データブリックスを活用した大規模な地理空間情報・ジオデータの処理と分析
によって Nima Razavi 、 Michael Johns による投稿
近年のテクノロジーの進化と統合により、リアルタイムで正確な地理空間情報・ジオデータを活用した市場が活性化しています。地理空間情報・ジオデータは日々、数十億ものハンドヘルドデバイスや IoT 機器、航空機や人工衛星に搭載された何千ものリモートセンシングプラットフォームから、数百エクサバイト生成されています。このような地理空間ビッグデータの拡大に、近年の機械学習の進展が加わり、業界ではこれを活用した新製品やサービスの�開発が進められています。
企業における地理空間情報・ジオデータの活用代表例として、ドローンを利用したマッピングや現地調査などのサービス提供があります。(参考:「インテリジェントクラウドとインテリジェントエッジの発展」)。地理空間データの活用で急速な成長を遂げているもう1つの産業は、自動運転車です。スタートアップ企業に加え、既存企業も車載センサーから豊富なコンテキスト情報を含んだ大量の地理空間データや空間インデックスを収集し、次世代の自動運転技術の開発に乗り出しています(参考:「データブリックス、Wejoのモビリティデータエコシステム構築を支援」)。小売業者や行政機関でも、地理空間情報・ジオデータの活用が模索されています。歩行者の交通量を分析することで、新規店舗の立地調査や行政による都市計画の改善に生かすことができます(参考:「歩行者交通情報データセットの構築」 )。このように多くの業界で活用を期待されている地理空間情報・ジオデータですが、いくつかの課題も抱えています。
大規模な地理空間情報の分析における課題
第一の課題は、ストリーミングおよびバッチアプリケーションのスケーリングです。地理空間データの急増と、空間インデックスなどのアプリケーションが必要とする SLA に対して、従来のストレージや処理システムの能力では太刀打ちできない状況になっています。顧客データは、データ量、速度、ストレージコスト、スキーマオンライト(Schema on Write)の厳格な適用などの要件により、ここ数年、垂直方向にスケールした既存のジオデータベースから、データレイクへと流出しています。地理空間情報・ジオデータに投資する企業はあるものの、大規模で複雑なこれらのデータセットをダウンストリームの分析用に準備するための適切な技術アーキテクチャを持っているケースはほとんどありません。さらに、高度なユースケースでは大規模なデータを必要とする場合が多く、AI主導のプロジェクトの大半は、パイロット版から本運用への移行に失敗しています。
第二の課題は、地理空間データにおけるデータ形式の互換性です。この数十年の間に、下記のように多数の地理空間データ形式や位置情報を収集できる二次的データソースがそれぞれに特化し��た状態で開発されており、複雑さを増しています。
- GeoJSON、KML、Shapefile、WKT などのベクトル(ベクター)データ形式
- ESRI Grid、GeoTIFF、JPEG 2000、NITF などのラスターデータ形式
- AIS や GPS デバイスで使用される航法システム基準
- JDBC / ODBC 接続を介して、PostgreSQL/ PostGIS として利用できる地理情報データベース
- Hyperspectral、Multispectral、Lidar、Radar プラットフォームでのリモートセンサー形式
- WCS、WFS、WMS、WMTS などの OGC Web 標準
- 位置情報タグが付いたログ、写真、動画、ソーシャルメディア
- 何らかの位置を示す非構造化データ
