Acceleratori per l'industria manifatturiera

Dalla pubblicazione dell'articolo seminale sui transformer di Vaswani et al. di Google, i modelli linguistici di grandi dimensioni (LLM) sono arrivati a dominare il campo dell'IA generativa. Senza dubbio, l'avvento di ChatGPT di OpenAI ha portato la tanto necessaria pubblicità e ha suscitato un crescente interesse per l'uso degli LLM, sia per uso personale sia per soddisfare le esigenze aziendali. Negli ultimi mesi, Google ha rilasciato Bard e Meta i suoi modelli Llama 2, dimostrando l'intensa concorrenza tra le grandi aziende tecnologiche.
I settori industriali manifatturiero ed energetico sono chiamati a fornire una maggiore produttività, a fronte di costi operativi in aumento. Le aziende orientate ai dati stanno investendo nell'IA e, più di recente, negli LLM. In sostanza, le aziende orientate ai dati stanno ricavando un valore enorme da questi investimenti.
Databricks crede nella democratizzazione delle tecnologie di AI. Crediamo che ogni azienda dovrebbe avere la possibilità di addestrare i propri LLM ed essere proprietaria dei propri dati e modelli. Nei settori industriali manifatturiero ed energetico, molti processi sono proprietari e sono fondamentali per mantenere un vantaggio competitivo o migliorare i margini operativi a fronte di una forte concorrenza. I segreti del mestiere sono protetti come segreti commerciali, anziché essere resi pubblici tramite brevetti o pubblicazioni. Molti degli LLM disponibili pubblicamente non soddisfano questo requisito fondamentale, che richiede la cessione del proprio know-how.
In termini di casi d'uso, la domanda che sorge spesso in questo settore industriale è come potenziare la forza lavoro attuale senza sommergerla con più app e più dati. È qui che risiede la sfida di creare e fornire più app basate sull'AI alla forza lavoro. Tuttavia, con l'avvento dell'IA generativa e dei modelli LLM, riteniamo che queste app basate su LLM possano ridurre la dipendenza da più applicazioni e consolidare le capacità di arricchimento delle conoscenze in un numero inferiore di app.
Diversi casi d'uso nel settore industriale potrebbero beneficiare degli LLM. Questi includono, tra gli altri:
- Potenziamento degli agenti del supporto clienti. Gli agenti del supporto clienti vogliono poter interrogare quali problemi aperti/irrisolti esistono per il cliente in questione e fornire uno script guidato dall'AI per assistere il cliente.
- Acquisizione e diffusione della conoscenza di dominio attraverso l'addestramento interattivo. Il settore è dominato da un profondo know-how, spesso descritto come conoscenza "tribale". L'invecchiamento della forza lavoro comporta la sfida di acquisire in modo permanente questa conoscenza di dominio. Gli LLM potrebbero fungere da serbatoi di conoscenza, che possono poi essere facilmente diffusi a scopo di addestramento.
- Potenziamento della capacità di diagnostica dei tecnici dell'assistenza sul campo. I tecnici dell'assistenza sul campo spesso faticano a consultare una marea di documenti tra loro interconnessi. L'utilizzo di un LLM per ridurre i tempi di diagnosi del problema aumenterà inavvertitamente l'efficienza.
In questo acceleratore di soluzioni, ci concentriamo sul punto (3) di cui sopra, ovvero il caso d'uso relativo al potenziamento dei tecnici dell'assistenza sul campo con una base di conoscenza sotto forma di una sessione interattiva di domande e risposte (Q/A) sensibile al contesto. La sfida che i produttori devono affrontare è come creare e incorporare dati da documenti proprietari negli LLM. L'addestramento degli LLM da zero è un'operazione molto costosa, con un costo di centinaia di migliaia, se non milioni, di dollari.
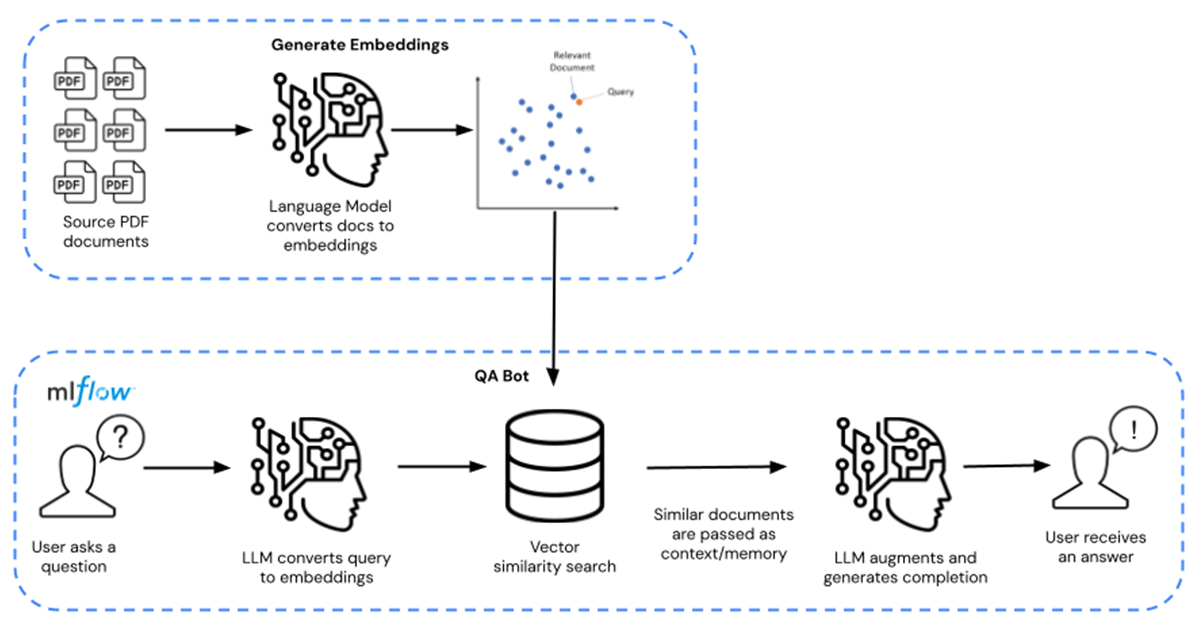
Le aziende possono invece attingere a modelli LLM di base pre-addestrati (come MPT-7B e MPT-30B di MosaicML) e arricchirli e perfezionarli con i propri dati proprietari. Questo riduce i costi a decine, se non centinaia di dollari, per un risparmio effettivo di 10.000 volte. Il percorso completo per il fine-tuning è mostrato da sinistra a destra, mentre il percorso per l'esecuzione di query Q/A è mostrato da destra a sinistra nella Figura 1 sottostante.
{kind=link}
In questo acceleratore di soluzioni, l'LLM è potenziato con schede informative chimiche distribuite in formato PDF disponibili pubblicamente. Può essere sostituito con qualsiasi dato proprietario a tua scelta. Le schede informative vengono trasformate in embedding e utilizzate come retriever per il modello. Langchain è stato quindi utilizzato per compilare il modello, che viene poi ospitato su Databricks MLflow. Il deployment assume la forma di un endpoint di Model Serving di Databricks con capacità di inferenza GPU.
Potenzia oggi la tua azienda scaricando qui questi asset. Contatta il tuo referente Databricks per capire meglio perché Databricks è la piattaforma di riferimento per creare e distribuire LLM.
Esplora l'acceleratore di soluzioni qui.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.