Modelli linguistici di grandi dimensioni
Accelerare l'innovazione utilizzando modelli LLM con Databricks

Cosa sono i modelli linguistici di grandi dimensioni?
I modelli linguistici di grandi dimensioni (LLM) sono modelli di machine learning molto efficaci nello svolgere compiti associati al linguaggio, come traduzioni, risposte a domande, chat e riassunto di contenuti, oltre a generazione di contenuti e codice. I modelli LLM estrapolano valore da grandi set di dati e rendono tale "conoscenza" accessibile in modo immediato. Databricks semplifica l'integrazione di questi modelli LLM nei flussi di lavoro e offre una piattaforma con funzionalità per ottimizzare i modelli LLM sui dati di ciascuna azienda, per migliorare le prestazioni in ambiti specifici.

Elaborazione del linguaggio naturale (NLP) con LLM
S&P Global usa modelli linguistici di grandi dimensioni su Databricks per comprendere meglio le principali differenze e similarità negli archivi delle aziende, aiutando i responsabili delle risorse a costruire un portafoglio più diversificato.
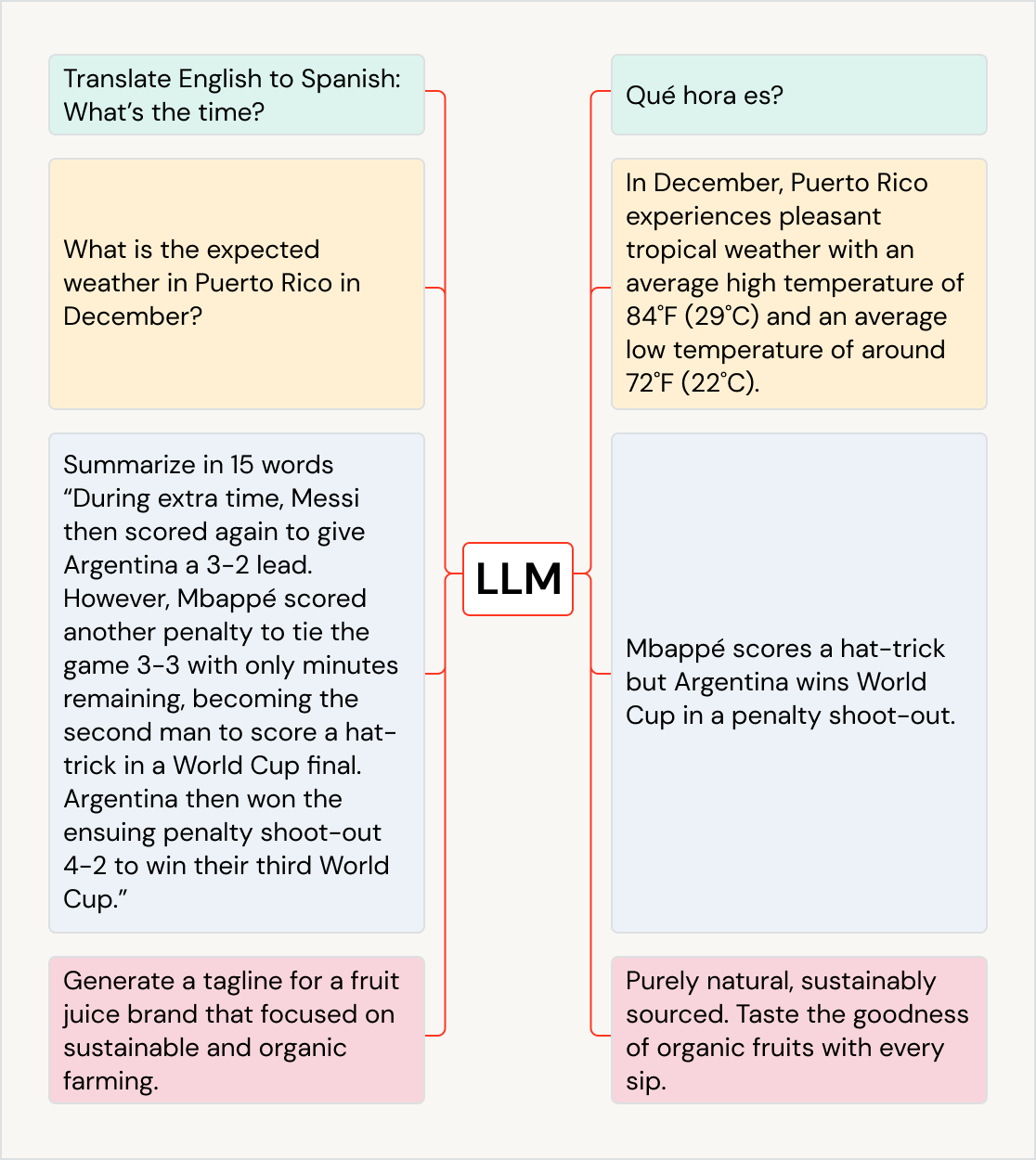
