リアルワールドデータ分析によるハイリスク患者の検知
Delta Lake で ML ランタイムと MLflow を活用して疾患を予測する方法
によって アミール・カーマニー 、 フランク・オースティン・ノーザフト による投稿
低コストのゲノムシークエンスや AI を活用した医療用画像診断の普及により、精密医療への関心が高まっています。Databricks では、精密医療の領域において、データや AI を活用して疾患に対する最適な治療法を発見することを目指しています。精密医療は、希少疾患やがんと診断された患者の治療のアウトカムを改善してきましたが、精密医療はリアクティブ型の医療です。精密医療を受けるには、患者が病気である必要があります。
医療・ヘルスケアのコストとアウトカムの面では、糖尿病や心臓病、薬物使用障害などの慢性疾患の予防が、医療費と生活の質の改善に大きく影響を与えることがわかっています。米国では、死亡者の 10 人のうち 7 人が慢性疾患の患者で、医療費の 85% が慢性疾患の治療によるものです。また、欧州や東南アジアでも同様の傾向が見られます。非感染性疾患は、患者への教育や慢性疾患の原因となる根本的な問題に対処することで、通常は予防可能です。これらの問題には、神経疾患の原因となる既知の遺伝的リスクなどの生物学的リスク、環境汚染や健康的な食事、予防治療へのアクセスの欠如などの社会経済的要因、喫煙や飲酒、座りっぱなしのライフスタイルなどの行動によるリスクが含まれます。
精密医療は、データを利用して疾病発症のリスクが高い患者集団を特定し、疾病リスクを軽減する介入を行うことに重点を置いています。介入の種類には、リスクのある患者をリモートで監視してライフスタイルや治療法を提案するデジタルアプリや、病状の監視の強化、補助的な予防医療の提供などがあります。しかし、これらの介入を実現するには、まずはリスクのある患者を特定する必要があります。
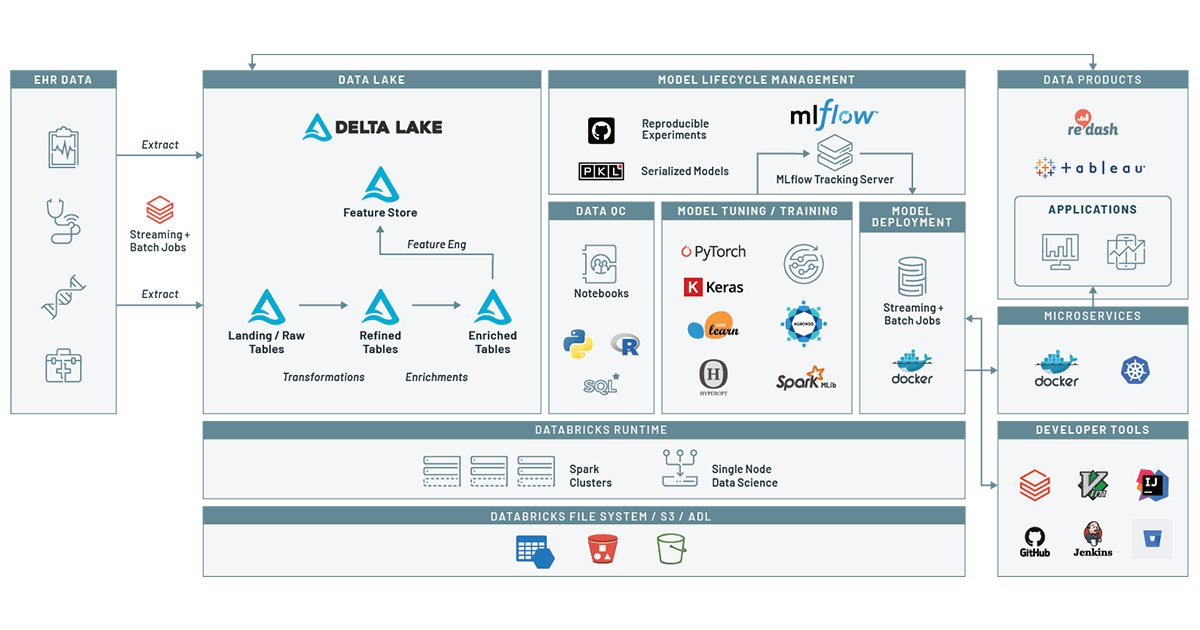
ハイリスク患者を特定する優れたツールの 1 つに、リアルワールドデータ(RWD)の活用があります。RWD とは、ヘルスケアのエコシステムで生成されるデータを相称したものです。電子医療記録(EMR)や健康記録(EHR)など、入院、臨床現場、薬局、医療従事者からのデータに加え、ゲノミクス、ソーシャルメディア、ウェアラブルなどの他のソースから�収集されるデータも増えています。同じシリーズのこちらのブログでは、EHR データから臨床データレイクを構築する方法をご紹介しました。このブログ記事では、Databricks の統合データ分析プラットフォームを活用して臨床データレイクを構築して患者のジャーニーを追跡し、機械学習モデルを作成します。このモデルを使用して、患者の来歴やデモグラフィック情報を考慮すると、特定の期間内に特定の症状を発症した患者のリスクを評価できます。ここでは、薬物の過剰使用を例に取り上げます。物質使用障害によって引き起こされる広範な健康被害に関する重要なトピックです。MLflow を利用してモデルを追跡することで、モデルの経時的な変化を容易に把握できるため、モデルを患者ケアに展開するプロセスに信頼性がもたらされます。
Databricks の機械学習による疾病予測
データの準備
特定の時間におけるリスクを予測するモデルをトレーニングする��には、患者の関連するデモグラフィック情報(診断時の年齢、人種など)、患者の診断履歴に関する時系列データを取得するデータセットが必要です。その後、このデータを利用して、患者が将来のある期間において病気と診断される可能性に影響を与える診断や、デモグラフィック的なリスクを学習するモデルをトレーニングできます。
