Che cos'è una piattaforma di funzionalità?
Infrastruttura per la gestione del ciclo di vita delle funzionalità, inclusi progettazione, archiviazione, individuazione, monitoraggio e governance con API per la creazione e l'erogazione
- I componenti includono strumenti di creazione di feature per la definizione di trasformazioni, sistemi di orchestrazione che pianificano pipeline di calcolo, livelli di archiviazione per feature offline e online, API di servizio per l'accesso in tempo reale e dashboard di monitoraggio per il monitoraggio della qualità.
- Supporta il calcolo batch di feature per l'addestramento dei modelli, lo streaming di aggiornamenti delle feature per sistemi in tempo reale, il calcolo on-demand delle feature durante l'inferenza e il backfilling delle feature per esperimenti storici.
- Le funzionalità avanzate includono la convalida delle feature per garantire la qualità, test automatizzati per pipeline di feature, infrastruttura di test A/B per esperimenti sulle feature e integrazione con piattaforme di apprendimento automatico per flussi di lavoro di sviluppo di modelli senza interruzioni.
Fino a due anni fa, solo le grandi aziende tecnologiche disponevano delle risorse e delle competenze necessarie per creare prodotti che dipendessero interamente da sistemi di machine learning. Esempi tipici includono Google per la gestione delle aste pubblicitarie, TikTok per la raccomandazione dei contenuti e Uber per l'adattamento dinamico dei prezzi. Per supportare con il machine learning le loro applicazioni più critiche, questi team hanno costruito infrastrutture personalizzate in grado di soddisfare le esigenze specifiche della messa in produzione di sistemi di machine learning.
Nel giro di pochi anni, è emerso un intero ecosistema di strumenti di MLOps volto a democratizzare il machine learning in produzione. Ma con centinaia di strumenti diversi disponibili, capire cosa faccia ciascuno di essi è ormai diventato un lavoro a tempo pieno. Le feature platform e i loro parenti stretti, i feature store, sono una parte diffusa di quell'ecosistema. In estrema sintesi, una feature platform abilita l'infrastruttura dati esistente (data warehouse, infrastrutture di streaming come Kafka, sistemi di elaborazione dei dati come Spark/Flink, ecc.) per applicazioni di ML operativo. Questo articolo spiega più nel dettaglio cosa sono le feature platform e quali problemi risolvono.
