Apprendimento supervisionato vs. non supervisionato: comprendere le differenze e le capacità di ciascun approccio di ML
- L'apprendimento supervisionato e non supervisionato hanno scopi diversi: l'apprendimento supervisionato utilizza dati etichettati per fare previsioni e classificazioni precise, mentre l'apprendimento non supervisionato trova pattern nascosti in dati grezzi e non etichettati, rendendo ciascuno più adatto a diversi obiettivi aziendali.
- L'ML moderno fonde entrambi gli approcci: tecniche come l'apprendimento semi-supervisionato e auto-supervisionato combinano i punti di forza di ciascun paradigma.
- La vera sfida è costruire sistemi: l'ML aziendale di successo dipende dall'orchestrazione di entrambi gli approcci all'interno di pipeline di dati affidabili, una governance solida e una valutazione continua durante l'intero ciclo di vita del modello.
I sistemi di machine learning imparano dai dati per fare previsioni, classificare informazioni o scoprire pattern che sarebbero difficili da identificare manualmente per gli esseri umani.
Cos'è l'apprendimento supervisionato?
Nell'apprendimento supervisionato, i modelli vengono addestrati utilizzando dati etichettati, dove ogni input è associato a un output noto. Il modello impara confrontando le sue previsioni con queste risposte corrette e riducendo iterativamente l'errore.
Al centro di questo processo ci sono i modelli di machine learning che apprendono relazioni esplicite tra feature e risultati. La presenza di dati etichettati fornisce una guida chiara, rendendo l'apprendimento supervisionato adatto a problemi in cui accuratezza, tracciabilità e ripetibilità sono essenziali.
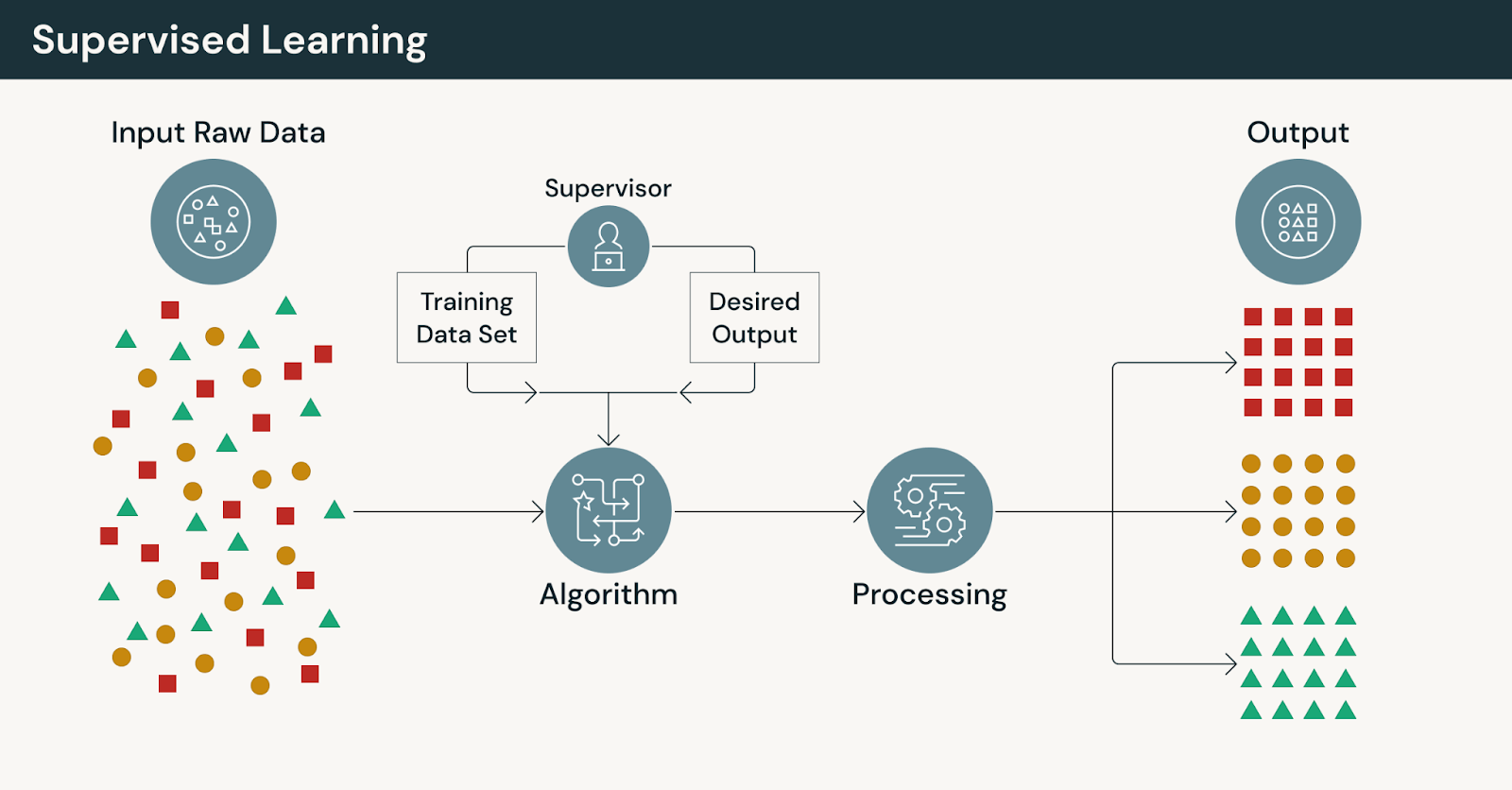
Come funziona l'apprendimento supervisionato
Un tipico flusso di lavoro di apprendimento supervisionato include:
- Raccolta di dati storici di addestramento con risultati noti
- Preparazione e validazione di set di dati di addestramento etichettati
- Ingegnerizzazione delle feature che catturano segnali rilevanti
- Addestramento e valutazione dei modelli rispetto alla ground truth
- Distribuzione dei modelli e monitoraggio delle prestazioni nel tempo
Questo flusso di lavoro dipende dalla disponibilità e dalla qualità delle etichette, un vincolo che spesso diventa più evidente all'aumentare del volume dei dati.
Tipi di apprendimento supervisionato
