Dati strutturati vs non strutturati
- I dati strutturati sono organizzati in schemi predefiniti. Archiviati in tabelle con formati fissi, i dati strutturati consentono query SQL veloci, supportano gli strumenti di Business Intelligence e servono per le analitiche tradizionali come il reporting e le previsioni, ma le modifiche allo schema possono essere complesse.
- I dati non strutturati rappresentano l'80-90% dei dati aziendali e richiedono strumenti avanzati per estrarre informazioni dettagliate da data lake o architetture lakehouse.
- Le aziende moderne necessitano di approcci ibridi che combinino entrambi i tipi di dati. Le architetture Lakehouse unificano la gestione dei dati strutturati e non strutturati, offrendo l'apertura dei data lake con l'affidabilità dei data warehouse, fornendo al contempo una governance unificata per tutti i tipi di dati.
I dati strutturati e non strutturati sono entrambi asset fondamentali per le organizzazioni moderne, ma sono fondamentalmente diversi. Le organizzazioni devono comprendere queste differenze e gestire ogni tipo in modo efficace per sfruttarne appieno il valore. Questa guida esamina le implicazioni pratiche, i casi d'uso reali e le considerazioni strategiche per la scelta del tipo di dati più adatto. Tratta anche di strumenti per i requisiti aziendali comuni, andando oltre i confronti generici per arrivare a quadri decisionali pratici.
Dati strutturati: caratteristiche e applicazioni
Caratteristiche principali dei dati strutturati
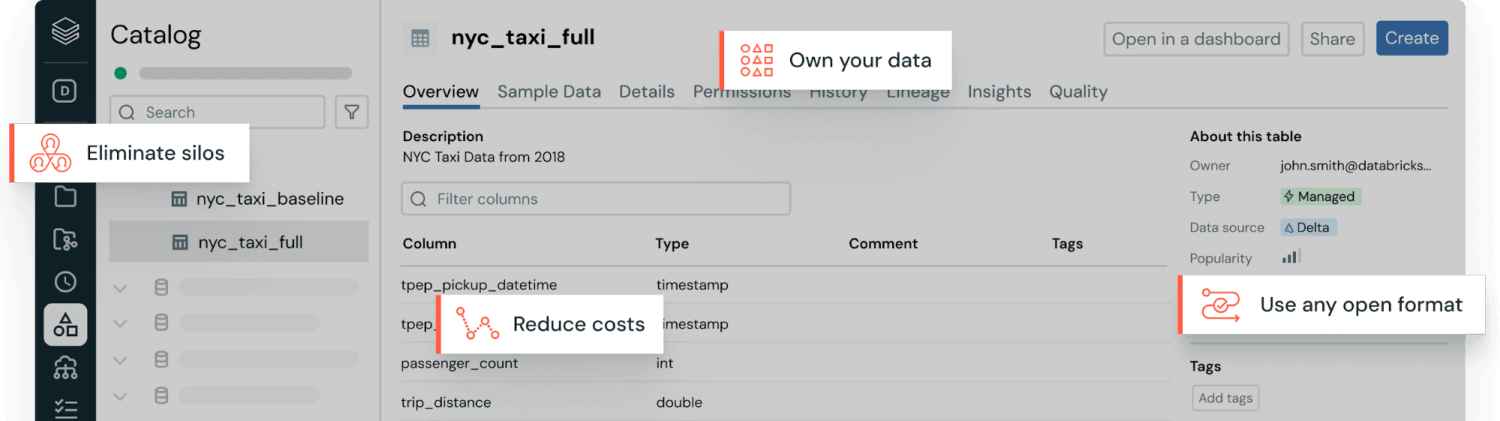
I dati strutturati sono informazioni organizzate all'interno di un modello di dati relazionale predefinito, il che significa che i dati sono disposti in tabelle con schemi fissi. Questo modello specifica la struttura (righe e colonne), i tipi di dati e le relazioni tra le tabelle prima dell'archiviazione dei dati, per consentire una ricerca e un'analisi efficienti. Esempi comuni di dati strutturati includono transazioni finanziarie, file Excel, record di gestione delle relazioni con i clienti (CRM), livelli di inventario, ordini di vendita, sistemi di prenotazione e letture dei sensori.
