Azure 環境でのモダン IIoT 分析 - Part 3
Azure Databricks による産業用 IoT 分析の事例が増えています
によって Samir Gupta, Lana Koprivica 、 Hubert Duan による投稿
モダン IIoT(産業用 IoT)アプリケーションのための Azure データ分析に関するブログを 3 部構成でお届けしています。前回の Part 2 では、フィールドデバイスからリアルタイムの IIoT データを Azure に取り込み、データレイク上で直接実行する複雑な時系列処理について解説しました。Part 3 となる今回は、機械学習を活用した予測メンテナンスで風力タービンの収益を最大にす�ると同時に、ダウンタイムによる機会コストを最小限に抑え、利益を最大化する手法を解説します。
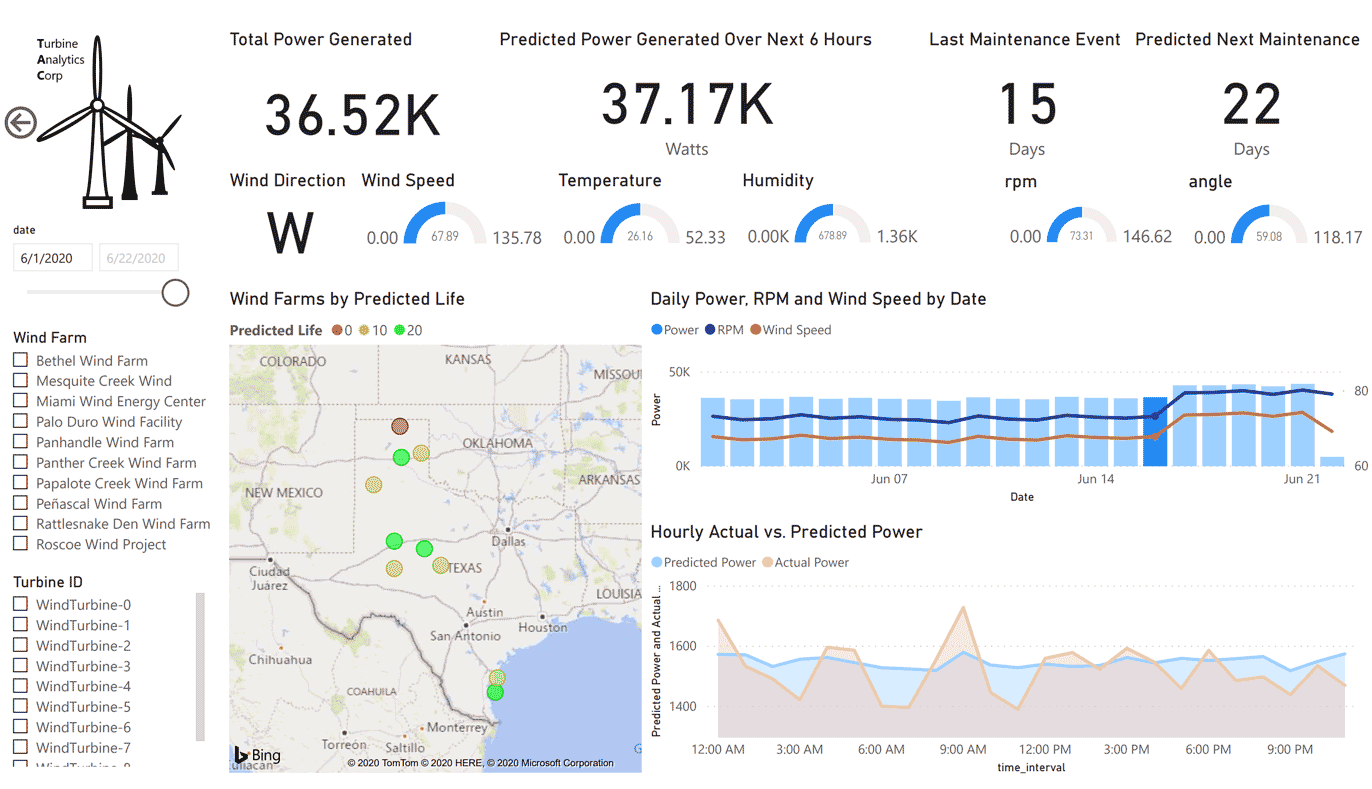
モデルのトレーニングによって得られた結果とそれを視覚化したものは、以下のような Power BI レポートに表示されます。
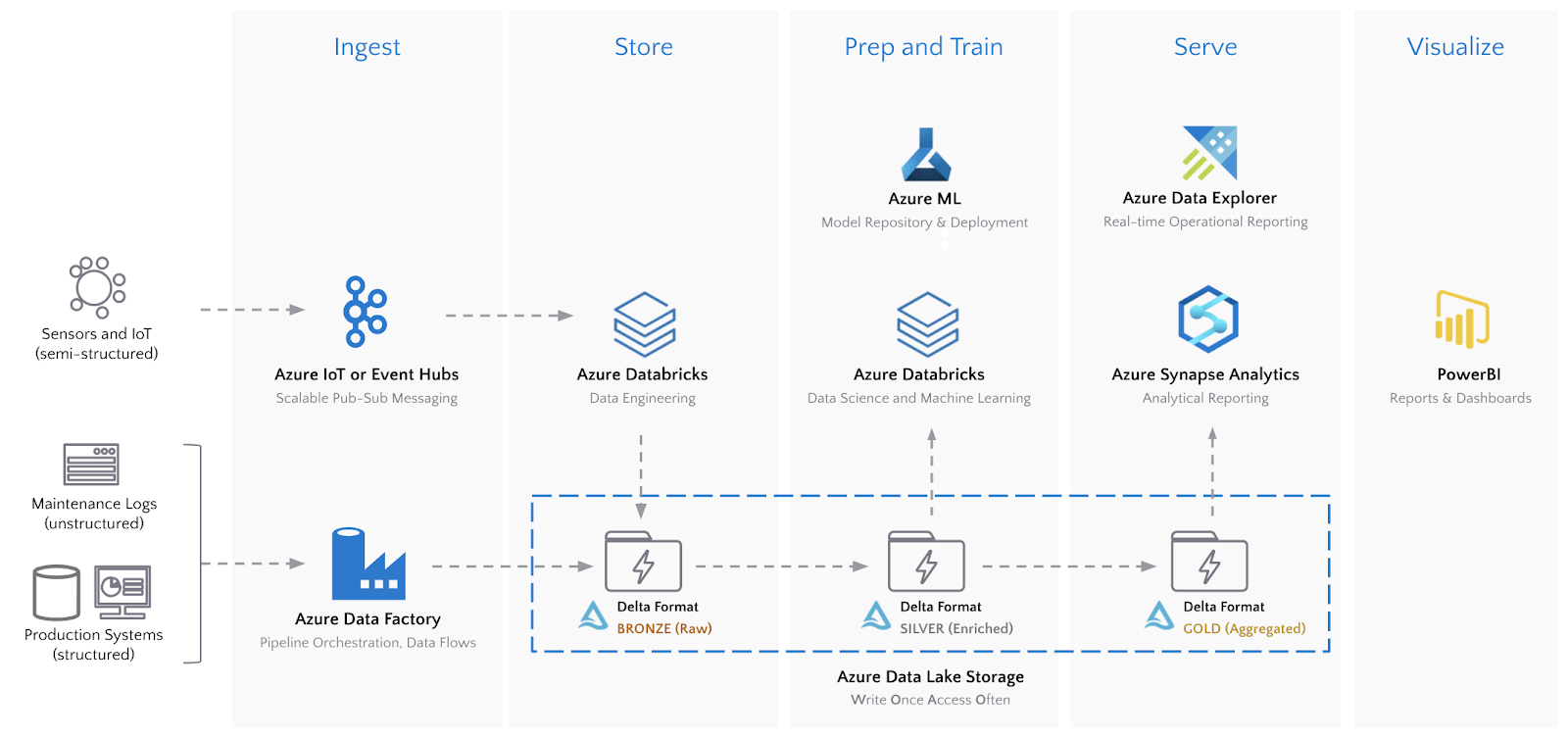
下の図は、エンドツーエンドのアーキテクチャを示したものです。
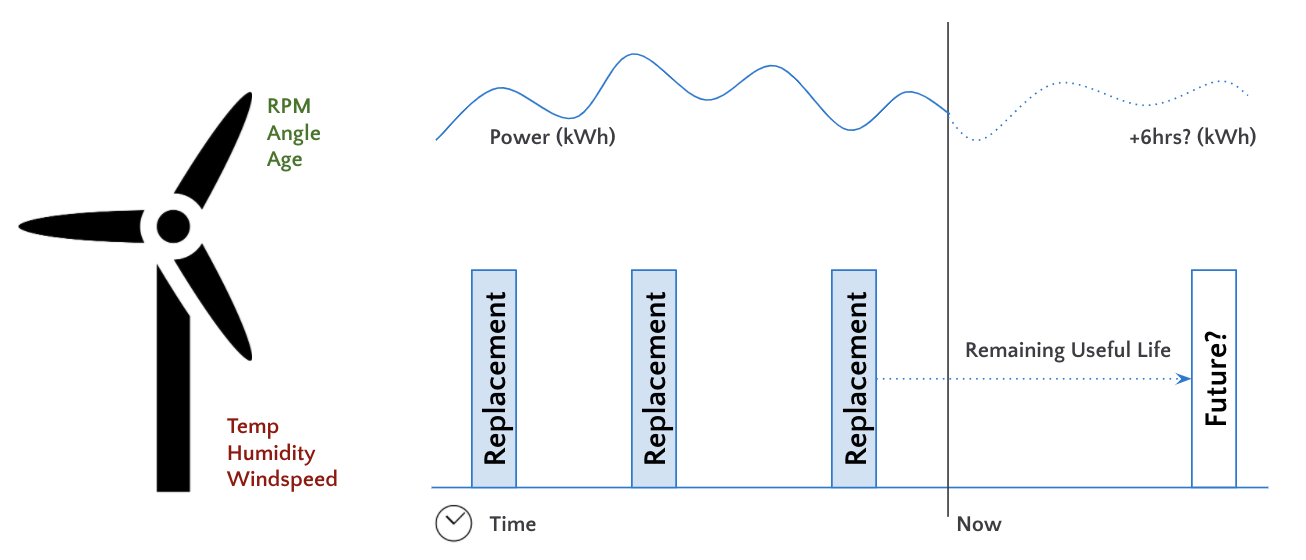