I problemi di apprendimento supervisionato rientrano generalmente in due categorie:
- Classificazione: Assegnazione di dati di input a classi predefinite, come email spam o legittime, o sentiment positivo o negativo.
- Regressione: Previsione di valori continui, come previsioni della domanda, prezzi o punteggi di rischio. Le compagnie di trasporto utilizzano modelli di regressione per prevedere i tempi di volo in base alle prestazioni storiche delle rotte, ai pattern stagionali e ai fattori operativi, aiutando a ottimizzare la pianificazione e a stabilire aspettative accurate per i clienti.
In entrambi i casi, le prestazioni del modello possono essere misurate direttamente rispetto ai risultati noti, il che semplifica la valutazione e la responsabilità.
Applicazioni comuni dell'apprendimento supervisionato
L'apprendimento supervisionato automatico è comunemente utilizzato per:
- Filtro email e moderazione dei contenuti
- Analisi del sentiment nel feedback dei clienti
- Previsioni e analisi predittive
- Classificazione di immagini e documenti
Molte applicazioni di elaborazione del linguaggio naturale si basano sul fine-tuning supervisionato per adattare modelli generici a compiti, policy o vocabolari specifici del dominio.
Apprendimento supervisionato nei vari settori
Le applicazioni di apprendimento supervisionato spaziano praticamente in ogni settore, con alcuni casi d'uso che sono diventati fondamentali per l'infrastruttura digitale moderna.
Cybersecurity: I sistemi di rilevamento dello spam analizzano miliardi di email al giorno, utilizzando modelli supervisionati addestrati su esempi etichettati di messaggi legittimi e dannosi. Il rilevamento moderno dello spam va oltre il semplice confronto di parole chiave, incorporando la reputazione del mittente, la struttura del messaggio, l'analisi degli allegati e i pattern comportamentali.
Sanità e scienze della vita: L'apprendimento supervisionato prevede l'addestramento di modelli predittivi su dati biomedici e genomici etichettati per identificare pattern associati a varianti legate a malattie e target terapeutici. Applicando questi modelli all'interno di una piattaforma di analisi scalabile, i ricercatori possono quantificare le relazioni tra caratteristiche genetiche e risultati clinici, consentendo una previsione più accurata dei target farmacologici e accelerando la scoperta basata su ipotesi.