I dati strutturati sono in genere archiviati in data warehouse. Questi sono ottimizzati per query rapide e affidabili tramite lo Structured Query Language (SQL), utilizzato per carichi di lavoro di dati strutturati.
Il formato standardizzato rende inoltre i dati strutturati altamente accessibili. Gli utenti aziendali possono esplorare, analizzare e creare report sui dati con facilità, utilizzando i familiari strumenti di business intelligence (BI) e di analisi per generare informazioni dettagliate senza bisogno di competenze tecniche avanzate.
Valore aziendale e analisi dei dati strutturati
I dati strutturati offrono un valore aziendale significativo perché il loro formato coerente e filtrabile supporta l'analisi dei dati con una pre-elaborazione minima, consentendo alle organizzazioni di eseguire calcoli, creare modelli e confrontare tendenze in modo efficiente. I dati strutturati costituiscono la spina dorsale delle analitiche aziendali, offrendo interrogazioni rapide, un'elevata integrità dei dati e output affidabili di cui le organizzazioni possono fidarsi per la pianificazione quotidiana e strategica. Ciò include la BI tradizionale, come la reportistica di routine, le previsioni, il monitoraggio dei KPI e le dashboard interattive che aiutano le organizzazioni a monitorare le prestazioni e a prendere decisioni per ottimizzare le attività operative.
I dati strutturati sono anche molto efficaci per i modelli di machine learning (ML) e i sistemi automatizzati che generano informazioni avanzate come riepiloghi generati dall'IA e la valutazione del sentiment dei clienti.
Archiviazione di dati strutturati e considerazioni sulla scalabilità
Un vantaggio principale dei set di dati strutturati è l'elevata efficienza di archiviazione tramite la compressione colonnare. Poiché i valori nella stessa colonna tendono a essere simili, i database colonnari consentono una compressione e una lettura efficienti dei dati, con conseguenti significativi risparmi di spazio di archiviazione e analitiche più rapide.
Tuttavia, le modifiche allo schema all'interno dei dati strutturati possono essere complesse. Poiché gli ecosistemi dei database sono altamente connessi, con molte dipendenze, modifiche come l'aggiunta, la modifica o la rimozione di campi possono causare perdita di dati, tempi di inattività delle applicazioni e guasti a cascata in altre parti del sistema, se non gestite correttamente. Le organizzazioni devono pianificare attentamente le migrazioni per evitare interruzioni.
Dati non strutturati: caratteristiche, sfide e opportunità
Caratteristiche e fonti dei dati non strutturati
I dati non strutturati sono informazioni nel loro formato nativo. A differenza dei dati strutturati, che sono organizzati in righe e colonne, i dati non strutturati sono privi di una struttura predefinita, il che li rende più difficili da ricercare e analizzare.
I dati in forma non strutturata possono essere generati da macchine, come dati GPS, file di log e altre informazioni di telemetria, oppure generati dall'uomo. Esempi di dati non strutturati generati dall'uomo includono post dei social media, file audio, file video, email, file multimediali e documenti di testo.
I dati non strutturati rappresentano dall'80% al 90% della crescita dei dati aziendali. Questo tipo di dati può offrire informazioni dettagliate preziose in aree come le tendenze di mercato, il sentiment dei clienti e i problemi operativi, ma estrarre tali informazioni dettagliate può essere complesso rispetto al lavoro con dati strutturati.