Costruire sistemi di machine learning operativo è complesso
Le feature platform abilitano il machine learning operativo, ovvero l'utilizzo, da parte di un'applicazione rivolta al cliente, di un modello di ML per prendere in modo autonomo e continuo decisioni che impattano sul business in tempo reale. Gli esempi che ho condiviso di Google, TikTok e Uber sono tutti casi di applicazioni di ML operativo. Qualsiasi progetto di machine learning si compone sempre di quattro fasi:
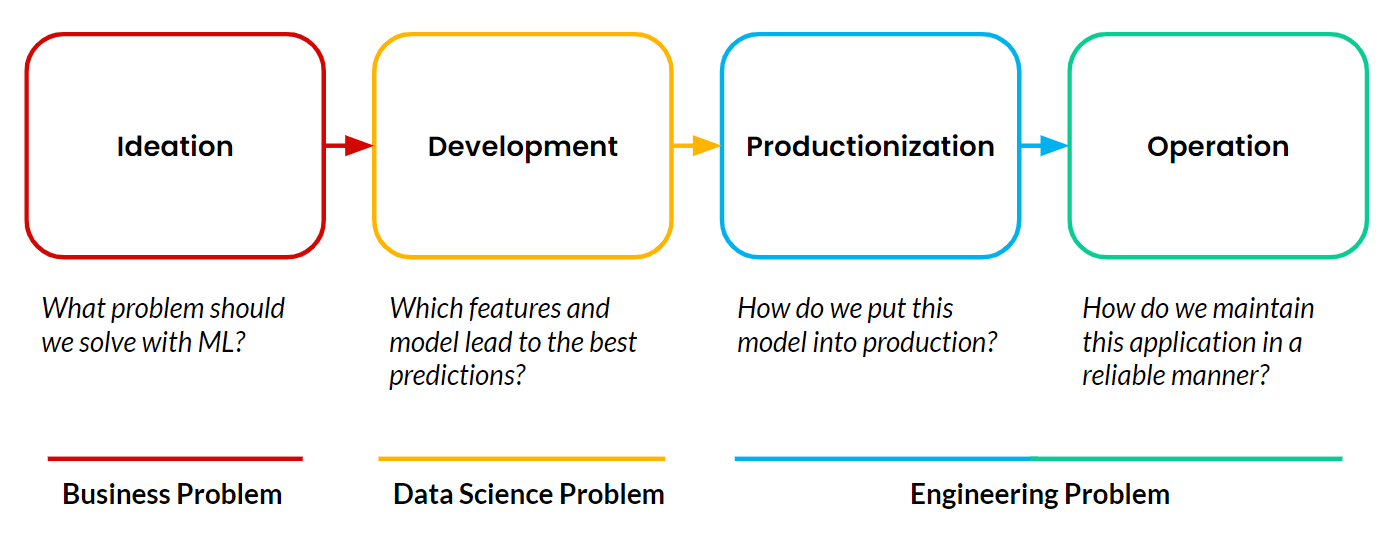
La maggior parte dei progetti non supera mai la fase di sviluppo. La messa in produzione e l'operatività delle applicazioni di machine learning rimangono il principale ostacolo per i team. E la parte più difficile, in questo contesto, è la gestione delle pipeline di dati che devono alimentare continuamente queste applicazioni.
Una feature platform risolve le sfide legate ai dati associate alla messa in produzione e all'operatività. Crea un percorso verso la produzione. Prima di approfondire questo aspetto, cominciamo descrivendo cos'è una feature.
Cosa si intende per feature nel machine learning?
Nel machine learning, una feature è un dato utilizzato come input dai modelli di ML per fare previsioni. I dati grezzi raramente sono in un formato utilizzabile da un modello di ML, quindi devono essere trasformati in feature. Questo processo è chiamato ingegneria delle feature (feature engineering).
Ad esempio, se una società di carte di credito sta cercando di rilevare transazioni fraudolente, il fatto che una transazione venga effettuata in un paese estero può essere un buon indicatore di frode. Questo segnale viene trasformato in una feature e rappresentato come una colonna nei dati forniti al modello.
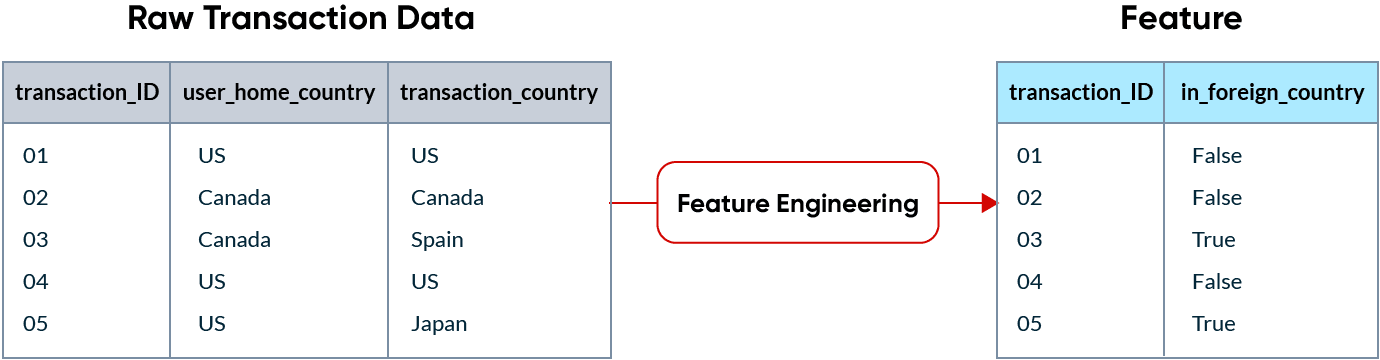
La particolarità del ML è che le feature vengono utilizzate in due modi diversi:
- Per addestrare un modello, abbiamo bisogno di grandi quantità di dati storici.
- Per effettuare una previsione in tempo reale, dobbiamo fornire al modello solo le feature più recenti, e farlo nel giro di pochi millisecondi. Questa modalità è detta anche inferenza online. In questo esempio, il modello ha bisogno solo di sapere se la transazione corrente avviene o meno in un paese estero e deve elaborare questa informazione mentre la transazione è in corso.