Utilizzo di LLM per svariati casi d'uso
Gli LLM possono avere un grande impatto su un'ampia gamma di casi d'uso e settori: tradurre testi in altre lingue, migliorare l'esperienza dei clienti con chatbot e assistenti AI, catalogare e distribuire ai giusti reparti i feedback dei clienti, riassumere documenti voluminosi, come teleconferenze di presentazione dei risultati finanziari e documenti legali, creare nuovi contenuti di marketing e generare codice software da linguaggio naturale. I modelli LLM possono essere utilizzati anche per alimentare altri modelli, ad esempio quelli che generano opere d'arte. Fra gli LLM più conosciuti ci sono i modelli della famiglia GPT (ad es. ChatGPT), BERT, T5 e BLOOM.
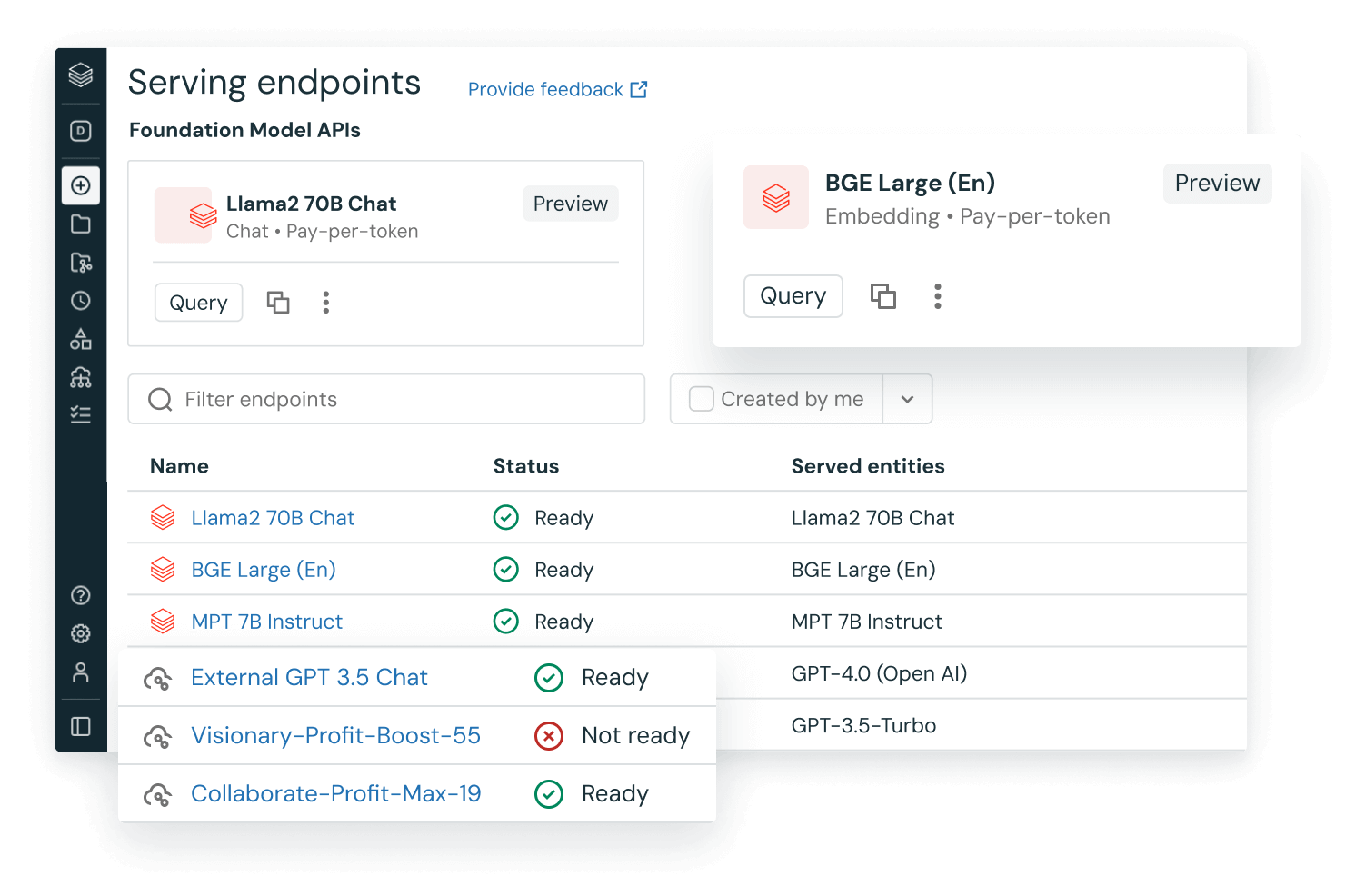
Utilizzo di LLM pre-addestrati nelle app
Nel flusso di lavoro si possono integrare modelli pre-addestrati, come quelli provenienti dalla libreria di trasformatori di Hugging Face o da altre librerie open-source. Le pipeline dei trasformatori facilitano l'uso di GPU e consentono di elaborare in batch gli elementi inviati alla GPU per aumentare la produttività.
