Facebook Prophet と Apache Spark による高精度で大規模な時系列予測・分析とは
によって ビラル・オベイダット(Bilal Obeidat), ブライアン・スミス(Bryan Smith) 、 Brenner Heintz による投稿
Databricks の時系列予測・解析 Notebook を試してみる
時系列予測・分析技術の進展により、小売業における需要予測の信頼性は向上しています。しかし、より正確なインベントリ管理を実現したい企業にとっては、予測の精度とタイミングが課題となっています。従来のソリューションにおいては拡張性や正確性の面で制約がありましたが、Apache Spark™ と Facebook Prophet の活用によってこれらの課題を克服する企業が増えてきています。
To see this solution for Spark 3.0, please read the post here
この投稿では、時系列予測の重要性、時系列データのサンプルの視覚化、Facebook Prophet を使ったシンプルな時系列予測モデルの構築について、順を追って説明していきます。単一モデルの構築に慣れた後は、Prophet に Apache Spark™ のテクノロジーを組み合わせて、数百規模のモデルを一度にトレーニングする方法を紹介します。これにより、これまでほとんど達成されなかった粒度で、SKU と店舗の組み合わせごとの正確な予測が作成できます。
需要予測システムの精度と欠品防止の重要性
商品やサービスの需要予測精度を改善するための、時系列分析の速度と精度の向上は小売業者の成功に不可欠です。店舗が管理する在庫が多すぎると、保管スペースの逼迫や商品の期限切れが生じ、インベントリの管理に多くの費用を投入せざるを得なくなります。さらに、��そのような状況が放置されると、新商品の投入や消費パターンの変化にともなう好機を逃すことにもなりかねません。一方、店頭の商品が少なすぎれば、欠品が発生し、顧客の購買機会が失われることになります。予測エラーは小売業者にとって直接の損失となるばかりでなく、消費者が不満を抱くような状況が続けば、競合他社に顧客を奪われる恐れも生じます。
より精度の高い時系列予測の分析手法とモデルの必要性とは
これまでの小売業界では、統合基幹業務(ERP)システムやサードパーティソリューションによる、シンプルな時系列モデルに基づいた需要予測システムが採用されてきました。しかし、技術的な進歩と業界における競争の激化を背景に、多くの企業がこれまでの線形モデルやアルゴリズムに変わる新しい手法を必要とするようになりました。
各企業のこれまでの時系列予測モデルに対して、データサイエンス分野で考案された Facebook Prophet などの新しい機械学習手法やモデルを、柔軟に適用できることが求められています。
![]()