Quali problemi risolve una feature platform?
Nella fase di sviluppo di un progetto di machine learning, i data scientist svolgono un intenso lavoro di feature engineering per individuare le feature che portano alla massima accuratezza predittiva. Una volta completato questo processo, il progetto viene di norma passato a un collega dell'unità di ingegneria, che si occupa di portare in produzione le pipeline di feature engineering.
Se sei un data scientist, non vuoi preoccuparti di come i dati diventino disponibili o di come vengano calcolati. Sai quali feature ti servono e vuoi che siano disponibili affinché il modello possa effettuare previsioni in tempo reale. Gli ingegneri, invece, devono reimplementare queste pipeline di dati in un ambiente di produzione, un'attività che diventa rapidamente molto complessa non appena entrano in gioco dati in tempo reale o quasi in tempo reale. Per supportare applicazioni di ML operativo, queste pipeline devono essere eseguite in modo continuo, non possono interrompersi, devono essere estremamente veloci e devono poter scalare con il business.
La reimplementazione delle pipeline di dati in un ambiente di produzione rappresenta il principale ostacolo per i progetti di ML operativo. Tornando all'esempio del rilevamento delle frodi, alcune feature realistiche che le aziende implementano sono:
- La distanza tra la posizione di residenza di un utente e il luogo in cui avviene la transazione, calcolata mentre la transazione è in corso.
- Il fatto che l’importo della transazione corrente sia superiore di oltre una deviazione standard rispetto alla media storica per quella sede dell’esercente.
- Il numero di transazioni effettuate da un utente negli ultimi 30 minuti, aggiornato ogni secondo.
Queste pipeline di ingegneria delle feature sono difficili da implementare. Non possono essere calcolate direttamente su un data warehouse e richiedono la configurazione di un'infrastruttura di streaming per elaborare i dati in tempo reale. Una feature platform risolve le sfide ingegneristiche legate alla messa in produzione di queste feature e, così facendo, crea un percorso semplice verso la produzione. Nel concreto, una feature platform:
- Orchestra ed esegue in modo continuo pipeline di dati per il calcolo delle feature, rendendo queste ultime disponibili sia per l'addestramento offline che per l'inferenza online.