Il flavor di MLflow per i trasformatori di Hugging Face consente di integrare nativamente pipeline di trasformatori, modelli e componenti di elaborazione nel servizio di tracciamento di MLflow. Si possono inoltre integrare nei flussi di lavoro su Databricks modelli OpenAI o soluzioni di partner come John Snow Labs.
Con le funzioni di AI, gli analisti di dati SQL possono accedere facilmente a modelli LLM, fra cui OpenAI, direttamente all'interno delle loro pipeline di dati e dei loro flussi di lavoro.
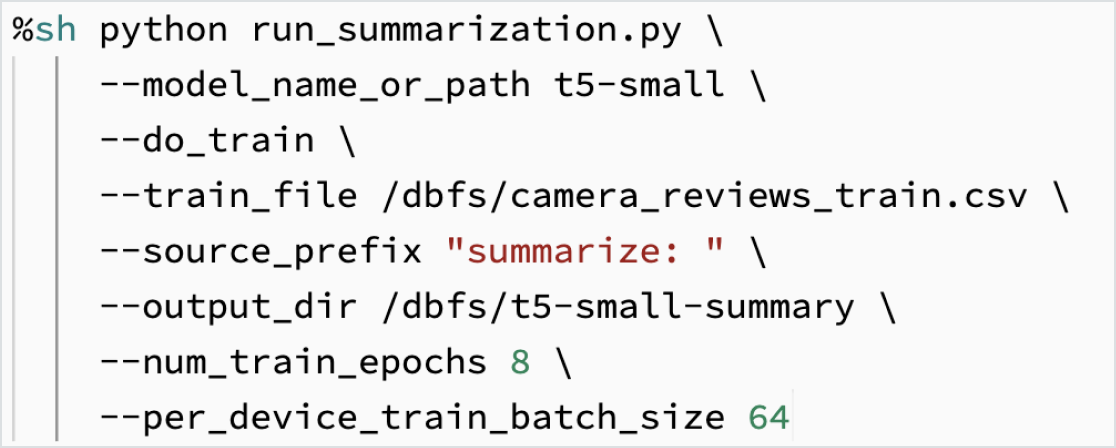
Ottimizzazione dei modelli LLM per i dati aziendali
Un modello può essere personalizzato sui dati aziendali per compiti specifici. Grazie a strumenti open-source come Hugging Face e DeepSpeed, si può prendere un LLM di base in modo rapido ed efficiente e cominciare ad addestrarlo con i propri dati, per avere una maggiore precisione nell'ambito e nel carico di lavoro specifici. Questo approccio consente inoltre di controllare i dati utilizzati per l'addestramento, assicurandosi di utilizzare l'AI in modo responsabile.