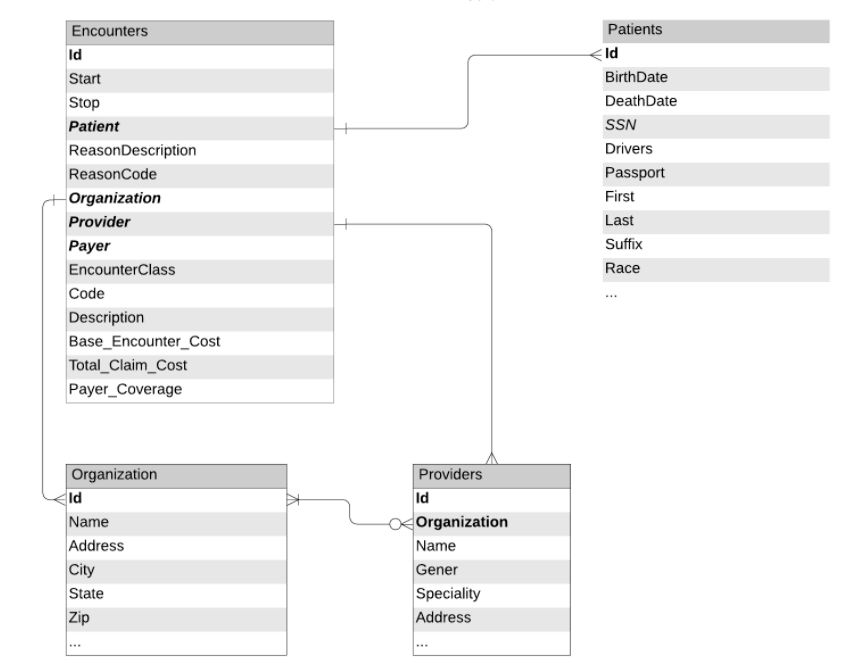
図 1:EHR から抽出されたデータスキーマとテーブル間のリレーションシップ
このモデルをトレーニングするには、電子カルテ(EHR)に含まれるような患者の診断履歴やデモグラフィック情報を活用できます。図1 は、今回のワークフローで使用するテーブルを示しています。これらのテーブルは、前回のブログの Notebook を利用して作成したものです。Delta Lake から来歴、組織、患者データ(難読化された PII 情報を含む)をロードし、全患者のデモグラフィック情報を伴う来歴のデータフレームを作成します。
対象となる症状に基づいて、トレーニングデータに含めるのに適した患者のセットを選択します。来歴から、少なくとも 1 度は病気と診断された患者である症例と、病気の既往がない患者である対照を同じ数用意し�ています。
ここで、患者エンカウンターのセットを分析対象の患者に限定します。
対象となるレコードが揃ったので、次のステップでは特徴量を追加していきます。この予測タスクでは、デモグラフィック情報に加えて、ある症状や共存する症状(併存疾患)と診断された回数の合計、過去の訪問回数の数を選択します。
ほとんどの疾患では、併存疾患に関する多くの文献がありますが、RWD のデータセットを活用して対象疾患に関連する併存疾患を特定することも可能です。
私たちのコードでは、Notebook ウィジェットを使用して、含めるべき併存疾患の数や診察を行う時間の長さ(日単位)を指定しています。これらのパラメータは MLflow のトラッキング API を使って記録されます。

次に、それぞれの診察に特徴量を追加する必要があります。各併存疾患に対応して、対象の症状が過去に何回診察されたかを示す列を追加します。
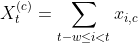
ここでは
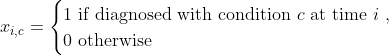
これらの特徴量を 2 つのステップで追加します。まずは、併存疾患インジゲーター関数を追加する関数(Xi,c)を定義します。
次に、 Spark SQL の強力なウィンドウ関数のサポートを利用して、連続する日数の範囲でこれらの指標関数を合計します。
併存疾患の特徴量を追加した後は、ターゲット変数を追加する必要があります。ターゲット変数は、患者が将来の所定の時間枠内(例えば、現在の診察から 1 か月後)にターゲット疾患と診断されるかどうかを示します。このオペレーションのロジックは、前のステップと類似していますが、時間枠が未来のイベントをカバーしている点が異なります。対象とする症状が将来診断されるかどうかを示す、バイナリラベルのみを使用します。
次に、これらの特徴量を Delta Lake の特徴量ストアに書き込みます。再現性を確保するために、特徴量ストアのカラムとして、MLFlow の実験 ID とラン ID を追加します。このアプローチによるメリットは、より多くのデータを取得することで、将来参照するために再利用できる新たな特徴量を特徴量ストアに追加できることです。
データの品質問題を制御する
トレーニングタスクに進む前に、クラス間で異なるラベルがどのように分布されているかを確認します。バイナリ分類の多くのアプリケーションでは、病気の予測などにおいて一方のクラスがレアになることがあります。このクラスの不均衡が、学習プロセスにマイナスの影響を及ぼします。推定プロセスにおいて、モデルは多数派のクラスに焦点を合わせてレアなイベントを犠牲にする傾向があります。さらに、評価プロセスも損なわれます。例えば、0/1 ラベルが 95% と 5%に分布している不均衡のデータセットでは、モデルは常に 0 を予測し、精度は 95% です。ラベルに不均衡がある場合、不均衡なデータを修正するために一般的なテクニックを適用する必要があります。