Servizi finanziari: L'apprendimento supervisionato è stato utilizzato per addestrare modelli di rilevamento del rischio e delle frodi su dati storici di transazioni etichettati, consentendo al sistema di distinguere tra attività legittime e sospette. Apprendendo da risultati noti, come casi di frode confermati o comportamenti validati dei clienti, i modelli hanno migliorato l'accuratezza del rilevamento in tempo reale riducendo al contempo i falsi positivi. Distribuiti all'interno di una piattaforma dati scalabile, questi modelli supervisionati hanno supportato un processo decisionale più rapido e una gestione del rischio finanziario più resiliente.
Retail e beni di consumo: Utilizzando dati storici di vendite, prezzi e promozioni etichettati, sono stati addestrati modelli predittivi per prevedere la domanda e ottimizzare le decisioni di inventario su larga scala. Apprendendo da risultati noti, come i movimenti di prodotti precedenti e i pattern di domanda regionali, il sistema ha migliorato l'accuratezza delle previsioni in migliaia di località. Ciò ha consentito una rifornitura più precisa, ridotto le rotture di stock e un allineamento più stretto tra le operazioni della catena di approvvigionamento e la domanda dei clienti.
Esperienze dei clienti: Modelli predittivi sono stati addestrati su dati unificati e etichettati di interazioni e profili dei clienti per apprendere pattern che aiutano a segmentare il pubblico e prevedere i comportamenti dei clienti. Questi modelli supervisionati hanno fornito insight più accurati sui clienti, supportando strategie di marketing mirato e personalizzazione. Ciò ha portato a una consegna più rapida di insight azionabili che migliorano il coinvolgimento e l'esperienza del cliente attraverso i canali.
Media e intrattenimento: Dati etichettati di gameplay, coinvolgimento e comportamento sono stati utilizzati per addestrare modelli predittivi che identificano pattern nell'attività dei giocatori e nell'interazione con i contenuti. Apprendendo da risultati noti, come segnali di abbandono, comportamenti in-game e tendenze della community, il sistema ha consentito previsioni più accurate e un'ottimizzazione dei contenuti più rapida. Ciò ha supportato migliori esperienze per i giocatori, decisioni operative live più efficaci e uno sviluppo basato sui dati in un ecosistema di gioco globale.
Ogni applicazione condivide un requisito comune: dati di addestramento etichettati affidabili che rappresentano accuratamente lo spazio del problema e un monitoraggio continuo per rilevare quando le prestazioni del modello degradano.