企業内でこうした新しい需要予測ソリューションへの移行を進めるには、需要予測の複雑さに対処するだけでなく、効率的な分散処理環境を用意して、数十万から数百万にも達する機械学習モデルを遅滞なく生成できるようにする必要があります。Spark は、この分散モデルトレーニングを実現するソリューションであり、商品やサービス全体の需要だけでなく、各拠点における商品単位での需要予測も行えます。
時系列データにおける季節変動需要の視覚化
ここでは、Prophet による個々の店舗と商品を対象とした高精度需要予測について見ていきます。データセットはKaggle の一般公開データで、50品目について10 店舗の日次売上を5年間記録したものを使用します。
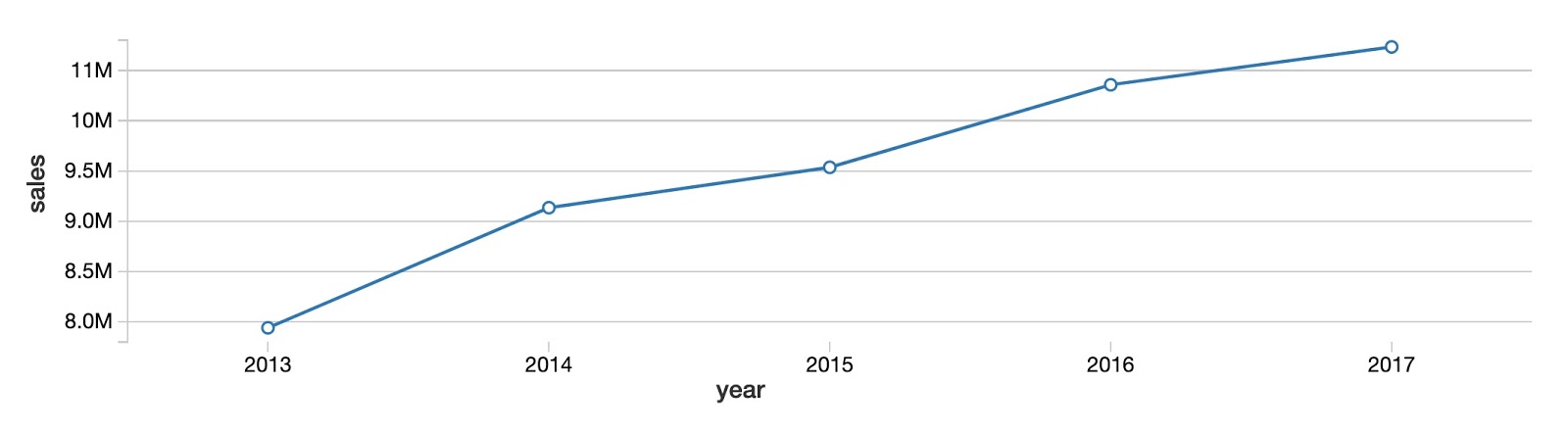
まず、全ての商品と店舗について、年間売上の全体像を確認しましょう。下のグラフからわかるように、商品の総売上高は大きな増減もなく毎年増加しています。
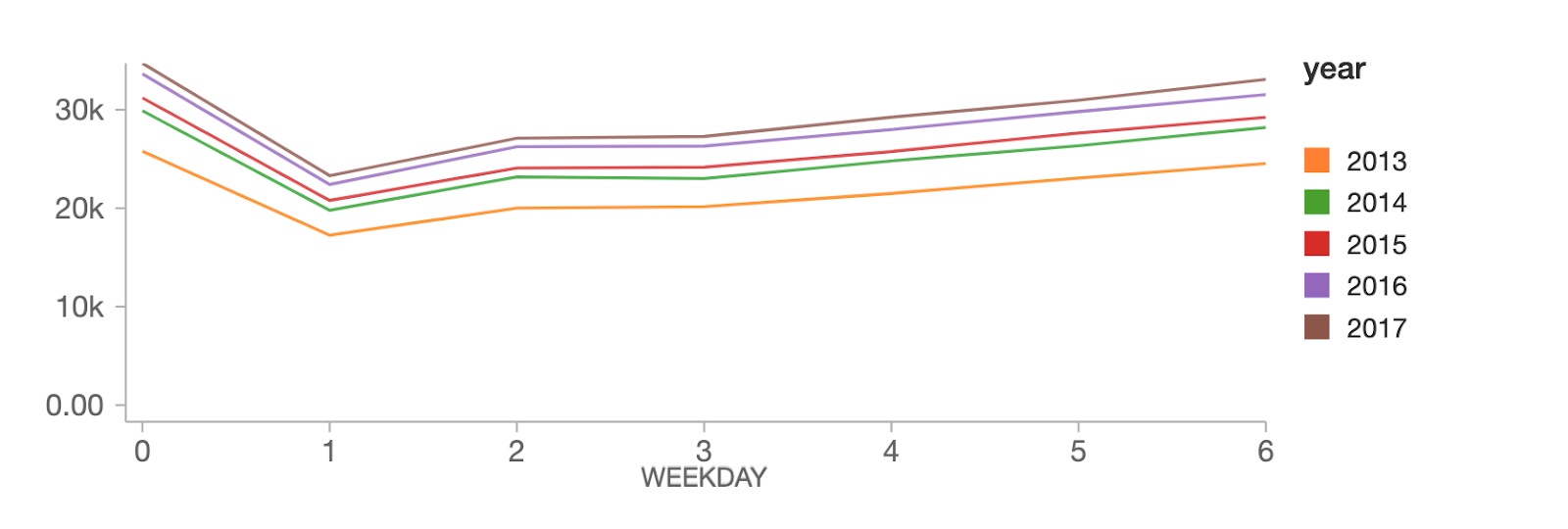
週単位では、売上のピークが日曜日(weekday 0)にあり、月曜日(weekday 1)に大きく落ち込んだ後、残りの平日に徐々に回復する傾向がみてとれます。
Prophet のシンプルな時系列予測のための解析モデル
上のグラフからわかるように、売上データからは年単位の増加傾向に加え、季節性のパターン(季節変動)と曜日によるパターンが見出せます。Facebook Prophet は、このような複数の傾向が重複したデータにも対応しています。
Facebook Prophet follows the scikit-learn API, so it should be easy to pick up for anyone with experience with sklearn. We need to pass in a 2 column pandas DataFrame as input: the first column is the date, and the second is the value to predict (in our case, sales). Once our data is in the proper format, building a model is easy:
これで、データに合致したモデルが作成できました。このモデルを使って90日分の予測を行ってみましょう。下のコードでは、Prophetの make_future_dataframe メソッドを使用して、データセットに日時の時系列データとその後の90日の予測を含めるよう指定します。
これだけです。そうすることで、Prophet の .plot メソッドを使って、将来の予測値に加えて実データと推計値の両方を合わせて表示できるようになります。下のグラフのように、先に示した週単位と季節単位の需要パターンが予測結果にも反映されます。