機械学習:出力と残存耐用年数の最適化
風力タービンのような産業用資産のユーティリティ、耐用期間、運用効率における最適化は、収益とコストに多くのメリットをもたらします。このブログでは、風力タービンの収益を最大にすると同時に、ダウンタイムによる機会コストを最小限に抑えることで純利益の最大化を図る実世界の課題について取り上げます。
純利益 = 発電収入 - 設備への負荷により発生するコスト
タービンを高い RPM(回転数)で動作させると、より多くのエネルギーを生み出し、その結果、さらなる収益が得られます。しかし、タービンに負荷をかけると故障が多くなり、コストアップにつながります。
このような最適化における課題を解決するために、次の 2 つのモデルを作成します。
- ある運転条件下におけるタービンの発電量を予測するモデル
- ある運転条件下におけるタービンの残存耐用年数を予測するモデル
次に、利益曲線を作成し、コストを最小限に抑えながら電力収入の最大化を実現する最適な運転条件を特定します。
Azure Databricks と Gold Delta テーブルを利用して特徴量エンジニアリングを実行し、対象フィールドの抽出、2 つのモデルのトレーニング、最後にそれらのモデルを Azure Machine Learning へデプロイしてホスティングします。
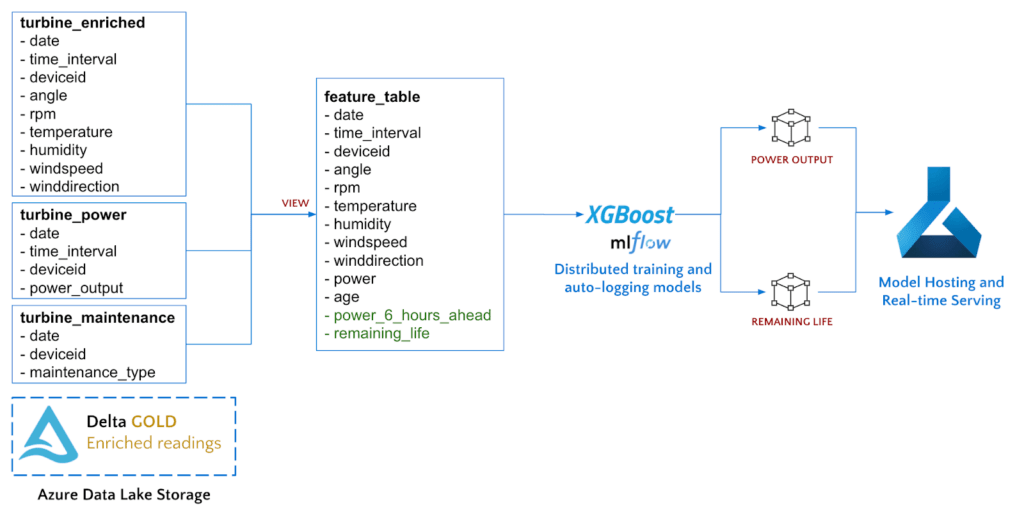
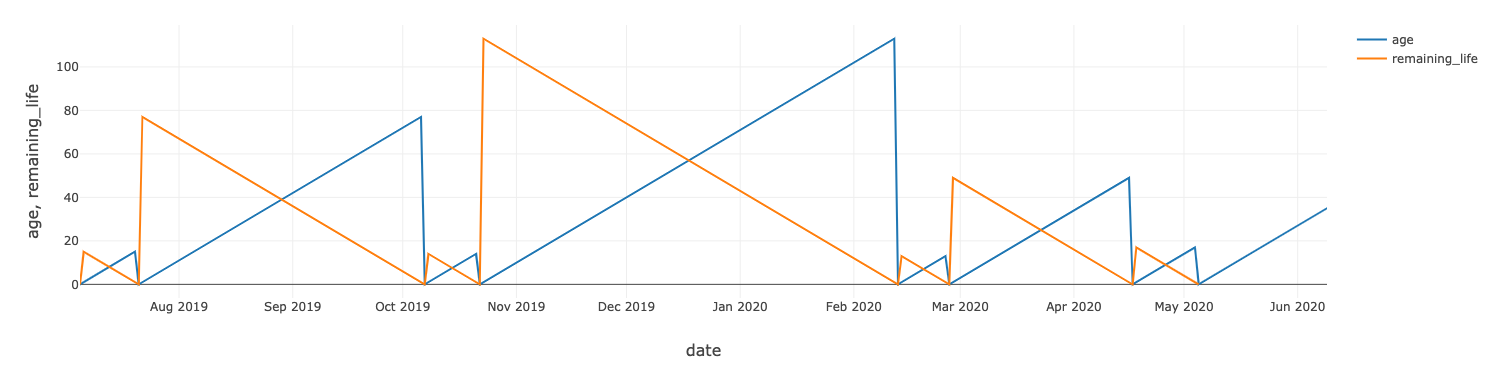
各風力タービンの残存耐用年数を算出するには、各資産の交換時期を示すメンテナンス記録を使用します。
Spark の window 関数を用いて時系列シフトを計算し、6 時間後の発電量を予測します。
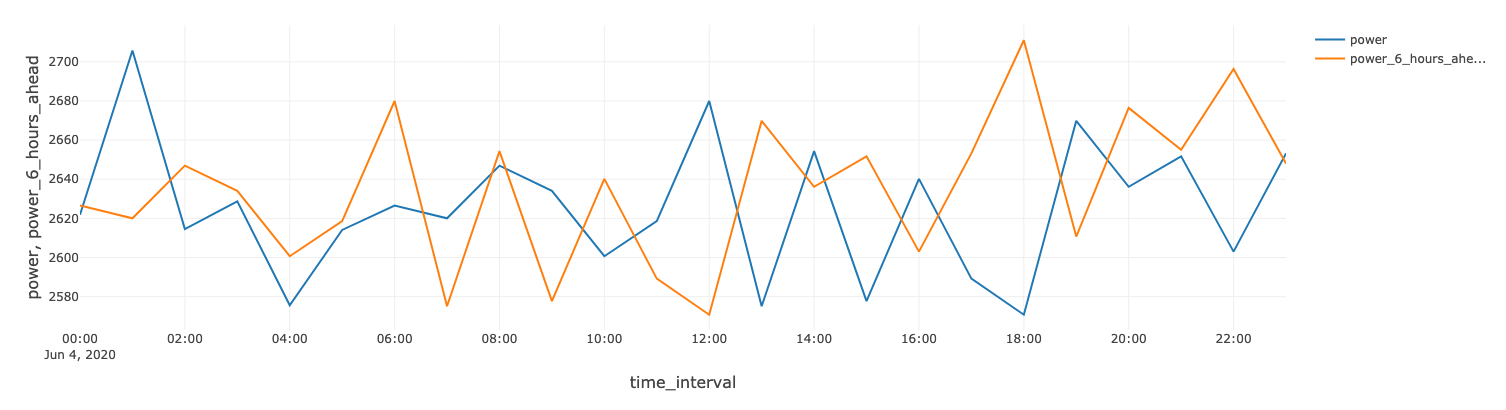
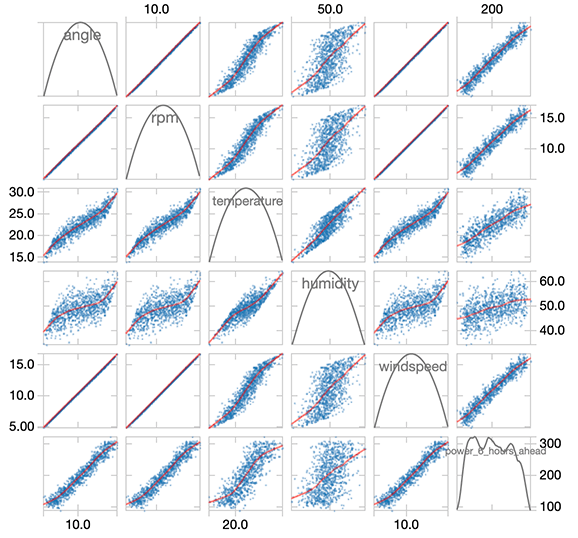
タービンの運転パラメータ(RPM、角度)や気象条件と 6 時間後の発電量には、密接な相関関係があります。
次に、XGBoost の回帰モデルをトレーニングし、特徴列(天気、センサー、電力測定値)を使用してラベル(6 時間先の電力測定値)を予測します。pandas UDF を利用すると、各風力タービンのモデルを並行してトレーニングできます。pandas UDF は、XGBoost モデルのトレーニングコードを Azure Databricks クラスタで利用可能な全てのノードに配布します。