Cos'è l'apprendimento non supervisionato?
Piuttosto che apprendere da esempi etichettati, l'apprendimento automatico non supervisionato analizza dati non etichettati per identificare pattern, strutture o relazioni senza target predefiniti.
Ciò rende l'apprendimento non supervisionato particolarmente prezioso nelle fasi iniziali dei progetti di ML, quando i team potrebbero non sapere ancora quali domande porsi, o quando l'etichettatura dei dati è impraticabile o proibitiva in termini di costi.
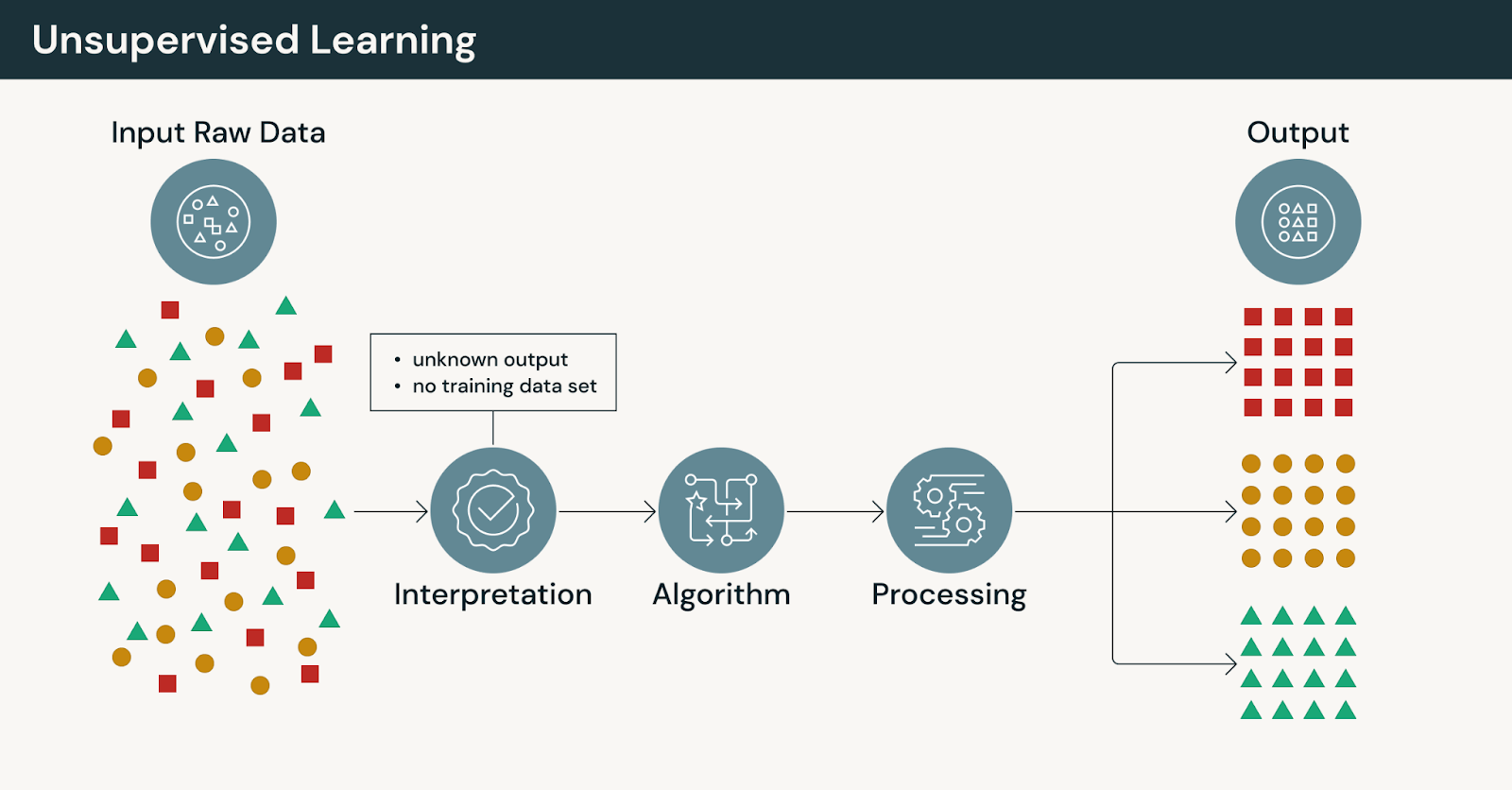
Come funziona l'apprendimento non supervisionato
Nell'apprendimento non supervisionato:
- I modelli operano senza etichette esplicite fornite dall'uomo
- Gli algoritmi raggruppano, comprimono o organizzano i dati in base alla similarità
- Gli output richiedono interpretazione e validazione da parte di esperti di dominio
Poiché non ci sono risposte corrette, l'apprendimento non supervisionato enfatizza l'esplorazione piuttosto che la previsione.
Tipi di apprendimento non supervisionato
Le tecniche comuni di apprendimento non supervisionato includono:
- Clustering: Raggruppamento di punti dati simili per rivelare la struttura
- Riduzione della dimensionalità: Semplificazione di dataset complessi per l'analisi
- Apprendimento di regole di associazione: Identificazione di relazioni tra variabili
Molti di questi metodi si basano su algoritmi di clustering per far emergere pattern che non erano definiti esplicitamente in anticipo.
Applicazioni comuni dell'apprendimento non supervisionato
L'apprendimento automatico non supervisionato è ampiamente utilizzato per:
- Strategie di segmentazione dei clienti nel marketing e nella personalizzazione, utilizzando il clustering per raggruppare dati simili per comportamento, preferenze e valore anziché per categorie predeterminate
- Sistemi di rilevamento delle anomalie per la prevenzione delle frodi e il monitoraggio operativo
- Analisi esplorativa dei dati e scoperta di pattern comportamentali
- Ricerca e raggruppamento di similarità su larga scala
- Analisi del carrello della spesa e sistemi di raccomandazione dei prodotti, dove algoritmi come l'algoritmo Apriori scoprono pattern di acquisto e associazioni di prodotti senza che venga detto quali articoli dovrebbero essere correlati
Man mano che le organizzazioni accumulano più dati grezzi, l'apprendimento non supervisionato offre un modo per estrarre valore senza attendere sforzi di etichettatura esaustivi.
