Modern Industrial IoT Analytics on Azure - Part 1
Customers Leverage Azure Databricks for Industrial IoT Analytics
by Samir Gupta, Lana Koprivica and Hubert Duan
This post and the three-part series about Industrial IoT analytics were jointly authored by Databricks and members of the Microsoft Cloud Solution Architecture team. We would like to thank Databricks Solutions Architect Samir Gupta and Microsoft Cloud Solution Architects Lana Koprivica and Hubert Dua for their contributions to this and the two forthcoming posts.
The Industrial Internet of Things (IIoT) has grown over the last few years as a grassroots technology stack being piloted predominantly in the oil & gas industry to wide scale adoption and production use across manufacturing, chemical, utilities, transportation and energy sectors. Traditional IoT systems like Scada, Historians and even Hadoop do not provide the big data analytics capabilities needed by most organizations to predictively optimize their industrial assets due to the following factors.
| Challenge | Required Capability |
|---|---|
| Data volumes are significantly larger & more frequent | The ability to capture and store sub-second granular readings reliably and cost effectively from IoT devices streaming terabytes of data per day |
| Data processing needs are more complex | ACID-compliant data processing - time-based windows, aggregations, pivots, backfilling, shifting with the ability to easily reprocess old data |
| More user personas want access to the data | Data is an open format and easily shareable with operational engineers, data analysts, data engineers, and data scientists without creating silos |
| Scalable ML is needed for decision making | The ability to quickly and collaboratively train predictive models on granular, historic data to make intelligent asset optimization decisions |
| Cost reduction demands are higher than ever | Low-cost on-demand managed platform that scales with the data and workloads independently without requiring significant upfront capital |
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Organizations are turning to cloud computing platforms like Microsoft Azure to take advantage of the scalable, IIoT-enabling technologies they have to offer that make ingesting, processing, analyzing and serving time-series data sources like Historians and SCADA systems easy.
In part 1, we discuss the end-to-end technology stack and the role Azure Databricks plays in the architecture and design for the industrial application of modern IoT analytics.
In part 2, we will take a deeper dive into deploying modern IIoT analytics, ingest real-time IIoT machine-to-machine data from field devices into Azure Data Lake Storage and perform complex time-series processing on Data Lake directly.
In part 3, we will look at machine learning and analytics with industrial IoT data.
The Use Case - Wind Turbine Optimization
Most IIoT Analytics projects are designed to maximize the short-term utilization of an industrial asset while minimizing its long-term maintenance costs. In this article, we focus on a hypothetical energy provider trying to optimize its wind turbines. The ultimate goal is to identify the set of optimal turbine operating parameters that maximizes each turbine’s power output while minimizing its time to failure.
The final artifacts of this project are:
- An automated data ingestion and processing pipeline that streams data to all end users
- A predictive model that estimates the power output of each turbine given current weather and operating conditions
- A predictive model that estimates the remaining life of each turbine given current weather and operating conditions
- An optimization model that determines the optimal operating conditions to maximize power output and minimize maintenance costs thereby maximizing total profit
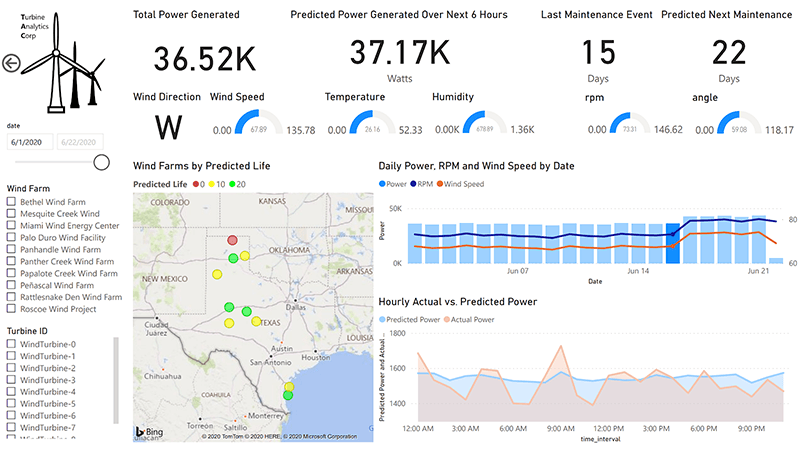
- A real-time analytics dashboard for executives to visualize the current and future state of their wind farms, as shown below:
The Architecture - Ingest, Store, Prep, Train, Serve, Visualize
The architecture below illustrates a modern, best-of-breed platform used by many organizations that leverages all that Azure has to offer for IIoT analytics.