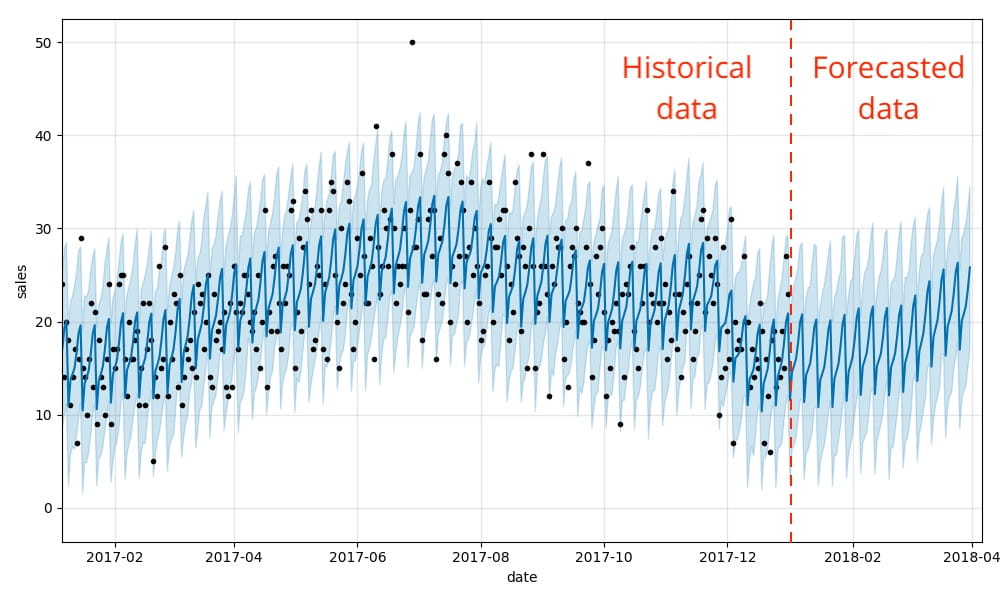
このグラフの見方については、少し説明が必要かもしれません。Bartosz Mikulski 氏がわかりやすく解説しています。端的にいえば、黒い点が実際の値、濃い青色の線が予測値を示し、薄い青色の部分が 95% の不確実性を示す範囲を示しています。
Prophet と Spark による数百の時系列予測モデルの並列トレーニング
ここまでで、単一の時系列予測解析モデルの作成方法を示しました。Apache Spark を活用することで、さらにその機能を高めることができます。具体的には、個々の商品と店舗を対象としたモデルを数百単位で生成することが可能です。単一モデルの場合、データセット全体を順次処理する形となり非常に時間がかかります。
数百単位のモデルを用意することで、たとえば、スーパーマーケットチェーンであれば、地域ごとの需要の違いに基づいて、各店舗で発注すべき生乳の量 などを正確に予測分析できるようになります。
Spark DataFrames を使用した時系列データの分散処理
膨大な数のモデルをトレーニングするには、通常、Apache Spark などの分散データ処理エンジンが使用されます。Spark のクラスターを活用することで、モデルのサブセットのトレーニングがクラスター内の複数のワーカーノードで並列処理され、時系列モデル全体のトレーニング時間を大きく削減できます。
もちろん、クラスターのワーカーノードでトレーニングする場合も、相応のクラウドインフラストラクチャが必要で、その分のコストがかかります。しかし、クラウドリソースをオンデマンドで容易に利用できれば、必要なリソースを迅速にプロビジョニングできます。また、モデルのトレーニングやリソースの展開も短期間に行え、物理資産を長期間保持することなく、拡張性を大きく向上させることができます。
なお、Spark の分散データ処理を実現するうえで重要な役割を果たしているのが Spark DataFrame です。DataFrame にデータを読み込むことで、クラスターの各ワーカーにデータが分散されます。それぞれのワーカーでデータのサブセットを並列処理し、全体での実行時間を減らすことができるのは、この DataFrame の働きによるものです。
各ワーカーが処理を実行するには、必要なデータのサブセットにアクセスできる必要があります。DataFrame では、キーバリュー形式でデータをグループ化することで、個々のワーカーノードにデータを渡します。今回のケースでは、全ての時系列解析に使用するデータを店舗と商品の組み合わせで構成されるキーバリューとしてグル�ープ化しています。
ここでは、groupByコードを使用して、複数モデルトレーニングの効率的な並行処理について解説しています。ただし、実際に動作させるには、次の段落で説明するUDF を設定してデータに適用する必要があります。
