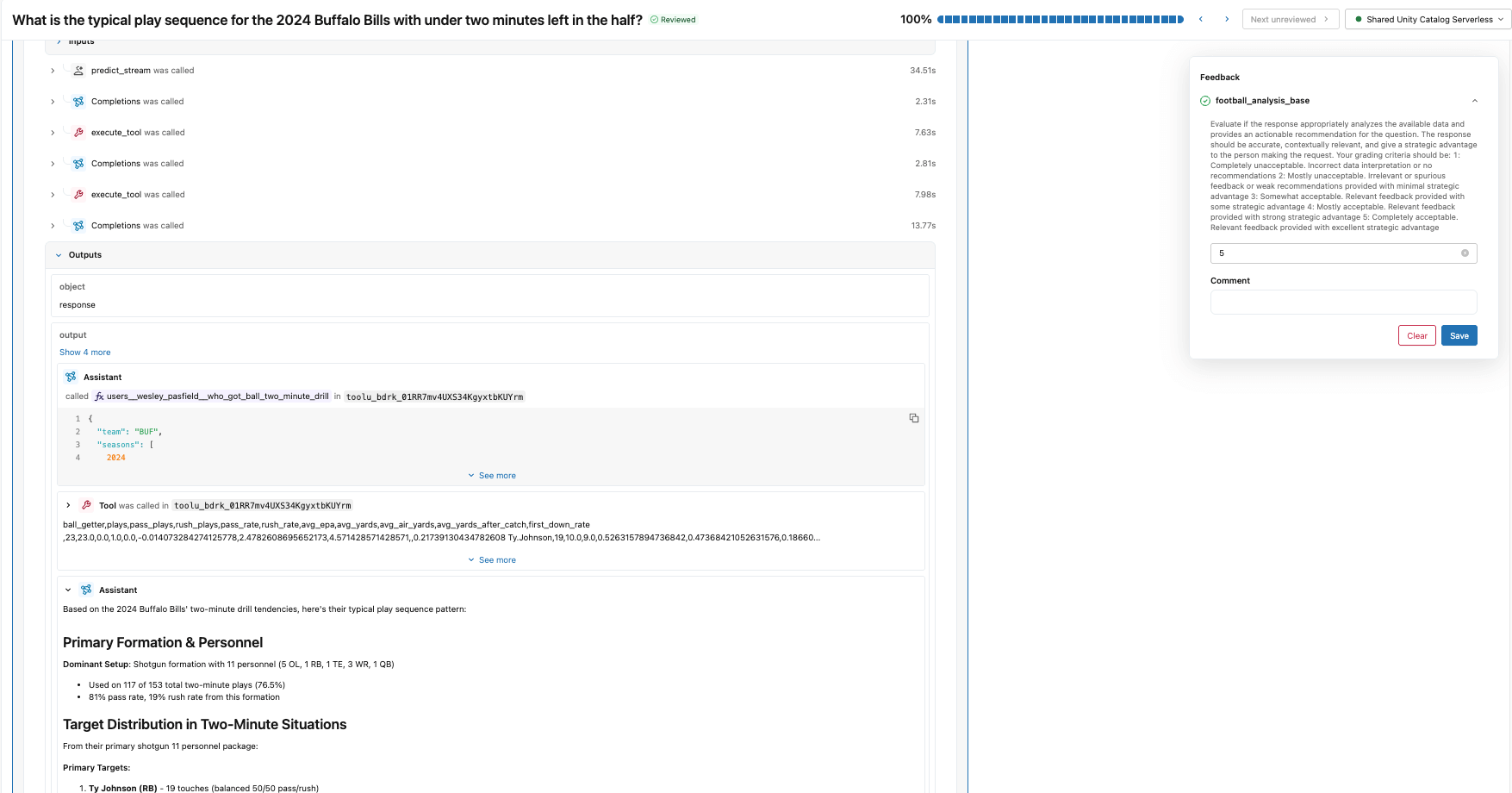
Questo feedback diventa la ground truth per l'allineamento del judge. Analizzando i punti in cui i punteggi del giudice di riferimento e quelli degli SME divergono, capiamo quali sono gli errori del giudice riguardo a questo dominio specifico.