Differenze chiave tra apprendimento supervisionato e non supervisionato
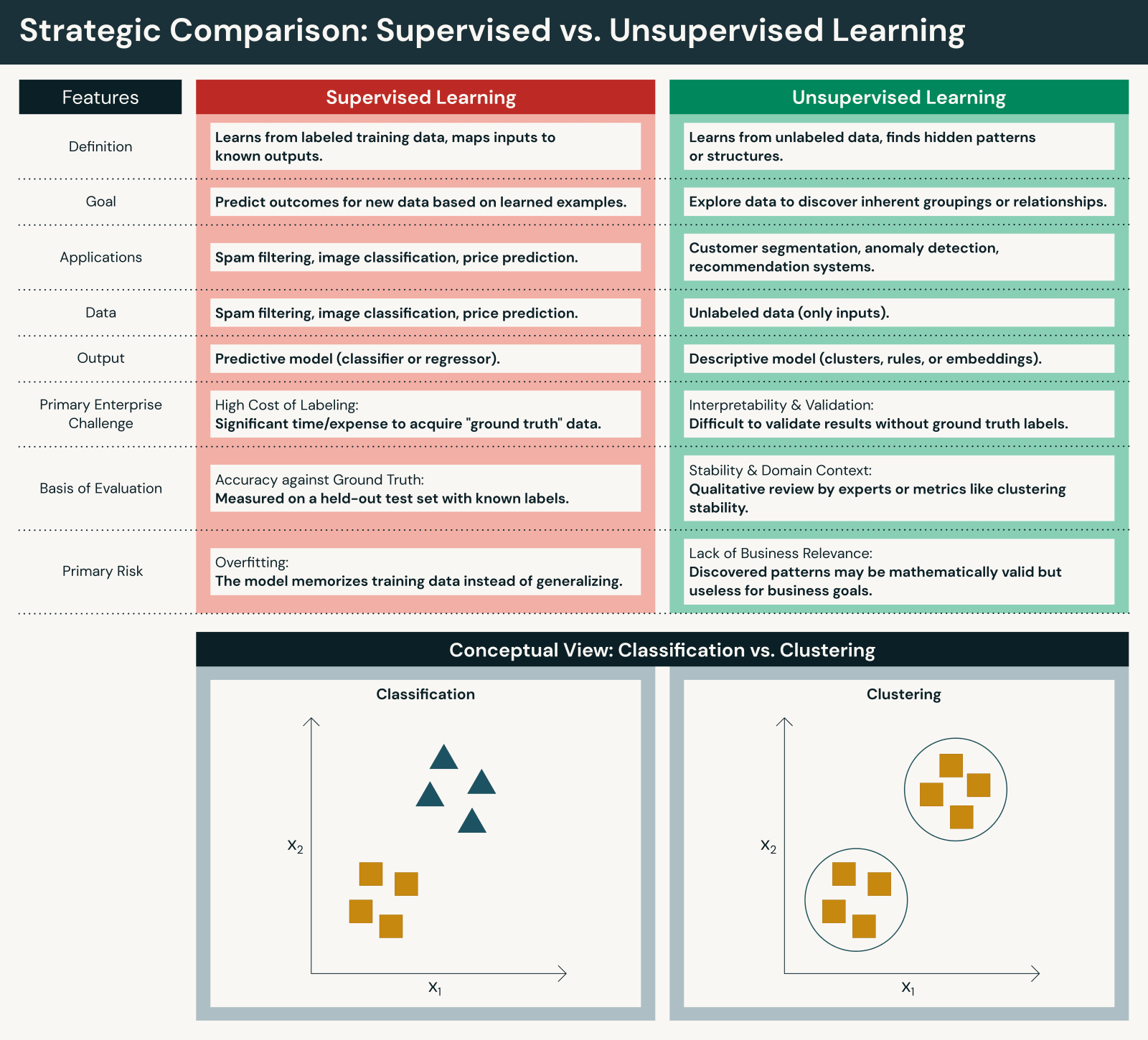
Sebbene entrambi gli approcci siano fondamentali, differiscono in modi importanti:
Dati e sforzo umano
- L'apprendimento supervisionato richiede set di dati etichettati, spesso creati tramite annotazione manuale o revisione di esperti. Sebbene l'apprendimento automatico supervisionato richieda un significativo intervento umano per l'etichettatura, questo intervento umano garantisce che l'accuratezza sia in linea con gli obiettivi aziendali.