Azure Databricks は、ホストされた MLflow の実験で実行された各モデルのトレーニングを自動的に追跡します。XGBoost 回帰においては、MLflow は params 引数に渡されたパラメータ、RMSE(二乗平均平方根誤差)指標、モデルがトレーニングされたタービン、結果として得られたモデル自体を追跡します。例えば、以下の動画では、デバイス ID 「WindTurbine-18」の電力を予測するための RMSE は、45.79 です。
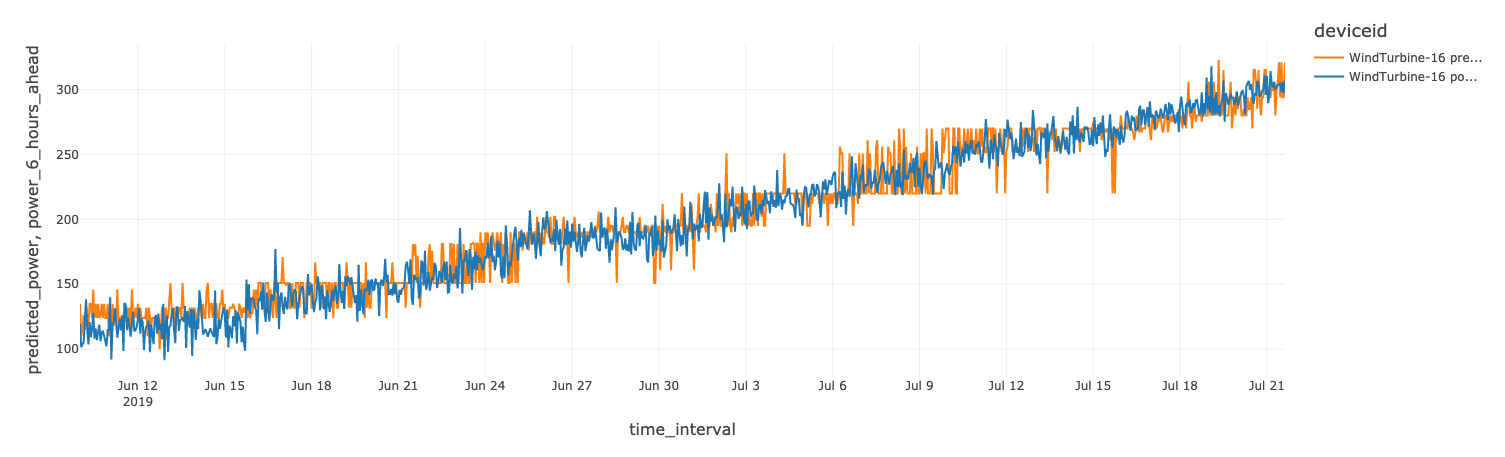
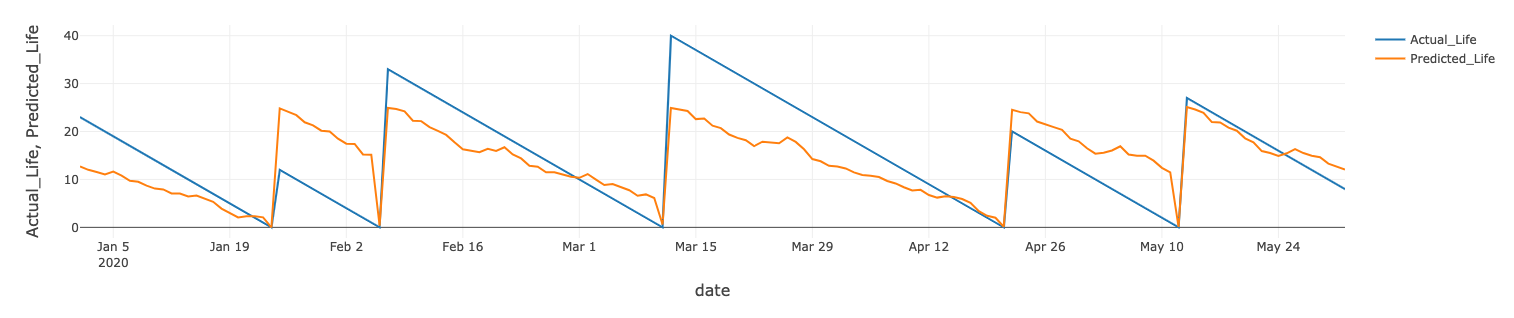
風力タービンの残存耐用年数についても、同様のモデルをトレーニングできます。あるタービンの実績値と予測値は、下図のとおりです。
モデルのデプロイメントとホスティング
Azure Databricks は Azure Machine Learning と統合されており、モデルのデプロイメントとスコアリングを実行します。Databricks 内で直接 Azure ML API を使用し、各モデルの画像を自動的にデプロイして、Azure ML による高速でスケーラブルなコンテナサービス(ACI:Azure Container Instances または AKS:Azure Kubernetes Service)でホスティングします。