- Gestisce le feature come codice, consentendo ai team di effettuare code review, gestire il controllo di versione e integrare le modifiche alle feature nelle pipeline di CI/CD.
- Crea una libreria di feature, standardizzando le definizioni e consentendo ai data scientist di condividere e individuare feature tra team diversi.
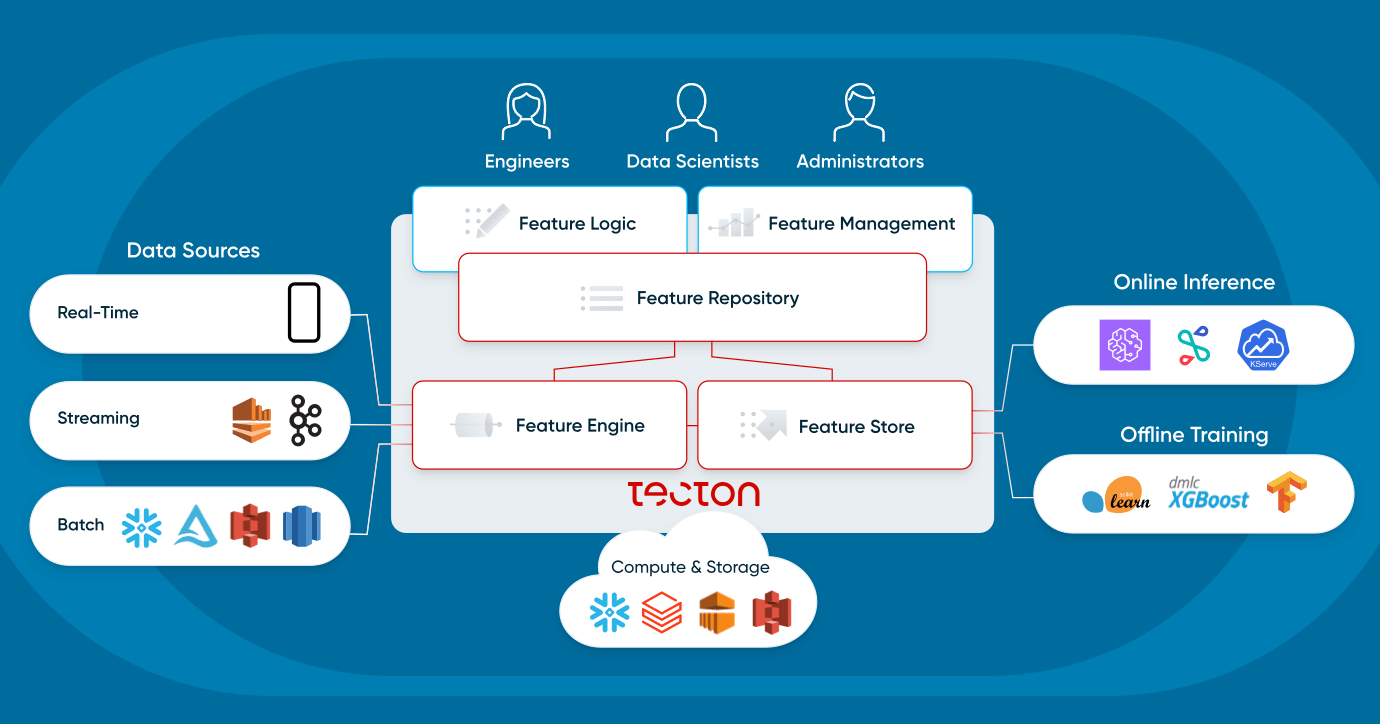
Vediamo ora più nel dettaglio come gli utenti interagiscono con una feature platform e quali sono i suoi componenti.
Il playbook sull'AI agentiva per l'enterprise

Che cos'è una feature platform?
Una feature platform è un sistema che orchestra l'infrastruttura dati esistente per trasformare, archiviare e servire dati in modo continuo a supporto di applicazioni di machine learning operativo.
Gli utenti interagiscono con una feature platform secondo due modalità principali:
- Creazione e individuazione delle feature
- Gli utenti definiscono nuove feature come codice in file Python utilizzando un framework dichiarativo. Le definizioni delle feature sono gestite in un repository Git.
- Gli utenti individuano feature esistenti definite da altri team.
- Recupero delle feature
- In fase di addestramento, gli utenti possono richiamare la feature platform all'interno di un notebook per ottenere tutti i dati storici necessari all'addestramento di un modello. Questo può avvenire tramite una chiamata come get_historical_features(fraud_model). La feature platform gestisce la complessità del backfill delle feature e dell'esecuzione corretta delle join point-in-time, e il data frame risultante può essere ingerito da qualsiasi strumento di addestramento dei modelli, come XGBoost, Scikit-learn, ecc.
- In fase di inferenza, la feature platform espone un endpoint REST che può essere chiamato da un'applicazione live. Questo restituisce in pochi millisecondi il vettore di feature più recente per un determinato entity ID, che il modello utilizzerà per effettuare una previsione.
Le feature platform non sostituiscono l'infrastruttura esistente. Al contrario, la abilitano per applicazioni di machine learning operativo:si connettono a (1) sorgenti batch come data lake e data warehouse e a (2) sorgenti di streaming come Kafka. Utilizzano (3) infrastrutture di calcolo esistenti, come un data warehouse o Spark, e (4) infrastrutture di storage esistenti, come S3, DynamoDB o Redis. Una feature platform moderna si connette in modo flessibile all'infrastruttura dati già presente in un'organizzazione.