- L'apprendimento non supervisionato lavora direttamente sui dati grezzi, riducendo la preparazione iniziale ma aumentando lo sforzo di interpretazione. L'apprendimento automatico non supervisionato riduce l'intervento umano durante l'addestramento ma richiede l'intervento umano per interpretare i risultati.
Obiettivi
- L'apprendimento supervisionato si concentra sulla previsione e classificazione rispetto a risultati noti per prevedere gli esiti con precisione.
- L'apprendimento non supervisionato si concentra sulla scoperta e sulla generazione di insight per scoprire pattern nei dati.
Valutazione e trasparenza
- I modelli supervisionati possono essere valutati utilizzando metriche di performance chiare rispetto a risposte corrette (accuratezza, precisione, richiamo, F1, RMSE, ecc.).
- I modelli di apprendimento non supervisionato richiedono una valutazione indiretta e un contesto di dominio per valutarne l'utilità (punteggi silhouette, metodo del gomito, validazione di esperti di dominio, ecc.).
Scalabilità
- L'apprendimento supervisionato spesso scala più lentamente a causa dei vincoli di etichettatura.
- L'apprendimento non supervisionato scala naturalmente con il volume dei dati ma può produrre risultati più rumorosi.
Negli ambienti enterprise, queste differenze chiave spingono i team verso approcci ibridi piuttosto che scelte esclusive.
Il playbook sull'AI agentiva per l'enterprise

Apprendimento semi-supervisionato e auto-supervisionato
I moderni sistemi di ML combinano sempre più paradigmi:
L'apprendimento semi-supervisionato combina un piccolo set di dati etichettato con un pool molto più ampio di dati non etichettati, riducendo i costi di etichettatura pur mantenendo l'accuratezza predittiva.
L'apprendimento auto-supervisionato va oltre, consentendo ai modelli di generare i propri segnali di addestramento dai dati grezzi. Questo approccio è alla base di molti modelli foundation moderni e ha spostato l'apprendimento supervisionato in un ruolo di affinamento piuttosto che di punto di partenza.
Queste tecniche consentono alle organizzazioni di:
- Sfruttare gli asset di dati esistenti su larga scala
- Adattarsi più rapidamente a nuove distribuzioni di dati
- Ridurre la dipendenza dall'etichettatura manuale
Vale la pena notare che l'apprendimento supervisionato e non supervisionato non rappresentano l'intero panorama del machine learning. L'apprendimento per rinforzo è un terzo paradigma principale in cui gli agenti apprendono comportamenti ottimali attraverso interazioni di tentativi ed errori con gli ambienti, ricevendo ricompense o penalità per le loro azioni. Sebbene l'apprendimento per rinforzo esuli dallo spettro supervisionato vs non supervisionato, i sistemi moderni combinano sempre più tutti e tre gli approcci a seconda dei requisiti del task.
Quando usare l'apprendimento supervisionato vs. non supervisionato
In pratica, la scelta giusta dipende dai dati, dagli obiettivi e dai vincoli operativi.
Valuta i tuoi dati
- Hai etichette affidabili oggi?
- Puoi mantenere la qualità dell'etichettatura all'aumentare dei dati?
- Quanto spesso cambiano i tuoi dati?
Definisci il tuo obiettivo
- Prevedere esiti? L'apprendimento supervisionato è adatto.
- Esplorare strutture sconosciute? L'apprendimento non supervisionato è spesso il giusto punto di partenza.
Pianifica l'intero ciclo di vita
Indipendentemente dall'approccio, sistemi di successo dipendono da pipeline di data engineering affidabili che spostano i dati dall'ingestion all'addestramento e alla produzione in modo coerente.
Molti team iniziano con l'esplorazione non supervisionata, quindi introducono l'apprendimento supervisionato una volta che target e metriche sono ben definiti.
Perché la governance unificata di dati e AI è fondamentale per una strategia ML enterprise
Man mano che i sistemi ML scalano, le enterprise devono gestire accessi, lineage, conformità e responsabilità.
È qui che la governance unificata dei dati diventa fondamentale. Governare dati e modelli in modo coerente attraverso i workflow garantisce che gli insight siano affidabili e che i sistemi rimangano verificabili man mano che evolvono.
