Governance unificata per dati, applicazioni e agenti AI
Garantisci che dati, modelli, agenti e applicazioni siano individuabili, governati e sicuri
IL SUCCESSO DEI MIGLIORI TEAM POGGIA SU UNA GOVERNANCE UNIFICATA E APERTA

Da dati attendibili ad un'AI affidabile, in un unico catalogo
Basa la tua AI su dati affidabili e un contesto di business condiviso, governa ciò che i tuoi modelli e agenti possono fare ed eseguili ovunque.Asset dati e AI unificati
Riunisci tutti i tuoi asset AI, inclusi agenti, applicazioni AI, MCP e modelli, sotto lo stesso sistema di individuazione, governance e protezione dei dati, su tutti i cloud e le piattaforme.
Individuazione arricchita dal contesto
Sfrutta una semantica di business condivisa per aiutare utenti e agenti a individuare dati affidabili e asset AI corredati del contesto necessario per utilizzarli con sicurezza.
Controlli di governance basati sull'AI
L'intelligenza integrata applica automaticamente le policy di accesso, protegge i dati sensibili, monitora la qualità e ottimizza le prestazioni della tua intera piattaforma.
Riunisci tutti i tuoi dati e asset AI in un unico catalogo
Utilizza un unico catalogo per gestire tutti i tuoi dati e gli asset AI, inclusi modelli, agenti e MCP, su qualsiasi cloud o piattaforma.Controlla a quali risorse agenti, modelli e MCP possono accedere e quali operazioni possono eseguire, applicando