Analisi dei dati non strutturati: sfide e soluzioni
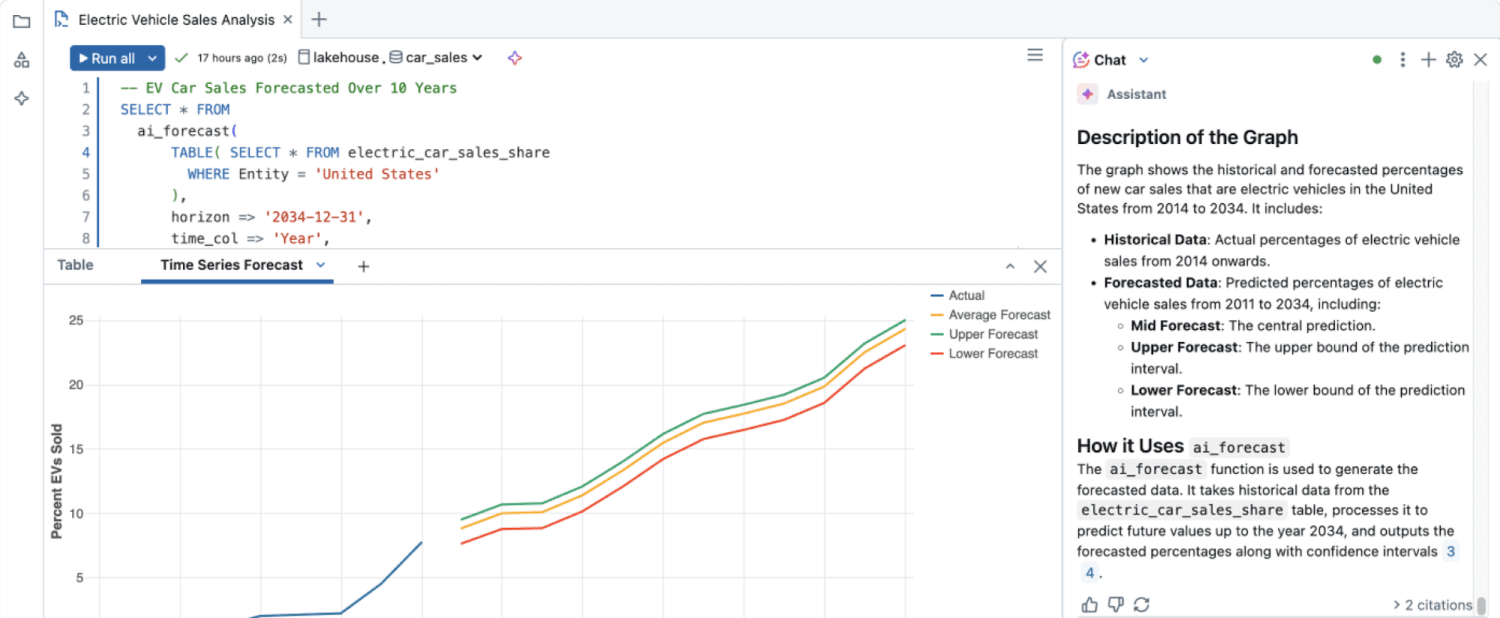
Gli approfondimenti sui dati non strutturati sono rimasti in gran parte inesplorati fino alla creazione di analisi dei dati avanzate, come gli algoritmi di ML, l'elaborazione del linguaggio naturale (NLP) e l'analisi del sentiment, in grado di estrarre automaticamente significato da grandi volumi di dati non strutturati.
In genere, le organizzazioni hanno bisogno di data scientist per gestire, elaborare ed estrarre pattern significativi dai dati non strutturati utilizzando tecniche avanzate. I data lake sono comunemente utilizzati per consolidare i dati non strutturati nel loro formato nativo e grezzo, offrendo uno spazio di archiviazione flessibile per grandi volumi. I data lake consentono di trasformare i dati grezzi in dati strutturati pronti per analisi SQL, data science e machine learning con bassa latenza. I data lake possono anche conservare i dati grezzi a tempo indeterminato e a basso costo per un uso futuro in ambito di ML e analitiche.
