Modern Industrial IoT Analytics on Azure - Part 2
Customers Leverage Azure Databricks for Industrial IoT Analytics
by Samir Gupta, Lana Koprivica and Hubert Duan
Introduction
In part 1 of the series on Modern Industrial Internet of Things (IoT) Analytics on Azure, we walked through the big data use case and the goals for modern IIoT analytics, shared a real-world repeatable architecture in use by organizations to deploy IIoT at scale and explored the benefits of Delta format for each of the data lake capabilities required for modern IIoT analytics.
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
The Deployment
We use Azure’s Raspberry PI IoT Simulator to simulate real-time machine-to-machine sensor readings and send them to Azure IoT Hub.
Data Ingest: Azure IoT Hub to Data Lake
Our deployment has sensor readings for weather (wind speed & direction, temperature, humidity) and wind turbine telematics (angle and RPM) sent to an IoT cloud computing hub. Azure Databricks can natively stream data from IoT Hubs directly into a Delta table on ADLS and display the input vs. processing rates of the data.
Delta allows our IoT data to be queried within seconds of it being captured in IoT Hub.
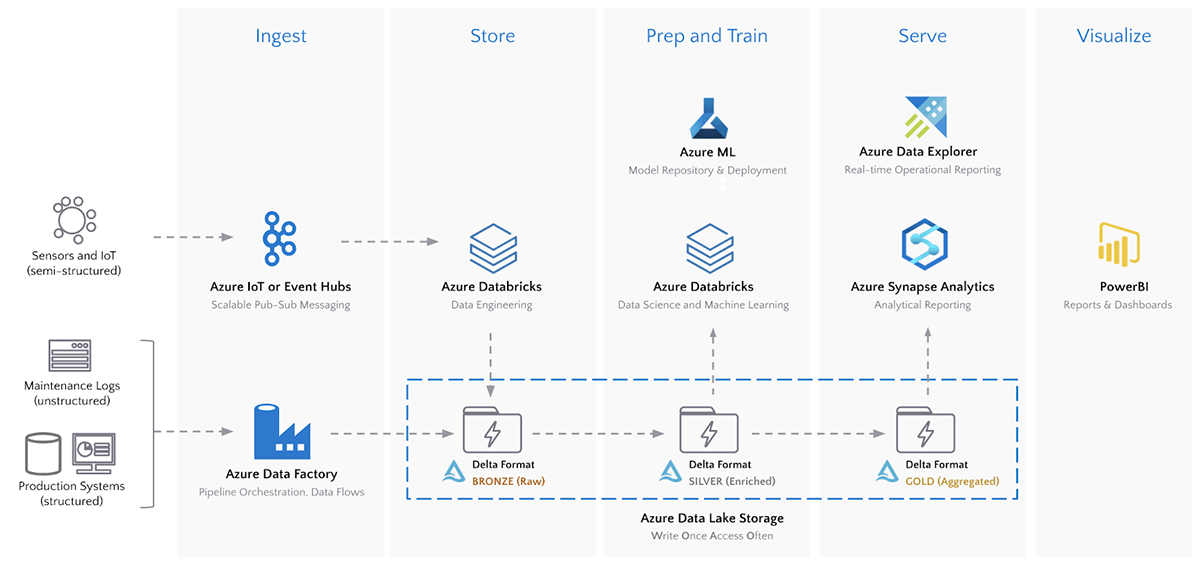
We can now build a downstream pipeline that enriches and aggregates our IIoT applications data for data analytics.
Data Storage and Processing: Azure Databricks and Delta Lake
Delta supports a multi-hop pipeline approach to data engineering, where data quality and aggregation increases as it streams through the pipeline. Our time-series data will flow through the following Bronze, Silver and Gold data levels.