gli stessi criteri di governance, controllo della spesa e visibilità utilizzati per i dati tramite Unity AI Gateway.

Lavora con qualsiasi formato aperto (Delta, Iceberg, Parquet) e accedi ai dati su piattaforme diverse senza spostarli, tramite API aperte e federazione.

Individua, governa e accedi ai dati su più cloud e aree geografiche, con un'unica vista attendibile, disaster recovery integrato e opzioni di compute globali.
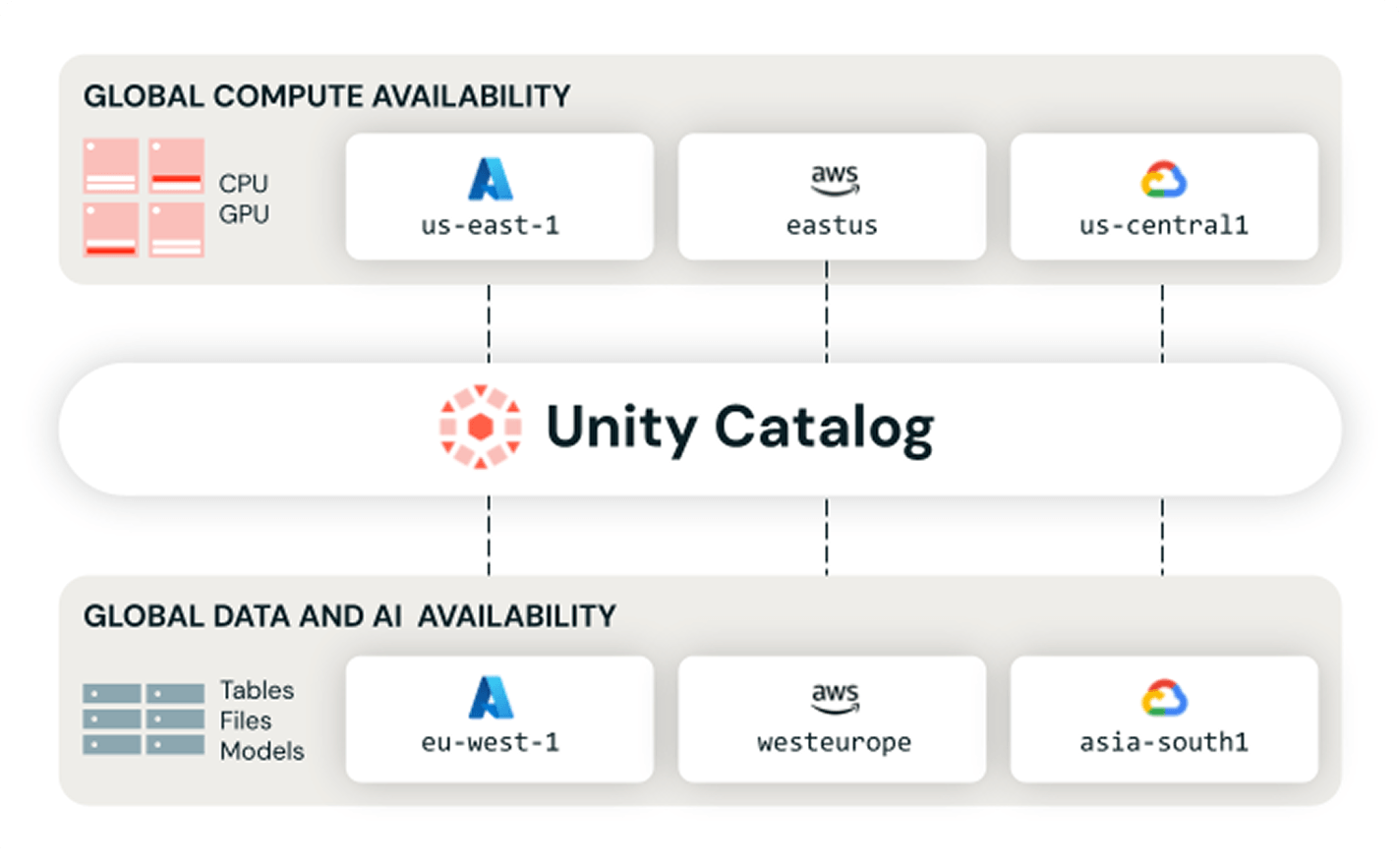
Individuazione affidabile per utenti e agenti
Aiuta persone e agenti a trovare, comprendere e utilizzare con fiducia i dati e gli asset AI corretti grazie a contesto, semantica e indicatori condivisi in tutto il tuo patrimonio