Dolly 2.0 è un modello linguistico di grandi dimensioni addestrato da Databricks per dimostrare come sia possibile addestrare in modo rapido ed economico il proprio LLM. Anche il dataset di alta qualità generato manualmente (databricks-dolly-15k) utilizzato per addestrare il modello è stato reso pubblico. Con Dolly 2.0, i clienti possono ora possedere, gestire e personalizzare il proprio LLM. Le aziende possono costruire e addestrare un LLM sui propri dati, senza dover inviare i dati a LLM proprietari. Per ottenere il codice di Dolly 2.0, i pesi dei modelli o il set di dati databricks-dolly-15k, visita Hugging Face.
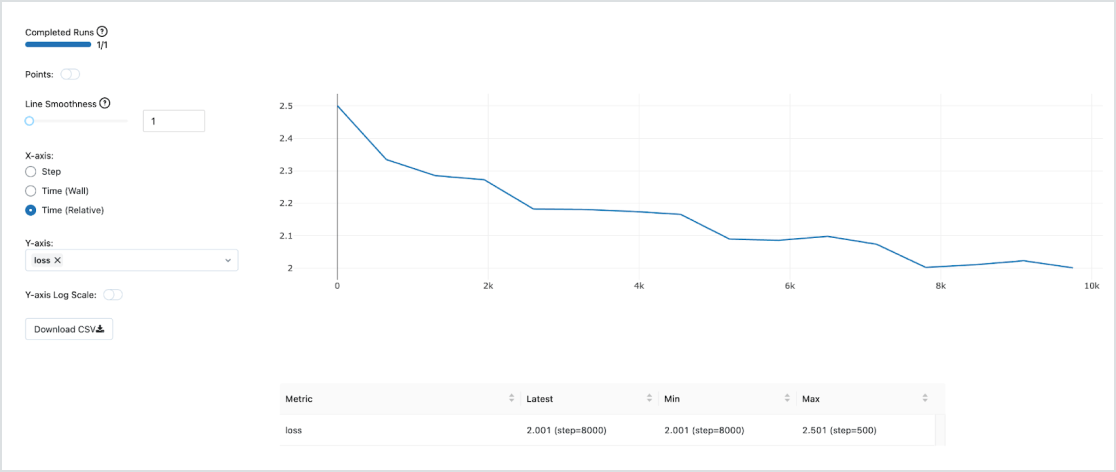
LLMOps integrate (MLOps per LLM)
Utilizza MLOPs integrate e pronte per la produzione con Managed MLflow per il tracciamento, la gestione e l'implementazione dei modelli. Una volta implementato il modello, si possono monitorare aspetti quali latenza, deriva dei dati e altro ancora, con la possibilità di avviare il riaddestramento delle pipeline... tutto sulla stessa Databricks Lakehouse Platform unificata per eseguire LLMOps a 360 gradi.
Dati e modelli su una piattaforma unificata
La maggior parte dei modelli viene addestrata più di una volta, pertanto diventa fondamentale, in termini di prestazioni e costi, avere tutti i dati di addestramento sulla stessa piattaforma di ML. Addestrando i modelli linguistici di grandi dimensioni (LLM) sul lakehouse si ha accesso a strumenti e sistemi di calcolo di prima qualità, all'interno di un data lakehouse estremamente economico, e si possono riaddestrare continuamente i modelli seguendo l'evoluzione dei dati nel tempo.