モデルがデプロイされると Azure ML Studio 内に表示され、REST API コールでインタラクティブにデータをスコアリングできるようになります。
電力最適化モデルと残存耐用年数モデルの両方が予測サービスとしてデプロイされたことで、この 2 つを各風力タービンにおける純利益の最適化に利用できるようになります。
1 KWh あたり 1 ドルと仮定すると、年間収益は、1 時間あたりの予想電力に 24 時間と 365 日を掛けることで簡単に算出できます。
年間コストは、日収にタービンの 1 年間のメンテナンスの必要回数(365 日/残存耐用年数)を掛け合わせることで算出できます。
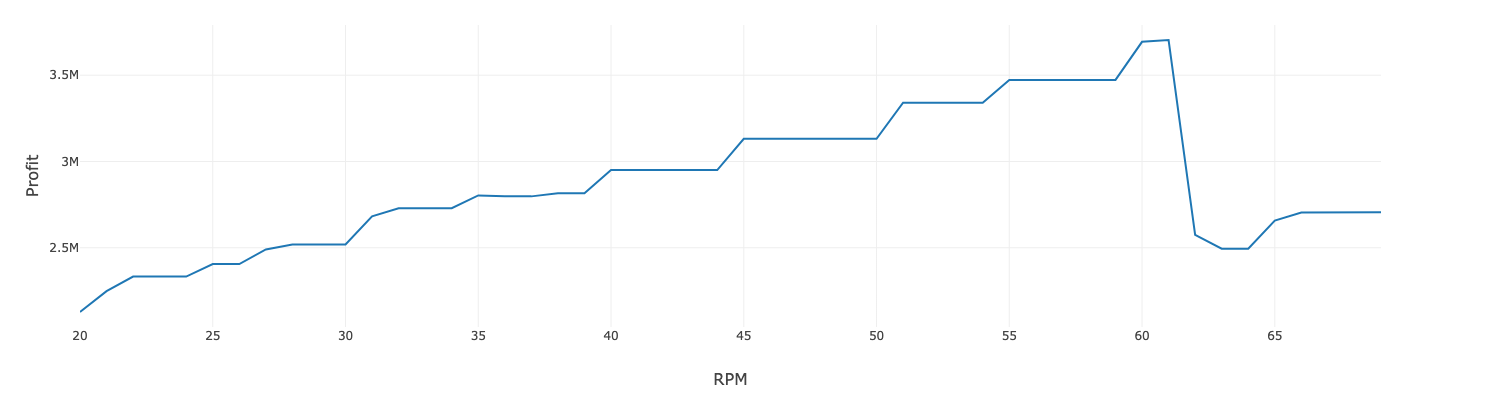
Azure ML でホストされているモデルに複数の呼び出しを行うだけで、さまざまな運転パラメータを繰り返しスコアリングすることが可能です。さまざまな運転パラメータに対する期待利益コストを可視化することで、最適な RPM を特定し、利益を最大化します。
データサービング:Azure Data Explorer と Azure Synapse Analytics
ADX における運用レポートの作成