informativo.Unity Catalog offre una selezione intelligente basata sull'AI dei dati e degli asset AI più affidabili, incluse tabelle, dashboard e modelli, con un contesto di business condiviso in un'unica esperienza unificata.
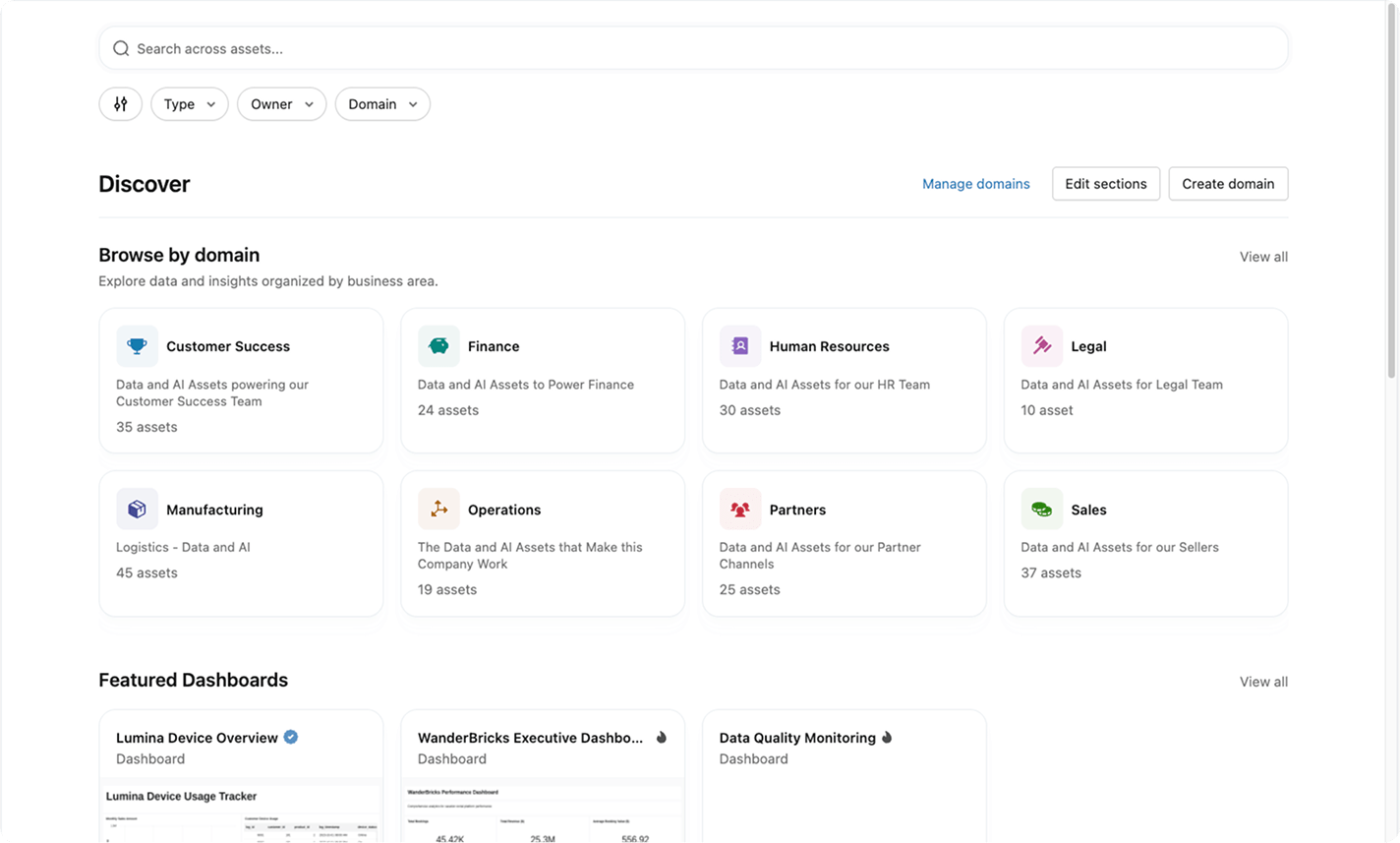
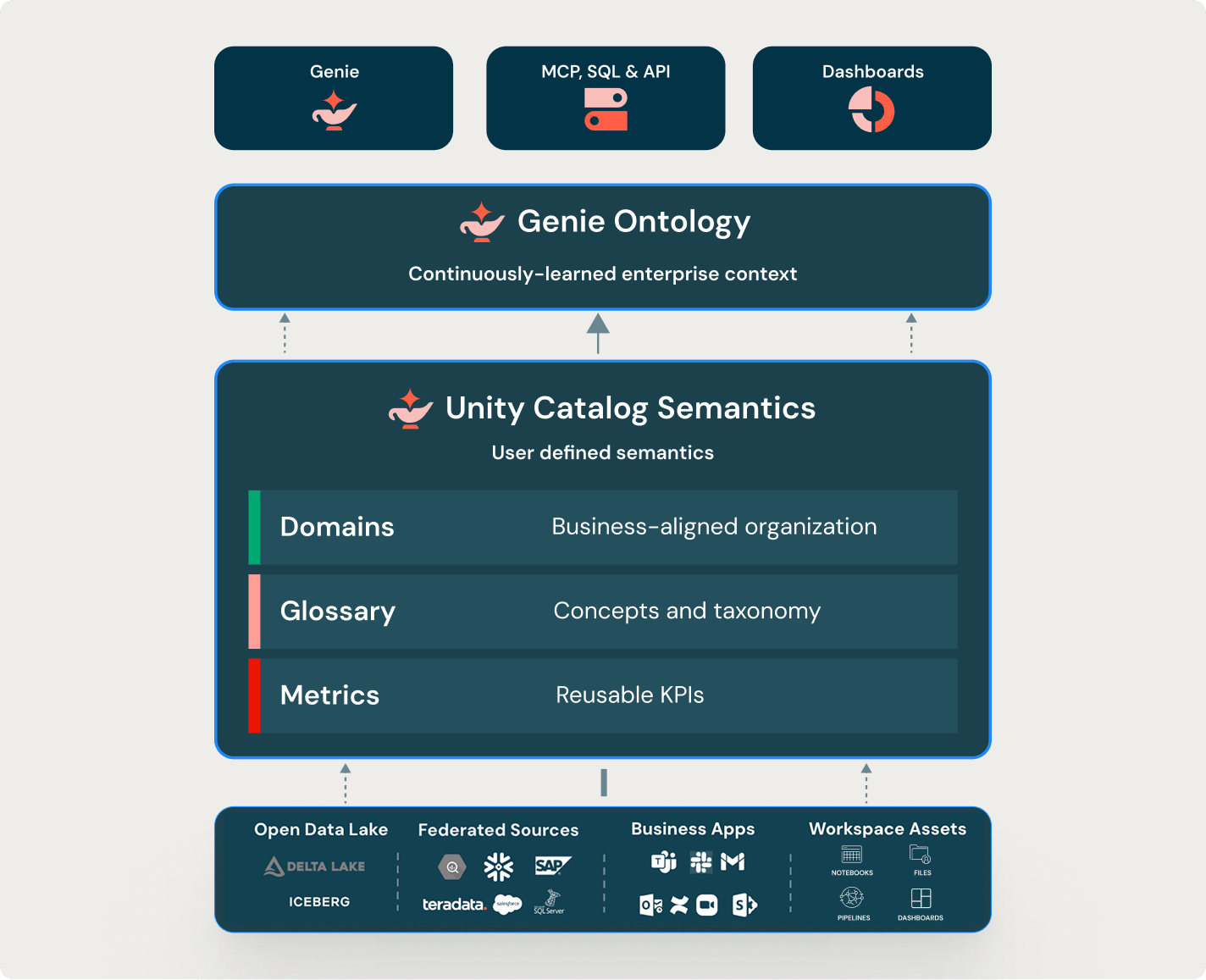
Unity Catalog crea una base semantica unificata e governata in modo che utenti business, team tecnici e agenti AI operino partendo dallo stesso significato e producano insight affidabili.
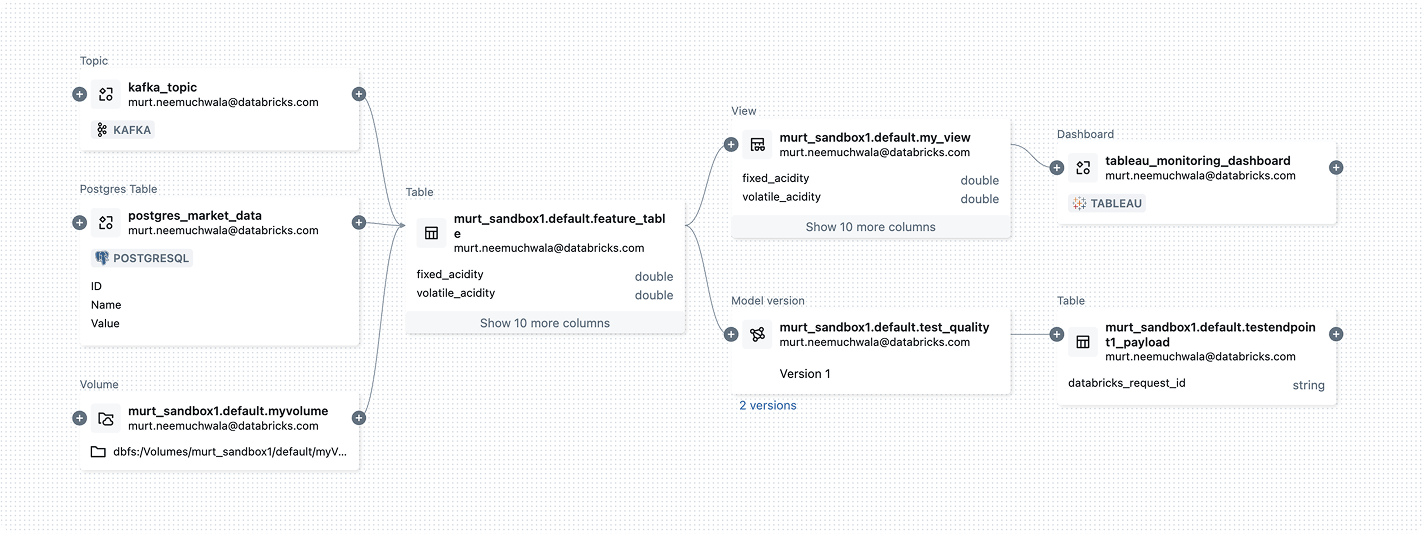
Derivazione automatizzata a livello di colonna, end-to-end, per asset di dati e AI: semplifica analisi d’impatto, troubleshooting, governance e audit AI.