このブログ投稿では、データブリックスの統合データ分析プラットフォームを使用して、この大きな2つの課題を解決する一般的なアプローチの概要を解説します。この投稿は、大規模な地理空間情報・データの分析や処理に関するブログシリーズ第一弾です。
地理空間ワークロードのスケーリング
データブリックスは、世界中の数千もの顧客に、ビッグデータ分析と機械学習用の統合データ分析プラットフォーム(UDAP)を提供しています。UDAP は、Apache Spark™、Delta Lake、MLflow から構成されており、広範なサードパーティエコシステムやライブラリと統合されています。データブリックスの統合データ分析プラットフォームは、実運用ワークロードに、エンタープライズクラスのセキュリティ、サポート、信頼性、性能を大規模に提供するソリューションです。地理空間情報・ジオデータベースのワークロードは複雑で、全てのユースケースを単体のライブラリではカバーできないため、Apache Spark でも地理空間のデータ型は直接には提供されていません。ただし、オープンソースコミュニティや各企業において、空間データを扱うライブラリの開発が進められており、多くのオプションが利用できます。
空間結合や最近傍探索などの地理空間データ操作についてスケーリングを行う場合、次の 3 つの方法が一般的です。
- Apache Spark の地理空間情報・ジオデータの分析を拡張する専用ライブラリを使用する:データブリックスのユーザーが使用するライブラリとしては、GeoSpark、GeoMesa、GeoTrellis、Rasterframes などが挙げられます。通常、これらのフレームワークでは複数言語のバインディングが提供されており、形式化されていない場合に比べてスケーリングやパフォーマンスも向上しています。ただし、習熟するまでに多少の時間がかかります。
- GeoPandas、Geospatial Data Abstraction Library (GDAL)、 Java Topology Service (JTS) などのシングルノードライブラリを、ユーザー定義関数(UDF)を使って都度ラッピングし、Spark DataFrame を使用して分散環境で処理する:このアプローチではコードの追加や修正がほとんどなく、既存のワークロードをスケーリングする場合、最も簡単です。ただし、事実上のリフトアンドシフトになるため、パフォーマンスの低下も見込まなければなりません。
- グリッドシステムを使用してデータをインデックス化し、生成されたインデックスを活用して地理空間情報・ジオデータベースを操作する:これは非常に大規模なワークロードやコンピューティングリソースに制約があるワークロードを扱う際に一般的なアプローチです。グリッドシステムの例には、S2、GeoHex、Uber のH3 などが挙げられます。グリッドシステムでは、地理上の特徴を、同一のポリゴン(多角形)やポイント(点)の組み合わせによるマス目(グリッド)に沿った近似値で表現します。そうすることで、地理空間データをそのまま処理することによる負荷の増大を避け、より効率的なスケーリングを図ります。具体的な実装としては、グリッドの精度を 1 つに固定することで、若干の精度低下を許容してパフォーマンスを優先する方法と、複数のグリッド精度を導入してパフォーマンスの低下を許容する代わりに精度を維持する方法があります。