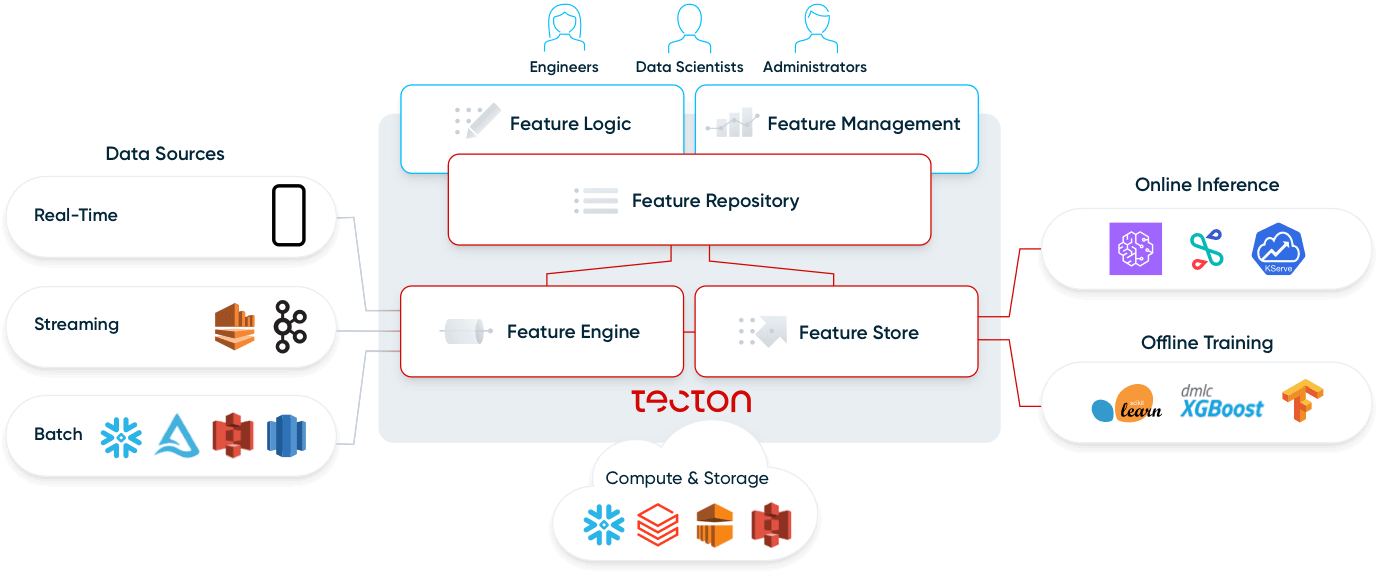
Guardiamo ora più da vicino i quattro componenti di una feature platform: feature repository, feature pipeline, feature store e monitoraggio.
Feature repository
Molti data scientist svolgono il feature engineering all'interno di notebook. Questi ultimi sono interattivi, facili da usare e consentono cicli di sviluppo rapidi. I problemi iniziano quando quelle feature devono essere portate in produzione: è impossibile integrarle nelle pipeline CI/CD e applicare i controlli tipici del software tradizionale.
I team che riescono a distribuire con successo applicazioni di ML operativo gestiscono le loro feature come asset di codice. Questo introduce tutti i benefici del DevOps: consente ai team di effettuare code review, tracciare la lineage e integrare le feature nelle pipeline di CI/CD, permettendo di rilasciare modifiche in modo più rapido e affidabile. Un segnale comune nei team che non gestiscono le feature come codice è l'incapacità di iterare oltre la prima versione di un modello.
In una feature platform, gli utenti definiscono le feature come codice utilizzando un'interfaccia dichiarativa che comprende tre elementi:
- Configurazione relativa alla frequenza con cui la feature deve essere calcolata.
- Metadati, come il nome e la descrizione della feature, per consentirne la condivisione e l'individuazione.
- Logica di trasformazione, definita in SQL o Python.