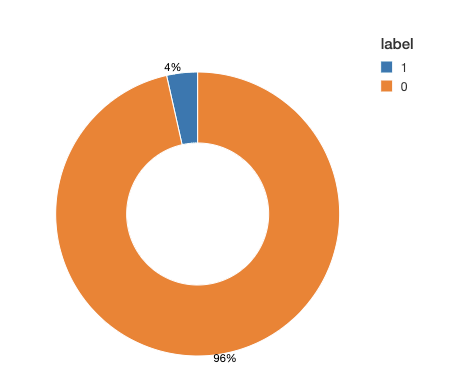
トレーニングデータを見てみると、データセットが極めて不均衡であることがわかります。タイムウィンドウの 95% 以上が診断の根拠を示していません。この不均衡を調整するために、コントロールクラスのダウンサンプルを行うか、合成サンプルを生成します。この選択はデータセットの規模や特徴量の数に依存します。この例では、多数派のダウンサンプルを行い、バランスのとれたデータセットを取得します。実際には、多数派のクラスのダウンサンプリングし、トレーニングアルゴリズムでクラスに重みを割り当てるなどメソッドを組み合わせる選択肢もあります。
モデルトレーニング
モデルをトレーニングするには、デモグラフィックと併存疾患の特徴量のサブセットで条件を補強してそれぞれの観測値にラベルを適用し、このデータをモデルに渡してダウンストリームのトレーニングを行います。例えば、ここでは、最近診断された併存疾患に加えて、エンカウンタークラス(例:予約の理由、予防治療/ER 受診)および受診�費用を追加し、デモグラフィック情報として、人種、性別、郵便番号、受診時の患者の年齢を選択しています。
多くの場合、元の臨床データはテラバイト規模になりますが、追加や除外の基準に基づいてレコードのフィルタ処理や制限をすることで、最終的には 1 台のマシンでトレーニングできるデータセットになります。Spark のデータフレームを pandas のデータフレームに容易に変換し、任意のアルゴリズムに基づいてモデルをトレーニングできます。Databricks の機械学習ランタイムを利用する場合は、広範なオープン ML ライブラリを容易に利用できます。
あらゆる機械学習アルゴリズムがパラメータのセット(ハイパーパラメータ)を受け取り、入力パラメータに応じてスコアが変動します。また、パラメータやアルゴリズムを間違えると、オーバーフィッティングの問題を起こすケースもあります。モデルの性能を確保するために、ここではハイパーパラメータチューニングを使用し、最適なモデルアーキテクチャを選択します。その後、このステップで取得したパラメーターを指定して最終的なモデルトレーニングを行います。
モデルチューニングを行うには、まずデータの前処理が必要です。このデータセットには、数値の特徴量(例えば、最近の併存疾患の数)の他に、カテゴリ変数のデモグラフィックデータ��があります。カテゴリ変数に最適なアプローチは、One-hot エンコーディングの使用です。これには 2 つ理由があります。第一は、ほとんどの分類器(この場合はロジスティック回帰)は数値の特徴量を取り扱うからです。第二は、カテゴリー変数を単純に数値指標に変換すると、データに序列性が生じ、分類器を誤認させる可能性があるからです。例えば、カリフォルニア州を 5、ニューヨーク州を 23 のように、州名を指標に変換すると、ニューヨーク州はカリフォルニア州よりも「大きい」ことになります。アルファベット順にリスト化した州名の指標を反映していますが、このモデルのコンテキストでは何の意味もありません。One-hot エンコーディングでは、このような効果を排除できます。
この場合の前処理のステップは、入力パラメータを必要としません。ハイパーパラメータは分類器のみに影響を与えるため、前処理には影響しません。前処理は別で実行し、モデルのチューニングには、その結果得たデータセットを使用します。