Tuttavia, i data lake possono facilmente degenerare in "paludi di dati" con problemi di affidabilità, prestazioni e governance. I data lake tradizionali da soli non sono sufficienti per soddisfare le esigenze delle aziende che desiderano innovare, motivo per cui le aziende operano spesso in architetture complesse, con dati isolati in diversi sistemi di archiviazione in tutta l'azienda.
L'archiviazione Lakehouse unifica la gestione dei dati strutturati e non strutturati per affrontare le sfide poste dai data lake. I Lakehouse implementano strutture simili a quelle dei data warehouse e funzionalità di gestione direttamente nell'archiviazione dati a basso costo di un data lake, combinando l'apertura dei data lake con le funzionalità di gestione e affidabilità dei data warehouse. Questa struttura garantisce che le aziende possano sfruttare vari tipi di dati per progetti di Data Science, ML e business analitiche.
Sbloccare il valore di business dai dati non strutturati
I dati non strutturati contengono informazioni ricche che le tecniche di analisi tradizionali non possono interpretare facilmente. Le funzionalità di machine learning consentono di elaborare contenuti non strutturati su vasta scala, identificando schemi, temi, sentiment e anomalie che altrimenti rimarrebbero nascosti. Utilizzando tecniche come l'NLP e la computer vision, le organizzazioni possono trasformare i dati qualitativi in informazioni dettagliate pratiche utilizzate per informare le decisioni.
Ad esempio, per migliorare il servizio clienti, le organizzazioni possono utilizzare l'IA per analizzare una varietà di fonti, tra cui recensioni di prodotti, trascrizioni di call center, menzioni sui social media e conversazioni con chatbot. I modelli identificati possono essere utilizzati per rivelare opportunità per risolvere problemi, aumentare l'efficienza e stimolare l'innovazione per migliorare l'esperienza del cliente.
Differenze principali tra dati strutturati e non strutturati e framework decisionale
Comprendere le differenze tra dati strutturati e non strutturati è essenziale per progettare architetture di dati efficaci e scegliere metodi analitici appropriati. Ogni tipo presenta punti di forza e sfide unici di cui si deve tener conto nella strategia dei dati di un'organizzazione.
Dimensioni di confronto fondamentali
- Formato dei dati: i dati strutturati sono organizzati in un formato fisso e predefinito. Ogni record utilizza lo stesso insieme di campi e tipi di dati, in modo che tutto rimanga coerente. I dati non strutturati sono archiviati nella loro forma grezza e nativa senza una struttura uniforme, il che li rende più flessibili ma più difficili da organizzare e analizzare.
- Strumenti di analisi: i dati strutturati possono essere facilmente interrogati tramite SQL e integrati negli strumenti di business intelligence standard. I dati non strutturati richiedono metodi di analitiche più avanzati, tra cui ML, NLP e visione artificiale. Questi sono generalmente gestiti da data scientist o analisti specializzati.
- Archiviazione: i dati strutturati si inseriscono naturalmente nei data warehouse, ottimizzati per le query relazionali e le prestazioni. I dati non strutturati sono più adatti ai data lake, che consentono alle organizzazioni di archiviare dati grezzi su larga scala, o ad architetture ibride lakehouse.
- Tempo di elaborazione: poiché i dati strutturati sono già organizzati, spesso possono essere analizzati immediatamente con una preparazione minima. I dati non strutturati richiedono generalmente una notevole pre-elaborazione, come pulizia, tokenizzazione, etichettatura ed estrazione di feature, prima che si possano generare informazioni dettagliate significative.
- Accessibilità per gli utenti: i dati strutturati sono accessibili a un'ampia gamma di utenti, inclusi business analyst e decisori che possono esplorarli tramite dashboard e strumenti di reporting. I dati non strutturati richiedono solitamente le competenze di data scientist o ingegneri per convertirli in formati utilizzabili e ricavare informazioni dettagliate azionabili.