6. Allineare i giudici.
Ora che disponiamo di tracce che includono sia il feedback degli esperti di dominio sia il feedback del judge LLM, possiamo sfruttare la funzionalità align() di MLflow per allineare il nostro judge LLM al feedback dei nostri esperti di dominio. Un judge allineato riflette la prospettiva dei tuoi esperti di dominio e i dati unici della tua organizzazione. L'allineamento porta gli esperti di dominio nel processo di sviluppo in un modo che prima non era possibile: il feedback di dominio modella direttamente il modo in cui il sistema misura la qualità, rendendo le metriche di prestazione dell'agente sia affidabili che scalabili.
align() consente di usare il proprio ottimizzatore o l'ottimizzatore binario predefinito SIMBA (Simplified Multi-Bootstrap Aggregation). In questo caso, sfruttiamo un ottimizzatore SIMBA personalizzato per calibrare un giudice su scala Likert:
Successivamente, recuperiamo le tracce che hanno sia i punteggi del giudice LLM sia il feedback degli SME che abbiamo taggato durante tutto il processo. Questi punteggi abbinati sono ciò che SIMBA utilizza per apprendere il divario tra il giudizio generico e quello esperto.
La seguente schermata mostra il processo di allineamento in corso. Il modello identifica le discrepanze tra i giudici LLM e il feedback degli SME, propone nuove regole e dettagli da integrare nel giudice per colmare queste discrepanze, quindi valuta i nuovi giudici candidati per vedere se superano le prestazioni del giudice di base.

L'output finale di questo processo è un giudice allineato che riflette direttamente il feedback degli esperti di dominio con istruzioni dettagliate.

Consigli per un allineamento efficace:
- L'obiettivo dell'allineamento è farti sentire come se avessi degli esperti di dominio seduti accanto a te durante lo sviluppo. Questo processo potrebbe portare a punteggi di performance inferiori per il tuo agente di base, il che significa che il tuo judge di base non era sufficientemente specifico. Ora che hai un judge che critica l'agente allo stesso modo in cui farebbero i tuoi SME, puoi apportare miglioramenti manuali o automatizzati per migliorare le performance.
- Il processo di allineamento è valido solo quanto il feedback fornito. Punta sulla qualità, non sulla quantità. Un feedback dettagliato e coerente su un numero ridotto di esempi (minimo 10) produce risultati migliori rispetto a un feedback incoerente su molti esempi.
Definire la qualità è spesso l'ostacolo principale al miglioramento delle prestazioni dell'agent. Indipendentemente dalla tecnica di ottimizzazione, se non c'è una chiara definizione di qualità, le prestazioni dell'agente non saranno all'altezza. Databricks offre un workshop che aiuta i clienti a definire la qualità attraverso un esercizio iterativo e interfunzionale. Per saperne di più, contatta il team del tuo account Databricks o compila questo modulo.
7. Ottimizza i prompt.
Con un judge allineato che riflette le preferenze degli SME, possiamo ora migliorare automaticamente il prompt di sistema dell'agente. La funzione optimize_prompts() di MLflow usa GEPA per perfezionare iterativamente il prompt in base al punteggio del judge allineato. GEPA (Genetic-Pareto), co-creato dal CTO di Databricks Matei Zaharia, è un algoritmo genetico evolutivo per prompt che sfrutta i modelli linguistici di grandi dimensioni per eseguire mutazioni riflessive sui prompt, consentendogli di perfezionare in modo iterativo le istruzioni e di superare le tecniche tradizionali di apprendimento per rinforzo nell'ottimizzazione delle prestazioni del modello.
Anziché lasciare che uno sviluppatore indovini quali aggettivi aggiungere al prompt di sistema, l'ottimizzatore GEPA evolve matematicamente il prompt per massimizzare il punteggio specifico definito dall'esperto. Il processo di ottimizzazione richiede un set di dati con risposte attese che guidano l'ottimizzatore verso i comportamenti desiderati, in questo modo:
L'ottimizzatore GEPA prende il prompt di sistema corrente e propone iterativamente dei miglioramenti, valutando ogni candidato rispetto al judge allineato. Qui, prendiamo il prompt iniziale, il set di dati di ottimizzazione che abbiamo creato e il judge allineato per sfruttare la funzione optimize_prompts() di MLflow. Usiamo quindi l'ottimizzatore GEPA per creare un nuovo prompt di sistema guidato dal nostro judge allineato:
Lo screenshot seguente mostra la modifica al prompt di sistema: quello vecchio è a sinistra e quello nuovo a destra. Il prompt finale scelto è quello che ha ottenuto il punteggio più alto misurato dal nostro giudice allineato. Il nuovo prompt è stato troncato per motivi di spazio, ma da questo esempio è chiaro che siamo riusciti a integrare le risposte degli esperti di settore per elaborare un prompt che si basa su un linguaggio specifico del dominio, con indicazioni esplicite su come gestire determinate richieste.

La capacità di generare automaticamente questo tipo di guida utilizzando il feedback degli SME consente essenzialmente ai tuoi SME di fornire indirettamente istruzioni a un agente semplicemente fornendo un feedback sulle tracce provenienti dall'agente.