Governance automatizzata integrata
Estendi automaticamente una governance coerente a tutti gli asset dati e AI, con prestazioni ottimizzate e senza controlli manuali.Applica un unico modello di policy al tuo intero patrimonio dati. Unity Catalog utilizza attributi, tag e classificazione automatica per applicare controlli di accesso granulari su larga scala senza intervento manuale.

Monitoraggio della qualità automatizzato e basato sull'AI per tutti i dati e gli asset AI, con indicatori di affidabilità in tempo reale ovunque lavorino i team e gli agenti AI.
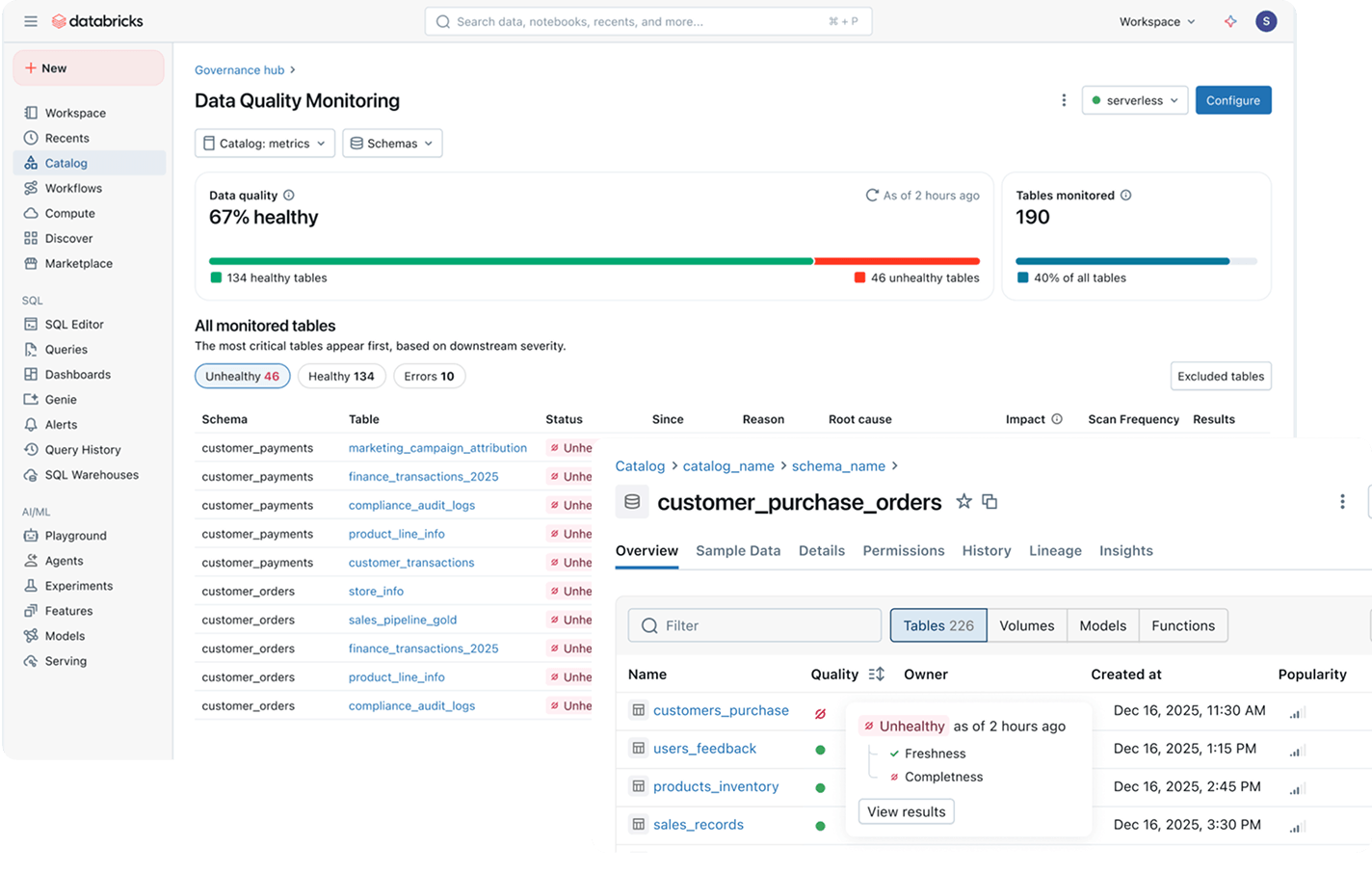
Monitora governance aziendale, costi e utilizzo dell'AI da un'unica vista, con insight integrati su lacune, modifiche rischiose agli accessi e derive delle policy.

Le Managed Tables di Unity Catalog offrono un'ottimizzazione basata sull'AI per query più veloci e costi inferiori, grazie a un layout auto-ottimizzante che si adatta ai tuoi modelli di utilizzo
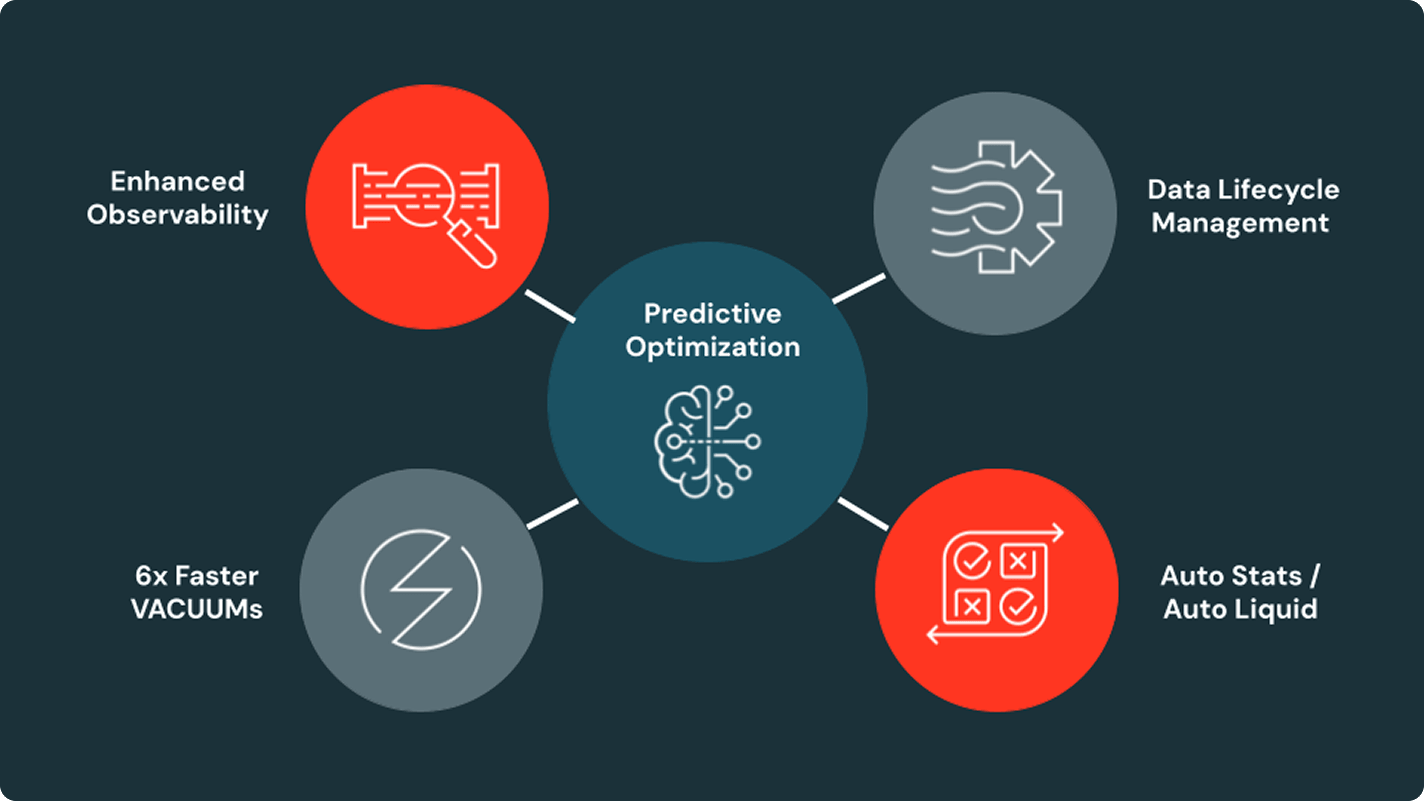