次に、モデルに最適なパラメータを選択します。この分類には、ロジスティック回帰を弾性ネット正則化と一緒に使用します。One-hot エンコーディングを適用した後��、問題のカテゴリ変数のカーディナリティに応じて、サンプル数を超える多くの特徴量を取得する可能性があります。このような問題に対するオーバーフィッティングを避けるには目的関数にペナルティを適用します。弾性ネット正則化のメリットは、2 つのペナルティ化手法(LASSO とリッジ回帰)を組み合わせることと、パイパーパラメータチューニングの過程で、混合の度合いを単一の変数で制御できることです。
このモデルを改善するために、hyperopt を使用してハイパーパラメータのグリッドを検索し、最適なパラメータを見つけます。さらに、hyperopt の SparkTrials モードを使用して、ハイパーパラメータを並列に検索します。このプロセスは、Databricks のマネージド MLflow を利用して、それぞれのハイパーパラメータの施行のおけるパラメータとメトリクスを自動的に記録します。各セットのパラメータのを検証するためには、モデルの評価の指標として k-分割交差検証を F1 スコアを用いて実行します。k-分割交差検証は複数の値が生成されるため、hyperopt を使用する際はスコアの最小値(ワーストケースのシナリオ)を選択し、それを最大化するようにしていることにご注意ください。

探索空間の検索を改善するために、logspace のパラメータのグリッドを選択し、hyperopt により提案されたパラメータを変換するための変換関数を定義します。アプローチの全体の概要と、ハイパーパラメータ空間の定義をこのように選択した理由については、こちらのトークでご覧いただけます。このトークでは、Databricks 上でエンドツーエンドの機械学習ライフサイクルを管理する方法を解説しています。
この実行で得る成果は、交差検証による F1 スコアに基づいて評価された最適なパラメータです。
次に、MLflow のダッシュボードを見てみましょう。MLflow は hyperopt の実行を自動的にグループ化します。そのため、図3のようにさまざまなプロットを用いて、各ハイパーパラメータが損失関数に与える影響を調べることができます。この機能は、モデルの動向の理解やハイパーパラメータによる効果を深く理解するために特に重要です。例えば、正則化の強さの逆数である C の値が低いと、F1 の値が高くなることに気づくことができます。
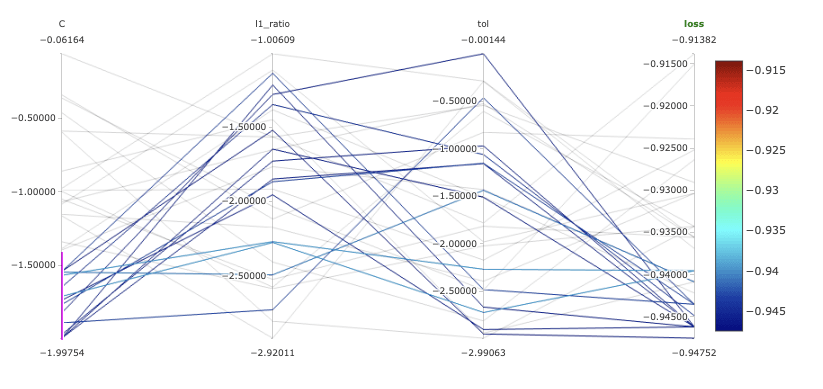
図3:MLflowで作成したモデルの平行座標
最適なパラメータの組み合わせを見つけた後は、最適なハイパーパラメータを用いてバイナリ分類器をトレーニングし、MLFLow でモデルをロギングします。MLflow のモデル API は、トレーニングに使用されたライブラリに関係なく、python 関数として容易にモデルを格納し、後にモデルのスコアリングの際に呼び出すことができます。モデルの発見性を高めるために、対象となる条件に関連した名前を付けてモデルを記録しています。(ここでは、”薬物の過剰摂取”)
ここで、前のステップで得られた最適なパラメータを指定して、モデルをトレーニングします。
モデルのトレーニングでは、sklearn のパイプラインの一部として、前処理(one-hot エンコーディング)を含め、エンコーダーと分類器を 1 つのモデルとして記録しています。次のステップでは、シンプルに患者データのモデルを呼び出して、患者のリスクを評価します。
モデルの展開と実運用化