Dati semi-strutturati e approcci moderni
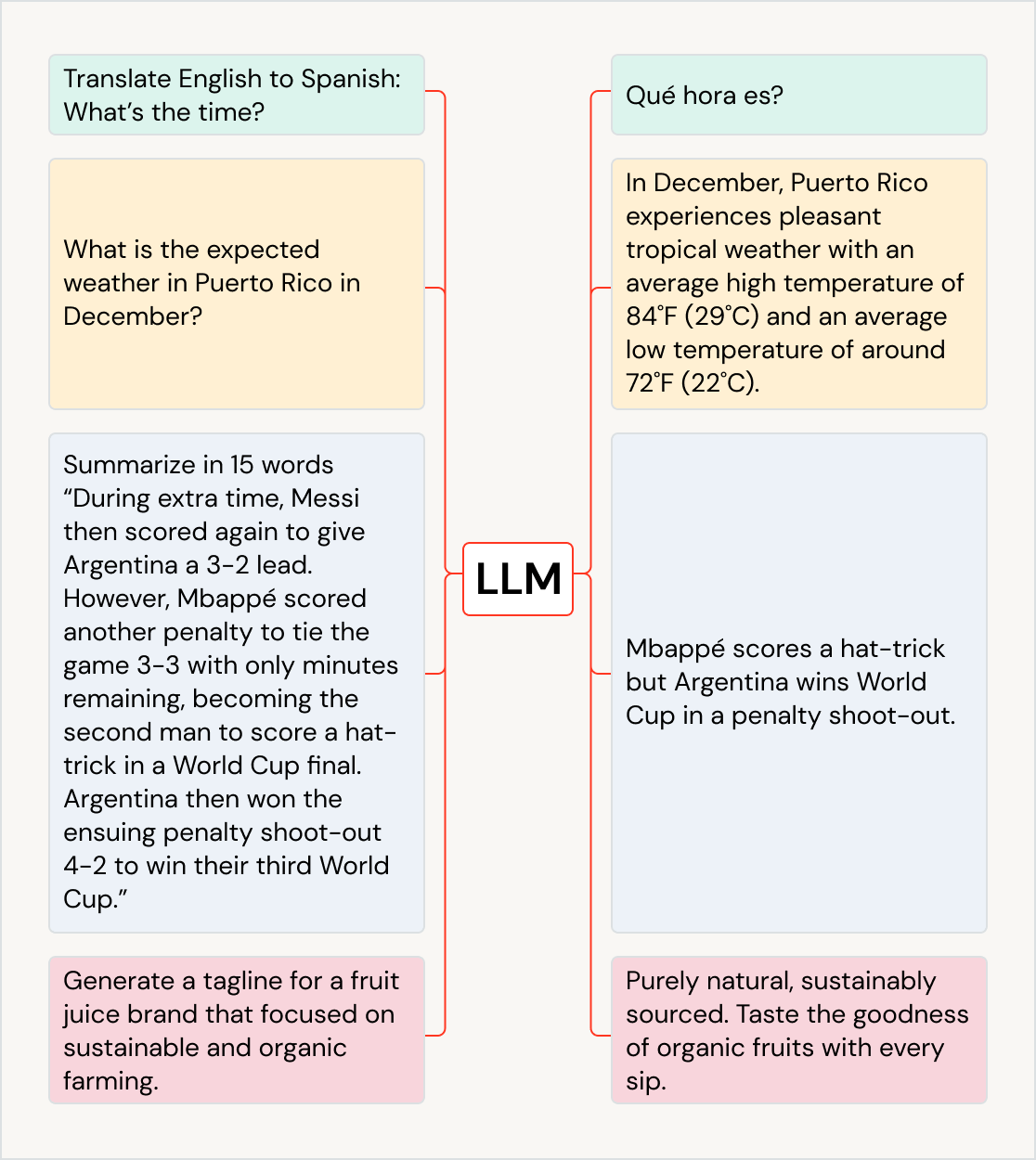
La via di mezzo ibrida
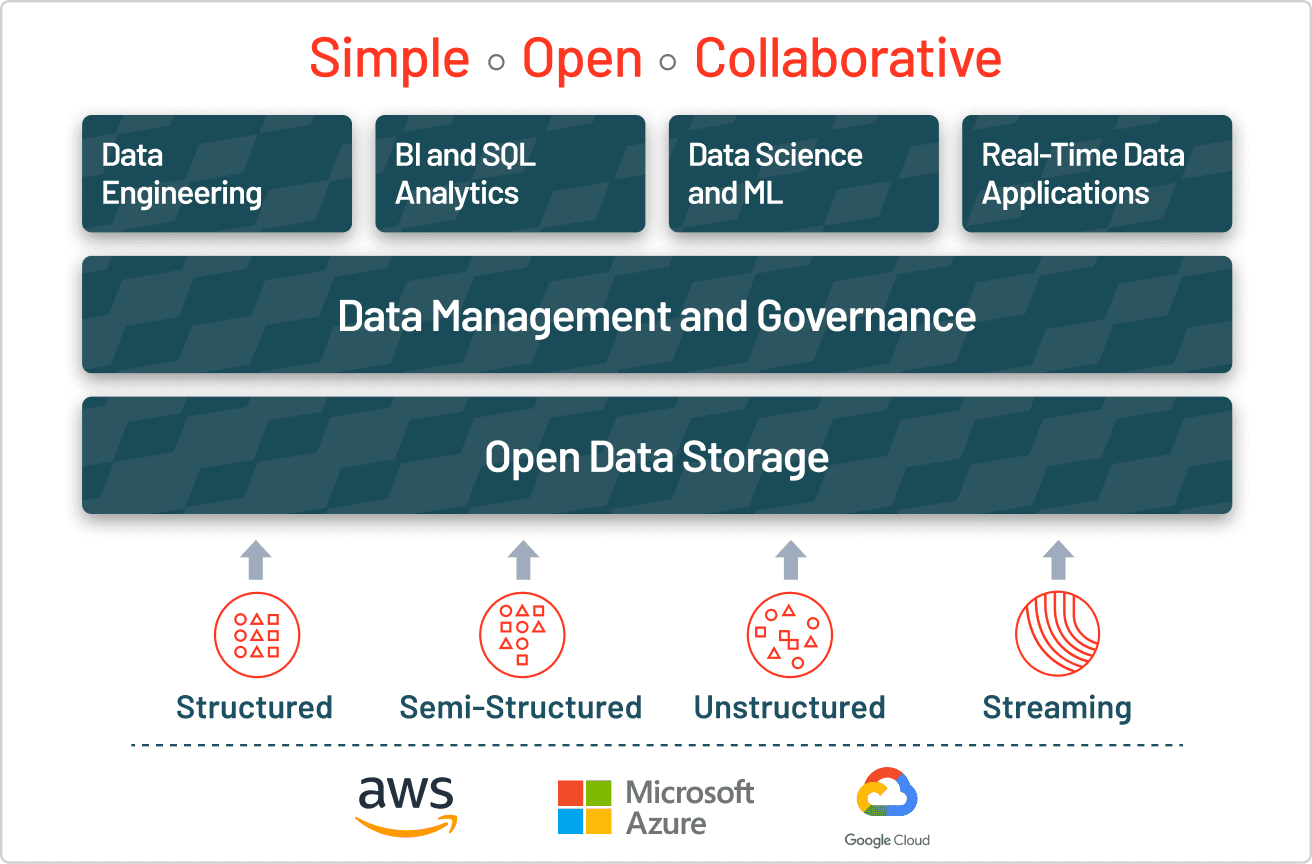
I dati strutturati e non strutturati non sono gli unici formati che le organizzazioni devono gestire. I dati semistrutturati colmano il divario tra i due, utilizzando tag di metadati per aggiungere un certo livello di organizzazione pur consentendo campi flessibili e in evoluzione. Esempi comuni includono i file JSON, XML e CSV. Le organizzazioni usano spesso database NoSQL e file system moderni per gestire questo tipo di dati, perché supportano schemi flessibili e si adattano più facilmente ai cambiamenti dei formati dei dati.