Sblocca il pieno valore aziendale dei dati con una governance unificata

Abilita data mesh e prodotti dati di dominio con una governance unificata
Permetti ai team di creare e pubblicare prodotti dati di alta qualità, mantenendo al contempo visibilità, sicurezza e affidabilità centralizzate in tutta l'organizzazione.
- Applica policy di governance coerenti ai prodotti dati di dominio e alle piattaforme
- Rendi i prodotti dati di dominio facilmente individuabili grazie a metadati e lineage centralizzati
- Classifica ed etichetta automaticamente i dati sensibili per consentire un controllo degli accessi scalabile
- Mantieni un unico piano di controllo per la governance federata e l'audit







Scopri di più
Scopri i prodotti che estendono la potenza di Unity Catalog in ambito di governance, collaborazione e data intelligence.
Genie One
Un'esperienza conversazionale, alimentata dall'AI generativa, che consente ai team aziendali di esplorare i dati e ottenere informazioni in tempo reale usando il linguaggio naturale.

Archiviazione nel lakehouse
Elimina le complessità della gestione dei dati grazie a formati di tabella aperti, governance centralizzata e ottimizzazioni automatiche dei dati.

OpenSharing
Un approccio open-source alla condivisione di dati e AI tra diverse piattaforme. Condividi dati in tempo reale con una governance centralizzata e senza repliche.

Databricks Clean Rooms
Analizza dati condivisi da più parti senza fornire un accesso diretto ai dati grezzi .

Databricks Marketplace
Un mercato aperto per risorse di dati, AI e analisi, come modelli di ML e notebook.
Fai il passo successivo
Esplora la documentazione di Unity Catalog
Consulta la documentazione di Unity Catalog per AWS, Azure e GCP per una guida dettagliata su funzionalità, configurazione e best practice.
Esplora le demo dei prodotti
Guarda le demo di Unity Catalog per scoprire come gestire, scoprire e condividere risorse di dati e AI in tutto il tuo ambiente dati.




FAQ su Unity Catalog
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il tuo percorso di trasformazione dei dati