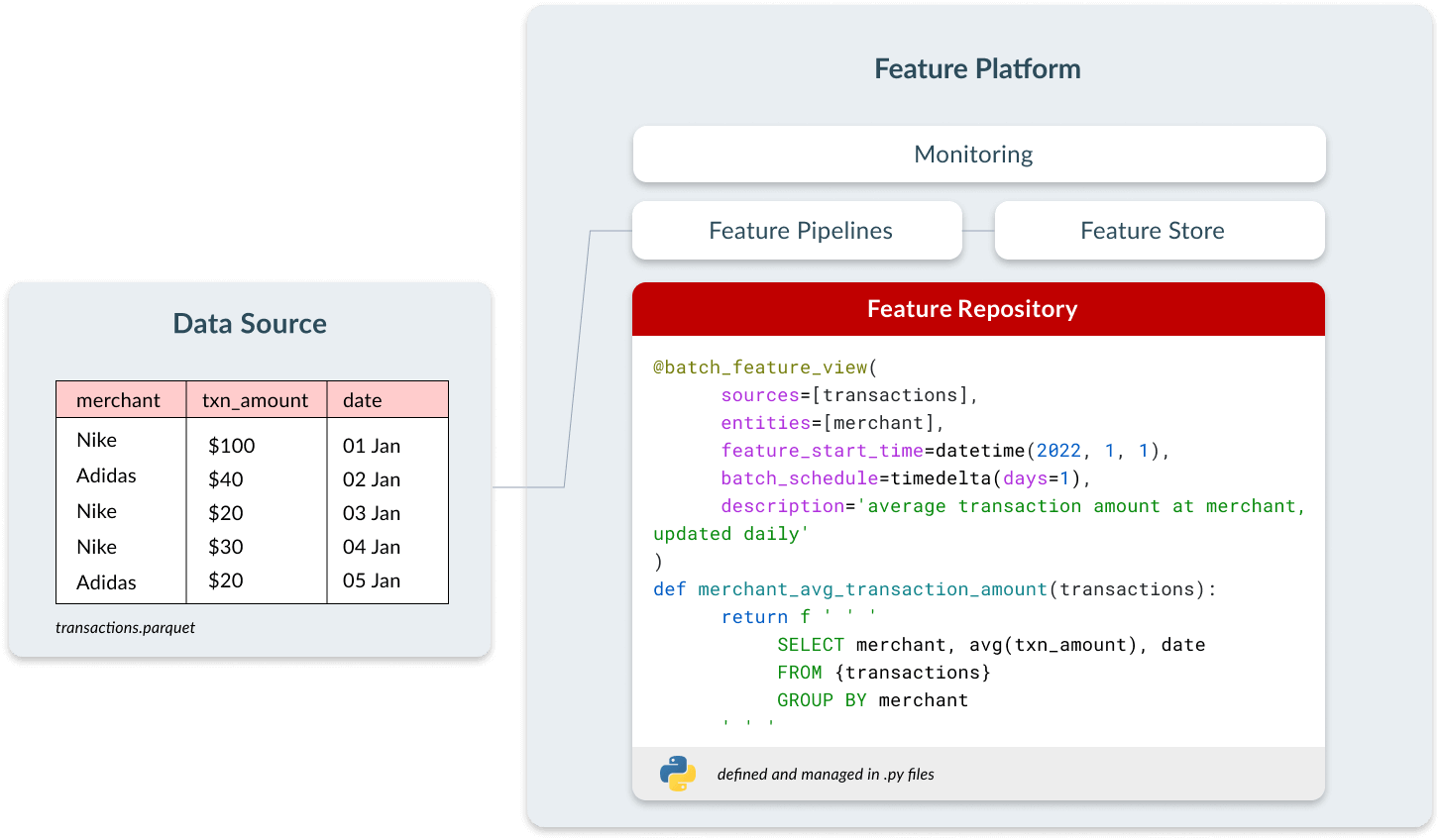
Queste feature diventano quindi disponibili in modo centralizzato, consentendo a tutti i team di individuarle e utilizzarle nei propri modelli. Questo riduce i tempi di sviluppo, crea coerenza tra i team e riduce i costi di calcolo, poiché le feature non devono essere calcolate più volte per casi d'uso diversi.
Feature pipeline
Le applicazioni di machine learning operativo richiedono l'elaborazione continua di nuovi dati, in modo che i modelli possano effettuare previsioni basate su una visione aggiornata della realtà. Una volta che un utente ha definito una feature nel repository, la feature platform elabora automaticamente le pipeline di dati necessarie a calcolarla.
Una feature platform deve supportare tre tipi di trasformazioni dei dati:
| Trasformazione | Definizione | Origine dati | Esempio |
|---|---|---|---|
| Batch | Trasformazioni applicate esclusivamente a dati a riposo | Data warehouse, data lake, database | Importo medio della transazione per esercente, aggiornato quotidianamente |
| Streaming | Trasformazioni applicate a sorgenti di streaming | Kafka, Kinesis, PubSub, Flink | Numero di transazioni dell'utente negli ultimi 30 minuti, aggiornato ogni secondo |
| On-demand | Trasformazioni utilizzate per produrre feature basate su dati disponibili solo al momento della previsione. Queste feature non possono essere pre-calcolate. | Applicazione rivolta all'utente, API verso servizi RPC, dati in memoria | L'importo della transazione corrente è superiore di oltre due deviazioni standard rispetto all'importo medio delle transazioni dell'utente, calcolato al momento della transazione. |
Queste trasformazioni vengono eseguite sui motori di elaborazione dati (Spark, Snowflake, Python) a cui è collegata la feature platform. La feature platform passa il codice di trasformazione definito dall'utente in modo 1:1 al motore di elaborazione dei dati sottostante. Ciò significa che la feature platform non dovrebbe disporre di un proprio dialetto SQL personalizzato né di una DSL Python proprietaria. Questo semplifica sia l'esperienza di onboarding alla feature platform, sia l'esperienza di debug.