In questo caso, il nuovo prompt ha portato a prestazioni migliori sul nostro set di dati di ottimizzazione secondo il nostro giudice allineato, quindi abbiamo assegnato al prompt appena registrato l'alias di produzione, consentendoci di rieseguire il deployment del nostro agente con questo prompt migliorato.
Suggerimenti per l'ottimizzazione dei prompt:
- Il set di dati di ottimizzazione dovrebbe coprire la diversità delle query che il tuo agente gestirà. Includi i casi limite, le richieste ambigue e gli scenari in cui la selezione degli strumenti è importante.
- Le risposte previste dovrebbero descrivere ciò che l'agente deve fare (quali strumenti chiamare, quali informazioni includere) anziché il testo di output esatto.
- Start con
max_metric_callsimpostato su un valore compreso tra50e100. Valori più alti esplorano più candidati ma aumentano il costo e il tempo di esecuzione. - L'ottimizzatore GEPA impara dalle modalità di errore. Se il giudice allineato penalizza i benchmark mancanti o le avvertenze per campioni di piccole dimensioni, GEPA inietterà tali requisiti nel prompt ottimizzato.
8. Chiudere il cerchio: automazione e miglioramento continuo.
I singoli passaggi che abbiamo esaminato possono essere orchestrati in una pipeline di ottimizzazione continua, in cui l'etichettatura da parte dell'esperto di dominio diventa il trigger per il ciclo di ottimizzazione e tutto può essere incluso in un job Databricks utilizzando gli Asset Bundle:
- Gli SME etichettano gli output dell'agente tramite l'interfaccia utente della sessione di etichettatura di MLflow, fornendo punteggi e commenti su tracce di produzione reali.
- La pipeline rileva nuove etichette e recupera le tracce con il feedback degli SME e i punteggi del giudice LLM di base.
- Viene eseguito l'allineamento del judge, producendo una nuova versione calibrata sulle più recenti preferenze degli SME.
- Viene eseguita l'ottimizzazione del prompt, utilizzando il judge allineato per migliorare iterativamente il prompt di sistema.
- La promozione condizionale invia il nuovo prompt in produzione se supera le soglie di prestazione. Ciò potrebbe comportare l'attivazione di un altro job di valutazione per garantire che il nuovo prompt generalizzi ad altri esempi.
- L'agente migliora automaticamente man mano che il registro dei prompt eroga la versione ottimizzata.
Quando gli esperti di dominio completano una sessione di etichettatura, viene attivato un job evaluate() per generare i punteggi del giudice LLM sulle stesse tracce. Quando il job evaluate() viene completato, viene eseguito un job align() per allineare il judge LLM al feedback dell'esperto di dominio. Al termine di tale job, viene eseguito un job optimize_prompts() per generare un nuovo prompt di sistema migliorato che può essere immediatamente testato su un nuovo set di dati e, se appropriato, promosso in produzione.
L'intero processo può essere completamente automatizzato, ma è anche possibile inserire una revisione manuale in qualsiasi fase, offrendo agli sviluppatori il pieno controllo sul livello di automazione coinvolto. Il processo si ripete man mano che gli SME continuano l'etichettatura, portando a rapidi test delle prestazioni sulle nuove versioni dell'agente e a guadagni cumulativi in termini di prestazioni di cui gli sviluppatori possono davvero fidarsi.
Conclusione
Questa architettura trasforma il modo in cui gli agenti migliorano nel tempo, utilizzando il Databricks Agent Framework e MLflow. Anziché lasciare che gli sviluppatori cerchino di indovinare cosa renda una risposta di qualità, gli esperti di settore modellano direttamente il comportamento dell'agente attraverso il feedback degli esperti. I processi di allineamento e ottimizzazione dei valutatori traducono le competenze di settore in modifiche concrete del sistema, mentre gli sviluppatori mantengono il controllo sull'intero sistema, decidendo quali parti automatizzare e dove consentire un intervento manuale.
In questo post abbiamo illustrato come personalizzare un agente per riflettere il linguaggio e i dettagli specifici importanti per gli esperti di settore nel football professionistico. L'assistente DC dimostra il modello, ma l'approccio funziona per qualsiasi settore in cui il giudizio degli esperti è importante: revisione di documenti legali, preparazione del turno di battuta nel baseball professionistico, triage medico, analisi del colpo nel golf, escalation dell'assistenza clienti o qualsiasi altra applicazione in cui è difficile per gli sviluppatori specificare cosa sia “buono” senza il supporto di esperti di settore.
Provalo sul tuo problema specifico di dominio e scopri come può guidare il miglioramento automatizzato e continuo basato sul feedback degli SME!
Scopri di più su Databricks Sports e Agent Bricks o richiedi una demo per scoprire come la tua organizzazione può ottenere informazioni dettagliate competitive.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.