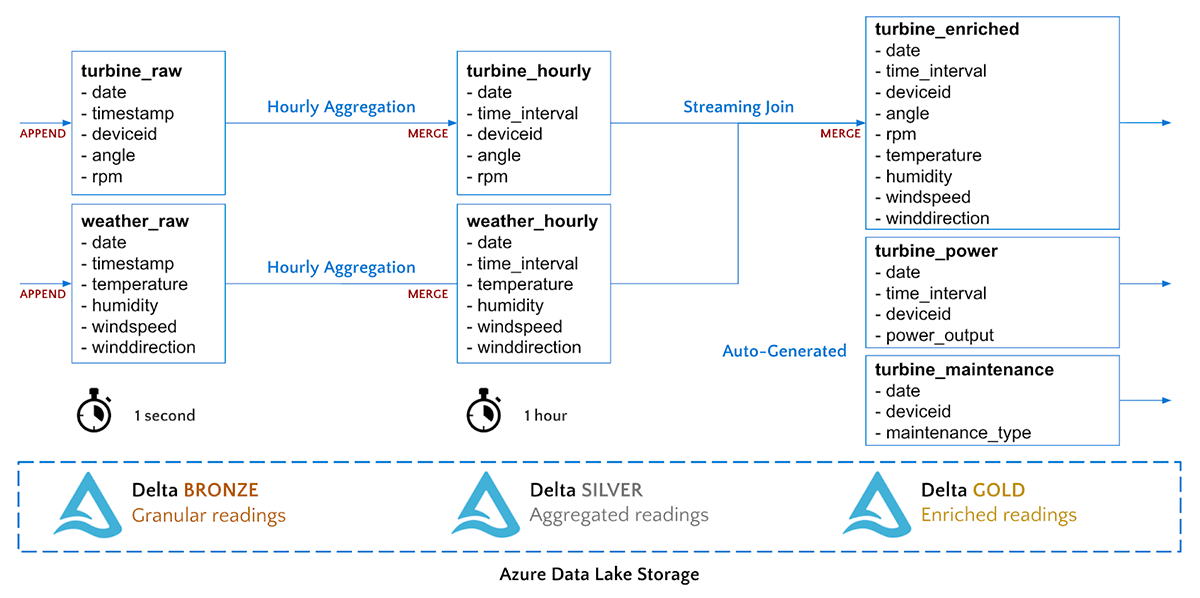
Our pipeline from Bronze to Silver will simply aggregate our turbine sensor data to 1 hour intervals. We will perform a streaming MERGE command to upsert the aggregated records into our Silver Delta tables.
Our pipeline from Silver to Gold will join the two streams together into a single table for hourly weather and turbine measurements.
We can query our Gold Delta table immediately.

The notebook also contains a cell that will generate historical hourly power readings and daily maintenance logs that will be used for model training. Running that cell will:
- Backfill historical readings for 1 year in the turbine_enriched table
- Generate historical power readings for each turbine in the power_output table
- Generate historical maintenance logs for each turbine in the turbine_maintenance table
We now have enriched, artificial intelligence (AI)-ready data in a performant, reliable format on Azure Data Lake that can be fed into our data science modeling to optimize asset utilization.

Our data engineering pipeline is complete! Data is now flowing from IoT Hubs to Bronze (raw) to Silver (aggregated) to Gold (enriched). It is time to perform some analytics on our data.
Summary
To summarize, we have successfully:
- Ingested real-time IIoT data from field devices into Azure
- Performed complex time-series processing on Data Lake directly
They key technology that ties everything together is Delta Lake. Delta on ADLS provides reliable streaming data pipelines and highly performant data science and analytics queries on massive volumes of time-series data. Lastly, it enables organizations to truly adopt a Lakehouse pattern by bringing best of breed Azure tools to a write-once, access-often data store.
In the next post we will explore the use of machine learning to maximize the revenue of a wind turbine while minimizing the opportunity cost of downtime.
What’s Next?
Try out the notebook hosted here, learn more about Azure Databricks with this 3-part training series and see how to create modern data architectures on Azure by attending this webinar.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.