Le trasformazioni batch sono semplici da realizzare: possono essere effettuate tramite una query SQL su un data warehouse o mediante l'esecuzione di un job Spark. Le applicazioni di ML operativo, tuttavia, traggono il massimo beneficio da informazioni aggiornate, a cui è possibile accedere solo tramite trasformazioni di streaming e on-demand. Nell'esempio del rilevamento delle frodi, le feature che consentono al modello di effettuare le previsioni migliori includono informazioni sulla transazione corrente, come importo, esercente e località, o informazioni su transazioni avvenute negli ultimi minuti.
Tutti i team con cui parliamo concordano sul fatto che avere accesso a dati aggiornati migliorerebbe le prestazioni di gran parte dei loro modelli. La maggior parte delle organizzazioni utilizza ancora esclusivamente trasformazioni batch, poiché la gestione di trasformazioni di streaming e on-demand è complessa. Una feature platform elimina questa complessità, consentendo all'utente di definire la logica di trasformazione e di selezionare se debba essere eseguita come trasformazione batch, di streaming o on-demand.
Quando si iterano nuove feature nella fase di sviluppo, è necessario effettuare il backfill dei dati per generare i set di dati di addestramento. Ad esempio, potremmo sviluppare oggi una nuova feature merchant_fraud_rate, che dovrà essere sottoposta a backfill per l'intera finestra temporale su cui intendiamo addestrare il modello. Le feature platform eseguono automaticamente queste trasformazioni al momento della definizione di nuove feature, consentendo cicli di iterazione rapidi nel processo di sviluppo.

Feature Store
I feature store sono diventati sempre più popolari da quando abbiamo introdotto per la prima volta il concetto con Uber Michelangelo nel 2017. Svolgono due funzioni principali: archiviare e servire le feature in modo coerente tra gli ambienti di addestramento offline e quelli di inferenza online.
Quando le feature non vengono archiviate in modo coerente in entrambi gli ambienti, le feature su cui il modello viene addestrato possono presentare sottili differenze rispetto a quelle utilizzate per l'inferenza online. Questo fenomeno è noto come train-serve skew e può compromettere le prestazioni di un modello in modo silenzioso e catastrofico, con effetti estremamente difficili da individuare e risolvere. Garantendo la coerenza dei dati in entrambi gli ambienti, un feature store risolve questo problema.
Per l'addestramento offline, i feature store devono contenere mesi o anni di dati. Questi dati sono archiviati in data warehouse o data lake come S3, BigQuery, Snowflake o Redshift, sorgenti ottimizzate per il recupero su larga scala.
Per l'inferenza online, le applicazioni devono poter accedere in modo estremamente rapido a piccole quantità di dati. Per consentire interrogazioni a bassa latenza, questi dati vengono conservati in uno store online come DynamoDB, Redis o Cassandra. Nello store online vengono mantenuti solo i valori più recenti delle feature per ciascuna entità.

Per il recupero dei dati offline, i valori delle feature sono comunemente accessibili tramite un SDK compatibile con i notebook. Per l'inferenza online, un feature store fornisce un singolo vettore di feature contenente i dati più aggiornati. Sebbene la quantità di dati in ciascuna di queste richieste sia ridotta, un feature store deve essere in grado di scalare fino a migliaia di richieste al secondo. Queste risposte vengono fornite alle applicazioni live in pochi millisecondi tramite un endpoint REST. I feature store ad alte prestazioni devono fornire SLA su disponibilità e latenza.