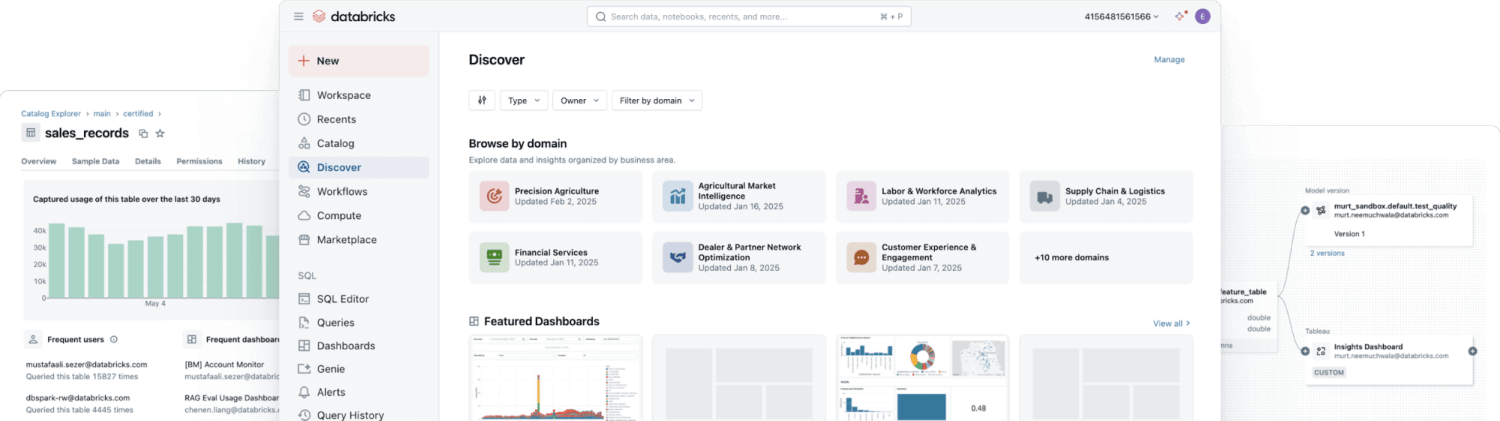
La maggior parte delle aziende ha bisogno di tutti i tipi di dati, quindi sta adottando strategie di archiviazione ibride che uniscono i punti di forza di diversi approcci ai dati. La moderna architettura lakehouse elimina la necessità di scegliere tra data lake e data warehouse, combinando le loro capacità in un'unica piattaforma. Unity Catalog di Databricks offre una governance unificata e aperta per tutti i i dati strutturati, i dati non strutturati, le metriche di business e i modelli di IA in qualsiasi cloud. Ciò consente alle organizzazioni di governare, scoprire, monitorare e condividere i dati, il tutto in un unico posto, semplificando la conformità e accelerando l'ottenimento di informazioni approfondite.
Conclusione
La strategia dei dati non è una soluzione universale. Comprendere le differenze tra dati strutturati, non strutturati e semi-strutturati è essenziale per creare una gestione dei dati efficace. Le organizzazioni devono disporre delle competenze necessarie per abbinare i tipi di dati alle loro specifiche esigenze di analisi e ai requisiti aziendali. Allineando le scelte sui dati ai loro casi d'uso specifici, le aziende possono ottenere informazioni più dettagliate, migliorare il processo decisionale e massimizzare l'impatto dei loro investimenti nei dati.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.