Cosa sono i dati alternativi?
Fonti di dati non tradizionali oltre ai dati finanziari standard (immagini satellitari, transazioni con carta di credito, social media e traffico web) per approfondimenti aziendali
- Include dati non convenzionali come segnali di geolocalizzazione, download di app, web scraping, dati di spedizione, andamenti meteorologici e sentiment dei dipendenti dai siti di recensioni di lavoro.
- Offre a hedge fund e investitori quantitativi vantaggi informativi rivelando le tendenze del mercato prima che i bilanci e le metriche tradizionali riflettano i cambiamenti.
- Richiede un'elaborazione specializzata per formati non strutturati, considerazioni etiche sulla privacy e una scienza dei dati avanzata per estrarre segnali significativi da set di dati rumorosi ad alta dimensionalità.
Che cosa sono i dati alternativi?
I dati alternativi sono informazioni raccolte utilizzando sorgenti di dati alternative non utilizzate da altri, ovvero fonti di informazione non tradizionali. L'analisi di dati alternativi può fornire informazioni che vanno al di là di quelle ottenute dalle normali sorgenti di dati di un settore industriale. Tuttavia, cosa si intenda esattamente per dati alternativi varia da un settore all'altro, in quanto dipende dalle sorgenti di dati tradizionali che la tua azienda e quelle concorrenti state già utilizzando.
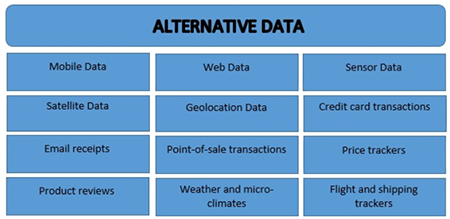
Tipi di dati alternativi più comuni
In genere, quando parliamo di dati alternativi, ci riferiamo principalmente alle seguenti tipologie di dati:
- Dati satellitari
- Dati mobili
- Dati di sensori
- Dati web
Tuttavia i dati alternativi possono includere anche:
- Geolocalizzazione (traffico pedonale)
- Transazioni con carta di credito
- Ricezione di e-mail
- Transazioni nei punti vendita
- Messaggi sui social media
- Attività di navigazione online
- Ricevute dei container di spedizione
- Recensioni di prodotti
- Strumenti di tracciamento prezzi
- Meteo e microclimi
- Tracciatori di voli e spedizioni
Negli ultimi anni, l'aumento dei dati provenienti da dispositivi mobili, satelliti, sensori e siti web ha generato grandi quantità di dati strutturati, semistrutturati e non strutturati, che vengono indicati con il termine generico di Big Data. L'utilizzo di dati alternativi permette di ottenere una comprensione unica del settore, un vantaggio competitivo e un aumento dei profitti. Si possono combinare set di dati provenienti da sorgenti diverse per acquisire una panoramica chiara della concorrenza. Esistono tre modi principali per accedere a dati alternativi:
- Acquisizione di dati grezzi
- Licenze di terze parti
- Web scraping (o web harvesting, o estrazione di dati dal web). Un web scraper è un'Application Programming Interface (API) che estrae i dati da un sito web ed è in grado di raccogliere, sull'argomento desiderato, le informazioni chiave necessarie per crescere nel proprio settore. Le forme più recenti di web scraping prevedono l'analisi di feed di dati dai server web. Ad esempio, JSON è comunemente usato come meccanismo di memorizzazione di trasporto tra il client e il server web.
Il playbook sull'AI agentiva per l'enterprise

Tecniche di scraping automatico
- Parsing HTML. Il parsing dell'HTML viene eseguito utilizzando script Java su pagine HTML lineari o annidate.
- Parsing DOM. Il Document Object Model, o DOM, definisce lo stile, la struttura e il contenuto dei file XML.
- Aggregazione verticale. Le piattaforme di aggregazione verticale sono create da organizzazioni che dispongono di un'enorme potenza di calcolo e che si rivolgono a settori verticali specifici.
- XPath. XML Path Language o XPath è un linguaggio query che può essere utilizzato sui documenti XML.
- Google Docs. I fogli di calcolo di Google possono essere utilizzati più o meno come se si stesse scrivendo uno scraper in un linguaggio di programmazione come Python o Ruby; di conseguenza, sono un modo valido e veloce per introdurre i fondamenti di alcuni tipi di scraper.
- Text Pattern Matching. Si tratta di un metodo basato sul matching di espressioni regolari che utilizza il comando "grep" di UNIX, abbinato a linguaggi di programmazione popolari come Perl o Python.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.