下のサンプルデータは、ニューヨーク市のタクシーの乗り降りについてまとめられたデータセット(こちらで確認可能)です。また、ニューヨーク市のタクシー区域のデータを、ポリゴンで構成されるジオメトリとして使用しています。ニューヨーク市の 5 つの行政区とその近隣区域が対象です。元のCSVファイルを Delta Lake テーブルに変換するための準備とクリーニングの手順については、こちらの Notebook を参照してください。Delta Lake テーブルに変換することで、より正確で効率よく扱えるデータソースとなります。
ベースとなる DataFrameは、Delta Lake テーブルからデータブリックスを使用して読み込んだタクシーの乗降データです。
Apache Spark の地理空間ライブラリを使用した地理空間データベース操作
ここ数年で、Apache Spark の地理空間情報の分析機能を拡張する複数のライブラリが開発されています。ユーザー定義型(UDT)やユーザー定義関数(UDF)を個別に登録して地理空間データに適用できるようにするには、その都度、空間データを処理するためのロジックを用意する必要があります。これらのフレームワークを使用すれば、個別の対処をある程度省略することができ、負担を軽減できます。なお、このブログ投稿では複数の空間データフレームワークを使用していますが、それらはさまざまな機能について解説することを主眼として選択されたものです。実際にデータブリックスを使用して空間ワークロードを処理する際には、ここで紹介した以外のフレームワークが適している場合もあります。
では、次に、ベースデータとして読み込んだ DataFrame を、緯度と経度の属性に基づいてポイントジオメトリに変換します。この処理を分散環境で実行するために UDF を使用します。詳細については、このブログの末尾にある Notebook を参照して、フレームワークのクラスタへの追加方法と、UDF および UDT を登録するための初期化呼び出しの方法をご覧ください。まず、ベクトル(ベクター)データの処理に特化したフレームワークである GeoMesa をクラスタに追加しました。データの取り込みについては、主に JTS と Spark SQL を組み合わせて�行います。そうすることで、登録済みの JTS ジオメトリクラスに容易に変換して使用することができます。ポイントジオメトリオブジェクトを作成するには、st_makePoint 関数に緯度と経度を渡して実行します。この関数は UDF であるため、データ列に直接適用できます。
分散環境下で空間結合を行うこともできます。サンプルでは、GeoMesa の提供する st_contains UDF を使用して、乗車地点に対する全てのポリゴンの結合結果を生成しています。
シングルノードライブラリを UDF でラップする
DataFrame の地理空間データ操作を分散環境で行うには、上記の空間フレームワークを使った方法に加え、既存のシングルノードライブラリをその都度 UDF でラッピングする方法もあります。この方法は、Scala、Java、Python、R、SQL など、Spark の全ての言語バインディングで利用できます。既存のワークロードを最小限のコード変更で使用できる最も簡単なアプローチです。このシングルノードでの方法を実行するには、まずニューヨーク市の行政区のデータを読み込み、ポイントインポリゴン操作を行う find_borough(…) UDFを定義します。次に geopandas を使用して GPS 位置情報を行政区に割り当てます。なお、この処理はベクトル化されたUDF でも実行可能です。パフォーマンスがより向上します。
これで、UDF を適用して Spark DataFrame にデータ列を追加できるようになりました。各乗車ポイントに行政区名が割り当てられます。
グリッドシステムによる空間インデックス生成