Affrontare domande comuni
La regressione lineare è supervisionata o non supervisionata?
La regressione lineare è apprendimento supervisionato perché richiede valori di output etichettati.
Qual è la differenza principale tra apprendimento supervisionato e non supervisionato?
L'apprendimento supervisionato prevede esiti noti utilizzando dati etichettati. L'apprendimento non supervisionato scopre pattern in dati non etichettati.
Cosa devi sapere per il futuro
Diverse tendenze stanno rimodellando l'ML enterprise:
- L'apprendimento auto-supervisionato domina l'addestramento dei modelli foundation.
- L'apprendimento supervisionato serve sempre più come livello di precisione.
- Clustering ed embeddings stanno diventando capacità enterprise fondamentali.
- Valutazione e governance stanno acquisendo importanza con l'espansione dell'uso di dati non etichettati.
Questi cambiamenti rafforzano la necessità di pensare in termini di sistemi, non di silos.
Sfide e limitazioni
Sia l'apprendimento supervisionato che quello non supervisionato svolgono ruoli essenziali nell'ML enterprise, ma ognuno presenta compromessi che i team devono pianificare in anticipo.
Sfide dell'apprendimento supervisionato
I requisiti dei dati sono spesso il vincolo maggiore. La creazione di dataset etichettati può richiedere tempo e costi elevati, specialmente quando l'etichettatura richiede competenze di dominio. In molti casi, l'accuratezza del modello è direttamente legata alla qualità delle etichette, rendendo le annotazioni incoerenti o distorte un rischio serio.
I modelli supervisionati affrontano anche rischi di overfitting. Quando i modelli imparano troppo da vicino i dati di addestramento, possono performare bene in valutazione ma fallire nel generalizzare a dati nuovi o non visti. Mitigazioni comuni includono la cross-validation, tecniche di regolarizzazione ed espansione dei dataset di addestramento per riflettere meglio la variabilità del mondo reale.
Le preoccupazioni sulla scalabilità emergono con l'aumentare dei volumi di dati. L'etichettatura human-in-the-loop non scala linearmente e i processi manuali possono diventare colli di bottiglia per progetti grandi o in rapida evoluzione. Senza un'attenta pianificazione, i workflow supervisionati possono faticare a tenere il passo con le esigenze aziendali.
Sfide dell'apprendimento non supervisionato
L'apprendimento non supervisionato introduce un diverso set di problemi, a partire dalla difficoltà di interpretazione. Cluster o pattern potrebbero non avere un significato ovvio senza contesto di dominio, e la struttura scoperta non sempre si allinea agli obiettivi aziendali. Estrarre valore spesso richiede una stretta collaborazione tra data scientist ed esperti di materia.
La complessità della validazione è un'altra sfida. Senza etichette di verità di base, può essere difficile valutare oggettivamente la qualità del modello. I team spesso si affidano a metriche proxy, allineamento aziendale o valutazione comparativa tra più algoritmi per acquisire fiducia nei risultati.
Infine, la selezione dell'algoritmo richiede sperimentazione. Gli esiti possono variare significativamente in base alle scelte dei parametri, alle misure di distanza o ai passaggi di pre-elaborazione, rendendo l'iterazione inevitabile.
Best practice di machine learning
In entrambi gli approcci, diverse pratiche migliorano costantemente i risultati:
- Garantire dati di input di alta qualità, inclusa la corretta gestione dei valori mancanti e degli outlier
- Iniziare con una chiara definizione del problema prima di selezionare un approccio
- Implementare controlli di qualità dei dati e processi di validazione precocemente
- Utilizzare metriche di valutazione appropriate per ciascun paradigma
- Iniziare con l'analisi esplorativa dei dati prima di impegnarsi in workflow di produzione
Soluzioni di data engineering affidabili forniscono le basi per applicare queste pratiche in modo coerente, aiutando i team a passare dalla sperimentazione alla produzione con maggiore sicurezza.
Cosa devi sapere nel 2026
Diversi cambiamenti stanno già rimodellando la pratica dell'ML enterprise.