モデルをトレーニングして MLflow に記録したら、次のステップは、そのモデルを用いた新たなデータのスコアリングです。MLflow では、��異なるタグを使用して実験を検索できる機能があります。例えばこの場合、モデルのトレーニングに指定された実行名を使用して、トレーニングモデルのアーティファクト URI を取得します。その後、主要な指標に基づいて取得した実験を並べ替えることができます。
特定のモデルを選択したら、モデルの URI や名前を指定してモデルをロードします。

Databricks のモデルレジストリを利用して、モデルのバージョンや運用ライフサイクル、モデルサービングを容易にすることもできます。
疾患の予測を高精度予防につなげる
このブログ記事では最初に、慢性疾患の発症を促進する臨床的およびデモグラフィック的な共変量を特定する精密予防システムの必要性について説明しました。次に、EHR から生成されたシミュレーションデータを用いて、薬物過剰摂取のリスクがある患者を特定するエンドツーエンドの機械学習ワークフローを見てきました。このワークフローの最後では、MLflowから学習した機械学習モデルをエクスポートすることに成功し、患者データの新��たなストリームに適用しました。
このモデルは参考にはなりますが、実際のプラクティスに移行できなければ成果はありません。リアルワールドの実践では、多くのお客様と協業し、これらと同様のシステムを実運用に展開してきました。例えば、サウスカロライナ医科大学では、EHR データを処理して敗血症のリスクがある患者を特定するライブストリーミングパイプラインを展開しています。これにより、敗血症による患者の衰弱を 8 時間前に発見できるようになりました。INTEGRIS Health 社では、同様のシステムを活用して、褥瘡(床ずれ)発生の兆候を EHR データでモニタリングしています。どちらの環境でも、患者が特定されると、ケアチームにその症状がすぐに通知されます。医療保険の領域では、Optum 社と協業して同様のモデルを展開しています。Optum 社では、長期、短期のアーキテクチャの回帰型ニューラルネットワークを使用する疾患予測エンジンを開発し、9 つの異なる疾患領域にわたって一般化を伴う疾患の進行を同定しています。このモデルは、患者に予防ケアのパスを割り当てるために用いられ、慢性疾患患者のアウトカムと治療コストの改善につながりました。
ここまでは、ヘルスケア領域における疾病予測アルゴリズムの活用にフォーカスしていましたが、これらのモデルを製薬業界のために構築して展開する機会も大いにあります。疾病予測モデルは、市販後に医薬品がどのように使用されているかの分析情報を提供します。また、これまで検知されなかった保護効果を検知し、ラベル表記の拡大に役立てることができます。さらに、疾病予測モデルを活用して、希少疾患や診断が不十分な疾患の臨床試験への登録を検討することも可能です。希少疾患の診断を受ける前に誤診された患者を検知するモデルを構築することで、臨床医に一般的な誤診のパターンを教育する教材を作成できます。また、試験の登録者数と有効性の改善につながる試験の包括的な基準を作成できるようになることも期待されています。
医療向け Delta Lake で高精度な予防を開始するには
このブログ記事では、慢性疾患の発症リスクを抱える患者を特定するために、リアルワールドのデータに機械学習を活用する方法を解説しました。医療データセットを格納、処理するための Delta Lake に関しては、リアルワールド医療データセットの操作に関する無料の eBook で詳細を説明しています。また、本ブログで使用した患者リスクのスコアリング Notebook をダウンロードして、無料トライアルを開始できます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。