地理空間情報・ジオデータベースの操作は、その性質上、多くのコンピューティングリソースを必要とします。ポイントインポリゴン、空間結合、最近傍探索、ルートのスナッピングなど、いずれも複雑な操作です。グリッドシステムによる空間インデックス化は、このような地理空間操作をできるだけ避けることを目的としています。このようなアプローチを採用することで、実装時の効率的なスケーリングを実現しつつ、近似値を求める操作に際して警告を発することも可能になります。では、H3 の簡単なサンプルを見てみましょう。
H3 での空間操作のスケーリングは、基本的に 2 つの手順に分けられます。最初の手順で、ポイントやポリゴンで構成される地理的特徴について、H3 インデックスを計算します。地理的特徴は geoToH3(…) UDF で定義しています。2 つ目の手順で、H3 インデックスを使って地理空間操作(ポイントインポリゴン、空間結合、k近傍探索など)を行います。今回のサンプルでは、multiPolygonToH3(…) UDF で定義しています。
ここで、上記の 2 つの UDF をニューヨーク市のタクシーのデータに適用します。また、行政区を示すポリゴンにも適用し、H3インデックスを生成します。
緯度と経度を示すポイントと行政区のポリゴンによるジオメトリを指定すると、h3index フィールドを結合条件とした空間結合が実行できるようになります。このように変数を指定することで、各ポリゴンの範囲内に含まれるポイントの数を集計することなどが行えます。通常は、数千から数百万のポリゴンと照合しなければならないポイントは数百万から数十億あり、これにはスケーラブルなアプローチが必要とされます。このブログでは取り上げませんが、近似値の処理が十分でない場合に地理空間操作を補完するために、空間インデックスを使用する手法などもあります。

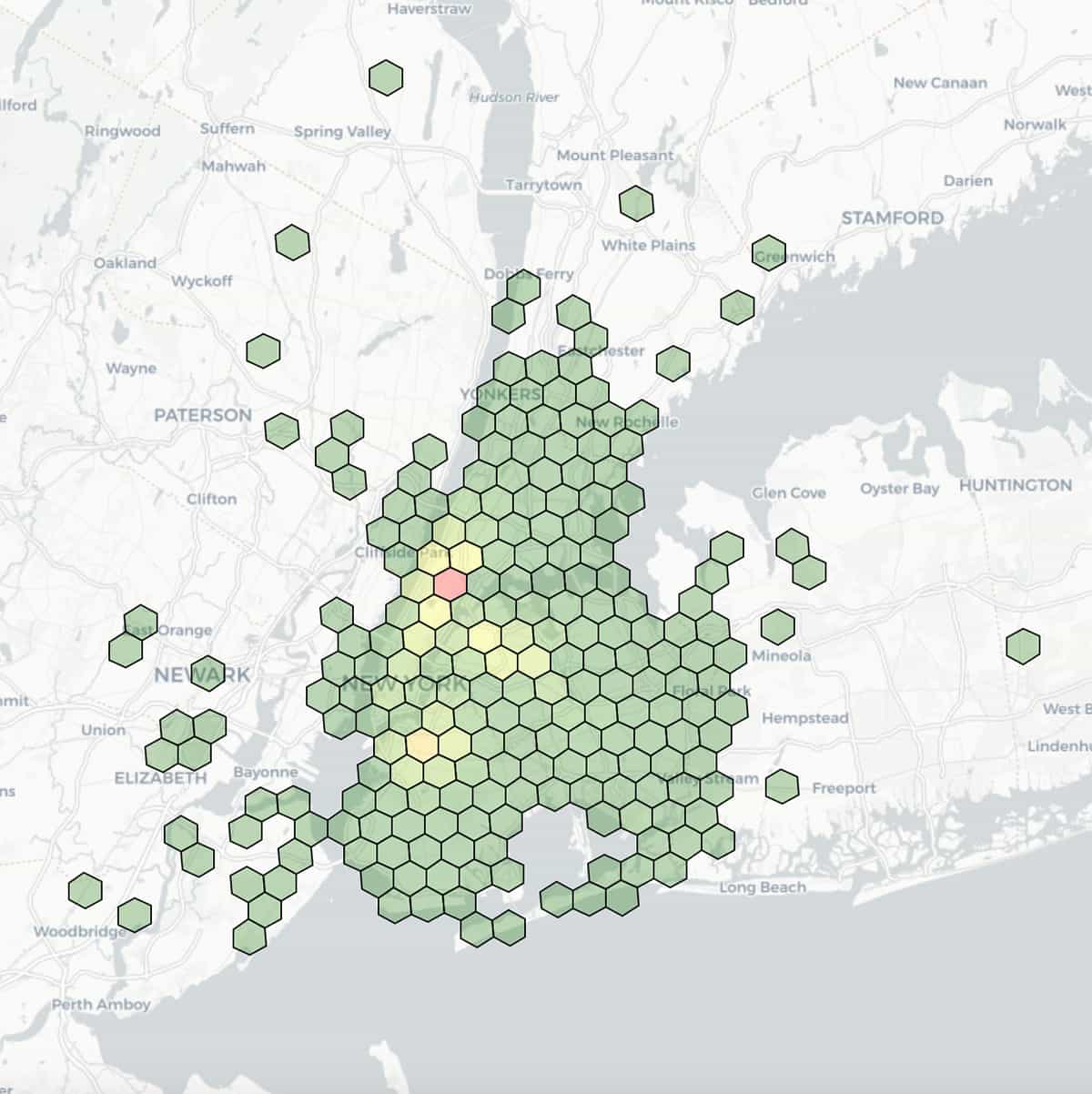
ここでは、タクシーの降車位置を視覚化した図を示します。緯度と経度による区分の精度を 7(辺長1.22km)に指定し、各区分で集計された数に基づいて色分けしています。
データブリックスによる空間データ形式の処理
地理空間情報・ジオデータは、緯度や経度など地球上の物理的な場所や範囲を示す参照点と、属性によって表現される特徴から構成されます。それらを規定するファイル形式には複数の種類がありますが、ここでは代表的なベクトル(ベクター)形式やラスター形式を取り上げて、データブリックスでの読み取り操作について示します。
ベクトルデータとは
ベクトル(ベクター)データとは、X 座標(経度)と Y座標(緯度)で地理空間を表現したものです。高さを考慮する場合には、Z座標(標高:メートル単位)も使用されます。基本的なオブジェクトの種類には、ポイント(点)、ライン(線分)、ポリゴン(多角形)があり、データ格納時の形式として Well-known-text (WKT)、GeoJSON、Shapefileがよく使用されます。以降で、この 3 つの形式について解説します。
WKT 形式で保存されたジオメトリを使用して、ニューヨーク市のタクシーのデータを読み込�みます。このブログ内で使用されている他の API やデータソースと形式や仕様を揃えるため、データ構造には DataFrame を使用します。WKT のテキストコンテンツは the_geom フィールドに含まれており、st_geomFromWKT(…) UDF を呼び出すことで、対応する JTS のジオメトリクラスに容易に変換できます。