Monitoraggio
Quando qualcosa va storto in un sistema di ML operativo, di solito si tratta di un problema legato ai dati. Poiché le feature platform gestiscono il processo end-to-end, dai dati grezzi fino ai modelli, si trovano in una posizione privilegiata per rilevare problemi sui dati. Le feature platform supportano due tipologie di monitoraggio:
Monitoraggio della qualità dei dati
Le feature platform possono monitorare la distribuzione e la qualità dei dati in ingresso. Si sono verificati cambiamenti significativi nella distribuzione dei dati dall'ultimo addestramento del modello? Stiamo improvvisamente riscontrando un aumento dei valori mancanti? Questo sta influenzando le prestazioni del modello?
Monitoraggio operativo
Durante l’esecuzione di sistemi in produzione, è inoltre fondamentale monitorare le metriche operative. Le feature platform tengono traccia dell'obsolescenza (staleness) delle feature per rilevare quando i dati non vengono aggiornati alla frequenza prevista, insieme ad altre metriche relative allo storage delle feature (disponibilità, capacità, utilizzo) e a metriche relative al serving delle feature (throughput, latenza, query al secondo, tassi di errore). Una feature platform monitora inoltre che le pipeline di feature eseguano i job come previsto, rileva quando i job non vengono completati correttamente e risolve automaticamente i problemi.
Le feature platform rendono queste metriche disponibili per l'integrazione con l'infrastruttura di monitoraggio esistente. Le applicazioni di ML operativo devono essere monitorate come qualsiasi altra applicazione in produzione, con gli strumenti di osservabilità già in uso.
Il quadro d'insieme
Parte della "magia" di una feature platform è che permette ai team ML di portare rapidamente in produzione nuove feature. Il vero incremento di valore, tuttavia, si manifesta quando la feature platform viene adottata da più team e utilizzata per supportare molteplici casi d'uso.

Una feature platform consente ai data engineer di supportare un numero maggiore di data scientist rispetto a quanto sarebbe altrimenti possibile. Abbiamo parlato con molti team che, in assenza di una feature platform, avevano bisogno di due data engineer per supportare un singolo data scientist. L'adozione di una feature platform ha permesso loro di invertire ampiamente questo rapporto. Una volta adottata su larga scala, una feature platform consente ai data scientist di aggiungere facilmente ai propri modelli feature già in fase di calcolo. Abbiamo osservato lo stesso schema ripetersi nel tempo: i team impiegano alcuni mesi per distribuire completamente il primo caso d'uso, alcune settimane per il secondo e solo pochi giorni per distribuire nuovi casi d'uso o iterare su quelli esistenti.
Quando adottare una feature platform (e quando no)
Ho iniziato questo articolo descrivendo quanto sia difficile tenersi al passo con l'intero ecosistema di strumenti di MLOps emerso negli ultimi anni. La realtà è che è preferibile mantenere lo stack il più semplice possibile e adottare nuovi strumenti solo quando sono davvero necessari.
Abbiamo riscontrato che i team traggono valore da una feature platform quando:
- Hanno sperimentato il processo di passaggio di consegne tra data scientist e data engineer e le difficoltà legate alla reimplementazione delle pipeline di dati per la produzione.
- Stanno distribuendo applicazioni di machine learning operativo, che devono rispettare SLA rigorosi, scalare in modo efficace e garantire continuità operativa in produzione.
- Hanno più team che desiderano disporre di definizioni di feature standardizzate e riutilizzare le feature tra modelli diversi.
I team dovrebbero invece evitare di adottare una feature platform quando:
- Si trovano nelle fasi di ideazione o di sviluppo e non sono ancora pronti per il rilascio in produzione.
- Hanno un solo team che lavora esclusivamente con dati batch.
Come cominciare
Ecco alcune opzioni per iniziare:
- Tecton è una feature platform gestita. Include tutti i componenti descritti in precedenza ed è scelto dai nostri clienti che necessitano di SLA di produzione e funzionalità di livello enterprise e non vogliono gestire direttamente una soluzione. Tecton è utilizzata da team ML che vanno dalle startup tecnologiche a numerose aziende Fortune 500.
- Feast è il feature store open source più diffuso. È un’ottima opzione se si dispone già di pipeline di trasformazione per calcolare le feature e si desidera archiviare e servire tali feature in produzione. Nel tempo, Feast continuerà ad aggiungere funzionalità di feature pipeline e di monitoring che lo renderanno una feature platform completa.
Ho scritto questo articolo per proporre una definizione condivisa delle feature platform, sistemi che oggi sono parte integrante dello stack per applicazioni di machine learning operativo.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.