1. Il pre-addestramento auto-supervisionato ora supporta la maggior parte dei modelli foundation moderni
La maggior parte dei modelli all'avanguardia — inclusi i modelli linguistici di grandi dimensioni, i sistemi di visione artificiale e le architetture multimodali — vengono ora addestrati principalmente utilizzando l'apprendimento auto-supervisionato. Invece di fare affidamento su dataset etichettati dall'uomo, questi modelli generano i propri segnali di addestramento dai dati grezzi, come prevedere il token successivo in una sequenza o ricostruire porzioni mascherate di un input.
Questo cambiamento riflette una realtà pratica: le enterprise possiedono vaste quantità di dati non etichettati, ma l'etichettatura su larga scala è costosa e lenta. L'apprendimento auto-supervisionato consente alle organizzazioni di estrarre valore dagli asset di dati esistenti mentre costruiscono rappresentazioni che possono poi essere adattate a task specifici.
2. Il fine-tuning supervisionato si è spostato in un ruolo di affinamento
L'apprendimento supervisionato non è scomparso, ma il suo ruolo è cambiato. Invece di servire come meccanismo di addestramento primario, il fine-tuning supervisionato viene sempre più utilizzato per affinare, allineare e validare modelli per obiettivi aziendali ben definiti.
Questo approccio consente ai team di concentrare gli sforzi di etichettatura dove la precisione è più importante, come requisiti normativi, vincoli di sicurezza o accuratezza specifica del dominio, evitando al contempo etichettature non necessarie nelle fasi iniziali della pipeline.
3. Gli embeddings sono ora capacità enterprise fondamentali
Gli embeddings sono diventati infrastruttura enterprise fondamentale. I modelli foundation producono sempre più embeddings vettoriali che catturano il significato semantico attraverso testo, immagini, audio e dati strutturati. Questi embeddings alimentano la ricerca di similarità, il recupero, la personalizzazione, il rilevamento di anomalie e i sistemi di raccomandazione su larga scala.
Il clustering e altri metodi basati sulla similarità sono importanti, ma sono applicazioni downstream degli embeddings piuttosto che paradigmi alla pari. Il cambiamento strategico non è verso il clustering in sé, ma verso architetture basate su embeddings che consentono la ricerca, il recupero e il ragionamento unificati attraverso i dati enterprise.
Man mano che le organizzazioni operationalizzano l'AI, gli embeddings diventano il tessuto connettivo tra pre-addestramento auto-supervisionato, fine-tuning supervisionato e applicazioni downstream. Forniscono un livello rappresentativo comune che supporta sia l'esplorazione che i workflow di precisione all'interno di piattaforme dati moderne e unificate.
Costruisci sistemi, non compartimenti stagni
L'apprendimento supervisionato e non supervisionato risolvono problemi diversi — e i moderni sistemi di ML ne necessitano entrambi. L'apprendimento automatico supervisionato eccelle quando si dispone di dati etichettati e si necessita di previsioni o classificazioni precise e affidabili. L'apprendimento automatico non supervisionato prospera quando l'obiettivo è la scoperta, aiutando i team a scoprire pattern e insight nei dati grezzi senza output predefiniti. Quando i dati etichettati sono limitati, gli approcci di apprendimento semi supervisionato colmano il divario combinando entrambi i paradigmi.
La vera sfida non è scegliere tra apprendimento supervisionato vs non supervisionato, ma costruire sistemi che possano combinare approcci, evolvere nel tempo e operare in modo affidabile in produzione. I team efficaci iniziano valutando la disponibilità dei loro dati, chiarendo se il loro obiettivo primario è la previsione o l'esplorazione, e valutando le risorse necessarie per supportare ciascun approccio.
Le strategie di machine learning sono raramente statiche. L'esplorazione non supervisionata spesso informa lo sviluppo successivo di modelli supervisionati, mentre il fine-tuning supervisionato porta precisione e validazione ai sistemi costruiti su rappresentazioni più ampie. Nel tempo, gli insight devono confluire nel business intelligence e nell'analisi dove possono informare le decisioni e guidare i risultati.
Per approfondire, esplora queste risorse:
- Una guida compatta al fine-tuning e al pre-training degli LLM — Impara le tecniche per il fine-tuning e il pre-training del tuo LLM
Ottieni la guida - Il grande libro dell'IA generativa — Best practice per la creazione di applicazioni GenAI di qualità produttiva
Scarica - Il grande libro dei casi d'uso del machine learning — Ottieni tutto ciò che ti serve per mettere in pratica il machine learning
Leggi ora
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.