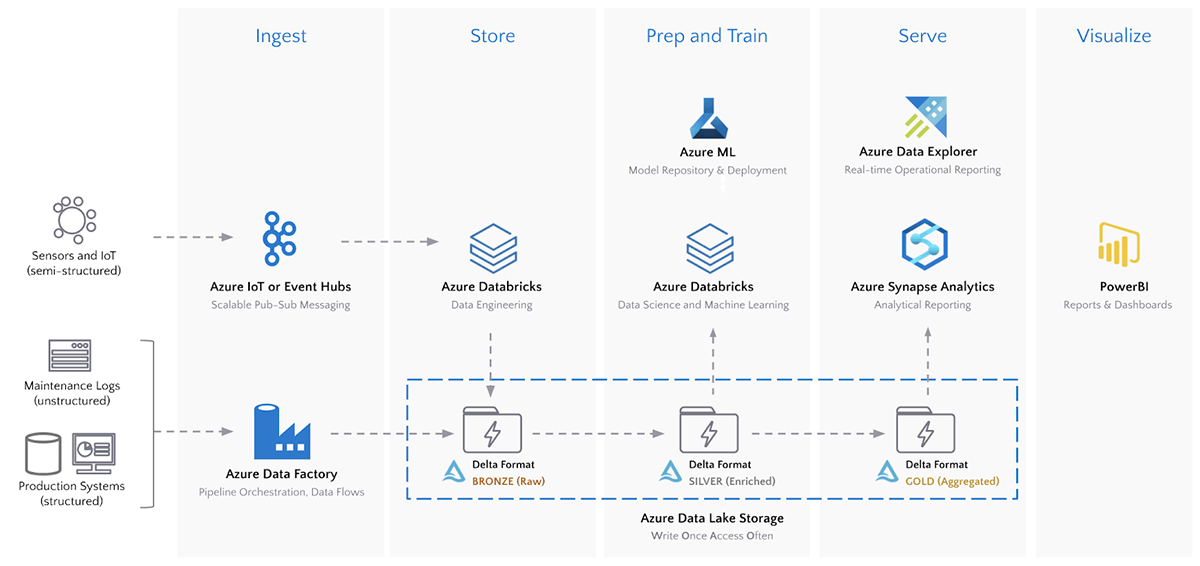
A key component of this architecture is the Azure Data Lake Store (ADLS), which enables the write-once, access-often analytics pattern in Azure. However, Data Lakes alone do not solve the real-world challenges that come with time-series streaming data. The Delta storage format provides a layer of resiliency and performance on all data sources stored in ADLS. Specifically for time-series data, Delta provides the following advantages over other storage formats on ADLS:
| Required Capability | Other formats on ADLS Gen 2 | Delta Format on ADLS Gen 2 |
|---|---|---|
| Unified batch & streaming | Data Lakes are often used in conjunction with a streaming store like CosmosDB, resulting in a complex architecture | ACID-compliant transactions enable data engineers to perform streaming ingest and historically batch loads into the same locations on ADLS |
| Schema enforcement and evolution | Data Lakes do not enforce schema, requiring all data to be pushed into a relational database for reliability | Schema is enforced by default. As new IoT devices are added to the data stream, schemas can be evolved safely so downstream applications don’t fail |
| Efficient Upserts | Data Lakes do not support in-line updates and merges, requiring deletion and insertions of entire partitions to perform updates | MERGE commands are effective for situations handling delayed IoT readings, modified dimension tables used for real-time enrichment, or if data needs to be reprocessed. |
| File Compaction | Streaming time-series data into Data Lakes generates hundreds or even thousands of tiny files. | Auto-compaction in Delta optimizes the file sizes to increase throughput and parallelism. |
| Multi-dimensional clustering | Data Lakes provide push-down filtering on partitions only | ZORDERing time-series on fields like timestamp or sensor ID allows Databricks to filter and join on those columns up to 100x faster than simple partitioning techniques. |
Summary
In this post we reviewed a number of different challenges facing traditional IIoT systems. We walked through the use case and the goals for modern IIoT analytics, shared a repeatable architecture that organizations are already deploying at scale and explored the benefits of Delta format for each of the required capabilities.
In the next post we will ingest real-time IIoT data from field devices into Azure and perform complex time-series processing on Data Lake directly.
They key technology that ties everything together is Delta Lake. Delta on ADLS provides reliable streaming data pipelines and highly performant data science and analytics queries on massive volumes of time-series data. Lastly, it enables organizations to truly adopt a Lakehouse pattern by bringing best of breed Azure tools to a write-once, access-often data store.
What’s Next?
Learn more about Azure Databricks with this 3-part training series and see how to create modern data architectures by attending this webinar.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.