Azure Data Explorer(ADX)は、ストリーミングの時系列データに対してリアルタイムな運用分析を行います。IIoT デバイスのデータは、IoT Hub から ADX に直接ストリーミングする、または、以下のように Microsoft の Kusto Spark Connector を使用して Azure Databricks からプッシュすることが可能です。
Power BI を Kusto テーブルに結合し、タービンのエンジニア向けの真のリアルタイムな運用ダッシュボードを作成できます。
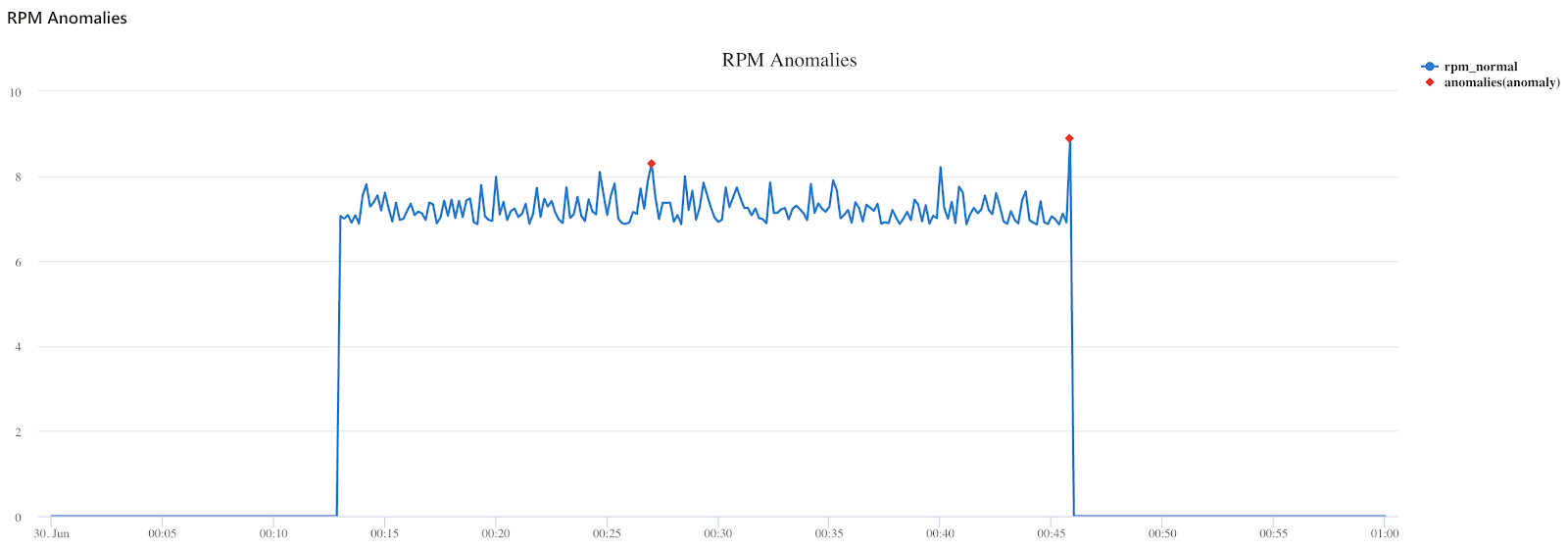
ADX には、予測や異常検知などの時系列分析機能もネイティブに実装されています。例えば、以下の Kusto コードは、データストリーム中の RPM の測定値の異常点を発見します。
ASA における分析レポートの作成
Azure Synapse Analytics(ASA)は、Azure の次世代データウェアハウスです。ADLS Gen2 をネイティブに活用し、Azure Databricks と統合してこれらのサービス間でシームレスなデータ共有を可能にします。
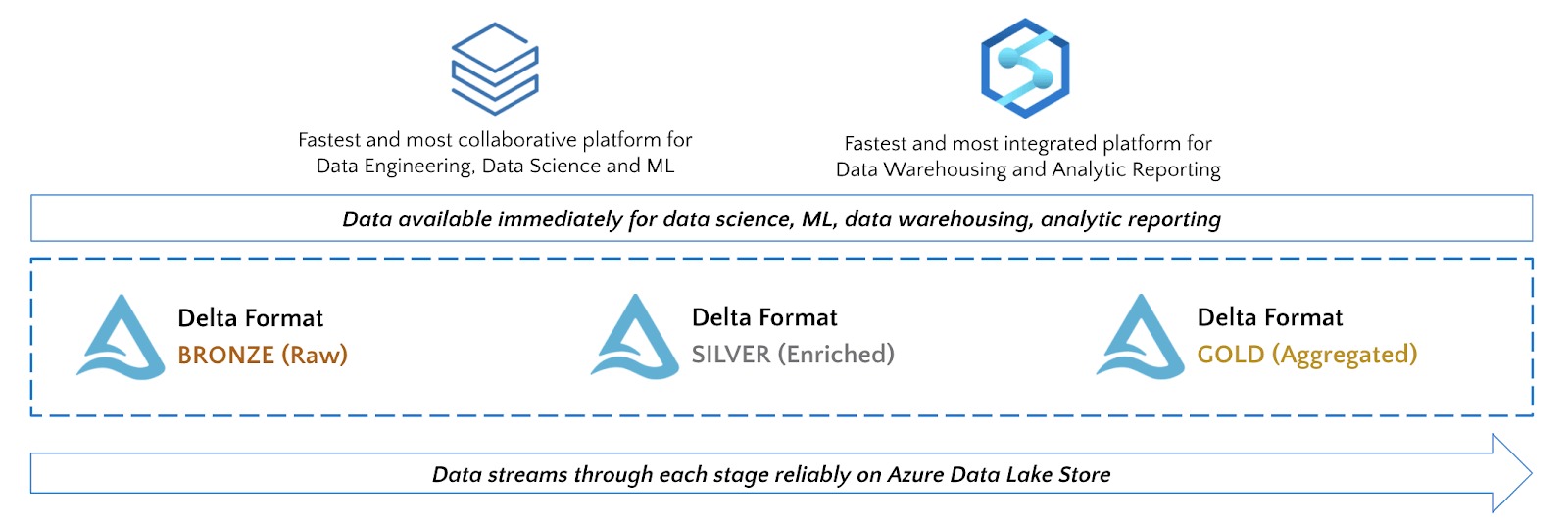