GeoJSON は、多くのオープンソース GIS パッケージで、特徴、プロパティ、空間範囲などのさまざまな地理空間データ構造のエンコードに使用されています。サンプルでは、ニューヨーク市の行政区分を読み込み、ワークフローに合わせてアプローチを指定します。データは JSON 形式に準拠しているため、データブリックスに組み込まれている JSON リーダーを使用できます。.option(“multiline”,”true”) を使えば、ネストされたスキーマを持つデータを読み込めます。

コードと出力例の説明:データブリックスの JSON リーダーに .option(“multiline”,”true”) を使用し、ネストされたスキーマを持つデータを読み込んだ例。
Spark の explode 関数を使用すると、上記の状態から任意のフィールドを選択して、最上位の��列に移すことができます。例えば、ジオメトリ、プロパティ、タイプを上位に移し、WKT の例と同様に、対応する JTS クラスにジオメトリをデータ変換することが可能です。

既存の DataFrameを使用するか、Python の空間データレンダリングライブラリである Foliumで直接データをレンダリングして、ニューヨーク市のタクシー区域データを Notebook 内で視覚化することもできます。そのためには、Databricks File System (DBFS) を使用します。DBFS は分散ストレージレイヤで実行され、既存のファイルシステム標準のデータ形式を維持したまま、コードを動作させることができます。この DBFS の FUSE マウントを使用することで、ローカルの API 呼び出しでファイルの読み込みと書き込みを行えるようになり、分散環境にない API でも容易にデータを読み込んで、インタラクティブにレンダリングできるようになります。下のコードでは、Python の open(…) コマンドで、引数の先頭に「/dbfs/」を付けることで、FUSE マウントを有効にしています。
Shapefile は、ESRI によって開発されたベクトル(ベクター)データ形式です。空間的な位置と地理上の特徴に関する属性情報を格納します。拡張子の異なる同じ名前のファイルを同一ディレクトリ内に置く形で構成され、*.shp、*.shx、*.dbf の必須ファイルに加え、複数のファイルを置くことができます。他によく使用されるものとして KML がありますが、今回は簡潔にするために省略します。ニューヨーク市の建築物のデータに対して、Shapefileを適用してみましょう。Shapefile の読み取りにはいくつかの方法がありますが、ここでは GeoSparkを使用して説明します。まず、デフォルトで利用できる ShapefileReaderを使用して rawSpatialDf DataFrame を生成します。
rawSpatialDf を一時的なビューとして登録することで、Spark SQL の標準の構文で DataFrame を操作できるようになります。UDF を適用して Shapefile 形式の WKT をジオメトリにデータ変換するなどの操作が可能です。
さらに、データブリックスに組み込まれたインライン分析視覚化機能によって、ニューヨーク市の高層ビルを高い順にグラフ化するといったこともできます。

ラスターデータとは
ラスターデータとは、空間の特徴を示す情報が、行と列で構成された格子状のセル(もしくはピクセル)のことです。連続したデータとしても、離散したデータとしても扱われます。衛星画像、写真測量、スキャンされた地図など、全てラスタベースの地球観測(EO)データです。