pandas のユーザ定義関数(UDF)の活用
時系列データを店舗と商品で適切にグループ化できたら、グループごとに単一モデルのトレーニングを行います。トレーニングには、pandasのユーザ定義関数(UDF)を使用します。UDF は、DataFrame のデータグループごとにカスタム関数を適用できます。
各モデルのトレーニングだけでなく予測結果の生成にも使用できます。トレーニングや予測は DataFrameのグループごとに別々に実行されますが、各グループから出力される結果は新たに生成される単一の DataFrame にまとめられます。このような仕組みとなっているのは、予測が個々の店舗と商品・在庫について行われるのに対して、分析や管理の際には単一のデータセットとして結果を出力できるようにするためです。
下のPython コードは一部省略したものではありますが、UDFの作成はそれほど難しいものではありません。UDF では、返り値のデータスキーマと受け取るデータタイプを pandas_udfメソッドで規定します。そして、その後に続けて、UDF で実行する処理内容について関数を定義します。
以下の関数では、モデルの作成と設定、受け取るデータとの適合について定義されています。また、モデルでの予測が実行され、関数からの出力としてデータが返されます。
UDF の用意ができたら、データセットを店舗と商品で適切にグループ化するために、先に紹介したgroupBy コマンドを使用します。あとは、UDF を DataFrame に apply すれば、モデルに合わせて UDF がデータグループごとの予測を行います。
各グループに対して関数が実行され、データセットが返されると、生成される予測データに結果が反映されます。このような仕組みにより、複数の時系列解析モデルから生成されるデータのトラッキングや、実運用への展開が可能となります。
次のステップ
このブログでは、店舗と商品の組み合わせを対象として時系列での需要予測のための解析モデルを構築しました。SQL クエリを使用すれば、個別の製品に絞った予測結果を表示させることもできます。下のグラフでは、商品#1 について 10 店舗での需要予測結果が示されています。店舗ごとに需要の推移は異なっていますが、全ての店舗に一貫したパターンが見てとれ、想定どおりの結果となっています。
新しい売上データに基づいて新たに予測を行う場合も、容易に予測を生成して既存のテーブル構造に追加できます。つまり、事業環境の変化に合わせて、想定を変えて分析を行うことが簡単に行えます。
さらなる詳細については、オンデマンド Webセミナー「スターバックスにおけるソリューション事例��:Facebook Prophet と Azure Databricks を利用した大規模な需要予測」をご覧ください。

最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。