Synapse と Azure Databricks のケイパビリティを活用して、チームの要件やデータにアクセスするユーザーのペルソナに応じた最適なツールを使用しましょう。例えば、Delta の性能メリットを必要とするデータエンジニアや、コラボレーティブで豊富かつ柔軟なワークスペースを必要とするデータサイエンティストには、Azure Databricks が適しています。データの取り込みや処理、可視化において、ローコードまたはデータウェアハウスベースの SQL 環境を必要とするアナリストには、Synapse が適しています。
Azure Databricks 向け Synapse ストリーミングコネクタを使用した場合は、Gold Turbine の測定値を Synapse SQL プールに直接ストリーミングしてレポートを作成できます。
また、Azure Data Factory を使用して、Delta フォーマットからデータを読み取り、Synapse SQL プールに書き込むことも可能です。詳しくは、こちらのドキュメントをご覧ください。
データがクリーニング、処理されて、データアナリストがレポートの作成に利用できるようになると、以下のように、ライブデータと機械学習モデルからの予測に対するライブ Power BI ダッシュボードを構築できるようになります。
まとめ
「Azure 環境でのモダン IIoT 分析」ブログシリーズで解説した実現内容は、次のとおりです。
- リアルタイムな IIoT データのフィールドデバイスから Azure への取り込み。
- データレイク上で複雑な時系列処理を直接実行。
- 風力タービン資産を最大活用する機械学習モデルのトレーニングとデプロイメント。
- エンジニアによる運用レポート、データアナリストによる分析レポートの作成を可能にするデータの提供。
Delta Lake は、全てをつなぐ重要なビッグデータテクノロジーです。Delta on ADLS は、信頼性の高いストリーミングデータパイプラインと、膨大な時系列データに対する高効率なデータサイエンスおよび分析クエリを提供します。さらに、Azure のベストオブブリードのツールを、1 回の書き込みで何度もアクセス可能なデータストアに導入することで、企業におけるレイクハウスパターンの真の採用が可能になります。
次のステップ
ホストされた Notebook は、こちらからお試しいただけます。 Azure Databricks の詳細については、3 部構成のトレーニングシリーズを、Azure 上でのモダンなデータアーキテクチャの構築方法については、こちらの Web セミナーをご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。