次の Python コードのサンプルでは、RasterFrames が使用されています。RasterFrames は DataFrame を扱う地理空間分析フレームワークで、GeoTIFF 形式の Landsat 8 画像(赤と近赤外線)の 2 つのバンドを読み込み、正規化差植生指数(NDVI)と組み合わせます。下のサンプルでは、このデータを使用して、ニューヨーク市の植生状況を評価しています。RasterFrame コンテンツの操作には rf_ipython モジュールを使い、下に示すように、赤(red)、近赤外線(NIR)、正規化差植生指数(NDVI)のそれぞれの色調に応じた表示が行えるようになっています。データブリックスの displayHTML(…) コマンドを使用すれば、Notebook 内に結果を表示させることもできます。
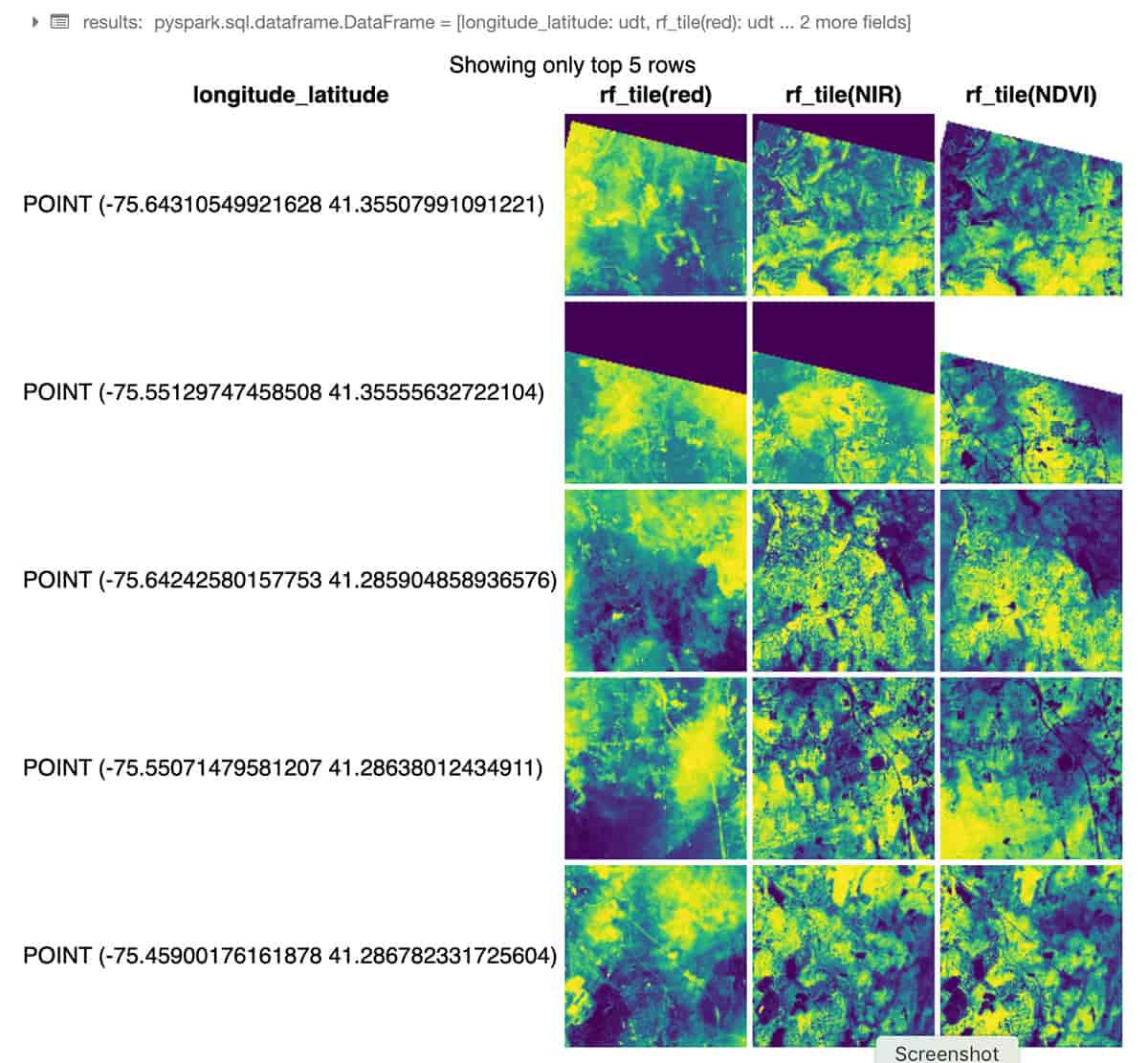
RasterFrame では、カスタム Spark データソースを通じて、GeoTIFF、 JP2000、MRF、HDF などのさまざまなラスターデータ形式を複数のサービスで読み込むことができます。また、ベクトル形式の GeoJSONと WKT/WKB の読み込みにも対応しています。RasterFrame コンテンツは、200 以上のラスター関数とベクトル関数を通じて、フィルタリング、変換、サマライズ、再サンプリング、ラスタライズを行えます。上のサンプルコードでは、st_reproject(…) や st_centroid(…) が使用されています。Python、SQL、Scala用の API も提供されており、Spark ML との相互運用も可能です。
ジオデータベース
ジオデータベースは、小規模データについてはファイル単位、中規模データについては JDBC / ODBC 接続を介した利用が可能です。データブリックスを使用すれば、あらかじめ用意されている JDBC / ODBC データソースで複数の SQL データベースにクエリできます。下に示す PostgreSQLへの接続は、小規模のワークロードに対してよく使用されるもので、PostGIS の拡張機能を適用して実行されます。このような形で接続することで、ユーザーは既存のデータベースの状態を変更することなく、アクセスを維持できます。
データブリックスで地理空間情報の分析を開始する
多くの企業や行政機関が、空間参照データと企業のデータソースを組み合わせて実用的な情報を抽出し、さまざまなユースケースでイノベーションを実現しようとしています。このブログでは、データブリックスの統合データ分析プラットフォームを使用して、地理空間情報ワークロードのスケーリングを容易にし、大規模データの収集、格納、分析を可能とするクラウドの活用方法について解説しました。
今後のブログでは、データブリックスを活用した大規模地理空間データ処理のさらに高度な内容を取り上げる予定です。地理空間データ形式の詳細と、このブログで紹介したフレームワークについては、次の Notebook で確認できます。Data Prep Notebook、GeoMesa + H3 Notebook、GeoSpark Notebook、GeoPandas Notebook、Rasterframes Notebook。地理空間データについては今後も更新していきます。引き続きデ�ータブリックスのドキュメントをご覧ください。
次のステップ
- Webセミナー「Geospatial Analytics and AI in the Public Sector(公共部門での地理空間情報(空間データベース)の分析と AI)」で、よく使用されるユースケースについて解説したライブデモをご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。